前言
我在网上搜索ELK安装教程学习部署的时候,发现网上的教程都比较零散,没有一份系统完整的教程,且大部分安装和配置方法都比较老旧,新版的ELK组件的安装明明都变得很简单方便了,如果还像以前那样,又要配置这个,又要配置那个,又要装这个又要装那个的,明显都不对也不合适,官方已经让工作变得简单,为什么还要被以前的安装思路把问题弄得复杂化?网上的教程很少提到安全相关的配置,在网络安全越注重的今天,安全配置也不容忽视,不要为了方便而把安全有关的东西都禁掉。同时许多的网上教程都是在线自动安装的,对于我们这些不通网的孩子来说,简直就是两眼一抓瞎,还有等等许多问题……于是就有了整理一篇完整且详细的教程的想法,本篇教程是我学习了解ELK部署安装过程时的一份记录,本篇教程尽量写得详细且通俗易懂,所以篇幅会比较长,认真看完能让像我这样的小白都能搭建起来那就是最好的啦。
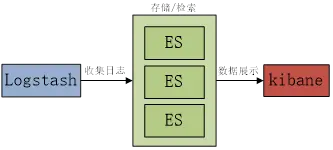
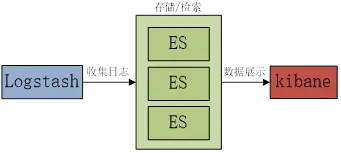
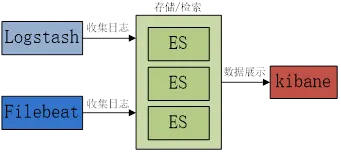
ELK日志收集管理系统是由Elasticsearch(简称:ES)、Logstash和Kibana三部分组件组成的一个日志收集系统。
Elasticsearch:ELK中最核心的是E(elasticsearch,简称:ES),我们可以从单词上理解翻译过来就是“弹性搜索”。提供搜索、分析、存储数据三大功能,特点稳定,可靠,快速(弹性)。
Logstash:一个具有实时流水线功能的开源数据收集引擎。Logstash 可以动态地统一来自不同来源的数据,并将数据规范化到您选择的目的地。为各种高级下游分析和可视化用例清理和普及所有数据,简单理解的话就是用来收集日志log的。
Kibana:ELK日志分析系统非常友好的 Web 界面,可以帮助我们搜索、观察、保护数据、分析数据、管理、监控和保护 Elastic Stack( Elasticsearch、Kibana、Beats 和 Logstash等组合在一起的统称)。
部署架构介绍
本次部署使用4台服务器进行演示操作,其中3台服务器用来部署ES集群,1台服务器用来部署Logstash和Kibana。ES集群用3台是因为后面我有安装kafka集群的操作,且因实际业务使用时集群数量为奇数为宜。如果你只是简单搭建了解,那么用2台做ES甚至只用1台服务器安装完所有ELK组件也是没问题的(在现实中只用1台服务器部署完所有ELK组件来使用的也有)。
文章前半部分讲解ELK基本的架构搭建:
文章后半部分会讲解ELK升级版的架构搭建:
操作系统方面,因为Centos系统已经停止更新服务,因安全要求为替代Centos操作系统,我选择CentosStream系统部署ELK。

目录
(一)基础:部署ELK基本架构
一、准备工作
二、安装ES(Elasticsearch)
三、使用ES-head插件
四、安装Kibana
五、Kibana开启https访问
六、Kibana配置ES监控和管理
七、安装Logstash收集日志
八、安装Filebeat收集日志
(二)进阶:使用Kafka作为日志消息缓存
一、安装JDK
二、安装Zookeeper
三、安装Kafka
四、使用logstash将Kafka日志发送到ES
五、配置Logstash发送日志到Kafka
六、配置Filebeat发送日志到Kafka
(三)ELK安全和防火墙配置
一、ELK系统防火墙安全配置
二、Kibana服务器系统防火墙安全配置
(四)ELK其他配置或指导
一、ES修改默认分片和副本数
二、ES启动锁定JVM内存配置
三、多Logstash配置启动和关闭Logstash方法
四、日志收集配置文件示例
1、防火墙、交换机、应用系统等514端口日志收集范例
2、filebeat收集nginx、tomcat日志范例
3、filebeat收集nginx拆分access和error日志范例
4、filebeat使用modules收集nginx日志范例
5、filebeat收集nginx和tomcat日志转json格式范例
6、filebeat收集多行日志(例如:java)范例
7、filebeat收集日志发送至Redis缓存范例
8、Logstash收集日志发送至Redis缓存范例
9、Logstash从Redis缓存发送日志到ES范例
(一)基础:部署ELK基本架构
一、准备工作
1、下载安装包,本次操作使用的操作系统为CentosStream8,ELK版本为当前(2022年8月27日)的最新版本8.4.0版本,后续还介绍了ELK+kafka搭建的日志架构,所以也用的当前最新的kafka版本。ELK是个版本更新狂魔,版本更新很快,不知道当你看到这篇文章的时候会更新到哪个版本了,希望也能给你做个参考。
用到的安装包下载地址为:
CentosStream8操作系统下载地址为:
https://mirrors.tuna.tsinghua.edu.cn/centos/8-stream/isos/x86_64/
ELK组件下载地址:(我下载的8.4版本)
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.4.0-x86_64.rpm
https://artifacts.elastic.co/downloads/logstash/logstash-8.4.0-x86_64.rpm
https://artifacts.elastic.co/downloads/kibana/kibana-8.4.0-x86_64.rpm
https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.4.0-x86_64.rpm
kafka和zookeeper下载地址:(我下载的kafka3.2.1,zookeeper3.8.0版本)
https://kafka.apache.org/downloads
https://archive.apache.org/dist/zookeeper/
java下载地址:(官网下载要登录,我用的jdk-8u311版本)
https://www.oracle.com/java/technologies/downloads/#java8
华为云的java也可以
https://repo.huaweicloud.com/java/jdk/
如今新版本的ELK不需要安装jdk环境了,这个Java是安装Kafka的时候才用到的。我所有的安装包我已经打包好放在百度网盘,可以自行选择下载。
百度网盘(自带提取码):https://pan.baidu.com/s/1JBlp9zk5GFtqWlCWSgbJ7Q?pwd=fhb6
2、我的服务器IP分配如下:
ES1:192.168.50.11
ES2:192.168.50.12
ES3:192.168.50.13
Logstash+Kibana:192.168.50.14
3、安装操作系统。本次安装CentosStream8系统使用最小化安装(尽量精简也是为了安全),安装过程略(毕竟这篇文章不是教怎么装系统的,只是交代一下ELK部署安装环境)。安装完后配置网卡IP,使用SSH远程连接工具连接上系统。
4、创建目录,使用SFTP工具上传部署安装包至该目录下,3台ES服务器都同样操作上传(文件上传步骤略,传文件到服务器目录大家应该都会的吧?)。
[root@localhost ~]# mkdir /opt/soft/
[root@localhost ~]# cd /opt/soft
[root@localhost soft]# ls

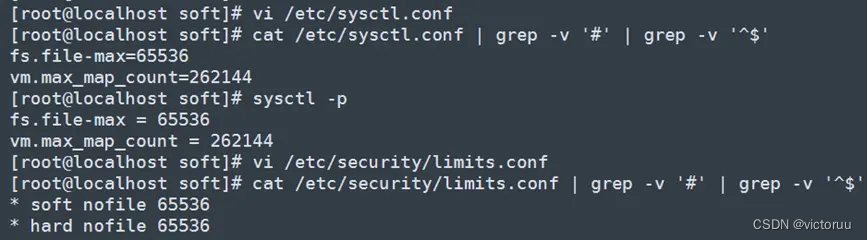
5、修改系统内核和资源参数,为ES集群做准备,在sysctl.conf和limits.conf文件的最后添加如下两个参数,ES的3台服务器都时同样操作修改,装kibana的服务器可以不改。
[root@localhost soft]# vi /etc/sysctl.conf
[root@localhost soft]# cat /etc/sysctl.conf | grep -v '#' | grep -v '^$'
fs.file-max=65536
vm.max_map_count=262144
[root@localhost soft]# sysctl –p //修改后重新加载
[root@localhost soft]# vi /etc/security/limits.conf
[root@localhost soft]# cat /etc/security/limits.conf | grep -v '#' | grep -v '^$'
* soft nofile 65536
* hard nofile 65536
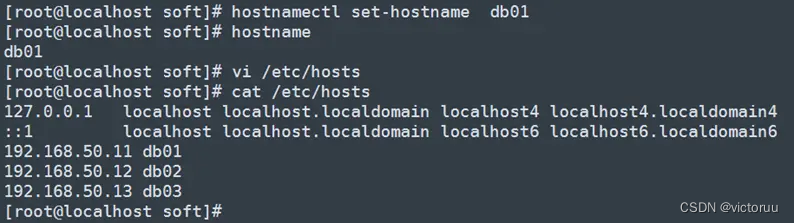
6、修改系统主机名并配置host文件,注意ES三台的名称不一样。
[root@localhost soft]# hostnamectl set-hostname db01 //相应的其他设置为db02、db03
[root@localhost soft]# vi /etc/hosts
[root@localhost soft]# cat /etc/hosts //3台ES的hosts文件一样
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.50.11 db01
192.168.50.12 db02
192.168.50.13 db03
第2台ES主机名为db02

第3台ES主机名为db03

修改完主机名后不会立刻显示更改的主机名,退出账户重新登录或重新远程连接服务器(重启系统也可以,你喜欢就好)就可以显示新的主机名了。
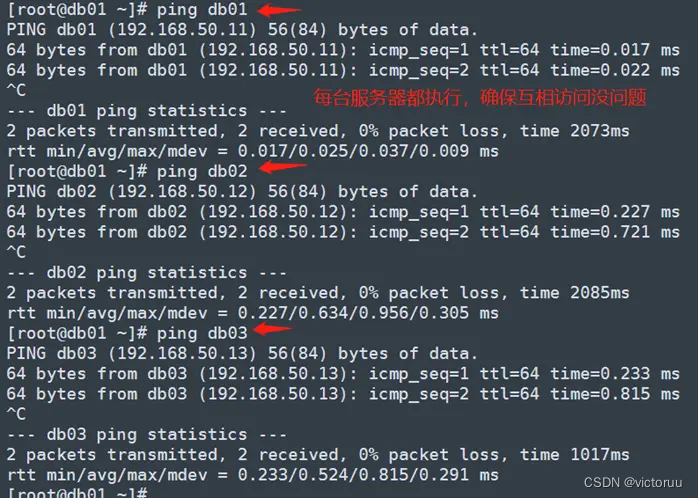
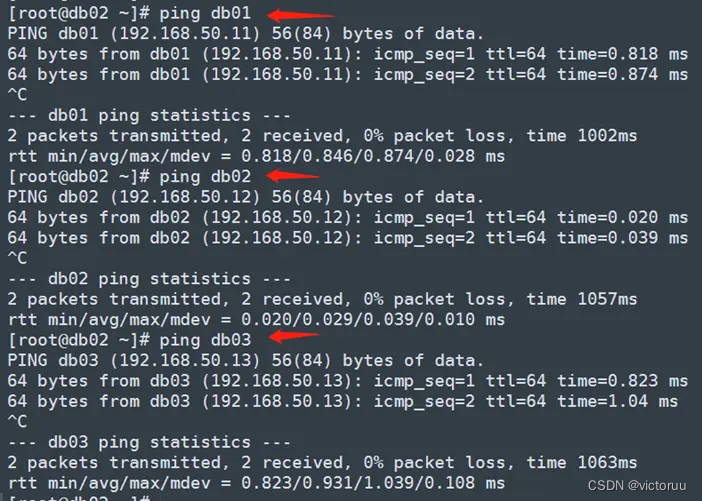
Ping一下主机名,确认主机名可以互相访问即可,3台服务器,每台服务器都要互ping一遍,确保网络没问题。
[root@db01 ~]# ping db01
[root@db01 ~]# ping db02
[root@db01 ~]# ping db03
[root@db02 ~]# ping db01
[root@db02 ~]# ping db02
[root@db02 ~]# ping db03
[root@db03 ~]# ping db01
[root@db03 ~]# ping db02
[root@db03 ~]# ping db03
二、安装ES(Elasticsearch)
1、进入安装包目录,执行安装。(说明:新版本的ELK自带java,不需要再安装jdk环境了)
3台ES服务器都同时进行如下安装操作,安装命令如下:
[root@db01 ~]# cd /opt/soft/
[root@db01 soft]# rpm -ivh elasticsearch-8.4.0-x86_64.rpm
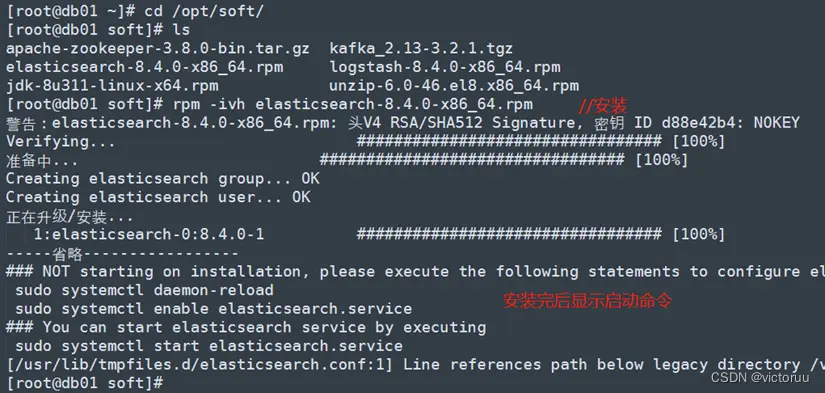
db02的安装,db03也同样进行安装。
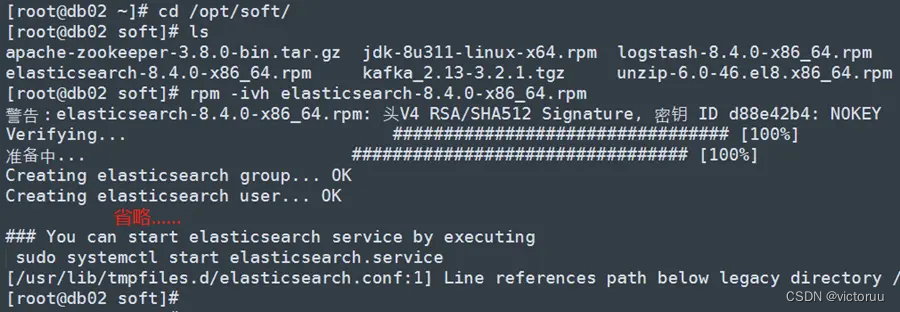
创建ES的数据存放目录并授权限,3台服务器都是同样操作。
[root@db01 soft]# mkdir -p /data/elasticsearch
[root@db01 soft]# chown -R elasticsearch:elasticsearch /data/elasticsearch/

db02和db03同上面db01创建目录并授权,我这里就不写步骤了。
2、更改ES配置文件。
(注意现在只操作db01,不操作配置db02和03,注意现在只操作db01,不操作配置db02和03,注意现在只操作db01,不操作配置db02和03)
修改db01的ES配置文件并启动db01的ES,配置文件的内容如下:
[root@db01 soft]# vi /etc/elasticsearch/elasticsearch.yml
[root@db01 soft]# cat /etc/elasticsearch/elasticsearch.yml | grep -v '#' | grep -v '^$'
cluster.name: ELK
node.name: db01
path.data: /data/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 192.168.50.11
discovery.seed_hosts: ["192.168.50.11", "192.168.50.12", "192.168.50.13"]
xpack.security.enabled: true
xpack.security.enrollment.enabled: true
xpack.security.http.ssl:
enabled: true
keystore.path: certs/http.p12
xpack.security.transport.ssl:
enabled: true
verification_mode: certificate
keystore.path: certs/transport.p12
truststore.path: certs/transport.p12
cluster.initial_master_nodes: ["db01"]
http.host: 0.0.0.0
[root@db01 soft]# systemctl start elasticsearch.service
[root@db01 soft]# systemctl status elasticsearch.service
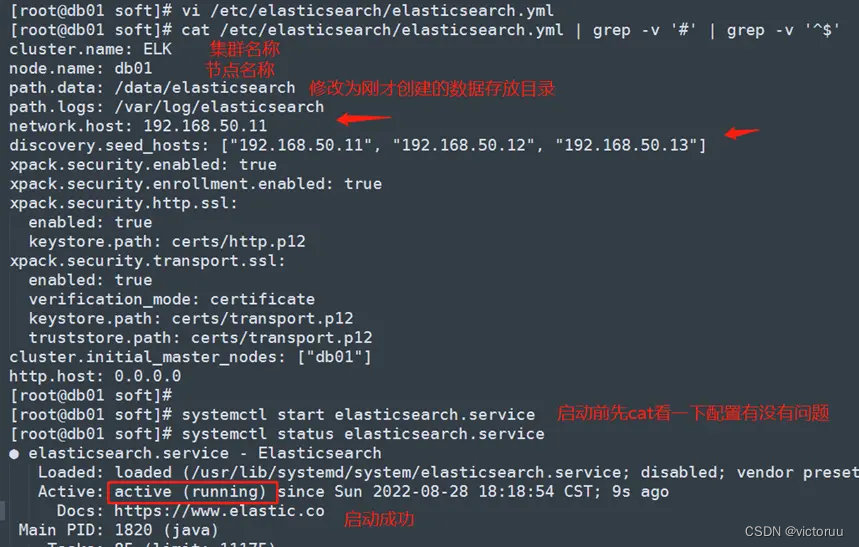
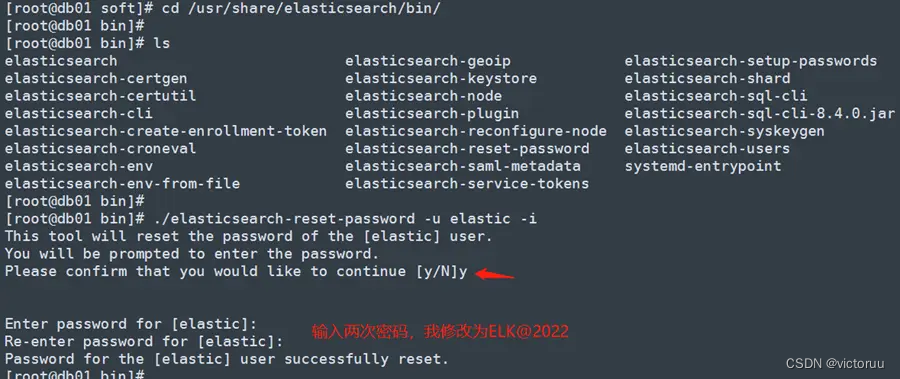
3、修改ES账户密码,并创建db02和db03加入集群的token。
安装好ES的时候会默认给elastic账户创建一个高复杂度的随机密码,这个密码生成在安装日志文件里,不过我们不需要知道密码是什么,我们直接更改elastic 账户的密码就好了,我这里重置的密码为ELK@2022。
[root@db01 soft]# cd /usr/share/elasticsearch/bin/
[root@db01 bin]# ./elasticsearch-reset-password -u elastic -i
在db01上创建db02和db03加入ES集群的token。
[root@db01 bin]# /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s node
eyJ2ZXIiOiI4LjQuMCIsImFkciI6WyIxOTIuMTY4LjUwLjExOjkyMDAiXSwiZmdyIjoiOTg3NWM4MzhjZjI1YzA4OGNhNTMwOTI3ZWMzM2JkZWM3MTgyOTg3YzZlNzRkOWVhY2VmMjk4ZmVkYzM5MGUyNyIsImtleSI6ImpMTUY1SUlCeURXYnJKOW5FWDAxOmlmdlh0NXVTUzVHRE1lTlRtcUlZUGcifQ== 作者:又菜又爱玩的张小剑 https://www.bilibili.com/read/cv19834484/ 出处:bilibili

4、在db02和db03上导入刚才db01生成的token,命令后面带着token,这一长串token值不要有回车什么的中断,导入过程输入“y”确认导入。
[root@db02 soft]# /usr/share/elasticsearch/bin/elasticsearch-reconfigure-node --enrollment-token eyJ2ZXIiOiI4LjQuMCIsImFkciI6WyIxOTIuMTY4LjUwLjExOjkyMDAiXSwiZmdyIjoiOTg3NWM4MzhjZjI1YzA4OGNhNTMwOTI3ZWMzM2JkZWM3MTgyOTg3YzZlNzRkOWVhY2VmMjk4ZmVkYzM5MGUyNyIsImtleSI6ImpMTUY1SUlCeURXYnJKOW5FWDAxOmlmdlh0NXVTUzVHRE1lTlRtcUlZUGcifQ==

db03同db02一样导入token。

5、修改db02和db03的ES配置文件,并启动ES。
[root@db02 soft]# vi /etc/elasticsearch/elasticsearch.yml
[root@db02 soft]# cat /etc/elasticsearch/elasticsearch.yml | grep -v '#' | grep -v '^$'
cluster.name: ELK
node.name: db02
path.data: /data/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 192.68.50.12
discovery.seed_hosts: ["192.168.50.11", "192.168.50.12", "192.168.50.13"]
cluster.initial_master_nodes: ["db01"]
xpack.security.enabled: true
xpack.security.enrollment.enabled: true
xpack.security.http.ssl:
enabled: true
keystore.path: certs/http.p12
xpack.security.transport.ssl:
enabled: true
verification_mode: certificate
keystore.path: certs/transport.p12
truststore.path: certs/transport.p12
http.host: 0.0.0.0
transport.host: 0.0.0.0
[root@db02 soft]# systemctl start elasticsearch.service
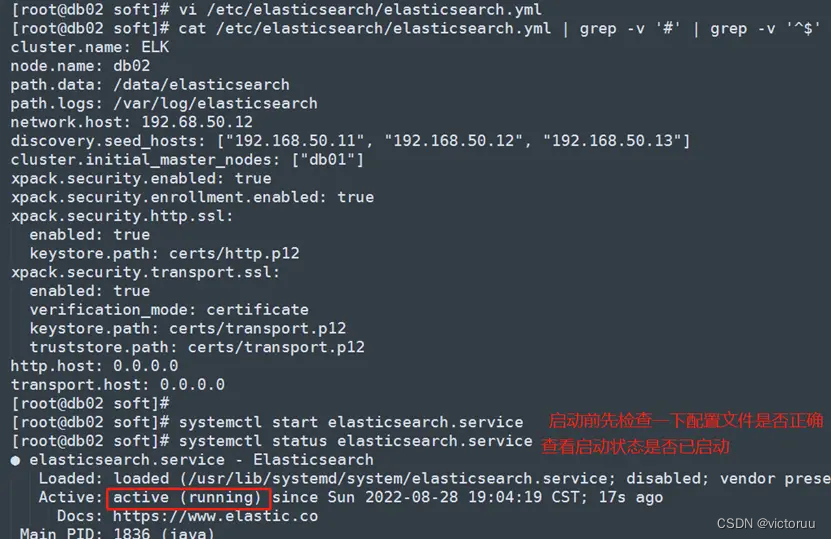
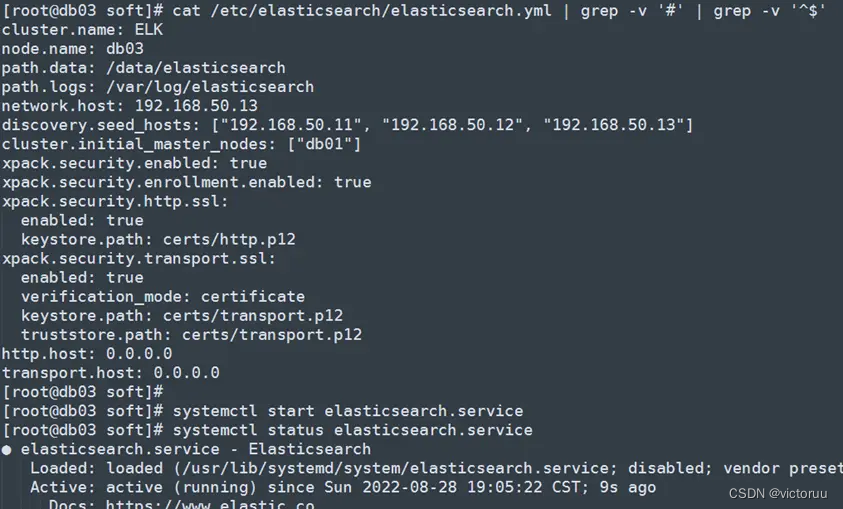
db03的配置文件如下,修改后启动ES:
6、检查ES集群状态。现在3台ES服务器已经安装完成,也都成功启动了ES,现在可以访问一下我们的ES服务看看是否已经开起来了。
浏览器打开地址(注意是https):https://192.168.50.11:9200,输入用户名:elastic和我们修改的密码:ELK@2022进行登录
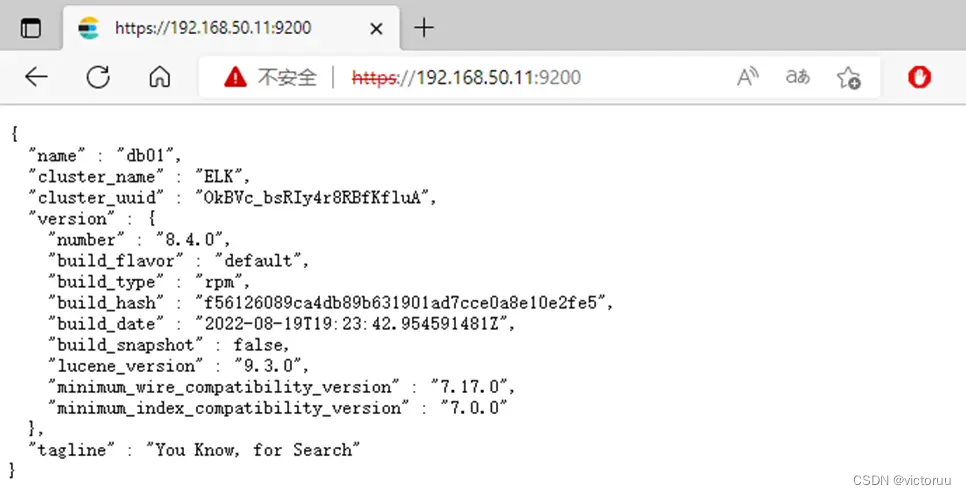
登录成功后显示ES集群和版本等信息,另外两台服务器地址也都可以登录。
我们的ES确认都能正常访问后,可以在服务器上给ES加上开机启动,3台都设置开机启动。
[root@db01 bin]# systemctl enable elasticsearch.service

启动ES:systemctl start elasticsearch .service
停止ES:systemctl stop elasticsearch .service
查看ES状态:systemctl status elasticsearch .service
设置ES开机启动:systemctl enable elasticsearch .service
三、使用ES-head插件
1、使用ES-head插件管理ES集群。
ES集群搭建好了,管理ES集群和数据可以通过命令的方式进行管理操作,但是使用命令明显记不住那么多命令且也非常不方便,我们管理ES集群服务器一般都会使用ES-head插件实现图形化的界面来进行管理操作,接下来介绍三种安装es-head插件的方式。
(1)、npm安装:下载源码,编译安装,在nodejs环境下运行插件(需要连网且国外源码地址下载速度慢,经常下载失败)
(2)、docker安装:下载已经做好的es-head插件的容器,运行(安装操作相较复杂)
(3)、Google浏览器插件:安装Google浏览器插件,直接访问es(简单快捷,浏览器插件直接打开,可以说是免安装)
显而易见,我这里示范的选第三种,直接使用Google浏览器的es-head插件。这个插件是Google浏览器上的,所以要使用谷歌Chrome浏览器,然后在Google的Chrome Web Store搜索此插件进行安装即可,但是在国内貌似是打不开谷歌商店的。没关系,我找到了别人打包好的插件包,直接把插件包导入浏览器也是可以用的。这个插件包文件跟安装包一起放在百度网盘中,可自行下载:百度网盘(自带提取码):https://pan.baidu.com/s/1JBlp9zk5GFtqWlCWSgbJ7Q?pwd=fhb6
我没有谷歌浏览器,但是win10自带的新版的Edge浏览器是基于谷歌Chrome浏览器同一个内核的,所以Edge浏览器可以导入使用此插件(别的浏览器我没试过,不懂有没有导入选项),插件包导入方式如下:
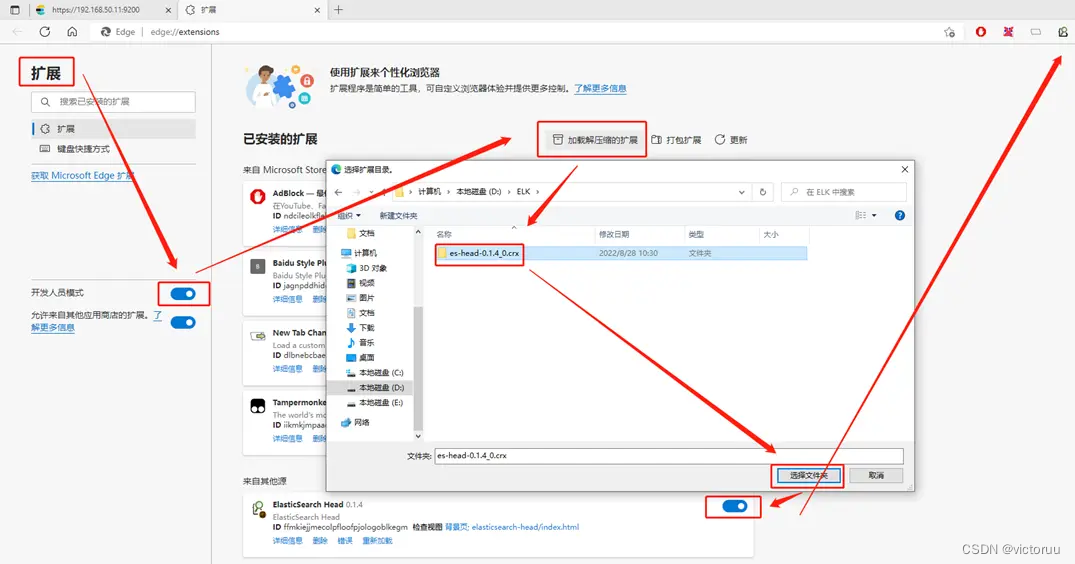
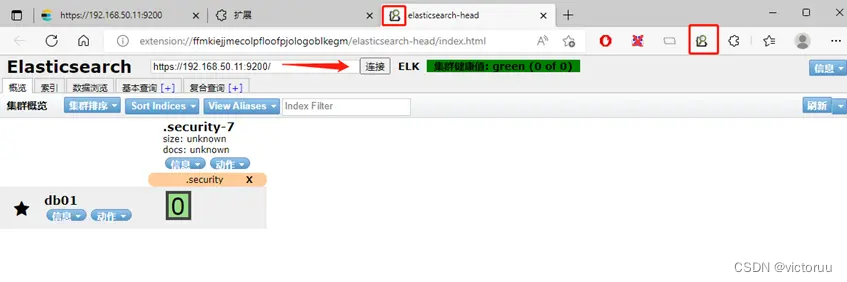
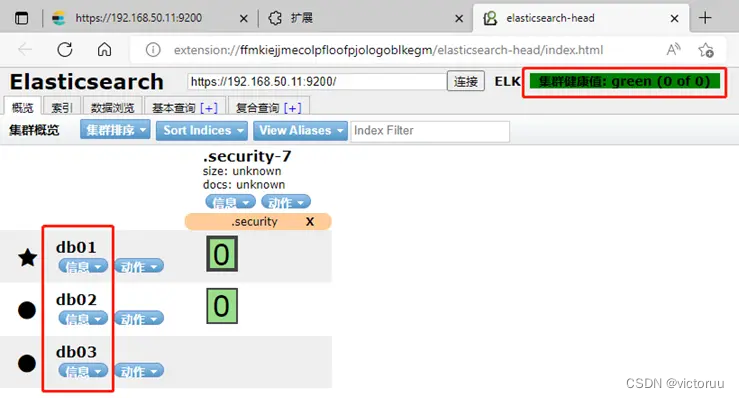
导入成功后,点击左上角插件,输入https://192.168.50.11:9200集群地址,输入账户密码登录。就可以看到我们的集群状态和3个节点(里面的索引、数据浏览、查询什么的功能这里不做介绍)。
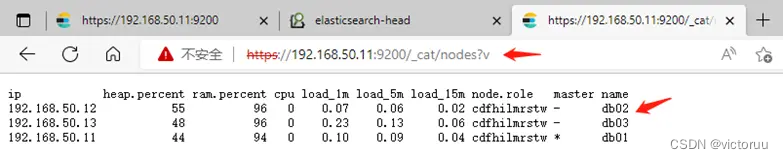
2、如果你装不上es-head插件,也没有浏览器插件包,不要悲伤,还可以用命令去执行操作。比如:输入地址:https://192.168.50.11:9200/_cat/nodes?v
列几个命令参数给你玩一下(命令方式确实没有直接使用es-head插件方便)。
/_cat/nodes?v #查看节点信息
/_cat/health?v #查看集群当前状态:红、黄、绿
/_cat/shards?v #查看各shard的详细情况
/_cat/shards/{index}?v #查看指定分片的详细情况
/_cat/master?v #查看master节点信息
/_cat/indices?v #查看集群中所有index的详细信息
/_cat/indices/{index}?v #查看集群中指定index的详细信息
如果你装不上es-head插件,也没有浏览器插件包,又不会那么多命令去执行操作,不要悲伤,我们还可以用Kibana监控和管理ES,没想到吧。下面我们开始安装Kibana。
四、安装Kibana
1、打开需要安装kibana的服务器(192.168.50.14),重命名主机名并上传安装包。
我这里命名为kibana(你命名成什么都行,你理解就好)。
[root@localhost ~]# hostnamectl set-hostname kibana

上传安装包到目录。
[root@kibana ~]# mkdir /opt/soft/
[root@kibana ~]# cd /opt/soft/
[root@kibana soft]# ls

2、安装kibana
如下命令,直接安装。
[root@kibana soft]# rpm -ivh kibana-8.4.0-x86_64.rpm
3、修改kibana配置文件,然后启动kibana
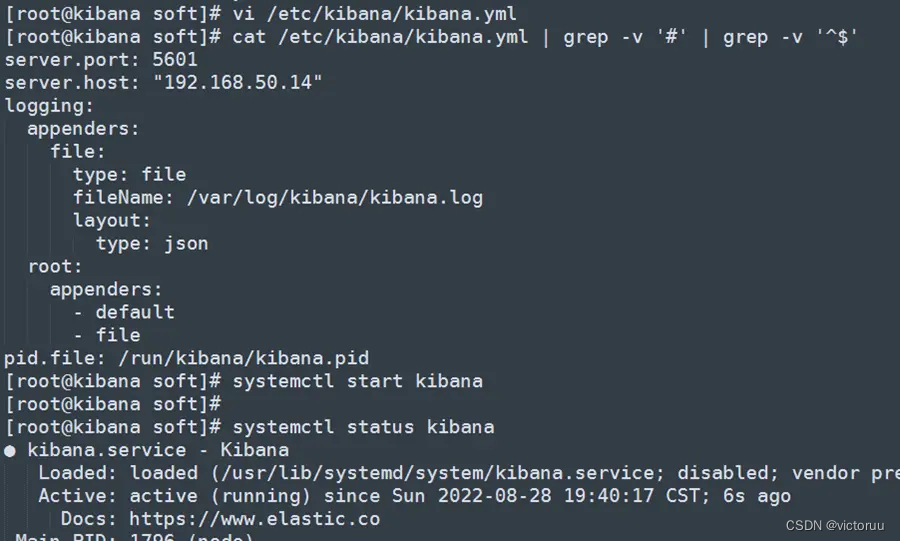
[root@kibana soft]# vi /etc/kibana/kibana.yml
[root@kibana soft]# cat /etc/kibana/kibana.yml | grep -v '#' | grep -v '^$'
server.port: 5601
server.host: "192.168.50.14"
logging:
appenders:
file:
type: file
fileName: /var/log/kibana/kibana.log
layout:
type: json
root:
appenders:
- default
- file
pid.file: /run/kibana/kibana.pid
[root@kibana soft]# systemctl start kibana
[root@kibana soft]# systemctl status kibana
4、启动kibana后查看端口,kibana启动比较慢,可以多等一两分钟。
[root@kibana soft]# ss -tunlp

打开浏览器,登录http://192.168.50.14:5601显示如下界面说明我们的kibana安装和配置没有问题。但因为是http的,所以我们把配置成https先,提高一点安全性。
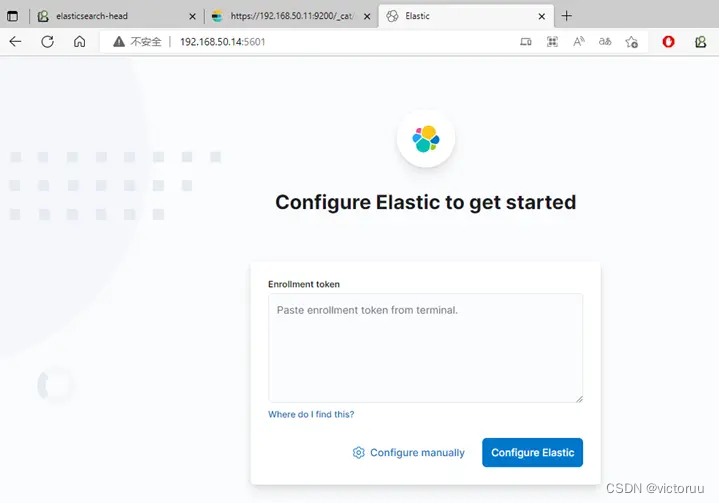
五、Kibana开启https访问
1、在db01上创建https证书和生成kibana的token。
回到db01服务器,生成kibana用的https证书。
[root@db01 ~]# cd /usr/share/elasticsearch/
[root@db01 elasticsearch]# ./bin/elasticsearch-certutil csr -name kibana-server -dns example.com, localhost
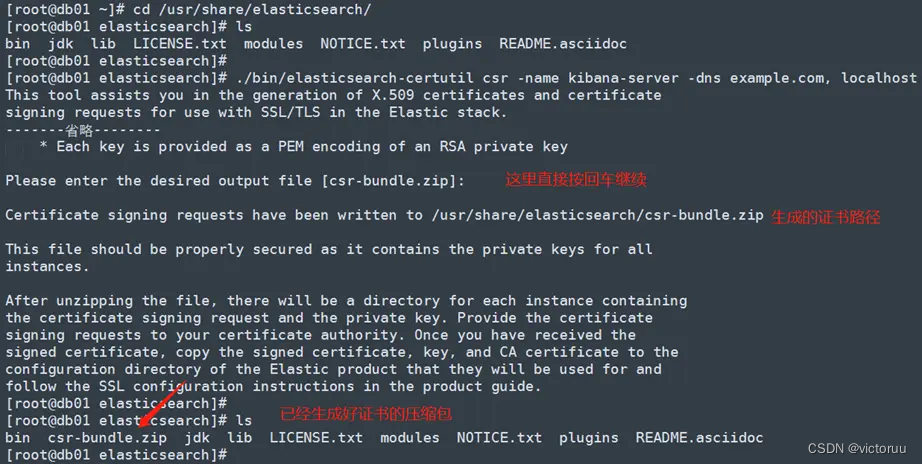
因为是zip的压缩文件,而我的系统是最小化安装的没有解压命令无法直接解压,所以我先装一个unzip的解压软件。如果你的系统有解压命令,可以略过此步骤。
[root@db01 elasticsearch]# rpm -ivh /opt/soft/unzip-6.0-46.el8.x86_64.rpm

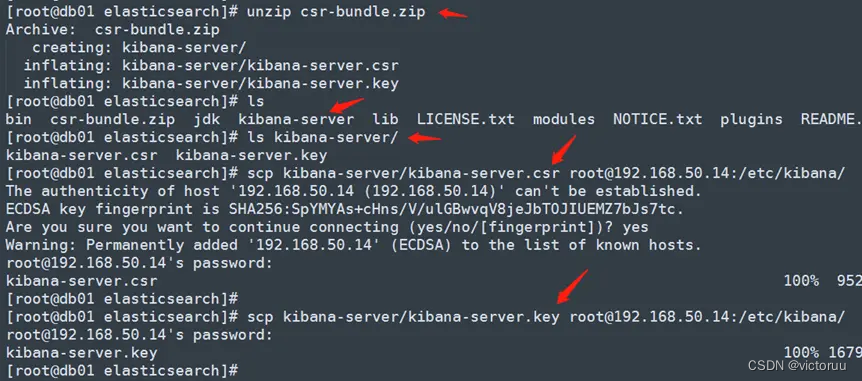
2、解压证书压缩包,并发送证书至kibana服务器的/etc/kibana/目录下。
[root@db01 elasticsearch]# unzip csr-bundle.zip
[root@db01 elasticsearch]# ls kibana-server/
[root@db01 elasticsearch]# scp kibana-server/kibana-server.csr [email protected]:/etc/kibana/
[root@db01 elasticsearch]# scp kibana-server/kibana-server.key [email protected]:/etc/kibana/
3、在db01上生成kibana的token,一会kibana连接ES时用。
[root@db01 elasticsearch]# /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibana
eyJ2ZXIiOiI4LjQuMCIsImFkciI6WyIxOTIuMTY4LjUwLjExOjkyMDAiXSwiZmdyIjoiOTg3NWM4MzhjZjI1YzA4OGNhNTMwOTI3ZWMzM2JkZWM3MTgyOTg3YzZlNzRkOWVhY2VmMjk4ZmVkYzM5MGUyNyIsImtleSI6IkZFU0g1SUlCVDBGT3ExeHpDMTZDOjFES3lfWF9CVF9heUpGMGI0Z0Y5MFEifQ==
4、kibana配置https。
进入/etc/kibana/目录查看从db01复制过来的证书文件,然后导入证书。
[root@kibana soft]# cd /etc/kibana/
[root@kibana kibana]# openssl x509 -req -in kibana-server.csr -signkey kibana-server.key -out kibana-server.crt

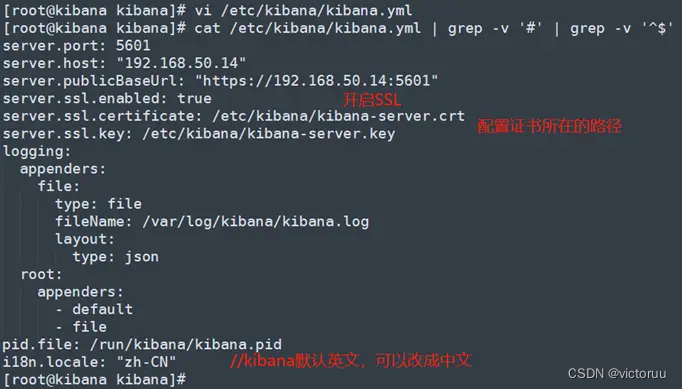
证书导入成功后,编辑kibana的配置文件,开启ssl。
[root@kibana kibana]# vi /etc/kibana/kibana.yml
[root@kibana kibana]# cat /etc/kibana/kibana.yml | grep -v '#' | grep -v '^$'
server.port: 5601
server.host: "192.168.50.14"
server.publicBaseUrl: "https://192.168.50.14:5601"
server.ssl.enabled: true
server.ssl.certificate: /etc/kibana/kibana-server.crt
server.ssl.key: /etc/kibana/kibana-server.key
logging:
appenders:
file:
type: file
fileName: /var/log/kibana/kibana.log
layout:
type: json
root:
appenders:
- default
- file
pid.file: /run/kibana/kibana.pid
i18n.locale: "zh-CN"
配置完成后重启kibana。
[root@kibana kibana]# systemctl stop kibana
[root@kibana kibana]# systemctl start kibana
[root@kibana kibana]# systemctl status kibana
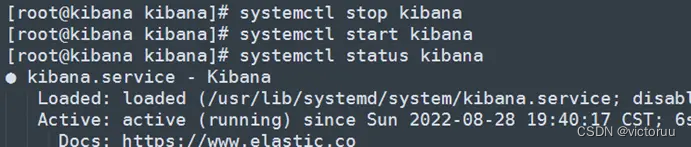
5、kibana连接ES集群
打开kibana页面,此时http已经打不开了,得换成https://192.168.50.14:5601/打开。

输入db01为kibana生成的token,点击配置Elastic
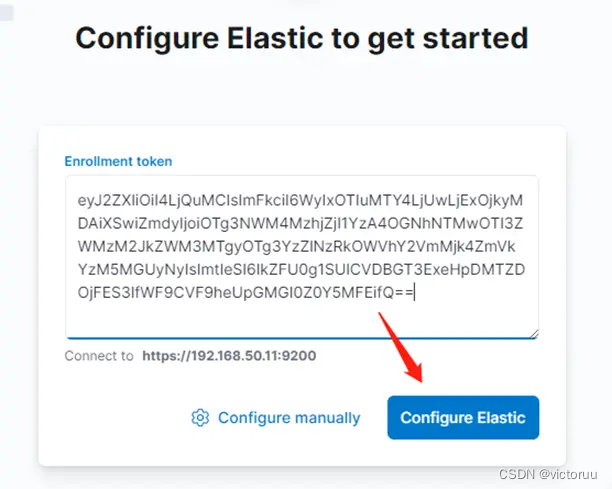
提示输入验证码,验证码需要在kibana服务上生成(有些远程ssh工具执行命令验证码可能会显示不出来,可以直接在系统命令界面去执行命令就可以看见验证码了)。
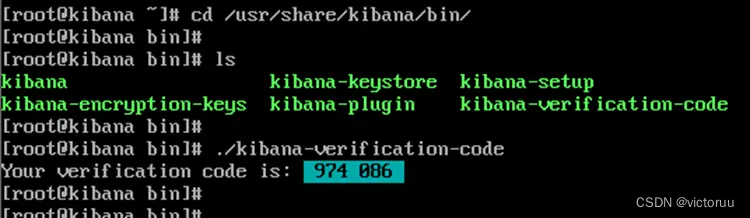
[root@kibana kibana]# cd /usr/share/kibana/bin/
[root@kibana bin]# ls
[root@kibana bin]# ./kibana-verification-code
Your verification code is: 974 086
输入生成的验证码连接。
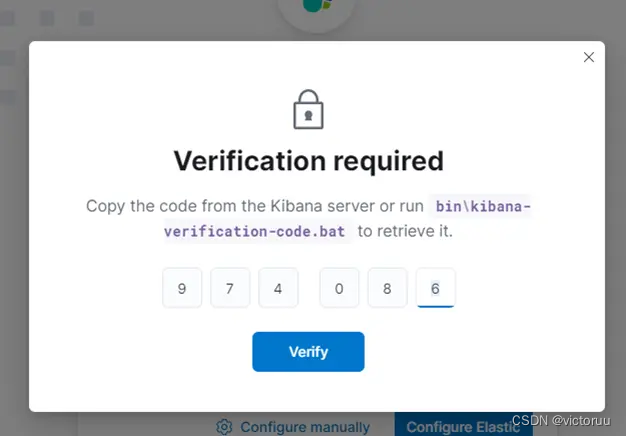
6、输入验证码后,就会跳转到登录窗口可以登录使用了。用户可以用ES上的账户elastic,密码就是前面ES设置的Elk@2022。
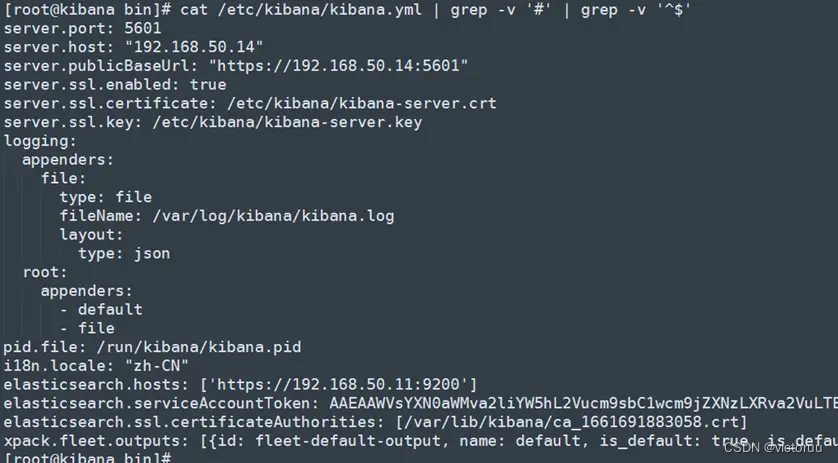
7、最后,Kibana的最终配置文件如下,补充完ES集群的地址,而最底下的elasticsearch信息是连接ES时自动生成的,不用管。
六、Kibana配置ES监控和管理
1、Kibana首次登录进来后,选择自己浏览。
2、前面说了,没有装ES-head怎么办,其实我们也只是监控ES状态用用可以使用Kibana。如下图操作,打开Management,找到“堆栈监测”开启ES集群的监控。
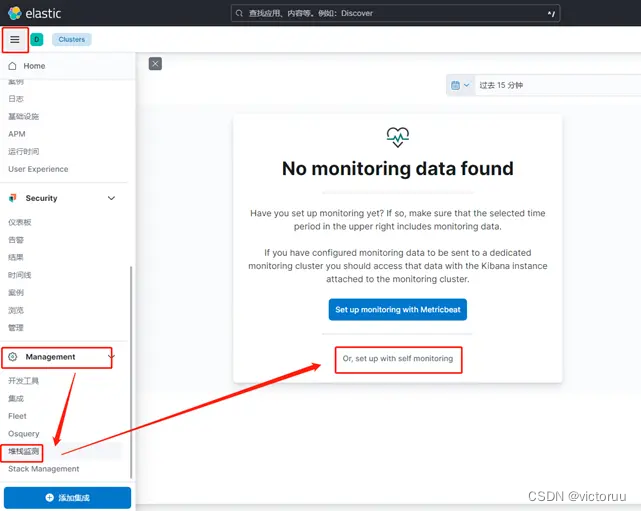
点击打开监控
稍等一会
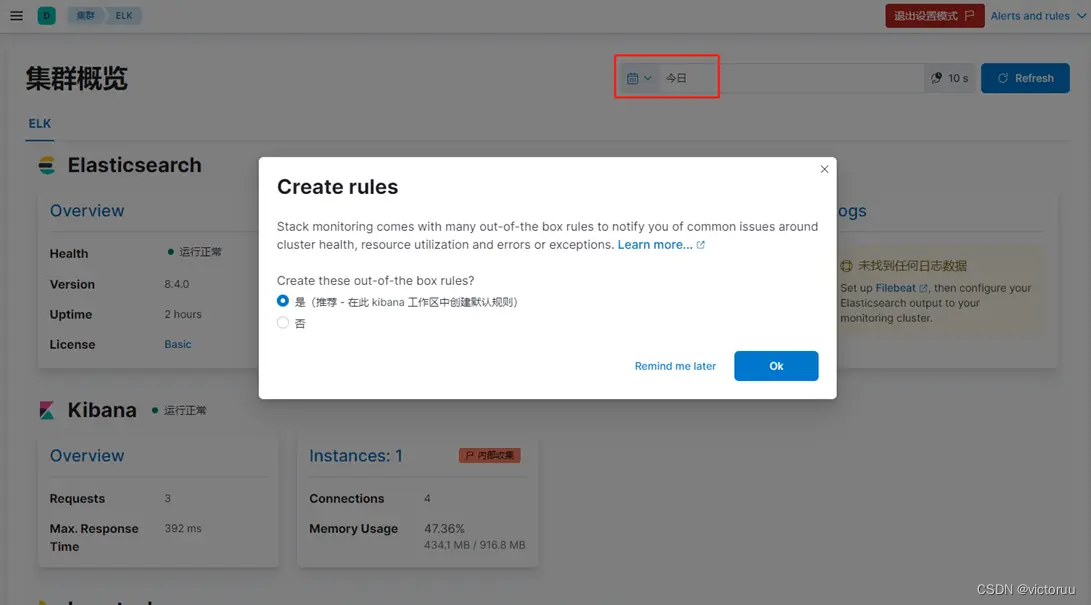
如果上面的界面加载了很久都没跳出页面可以如下图右上角。选择今天的数据时间范围,就有数据了,然后弹出创建规则窗口,按推荐默认的来也可以。
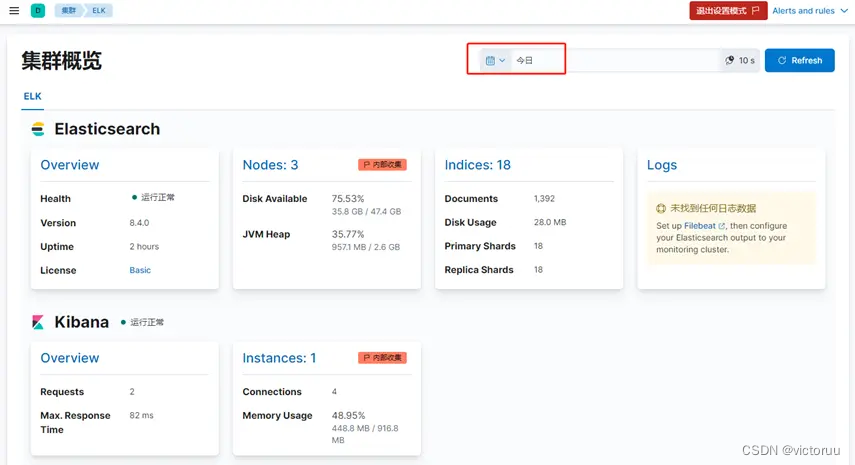
这里你就可以看到集群的状态看,退出右上角“设置模式”,点击nodes就可以查看到节点状态,你可以随便点点就知道能浏览查看什么数据了,这里不再过多介绍。
3、如果你想管理索引,点击左边菜单栏,点击最底下的Stack Management,找到索引管理,里面的功能基本上就可以对ES上的数据进行操作了。
如果以上自带的功能还不能满足你管理ES,那么可以还在如下菜单添加ES的管理,这里不做介绍了(因为我也不会),能用到这么高级的功能的人估计也不会看我这篇入门教程,更不需要我介绍使用。
至此,ELK日志系统的E和K我们已经搞定了,接下来介绍一下“L”。
七、安装Logstash收集日志
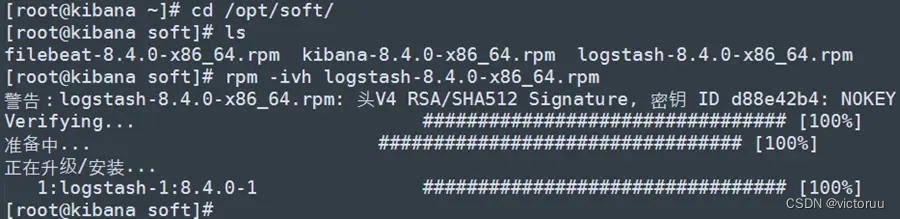
1、我这里选择把logstash安装在kibana的服务器(192.168.50.14)上。进入安装包目录开始安装。
[root@kibana ~]# cd /opt/soft/
[root@kibana soft]# ls
[root@kibana soft]# rpm -ivh logstash-8.4.0-x86_64.rpm
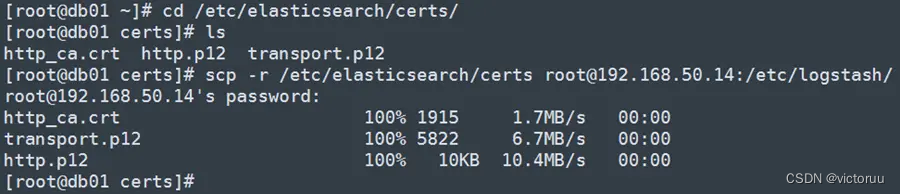
2、登录db01,将ES的证书复制到Logstash目录。因为我们的ES使用的HTTPS访问认证, Logstash要发送日志到ES时,需要进行证书认证。
[root@db01 certs]# scp -r /etc/elasticsearch/certs [email protected]:/etc/logstash/
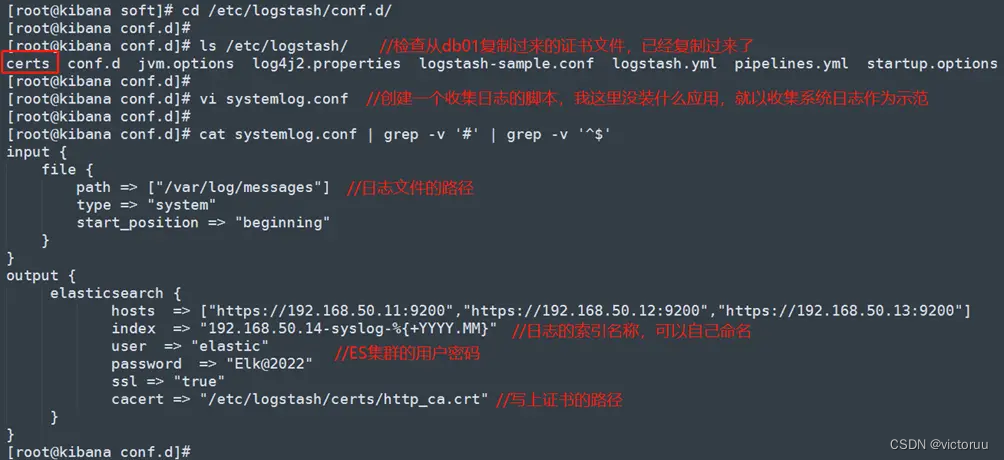
3、使用Logstash收集日志。进入Logstash目录,创建日志收集的配置文件,因为我的服务器没装有什么应用,就以收集操作系统日志作为例子。
[root@kibana soft]# cd /etc/logstash/conf.d/
[root@kibana conf.d]# vi systemlog.conf
[root@kibana conf.d]# cat systemlog.conf | grep -v '#' | grep -v '^$'
input {
file {
path => ["/var/log/messages"]
type => "system"
start_position => "beginning"
}
}
output {
elasticsearch {
hosts => ["https://192.168.50.11:9200","https://192.168.50.12:9200","https://192.168.50.13:9200"]
index => "192.168.50.14-syslog-%{+YYYY.MM}"
user => "elastic"
password => "Elk@2022"
ssl => "true"
cacert => "/etc/logstash/certs/http_ca.crt"
}
}
4、收集日志。运行日志收集脚本,开始收集日志,并查看日志。
执行日志收集命令:
[root@kibana conf.d]# /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/systemlog.conf
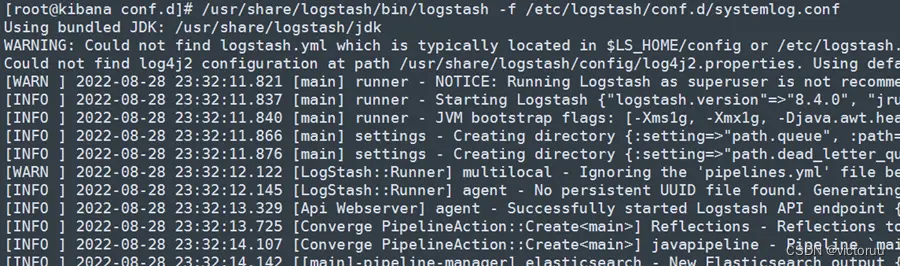
如果运行没有报错,说明我们的配置文件没有问题,下次执行命令的时候,可以在命令最后面加上“&”放在后台运行。
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/systemlog.conf &
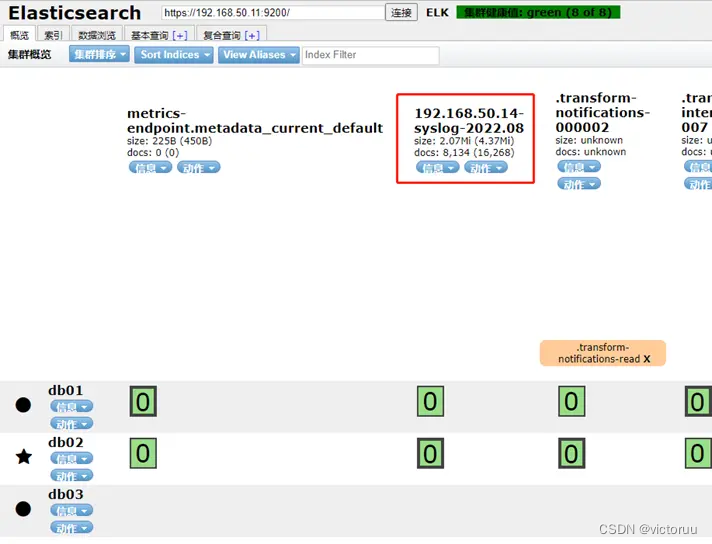
查看ES集群是否有日志索引创建。这个时候已经可以看到有我们刚才收集日志的索引名称了。
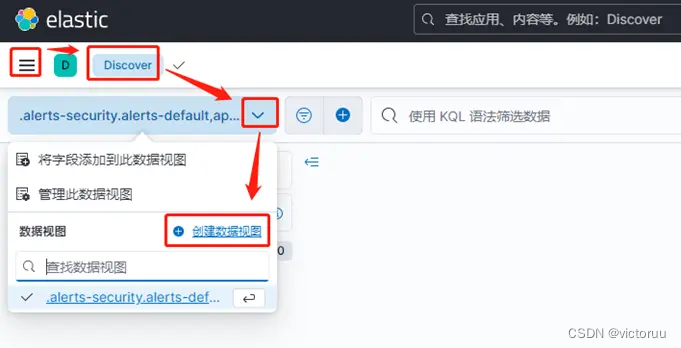
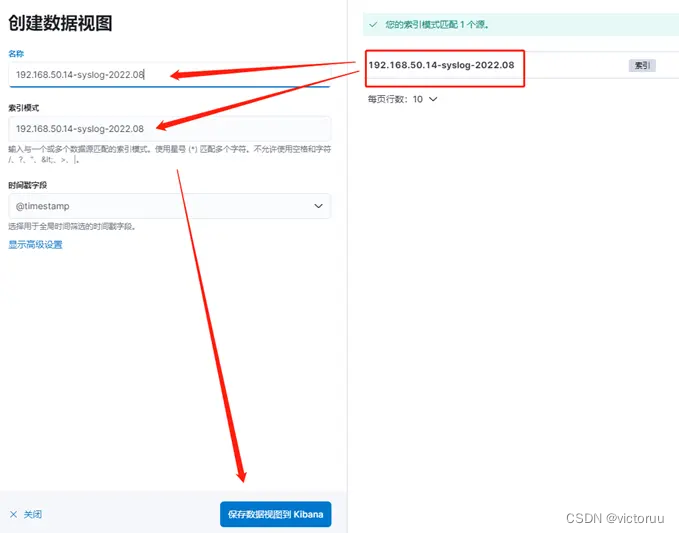
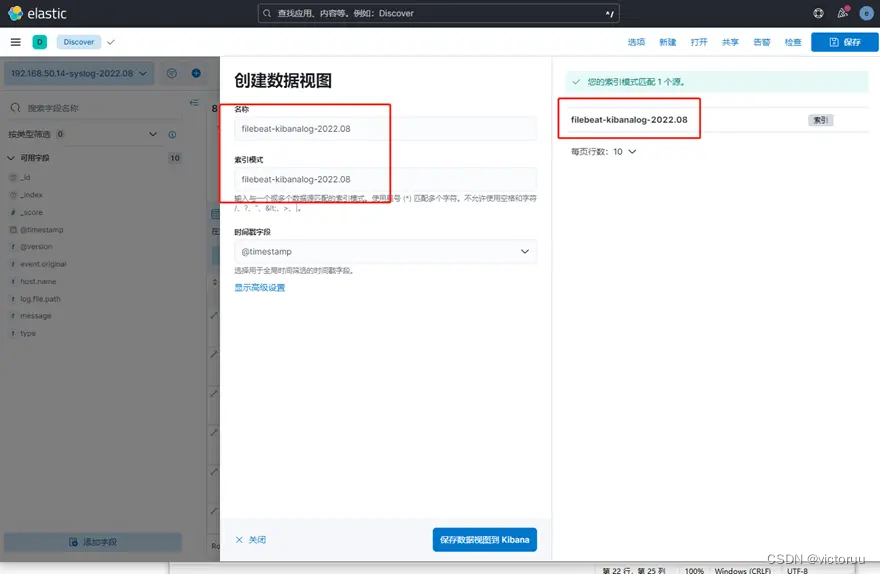
使用Kibana查看日志。打开Kibana页面,点击左侧菜单栏的Discover选项卡,如下图创建数据视图。
如下图复制粘贴索引名称过来,然后保存数据视图,名称可以自己命名。
然后就可以查看到日志了,左侧可以做一些日志筛选,右侧可选相应时间段。
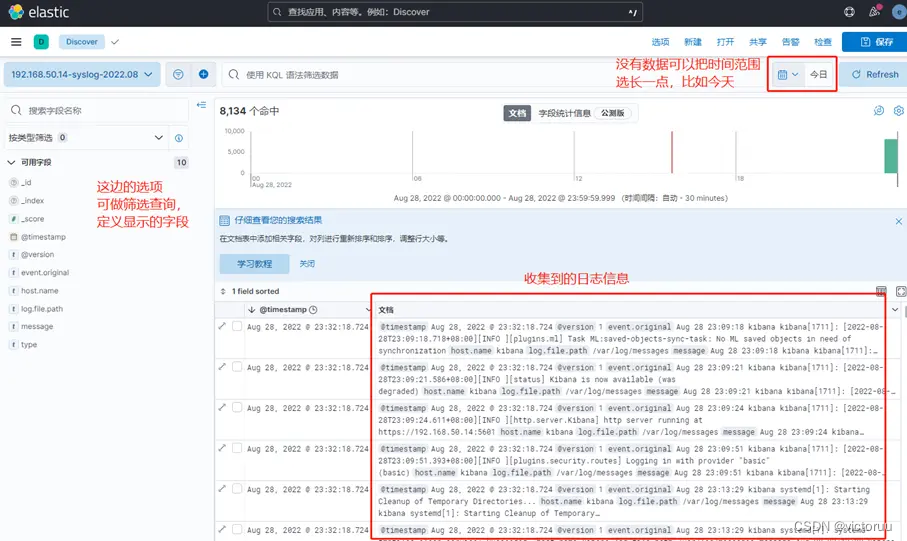
以上,就算是整套ELK收集日志的一个简单示范:Logstash收集日志发送到ES,Kibana从ES读取数据进行日志展示和查询。
八、安装Filebeat收集日志
1、安装Filebeat。我这里也是在192.168.50.14这台机子上安装作为演示。进入安装包目录,执行安装。
[root@kibana ~]# cd /opt/soft/
[root@kibana soft]# rpm -ivh filebeat-8.4.0-x86_64.rpm
2、同Logstash一样,因需要进行证书认证,需要将ES的证书复制到Filebeat目录。
[root@db01 ~]# scp -r /etc/elasticsearch/certs [email protected]:/etc/filebeat/

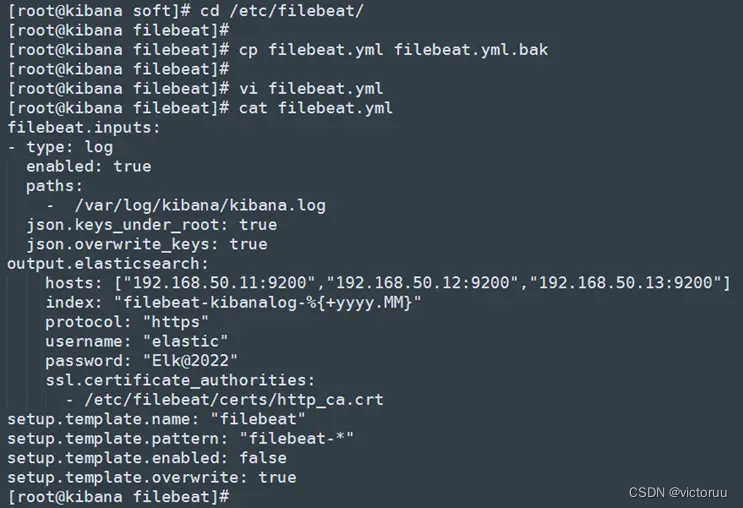
3、进入filebeat目录,编辑filebeat 的配置文件,编辑filebeat.yml配置文件可以先做个备份(不备也行,反正没啥用),为方便编写,将filebeat.yml原有的内容全部清空,然后写上我们自己的日志收集配置。我这里以日志格式是Json格式的kibana日志作为示范。
[root@kibana soft]# cd /etc/filebeat/
[root@kibana filebeat]# vi filebeat.yml
[root@kibana filebeat]# cat filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/kibana/kibana.log
json.keys_under_root: true
json.overwrite_keys: true
output.elasticsearch:
hosts: ["192.168.50.11:9200","192.168.50.12:9200","192.168.50.13:9200"]
index: "filebeat-kibanalog-%{+yyyy.MM}"
protocol: "https"
username: "elastic"
password: "Elk@2022"
ssl.certificate_authorities:
- /etc/filebeat/certs/http_ca.crt
setup.template.name: "filebeat"
setup.template.pattern: "filebeat-*"
setup.template.enabled: false
setup.template.overwrite: true
4、启动filebeat收集日志。
因为filebeat收集日志的配置是yml格式的,书写语法比较严格规范,在启动filebeat前,可以先检查一下配置文件的语法有没有问题。
[root@kibana filebeat]# filebeat test config -c filebeat.yml

当然也可以把你的文件贴到https://www.bejson.com/validators/yaml_editor/来检查
检查没有问题,可以启动filebeat了。
[root@kibana filebeat]# systemctl start filebeat
[root@kibana filebeat]# systemctl status filebeat
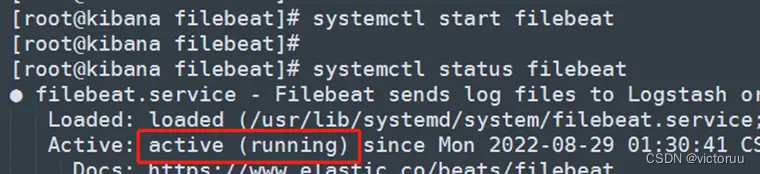
重启filebeat:systemctl restart filebeat
设置开启自启动filebeat:systemctl enable filebeat
如果启动异常,可以用下列的命令检查日志再排查问题,新版本的filebeat日志是放在messages里。
新版查看filebeat日志:tail -f /var/log/messages
4、filebeat启动正常后,打开ES,查看是否已经生成日志索引,生成了说明成功收集了日志。
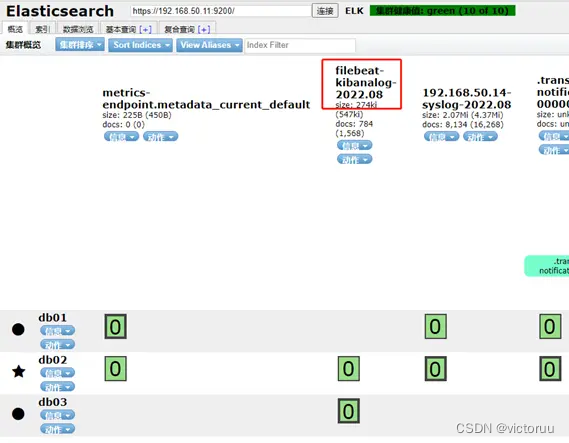
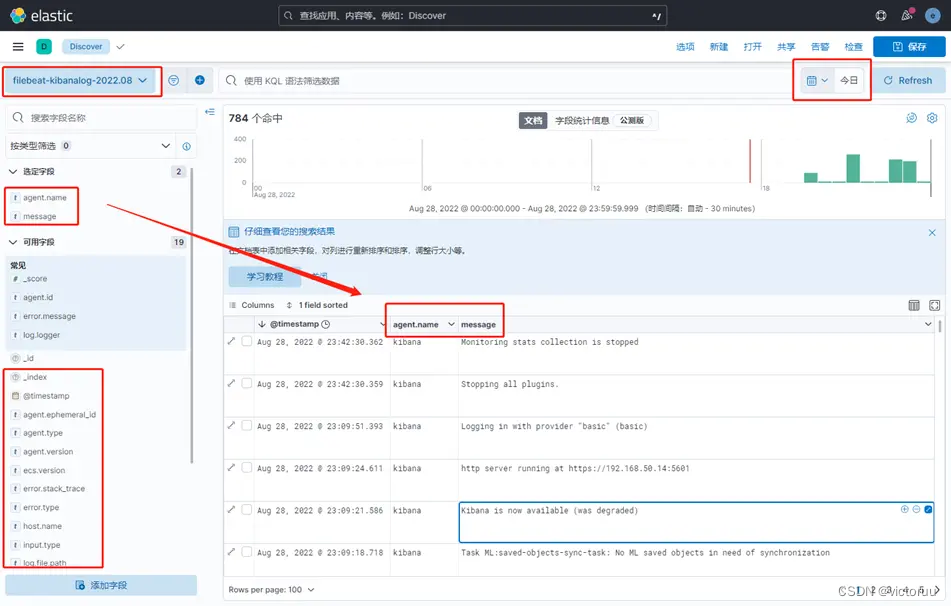
同logstash一样,打开Kibana创建数据视图导入索引,查看日志。
Json格式的日志会自动生成相应的字段名称,可以根据字段筛选显示想查看的内容。
好了,Filebeat日志收集就介绍这么多,在实际使用的时候可以根据自己的业务需求来,在相应的服务器上安装filebeat,然后配置好相应的filebeat.yml文件,不同的应用,不同的日志类型,所编写的yml文件不同得根据实际灵活变通,logstash的日志收集配置文件也是,针对具体应用的日志收集写法,因篇幅有限,这里不一一列举,可以百度找一些别人收集的日志的模板改成自己的。
(二)进阶:使用Kafka作为日志消息缓存
在一些比较大的业务使用场景中,因为应用繁多,需要收集的日志也很多,通过filebeat或者logstash收集上来的日志如果全都直接发送给ES,那么就会对ES集群产生一定的压力,为了避免出现日志接收不过来的问题,于是引入了消息队列作为缓存,比如常见的使用Redis或Kafka作为消息缓存。本篇讲的是以kafka作为消息缓存的架构,收集上来的日志先发送给Kafka,然后再发送给ES集群,当然因Kafka没办法直接和ES对接数据,需在这两者之间使用Logstash来传输。于是架构就有了如下:
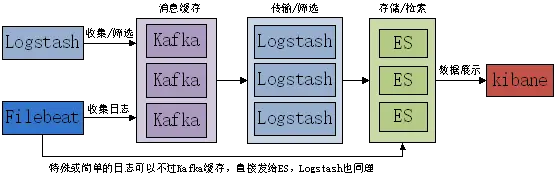
我这里的Kafka部署也是3个节点部署,都安装在之前的ES服务器上,即分别安装在db01(192.168.50.11)、db02(192.168.50.12)、db03(192.168.50.13)上。
PS:3台ES节点的服务器的数据并发吞吐量我觉得也挺高的,至于多少数据负载时必须要用消息缓存我也不清楚,因为我没有接触过什么大的业务系统来给我实践需要使用缓存,哈哈……
一、安装JDK
1、安装JDK,因为部署Kafka需要依赖java环境但又不能直接使用ELK自带的JDK。
登录3台ES集群服务器,先检查系统是否已经装有java了,然后进入安装包目录,执行安装即可。(如装有java了可以跳过此步骤)
[root@db01 ~]# cd /opt/soft/
[root@db01 soft]# java –version
[root@db01 soft]# rpm -ivh jdk-8u311-linux-x64.rpm
[root@db01 soft]# java -version
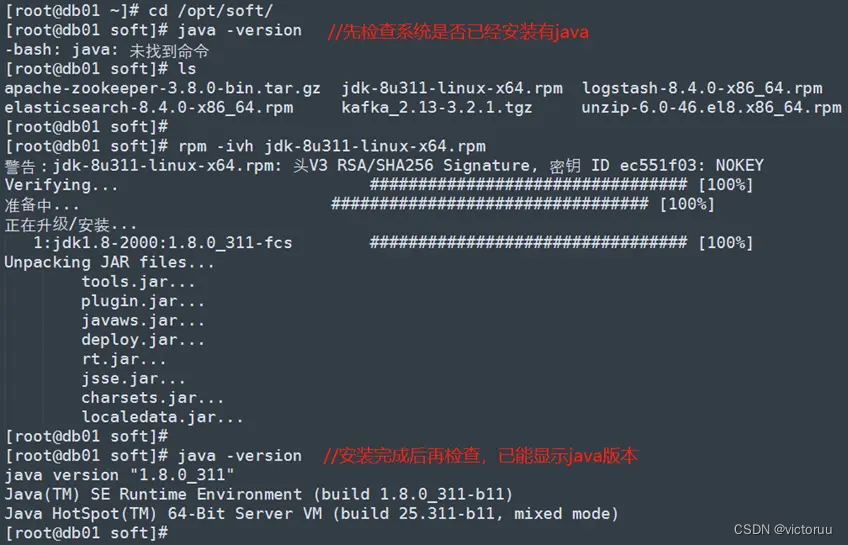
db02和db03两台机子也都进行java的安装。


java安装完成即可,无需再做其他配置(网上太多坑还要你改环境变量的,实际什么都不用改)。
二、安装Zookeeper
1、部署Kafka之前还需要先安装zookeeper。zookeeper是一个集群调度的工具,可以用来调度Kafka集群。
进入安装包目录,执行安装,安装完成后编辑配置文件。
[root@db01 soft]# tar zxf apache-zookeeper-3.8.0-bin.tar.gz -C /opt/
[root@db01 soft]# ln -s /opt/apache-zookeeper-3.8.0-bin/ /opt/zookeeper
[root@db01 soft]# mkdir -p /data/zookeeper
[root@db01 soft]# cp /opt/zookeeper/conf/zoo_sample.cfg /opt/zookeeper/conf/zoo.cfg
[root@db01 soft]# vi /opt/zookeeper/conf/zoo.cfg
[root@db01 soft]# cat /opt/zookeeper/conf/zoo.cfg | grep -v '#' | grep -v '^$'
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper
clientPort=2181
server.1=192.168.50.11:2888:3888
server.2=192.168.50.12:2888:3888
server.3=192.168.50.13:2888:3888
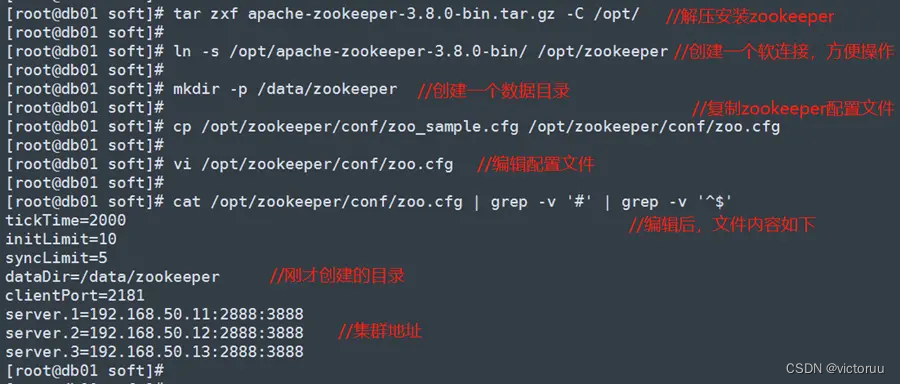
db02和db03两台机子也都同样进行zookeeper的安装
2、安装完zookeeper后配置节点ID。
[root@db01 soft]# echo "1" > /data/zookeeper/myid
[root@db01 soft]# cat /data/zookeeper/myid

db02和db03两台机子也都同db01一样创建ID号,注意ID号不一样,db02设置“2”,db03设置“3”。
[root@db02 soft]# echo "2" > /data/zookeeper/myid
[root@db02 soft]# cat /data/zookeeper/myid

[root@db03 soft]# cat /data/zookeeper/myid

3、启动zookeeper,每台机子都启动。
[root@db01 soft]# /opt/zookeeper/bin/zkServer.sh start
[root@db01 soft]# /opt/zookeeper/bin/zkServer.sh status
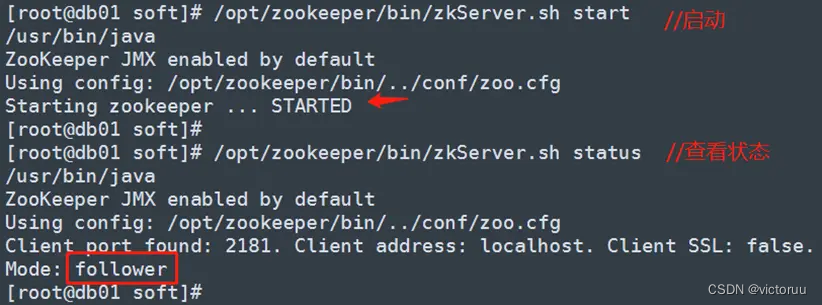
db02启动zookeeper
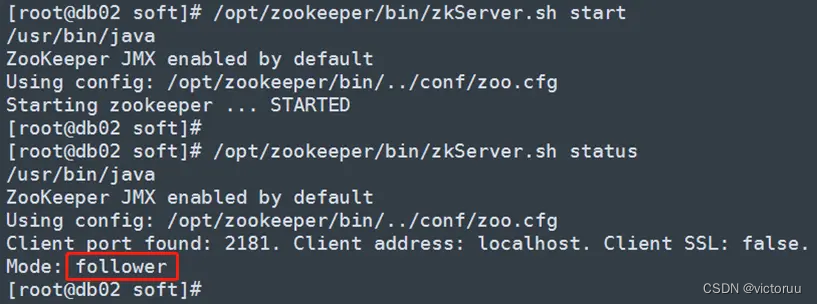
db03启动zookeeper
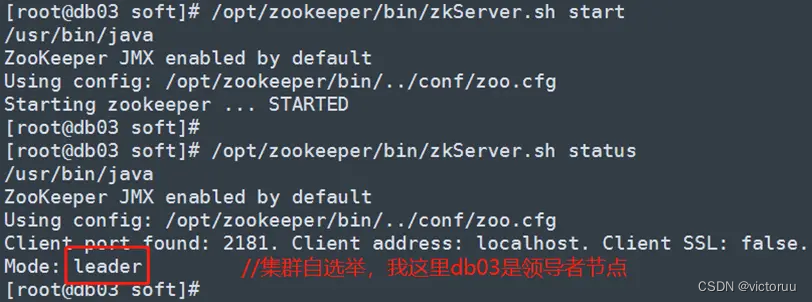
至此,zookeeper部署完成。
三、安装Kafka
1、安装Kafka,进入安装包目录,执行安装,然后修改配置文件。
[root@db01 ~]# cd /opt/soft
[root@db01 soft]# tar zxf kafka_2.13-3.2.1.tgz -C /opt/
[root@db01 soft]# ln -s /opt/kafka_2.13-3.2.1/ /opt/kafka
[root@db01 soft]# mkdir /opt/kafka/logs
[root@db01 soft]# vi /opt/kafka/config/server.properties
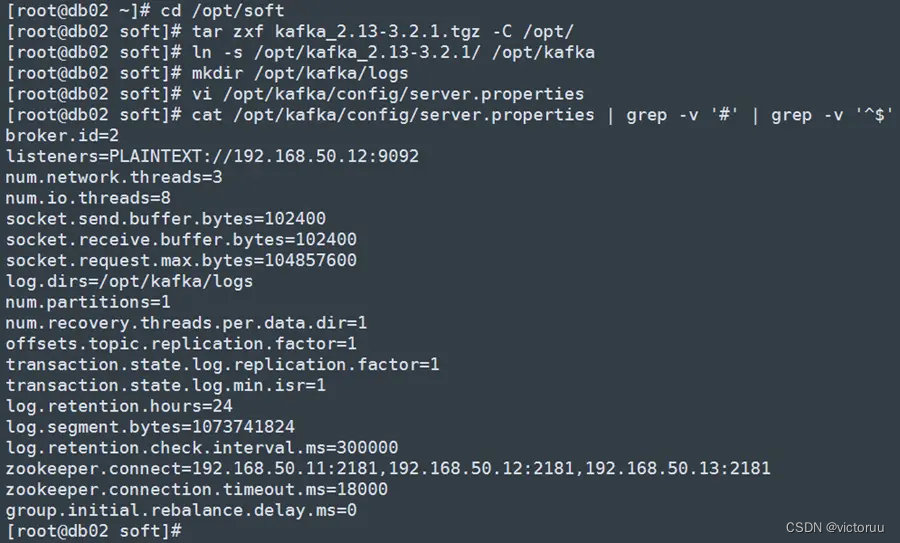
[root@db01 soft]# cat /opt/kafka/config/server.properties | grep -v '#' | grep -v '^$'
broker.id=1
listeners=PLAINTEXT://192.168.50.11:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/kafka/logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=24
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.50.11:2181,192.168.50.12:2181,192.168.50.13:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
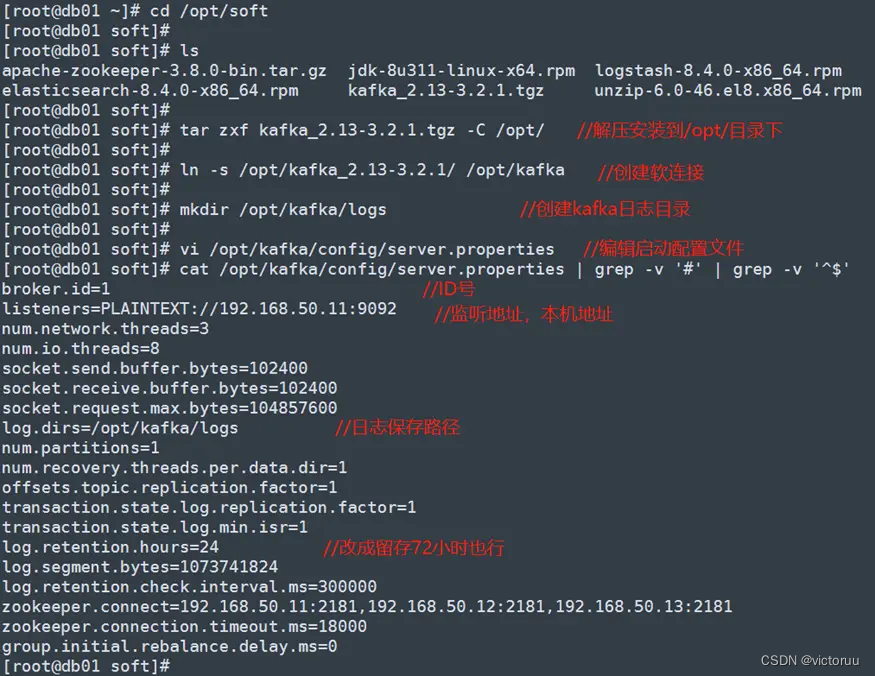
db02和db03两台机子也都同样进行Kafka的安装,注意配置文件ID号和监听地址的改变。
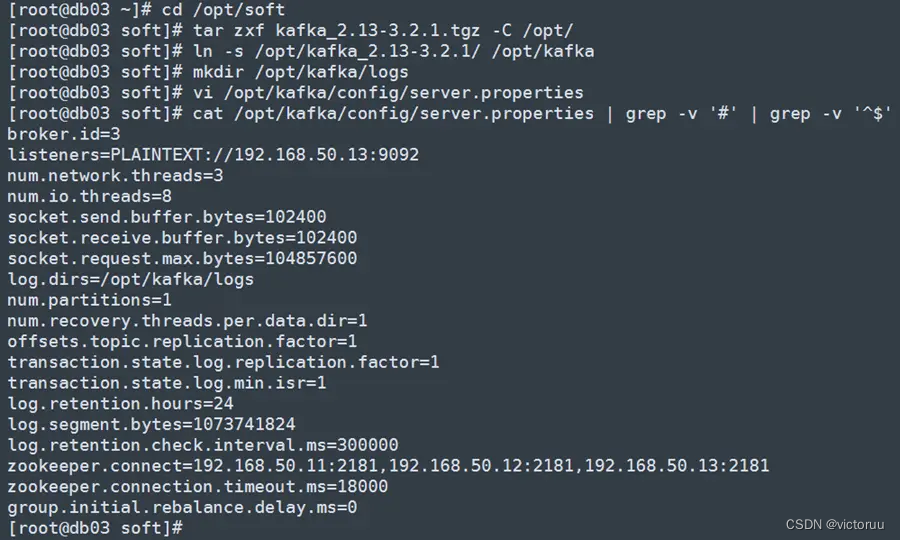
2、安装配置完后,可以开始启动Kafka了,注意启动Kafka需要确保zookeeper已经启动,否则会启动失败。
三台机子都可以同时启动,启动后当出现有Starting的字眼的时候,表示已经启动成功了。
[root@db01 soft]# /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties

db02启动Kafka
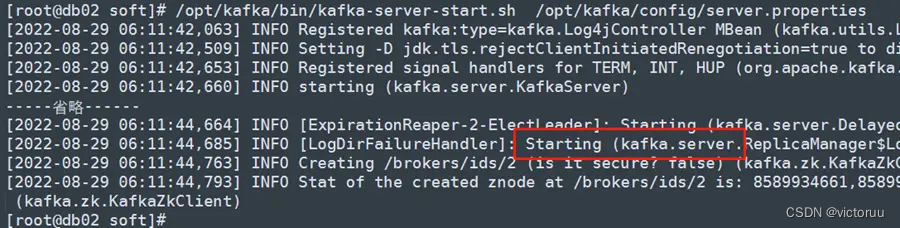
db03启动Kafka

启动都没有报错,没有问题,正常使用的就可以放在后台运行了,后台运行命令:
/opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties
Kafka部署完成,下面开始使用Kafka对日志发送进行缓存。
写完才发现B站最多仅支持100张图片,后面的步骤图片没法上传了,所以B站教程先写到这里。尴尬 ( ̄ー ̄*|||
请放心,我已将教程转为PDF文档并上传网盘,后面的教程步骤请到百度网盘下载教程文档:https://pan.baidu.com/s/1DNfun0df_rJeX8reEDj6Cg?pwd=2y6x(链接失效请联系我,如果能联系得到的话)网页教程是从文档复制粘贴的,难免有错漏,请看文档为准(..•˘_˘•..)
本新手初学ELK部署,教程有写得不对的地方请大佬指出,谢谢!如果教程对你有帮助,请帮我点个赞,再次谢谢 作者:又菜又爱玩的张小剑 https://www.bilibili.com/read/cv19834484/ 出处:bilibili