转载:图解 生成对抗网络GAN 原理 超详解_gan原理图-CSDN博客
Gan 和 StyleGAN 架构_stylegan和gan-CSDN博客
1.1 组成部分:生成器和判别器
Generator生成器,它是一个深度神经网络,输入一个低维vector,输出高维vector(图片或文本或语音)
Discriminator判别器,它也是一个深度神经网络,输入一个高维vector(图片或文本或语音),输出一个标量。标量越大,代表输入图片(或文本语音)越真实。
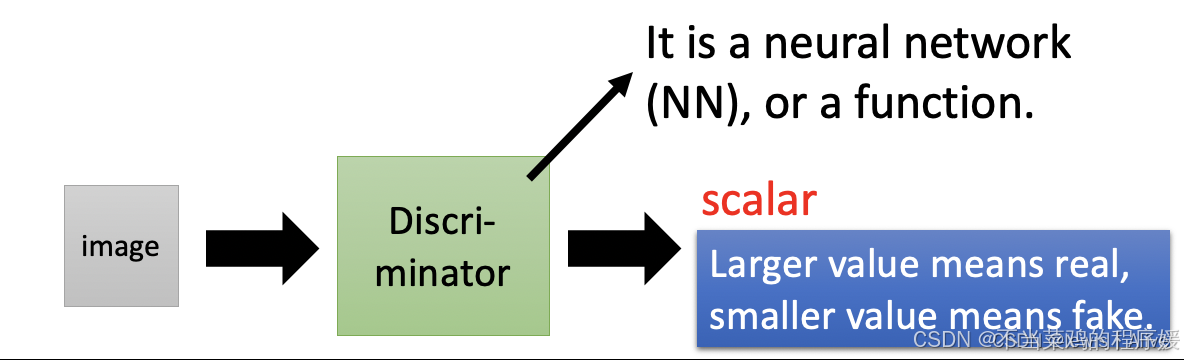
1.1.1对抗学习
生成器和判别器二者进行对抗学习,生成器不断迭代进化,努力生成假的图片,从而可以骗过判别器。判别器也在不断迭代进化,努力识别越来越接近真实的假图片。通过二者对抗学习,最终生成器生成的假图片越来越像真实图片,而判别器越来越能区分和真实图片很接近的假图片。二者能力在迭代过程中,都可以得到大幅提升。
StyleGAN 的前身——ProGAN

StyleGAN 算法总体预览
StyleGAN 用风格(style)来影响人脸的姿态、身份特征等,用噪声 ( noise ) 来影响头发丝、皱纹、肤色等细节部分。
StyleGAN 的网络结构包含两个部分,第一个是Mapping network,即下图 (b)中的左部分,由隐藏变量 z 生成 中间隐藏变量 w的过程,这个 w 就是用来控制生成图像的style,即风格,为什么要多此一举将 z 变成 w 呢,后面会详细讲到。 第二个是Synthesis network,它的作用是生成图像,创新之处在于给每一层子网络都喂了 A 和 B,A 是由 w 转换得到的仿射变换,用于控制生成图像的风格,B 是转换后的随机噪声,用于丰富生成图像的细节,即每个卷积层都能根据输入的A来调整"style",通过B来调整细节。整个网络结构还是保持了 PG-GAN (progressive growing GAN) 的结构。最后论文还提供了一个高清人脸数据集FFHQ。
此外,传统的GAN网络输入是一个随机变量或者隐藏变量 z,但是StyleGAN 将 z 单独用 mapping网络将z变换成w,再将w投喂给 Synthesis network的每一层,因此Synthesis network中最开始的输入变成了常数张量,见下图b中的Const 4x4x512。
