深度学习领域的发展日新月异,在自然语言处理(NLP)、计算机视觉等领域取得了巨大突破。然而,早期的循环神经网络(RNN)在处理长序列时面临着梯度消失、并行计算能力不足等瓶颈。而 Transformer 的横空出世,以其独特的注意力机制和并行计算能力,彻底改变了序列建模的范式,为深度学习带来了革命性的变革。本文将深入探讨 Transformer 的核心思想、关键组件、技术演进路线、应用场景,旨在帮助大家全面理解 Transformer 的强大力量。
一、从 RNN 的瓶颈到 Transformer 的横空出世 💥
在 Transformer 诞生之前,循环神经网络(RNN)及其变体(如 LSTM、GRU)是序列建模的主流方法。RNN 通过循环结构处理序列数据,将当前时刻的输入和上一时刻的隐藏状态相结合,逐步提取序列的特征。然而,RNN 在处理长序列时存在以下主要问题:
RNN的结构
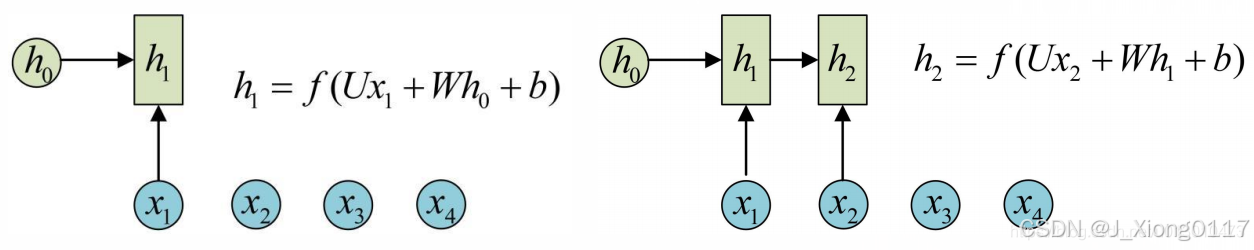
RNN的应用场景
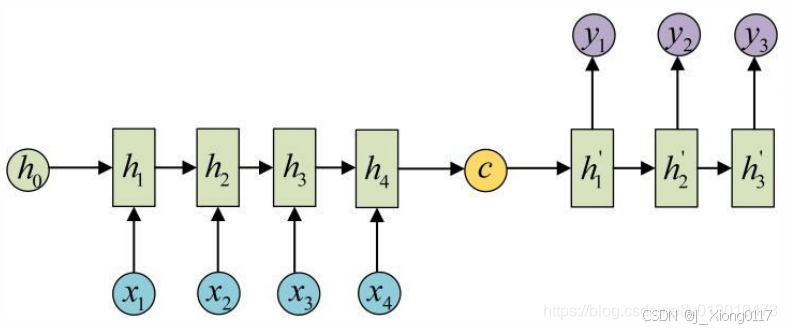
文本分类、情感分析(N vs 1)
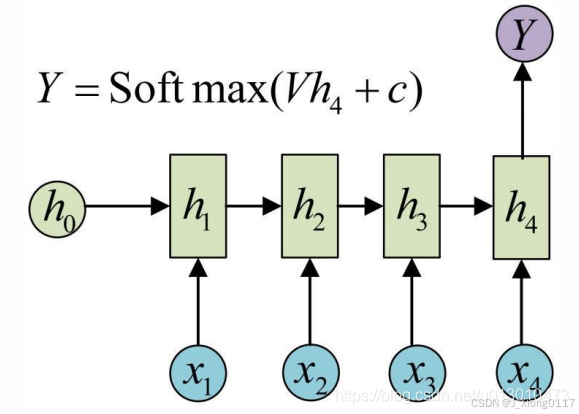
图片描述image caption(1 Vs N)
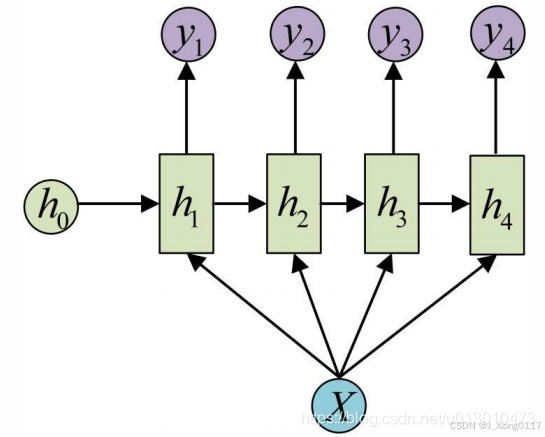
机器翻译(N vs M)
- 梯度消失/爆炸 📉: RNN 在反向传播过程中,由于参数共享和多次连乘的特性,梯度会随着时间步的增加而衰减或爆炸,导致模型难以训练或无法收敛。
- 难以并行计算 ⏳: RNN 的计算过程是基于时间步展开的,每个时间步都需要依次计算,造成计算效率较低。
- 长距离依赖建模能力不足 ⛓️: 由于梯度消失的原因,RNN 在处理长序列时难以捕捉到长期依赖关系,只能有效利用较短的上下文信息。
这些局限性阻碍了 RNN 在处理复杂序列任务上的进一步发展。为了解决这些问题,Google 提出了 Transformer 模型,该模型完全抛弃了循环结构,转而采用注意力机制(Attention Mechanism)来建模序列的依赖关系。Transformer 的出现标志着深度学习领域的一次重大突破,其优异的性能和并行计算能力迅速引起了广泛关注,并被广泛应用于各种序列建模任务中。


二、Transformer 的核心概念:注意力机制 🧠
Transformer 的核心思想是注意力机制,其目标是直接建模序列中任意两个位置之间的依赖关系,摆脱 RNN 的顺序依赖。注意力机制允许模型在处理某个位置的输入时,关注序列中所有位置的信息,从而更好地捕捉全局上下文信息。
1. Self-Attention(自注意力) 👁️
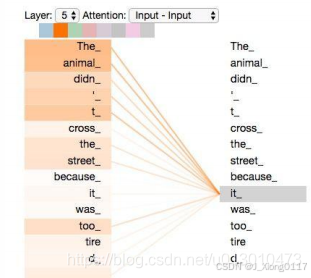
Self-Attention 是注意力机制的一种特殊形式,它关注输入序列内部的依赖关系。对于输入序列中的每个位置,Self-Attention 计算该位置与其他所有位置的关联程度,并根据关联程度加权求和,得到该位置的新的表示。这个过程相当于让模型为每个位置的表示融入上下文信息,从而更好地理解序列的含义。
具体来说,对于一个输入序列,Self-Attention 将每个位置的输入映射为三个向量:Query (Q), Key (K), 和 Value (V)。然后,通过计算 Query 和 Key 之间的点积,得到注意力权重,并对 Value 进行加权求和,得到该位置的输出。
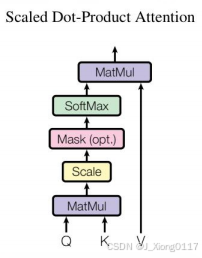
Scaled Dot-Product Attention
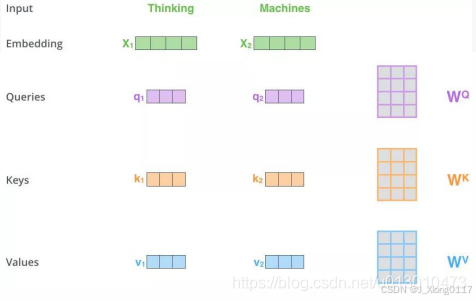
Step 1: 输入X,通过3个线性转换把X转换为Q、K、V。如下图,两个单词Thinking,Machines通过嵌入变换会得到两个[1x4]的向量X1,X2。分别与Wq,Wk,Wv三个[4x3]矩阵做点乘得到6个[1x3]向量{q1,q2},{k1,k2},{v1,v2}
Step 2: 向量{q1,k1}做点乘得到得分Score 112,{q1,k2}做点乘得到得分Score 96
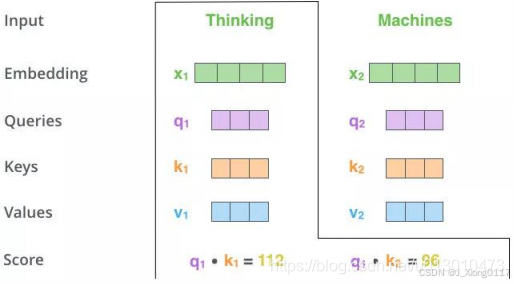
Step 3:对该得分就行规范,除以8.这样做的目的是为了使得梯度更稳定。之后对得分[14,12]做softmax得到比例[0.88,0.12]

Step 4: 用得分比例[0.88,0.12]乘以[v1,v2]值(Values)得到一个加权后的值。将这些值加起来得到z1。

2. Multi-Head Attention(多头注意力) 👯:
Multi-Head Attention 是 Self-Attention 的一种扩展,它并行执行多个注意力计算,每个注意力计算称为一个 “头”(head)。不同的头可以学习不同的注意力模式,捕捉不同的信息通道。通过并行执行多个注意力机制,模型可以更好地捕捉序列的复杂依赖关系,增强模型的表达能力。
Multi-Head Attention 的最终输出是将各个头的输出拼接起来,并通过线性变换得到。这种设计使得模型能够捕获更丰富的语义信息,从而提高模型性能。
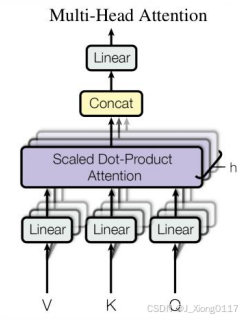
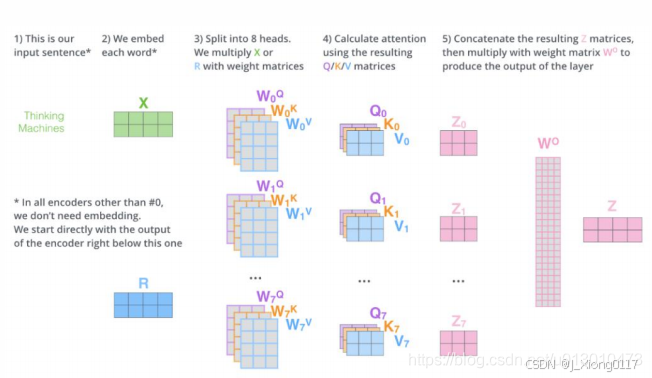
理解了Scaled Dot-Product Attention,Multi-Head Attention也很容易理解。Transformer论 文提到将Q、K、V通过一个线性映射之后,分成h份,对每一份进行Scaled Dot-Product Attention效果更好。然后,把各个部分的结果合并起来,再次经过线性映射,得到最终的 输出。这就是所谓的Multi-Head Attention。这里的超参数h就是heads的数量,默认是8。 上面说的分成h份是在dQ、dK和dV的维度上进行切分。因此进入到Scaled Dot-Product Attention的dK实际上等于DK/h。 Multi-head attention的公式如下:
其中,
dmodel=512,h=8,所以在Scaled Dot-Product Attention里面的
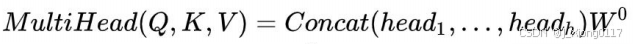
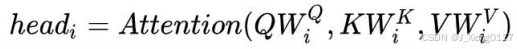
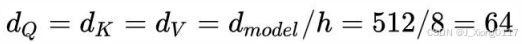
所谓Multi-Head,就是多做几次同样的事情,同时参数不共享,然后把结果拼接(类似于 卷积神经网络中用不同的卷积核来提取特征)。
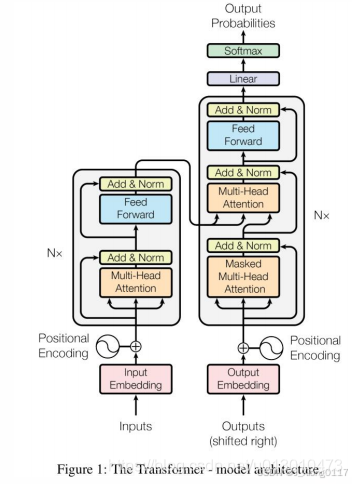
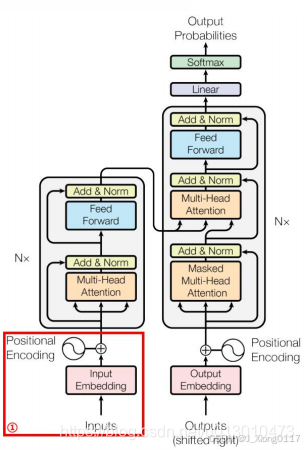
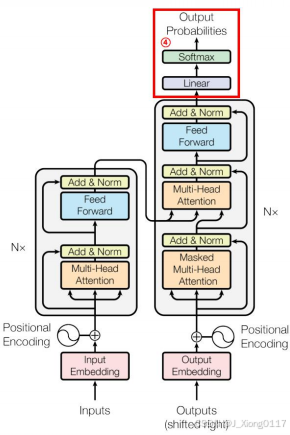
三、Transformer 的关键组件:编码器和解码器 🧱
Transformer 模型主要由编码器(Encoder)和解码器(Decoder)两部分组成,用于序列到序列的转换任务。
1. 编码器(Encoder) ⚙️:
编码器的作用是将输入序列编码为高维上下文向量,捕捉全局语义信息。编码器由多个相同的编码器层堆叠而成,每个编码器层主要由以下两部分组成:
多头注意力层(Multi-Head Attention) 👁️👯: 用于捕捉输入序列的依赖关系。
前馈神经网络层(Feed Forward Network) 🧠:用于对多头注意力的输出进行非线性变换。
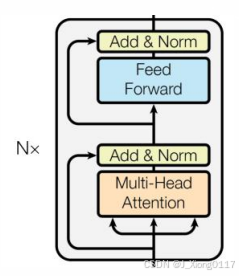
在每个子层之后,都添加了残差连接(Residual Connection)和层归一化(Layer Normalization),以加速模型训练并提高模型稳定性。编码器最终输出的是输入序列的上下文表示,包含了全局的语义信息。
2. 解码器(Decoder) 🧩:
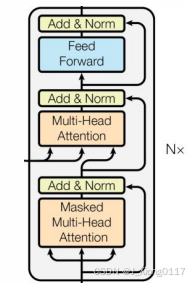
解码器的作用是根据编码器的输出和之前生成的输出,生成目标序列。解码器也由多个相同的解码器层堆叠而成,每个解码器层主要由以下三部分组成:
自注意力层(Masked Self-Attention) 🎭:类似于编码器的多头注意力,但只关注当前位置之前的信息,避免了信息泄露。
编码器-解码器注意力层(Encoder-Decoder Attention) 🔗: 该层使用解码器的输出作为 Query,编码器的输出作为 Key 和 Value,从而将编码器的上下文信息融入到解码器的输出中。
前馈神经网络层(Feed Forward Network) 🧠:用于对注意力层的输出进行非线性变换。
与编码器相同,解码器的每个子层之后也添加了残差连接和层归一化。解码器最终生成目标序列,并根据目标序列计算损失函数,进行模型训练。
3. 位置编码(Positional Encoding) 📍:
由于 Transformer 模型没有循环结构,无法捕捉序列的位置信息。为了让模型感知序列中元素的位置信息,需要引入位置编码。位置编码将每个位置的位置信息编码成一个向量,然后与输入向量相加,作为模型的输入。
常见的位置编码方法有正弦函数和余弦函数,也可以是学习的向量。使用正弦、余弦函数编码位置信息的原因在于,它们具有较好的泛化能力和周期性,便于模型学习相对位置信息。
其中,pos是指词语在序列中的位置。可以看出,在偶数位置,使用正弦编码,在奇数位置,使用余弦 编码。从编码公式中可以看出,给定词语的pos,我们可以把它编码成一个dmodel的向量。也就是说,位置 编码的每一个维度对应正弦曲线,波长构成了从2π到10000X2π的等比数列。
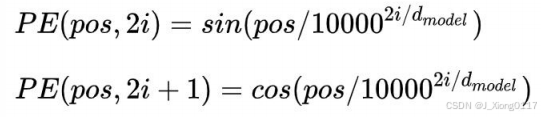
上面的位置编码是绝对位置编码。但是词语的相对位置也非常重要。这就是论文为什么使用三角函数的原因。正弦函数能够表达相对位置信息,主要数据依据是以下两个公式:
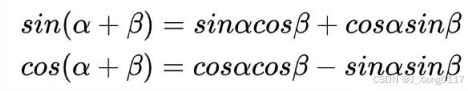
上面的公式说明,对于词汇之间的位置偏移k,PE(pos+k)可以表示成PE(pos)和PE(k)组合的形式, 相当于有了可以表达相对位置的能力。
四、技术详解:Self-Attention 的计算过程及 Multi-Head Attention 的优势 🧮
1. Self-Attention 计算过程
Self-Attention 的计算过程可以用以下公式表示:

其中,Q、K、V 分别代表 Query、Key、Value,dk 表示 Key 的维度。具体计算步骤如下:
线性变换 ➡️: 将输入向量通过线性变换分别映射为 Query、Key、Value 三个向量。
点积运算 ✖️:计算 Query 和 Key 之间的点积,得到注意力权重。
缩放 ➗:将点积结果除以 sqrt(dk) 进行缩放,避免点积过大导致梯度消失。
Softmax 📈:使用 softmax 函数将注意力权重归一化为概率分布。
加权求和 ➕:将注意力权重与 Value 进行加权求和,得到最终的输出。
该过程可以通过图示清晰展示 Q、K、V 的生成和计算流程,帮助理解 Self-Attention 的计算原理。
2. Multi-Head Attention 的优势
Multi-Head Attention 的优势主要体现在以下两个方面:
多头并行🚀: 不同头学习不同的注意力模式,捕捉不同的语义信息。
增强表达 💪: 模型更具鲁棒性,表达能力更强。
通过并行执行多个注意力计算,模型可以更好地捕捉序列的复杂依赖关系,避免模型陷入局部最优解,从而提高模型性能。
3. Transformer过程图解
3.1. Word embedding + Position encoding
• Inputs首先根据该语言词汇表的大小转成V维的one-hot向量v1;
• 根据one-hot向量和词嵌入模型(预训练好或者随机初始化)查找相应词向 量v2;
• v2添加位置编码向量信息(训练或用规则)得到带有位置信息的向量v3。
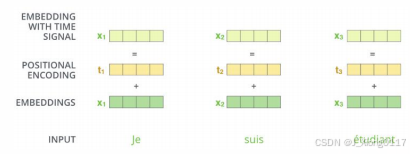
3.2 Encoder
上一步得到的v3向量作为Encoder1的输入,经过Self-Attention层得到Attention 的输出,再经过Feed Forward自动生成Encoder1的输出,Encoder1的输出作为 Encoder2的输入,以此类推,一直进入到顶层Encoder,输出矢量组成的列表 ,然后将其转化为一组attention的集合(K,V)。
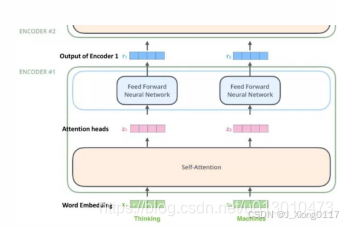
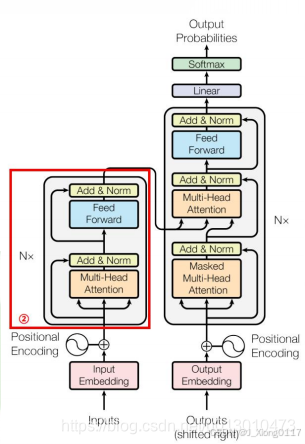
3.3 Decoder
上一步Encoder输出的attention的集合(K,V)将被送入到每个Decoder的 Encoder-Decoder attention模块作为K,V的输入(Q取Decoder中Self-Attention的 输出)。至于Decoder中的Self-Attention实现过程同Encoder的Self-Attention,重复6层,最后顶层Decoder输出浮点数向量列表。
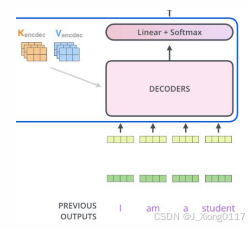
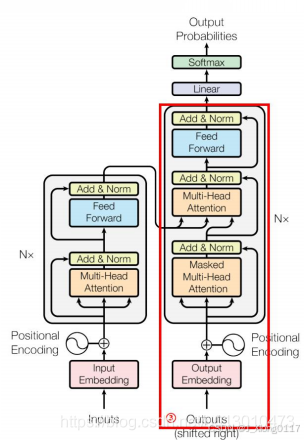
3.4 Final Linear + Softmax
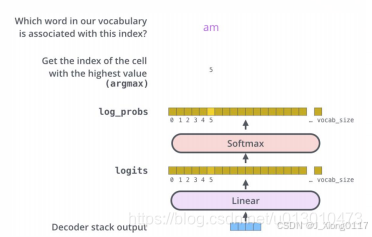
顶层Decoder也是一个隐层,输出是2048或1024(这里只是打个比方)的隐层。 那么这些隐层节点怎样对应到输出的词呢? 首先,我们对每种语言会有一个固定的词表,比如这个语言到底有多少个词, 比如中文里有2万词、3万词、5万词。对网络隐层会先过一个线性的投射层,去把它投射到一个词表大小的向量维度,形成一个词表大小向量,我们在这个向量基础上做softmax,把它转成概率。比如是3万的词,去选取里面概率最大的那个词作为我们实际的输出,这里面第五位是最大的,它会输出一个am,这样就 达到了通过Encoder输出隐层来去实际生成一个词翻译的效果。
3.5 loss function
Transformer的训练优化目标是概率的交叉熵cross entropy,以cross entropy作为梯度更新的优化目标。下图(左)是优化目标的loss随着训练的轮数的变化情况,因为是entropy,所以是稳定下降的过程。相应的,翻译的评价目标Bleu值是匹配度加权的分数,Bleu值越高越好,它随着训练过程的进行会有一个逐步向上升的过程。训练的优化目标就是这样的,通过交叉熵的优化来提升Bleu,就能实现翻译效果优化的过程。

4. 为什么 Transformer 没有梯度消失或爆炸?
无循环结构: Transformer 的 Self-Attention 计算不依赖于循环结构,梯度可以直接从输出层通过较短的路径传递到输入层,而不是像 RNN 那样经过多个时间步的循环传递,避免了因时间步增加而导致的梯度衰减或爆炸。
直接依赖: Self-Attention 直接计算输入序列中任意两个位置之间的依赖关系,梯度计算也直接作用于对应的权重矩阵,不会因为序列过长而产生梯度衰减。
标准化: sqrt(dk) 对 QK^T 的点积进行缩放,softmax 函数对注意力权重进行归一化,这些操作都有助于稳定梯度传播,防止梯度爆炸。
残差连接和层归一化: Transformer 中使用的残差连接和层归一化技术,也能够进一步缓解梯度消失和爆炸问题,使得模型更容易训练。
Transformer 中 Self-Attention 的梯度传播
在 Transformer 中,Self-Attention 层的核心计算如下:
1.计算 Query (Q), Key (K), Value (V):
Q = X W_Q
K = X W_K
V = X W_V
其中 X 是输入矩阵,WQ, WK, W_V 是可学习的权重矩阵。
2.计算 Attention 权重:
Attention Weights = softmax((Q * K^T) / sqrt(dk))
其中 dk 是 Key 的维度。
3.加权求和得到输出:
Self-Attention Output = Attention Weights * V
梯度传播过程:
假设 L 为损失函数,那么反向传播的目标是计算 ∂L/∂W_Q, ∂L/∂W_K, ∂L/∂W_V 这些权重矩阵的梯度,从而更新网络参数。
- 从输出层到 Attention 权重:
假设 O = Self-Attention Output, 则 ∂L/∂O 表示损失函数 L 对 Self-Attention 输出 O 的梯度。
根据 Self-Attention Output = Attention Weights * V,我们可以计算 ∂L/∂(Attention Weights):
∂L/∂(Attention Weights) = ∂L/∂O * V^T
注意,这里是直接计算,而不是通过多个时间步传递。
- 从 Attention 权重到 Q, K:
-
Attention Weights = softmax((QK^T) / sqrt(dk)),根据链式法则,求梯度比较复杂,但我们关注的是梯度的传播路径是直接的,不涉及时间的循环累积。 -
简化的表达方式:
∂L/∂Q = ∂L/∂(Attention Weights) * ∂(Attention Weights) /∂(QK^T) * K
∂L/∂K = ∂L/∂(Attention Weights) * ∂(Attention Weights) /∂(QK^T) * Q
∂(Attention Weights) /∂(QK^T) 这个项涉及到 softmax 和点积的导数计算,其本身也是一个稳定的算子,不会导致梯度消失或爆炸。
- 从 Q, K, V 到 W_Q, W_K, W_V:
根据 Q = XW_Q, K = XW_K, V = X*W_V,计算梯度为:
∂L/∂W_Q = X^T * ∂L/∂Q
∂L/∂W_K = X^T * ∂L/∂K
∂L/∂W_V = X^T * ∂L/∂V
注意,这里的梯度是直接与输入X和梯度乘积计算,而不是像RNN那样进行循环累乘。
五、Transformer 的技术演进路线:从最初到更高效 🛤️
Transformer 模型自 2017 年提出以来,经历了快速发展,涌现出许多变体和改进方法。以下是 Transformer 技术演进的主要路线:
-
最初的 Transformer 🥇:
原始的 Transformer 模型提出了 Self-Attention 机制和 Encoder-Decoder 架构,为后续的研究奠定了基础。
-
Transformer 的变体 🔄:
Reformer 🛠️: 利用局部敏感哈希 (LSH) 减少注意力计算量。
Longformer 📏: 结合全局和局部注意力,处理更长的序列。
BigBird 🐦: 使用随机稀疏注意力,降低计算复杂度。 -
更高效的注意力机制 ✨:
线性注意力 ➖:使用核函数近似注意力,实现线性复杂度。
全局注意力 🌐:引入全局 token,实现高效长序列建模。 -
模型加速和压缩 ⚡️:
量化 🔢: 将浮点数表示为低精度整数,减少模型大小和计算量。
剪枝 ✂️: 删除模型中不重要的参数,减少模型复杂度。
知识蒸馏 🧪: 将大模型的知识转移到小模型,加速推理。
这些改进方法旨在解决 Transformer 模型在计算量、参数量和长序列处理等方面的局限性,使得 Transformer 模型在各种应用场景中更加高效和实用。
六、Transformer 的应用场景:从 NLP 到多领域突破 🌍
Transformer 模型在各个领域都取得了巨大成功,特别是在自然语言处理(NLP)领域,其应用非常广泛:
-
自然语言处理 (NLP) 💬:
机器翻译 🌐:Transformer 模型成为翻译标准,大幅提升翻译质量和速度。(如 Google Translate)
文本摘要 📝:根据长文本生成简洁摘要,提高信息获取效率。(如新闻摘要工具)
文本生成 ✍️:生成高质量文本,如文章、代码、诗歌等。(如 GPT 系列)
文本分类 🏷️:对文本进行分类,如情感分析、垃圾邮件检测。(广泛应用于各种应用场景) -
其他领域 💫:
计算机视觉 🖼️: ViT 模型将 Transformer 应用于图像处理,取得了优异表现。(Transformer 在图像领域大放异彩)
生物信息学 🧬: 处理基因序列、蛋白质序列,进行生物信息分析。(Transformer 在生物信息学领域应用潜力巨大)
Transformer 在这些领域的成功应用,证明了其强大的建模能力和广泛的适用性。随着研究的深入,Transformer 在未来将在更多领域发挥重要作用。
七、总结与展望 🔮
Transformer 的出现是深度学习领域的一次革命性突破,它以独特的注意力机制和并行计算能力,彻底改变了序列建模的范式。本文从 Transformer 的核心概念、关键组件、技术演进路线、应用场景等方面进行了详细介绍,旨在帮助读者全面理解 Transformer 的强大力量。
-
Transformer 的优势 👍:
并行计算、长距离依赖、强大的表达能力。
-
Transformer 的局限 👎:
计算量大、模型参数多、长序列处理效率低。
Transformer 的未来发展前景广阔,随着技术的不断进步,相信 Transformer 将在更多领域取得新的突破。我们有理由相信,Transformer 将继续引领深度学习的未来,为人类社会带来更多的福祉。
参考链接:
https://blog.csdn.net/u013010473/article/details/105624048?spm=1001.2014.3001.5502
https://blog.csdn.net/u013010473/article/details/106342427?spm=1001.2014.3001.5502
https://blog.csdn.net/u013010473/article/details/106343190?spm=1001.2014.3001.5502
https://blog.csdn.net/u013010473/article/details/106344063?spm=1001.2014.3001.5502
https://blog.csdn.net/u013010473/article/details/106436994?spm=1001.2014.3001.5502
https://blog.csdn.net/u013010473/article/details/106439332?spm=1001.2014.3001.5502