COCO系列文章:
MS COCO数据集目标检测评估(Detection Evaluation)(来自官网)
MS COCO数据集人体关键点评估(Keypoint Evaluation)(来自官网)
MS COCO数据集输出数据的结果格式(result format)和如何参加比赛(participate)(来自官网)
MS COCO官网数据集(百度云)下载,COCO API、MASK API和Annotation format介绍(来自官网)
目标检测评估
1. Detection Evaluation
本页介绍了COCO使用的检测评估指标。此处提供的评估代码可用于在公开可用的COCO验证集上获得结果。它计算下面描述的多个指标。为了在COCO测试集上获得结果,其中隐藏了实际真值注释,必须将生成的结果上传到评估服务器。下面描述的评估代码用于评估测试集的结果。
2. Metrics(指标)
| 预测情况 | |||
| Positive(预测结果为正例) | Negative(预测结果为负例) | ||
| GroundTruth | True(正例) | TP | FN(注意这并不是TN) |
| False(负例) | FP | TN(注意这并不是FN) | |
Recall 召回率(查全率)。表示正确识别物体A的个数占测试集中物体A的总个数的百分数,即所有正例中预测正确的概率,Recall = tpr = TP / (TP+FN)
Precision 精确率(查准率)。表示正确识别物体A的个数占总识别出的物体个数n的百分数,即预测为正例中预测正确的概率,Precision = TP / (TP+FP)
fp :false positive误报,即负例中识别为正例的样本。其中在计算roc曲线的时候需要fpr = FP / (FP + TN)
fn :false negative漏报,即没有预测到
tp:true positive
tn:true negative
iou:intersection-over-union
Accuracy 准确率。正确分类(正例分为正例,负例分为负例)的样本数除以所有的样本数,正确率越高,分类器越好。Accuracy=(TP+TN)/ (TP+TN+FP+FN)
以上介绍都是基于2分类的,并不是多分类的
以下12个指标用于表征COCO上物体检测器的性能:
Average Precision (AP):
AP % AP at IoU=0.50:0.05:0.95 (primary challenge metric)
APIoU=.50 % AP at IoU=0.50 (PASCAL VOC metric)
APIoU=.75 % AP at IoU=0.75 (strict metric)
AP Across Scales:
APsmall % AP for small objects: area < 322
APmedium % AP for medium objects: 322 < area < 962
APlarge % AP for large objects: area > 962
Average Recall (AR):
ARmax=1 % AR given 1 detection per image
ARmax=10 % AR given 10 detections per image
ARmax=100 % AR given 100 detections per image
AR Across Scales:
ARsmall % AR for small objects: area < 322
ARmedium % AR for medium objects: 322 < area < 962
ARlarge % AR for large objects: area > 962
1)除非另有说明,否则AP和AR在多个交汇点(IoU)值上取平均值。具体来说,我们使用10个IoU阈值0.50:0.05:0.95。这是对传统的一个突破,其中AP是在一个单一的0.50的IoU上计算的(这对应于我们的度量APIoU=.50 )。超过均值的IoUs能让探测器更好定位(Averaging over IoUs rewards detectors with better localization.)。
2)AP是所有类别的平均值。传统上,这被称为“平均精确度”(mAP,mean average precision)。我们没有区分AP和mAP(同样是AR和mAR),并假定从上下文中可以清楚地看出差异。
3)AP(所有10个IoU阈值和所有80个类别的平均值)将决定赢家。在考虑COCO性能时,这应该被认为是最重要的一个指标。
4)在COCO中,比大物体相比有更多的小物体。具体地说,大约41%的物体很小(面积<322),34%是中等(322 < area < 962)),24%大(area > 962)。测量的面积(area)是分割掩码(segmentation mask)中的像素数量。
5)AR是在每个图像中检测到固定数量的最大召回(recall),在类别和IoU上平均。AR与提案评估(proposal evaluation)中使用的同名度量相关,但是按类别计算。
6)所有度量标准允许每个图像(在所有类别中)最多100个最高得分检测进行计算。
7)除了IoU计算(分别在框(box)或掩码(mask)上执行)之外,用边界框和分割掩码检测的评估度量在所有方面是相同的。
3. Evaluation Code
评估代码可在COCO github上找到。 具体来说,分别参见Matlab或Python代码中的CocoEval.m或cocoeval.py。另请参阅Matlab或Python代码(demo)中的evalDemo。在运行评估代码之前,请按结果格式页面上描述的格式准备结果(查看具体的结果格式MS COCO数据集比赛参与(participate)(来自官网))。
评估参数如下(括号中的默认值,一般不需要改变):
params{
"imgIds" : [all]N img ids to use for evaluation
"catIds " : [all] K cat ids to use for evaluation cat=category
"iouThrs" : [0.5:0.05:0.95] T=10 IoU thresholds for evaluation
"recThrs" : [0:0.01:1] R=101 recall thresholds for evaluation
"areaRng" : [all,small,medium,large] A=4 area ranges for evaluation
"maxDets" : [1 10 100] M=3 thresholds on max detections per image
"useSegm" : [1] if true evaluate against ground-truth segments
"useCats" : [1] if true use category labels for evaluation
}
运行评估代码通过调用evaluate()和accumulate()产生两个数据结构来衡量检测质量。这两个结构分别是evalImgs和eval,它们分别衡量每个图像的质量并聚合到整个数据集中。evalImgs结构体具有KxA条目,每个评估设置一个,而eval结构体将这些信息组合成 precision 和 recall 数组。这两个结构的细节如下(另请参阅CocoEval.m或cocoeval.py):
evalImgs[{
"dtIds" : [1xD] id for each of the D detections (dt)
"gtIds" : [1xG] id for each of the G ground truths (gt)
"dtImgIds" : [1xD] image id for each dt
"gtImgIds" : [1xG] image id for each gt
"dtMatches" : [TxD] matching gt id at each IoU or 0
"gtMatches" : [TxG] matching dt id at each IoU or 0
"dtScores" : [1xD] confidence of each dt
"dtIgnore" : [TxD] ignore flag for each dt at each IoU
"gtIgnore" : [1xG] ignore flag for each gt
}]
eval{
"params" : parameters used for evaluation
"date" : date evaluation was performed
"counts" : [T,R,K,A,M] parameter dimensions (see above)
"precision" : [TxRxKxAxM] precision for every evaluation setting
"recall" : [TxKxAxM] max recall for every evaluation setting
}
最后,summary()根据eval结构计算前面定义的12个检测指标。
4. Analysis Code
除了评估代码外,我们还提供一个函数analyze()来执行误报的详细分类。这受到了Derek Hoiem等人在诊断物体检测器中的错误(Diagnosing Error in Object Detectors)的启发,但在实现和细节方面却有很大不同。代码生成这样的图像:
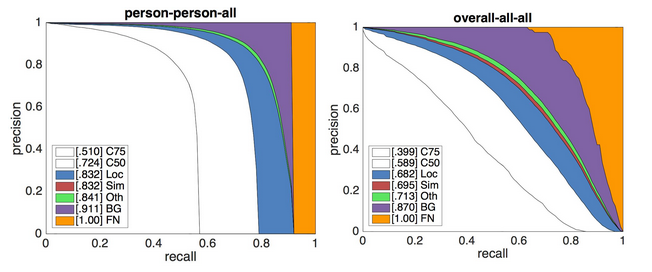
这两幅图显示了来自2015年检测挑战赛获胜者Kaiming He等人的ResNet(bbox)检测器的分析结果。左图显示了ResNet的人员类别错误;右图是ResNet对所有类别平均值的整体分析。每个绘图是一系列精确召回(precision recall)曲线,其中每个PR曲线被保证严格地高于之前的评估设置变得更宽容。曲线如下:
1)C75:在IoU = 0.75(严格的IoU的AP)的PR(precision),对应于APIoU=.75度量曲线下的面积(area under curve )。
2)C50:IoU = 0.50处的PR(PASCAL IoU处的AP),对应于APIoU=.50度量曲线下面积。
3)Loc:在IoU =0 .10的PR(定位误差(localization errors ignored)被忽略,但不重复检测)。 所有其余的设置使用IoU = 0.1。
4)Sim:超类别误报(fps,supercategory false positives)被移除后的PR值。具体而言,与具有不同类标签但属于同一个超类别的对象的任何匹配都不会被视为fp(或tp)。通过设置同一超类别中的所有对象与所讨论的类具有相同的类标签并将它们的忽略标志设置为1来计算Sim。注意,该人是单例超类别,因此其Sim结果与Loc完全相同。
5)Oth:所有类型混乱被移除后的PR值。与Sim类似,除了现在如果检测与任何其他对象匹配,则不再是fp(或tp)。计算Oth的方法是将所有其他对象设置为与所讨论的类具有相同的类标签,并将忽略标志设置为1。
6)BG:所有背景误报(和类混乱(class confusion))被移除后的PR。 对于单个类别,BG是一个阶跃函数,直到达到最大召回后才降为0(跨类别平均后曲线更平滑)。
7)FN:在所有剩余错误都被删除后(平均AP = 1)的PR。
每条曲线下面的区域显示在图例的括号中。在ResNet检测器的情况下,IoU = 0.75的整体AP为0.399,完美定位将使AP增加到0.682。有趣的是,消除所有类别混乱(超范畴内和超范畴内)只会将AP略微提升至0.713。除去背景fp会将性能提高到0.870 AP,而其余的错误则缺少检测(尽管假设更多的检测被添加,这也会增加大量的fps)。总之,ResNet的错误来自不完美的定位和背景混淆。
对于一个给定的探测器(detector),代码总共产生了372个块(plots)!共有80个类别(category),12个超类别(supercategory),1个总体结果,总共93个不同的设置,分析是在4个尺度(scale)(全部,小,中,大,所以93 * 4 = 372个块)进行。 文件命名为[supercategory] - [category] - [size] .pdf(对于80 * 4每个分类结果),overall- [supercategory] - [size] .pdf(对于12 * 4每个超类别结果)全部[[size] .pdf为1 * 4的整体结果。在所有图中,通常总体和超类别的结果是最感兴趣的。
注意:analyze()可能需要很长时间才能运行,请耐心等待。因此,我们通常不会在评估服务器上运行此代码;您必须使用验证集在本地运行代码。最后,目前analyze()只是Matlab API的一部分; Python代码即将推出。