Tcp连接出现大量ESTABLISHED连接解决方法,记录一次对进程大量积压 ESTABLISHED 链接的排查记录,以及出现大量的UDP连接现象,服务端口连接数几十万,导致网络连接不上、缓慢、卡顿。

大量的TCP连接,状态为 ESTABLISHED :
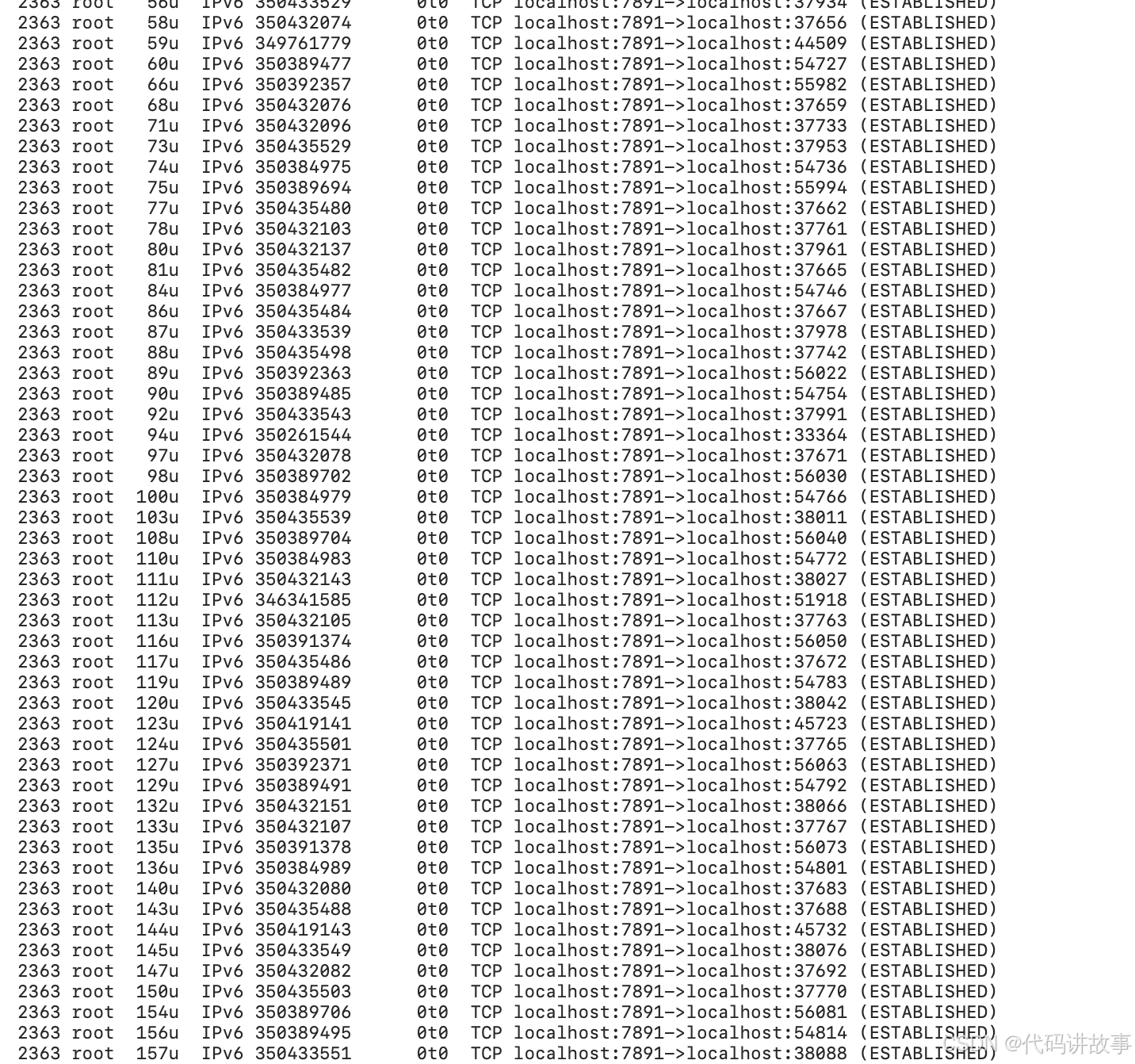
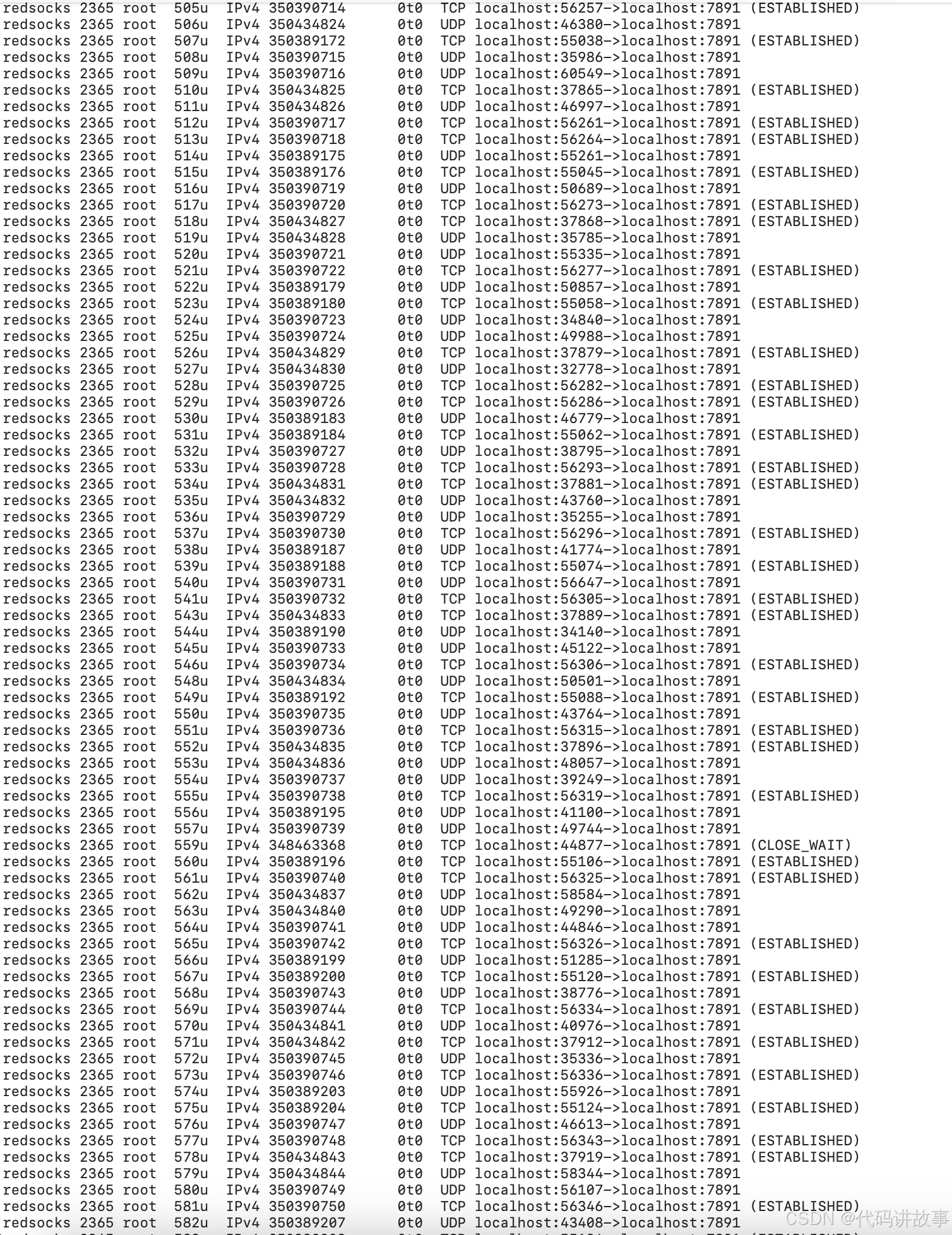
还有这种大量的UDP连接:
tcp连接状态统计:
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
它会显示例如下面的信息:
TIME_WAIT 814
CLOSE_WAIT 1
FIN_WAIT1 1
ESTABLISHED 634
SYN_RECV 2
LAST_ACK 1
常用的三个状态是:ESTABLISHED 表示正在通信,TIME_WAIT 表示主动关闭,CLOSE_WAIT 表示被动关闭。
TCP状态转移要点
TCP协议规定,对于已经建立的连接,网络双方要进行四次握手才能成功断开连接,如果缺少了其中某个步骤,将会使连接处于假死状态,连接本身占用的资源不 会被释放。网络服务器程序要同时管理大量连接,所以很有必要保证无用连接完全断开,否则大量僵死的连接会浪费许多服务器资源。
TCP状态介绍
1、LISTENING状态
FTP服务启动后首先处于侦听(LISTENING)状态。
2、ESTABLISHED状态
ESTABLISHED的意思是建立连接。表示两台机器正在通信。
3、CLOSE_WAIT
对方主动关闭连接或者网络异常导致连接中断,这时我方的状态会变成CLOSE_WAIT 此时我方要调用close()来使得连接正确关闭
4、TIME_WAIT
我方主动调用close()断开连接,收到对方确认后状态变为TIME_WAIT。TCP协议规定TIME_WAIT状态会一直持续2MSL(即两倍的分 段最大生存期),以此来确保旧的连接状态不会对新连接产生影响。处于TIME_WAIT状态的连接占用的资源不会被内核释放,所以作为服务器,在可能的情 况下,尽量不要主动断开连接,以减少TIME_WAIT状态造成的资源浪费。目前有一种避免TIME_WAIT资源浪费的方法,就是关闭socket的LINGER选项。但这种做法是TCP协议不推荐使用的,在某些情况下这个操作可能会带来错误。
5、SYN_SENT状态
SYN_SENT状态表示请求连接,当你要访问其它的计算机的服务时首先要发个同步信号给该端口,此时状态为SYN_SENT,如果连接成功了就变为 ESTABLISHED,此时SYN_SENT状态非常短暂。但如果发现SYN_SENT非常多且在向不同的机器发出,那你的机器可能中了冲击波或震荡波 之类的病毒了。这类病毒为了感染别的计算机,它就要扫描别的计算机,在扫描的过程中对每个要扫描的计算机都要发出了同步请求,这也是出现许多 SYN_SENT的原因。
TCP协议中有TIME_WAIT这个状态
主要有两个原因
1。防止上一次连接中的包,迷路后重新出现,影响新连接(经过2MSL,上一次连接中所有的重复包都会消失)
2。可靠的关闭TCP连接。在主动关闭方发送的最后一个 ack(fin) ,有可能丢失,这时被动方会重新发
fin, 如果这时主动方处于 CLOSED 状态 ,就会响应 rst 而不是 ack。所以主动方要处于 TIME_WAIT 状态,而不能是 CLOSED 。
查看网络连接数:
#netstat -an |grep ESTABLISHED |wc -l
查看不同状态的连接数数量
# netstat -an | awk '/^tcp/ {++y[$NF]} END {for(w in y) print w, y[w]}'
一般情况下,系统的socket资源默认5000个。(非官方)
状态:描述
CLOSED:无连接是活动的或正在进行
LISTEN:服务器在等待进入呼叫
SYN_RECV:一个连接请求已经到达,等待确认
SYN_SENT:应用已经开始,打开一个连接
ESTABLISHED:正常数据传输状态
FIN_WAIT1:应用说它已经完成
FIN_WAIT2:另一边已同意释放
ITMED_WAIT:等待所有分组死掉
CLOSING:两边同时尝试关闭
TIME_WAIT表示处理完毕,等待超时结束的请求数。
LAST_ACK:等待所有分组死掉
查看每个ip跟服务器建立的连接数
# netstat -nat|grep "tcp"|awk ' {print$5}'|awk -F : '{print$1}'|sort|uniq -c|sort -rn
查看每个ip建立的ESTABLISHED/TIME_OUT状态的连接数
# netstat -nat|grep ESTABLISHED|awk '{print$5}'|awk -F : '{print$1}'|sort|uniq -c|sort -rn
netstat监控大量ESTABLISHED连接与Time_Wait连接。
# netstat -n | awk '/^tcp/ {++y[$NF]} END {for(w in y) print w, y[w]}'
排查假 ESTABLISHED 连接
首先,如果出现假的 ESTABLISHED 连接,表示连接的客户端已经不存在了,客户端一方,要么发起了 TCP FIN 请求服务端没有收到,比如因为网络的各种原因(比如断网了)之后,FTP客户端无法发送FIN到服务端。要么服务端服务器接受到了 FIN,但是在后续过程中,丢包了等等。
为了验证上面的问题,我本机进行了一次模拟,连接FTP服务端后,本机直接断网,断网后,杀死FTP客户端进程,等待5分钟(为什么等待5分钟后面说)后,重新联网。然后再 FTP 服务端,查看服务器上与 FTP代理进行连接的所有IP,然后发现我本机的IP和端口依然在列,然后再我本机,通过
lsof -i :端口号
却没有任何记录,直接说明:服务端确实保持了假 ESTABLISHED 链接,一直不释放。
上面提到,我等待5分钟,是因为,服务端的 keepalive,是这样的配置:
[root@xx xx]# sysctl -a |grep keepalive
net.ipv4.tcp_keepalive_intvl = 75
net.ipv4.tcp_keepalive_probes = 9
net.ipv4.tcp_keepalive_time = 300
服务器默认设置的 tcp keepalive 检测是300秒后进行检测,也就是5分钟,当检测失败后,一共进行9次重试,每次时间间隔是75秒。
那么,问题就来了,服务器设置了 keepalive,如果 300 + 9*75 秒后,依然连接不上,就应该主动关闭假 ESTABLISHED 连接才对。为何还会积压呢?
猜想1:大量的积压的 ESTABLISHED 连接,实际上都还没有到释放时间
为了验证这个问题,我们就需要具体的看某个连接,什么时候创建的。所以,我找到其中一个我确定是假的 ESTABLISHED的链接(那个IP的用户,把所有FTP客户端都关了,进程也杀死了),看此连接的创建时间,过程如下:
先确定 FTP 代理进程的ID,为 61604
然后,看看这个进程的所有连接,找到某个端口的(55360,就是一个客户端所使用的端口)
[root@xxx xxx]# lsof -p 61604|grep 55360
server 61604 root 6u IPv4 336087732 0t0 TCP node088032:ftp->192.168.70.16:55360 (ESTABLISHED)
我们看到一个 “6u”,这个就是进程使用的这个连接的socket文件,Linux中,一切皆文件。我们看看这个文件的创建时间,就是这个连接的创建时间了
ll /proc/61604/fd/6
//输出:
lrwx------. 1 root root 64 Nov 1 14:03 /proc/61604/fd/6 -> socket:[336087732]
这个连接是11月1号创建的,现在已经11月8号,这个时间,早已经超出了 keepalive 探测 TCP连接是否存活的时间。这说明2个点:
1、可能 Linux 的 KeepAlive 压根没生效。
2、可能我的 FTP 代理进程,压根没有使用 TCP KeepAlive
猜想2: FTP 代理进程,压根没有使用 TCP KeepAlive
要验证这个结论,就得先知道,怎么看一个连接,到底具不具备 KeepAlive 功效?
netstat 命令不好使(也可能我没找到方法),我们使用 ss 命令,查看 FTP进程下所有连接21端口的链接
ss -aoen|grep 192.168.12.32:21|grep ESTAB
从众多结果中,随便筛选2个结果:
tcp ESTAB 0 0 192.168.12.32:21 192.168.20.63:63677 ino:336879672 sk:65bb <->
tcp ESTAB 0 0 192.168.12.32:21 192.168.49.21:51896 ino:336960511 sk:67f7 <->
我们再对比一下,所有连接服务器sshd进程的
tcp ESTAB 0 0 192.168.12.32:333 192.168.53.207:63269 timer:(keepalive,59sec,0) ino:336462258 sk:6435 <->
tcp ESTAB 0 0 192.168.12.32:333 192.168.55.185:64892 timer:(keepalive,3min59sec,0) ino:336461969 sk:62d1 <->
tcp ESTAB 0 0 192.168.12.32:333 192.168.53.207:63220 timer:(keepalive,28sec,0) ino:336486442 sk:6329 <->
tcp ESTAB 0 0 192.168.12.32:333 192.168.53.207:63771 timer:(keepalive,12sec,0) ino:336896561 sk:65de <->
对比很容易发现,连接 21端口的所有连接,多没有 timer 项。这说明,FTP代理 进程监听 21 端口时,所有进来的链接,全都没有使用keepalive。
找了一些文章,大多只是说,怎么配置Linux 的 Keep Alive,以及不配置的,会造成 ESTABLISHED 不释放问题,想要使用 Linux 的 KeepAlive,需要程序单独做设置进行开启才行。
最后:ss 命令结果中 keepalive 的说明
首先,看一下 Linux 中的配置,我的机器如下:
[root@xx xx]# sysctl -a |grep keepalive
net.ipv4.tcp_keepalive_intvl = 75
net.ipv4.tcp_keepalive_probes = 9
net.ipv4.tcp_keepalive_time = 300
tcp_keepalive_time:表示多长时间后,开始检测TCP链接是否有效。
tcp_keepalive_probes:表示如果检测失败,会一直探测 9 次。
tcp_keepalive_intvl:承上,探测9次的时间间隔为 75 秒。
然后,我们看一下 ss 命令的结果:
ss -aoen|grep 192.168.12.32:21|grep ESTAB
tcp ESTAB 0 0 192.168.12.32:21 192.168.70.76:54888 timer:(keepalive,1min19sec,0) ino:397279721 sk:6b49 <->
摘取这部分:timer:(keepalive,1min19sec,0) ,其中:
keepalive:表示此链接具备 keepalive 功效。
1min19sec:表示剩余探测时间,这个时间每次看都会边,是一个递减的值,第一次探测,需要 net.ipv4.tcp_keepalive_time 这个时间倒计时,如果探测失败继续探测,后边会按照 net.ipv4.tcp_keepalive_intvl 这个时间值进行探测。直到探测成功。
0:这个值是探测时,检测到这是一个无效的TCP链接的话已经进行了的探测次数。
1、解决 TIME_WAIT 连接数大量问题
如发现系统存在大量 TIME_WAIT 状态的连接,通过调整内核参数解决,调整内核参数:/etc/sysctl.conf
vim /etc/sysctl.conf
添加以下配置文件:
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_fin_timeout = 30
#然后执行,让参数生效,调优完成
/sbin/sysctl -p
参数详解:
net.ipv4.tcp_syncookies = 1 表示开启 syn cookies 。当出现 syn 等待队列溢出时,启用 cookies 来处理,可防范少量 syn ***,默认为 0 ,表示关闭;
net.ipv4.tcp_tw_reuse = 1 表示开启重用。允许将 time-wait sockets 重新用于新的 tcp 连接,默认为 0 ,表示关闭;
net.ipv4.tcp_tw_recycle = 1 表示开启 tcp 连接中 time-wait sockets 的快速回收,默认为 0 ,表示关闭。
net.ipv4.tcp_fin_timeout 修改系靳默认的 timeout 时间
如果以上配置调优后性能还不理想,可继续修改一下配置:
vi /etc/sysctl.conf
net.ipv4.tcp_keepalive_time = 1200
net.ipv4.tcp_syn_retries=2
net.ipv4.tcp_orphan_retries=3
net.ipv4.ip_local_port_range = 1024 65000
net.ipv4.tcp_max_syn_backlog = 8192
net.ipv4.tcp_max_tw_buckets = 5000
net.ipv4.tcp_keepalive_probes=5
net.core.netdev_max_backlog=3000
修改完之后执行/sbin/sysctl -p让参数生效。
这里头主要注意到的是 net.ipv4.tcp_tw_reuse
net.ipv4.tcp_tw_recycle
net.ipv4.tcp_fin_timeout
net.ipv4.tcp_keepalive_*
这几个参数。
net.ipv4.tcp_tw_reuse和net.ipv4.tcp_tw_recycle的开启都是为了回收处于TIME_WAIT状态的资源。
net.ipv4.tcp_fin_timeout这个时间可以减少在异常情况下服务器从FIN-WAIT-2转到TIME_WAIT的时间。
net.ipv4.tcp_keepalive_*一系列参数,是用来设置服务器检测连接存活的相关配置。
net.ipv4.tcp_keepalive_time = 1200 #表示当keepalive起用的时候,TCP发送keepalive消息的频度。缺省是2小时,改为20分钟。
net.ipv4.ip_local_port_range = 1024 65000 #表示用于向外连接的端口范围。缺省情况下很小:32768到61000,改为1024到65000。
net.ipv4.tcp_max_syn_backlog = 8192 #表示SYN队列的长度,默认为1024,加大队列长度为8192,可以容纳更多等待连接的网络连接数。
net.ipv4.tcp_max_tw_buckets = 5000 #表示系统同时保持TIME_WAIT套接字的最大数量,如果超过这个数字,TIME_WAIT套接字将立刻被清除并打印警告信息。默认为180000,改为5000。表示系统同时保持TIME_WAIT套接字的最大数量,如果超过这个数字,TIME_WAIT套接字将立刻被清除并打印警告信息。默认为180000,改为5000。对于Apache、Nginx等服务器,上几行的参数可以很好地减少TIME_WAIT套接字数量,但是对于 Squid,效果却不大。此项参数可以控制TIME_WAIT套接字的最大数量,避免Squid服务器被大量的TIME_WAIT套接字拖死。
调优完毕,再压一下看看效果吧。
# netstat -n | awk '/^tcp/ {++y[$NF]} END {for(w in y) print w, y[w]}'
使用killcx关闭Linux上的tcp连接
killcx 可以关闭一个linux上的tcp连接,而不管连接的状态是怎么样的(半开,已建立,等待或关闭状态)。
它是一个Perl的脚本程序,在linux上使用需要安装一下它的依赖的包。
它依赖三个包:Net :: RawIP,Net :: Pcap和Net :: Pcap。
安装命令如下:
apt-get install libnet-rawip-perl
apt-get install libnet-pcap-perl
cpan NetPacket::Ethernet
安装完成就可以使用了,使用语法为: killcx ip:port
注意如果关闭半开状态的连接(即只有一端有连接,另外一端没有连接),killcx需要运行在还有连接存在的主机上才可以关闭连接。
2 解决 ESTABLISHED 连接数大量问题
主要修改目标服务的连接超时时间,让超时的连接自动释放掉,比如redsocks可以通过 timeout 设置。
redsocks2 配置文件示例:
redsocks {
timeout = 12;
autoproxy = 1;
}
redsocks {
timeout = 12;
autoproxy = 1;
}
redsocks {
timeout = 1;
autoproxy = 0;
}
redudp {
udp_timeout_stream = 10;
udp_timeout = 10;
}
autoproxy {
no_quick_check_seconds = 300;
quick_connect_timeout = 2;
}
ipcache {
stale_time = 7200;
autosave_interval = 3600;
port_check = 1;
}
base {
/* Override per-socket values for TCP_KEEPIDLE, TCP_KEEPCNT,
* and TCP_KEEPINTVL. see man 7 tcp for details.
* `redsocks' relies on SO_KEEPALIVE option heavily. */
//tcp_keepalive_time = 0;
//tcp_keepalive_probes = 0;
//tcp_keepalive_intvl = 0;
}
tcpdns {
timeout = 4; // Timeout value for TCP DNS requests
}
autoproxy {
no_quick_check_seconds = 60; // Directly relay traffic to proxy if an IP
// is found blocked in cache and it has been
// added into cache no earlier than this
// specified number of seconds.
// Set it to 0 if you do not want to perform
// quick check when an IP is found in blocked
// IP cache, thus the connection will be
// redirected to proxy immediately.
quick_connect_timeout = 3; // Timeout value when performing quick
// connection check if an IP is found blocked
// in cache.
}
redsocks 配置文件示例:
base {
/* Override per-socket values for TCP_KEEPIDLE, TCP_KEEPCNT,
* and TCP_KEEPINTVL. see man 7 tcp for details.
* `redsocks' relies on SO_KEEPALIVE option heavily. */
//tcp_keepalive_time = 0;
//tcp_keepalive_probes = 0;
//tcp_keepalive_intvl = 0;
// Set maximum number of open file descriptors (also known as `ulimit -n`).
// 0 -- do not modify startup limit (default)
// rlimit_nofile = 0;
// Set maximum number of served connections. Default is to deduce safe
// limit from `splice` setting and RLIMIT_NOFILE.
// redsocks_conn_max = 0;
// Close connections idle for N seconds when/if connection count
// limit is hit.
// 0 -- do not close idle connections
// 7440 -- 2 hours 4 minutes, see RFC 5382 (default)
// connpres_idle_timeout = 7440;
// `max_accept_backoff` is a delay in milliseconds to retry `accept()`
// after failure (e.g. due to lack of file descriptors). It's just a
// safety net for misconfigured `redsocks_conn_max`, you should tune
// redsocks_conn_max if accept backoff happens.
// max_accept_backoff = 60000;
}
redudp {
udp_timeout = 30;
udp_timeout_stream = 180;
}
dnsu2t {
// I/O timeout of remote endpoint. Default value is quite conservative and
// corresponds to the highest timeout among public servers from Wikipedia.
// remote_timeout = 30;
}