一、grep工具快速查找表
grep与标准正则表达式结合常见条目:
| 形式 | 说明 |
|---|---|
| . | 这是一个英文的点号。表示匹配任意单个字符; |
| [] | 表示匹配指定范围内的任意单个字符; |
| [^] | 表示匹配指定范围外的任意单个字符; |
| * | 表示匹配前面的条目0次或多次; |
| .* | 表示匹配任意长度的任意字符; |
| \? | 表示匹配前边的条目至多一次,既 0次或1次; |
| \+ | 表示匹配前边的条目1次或多次; |
| \{n\} | 表示匹配前边的条目n次,多于n次,少于n次都不可行; |
| \{n,\} | 表示匹配前边的条目n次或n次以上,既大于等于n次; |
| \{,m\} | 表示匹配前边的条目至多m次,既小于等于m次;(GNU扩展用法) |
| \{n,m\} | 表示匹配前边的条目至少n次,至多m次,包含n和m且m要大于等于n; |
| A\|B | 表示A部分或者B部分; |
| \(...\) | 表示分组,其后可用\num对分组的内容做引用,num表示数字; |
| ^ | 脱字符表示锚定行首,可以理解为匹配到的是空串(empty string); |
| $ | 美元符表示锚定行尾,可以理解为匹配到的是空串(empty string); |
| ^$ | 表示匹配空白行; |
| \< | 表示单词词首锚定,可以理解为匹配到单词词首的空串(empty string); |
| \> | 表示单词词尾锚定,可以理解为匹配到单词词尾的空串(empty string); |
| \b | 表示单词边界的锚定,可以替代\<或\>,可以理解为匹配到单词边界的空串(empty string); |
| \B | 表示匹配单词边界之外的空串(empty string); |
| \w | 基本可以理解为与[_[:alnum:]]同义,表示匹配下划线以及字母数字字符; |
| \W | 基本可以理解为与[^_[:alnum:]]同义,表示匹配出下划线、字母数字字符之外的字符; |
| [:alnum:] | 表示字母数字字符,使用形式[[:alnum:]],如果要排除,可以配合脱字符[^[:alnum:]]; |
| [:alpha:] | 表示字母字符,使用形式[[:alpha:]],如果要排除,可以配合脱字符[^[:alpha:]]; |
| [:cntrl:] | 表示控制字符,使用形式[[:cntrl:]]后文有解析为何控制字符,不常用。如果要排除,[^[:cntrl:]]; |
| [:digit:] | 表示数字字符,使用形式[[:digit:]]。如果要排除,[^[:digit:]]; |
| [:graph:] | 表示可打印且可见字符,后文有注解。使用形式,[[:graph:]],不常用。如果要排除,[^[:graph:]]; |
| [:lower:] | 表示小写字母字符,使用形式[[:lower:]],如果要排除,[^[:lower:]]; |
| [:print:] | 表示可打印字符,使用形式[[:print:]],排除,[^[:print:]]; |
| [:punct:] | 表示标点符号字符,使用形式[[:punct:]],排除,[^[:punct:]];(除了文字字符[可以理解为字母],数字,控制字符,空格字符之外的字符) |
| [:space:] | 空格字符,使用形式[[:space:]],有空格,换页,换行,回车,横向制表符,纵向制表符;排除[^[:space:]]; |
| [:upper:] | 表示大写字母字符,使用形式[[:upper:]],排除,[^[:upper:]]; |
| [:xdigit:] | 表示16进制数字字符,使用形式[[:xdigit:]],排除,[^[:xdigit:]]; |
| [:blank:] | 表示空格或横向制表符字符,使用形式[[:blank:]],排除,[^[:blank:]]; |
grep与扩展正则表达式结合常见条目:
| 形式 | 说明 |
|---|---|
| . | 这是一个英文的点号。表示匹配任意单个字符; |
| [] | 表示匹配指定范围内的任意单个字符; |
| [^] | 表示匹配指定范围外的任意单个字符; |
| * | 表示匹配前面的条目0次或多次; |
| .* | 表示匹配任意长度的任意字符; |
| ? | 表示匹配前边的条目至多一次,既 0次或1次; |
| + | 表示匹配前边的条目1次或多次; |
| {n} | 表示匹配前边的条目n次,多于n次,少于n次都不可行; |
| {n,} | 表示匹配前边的条目n次或n次以上,既大于等于n次; |
| {,m} | 表示匹配前边的条目至多m次,既小于等于m次;(GNU扩展用法) |
| {n,m} | 表示匹配前边的条目至少n次,至多m次,包含n和m且m要大于等于n; |
| A|B | 表示A部分或者B部分; |
| (...) | 表示分组,其后可用\num对分组的内容做引用,num表示数字; |
| ^ | 脱字符表示锚定行首,可以理解为匹配到的是空串(empty string); |
| $ | 美元符表示锚定行尾,可以理解为匹配到的是空串(empty string); |
| ^$ | 表示匹配空白行; |
| \< | 表示单词词首锚定,可以理解为匹配到单词词首的空串(empty string); |
| \> | 表示单词词尾锚定,可以理解为匹配到单词词尾的空串(empty string); |
| \b | 表示单词边界的锚定,可以替代\<或\>,可以理解为匹配到单词边界的空串(empty string); |
| \B | 表示匹配单词边界之外的空串(empty string); |
| \w | 基本可以理解为与[_[:alnum:]]同义,表示匹配下划线以及字母数字字符; |
| \W | 基本可以理解为与[^_[:alnum:]]同义,表示匹配出下划线、字母数字字符之外的字符; |
| [:alnum:] | 表示字母数字字符,使用形式[[:alnum:]],如果要排除,可以配合脱字符[^[:alnum:]]; |
| [:alpha:] | 表示字母字符,使用形式[[:alpha:]],如果要排除,可以配合脱字符[^[:alpha:]]; |
| [:cntrl:] | 表示控制字符,使用形式[[:cntrl:]]后文有解析为何控制字符,不常用。如果要排除,[^[:cntrl:]]; |
| [:digit:] | 表示数字字符,使用形式[[:digit:]]。如果要排除,[^[:digit:]]; |
| [:graph:] | 表示可打印且可见字符,后文有注解。使用形式,[[:graph:]],不常用。如果要排除,[^[:graph:]]; |
| [:lower:] | 表示小写字母字符,使用形式[[:lower:]],如果要排除,[^[:lower:]]; |
| [:print:] | 表示可打印字符,使用形式[[:print:]],排除,[^[:print:]]; |
| [:punct:] | 表示标点符号字符,使用形式[[:punct:]],排除,[^[:punct:]];(除了文字字符[可以理解为字母],数字,控制字符,空格字符之外的字符) |
| [:space:] | 空格字符,使用形式[[:space:]],有空格,换页,换行,回车,横向制表符,纵向制表符;排除[^[:space:]]; |
| [:upper:] | 表示大写字母字符,使用形式[[:upper:]],排除,[^[:upper:]]; |
| [:xdigit:] | 表示16进制数字字符,使用形式[[:xdigit:]],排除,[^[:xdigit:]]; |
| [:blank:] | 表示空格或横向制表符字符,使用形式[[:blank:]],排除,[^[:blank:]]; |
二、grep概述以及常用选项说明
2.1、grep概述
grep是linux常见文本处理工具之一,是我们俗称文本处理"三剑客"工具之一,比较实用。他的功能就是打印通过指定模式(pattern)所匹配到的行。grep工具是由grep软件包提供的,grep软件包提供的工具其实有三个,分别是grep,fgrep,egrep,由于历史版本原因,还保留着fgrep,egrep,不过grep可以通过加上指定的选项来使用fgrep和egrep的功能,而且官方也建议不用使用fgrep,egrep。详细用法请参见后面部分的语法结构和选项类说明。
2.2、grep语法结构和基本选项说明(非完整版)
2.2.1、grep语法结构
grep [OPTIONS] PATTERN [FILE...]
grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]
注解部分: 其中OPTIONS表示选项,可以省略;PATTERN表示指定的模式,为了考虑shell解析特殊符号原因,这个模式平常我们见到最多的时候是用单引号或双引号所引起来,其实可以不用引用起来,视具体使用情况而定。PATTERN可以由-e明确指明,表明后边部分使一个匹配所用到的模式。FILE表示所处理的目标文件,如果要从文件中读取其他选项,可以加上-f 并后边指明文件,正常情况我们用到最多的语法是以下这两种:
xxx | grep 选项 '模式'
grep 选项 '模式' 被处理的文件
2.2.2、grep基本选项说明
-h:查看帮助信息
-V,--version:查看版本信息
2.2.3、grep匹配正则选择相关的选项
-G, --basic-regexp:表示grep使用pattern部分通过基本正则语法来解析(也是默认的选项);
-E, --extended-regexp:表示grep使用pattern部分通过扩展正则语法来解析(替代来egrep这个工具);
-P, --perl-regexp:表示grep使用pattern部分通过perl正则语法来解析(grep断言就是perl正则的语法);
-F, --fixed-strings:表示grep使用pattern部分不使用正则表达式解析,就当做一般搜索过滤的字符串(替代来fgrep
这个工具);
2.2.4、grep匹配控制相关的选项
-e PATTERN, --regexp=PATTERN:这个是POSIX风格的选项,表示显式指明-e表明后边是一个PATTERN,
可以有多个这样的选项;
-f FILE, --file=FILE:这个是POSIX风格的选项,表示通过在指定的文件中指定grep要使用的pattern,这个文件
的语法为,每行一个pattern,如果指定来-f或--file选项且文件内容为空,表示没有任何pattern,表示不做任何
处理(POSIX风格的选项);
-i, --ignore-case:表示pattern匹配的部分忽略字符串大小写(POSIX风格的选项);
-v, --invert-match:表示反选匹配的内容。默认是匹配到的行才输出,反选后打印不匹配的行(POSIX风格的选项);
-w, --word-regexp:表示只匹配精确的单词(由字母,数字,下划线组成),特殊字符(不是字母,数字,下划线)可以
起到分隔单词的作用,具体示例演示会更加明白;
-x, --line-regexp:表示全行完全匹配才打印出来(POSIX风格的选项);
2.2.5、grep匹配通用输出选项
-c, --count:只输出匹配的行或者目标的数量;
--color[=WHEN], --colour[=WHEN]:控制输出颜色,可选参数never(表示不带颜色),always,auto(表示带颜色);
-l, --files-with-matches:只打印匹配到的文件名;
-m NUM, --max-count=NUM:表示匹配多少行文本后退出,不管是否有匹配到;
-o, --only-matching :打印仅仅匹配到的行中的内容而不是一整行都输出;
-q, --quiet, --silent:安静模式,可以通过分析命令退出状态来判断是否匹配到来内容
2.2.6、grep输出行前缀选项
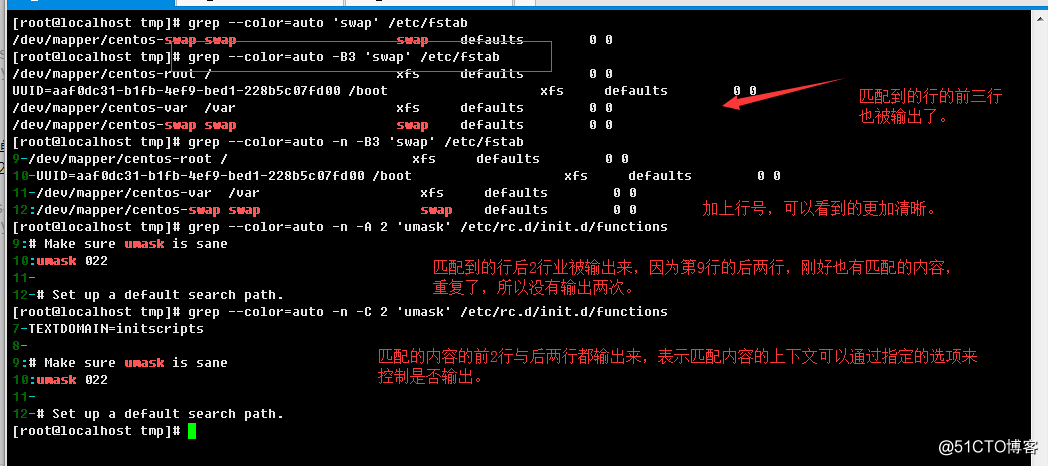
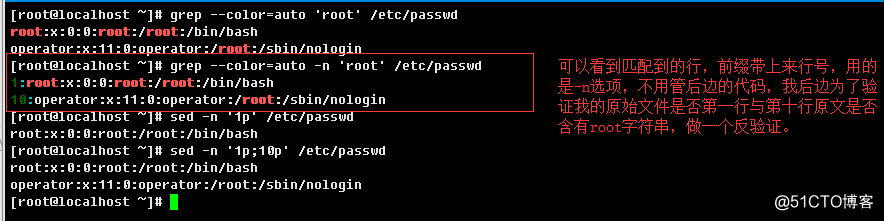
-n, --line-number:给输出的文本前边加上行号标记,行号与原始文本所在行保持一致;2.2.7、grep控制匹配输出上下文选项
-A NUM, --after-context=NUM:除了匹配到的行输出,也输出匹配到行的后NUM行;
-B NUM, --before-context=NUM:除了匹配到的行输出,也输出匹配到行的前NUM行;
-C NUM, -NUM, --context=NUM:除了匹配到的行输出,也输出匹配到行的前NUM行和后NUM行;
小贴士:如果前后的行不够,就保持默认,比如如果前面没有2行,而指定了-B 中的NUM等于2,就
有多少行输出多少行,-A和-C选项同理;2.2.8、grep文件和目录选择相关选项
--include=GLOB:仅仅从GLOB匹配的文件中去搜索;
-r, --recursive:递归查找,对于如果指明的文件为符号链接文件,会去检索,如果是其他匹配到的符号链接文件
例如 .下刚好有个符号链接文件,这种情况,符号链接文件就会被跳过,也就是说-r如果要检索到的文件也包括
符号链接文件本身,要去显示在命令行上指明这个符号链接文件;
-R, --dereference-recursive:递归查找,与-r的区别在于是否检索符号链接文件,这个就是不管是什么情况,只
要符号链接文件有满足的,都会被检索出来;
2.3、grep的标准正则与扩展正则语法说明
2.3.1、正则表达式的概述
正则表达式(REGEXP,Regular Expression)指的是由一类特殊字符及文本字符所编写的模式,其中有些字符不表示其字面意义,而是用于控制和通配的功能。它类似于算术表达式,通过使用各种运算符来组合微小的表达式。grep工具所支持正则表达式的有三类,分别是:基本正则表达式(BRE,Basic Regular Expression),扩展正则表达式(ERE,Extended Regular Expression)以及perl正则表达式(Perl's Regular Expression);就其功能实现来讲,grep所支持的正则表达式,基本的正则表达式与扩展的正则表达式所能实现的功能几乎无差异,都可以相互转换,只是表达形式略有不同而已。可能其他应用程序所实现的正则表达式语法,扩展正则表达式语法要比基本正则表达式语法功能实现要强,不过我们这里不加赘述。不过Perl所能实现的正则表达式语法要比前两者都要强大而且复杂。
不管正则表达式是否真如它所描述的这样神秘,我们理解起来无非是不同的字符的组合,就其字符本身,并没有新的东西,无非是定义来一些特定格式的组合用来表述其不同的含义。匹配单个字符是正则表达式是用来匹配一个组成代码块的基础,可以理解为,大部分的字符,包括所有的字母,通过可以都通单个字符组成的代码块的组合来匹配。任何在正则表达式中具有特殊含义的元字符都可以反斜杠(转移字符)来引用。元字符(meta-characters)大概有以下这些:
?,+,{,|,(,)等正是由于这些元字符的引入,才让正则表达式有了丰富的含义和神秘感,而且这些特定元字符在基本正则表达式以及扩展正则表达式中表现形式略有不同,简单来说就是基本正则表达式中要用到这些特定元字符要转移,而扩展正则表达式中表示则不用,具体后面小节中会举例引用说明。
2.3.2、与大括号组合的字符类匹配
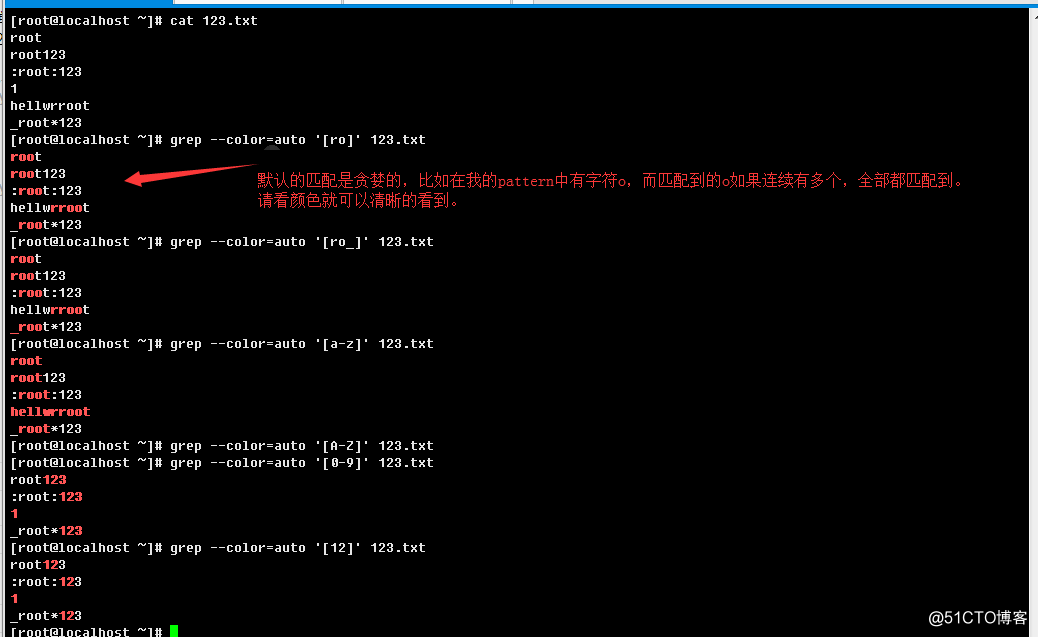
一组大括号表达式是由[和]括起来的一系列字符。表示匹配这个括号内所有字符中的任意单个字符。如果里面的第一个字符是^,表示匹配排除括号内的所有字符之外的任意单个字符,例如[0123456789]表示匹配0到9这10个数字中的任意一个数字,而[^0123456789],表示出了数字之外,其他任意的单个字符。简单表示形式如下:
[]:表示匹配括号内任意的单个字符;
[^]:表示匹配除了括号内字符以外的任意单个字符;
在大括号的表达式中,一个范围表达式的组成,由两个字符中间加上一个减号(-)相连接,例如像[a-z],[2-9]等。这个字符序列,边界,左边的值和右边的值要按照一定的顺序,比如常见的[a-z]就不能写成[z-a],[0-9]不能写成[9-0],可以很简单的理解成从小到大,左边的字符值要比右边的小,而且要连续。在我们常见的linux,unix环境中,一般的locale校验,都是大小写敏感,所以[a-d]一定是表示[abcd],但是针对不同的系统的locale值,可能[a-d]可能表示为[aAbBcCdD],不过后者我们不用关系。简单表示形式如下:
[start-stop]:表示一组连续的字符,我们可以中间加上一个减号来连起来,表示取这一组范围内的任意单个字符;
其中start不管是数字还是字符,都应该在stop前,例如a在b前,a在c前,0在9前。所以常见表示有:
[a-z]:表示匹配所有小写字母(还是只匹配单个字符,连续26个小写字母中的任意单个字符);
[A-Z]:表示匹配所有大写字母(还是只匹配单个字符,连续26个大写字母中的任意单个字符);
[0-9]:表示匹配所有数字(还是只匹配单个字符,连续10个数字中的任意单个数字字符);
[a-zA-Z]:表示匹配所有字母字符(还是只匹配单个字符);
[a-zA-Z0-9]:表示匹配字母数字字符(也是匹配括号内任意单个字符);
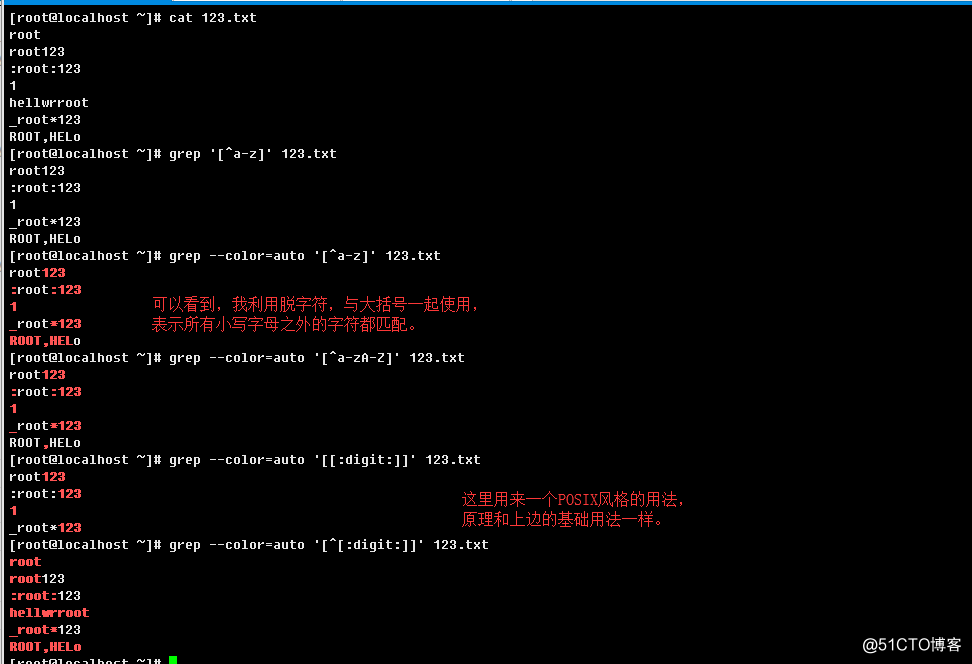
当然,也可以这样写[6-9],[c-f]等;除了以上两种形式之外,还有一组POSIX风格的组成,都有其特定含义:
[:lower:]:小写字母字符;
[:upper:]:大写字母字符;
[:alpha:]:字母字符(大小写字母);
[:digit:]:数字字符;
[:xdigit:]:16进制的数字字符;
[:alnum:]:字母数字字符;
[:cntrl:]:控制字符;
[:graph:]:可打印且可见字符(空格属于可打印字符,但是它不可见);
[:print:]:可打印字符(控制字符都不可打印)
[:punct:]:标点符号字符(除了文字字符[可以理解为字母],数字,控制字符,空格字符之外的字符);
[:space:]:空格字符,包括:空格(' '),ascii码表换页字符('\f'),ascii码表换行字符('\n'),ascii码表回车字符('\r')
ascii码表横向制表符('\t'),ascii码表纵向制表符('\v');
[:blank:]:空格(' ')或横向制表符字符('\t');
上面中的[]是一个整体,是和中间的字符串一起组成表示一类特定含义的,如果要使用,要配和再加一层大括号,
例如[^xxx],[...],其中xxx和...就可以引用这些特定的命名类,[^[:alnum:]]表示除了[:alnum:]匹配的到的之外的,
[[:alnum:]]表示[:alnum:]匹配到的,在于这种特殊类的一起配和使用的时候,并且在大括号中,有些特殊要
记忆的东西,比如[_[:alpha:]]这种用法,就除了匹配[:alpha:]匹配到的之外,还包括了下划线字符。那么如果
对于要匹配像"[","]","^","-"本身的含义,书写位置是有讲究的,分别可以这样设置:[^a-z^],[a-z-]或
[-a-z],[a-z[],[]a-z]等。
2.3.3、位置锚定和特殊字符组合
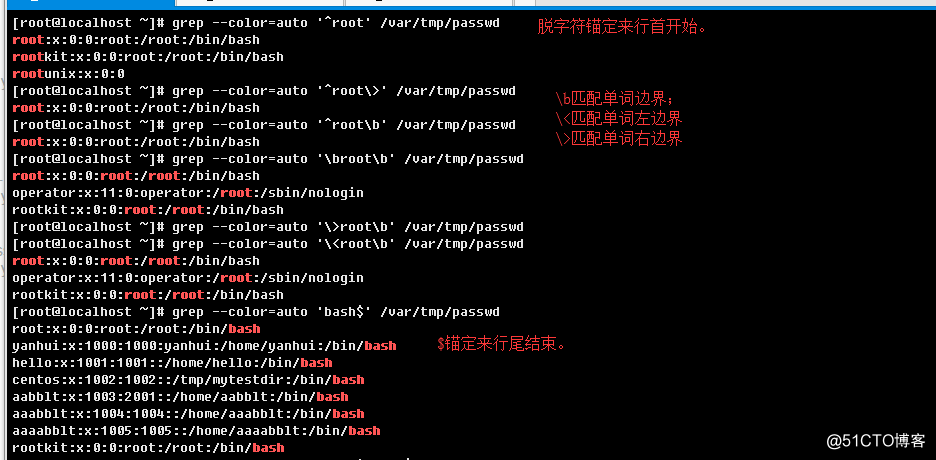
锚定字符,其中有两个元字符,一个脱字符(^)表示锚定行首,一个是美元符($)表示锚定行尾;
与位置锚定字符相似的有一个特殊的表示,由右斜杠"\"组合特殊字符"<"或">"所构成,分别为:
\<:表示匹配单词的行首;
\>:表示匹配单词的行尾;
而另外有几个比较特殊的,也是由\一般字母字符所组成,分别为:
\b:表示匹配单词的边界,边缘;(可以用来替代\<和\>做单词词首和词尾锚定用);
\B:表示除了单词边缘空串之外的所有空串;
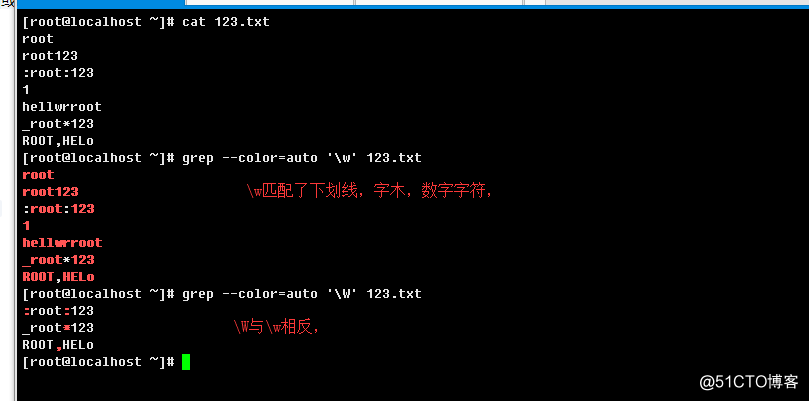
\w:与[_[:alnum:]]同义,表示匹配下划线,字符,数字字符;
\W:与[^_[:alnum:]]同义,表示匹配非下划线,字母数字字符;
2.3.4、匹配次数相关
?:表示前边的条目匹配至多一次(0次或1次);
*:表示前边的条目匹配0次或多次;
+:表示前边的条目匹配1次或多次;
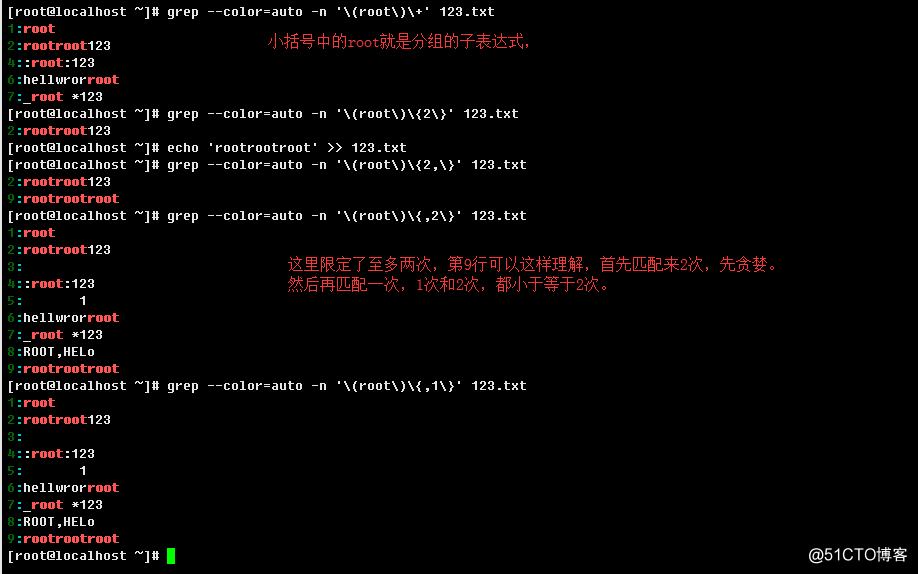
{n}:表示前边的条目精确匹配n次,多于n和少于n次都不行;
{n,}:表示前边的条目匹配n次或n次以上;
{,m}:表示前边的条目匹配至多m次,小于等于m,这个是GNU扩展用法(有时候不一定可行,非标准);
{n,m}:表示前边的条目匹配至少n次,至多m次;
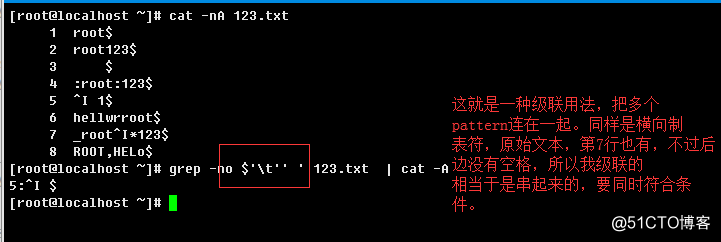
2.3.5、级联与交替
级联(Concatenation)简单来说就是可以多个pattern分开组合在一起来完成特定的工作,例如$'\t'' '表示匹配一个
横向制表符与后边的一个空格字符组合的结果;
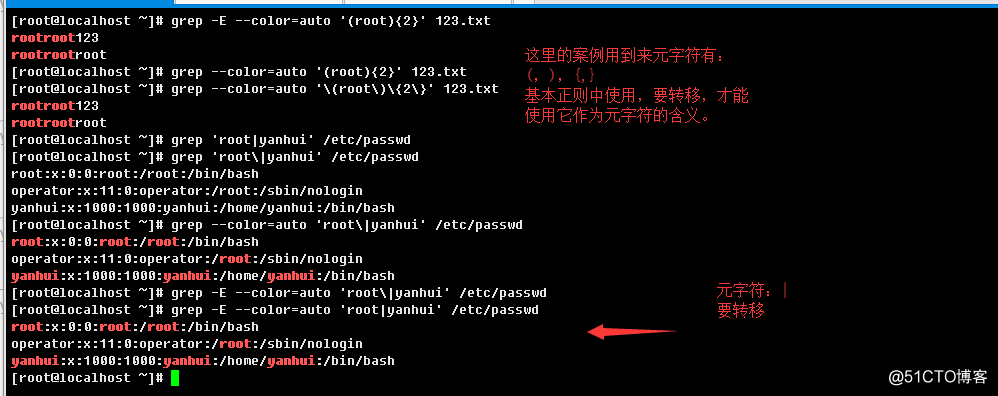
交替(Alternation)表示二者可选值,可以利用符号|来组合左边和右边的部分,用来匹配左边或右边的部分,表示
形式如下:
X|Y:匹配X或匹配Y;
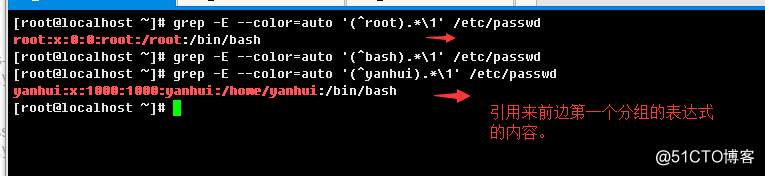
2.3.6、分组与后向引用以及优先顺序
分组就是把特定的pattern用小括号"()"所引起来,用来作为一个整体,也可以理解为把一个或多个字符串绑定在
一起。例如(^xy)+ab,这样元字符"+"修饰的就是分组内的一个整体了。
后向引用:表现形式为 \n,其中n是数字,表示引用前面正则表达式匹配的以小括号()引用起来的子串部分,
表示反向引用或后向应用。例如:
([^a-z])a.*\1其中()中的内容是一个子pattern,\1就是引用这个子pattern匹配到的部分;()可以嵌套使用,
不过不具备交叉性,即([^a-z]a([[:alnum:]]*)) 其中括号不能相交引用;
2.3.7、基本正则表达式与扩展正则表达式的比较
在基本正则表达式中,元字符(?,+,{,|,(,) ),如果不加转移字符使用,只会表示符号本身含义,不会作为正则
元字符含义,所以如果要作为特殊元字符含义,比如表现为以下形式
\?
\+
\{
\|
\(
\)
而在扩展正则表达式语法中(使用egrep或者grep -E或grep --extended-regexp),这些元字符可以直接使用:
?
+
{
}
(
)2.4、关于grep使用断言语法基本解析(选读)
三、grep使用示例分析与说明
3.1、字符匹配基础用法
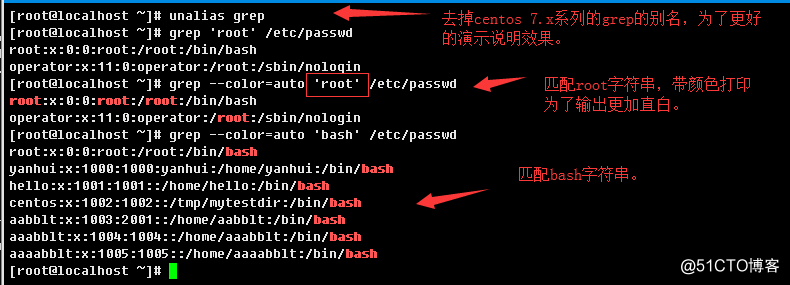
3.1.1、基本字符串匹配的行
3.1.2、打印行号
3.1.3、只输出匹配到的部分
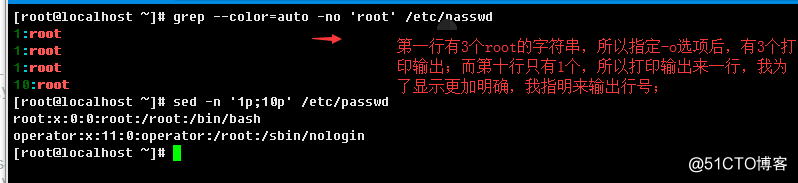
3.1.4、输出匹配到行的数量

3.1.5、反向匹配的结果
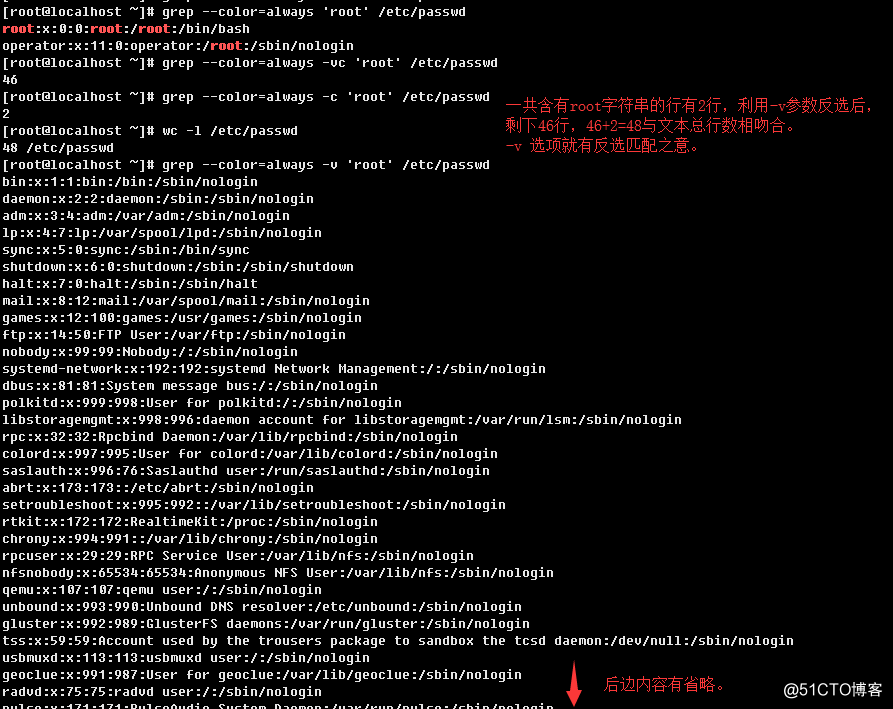
3.1.6、匹配忽略大小写
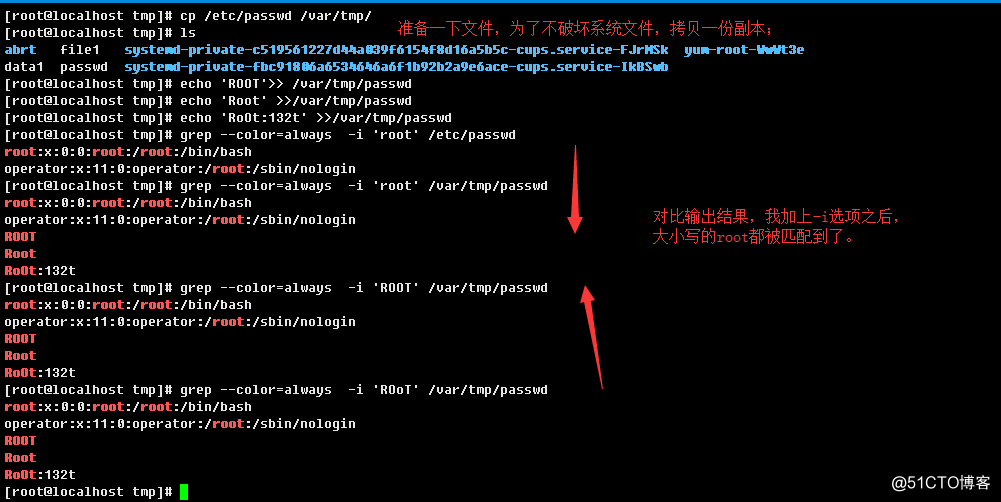
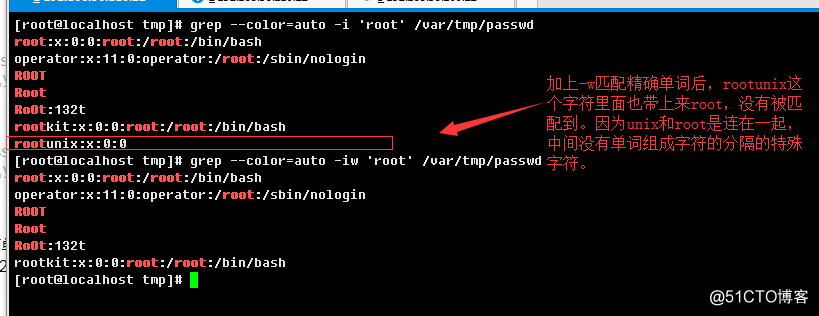
3.1.7、只匹配单词行和精确单词行
这里有个概念要知道一下,单词是有特殊字符分隔的,比如常见的冒号,逗号,空白符号等。而单词是由字母,数字,下划线组成;-w选项指明后,如果一个字符串,例如rootkit:124,root:123,那么前者"rootkit:124"就不会被匹配到,后者"root:123"才会被匹配到。请看示例: