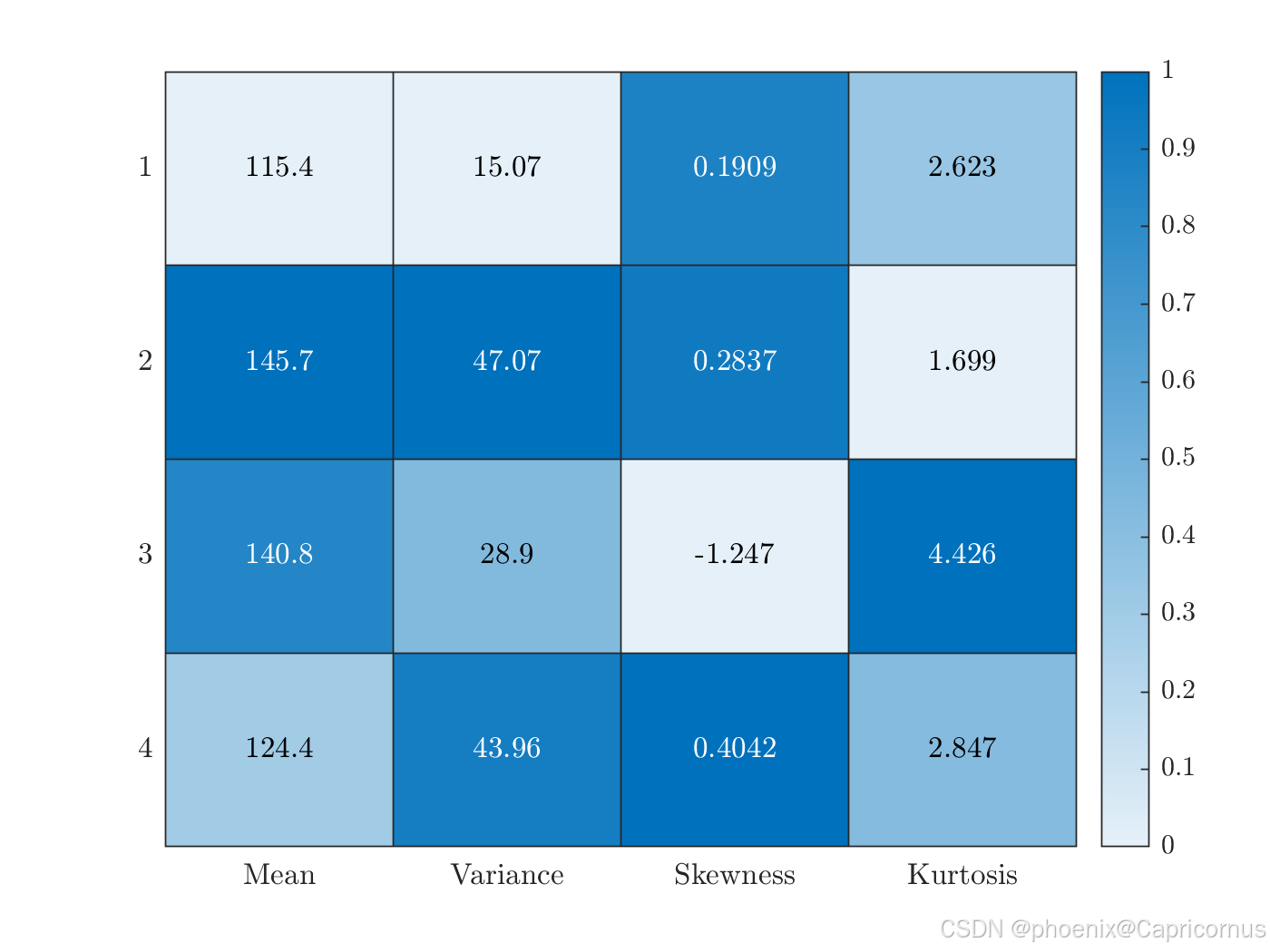
原点矩(Moment about the Origin)和中心矩(Central Moment)是概率论和数理统计中描述随机变量分布特征的统计量。
原点矩
原点矩基于随机变量与其原点(通常是0)之间的距离进行定义,用于描述数据的集中趋势、离散程度等特性。
对于一个随机变量 X X X,其 r r r阶原点矩定义为:
μ r = E ( X r ) \mu_r = E(X^r) μr=E(Xr)
其中:
- E E E表示期望值。
- r r r是一个正整数,表示矩的阶数。
连续型随机变量:如果 X X X是连续型随机变量,其概率密度函数为 f ( x ) f(x) f(x),则 r r r阶原点矩可以表示为:
μ r = ∫ − ∞ ∞ x r f ( x ) d x \mu_r = \int_{-\infty}^{\infty} x^r f(x) \, dx μr=∫−∞∞xrf(x)dx
离散型随机变量:如果 X X X是离散型随机变量,其概率分布列为 p ( x i ) p(x_i) p(xi),则 r r r阶原点矩可以表示为:
μ r = ∑ i x i r p ( x i ) \mu_r = \sum_{i} x_i^r p(x_i) μr=i∑xirp(xi)
中心矩
与原点矩不同,中心矩是基于随机变量与其期望值(均值)之间的偏差进行定义的,主要用于描述数据的离散程度、对称性和峰态等特性。
对于一个随机变量 X X X,其 r r r阶中心矩定义为:
m r = E [ ( X − μ ) r ] m_r = E[(X - \mu)^r] mr=E[(X−μ)r]
其中:
- E E E表示期望值。
- μ = E ( X ) \mu = E(X) μ=E(X)是随机变量 X X X的期望值。
- r r r是一个正整数,表示矩的阶数。
连续型随机变量:如果 X X X是连续型随机变量,其概率密度函数为 f ( x ) f(x) f(x),则 r r r阶中心矩可以表示为:
m r = ∫ − ∞ ∞ ( x − μ ) r f ( x ) d x m_r = \int_{-\infty}^{\infty} (x - \mu)^r f(x) \, dx mr=∫−∞∞(x−μ)rf(x)dx
离散型随机变量:如果 X X X是离散型随机变量,其概率质量函数为 p ( x i ) p(x_i) p(xi),则 r r r阶中心矩可以表示为:
m r = ∑ i ( x i − μ ) r p ( x i ) m_r = \sum_{i} (x_i - \mu)^r p(x_i) mr=i∑(xi−μ)rp(xi)
常用的统计矩
-
一阶原点矩(均值):
- 定义: μ 1 = E ( X ) \mu_1 = E(X) μ1=E(X)
- 描述:一阶原点矩即为随机变量的期望值,表示数据的中心位置或平均值。
-
二阶中心矩(方差):
- 定义: m 2 = E [ ( X − μ ) 2 ] m_2 = E[(X - \mu)^2] m2=E[(X−μ)2]
- 描述:二阶中心矩即为方差 σ 2 \sigma^2 σ2,表示数据的离散程度或波动大小。方差的平方根称为标准差 σ \sigma σ。
-
三阶中心矩:
- 定义: m 3 = E [ ( X − μ ) 3 ] m_3 = E[(X - \mu)^3] m3=E[(X−μ)3]
- 描述:三阶中心矩经过标准化(除以标准差的三次方)后称为偏度 γ 1 \gamma_1 γ1,用于描述分布的不对称性。正偏度表示分布有较长的右尾,负偏度表示有较长的左尾。
-
四阶中心矩:
- 定义: m 4 = E [ ( X − μ ) 4 ] m_4 = E[(X - \mu)^4] m4=E[(X−μ)4]
- 描述:四阶中心矩经过标准化(除以标准差的四次方)后称为峰度 γ 2 \gamma_2 γ2,用于描述分布的峰态或“尖峭”程度。标准正态分布的峰度为3,因此有时会报告超额峰度(即峰度减去3),以突出与正态分布相比的差异。
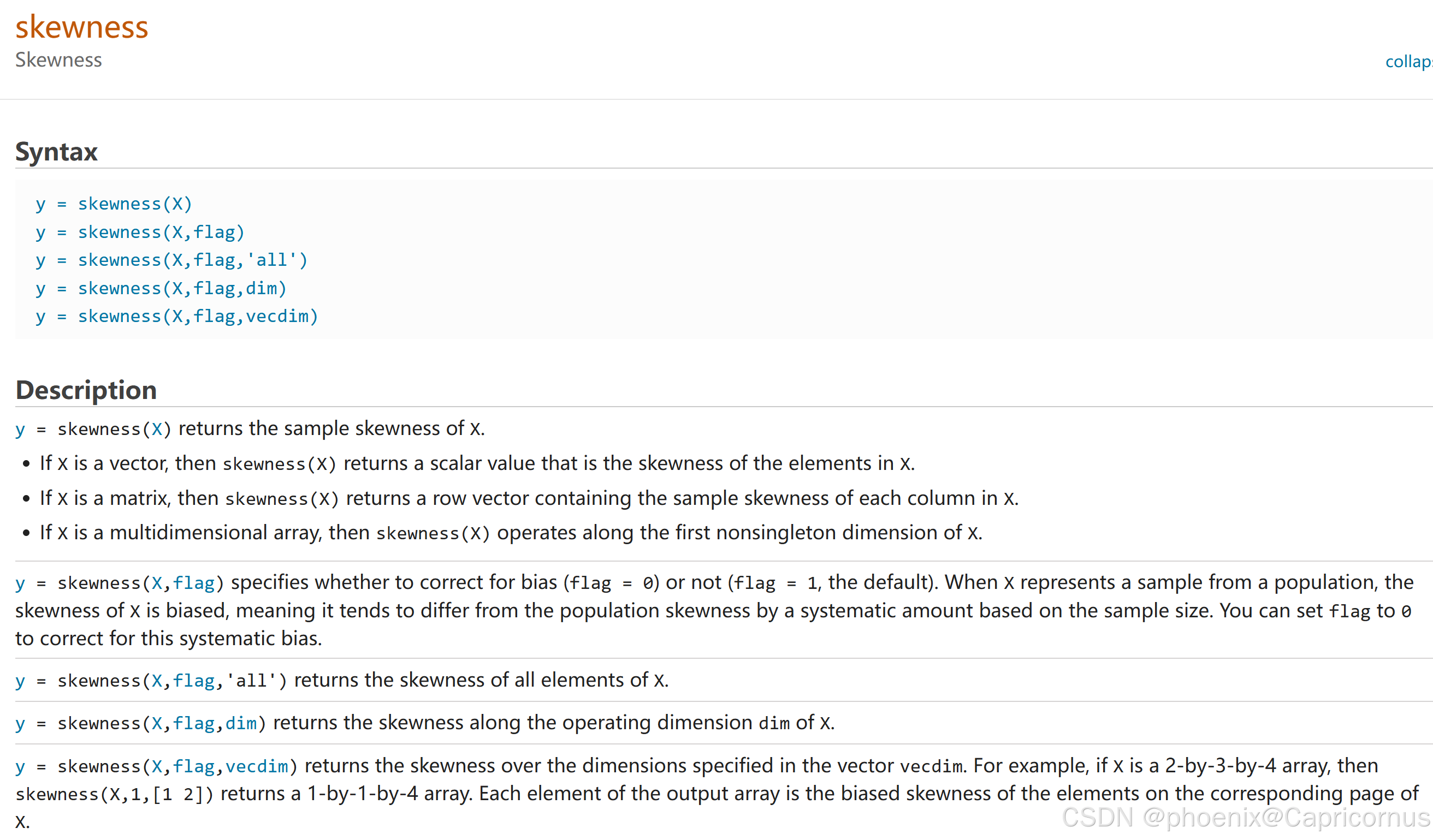
偏度(Skewness)
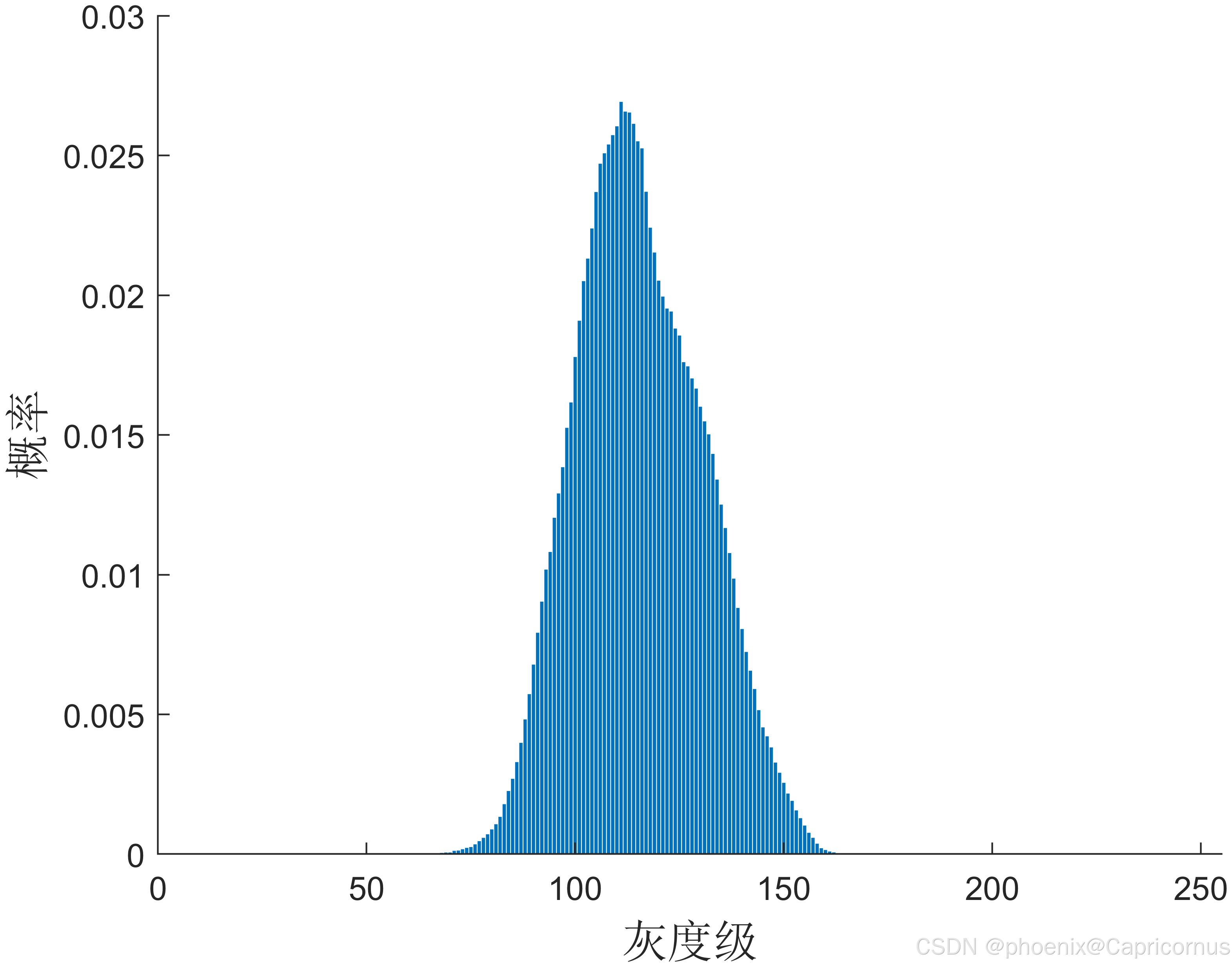
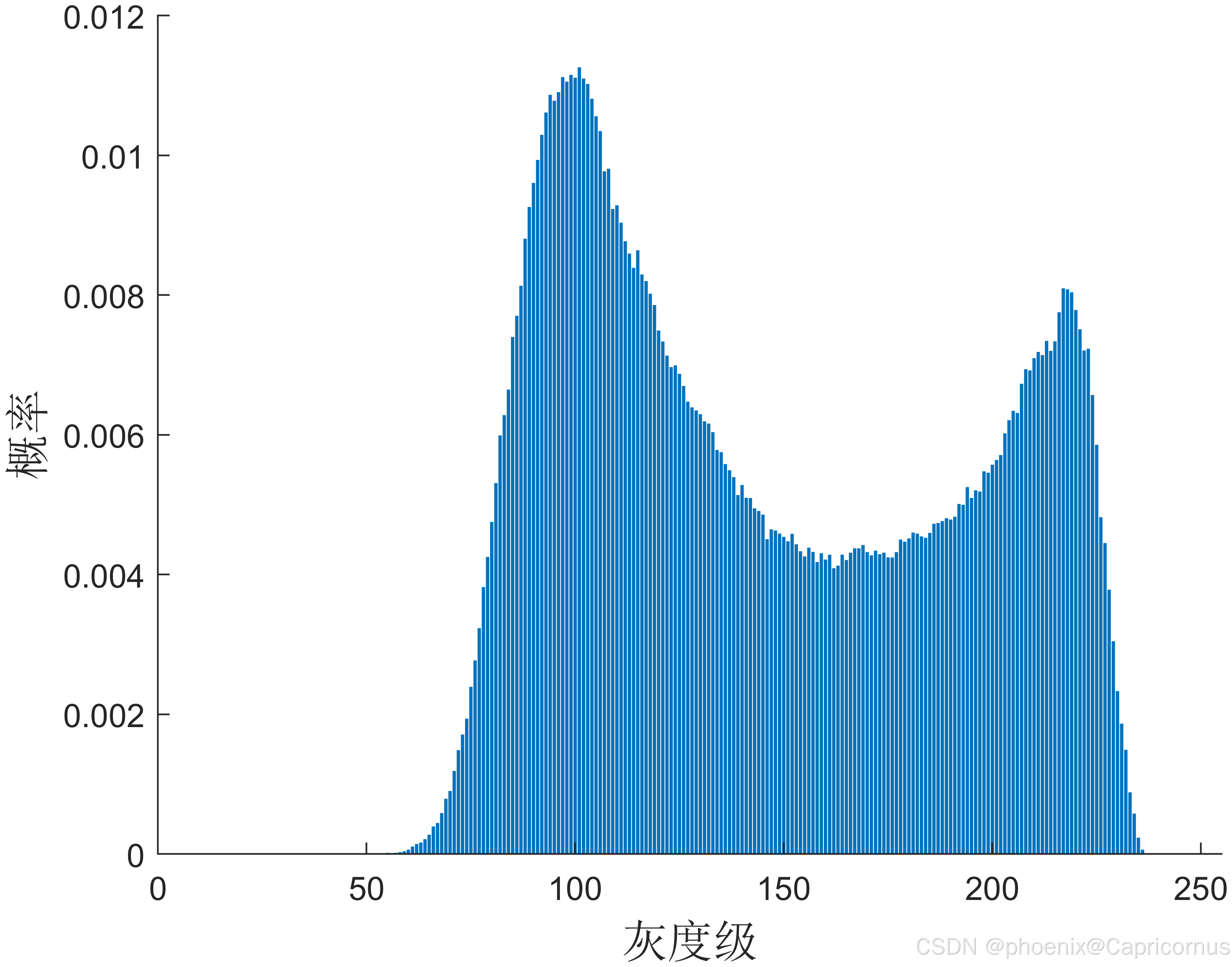
偏度(Skewness)是描述概率分布对称性的统计量,用于衡量数据分布的不对称程度。具体来说,偏度可以告诉我们数据分布的尾部是否偏向某一侧。正偏度表示分布有较长的右尾,而负偏度表示有较长的左尾。标准正态分布的偏度为0,表示其是对称的。
定义
偏度通常通过三阶中心矩标准化后得到。对于一个随机变量 X X X,其偏度 γ 1 \gamma_1 γ1定义为:
γ 1 = m 3 σ 3 \gamma_1 = \frac{m_3}{\sigma^3} γ1=σ3m3
其中:
- m 3 = E [ ( X − μ ) 3 ] m_3 = E[(X - \mu)^3] m3=E[(X−μ)3]是三阶中心矩。
- μ = E ( X ) \mu = E(X) μ=E(X)是随机变量 X X X的期望值。
- σ = m 2 = E [ ( X − μ ) 2 ] \sigma = \sqrt{m_2} = \sqrt{E[(X - \mu)^2]} σ=m2=E[(X−μ)2]是标准差,其中 m 2 m_2 m2是二阶中心矩(方差)。
标准差 σ \sigma σ的量纲与 X X X相同,因此 σ 3 \sigma^3 σ3的量纲也是 X X X的量纲的三次方。通过除以标准差的三次方,偏度成为了一个无量纲的统计量,不受量纲的影响,使得不同数据集的偏度可以直接进行比较。
解释
-
正偏度(Positive Skewness):
- 当 γ 1 > 0 \gamma_1 > 0 γ1>0时,表示分布有较长的右尾。这表明大多数数据集中在左侧,而右侧有少量极端值。
-
负偏度(Negative Skewness):
- 当 γ 1 < 0 \gamma_1 < 0 γ1<0时,表示分布有较长的左尾。这表明大多数数据集中在右侧,而左侧有少量极端值。
-
对称分布:
- 当 γ 1 = 0 \gamma_1 = 0 γ1=0时,表示分布是对称的,如标准正态分布。
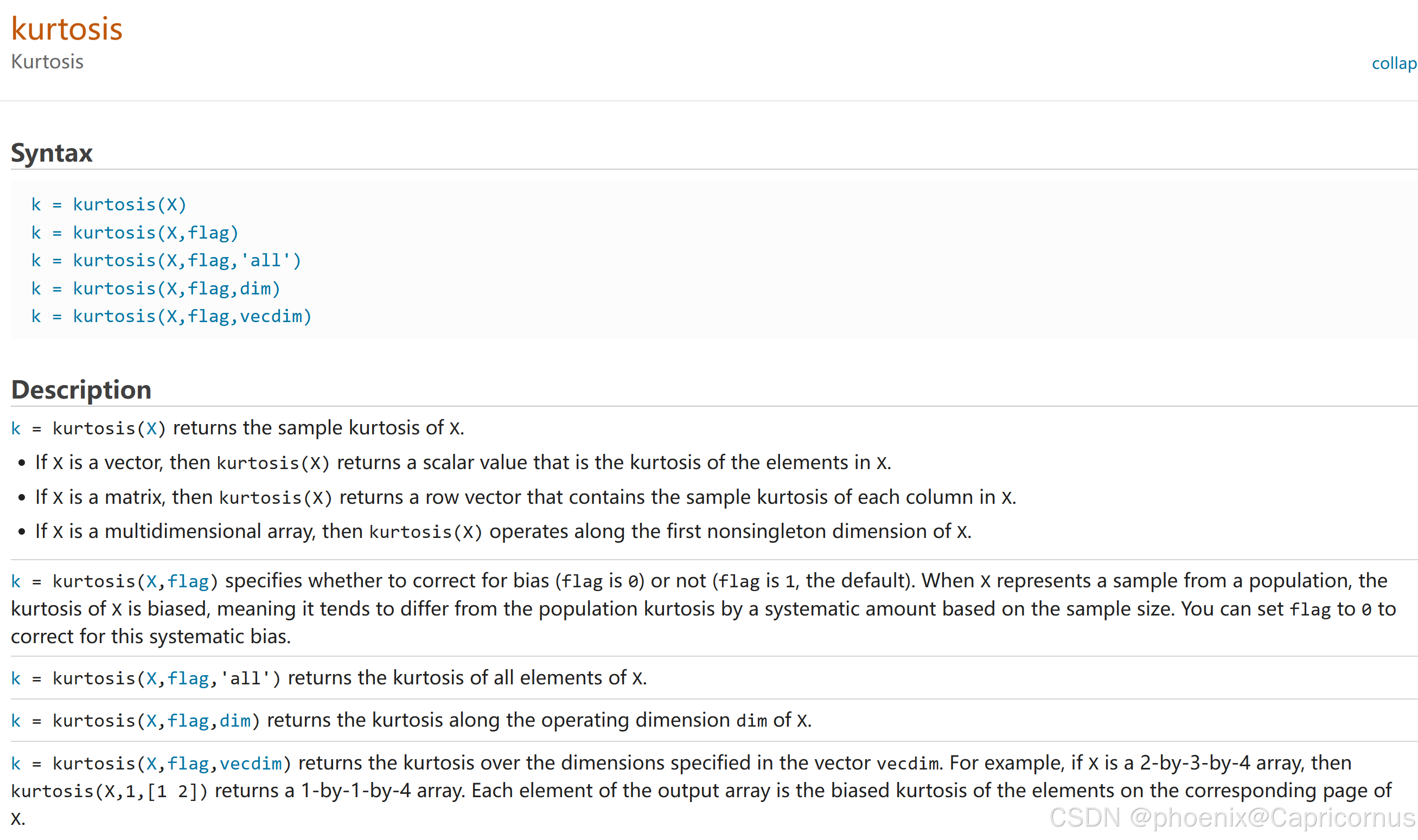
峰度(Kurtosis)
峰度(Kurtosis)是描述概率分布形状的一个统计量,特别关注分布的“峰态”或“尖峭”程度。峰度衡量的是数据分布的尾部重厚程度以及峰顶的尖锐程度,与正态分布相比较而言。
定义
对于一个随机变量 X X X,其峰度定义为四阶中心矩除以方差的平方,再减去3:
Kurtosis ( X ) = E [ ( X − μ ) 4 ] ( σ 2 ) 2 − 3 = m 4 σ 4 − 3 \text{Kurtosis}(X) = \frac{E[(X - \mu)^4]}{(\sigma^2)^2} - 3= \frac{m_4}{\sigma^4} - 3 Kurtosis(X)=(σ2)2E[(X−μ)4]−3=σ4m4−3
其中:
- E [ ( X − μ ) 4 ] E[(X - \mu)^4] E[(X−μ)4] 表示 X X X 的四阶中心矩。
- μ = E ( X ) \mu = E(X) μ=E(X) 是 X X X 的期望值。
- σ 2 = V a r ( X ) = E [ ( X − μ ) 2 ] \sigma^2 = Var(X) = E[(X - \mu)^2] σ2=Var(X)=E[(X−μ)2] 是 X X X 的方差。
解释
-
标准正态分布:标准正态分布的峰度为0(或说其超额峰度为0)。这是因为它的四阶中心矩正好是方差平方的3倍,因此在上述公式中减去3之后结果为0。
-
正峰度(Leptokurtic):如果一个分布的峰度大于0(即超额峰度大于0),则说明该分布比正态分布更“尖”,且具有更重的尾部。这表明分布中有更多的极端值。
-
负峰度(Platykurtic):如果一个分布的峰度小于0(即超额峰度小于0),则说明该分布比正态分布更“平”,且具有较轻的尾部。这表明分布中的极端值较少,大多数观测值集中在均值附近。
统计矩的应用
- 描述数据分布:通过计算不同阶数的中心矩,可以全面地描述数据的分布特性,如离散程度、对称性和峰态。
- 参数估计:在参数估计中,中心矩常用于估计总体参数,特别是在矩估计法中。
- 数据分析:中心矩可以用于各种数据分析任务,如计算方差、偏度和峰度等。
MATLAB相关函数