前言
成就本文有以下三个因素
- 24年5.17日,我在我司一课程「大模型与多模态论文100篇」里问道:大家希望我们还讲哪些论文
一学员朋友小栗说:幻方发布的deepseek-v2 - 24年5.24日,我司一课程「大模型项目开发线上营1」里的一学员朋友问我:校长最近开始搞deepseek了吗?刚看了论文,没搞懂MLA那块的cache是怎么算的,我总觉得他的效果应该类似MQA才对,但是反馈是挺好的
我当时回复他道:目前团队项目上的事情太多,然后近期在写那个KAN
确实还没来得及看这个deepseek,我近期看下 - 我们在继英文层面的论文翻译、审稿、对话、idea提炼之后(其中的审稿和翻译已于24年8月底上线七月官网 )
打算再整一下中文层面的「硕士论文修订助手(不限学科,CS和非CS的都涵盖)」,预计24年9月份上线七月官网
对于模型的选择,除了闭源外,在开源模型上 有两个选择,一个chatglm4,一个DeepSeek,两者都会搞下
而搞DeepSeek之前——近几天,会先写一下它的论文解读(当然,因为DeepSeek-V2从DeepSeek LLM、DeepSeekMoE迭代而来,且用到了DeepSeekMath中的GRPO算法,故第一部分会先讲DeepSeek LLM、DeepSeekMoE、DeepSeekMath),故本文就来了,且DeepSeek也算证明了在国内也可以做出有效果、有影响力的创新
且一如既往做到——对于几乎每一个主题,都如本博客万千读者或七月学员所说的:“还是看校长的文章好理解”,而其中的关键之一是做好图、文、公式的一一对应,不一笔带过、不自以为然,本文亦如此

同时本文也见证了自己从技术人到产品人定位的过渡
- 23上半年 侧重原理,系统大量读paper,深挖原理
- 23下半年 侧重工程,和项目组不断优化各种工程问题
- 24上半年 侧重研究,横跨或综合多个领域(比如llm+机器人),继续各种抠paper
- 24下半年 侧重产品,把技术落地成产品 给用户使用,以发挥更大的价值和影响力(希望有机会早日达到世界级影响力)
最后,还是那句老话,如有任何问题或任何不懂的地方,可以随时留言/评论,我会找时间尽快回复,至于更多,本课程《大模型项目开发线下强化班 [线下4天实战6大商用落地项目]》里见
第一部分 从DeepSeek LLM、DeepSeekMoE到DeepSeekMath
友情提醒,想直接看DeepSeek-V2的,可以直接跳到本文的第二部分,本文第二部分也是本文的最精华所在
当然,如果你就是想先从本第一部分也行,但里面的数学公式比较多,喜欢抠公式的可以细抠,不喜欢抠公式的则不用抠太细,不影响对DeepSeek-V2的整体理解
1.1 DeepSeek LLM的预训练与对齐
1.1.1 架构设计、预训练、并行训练等细节
24年1.5日,量化巨头幻方旗下的杭州深度求索公司提出DeepSeek LLM,其对应的论文为《DeepSeek LLM: Scaling Open-Source Language Models with Longtermism》
- 该模型基本遵循Llama结构的设计「关于llama结构的解读,详见此文:LLaMA的解读与其微调(含LLaMA 2):Alpaca-LoRA/Vicuna/BELLE/中文LLaMA/姜子牙」
比如采用了RMSNorm函数的Pre-Norm结构,并使用SwiGLU作为前馈网络FFN的激活函数,中间层的维度为,它还结合了旋转嵌入RoPE作为位置编码
- 且为了优化推理成本,67B 模型使用了分组查询注意力GQA,而不是传统的多头注意力MHA
此外,DeepSeek LLM 7B 是一个30层的网络,而 DeepSeek LLM 67B 有95层,更多参数如下表所示

以下是其他的一些细节
- 基于tokenizers库(Huggingface团队,2019)实现了字节级字节对编码(BBPE)算法
- DeepSeek LLM 以0.006的标准差初始化,并使用 AdamW 优化器进行训练,具有以下超参数: 𝛽1 = 0.9, 𝛽2 = 0.95, 和 weight_decay = 0.1
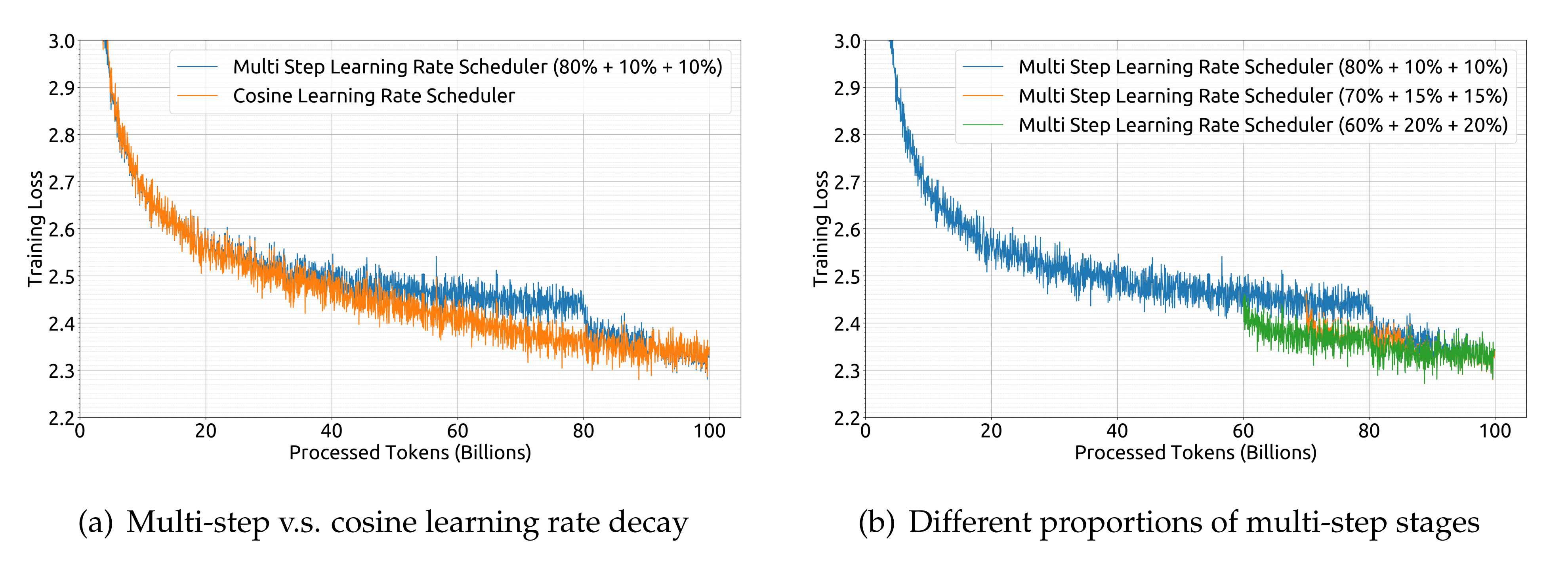
- 在预训练期间,采用了多步学习率调度器(multi-step learning rate scheduler),而不是典型的余弦调度器
原因在于当在保持模型大小不变的情况下调整训练规模时,多步学习率调度器允许重用第一阶段的训练,从而为持续训练提供了独特的便利,因此,选择了多步学习率调度器作为默认设置
具体来说,模型的学习率在2000个预热步骤后达到最大值,然后在处理80%的训练数据后下降到最大值的31.6%。在处理90%的数据后,它进一步减少到最大值的10%
此外,在模型的加速上
- 使用一个名为 HAI-LLM的高效轻量级训练框架来训练和评估大型语言模型
数据并行、张量并行、序列并行和1F1B流水线并行被集成到这个框架中,就像在Megatron中所做的那样 (如果还不太熟悉并行训练相关的原理,可以参见此文:大模型并行训练指南:通俗理解Megatron-DeepSpeed之模型并行与数据并行)
且还利用了flash attention来提高硬件利用率,以及利用ZeRO-1将优化器状态划分到数据并行等级中
还努力重叠计算和通信以最小化额外的等待开销,包括最后一个微批次的反向过程和ZeRO-1中的reduce-scatter操作,以及序列并行中的GEMM计算和all-gather/reduce-scatter - 一些层/操作被融合以加速训练,包括LayerNorm、GEMM和Adam更新
为了提高模型训练的稳定性,在 bf16 精度下训练模型,但在 fp32 精度下累积梯度
为了减少 GPU 内存消耗,执行就地交叉熵操作,即:在交叉熵 CUDA 内核中即时将 bf16 logits 转换为fp32 精度(而不是事先在 HBM 中转换),计算相应的 bf16 梯度,并用其梯度覆盖 logits
且模型权重和优化器状态每 5 分钟异步保存一次,这意味着在偶尔的硬件或网络故障的最坏情况下,最多会丢失 5 分钟的训练数据。这些临时模型检查点会定期清理,以避免消耗过多的存储空间
且还支持从不同的 3D 并行配置恢复训练,以应对计算集群负载的动态变化。
至于评估,在生成任务中采用 vLLM (Kwon et al., 2023),在非生成任务中采用连续批处理,以避免手动调整批处理大小并减少 token 填充
1.1.2 对齐:监督微调与DPO
在数据集上,收集了大约 150 万条英文和中文的指令数据实例,涵盖了广泛的有用性和无害性主题。其中
- 有用数据包含 120 万个实例,其中 31.2% 是一般语言任务,46.6% 是数学问题,22.2% 是编码练习
- 安全数据包含 30 万个实例,涵盖各种敏感话题
至于对齐流程则包含两个阶段
- 监督微调
对 7B 模型进行了 4 个周期的微调,但对 67B 模型只进行了 2 个周期的微调,因为观察到 67B 模型的过拟合问题很严重
且观察到 GSM8K和 HumanEval在 7B 模型上持续改进,而 67B 模型很快达到了上限
对于 7B 和 67B 模型,它们对应的学习率分别为 1e-5 和 5e-6
除了监控基准准确性外,我们还评估了微调过程中聊天模型的重复率
比如,收集了总共 3868 个中英文提示,并确定了生成的响应中未能终止而是无休止重复一段文本的比例
且观察到,随着数学 SFT 数据量的增加,重复率往往会上升,这可以归因于数学 SFT 数据偶尔包含类似的推理模式。因此,较弱的模型难以理解这些推理模式,导致重复的响应
为了解决这个问题,尝试了两阶段微调和 DPO(关于什么是DPO,详见此文:RLHF的替代之DPO原理解析:从RLHF、Claude的RAILF到DPO、Zephyr),这两种方法几乎都能保持基准分数并显著减少重复 - DPO
为了进一步增强模型的能力,他们使用了直接偏好优化算法DPO,这被证明是一种简单但有效的 LLM 对齐方法
比如构建了DPO训练的偏好数据,主要包括有用性和无害性对于有用性数据,收集了多语言提示,涵盖了创意写作、问答、指令执行等类别,然后使用DeepSeek Chat模型生成响应作为候选答案
且以5e-6的学习率和512的批处理大小训练了一个DPO周期,并使用了学习率预热和余弦学习率调度器
另,发现DPO可以增强模型的开放式生成能力,同时在标准基准测试中的表现差异很小
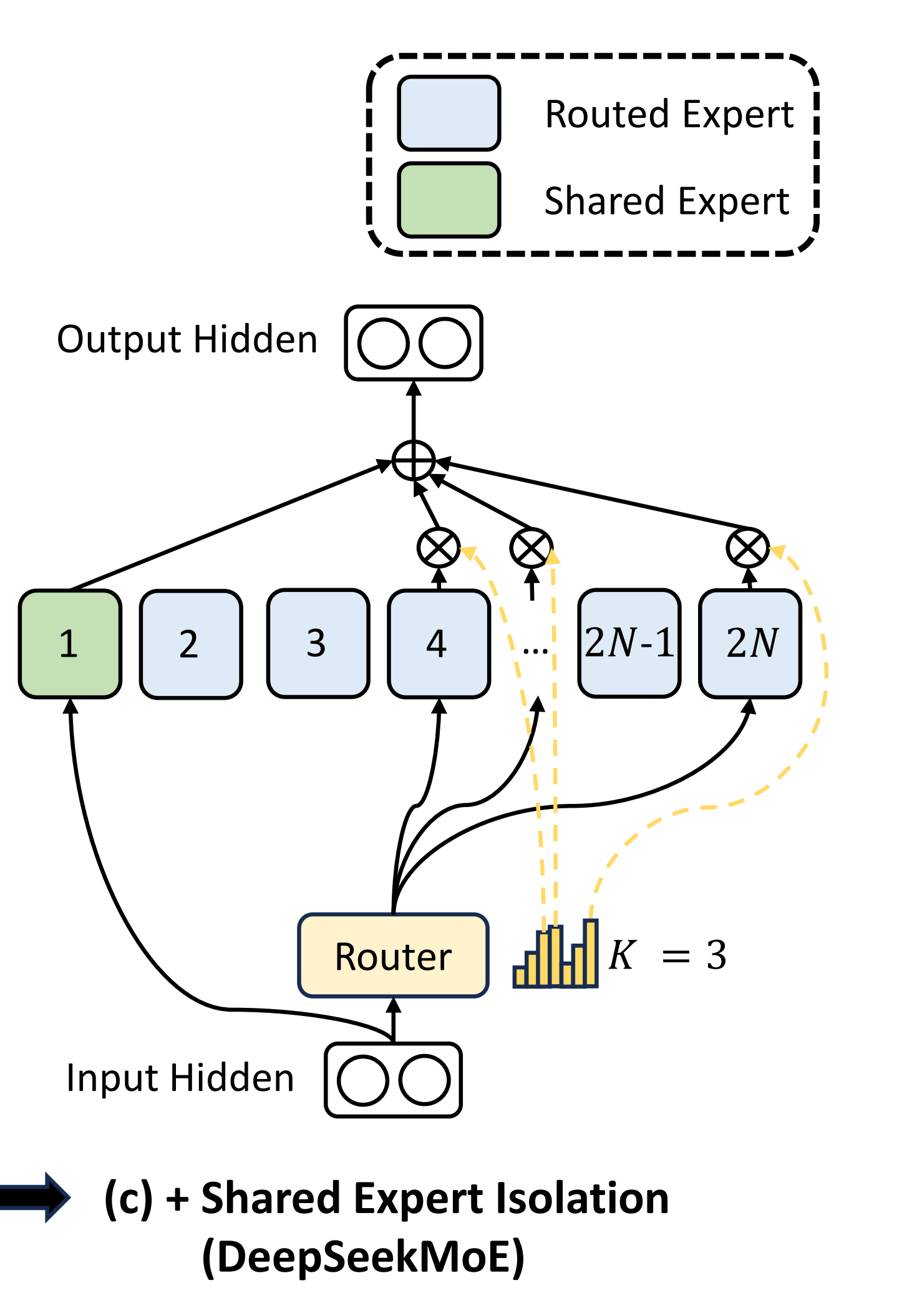
1.2 DeepSeekMoE的创新:细粒度专家分割与共享专家隔离
1.2.1 为何提出细粒度专家分割和共享专家隔离
24年1.11日,深度求索公司很快又提出了DeepSeekMoE,其对应的论文为《DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models》
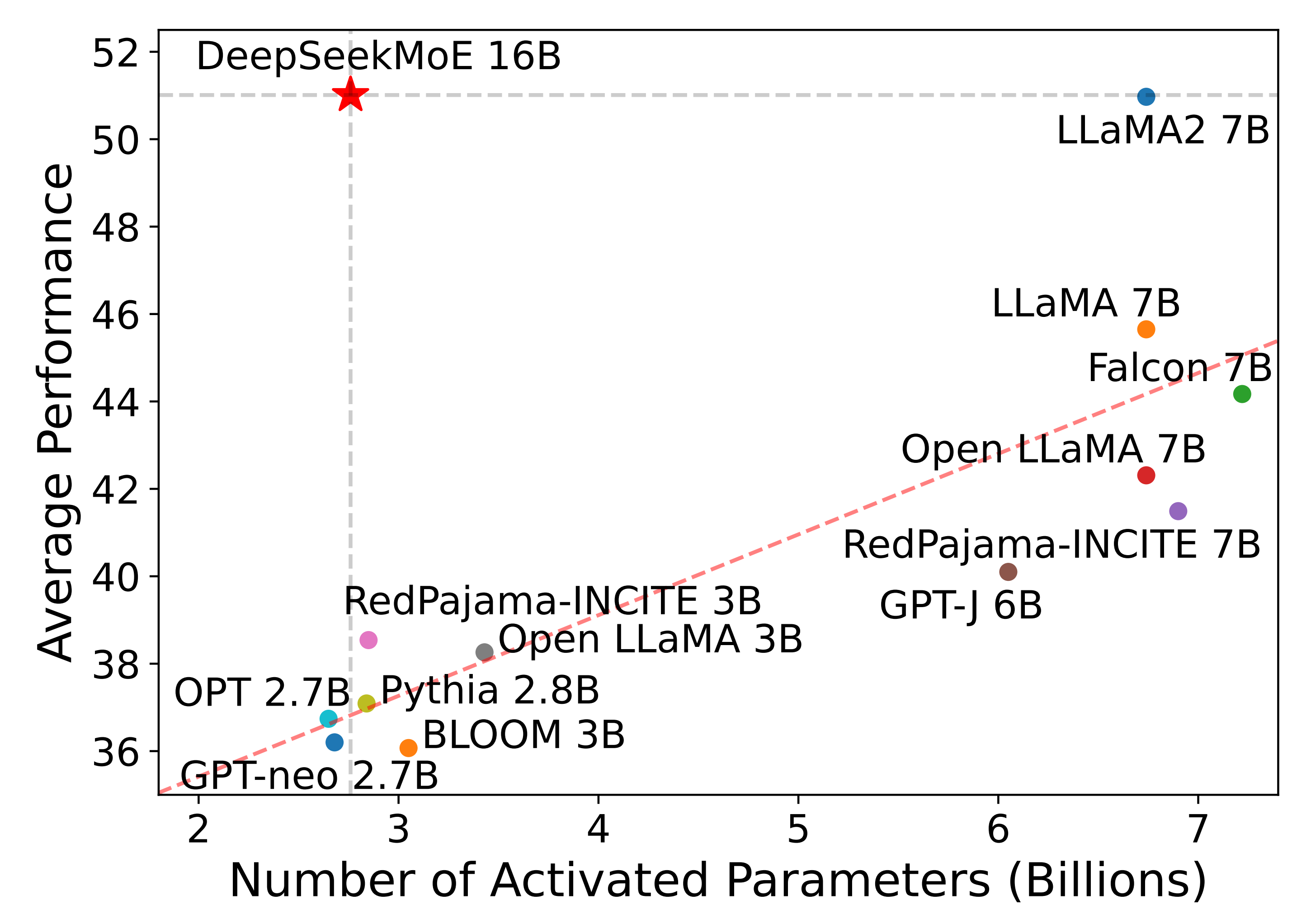
在参数规模上,虽然只有16B(在2T的token数据上训练而成),但由于其性能的高效,使得其达到同等的性能下,所需要调动的参数量是相比其他模型 更低的,如下图所示
那DeepSeekMoE到底有什么创新性呢?「至于什么是MoE,详见此文《从Mistral 7B到MoE模型Mixtral 8x7B的全面解析:从原理分析到代码解读》的第二部分」
首先,传统的 MoE 架构用 MoE 层替代了 Transformer 中的前馈网络 (FFNs)。每个 MoE 层由多个专家组成,每个专家在结构上与标准 FFN 相同,每个token被分配给一个 或两个专家
这里面存在两个问题
- 在专家数量有限的情况下,分配给特定专家的token更有可能涵盖多种类型的知识。因此,指定的专家将倾向于在其参数中学习截然不同类型的知识,而这些知识难以同时利用
然而,如果每个token可以被路由到更多的专家,分散的知识将有可能在不同的专家中分别学习 - 有些知识是比较大众通用的,所以会导致某几个专家会被调用的异常频繁
那是否可以比较好的解决这两个问题呢
- 对于前者,DeepSeekMoE提出细粒度专家分割——Fine-Grained Expert Segmentation:在保持参数数量不变的情况下,通过拆分FFN 中间隐藏维度来将专家分割为更细的粒度(说白了,细粒度的专家分割允许将多样化的知识更精细地分解,并更精确地学习到不同的专家中,从而使得专家更专业)
相应地,在保持计算成本不变的情况下,还激活了更多细粒度的专家,以实现更灵活和适应性更强的激活专家组合(增加的激活专家组合的灵活性也有助于更准确和有针对性的知识获取) - 对于后者,DeepSeekMoE提出共享专家隔离——Shared Expert Isolatio:隔离某些专家作为共享专家,这些专家始终被激活,旨在捕捉和巩固不同上下文中的共同知识
综上,如下图所示(子图a展示了具有传统 top-2 路由策略的 MoE 层;子图b说明了细粒度专家分割策略;随后,子图c展示了共享专家隔离策略的集成,从而构成了完整的 DeepSeekMoE 架构)

1.2.2 前情回顾:基于transformer的传统MoE结构
一个标准的Transformer语言模型是通过堆叠 𝐿层标准的Transformer块构建的,每个块可以表示如下(为简洁起见,省略了层归一化)
其中,

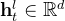
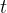
构建 MoE 语言模型的典型做法通常是在指定的间隔处用 MoE 层替换 Transformer 中的 FFN,MoE 层由多个专家组成,每个专家在结构上与标准 FFN 相同。然后,每个token将被分配给一个或两个专家。如果将第

其中
表示专家的总数
是第
个专家的FFN
表示第
表示token到专家的亲和度
表示第
个最高亲和度分数的集合
是第
注意
1.2.3 细粒度专家分割
具体来说
- 在下图a所示的典型MoE架构的基础上,通过将FFN中间隐藏维度减少到
其原始大小(比如下图m=2),从而将每个专家FFN分割成𝑚个更小的专家
- 由于每个专家变得更小,特此可以增加激活专家的数量到𝑚倍,以保持相同的计算成本,如下图b所示(正因为m=2,所以下图b有2N个专家)
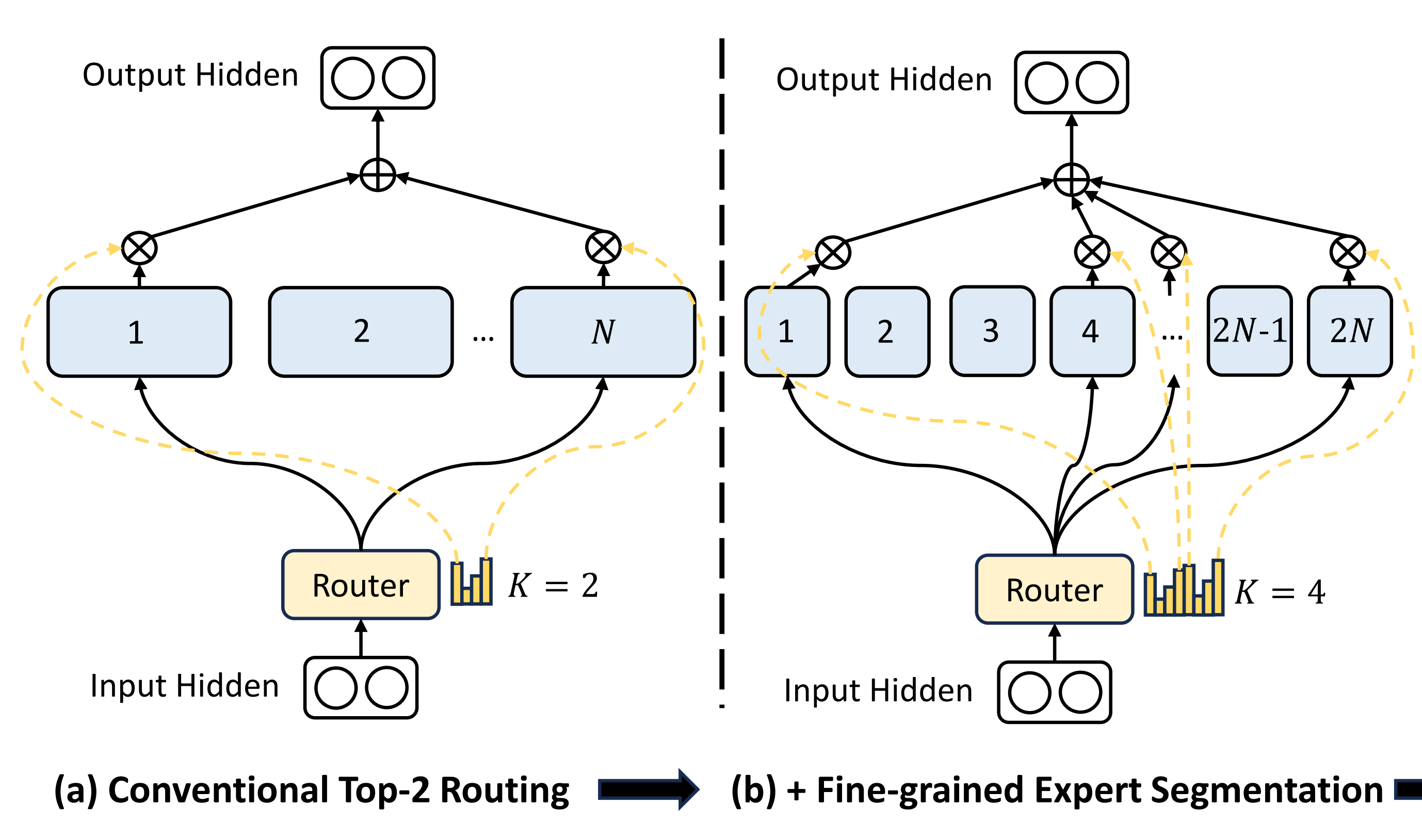
通过细粒度的专家分割,MoE层的输出可以表示为

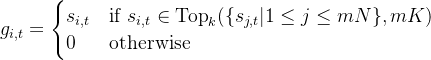
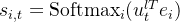
其中专家参数的总数等于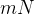
过细粒度专家分割策略,非零门的数量也将增加到 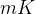
举个例子,如果 𝑁 =16,一个典型的top-2路由策略可以产生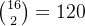
潜在的组合,组合灵活性的激增增强了实现更准确和有针对性的知识获取的潜力
1.2.4 共享专家隔离
在传统的路由策略中,分配给不同专家的token可能需要一些共同的知识或信息。因此,多个专
家可能会在各自的参数中获取共享知识,从而导致专家参数的冗余
然而,如果有共享专家专门用于捕捉和整合不同上下文中的共同知识,那么其他路由专家之间的参数冗余将会减少。这种冗余的减少将有助于构建一个参数更高效且专家更专业化的模型
为实现这一目标,除了细粒度的专家分割策略外,DeepSeekMoE进一步隔离了
为了保持恒定的计算成本,其他路由专家中被激活的专家数量将减少
在集成了共享专家隔离策略后,完整的 DeepSeekMoE 架构中的 MoE 层公式如下
最后,在 DeepSeekMoE 的完整结构中
- 共享专家的数量是
- 路由专家的总数是
,相当于2N-1
- 非零门的数量是
(如果没有共享专家 则是mK,有共享专家 则减掉共享专家即可),相当于4 - 1 = 3
1.2.5 负载平衡:专家级平衡损失、设备级平衡损失
自动学习的路由策略可能会遇到负载不平衡的问题,这会表现出两个显著缺陷
- 首先,存在路由崩溃的风险(Shazeer等人,2017年),即模型总是选择少数几个专家,导致其他专家无法得到充分训练
- 其次,如果专家分布在多个设备上,负载不平衡会加剧计算瓶颈
为了减轻路由崩溃的风险,他们采取了以下两种措施
- 专家级平衡损失
其中 𝛼1是一个称为专家级平衡因子的超参数,路由专家的数量等于
等于
表示indicator function
- 设备级平衡损失
当旨在缓解计算瓶颈时,在专家级别强制执行严格的平衡约束变得不必要,因为对负载平衡的过度约束会损害模型性能
相反,主要目标是确保设备间的计算平衡。如果将所有路由的专家划分为组,并将每组部署在一个设备上,则设备级平衡损失计算如下
其中 𝛼2是一个称为设备级平衡因子的超参数
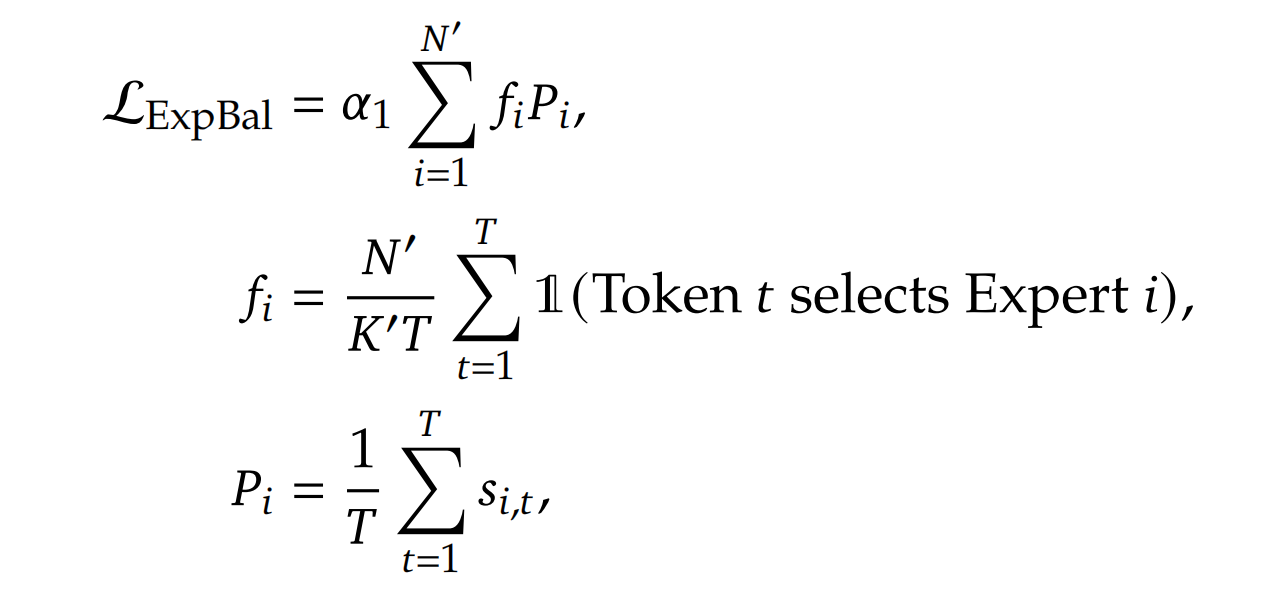
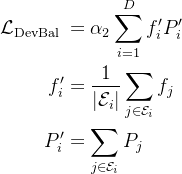
在实践中,一般设置一个较小的专家级平衡因子以减轻路由崩溃的风险,同时设置一个较大的设备级平衡因子以促进设备之间的计算平衡
1.3 DeepSeekMath及其提出的GRPO
因为DeepSeek-V2涉及到了DeepSeekMath「其对应论文为 24年2月发表的《DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models》」中提出的群体相对策略优化——Group Relative Policy Optimization(简称GRPO)
故本节重点介绍一下DeepSeekMath及其提出的GRPO
1.3.1 DeepSeekMath(基于DeepSeek-Coder初始化)的三阶段训练方式:预训练-微调-RL训练
DeepSeekMath是一个包含120B的数学token的大规模高质量预训练语料库,训练过程是经典的预训练-微调-RL训练三阶段
- DeepSeekMath-Base 7B
DeepSeekMath-Base 是在 DeepSeek-Coder-Base-v1.5 7B的基础上初始化的,因为他们注意到从代码训练模型开始比从通用 LLM 开始是一个更好的选择
具体而言
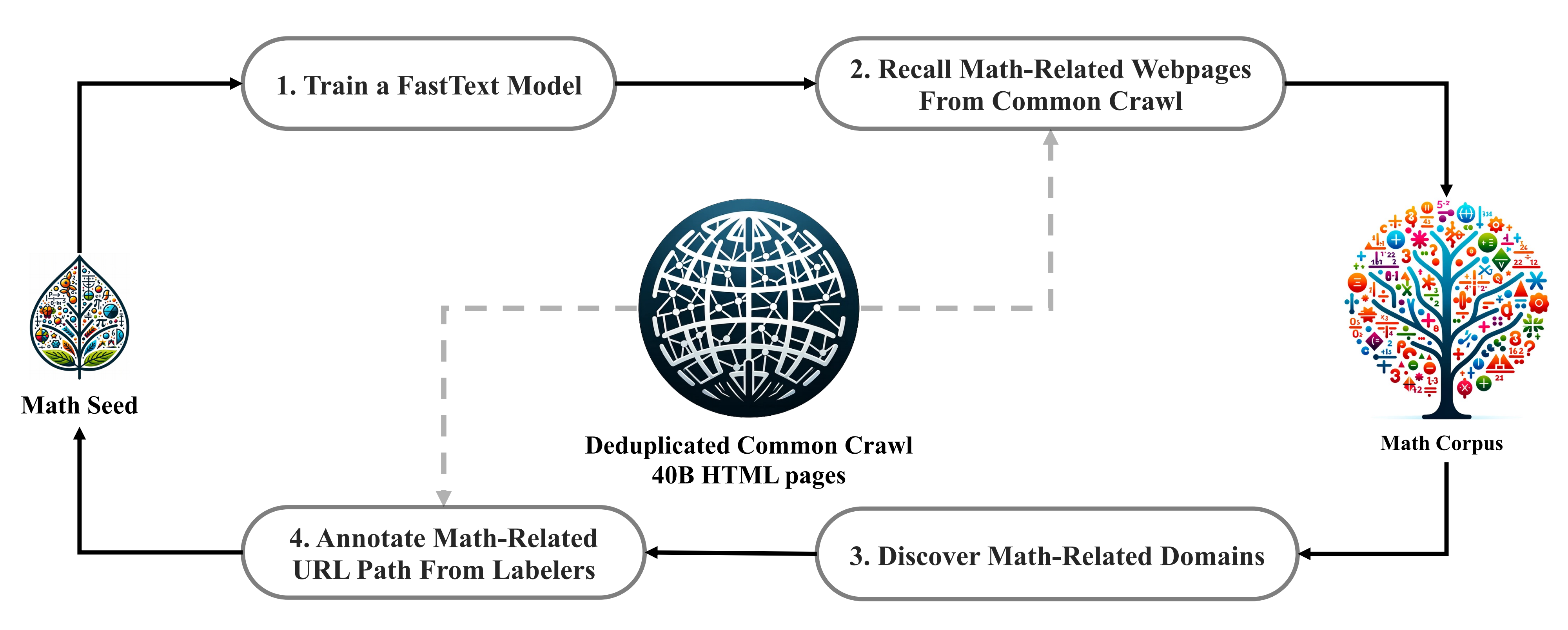
首先,通过从种子语料库OpenWebMath(一个高质量的数学网页文本集合)中随机选择50万个数据点作为正训练样本,训练一个fastText模型作为分类器
然后,使用该分类器从从Common Crawl(简称CC)中挖掘出更多的正例,且还选择其中的50万个网页作为负样本
当然,过程中,会对CC数据集做大量的去重,最终得到40B HTML网页
最后,针对这个去重后的40B CC数据集,直接人工标注出与数学相关的URL网页,然后归纳到种子数据集,从而通过这个扩大后的种子数据集去继续训练fastText,以提升其性能
最终,该模型与DeepSeek LLMs(DeepSeek-LLM 1.3B)有着相同的框架
1) 他们分别在每个数学语料库上训练模型,训练量为150B个token
2) 所有实验均使用高效且轻量级的HAI-LLM训练框架进行,且使用AdamW优化器,其中 𝛽1 = 0.9, 𝛽2 =0.95,weight_decay =0.1
3) 并采用多步学习率调度,学习率在2,000个预热步骤后达到峰值,在训练过程的80%后降至峰值的31.6%,在训练过程的90%后进一步降至峰值的10.0%
4) 另将学习率的最大值设置为5.3e-4,并使用包含4K上下文长度的4M token批量大小 - DeepSeekMath-Instruct
在预训练之后,对 DeepSeekMath-Base 应用了数学指令调优,且使用了CoT、program-of-thoug和tool-integrated reasonin数据
最终DeepSeekMath-Instruct 7B 在数学方面的能力,超越了所有 7B 同类模型,并且可以与 70B 开源指令微调模型相媲美 - DeepSeekMath-RL
此外,引入群体相对策略优化GRPO做进一步的RL训练,这是近端策略优化PPO的另一种变体算法
该方法放弃了通常与策略policy模型大小相同的critic模型,而是从群体得分中估计基线baseline,最终显著减少了所需的训练资源
In order to save the training costs of RL, we adopt Group Relative Policy Optimization (GRPO) (Shao et al., 2024), which foregoes the critic model that is typically with the same size as the policy model, and estimates the baseline from group scores instead
1.3.2 详解GRPO:与PPO的对比及其如何做RL训练
首先,什么是PPO呢?
通过本博客内的其他文章(如果对RLHF或PPO的原理及其在ChatGPT中的应用不了解,则可以看这两篇文章:RL极简入门、ChatGPT原理详解、从零实现带RLHF的类ChatGPT 即可,胜过网上任何一切资料 ),可知
近端策略优化PPO是一种actor-critic的RL算法,其通过最大化以下目标函数来优化LLM
其中
、
分别代表当前策略、旧策略
、
分别采样于问题数据集、旧策略
是PPO中引入的与裁剪clip相关的超参数,用于稳定训练
是优势,其通过应用广义优势估计GAE计算出——基于奖励
和可学习的价值函数
因此,在PPO中,需要一个价值函数与策略模型一起训练
- 且为了减轻奖励模型的过度优化,会在每个token的奖励得分中添加一个来自参考模型中对应token的KL惩罚(the standard approach is to add a per-token KL penalty from a reference model in the reward at each token,言外之意就是可以为讨领导喜欢而不断改进自己的行为,但一切行为的底限是:不与公司倡导的价值感 相差太远 ),即
其中,是奖励模型,
是基线模型(即reference model,其被SFT模型初始化),
是KL惩罚的系数
- 不过,按理来说,这里的
,类似如下所示
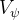
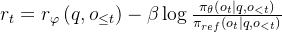
其次,PPO的问题是什么呢?
- 由于 PPO 中使用的价值函数value function(相当于actor-critic中的critic)通常是与策略模型policy model相当规模的另一个模型,这带来了巨大的内存和计算负担
如此文《速读deepseek v2 (三)- 理解GRPO(deepseekmath 与 deepseek coder)》所说
PPO的算法中,有4个模型
一个actor,生成句子
一个critic模型,类似国内教练,输出value,也算做价值函数
一个reward模型,类似国际裁判
一个reference模型
PPO的效率缺陷主要在于actor和critic的交互,是否可以丢掉critic呢,让actor直接去对齐RM
其实在PPO之前,最早是没有 Critic 的,用 actor 去生成行为,然后利用所有行为共同获得分数来训练模型,但是,因为每一个action(对应生成句子中的每一个 token)都是一个随机变量,N 个随机变量加在一起,方差就会非常巨大,这通常会导致整个 RL 训练崩掉,ReMax 的工作中就有类似的说明
为了解决这个问题,可以寻找一个baseline,让每一个随机变量都减掉该baseline,从而降低方差,这样训练就稳定了
那如何得到该baseline?简单一点,随机采样 N 次,取 N 次采样结果的得分「均值」作为 baseline,不过这种策略下只有当采样 N 足够大时,方差才能足够小,否则采样的代表性可能不足
PPO 的处理方式是使用一个神经网络 Critic 去拟合该均值均值(并非直接叠加),以减小方差 - 此外,在 RL 训练期间,价值函数被视为计算优势的基线——
「注意体会这句话,特别是其中基线的意义」,以减少方差
而在有的 LLM 环境中,通常只有最后一个token由奖励模型分配奖励分数,这可能会使在每个token上想要得到准确的价值评估会比较复杂——即价值函数训练变得复杂
不过,话说回来,还有的LLM环境中,比如微软的deepspeed chat——简称DSC,其在实现PPO/RLHF时,会涉及到对每个token的价值评估,详见:从零实现带RLHF的类ChatGPT:逐行解析微软DeepSpeed Chat的源码
最后,有没PPO的替代算法呢?一方面,上文提过的DPO是一种
另一方面,DeepSeek提出了群体相对策略优化GRPO——Group Relative Policy Optimization
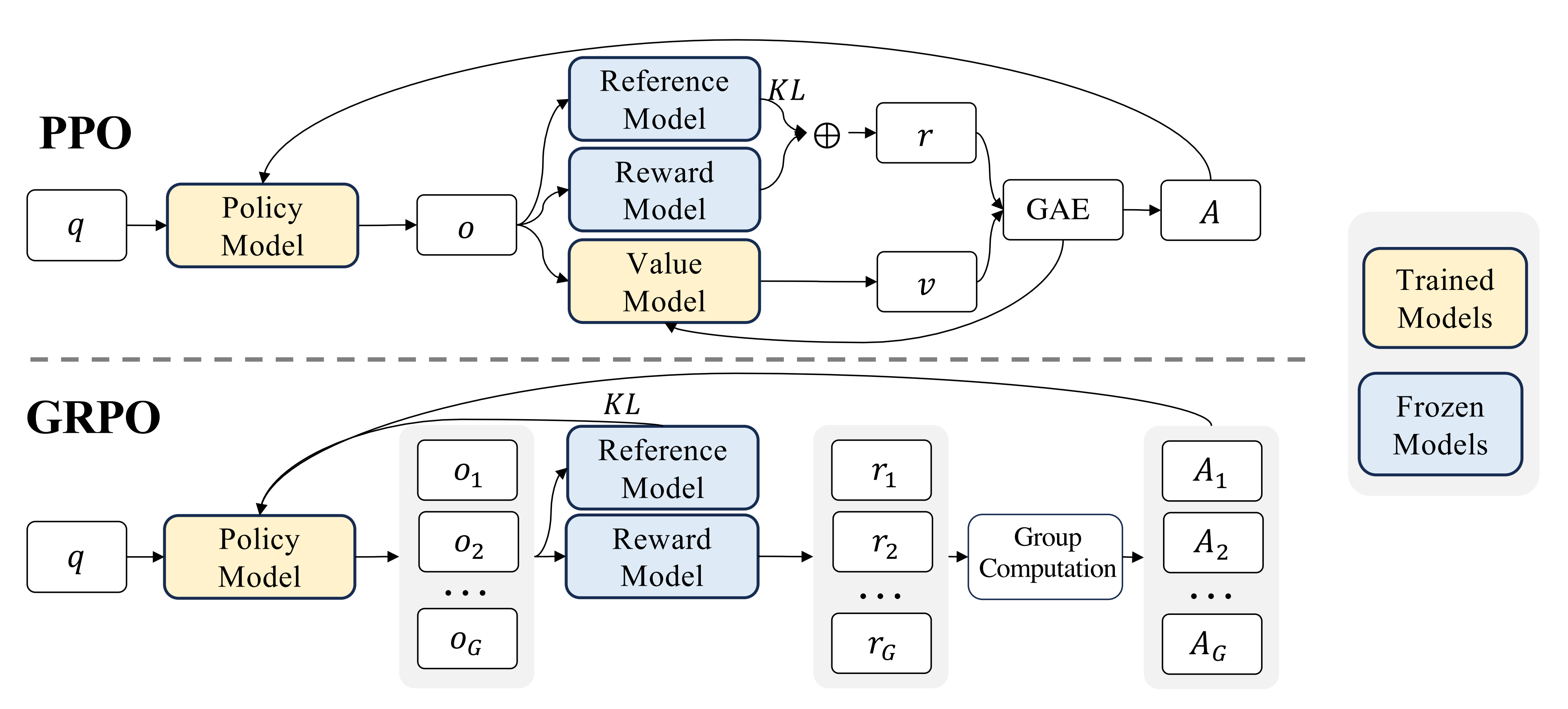
- 它避免了像 PPO 那样需要额外的价值函数近似——说白了 就是不要PPO当中的value model或value function去做价值评估
we propose Group Relative Policy Optimization (GRPO), which obviates the need for additional value function approximation as in PPO
就是丢掉critic,也就没有了value(不需要基于value做估计),也就不需要GAE - 而是使用对同一问题的多个采样输出的平均奖励作为基线(说白了,直接暴力采样 N 次求均值)
and instead uses the average reward of multiple sampled outputs, produced in response to the same question, as the baseline
毕竟优势函数不就重点考察那些超出预期、超出基线baseline的表现么,所以问题的关键就是基线baseline的定义,因为一旦定义好了baseline,我们的目标就明确了——越发鼓励可以超过baseline的行为(而每个行为是由背后的策略所决定的,故优化行为的同时就是策略的不断迭代与优化),而这就是优势函数所追求的
上面这段话值得反复品读三遍..
更具体地,对于每个问题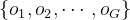
- 在目标函数方面
GRPO通过最大化下述目标函数以优化策略模型
其中,是基于每组内部输出的相对奖励计算的优势(ˆ𝐴𝑖,𝑡 is the advantage calculated based on relative rewards of the outputs inside each group on)
如此,GRPO 用的计算优势的群体相对方式,与奖励模型的比较性质非常契合,因为奖励模型通常是在同一问题的输出比较数据集上训练的
The group relative way that GRPO leverages to calculate the advantages, aligns well with the comparative nature of rewards models, as reward models are typically trained on datasets of comparisons between outputs on the same question - 在KL惩罚项方面
GRPO 不是在奖励中添加 KL 惩罚,而是通过直接将训练策略和参考策略之间的 KL 散度添加到损失中来进行正则化,从而避免了复杂的
instead of adding KL penalty in the reward, GRPO regularizes by directly adding the KL divergence between the trained policy and the reference policy to the loss, avoiding complicating the calculation of ˆ𝐴𝑖,𝑡 .
说白了,GRPO 中虽然也加了 KL Penalty,只不过不像 PPO 的实现是每个 token 位置上加一个惩罚(即没有加在RM里,比如上面提到的微软DSC在实现PPO/RLHF时,就涉及到对每个token的评估,故自然便有了对每一个token的KL惩罚),而是直接一并计算完后加到最后的 loss 中去
总之,与PPO中奖励函数所使用的KL惩罚项不同,GRPO中使用以下无偏估计器估计KL散度 - 在梯度计算方面
如果为了简化分析,比如假设模型在每个探索阶段之后只有一次更新,从而确保,在这种情况之下,便可以移除上面的clip操作「it is assumed that the model only has a single update following each exploration stage, there by ensuring that 𝜋𝜃𝑜𝑙𝑑 = 𝜋𝜃. In this case, we can remove the min and clip operation」
即如下图所示(虽然下图所示的过程是在PPO中,但本质是一个意思)
且再把上面的放入到
表达式中,即可得
接下来,便可以计算
如此,梯度系数是
其中的
![\mathbb{D}_{K L}\left[\pi_{\theta}|| \pi_{r e f}\right]=\frac{\pi_{r e f}\left(o_{i, t} \mid q, o_{i,<t}\right)}{\pi_{\theta}\left(o_{i, t} \mid q, o_{i,<t}\right)}-\log \frac{\pi_{r e f}\left(o_{i, t} \mid q, o_{i,<t}\right)}{\pi_{\theta}\left(o_{i, t} \mid q, o_{i,<t}\right)}-1](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUNtYXRoYmIlN0JEJTdEXyU3QkslMjBMJTdEJTVDbGVmdCU1QiU1Q3BpXyU3QiU1Q3RoZXRhJTdEJTdDJTdDJTIwJTVDcGlfJTdCciUyMGUlMjBmJTdEJTVDcmlnaHQlNUQlM0QlNUNmcmFjJTdCJTVDcGlfJTdCciUyMGUlMjBmJTdEJTVDbGVmdCUyOG9fJTdCaSUyQyUyMHQlN0QlMjAlNUNtaWQlMjBxJTJDJTIwb18lN0JpJTJDJTNDdCU3RCU1Q3JpZ2h0JTI5JTdEJTdCJTVDcGlfJTdCJTVDdGhldGElN0QlNUNsZWZ0JTI4b18lN0JpJTJDJTIwdCU3RCUyMCU1Q21pZCUyMHElMkMlMjBvXyU3QmklMkMlM0N0JTdEJTVDcmlnaHQlMjklN0QtJTVDbG9nJTIwJTVDZnJhYyU3QiU1Q3BpXyU3QnIlMjBlJTIwZiU3RCU1Q2xlZnQlMjhvXyU3QmklMkMlMjB0JTdEJTIwJTVDbWlkJTIwcSUyQyUyMG9fJTdCaSUyQyUzQ3QlN0QlNUNyaWdodCUyOSU3RCU3QiU1Q3BpXyU3QiU1Q3RoZXRhJTdEJTVDbGVmdCUyOG9fJTdCaSUyQyUyMHQlN0QlMjAlNUNtaWQlMjBxJTJDJTIwb18lN0JpJTJDJTNDdCU3RCU1Q3JpZ2h0JTI5JTdELTE%3D)

![\begin{array}{l} \mathcal{J}_{G R P O}(\theta)=\mathbb{E}\left[q \sim P_{s f t}(Q),\left\{o_{i}\right\}_{i=1}^{G} \sim \pi_{\theta_{o l d}}(O \mid q)\right] \\ \frac{1}{G} \sum_{i=1}^{G} \frac{1}{\left|o_{i}\right|} \sum_{t=1}^{\left|o_{i}\right|}\left[\frac{\pi_{\theta}\left(o_{i, t} \mid q, o_{i,<t}\right)}{\pi_{\theta_{o l d}}\left(o_{i, t} \mid q, o_{i,<t}\right)} \hat{A}_{i, t}-\beta\left(\frac{\pi_{r e f}\left(o_{i, t} \mid q, o_{i,<t}\right)}{\pi_{\theta}\left(o_{i, t} \mid q, o_{i,<t}\right)}-\log \frac{\pi_{r e f}\left(o_{i, t} \mid q, o_{i,<t}\right)}{\pi_{\theta}\left(o_{i, t} \mid q, o_{i,<t}\right)}-1\right)\right] \end{array}](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUNiZWdpbiU3QmFycmF5JTdEJTdCbCU3RCUyMCU1Q21hdGhjYWwlN0JKJTdEXyU3QkclMjBSJTIwUCUyME8lN0QlMjglNUN0aGV0YSUyOSUzRCU1Q21hdGhiYiU3QkUlN0QlNUNsZWZ0JTVCcSUyMCU1Q3NpbSUyMFBfJTdCcyUyMGYlMjB0JTdEJTI4USUyOSUyQyU1Q2xlZnQlNUMlN0JvXyU3QmklN0QlNUNyaWdodCU1QyU3RF8lN0JpJTNEMSU3RCU1RSU3QkclN0QlMjAlNUNzaW0lMjAlNUNwaV8lN0IlNUN0aGV0YV8lN0JvJTIwbCUyMGQlN0QlN0QlMjhPJTIwJTVDbWlkJTIwcSUyOSU1Q3JpZ2h0JTVEJTIwJTVDJTVDJTIwJTVDZnJhYyU3QjElN0QlN0JHJTdEJTIwJTVDc3VtXyU3QmklM0QxJTdEJTVFJTdCRyU3RCUyMCU1Q2ZyYWMlN0IxJTdEJTdCJTVDbGVmdCU3Q29fJTdCaSU3RCU1Q3JpZ2h0JTdDJTdEJTIwJTVDc3VtXyU3QnQlM0QxJTdEJTVFJTdCJTVDbGVmdCU3Q29fJTdCaSU3RCU1Q3JpZ2h0JTdDJTdEJTVDbGVmdCU1QiU1Q2ZyYWMlN0IlNUNwaV8lN0IlNUN0aGV0YSU3RCU1Q2xlZnQlMjhvXyU3QmklMkMlMjB0JTdEJTIwJTVDbWlkJTIwcSUyQyUyMG9fJTdCaSUyQyUzQ3QlN0QlNUNyaWdodCUyOSU3RCU3QiU1Q3BpXyU3QiU1Q3RoZXRhXyU3Qm8lMjBsJTIwZCU3RCU3RCU1Q2xlZnQlMjhvXyU3QmklMkMlMjB0JTdEJTIwJTVDbWlkJTIwcSUyQyUyMG9fJTdCaSUyQyUzQ3QlN0QlNUNyaWdodCUyOSU3RCUyMCU1Q2hhdCU3QkElN0RfJTdCaSUyQyUyMHQlN0QtJTVDYmV0YSU1Q2xlZnQlMjglNUNmcmFjJTdCJTVDcGlfJTdCciUyMGUlMjBmJTdEJTVDbGVmdCUyOG9fJTdCaSUyQyUyMHQlN0QlMjAlNUNtaWQlMjBxJTJDJTIwb18lN0JpJTJDJTNDdCU3RCU1Q3JpZ2h0JTI5JTdEJTdCJTVDcGlfJTdCJTVDdGhldGElN0QlNUNsZWZ0JTI4b18lN0JpJTJDJTIwdCU3RCUyMCU1Q21pZCUyMHElMkMlMjBvXyU3QmklMkMlM0N0JTdEJTVDcmlnaHQlMjklN0QtJTVDbG9nJTIwJTVDZnJhYyU3QiU1Q3BpXyU3QnIlMjBlJTIwZiU3RCU1Q2xlZnQlMjhvXyU3QmklMkMlMjB0JTdEJTIwJTVDbWlkJTIwcSUyQyUyMG9fJTdCaSUyQyUzQ3QlN0QlNUNyaWdodCUyOSU3RCU3QiU1Q3BpXyU3QiU1Q3RoZXRhJTdEJTVDbGVmdCUyOG9fJTdCaSUyQyUyMHQlN0QlMjAlNUNtaWQlMjBxJTJDJTIwb18lN0JpJTJDJTNDdCU3RCU1Q3JpZ2h0JTI5JTdELTElNUNyaWdodCUyOSU1Q3JpZ2h0JTVEJTIwJTVDZW5kJTdCYXJyYXklN0Q%3D)

接下来,我们来看下优势函数如何设计
类似此文《ChatGPT原理详解 》3.2.1节如何更好的理解Actor-Critic架构中的Critic网络节最后有讲到的
优势的计算、回报的计算、Critic的输出等等都是开放性的话题
- 设计者认为Critic不需要去评价时间步、只需要评价完整序列,那么Critic就被设计成标量预测,比如colossalchat
- 设计者认为Critic需要严谨到对每个时间步做评价,那么Critic就会被设计成序列预测,比如微软deepspeed chat
可以有三种设计
- 使用GRPO的结果监督强化学习,相当于奖励模型只看最终生成句子的表现,不看生成过程中是否按预期进行
首先,对于每个问题,通过旧策略模型
Formally, for each question 𝑞, a group of outputs {𝑜1, 𝑜2, · · · , 𝑜𝐺 } are sampled from the old policy model 𝜋𝜃𝑜𝑙𝑑 .
其次,使用奖励模型对每个输出进行评分,从而得到G个奖励
A reward model is then used to score the outputs, yielding 𝐺 rewards r = {𝑟1, 𝑟2, · · · , 𝑟𝐺 } correspondingly.
随后,通过减去组平均值并除以组标准差来规划化这些奖励
Subsequently, these rewards are normalized by subtracting the group average and dividing by the group standard deviation.
结果监督在每个输出结束时提供规范化的奖励,并将输出中所有token的优势
Outcome supervision provides the normalized reward at the end of each output 𝑜𝑖 and sets the advantages ˆ𝐴𝑖,𝑡 of all tokens in the output as the normalized reward, i.e., ˆ𝐴𝑖,𝑡 = e𝑟𝑖 = 𝑟𝑖 −mean(r) std(r)
最后,通过最大化这个目标函数
and then optimizes the policy bymaximizing the objective defined in equation - 使用GRPO进行过程监督RL
结果监督仅在每个输出的末尾提供奖励,这可能不足以有效监督复杂数学任务中的策略(毕竟数学计算讲究step by step,需要关注类似CoT那种推断的过程)
根据Wang等人(Math-shepherd: Verify and reinforce llms step-by-step without human annotations)的研究,deepseek还探索了过程监督,它在每个推理步骤结束时提供奖励
Outcome supervision only provides a reward at the end of each output, which may not be sufficient and efficient to supervise the policy in complex mathematical tasks. Following Wang et al. (2023b), we also explore process supervision, which provides a reward at the end of each reasoning step.
形式上,给定问题采样输出
其中是第
步的结束token索引,
是第
Formally, given the question 𝑞 and 𝐺 sampled outputs {𝑜1, 𝑜2, · · · , 𝑜𝐺 }, a process reward model is used to score each step of the outputs, yielding corresponding rewards: R = {{𝑟𝑖𝑛𝑑𝑒𝑥 (1)1 , · · · , 𝑟𝑖𝑛𝑑𝑒𝑥 (𝐾1 )1 }, · · · , {𝑟𝑖𝑛𝑑𝑒𝑥 (1)𝐺 , · · · , 𝑟𝑖𝑛𝑑𝑒𝑥 (𝐾𝐺 )𝐺 }}, where 𝑖𝑛𝑑𝑒𝑥 ( 𝑗) is the end token index of the 𝑗-th step, and 𝐾𝑖 is the total number of steps in the 𝑖-th output.
且还用平均值和标准差对这些奖励进行归一化,即
We also normalize these rewards with the average and the standard deviation, i.e., e𝑟𝑖𝑛𝑑𝑒𝑥 ( 𝑗)𝑖 = 𝑟𝑖𝑛𝑑𝑒𝑥 ( 𝑗)𝑖 −mean(R)std(R) .
随后,过程监督计算每个token的优势作为以下步骤的归一化奖励的总和,即
最后,通过最大化
Subsequently,the process supervision calculates the advantage of each token as the sum of the normalized rewards from the following steps, i.e., ˆ𝐴𝑖,𝑡 = Í𝑖𝑛𝑑𝑒𝑥 ( 𝑗) ≥𝑡 e𝑟𝑖𝑛𝑑𝑒𝑥 ( 𝑗)𝑖 , and then optimizes the policy by maximizing the objective defined in equation - 使用 GRPO 的迭代强化学习
随着强化学习训练过程的进展,旧的奖励模型可能不足以监督当前的策略模型
因此,他们还探索了使用 GRPO 的迭代强化学习,如下图所示
在迭代 GRPO 中,根据策略模型的采样结果为奖励模型生成新的训练集,并使用包含 10%历史数据的重放机制不断训练旧的奖励模型
然后,将参考模型设为策略模型,并使用新的奖励模型持续训练策略模型
友情提醒:如果这段看着比较费劲,建议可以不用深究

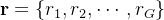





在本次对策略模型(基于DeepSeekMath-Instruct 7B)做强化学习的训练中
- 且强化学习的训练数据是与GSM8K和MATH相关的链式思维格式问题,这些问题来自SFT数据,总共约有144K个问题
- 排除其他SFT问题,以研究在整个强化学习阶段缺乏数据的基准测试上强化学习的影响
且按照(Wang etal., 2023b,即上文提过的Math-shepherd)构建奖励模型的训练集 - 基于DeepSeekMath-Base 7B训练初始奖励模型,学习率为2e-5
- 对于GRPO,将策略模型的学习率设为1e-6。KL系数为0.04
对于每个问题,采样64个输出,最大长度设置为1024,训练批量大小为1024 - 策略模型在每个探索阶段之后仅进行一次更新
在基准测试中评估了DeepSeekMath-RL 7B,遵循DeepSeekMath-Instruct 7B
对于DeepSeekMath-RL 7B,带有链式推理的GSM8K和MATH可以视为域内任务,所有其他基准测试可以视为域外任务
1.3.3 针对SFT、RFT、DPO、PPO、GRPO的统一范式
通常,训练方法相对于参数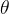
![\nabla_{\theta} \mathcal{J}_{\mathcal{A}}(\theta)=\mathbb{E}[\underbrace{(q, o) \sim \mathcal{D}]}_{\text {Data Source }}(\frac{1}{|o|} \sum_{t=1}^{|o|} \underbrace{G C_{\mathcal{A}}\left(q, o, t, \pi_{r f}\right)}_{\text {Gradient Coefficient }} \nabla_{\theta} \log \pi_{\theta}\left(o_{t} \mid q, o_{<t}\right))](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUNuYWJsYV8lN0IlNUN0aGV0YSU3RCUyMCU1Q21hdGhjYWwlN0JKJTdEXyU3QiU1Q21hdGhjYWwlN0JBJTdEJTdEJTI4JTVDdGhldGElMjklM0QlNUNtYXRoYmIlN0JFJTdEJTVCJTVDdW5kZXJicmFjZSU3QiUyOHElMkMlMjBvJTI5JTIwJTVDc2ltJTIwJTVDbWF0aGNhbCU3QkQlN0QlNUQlN0RfJTdCJTVDdGV4dCUyMCU3QkRhdGElMjBTb3VyY2UlMjAlN0QlN0QlMjglNUNmcmFjJTdCMSU3RCU3QiU3Q28lN0MlN0QlMjAlNUNzdW1fJTdCdCUzRDElN0QlNUUlN0IlN0NvJTdDJTdEJTIwJTVDdW5kZXJicmFjZSU3QkclMjBDXyU3QiU1Q21hdGhjYWwlN0JBJTdEJTdEJTVDbGVmdCUyOHElMkMlMjBvJTJDJTIwdCUyQyUyMCU1Q3BpXyU3QnIlMjBmJTdEJTVDcmlnaHQlMjklN0RfJTdCJTVDdGV4dCUyMCU3QkdyYWRpZW50JTIwQ29lZmZpY2llbnQlMjAlN0QlN0QlMjAlNUNuYWJsYV8lN0IlNUN0aGV0YSU3RCUyMCU1Q2xvZyUyMCU1Q3BpXyU3QiU1Q3RoZXRhJTdEJTVDbGVmdCUyOG9fJTdCdCU3RCUyMCU1Q21pZCUyMHElMkMlMjBvXyU3QiUzQ3QlN0QlNUNyaWdodCUyOSUyOQ%3D%3D)
其存在三个关键组成部分:1)数据来源 D,决定训练数据;2) 奖励函数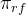
来源;3)算法 A:处理训练数据和奖励信号以获得梯度系数
比如
- 对于监督微调SFT而言
SFT 在人工选择的 SFT 数据上微调预训练模型 - 对于拒绝采样微调 (RFT)而言
RFT基于SFT问题从SFT模型中采样的过滤输出进一步微调SFT模型,RFT根据答案的正确性过滤输出 - 对于直接偏好优化 (DPO)而言
DPO通过使用成对DPO损失在增强输出上微调SFT模型,从而进一步优化SFT模型 - 对于在线拒绝采样微调 (在线RFT)而言
与RFT不同,在线RFT使用SFT模型初始化策略模型,并通过在实时策略模型中采样的增强输出进行微调来优化它 - PPO/GRPO: PPO/GRPO使用SFT模型初始化策略模型,并通过从实时策略模型中采样的输出进行强化(当然,严格意义上,得区分策略模型的旧策略和当前策略)
第二部分 DeepSeek-V2:提出多头潜在注意力MLA且改进MoE
DeepSeek-V2属于DeepSeek的第二代版本,参数规模虽然达到了庞大的236B,但由于其MoE的结构,使得其中每个token激活仅21B的参数,且支持128K的上下文(It is equipped with a total of 236B parameters, of which 21B are activated for each token, and supports a context length of 128K tokens)
其对应论文为《DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model》
- 他们首先在完整的预训练语料库上预训练DeepSeek-V2
- 然后,收集了150万个对话会话,涵盖了数学、代码、写作、推理、安全等各个领域,以对DeepSeek-V2 Chat(SFT)进行监督微调(SFT)
- 最后,我们遵循DeepSeekMath的方法,采用组相对策略优化(GRPO)进一步使模型与人类偏好对齐,并生成DeepSeek-V2 Chat(RL)
DeepSeek-V2主要有两大创新点,其在Transformer架构「一个注意力模块和一个前馈网络(FFN),如对transformer还不够熟练,请看此文:Transformer通俗笔记:从Word2Vec、Seq2Seq逐步理解到GPT、BERT」的基础上
- 改造注意力模块
其通过创造性的提出多头潜在注意力——Multi-head Latent Attent(简称MLA),替代传统多头注意力(Multi Head Attention)
具体而言,MLA利用低秩键值联合压缩(low-rank key-value joint compression)来降低推理时的KV Cache开销,且性能不输于MHA(论文中说的是性能比MHA还更好) - 改造FFN
其把FFN的结构改成DeepseekMoE——是对传统MoE结构的改进(下图各种结构、表示很懂,初看难以一看就懂,没事,下文会逐一详解,一个符号都不会放过)

值得一提的是,他们还一块发布了 DeepSeek-V2-Lite,相当于配备 MLA 和 DeepSeekMoE 的较小模型,它总共有15.7B参数,其中每个token激活2.4B参数(we also release DeepSeek-V2-Lite, a smaller model equipped with MLA and DeepSeekMoE, for the open-source community. It has a total of 15.7B parameters, where 2.4B are activated for each token)
- DeepSeek-V2-Lite 有 27 层,隐藏维度为 2048。 它还采用 MLA,并具有 16 个注意力头,每个头的维度为 128。 其 KV 压缩维度为 512,但与 DeepSeek-V2 略有不同,它不压缩查询
对于解耦查询和键,每头维度为 64 - DeepSeek-V2-Lite 还采用 DeepSeekMoE,除了第一层外,所有前馈神经网络 (FFNs) 都被 MoE 层替换
每个 MoE 层由 2 个共享专家和 64 个路由专家组成,每个专家的中间隐藏维度为 1408。 在这些路由专家中,每个token将激活6个专家 - DeepSeek-V2-Lite 也在与 DeepSeek-V2 相同的预训练语料库上从头开始训练,该语料库未被任何 SFT 数据污染
它使用 AdamW 优化器,超参数设置为 𝛽1 = 0.9, 𝛽2 =0.95,权重衰减 =0.1。学习率使用预热和阶梯衰减策略进行调度
最初,在前2000步期间,学习率从0线性增加到最大值。 随后,在训练了大约80%的tokens后,学习率乘以0.316,并在训练了大约90%的tokens后再次乘以0.316。
最大学习率设置为4.2 × 10−4,梯度裁剪范数设置为1.0。没有采用批量大小调度策略,而是以恒定的批量大小4608个序列进行训练。 在预训练期间,将最大序列长度设置为4K,并在5.7T tokens上训练DeepSeek-V2-Lite
2.1 DeepSeek-V2提出MLA的背景与作用
2.1.1 KV Cache所导致的显存消耗大,需要尽可能降低
众所周知,KV Cache是大模型标配的推理加速功能——也是推理过程中,显存资源巨大开销的元凶之一。如下图所示,在模型推理时,KV Cache在显存占用量可达30%以上

目前大部分针对KV Cache的优化工作
- 比如著名的vLLM(这是其介绍页面、这是其对应的GitHub、其论文则为:Efficient Memory Management for Large Language Model Serving with PagedAttention,当然了,我后面会专门写一篇解读vLLM的博客),其基于paged Attention,最大限度地利用碎片化显存空间,从而提升了空间利用率
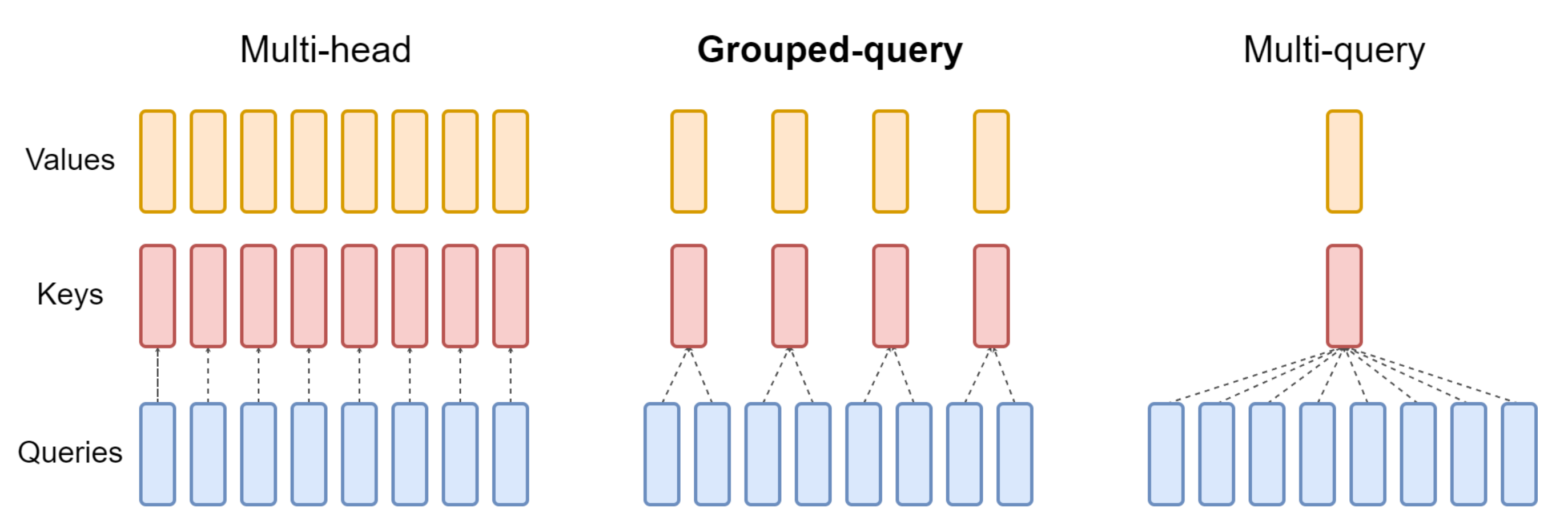
- 再比如GQA、MQA
GQA是query数不变,但多个query(比如2个)组成一个group以共享一个key value
MQA则query也不变,但所有query(比如8个)共享一个key、一个value
至于更多,详见此文:一文通透各种注意力:从多头注意力MHA到分组查询注意力GQA、多查询注意力MQA
这些方案的问题是什么呢?在于
- 第一类方案并没有从根本上改变KV Cache占用空间巨大的问题
- 而第二类方案中的MQA虽然较大降低了KV cache计算量,但性能相比MHA下降太多了
至于第二类方案中的GQA则取了个折中:不好的是缓存下降的不够多、好的是相比MHA性能没有下降太多,毕竟我们追求的是缓存下降、性能不降
那KV Cache到底是什呢
- 对此,我们先来回顾下transformer当中的注意力计算公式
- GPT预测下一个token时,其只能看到待预测token之前的所有token,故在最终生成
整个序列的过程中,会涉及到如下计算过程
- 然后把上面的softmax结果和对应的V值一相乘,便可得到
可以很明显的看到,上述计算过程中,有不少的重复计算,比如
、
、
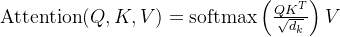
![\operatorname{softmax}\left(\begin{array}{cccc} Q_{1} K_{1}^{T} & -\infty & -\infty & -\infty \\ Q_{2} K_{1}^{T} & Q_{2} K_{2}^{T} & -\infty & -\infty \\ Q_{3} K_{1}^{T} & Q_{3} K_{2}^{T} & Q_{3} K_{3}^{T} & -\infty \\ Q_{4} K_{1}^{T} & Q_{4} K_{2}^{T} & Q_{4} K_{3}^{T} & Q_{4} K_{4}^{T} \end{array}\right)\left[\begin{array}{c} \overrightarrow{V_{1}} \\ \overrightarrow{V_{2}} \\ \overrightarrow{V_{3}} \\ \overrightarrow{V_{4}} \end{array}\right]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUNvcGVyYXRvcm5hbWUlN0Jzb2Z0bWF4JTdEJTVDbGVmdCUyOCU1Q2JlZ2luJTdCYXJyYXklN0QlN0JjY2NjJTdEJTIwUV8lN0IxJTdEJTIwS18lN0IxJTdEJTVFJTdCVCU3RCUyMCUyNiUyMC0lNUNpbmZ0eSUyMCUyNiUyMC0lNUNpbmZ0eSUyMCUyNiUyMC0lNUNpbmZ0eSUyMCU1QyU1QyUyMFFfJTdCMiU3RCUyMEtfJTdCMSU3RCU1RSU3QlQlN0QlMjAlMjYlMjBRXyU3QjIlN0QlMjBLXyU3QjIlN0QlNUUlN0JUJTdEJTIwJTI2JTIwLSU1Q2luZnR5JTIwJTI2JTIwLSU1Q2luZnR5JTIwJTVDJTVDJTIwUV8lN0IzJTdEJTIwS18lN0IxJTdEJTVFJTdCVCU3RCUyMCUyNiUyMFFfJTdCMyU3RCUyMEtfJTdCMiU3RCU1RSU3QlQlN0QlMjAlMjYlMjBRXyU3QjMlN0QlMjBLXyU3QjMlN0QlNUUlN0JUJTdEJTIwJTI2JTIwLSU1Q2luZnR5JTIwJTVDJTVDJTIwUV8lN0I0JTdEJTIwS18lN0IxJTdEJTVFJTdCVCU3RCUyMCUyNiUyMFFfJTdCNCU3RCUyMEtfJTdCMiU3RCU1RSU3QlQlN0QlMjAlMjYlMjBRXyU3QjQlN0QlMjBLXyU3QjMlN0QlNUUlN0JUJTdEJTIwJTI2JTIwUV8lN0I0JTdEJTIwS18lN0I0JTdEJTVFJTdCVCU3RCUyMCU1Q2VuZCU3QmFycmF5JTdEJTVDcmlnaHQlMjklNUNsZWZ0JTVCJTVDYmVnaW4lN0JhcnJheSU3RCU3QmMlN0QlMjAlNUNvdmVycmlnaHRhcnJvdyU3QlZfJTdCMSU3RCU3RCUyMCU1QyU1QyUyMCU1Q292ZXJyaWdodGFycm93JTdCVl8lN0IyJTdEJTdEJTIwJTVDJTVDJTIwJTVDb3ZlcnJpZ2h0YXJyb3clN0JWXyU3QjMlN0QlN0QlMjAlNUMlNUMlMjAlNUNvdmVycmlnaHRhcnJvdyU3QlZfJTdCNCU3RCU3RCUyMCU1Q2VuZCU3QmFycmF5JTdEJTVDcmlnaHQlNUQ%3D)

如果序列长度越长,类似这样的
2.1.2 Multi-head Latent Attent:致力于在推理中降低
MLA是对传统多头注意力做的改进,其目的有两个:首先是,降低推理过程中的KV Cache资源开销,其次,缓解MQA、MGA对性能的损耗
如上文所说,KV Cache中,提到每一步都需要将K和V缓存下来
具体而言,对于单个Attention Block块中的多头注意力(下图来自上文提到过的Transformer通俗笔记)

比如,举个例子,假设
- 输入embedding的维度为
,比如512
- 然后有
个头,比如8个头
- 每个头——
和
的维度为
,比如64
为注意力层中第
- transformer的层数为
——Thinking
- 首先,标准的MHA会通过三个矩阵
分别生成
,即
- 然后,
将被切分成
其中分别表示第
表示输出投影矩阵
- 最终,在推理过程中,需要缓存所有的键和值以加速推理,因此MHA需要为每个token缓存的参数量为
(注意,是针对每个token,总之,如论文中所说,During inference, all keys and values need to be cached to accelerate inference, so MHA needs to cache

![\begin{array}{l} {\left[\mathbf{q}_{t, 1} ; \mathbf{q}_{t, 2} ; \ldots ; \mathbf{q}_{t, n_{h}}\right]=\mathbf{q}_{t}} \\ {\left[\mathbf{k}_{t, 1} ; \mathbf{k}_{t, 2} ; \ldots ; \mathbf{k}_{t, n_{h}}\right]=\mathbf{k}_{t}} \\ {\left[\mathbf{v}_{t, 1} ; \mathbf{v}_{t, 2} ; \ldots ; \mathbf{v}_{t, n_{h}}\right]=\mathbf{v}_{t}} \\ \quad \mathbf{o}_{t, i}=\sum_{j=1}^{t} \operatorname{Softmax}_{j}\left(\frac{\mathbf{q}_{t, i}^{T} \mathbf{k}_{j, i}}{\sqrt{d_{h}}}\right) \mathbf{v}_{j, i} \\ \quad \mathbf{u}_{t}=W^{O}\left[\mathbf{o}_{t, 1} ; \mathbf{o}_{t, 2} ; \ldots ; \mathbf{o}_{t, n_{h}}\right] \end{array}](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUNiZWdpbiU3QmFycmF5JTdEJTdCbCU3RCUyMCU3QiU1Q2xlZnQlNUIlNUNtYXRoYmYlN0JxJTdEXyU3QnQlMkMlMjAxJTdEJTIwJTNCJTIwJTVDbWF0aGJmJTdCcSU3RF8lN0J0JTJDJTIwMiU3RCUyMCUzQiUyMCU1Q2xkb3RzJTIwJTNCJTIwJTVDbWF0aGJmJTdCcSU3RF8lN0J0JTJDJTIwbl8lN0JoJTdEJTdEJTVDcmlnaHQlNUQlM0QlNUNtYXRoYmYlN0JxJTdEXyU3QnQlN0QlN0QlMjAlNUMlNUMlMjAlN0IlNUNsZWZ0JTVCJTVDbWF0aGJmJTdCayU3RF8lN0J0JTJDJTIwMSU3RCUyMCUzQiUyMCU1Q21hdGhiZiU3QmslN0RfJTdCdCUyQyUyMDIlN0QlMjAlM0IlMjAlNUNsZG90cyUyMCUzQiUyMCU1Q21hdGhiZiU3QmslN0RfJTdCdCUyQyUyMG5fJTdCaCU3RCU3RCU1Q3JpZ2h0JTVEJTNEJTVDbWF0aGJmJTdCayU3RF8lN0J0JTdEJTdEJTIwJTVDJTVDJTIwJTdCJTVDbGVmdCU1QiU1Q21hdGhiZiU3QnYlN0RfJTdCdCUyQyUyMDElN0QlMjAlM0IlMjAlNUNtYXRoYmYlN0J2JTdEXyU3QnQlMkMlMjAyJTdEJTIwJTNCJTIwJTVDbGRvdHMlMjAlM0IlMjAlNUNtYXRoYmYlN0J2JTdEXyU3QnQlMkMlMjBuXyU3QmglN0QlN0QlNUNyaWdodCU1RCUzRCU1Q21hdGhiZiU3QnYlN0RfJTdCdCU3RCU3RCUyMCU1QyU1QyUyMCU1Q3F1YWQlMjAlNUNtYXRoYmYlN0JvJTdEXyU3QnQlMkMlMjBpJTdEJTNEJTVDc3VtXyU3QmolM0QxJTdEJTVFJTdCdCU3RCUyMCU1Q29wZXJhdG9ybmFtZSU3QlNvZnRtYXglN0RfJTdCaiU3RCU1Q2xlZnQlMjglNUNmcmFjJTdCJTVDbWF0aGJmJTdCcSU3RF8lN0J0JTJDJTIwaSU3RCU1RSU3QlQlN0QlMjAlNUNtYXRoYmYlN0JrJTdEXyU3QmolMkMlMjBpJTdEJTdEJTdCJTVDc3FydCU3QmRfJTdCaCU3RCU3RCU3RCU1Q3JpZ2h0JTI5JTIwJTVDbWF0aGJmJTdCdiU3RF8lN0JqJTJDJTIwaSU3RCUyMCU1QyU1QyUyMCU1Q3F1YWQlMjAlNUNtYXRoYmYlN0J1JTdEXyU3QnQlN0QlM0RXJTVFJTdCTyU3RCU1Q2xlZnQlNUIlNUNtYXRoYmYlN0JvJTdEXyU3QnQlMkMlMjAxJTdEJTIwJTNCJTIwJTVDbWF0aGJmJTdCbyU3RF8lN0J0JTJDJTIwMiU3RCUyMCUzQiUyMCU1Q2xkb3RzJTIwJTNCJTIwJTVDbWF0aGJmJTdCbyU3RF8lN0J0JTJDJTIwbl8lN0JoJTdEJTdEJTVDcmlnaHQlNUQlMjAlNUNlbmQlN0JhcnJheSU3RA%3D%3D)
因此,MLA致力于在推理中降低

- 对Key和Value进行了一个低秩联合压缩(即Low-Rank Key-Value Joint Compression,通过低秩转换为一个压缩的KV,使得存储的KV的维度显著减小)
- 如上图所示(在MHA GQA中大量存在于keys values中的KV缓存——带阴影表示,到了MLA中时,只有一小部分的被压缩的Latent KV了)
那,MLA具体如何做压缩呢,详看下节

2.2 详解MLA的两个部分:一部分做压缩、一部分做RoPE编码
DeepSeek通过对Query和Key进行拆分为![\left[q_{t}^{R}, q_{t}^{C}\right]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUNsZWZ0JTVCcV8lN0J0JTdEJTVFJTdCUiU3RCUyQyUyMHFfJTdCdCU3RCU1RSU3QkMlN0QlNUNyaWdodCU1RA%3D%3D)
![\left[k_{t}^{R}, k_{t}^{C}\right]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUNsZWZ0JTVCa18lN0J0JTdEJTVFJTdCUiU3RCUyQyUyMGtfJTdCdCU3RCU1RSU3QkMlN0QlNUNyaWdodCU1RA%3D%3D)
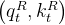
2.2.1 MLA对Q K V的压缩:先对KV联合压缩后升维,再对Q压缩后升维
首先,对于上图右下角的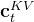
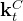
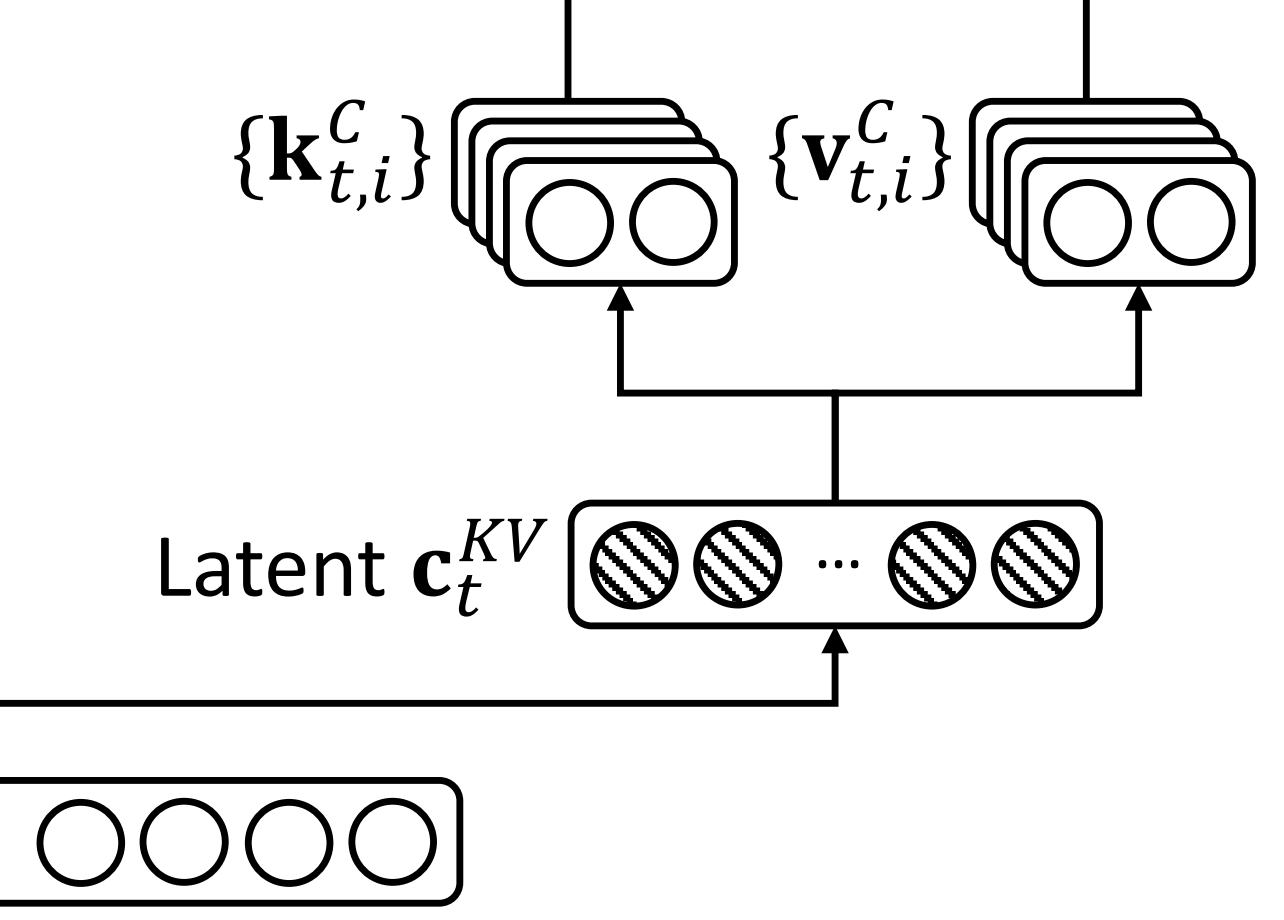
可以看到先降维down(公式表示时用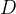
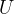
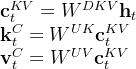
- 先针对KV联合压缩以降维
对于上述第一个公式,是对key和value压缩后的潜在向量,对于
表示KV被压缩后的维度
「远小于到头key和value的原始维度
和模型输入
相乘得到
注,为方便大家更好的理解,我特地花了个把小时(反复琢磨、反复修改),用手头的iPad Pro + apple pencil画了下上述过程,以方便大家一目了然的对比前后维度的变化(至于下图底部中除了之外的怎么回事,不急,下文很快会逐一阐述)
- 后再对K、V分别升维以还原
至于上述第二三公式,在于通过第一个公式得到后,具体的key和value由两个对应的升维矩阵
还原,即
且在推理的过程中
1) 只需要缓存每一步的
2) 由于可以吸收到
中,而
可以吸收到
中,我们甚至不需要计算注意力的键和值(即如论文中所说,during inference, since 𝑊𝑈 𝐾 can be absorbed into 𝑊𝑄 , and 𝑊𝑈𝑉 can be absorbed into 𝑊𝑂, we even do not need to compute keys and values out for attent)
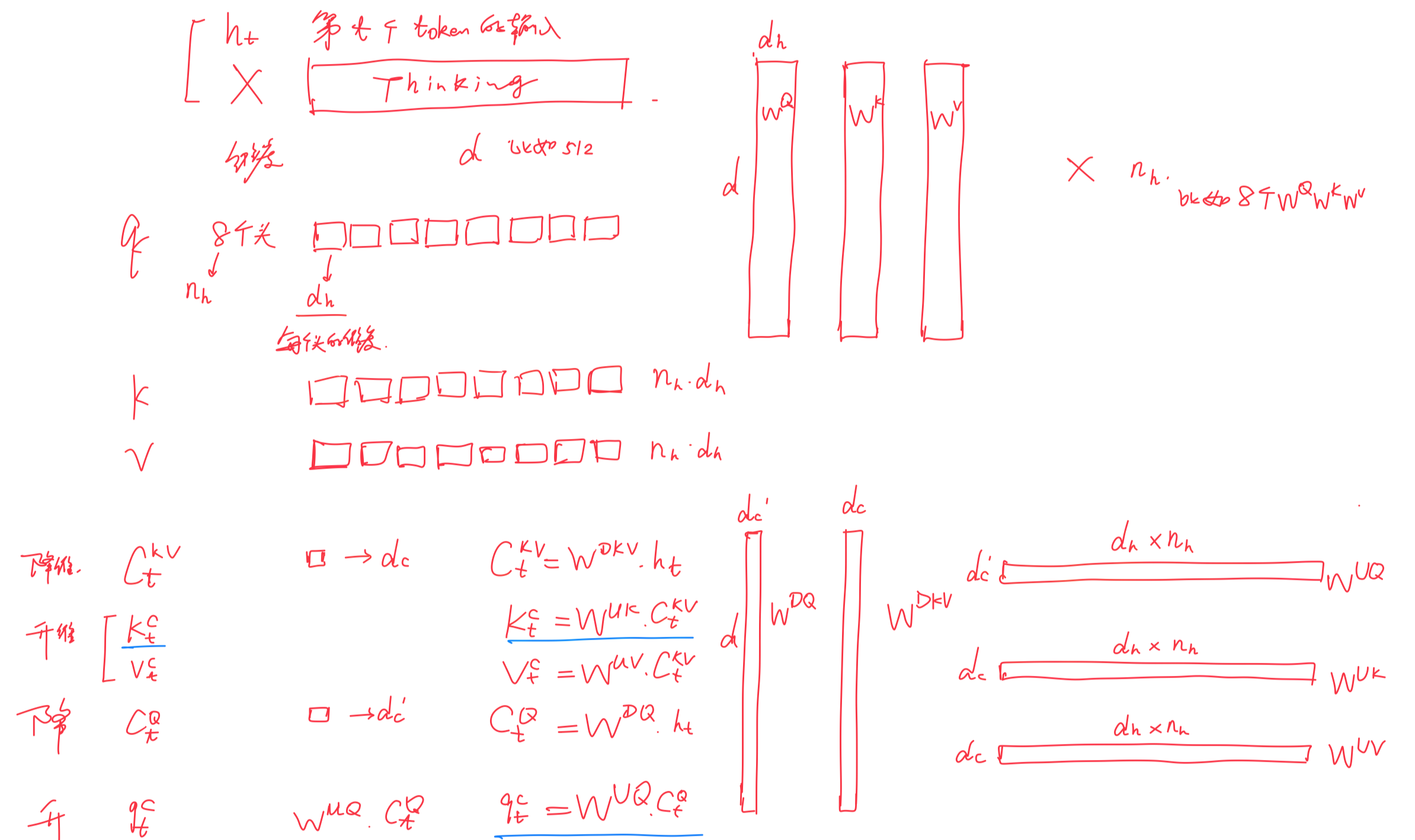


其次,对于上图左下角的


之前提到KV Cache中,Q的作用只发生在当下(预测下一个token时,其只能看到待预测token之前的所有token),但是在模型训练的过程中,每个输入的token会通过多头注意力机制生成对应的query、key和value
这些中间数据的维度往往非常高,因此占用的内存量也相应很大
所以论文中也提到,为了降低训练过程中的激活内存activation memory,DeepSeek-V2还对queries进行低秩压缩,即便这并不能降低KV Cache,而其对Q的压缩方式和K、V一致,依然是先降维再升维
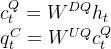
其中
是查询的压缩潜在向量(the compressed latent vector for queries)
表示查询压缩后的维度(这个也好理解,为了区别上面的
表示)
而、
则分别表示查询的下投影和上投影矩阵(相当于还是先降维再升维)

2.2.2 MLA对query和key的RoPE编码
如下图红框所示,需要对,从而在推理时不需要对Key进行位置编码的计算,提高了推理效率

在RoPE的实现中,如果要让Q、K带上位置信息,会分别乘以相应的位置编码矩阵
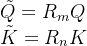
如果计算QK时,自然就变成了
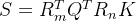
通过上一节可知,DeepSeek-V2对Q和K都进行了压缩:

则整个过程变成
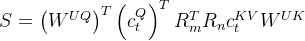
其中的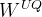
然有个问题
- 问题在于,由于低秩表示已经是压缩了的状态,故直接在
和
,不等价于在完整的Q和K上应用位置编码(因为压缩操作可能已经丢失了某些信息,使得位置编码不能直接和有效地反映原始Q和K的位置关系)
换言之,RoPE与低秩KV压缩不兼容——RoPE is incompatible with low-rank KV compression - 为了解决这问题,Deepseek-V2设计了两个pe结尾的变量——
、
(如论文中所说,we propose the decoupled RoPE strategy that uses additional multi-head queries q𝑅𝑡,𝑖 ∈ R𝑑𝑅ℎ and a shared key k𝑅𝑡 ∈ R𝑑𝑅ℎ to carry RoPE, where
denotes the per-head dimension of the decoupled queries and key,即表示解耦查询和键的每头维度)
即用于储存旋转位置编码的信息,将信息存储和旋转编码解耦开
其中,、
分别是用于生成解耦查询和键的矩阵
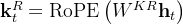
为方便大家更好的理解,我把我自己上面画的手绘图又加了一些内容,好与上述这些公式逐一比对
且顺带总结一下
- 首先,因为
故不能直接在
从而也就不能- 故额外设计两个变量
、
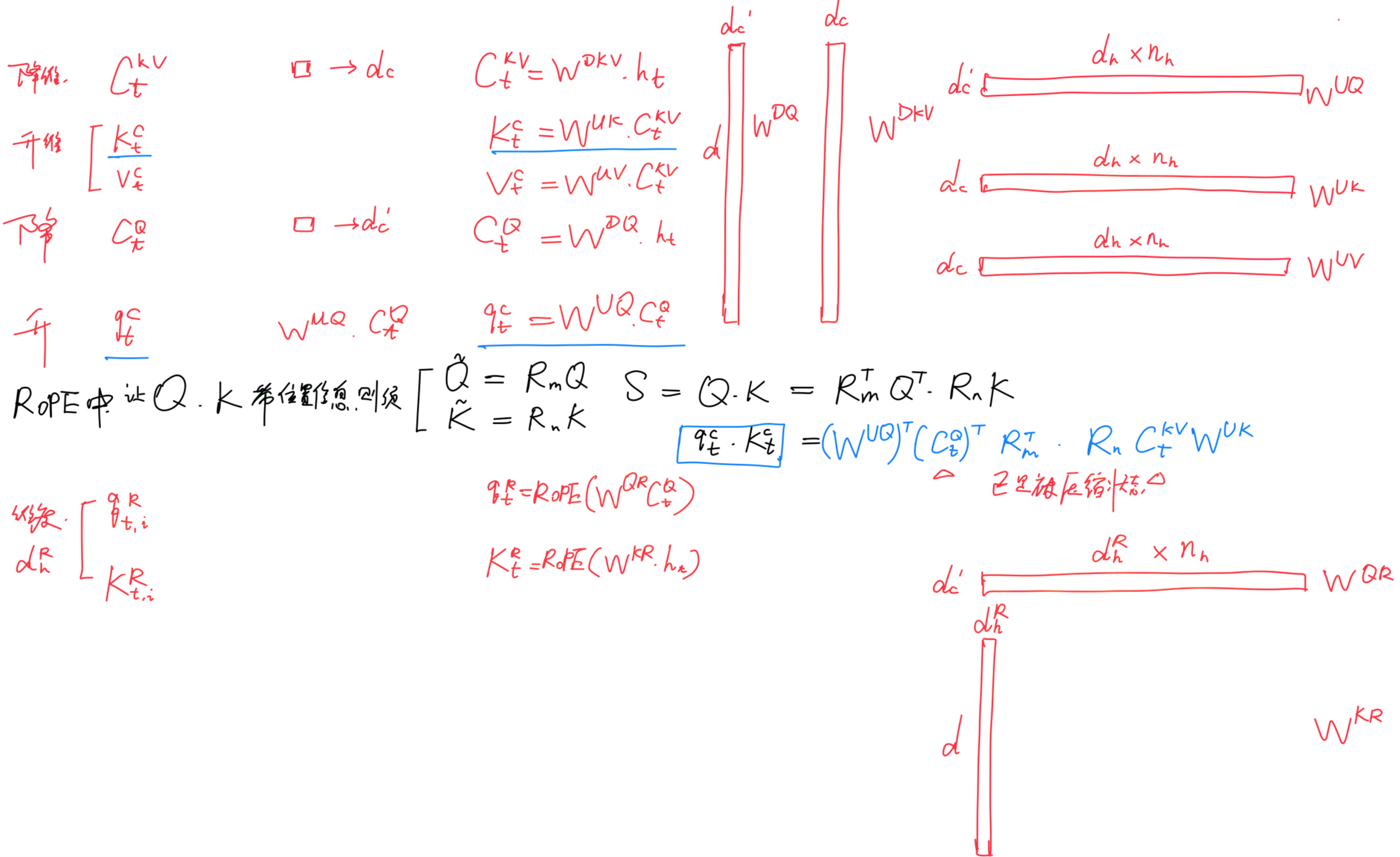
压缩完、且RoPE编码完之后,最后将这4个变量——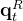
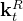
- 带信息压缩的Q——
、K——
- 带位置信息的Q——
以进行最后的计算(其中蓝色框中的向量

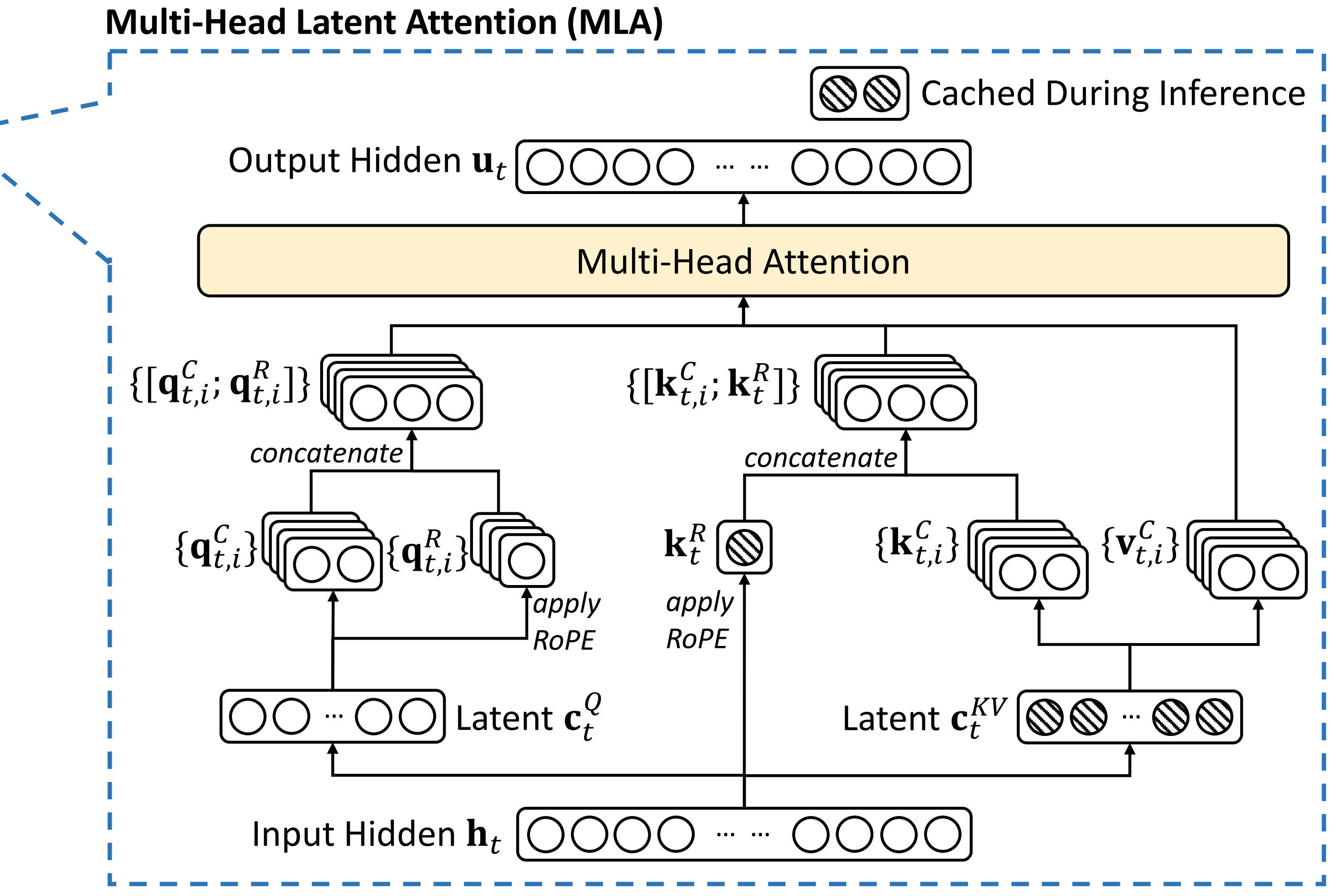
最终,单个Token产生的缓存包含了两个部分,即

其中,如上文说过的
- 有
表示为GQA中的组数
、
在DeepSeek-V2中,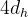
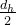
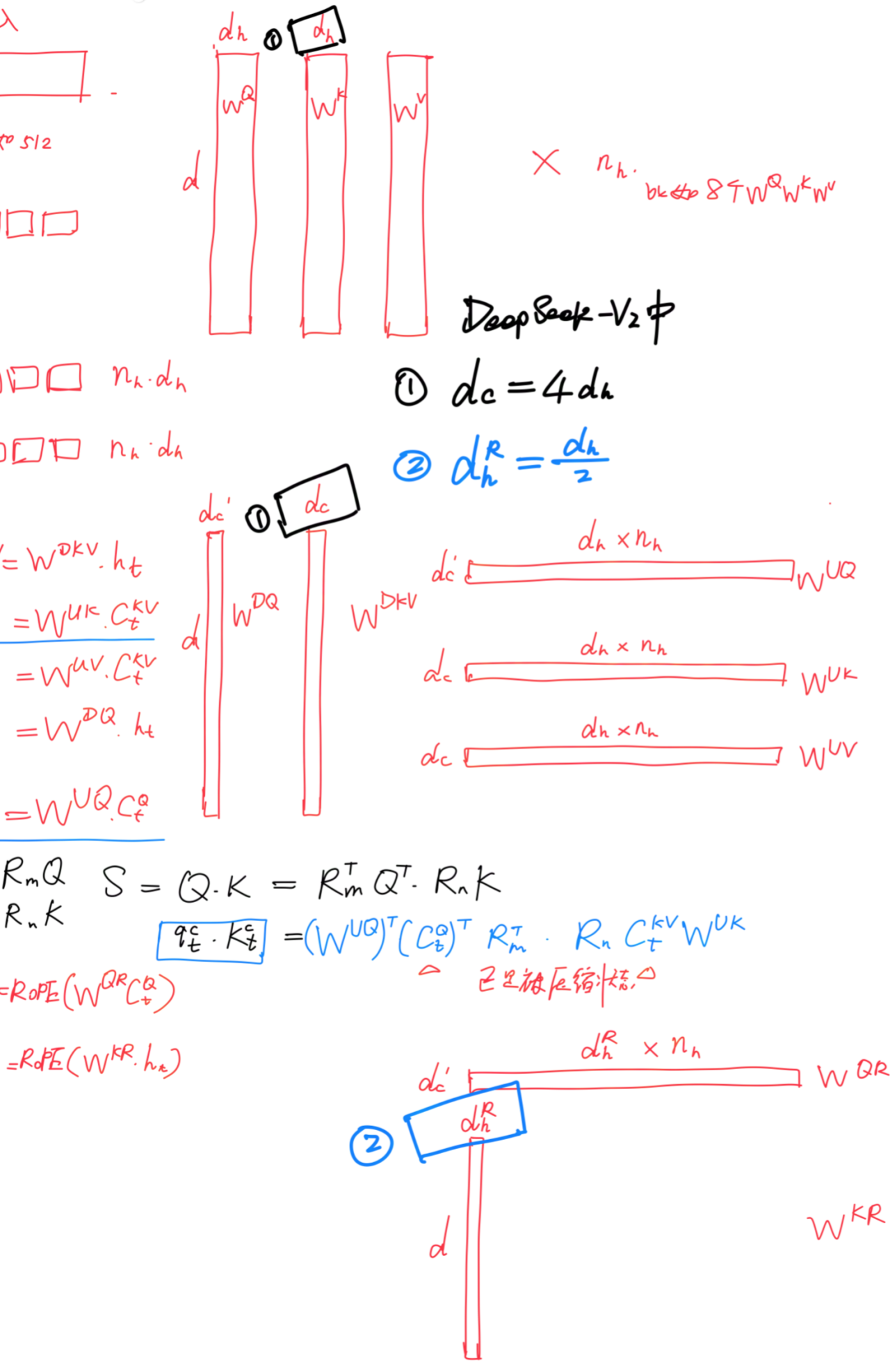
因此,它的KV缓存等于只有2.25组的GQA,但其性能强于MHA
2.3 DeepSeekMoE:以经济成本训练强大的模型
2.3.1 基本架构与Device-Limited Routing
由于在上文的1.3节,我们详细的介绍了DeepSeekMoE(包括细粒度专家分割和共享专家隔离),故本节描述从简
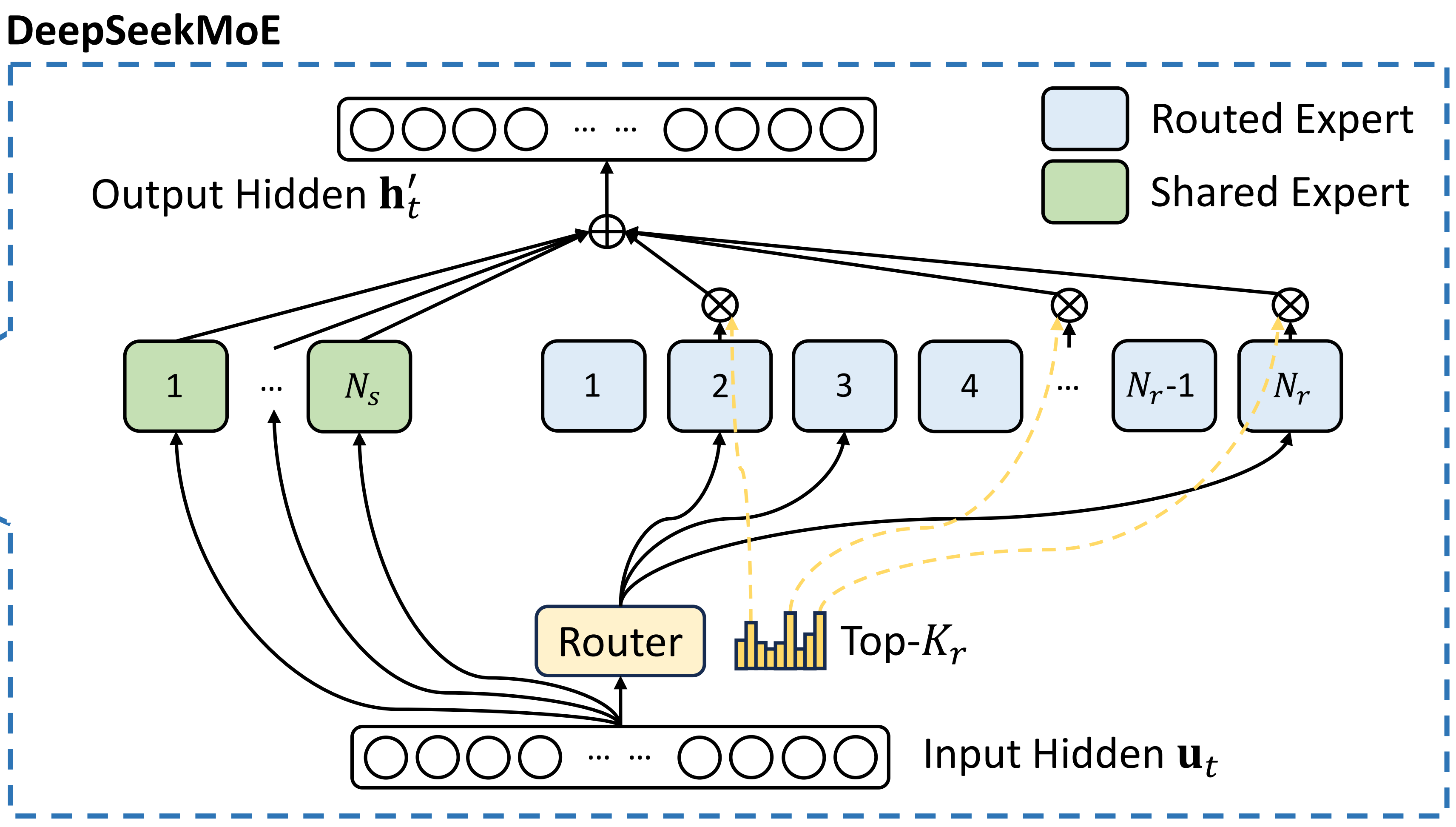
DeepSeekMoE有两个关键理念:
- 将专家细分为更细的粒度以实现更高的专家专业化和更准确的知识获取
- 隔离一些共享专家以减轻路由专家之间的知识冗余
最终,在激活和总专家参数数量相同的情况下,DeepSeekMoE 可以大幅超越传统的 MoE 架构
设
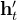
其中
和
分别表示共享专家和路由专家的数量
和
分别表示第
表示激活的路由专家数量
是token到专家的亲和度
是这一层中第
- 而
对于DeepSeek-V2,除了简单的top-K路由专家选择外,其还确保每个token的目标专家最多分布在 𝑀个设备上。 具体来说,对于每个token,我们首先选择 𝑀个设备,这些设备中有专家具有最高的亲和分数
然后,在这些 𝑀个设备上的专家中进行top-K选择。 在实践中,我们发现当 𝑀 ⩾3 时,设备限制路由可以实现与不受限制的 top-K 路由大致一致的良好性能
2.3.2 负载均衡的辅助损失(Auxiliary Loss for Load Balance)
首先,不平衡的负载会增加路由崩溃的风险,防止某些专家得到充分的训练和利用。 其次,当采用专家并行时,不平衡的负载会降低计算效率
故在 DeepSeek-V2 的训练过程中,设计了三种辅助损失,分别用于控制专家级负载均衡
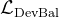
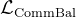
- 专家级均衡损失
- 设备级平衡损失
- 通信平衡损失
此外,虽然平衡损失旨在鼓励负载平衡,但需要承认它们不能保证严格的负载平衡
为了进一步减轻由于负载不平衡导致的计算浪费,他们在训练期间引入了设备级的Token-Dropping策略
- 这种方法首先计算每个设备的平均计算预算,这意味着每个设备的容量因子相当于1.0
- 然后,受Riquelme等人的启发,在每个设备上丢弃具有最低亲和力分数的token,直到达到计算预算
- 此外,确保大约10%的训练序列中的token永远不会被丢弃。 通过这种方式,可以根据效率要求灵活决定在推理过程中是否丢弃标记,并始终确保训练和推理之间的一致性
第三部分 DeepSeek-V2的预训练与对齐
3.1 预训练(含数据构建与参数设置)、长度扩展、训练和推理效率
为提高其性能,他们构建了一个高质量的多源预训练语料库,包括8.1T的token,与DeepSeek 67B使用的语料库相比,该语料库的数据量有所增加,特别是中文数据,并且数据质量更高
且其采用与DeepSeek 67B相同的分词器,该分词器基于字节级字节对编码(BBPE)算法构建,词汇量为100K,其分词预训练语料库包含8.1T个token,其中中文token比英文标记多约12%
3.1.1 模型超参数
对于模型超参数,将Transformer层数设置为60,隐藏维度设置为5120。 所有可学习参数均以标准差0.006随机初始化
在MLA中
- 将注意力头的数量
设置为128
- 每头维度
设置为128
- KV压缩维度
查询压缩维度
对于解耦查询和键,设置每头维度
上述3个数据的设置,其实也刚好呼应了上文2.2节最后说的
“在DeepSeek-V2中,
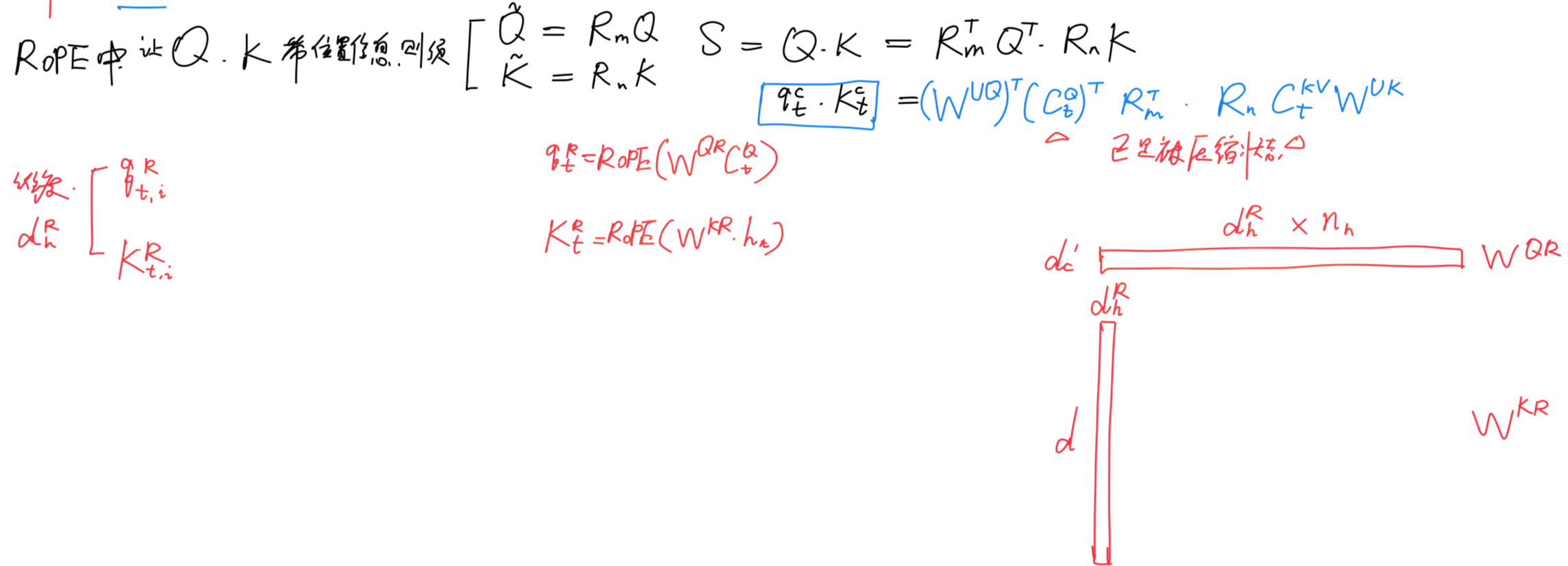
在DeepSeekMoE中,按照Dai等人的做法
- 将除第一层外的所有前馈神经网络替换为专家混合层
每个专家混合层由2个共享专家和160个路由专家组成,每个专家的中间隐藏维度为1536 - 在这些路由专家中,每个token将激活6个专家
此外,低秩压缩和细粒度专家分割将影响层的输出规模 - 因此,在实践中,在压缩的潜在向量之后使用额外的RMS Norm层,并在宽度瓶颈处(即压缩的潜在向量和路由专家的中间隐藏状态)乘以额外的缩放因子,以确保训练的稳定性
在这种配置下,DeepSeek-V2总参数量为236B,其中每个token激活21B
3.1.2 训练超参数
以下是论文中所述的训练超参数设置
- 使用AdamW优化器(Loshchilov和Hutter,2017),超参数设置为 𝛽1 = 0.9, 𝛽2 =0.95,权重衰减 =0.1
- 学习率使用预热和阶梯衰减策略进行调度(DeepSeek-AI,2024)
最初,学习率在前2K步期间从0线性增加到最大值。
随后,在训练约60%的token后,学习率乘以0.316,并在训练约90%的token后再次乘以0.316
其中,最大学习率设置为2.4 × 10−4,梯度裁剪范数设置为1.0 - 还使用批量大小调度策略,在前225B token的训练中,批量大小从2304逐渐增加到9216,然后在剩余的训练中保持9216
- 将最大序列长度设置为4K,并在8.1T个tokens上训练DeepSeek-V2
- 利用流水线并行技术在不同设备上部署模型的不同层,对于每一层,路由的专家将均匀部署在8个设备上 (𝐷 =8)
至于设备限制路由,每个token最多会被发送到3个设备上 (𝑀 =3)。 关于平衡损失,我们将 𝛼1设置为0.003, 𝛼2设置为0.05, 𝛼3设置为0.02 - 在训练期间采用Token-Dropping策略以加速,但在评估时不丢弃任何token
此外,DeepSeek-V2基于HAI-LLM框架(High-flyer, 2023)进行训练,这是高效且轻量的训练框架
- 它采用了16路零气泡流水线并行(Qi等,2023),8路专家并行(Lepikhin等,2021),以及ZeRO-1数据并行(Rajbhandari等,2020)
- 鉴于DeepSeek-V2激活的参数相对较少,并且部分操作符会重新计算以节省激活内存,因此可以在不需要张量并行的情况下进行训练,从而减少通信开销
- 此外,为了进一步提高训练效率,我们将共享专家的计算与专家并行的全对全通信重叠
- 且还为通信、路由算法和融合定制了更快的CUDA内核
以及还基于改进版的 FlashAttention-2 (Dao, 2023) 进行了优化
最终,他们在配备 NVIDIA H800 GPU 的集群上进行所有实验。H800 集群中的每个节点包含 8 个GPU,这些 GPU 在节点内使用 NVLink 和 NVSwitch 连接。 在节点之间,使用 InfiniBand 互连来促进通信
3.1.3 长上下文扩展
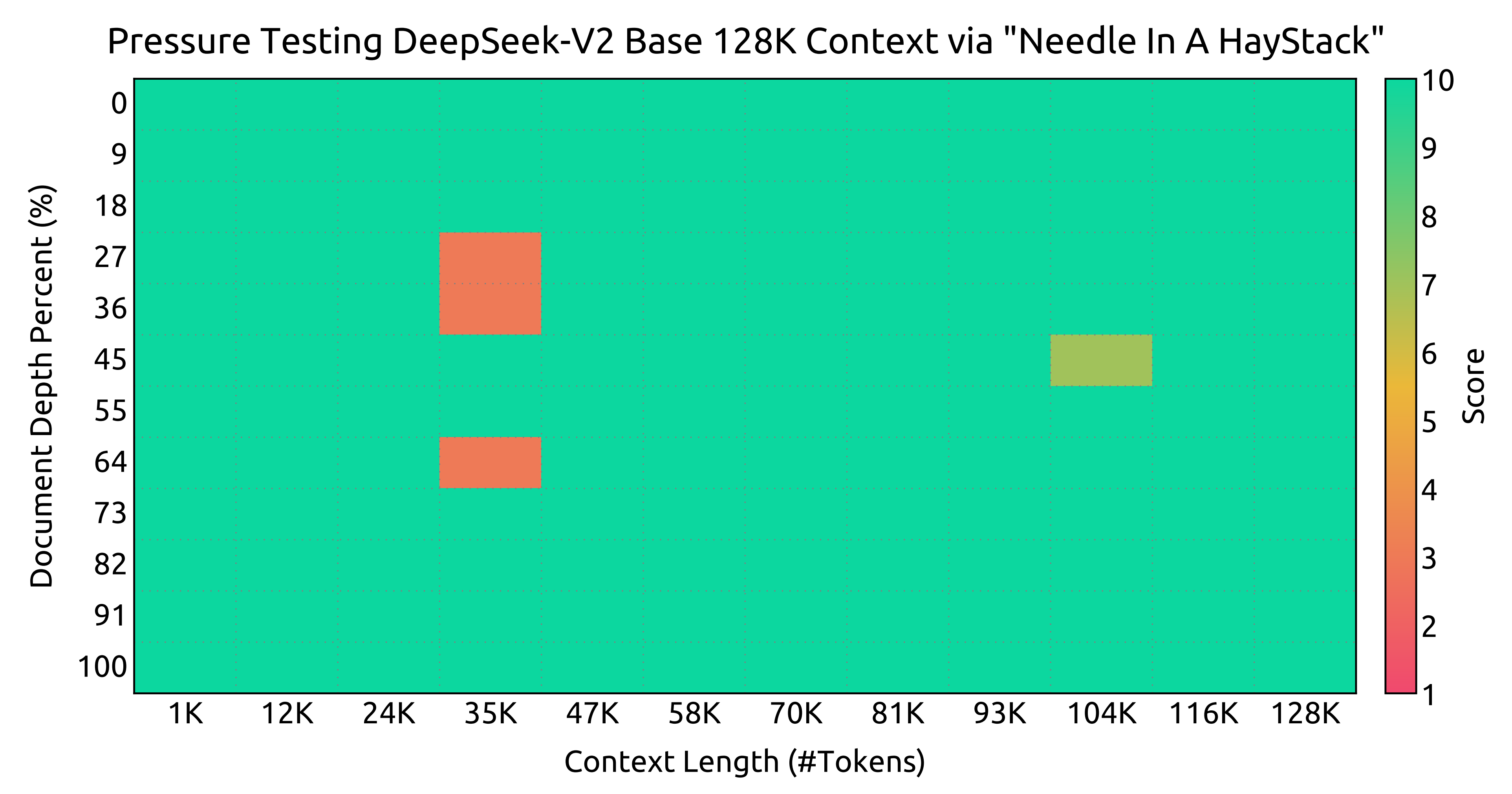
在 DeepSeek-V2 的初始预训练之后,他们采用 YaRN「关于YaRN,详见此文《大模型长度扩展综述:从直接外推ALiBi、插值PI、NTK-aware插值(对此介绍最详)、YaRN到S2-Attention》的第四部分」将默认上下文窗口长度从 4K 扩展到 128K
- YaRN 专门应用于解耦的共享key
YaRN was specifically applied to the decoupled shared key k𝑅𝑡 as it is responsible for carrying RoPE - 对于 YaRN,将比例scale
设置为 40,
设置为 1,
另由于 DeepSeek-V2独特的注意力机制——MLA,与原始 YaRN 略有不同,故调整了长度缩放因子以调节注意力熵。 因子

且另外训练了模型 1000 步,序列长度为 32K,批量大小为 576 个序列。 尽管训练仅在32K的序列长度下进行,但在128K的上下文长度下评估时,该模型仍表现出强大的性能
如下图所示,“大海捞针”(NIAH)测试的结果表明,DeepSeek-V2在所有上下文窗口长度(最长至128K)上表现良好
3.1.4 训练和推理效率
如论文中所说
在训练成本上
- 由于 DeepSeek-V2 对每个 token 激活的参数较少且所需的 FLOPs 少于 DeepSeek 67B,理论上训练 DeepSeek-V2 将比训练 DeepSeek 67B 更经济
- 尽管训练一个 MoE 模型会引入额外的通信开销,但通过相应的操作和通信优化,DeepSeek-V2 的训练可以达到相对较高的模型 FLOPs 利用率 (MFU)
- 在对 H800 集群的实际训练中,每训练一万亿个 token,DeepSeek 67B 需要 300.6K GPU 小时,而 DeepSeek-V2 仅需 172.8K GPU 小时,即稀疏的 DeepSeek-V2 比密集的 DeepSeek 67B 节省了 42.5% 的训练成本
在推理效率上
- 为了高效地部署DeepSeek-V2服务,首先将其参数转换为FP8精度。此外,我们还对DeepSeek-V2进行KV缓存量化(Hooper等,2024;赵等,2023),以进一步将其KV缓存中的每个元素平均压缩到6位
得益于MLA和这些优化,实际部署的DeepSeek-V2所需的KV缓存显著少于DeepSeek 67B,因此可以服务更大的批处理大小 - 基于实际部署的DeepSeek 67B服务的提示和生成长度分布评估了DeepSeek-V2的生成吞吐量
在单个节点上配备8个H800 GPU,DeepSeek-V2实现了超过每秒50K个token的生成吞吐量,是DeepSeek 67B最大生成吞吐量的5.76倍
此外,DeepSeek-V2 的提示输入吞吐量超过每秒 100K 个token
3.2 对齐:监督微调与强化学习
3.2.1 DeepSeek-V2的一些微调、评估细节
基于之前DeepSeek-AI,他们整理了包含 150 万实例的指令微调数据集,其中包括 120 万个有用性实例和 30 万个安全性实例
与初始版本相比,改进了数据质量,以减少幻觉反应并提高写作能力且对 DeepSeek-V2 进行了 2 个周期的微调,学习率设置为 5 × 10−6
为了评估 DeepSeek-V2 Chat(SFT)
- 主要包括基于生成的基准测试,除了几个具有代表性的多项选择任务(MMLU 和 ARC)
- 且还对 DeepSeek-V2 Chat(SFT)进行了指令跟随评估(IFEval),使用提示级松散准确率作为指标
- 此外,我们使用2023年9月1日至2024年4月1日期间的LiveCodeBench (Jain et al., 2024)问题来评估聊天模型
- 除了标准基准测试外,还在开放式对话基准测试中评估了模型,包括MT-Bench (Zheng et al., 2023)、AlpacaEval 2.0 (Dubois et al., 2024)和AlignBench (Liu et al., 2023)
3.2.2 DeepSeek-V2通过GRPO训练策略模型
为了进一步释放DeepSeek-V2的潜力并使其与人类偏好对齐,进行强化学习(RL)以调整其偏好,且为了节省强化学习的训练成本,采用了上文第一部分介绍过的GRPO
具体来说,对于每个问题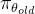
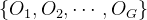
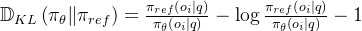
其中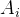
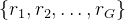

在具体的训练策略上,采用了两阶段的强化学习训练策略,首先进行推理对齐,然后进行人类偏好对齐
- 在第一个推理对齐阶段,我们训练了一个奖励模型
用于代码和数学推理任务,并通过
- 在第二个人类偏好对齐阶段,采用了一个多奖励框架,即
一个有帮助的奖励模型
一个安全奖励模型
一个基于规则的奖励模型获取奖励
从而一个响应的最终奖励 𝑜𝑖是
其中 𝑐1, 𝑐2, 和 𝑐3是相应的系数

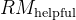
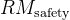
更多,可以参见原论文