0 前言
二进制的相关概念是学习数据存储、数据压缩、数据序列化的基石,只有真正搞清楚了二进制,才能逐步深入到算法源码,达到理解和复现的目的。
本文将介绍二进制和数据存储的相关概念(包括位、字节、高低位、大小端、原码、反码、补码、进制转换),以及二进制的位运算。注意:本文讲解偏实战,有些定义不够严谨,如需深入研究可以进一步阅读二进制的原码、反码、补码。
1 基本概念
1.1 位、字节
位(bit):计算机内部存储数据的最小单位。
字节(Byte):计算机存储容量(数据处理)的基本单位,1byte (字节)= 8 bit(位)。无符整型取值范围0~255,有符整型取值范围-128~127。
1byte = 8bit = 8二进制位 = 2个十六进制位
JAVA中数据类型的占用内存大小如图所示:
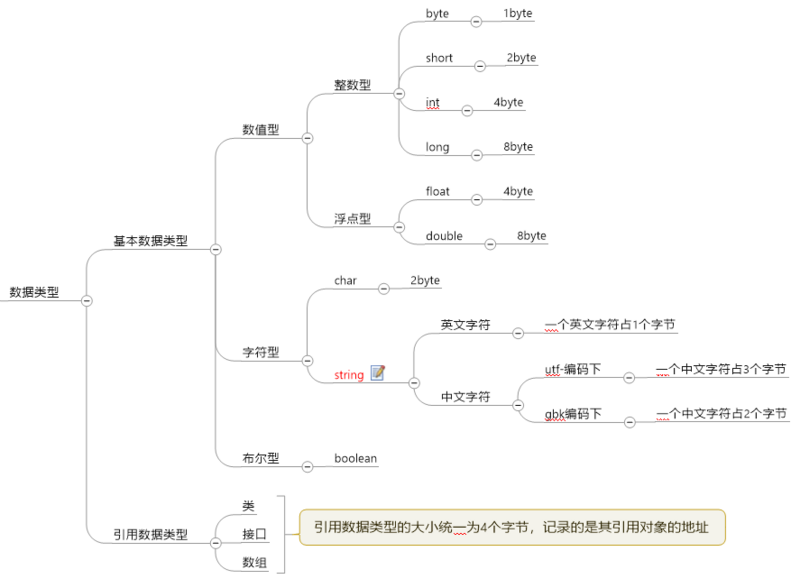
1.2 高位、低位、符号位高位:指在数据类型限定范围内靠左的二进制位。
低位:指在数据类型限定范围内靠右的二进制位。
符号位:指在数据类型限定范围内最左边的一个二进制位,符号位为0表示正数,1表示负数。
【举例说明】
十进制数1的二进制为:0000 0001(最左边的0为符号位,从左往右对应的是高位向低位延伸)
十进制数-1的二进制为:1111 1111(最左边的1为符号位,从左往右对应的是高位向低位延伸)
【扩展】为什么-1的二进制位不是1000 0001呢?
1.3 大小端
对于一个字节序列,如何解析?究竟是从左读还是从右读?正因为有了读写顺序的差异,带来了两种不同的模式。
【定义】大端模式(Big-endian),是指数据的高字节位 保存在 内存的低地址中,而数据的低字节位 保存在 内存的高地址中。这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放。和我们”从左到右“阅读习惯一致。简言之,高位字节在前,低位字节在后。
小端模式(Little-endian),是指数据的高字节位 保存在 内存的高地址中,而数据的低字节位 保存在 内存的低地址中。这种存储模式将地址的高低位和数据位有效地结合起来,高地址部分权值高,低地址部分权值低,和我们的逻辑方法一致。简言之,低位字节在前,高位字节在后。
比如字节数据0x1A2B3C4D,要存在数组bytes[]中内存的低位地址----------->内存的高位地址
大端模式:1A 2B 3C 4D 即bytes[0]=1A,bytes[1]=2B,bytes[2]=3C,bytes[3]=4D 先存高位
小端模式:4D 3C 2B 1A 即bytes[0]=4D,bytes[1]=3C,bytes[2]=2B,bytes[3]=1A 先存低位
详细案例可见:https://blog.csdn.net/kuangsu...
【特点】大端:符号位在所表示的数据内存的第一个字节中,便于快速判断数据的正负和大小(CPU做数值运算时从内存中依顺序依次从低位地址到高位地址取数据进行运算,大端就会最先拿到数据的(高字节的)符号位)。
小端:CPU做数值运算时从内存中依顺序依次从低位地址到高位地址取数据进行运算,开始只管取值,最后刷新最高位地址的符号位就行,这样的运算方式会更高效一些。
目前我们常见的CPU PowerPC、IBM是大端模式,x86是小端模式。ARM既可以工作在大端模式,也可以工作在小端模式,一般ARM都默认是小端模式。一般通讯协议都采用的是大端模式。
1.4 原码、反码、补码
暂不深究定义,从应用的角度,可以将原码、反码和补码联系在一起理解,就是计算相反数,即原码的相反数=原码的补码=原码的反码(在原码基础上按位取反)+1
【举例说明】
原码=0000 0001(十进制为1)
反码=原码按位取反=1111 1110
补码=反码+1=1111 1111(十进制为-1)=-原码
若原码为-1,同样的运算可以得到其补码为1,因此,对于计算相反数而言,原码和补码是个相对概念。
通过java程序验证:import org.junit.Test;
public class binaryTest {
public void print(int value){
System.out.println("value="+value+",其二进制串为(左侧的0省略):"+Integer.toBinaryString(value));
}
@Test
public void test(){
int i=-1;
print(i); // 原码
pr