数据库——MySQL读写分离后的延迟解决方案
背景:
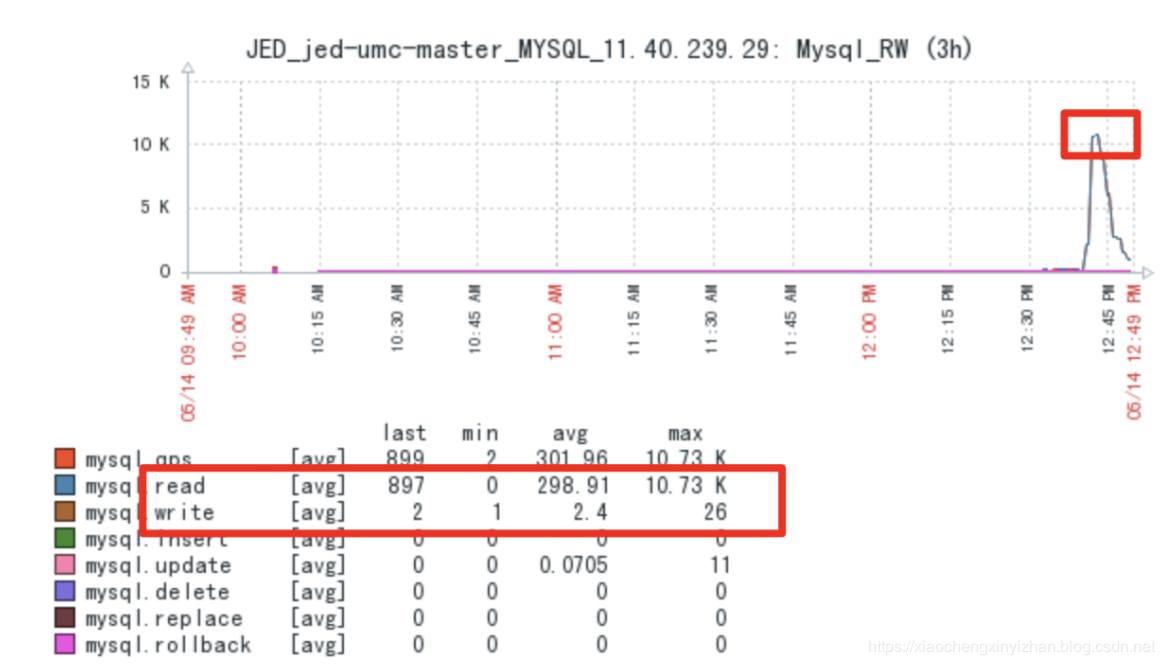
根据上图可以看到QPS:10.73k,实际上真实的并发大量数据到达的时候,我这里最高的QPS是将近15k.而目前单个数据库分片(实例)4CPU8G内存的配置下,最高的性能是7k的QPS。
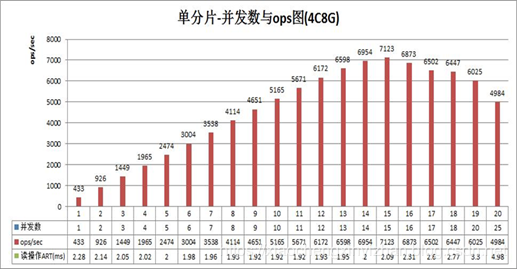
基于上篇我进行了分库分表是对于性能有很大的提高,分库分表实践和中间件的引申
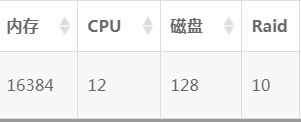
我这里讲解的例子是目前4主8从库(12个实例),以下每个实例都会称为分片。单个分片配置mysql版本5.7.19(一会说明不同版本是读写分离的不同策略),12CPU16G内存,128G的磁盘,Raid:10。
读写分离实践
读写分离可以参考上篇文章的分库分表实践中的中间件的用法来实现。主流一般会使用mycat,但是每个中间件都有自己的优点可以择优和业务特点而用。接下来讲读写分离后的后遗症。
读写分离的延迟和实时insert/update和查询操作
比如我这里的一个场景:由于数据量大,以人维度的情况下,商品量20w~50w。然后需要分页查询未同步下游状态,进行数据同步后再更新该分页数据。我当时设定了如下的四种场景,最后选择了读写分离和不分离同时存在,针对于实时要求结果高的依然是master主库读写,变动需求量小的数据,全部转移slave从库。
如下是四种场景的方案:
1、 完全分离:全量读->从库,全量读写->主库
前提:第一页查询逻辑不变
特点:半同步复制,目前是1主2从库,利用半同步复制原理,1/2的可能性会重复查询,当然这个几率需要和延时性进行测试计算可得,也就是最坏的结果可能性是重复查询50%的可能性。目前反馈主从同步延时1s
方案:
(1)冗余性:去重校验,对于50%的可能性查询出的重复数据。
(2)性能:重复数据和校验会使性能有所降低,但是从库是2个分摊QPS的压力,会使性能有所提高,相互抵消一部分。
2、 不完全分离:商品读写模块依然master主库,其他地方读->从库,写->主库。
前提:第一页查询逻辑不变
特点:由于联合营销系统场景单一,主要是围绕SKU进行。但是会改善一部分压力。
方案:
(1) 冗余性:代码冗余地方多,风格不统一。
(2) 性能:会有部分改善,但是从整体看,数据量大的时候,依然是master主库读写压力大。
3、 完全分离:全量读->从库,全量读写->主库。
前提:分页查询(不加同步状态)
特点:分页查询随着页数和数据量大的情况呈正相关也会时间越来越大。
方案:
(1) 冗余性: 会重复查询,由于分页和性能成正相关,数据量越大,耗时越大。
(2) 分页查询解决性能损耗来减少性能响应时间的方案
(2.1)可以采用延时关联策略(弹性数据库不支持)
(2.2)采用id序列(利用数据库id索引过滤)和limit组合使用(效果不大)。
4、 完全分离:全量读->从库,全量读写->主库
前提:分页查询(加同步状态),最后一次结果集退出的时候进行兜底全量count查询并重新执行上述逻辑。
特点:分页查询随着页数和数据量大的情况呈正相关也会时间越来越大。
方案:与上诉3的方案相同。但避免了查询出重复数据。
读写分离和非分离同时存在,改造后的效果图(我这里的数据量2亿):
读写分离之前master主库CPU使用率95%~99%