本案例源码下载
链接:https://pan.baidu.com/s/1IzOvSCtLvZzj81XZaYl6CQ
提取码:i6i8
项目背景
网络发展迅速的时代,越来越多人通过网络获取跟多的信息或通过网络作一番自己的事业,当投身于搭建属于自己的网站、APP或小程序时会发现,经过一段时间经营和维护发现浏览量和用户数量的增长速度始终没有提升。在对其进行设计改造时无从下手,当在不了解用户的浏览喜欢和个用户群体的喜好。虽然服务器日志中明确的记载了用户访浏览的喜好但是通过普通方式很难从大量的日志中及时有效的筛选出优质信息。Spark Streaming是一个实时的流计算框架,该技术可以对数据进行实时快速的分析,通过与Flume、Kafka的结合能够做到近乎零延迟的数据统计分析。
案例需求
要求:实时分析服务器日志数据,并实时计算出某时间段内的浏览量等信息。
使用技术:Flume-》Kafka-》SparkStreaming-》MySql数据库
#案例架构
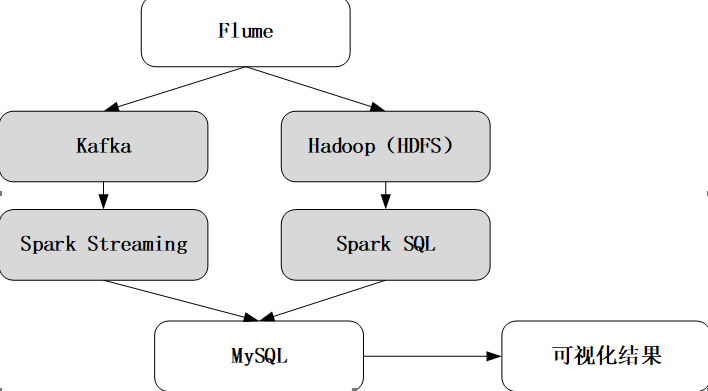
架构中通过Flume实时监控日志文件,当日志文件中出现新数据时将该条数据发送给Kafka,并有Spark Streaming接收进行实时的数据分析最后将分析结果保存到MySQL数据库中。
一、分析
1、日志分析
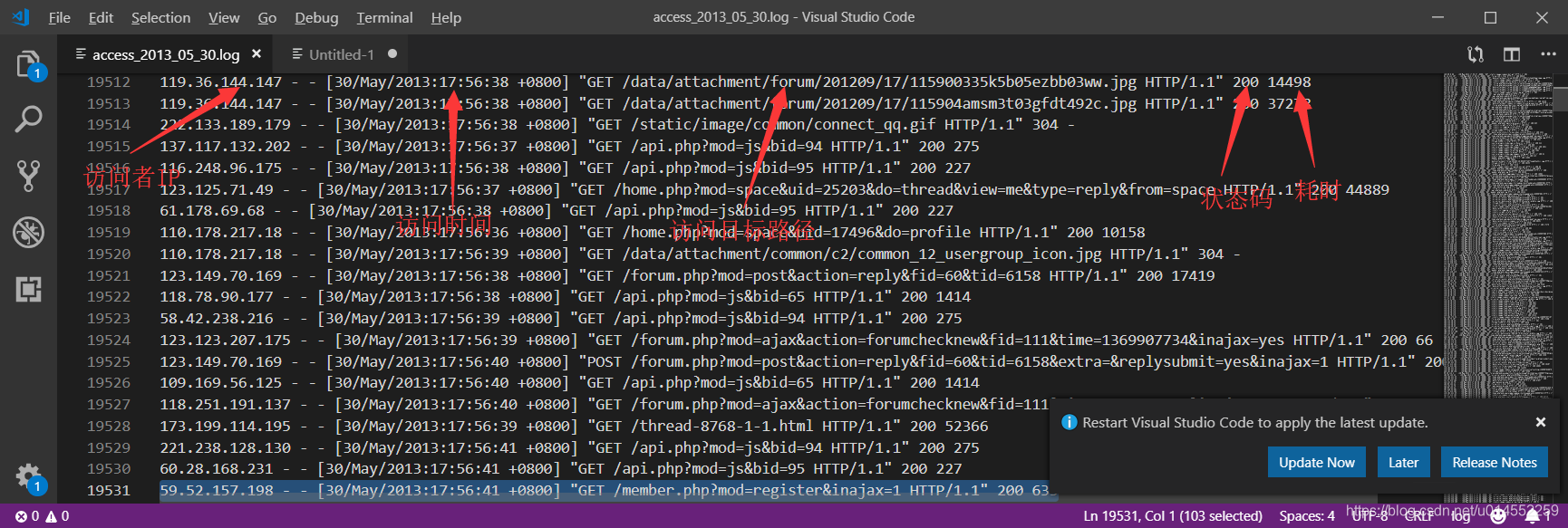
1.通过浏览器访问服务器中的网页,每访问一次就会产生一条日志信息。日志中包含访问者IP、访问时间、访问地址、状态码和耗时等信息,如下图所示:
二、日志采集
第一步、代码编辑
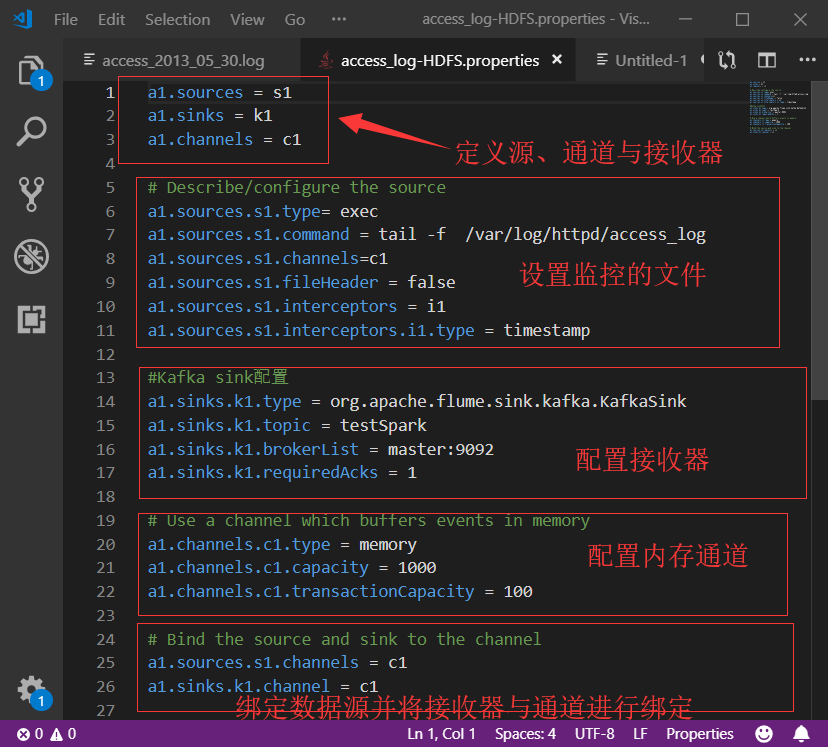
通过使用Flume实时监控服务器日志文件内容,每生成一条都会进行采集,并将采集的结构发送给Kafka,Flume代码如下。
2、启动采集代码
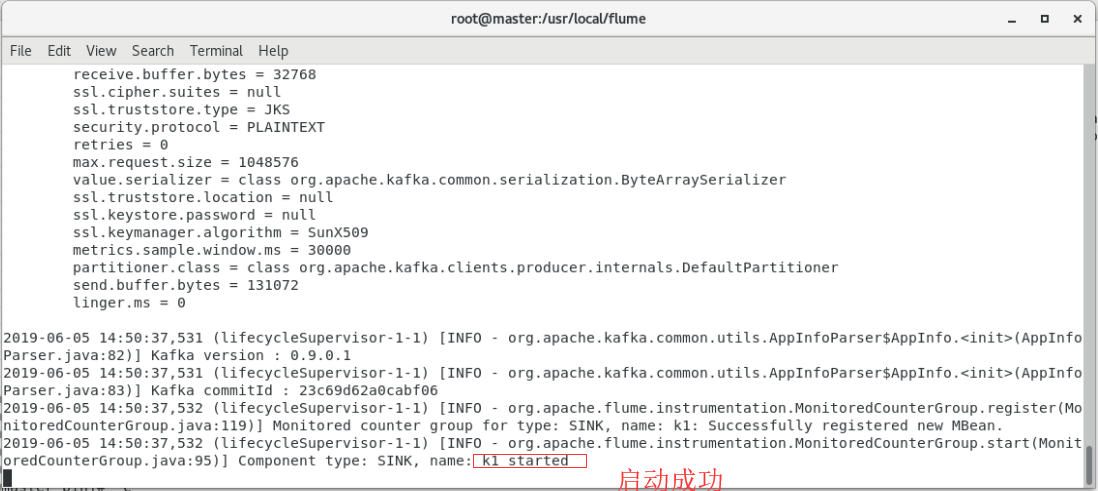
代码编辑完成后启动Flume对服务器日志信息进行监控,进入Flume安装目录执行如下代码。
[root@master flume]# bin/flume-ng agent --name a1 --conf conf --conf-file conf/access_log-HDFS.properties -Dflume.root.logger=INFO,console
效果下图所示。
三、编写Spark Streaming的代码
第一步 创建工程
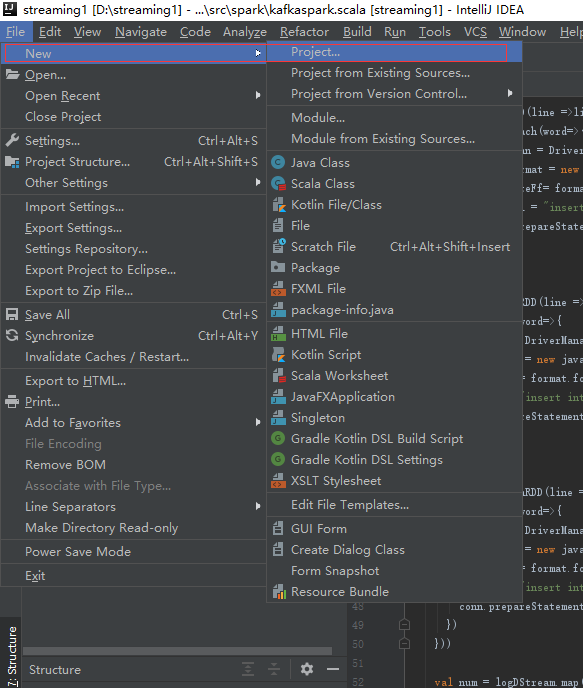
第二步 选择创建Scala工程
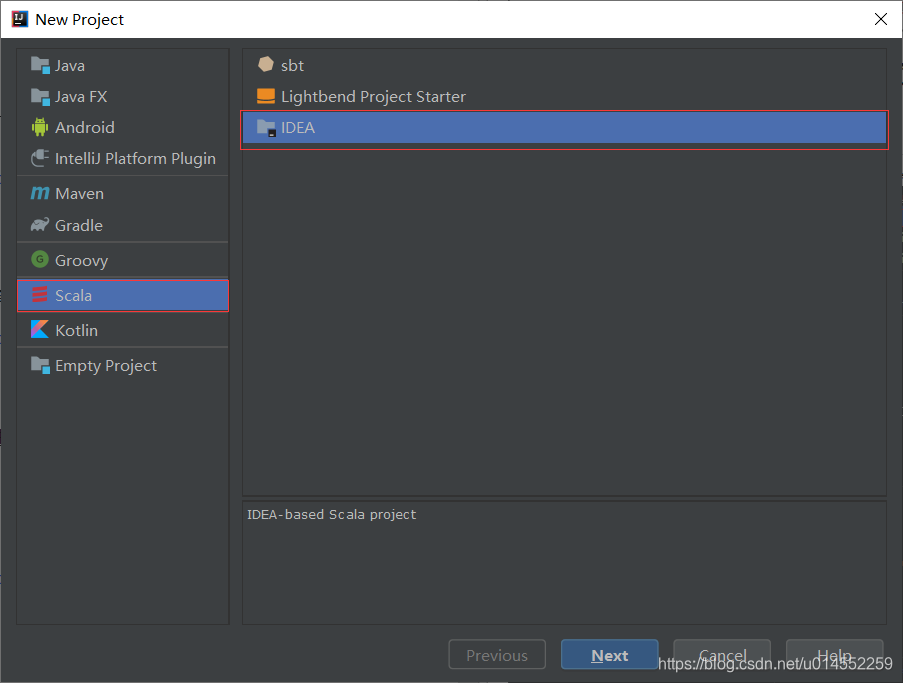
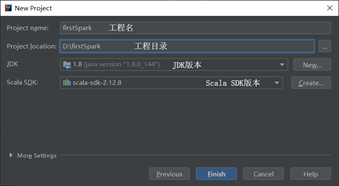
第三步 设置工程名与工程所在路径和使用的Scala版本后完成创建
第四步 创建scala文件
项目目录的”src”处单机鼠标右键依次选择”New”->”Package”创建一个包名为”com.wordcountdemo”,并在该包处单机右键依次选择”New”->”scala class”创建文件命名为wordcount
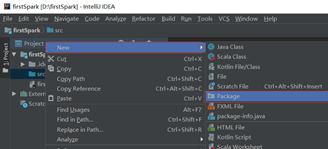
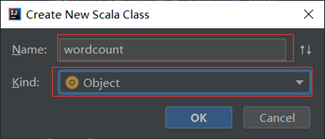
第五步:导入依赖包
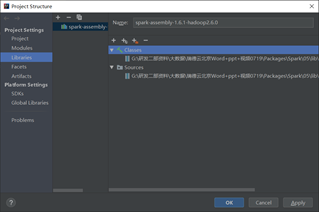
在IDEA中导入Spark依赖包,在菜单中依次选择”File”->”Project Structure”->”Libraries”后单击”+”号按钮选择”Java”选项,在弹出的对话框中找到spark-assembly-1.6.1-hadoop2.6.0.jar依赖包点击”OK”将所有依赖包加载到工程中,结果如图X所示。