推荐
MapReduce分析明星微博数据
这篇博客,给大家,体会不一样的版本编程。
执行
2016-12-12 15:07:51,762 INFO [org.apache.hadoop.metrics.jvm.JvmMetrics] - Initializing JVM Metrics with processName=JobTracker, sessionId=
2016-12-12 15:07:52,197 WARN [org.apache.hadoop.mapreduce.JobSubmitter] - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2016-12-12 15:07:52,199 WARN [org.apache.hadoop.mapreduce.JobSubmitter] - No job jar file set. User classes may not be found. See Job or Job#setJar(String).
2016-12-12 15:07:52,216 INFO [org.apache.hadoop.mapreduce.lib.input.FileInputFormat] - Total input paths to process : 1
2016-12-12 15:07:52,265 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - number of splits:1
2016-12-12 15:07:52,541 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - Submitting tokens for job: job_local1414008937_0001
2016-12-12 15:07:53,106 INFO [org.apache.hadoop.mapreduce.Job] - The url to track the job: http://localhost:8080/
2016-12-12 15:07:53,107 INFO [org.apache.hadoop.mapreduce.Job] - Running job: job_local1414008937_0001
2016-12-12 15:07:53,114 INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter set in config null
2016-12-12 15:07:53,128 INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
2016-12-12 15:07:53,203 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Waiting for map tasks
2016-12-12 15:07:53,216 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local1414008937_0001_m_000000_0
2016-12-12 15:07:53,271 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2016-12-12 15:07:53,374 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@65f3724c
2016-12-12 15:07:53,382 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: file:/D:/Code/MyEclipseJavaCode/myMapReduce/data/Weibodata.txt:0+174116
2016-12-12 15:07:53,443 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)
2016-12-12 15:07:53,443 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100
2016-12-12 15:07:53,443 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080
2016-12-12 15:07:53,444 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600
2016-12-12 15:07:53,444 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600
2016-12-12 15:07:53,450 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2016-12-12 15:07:54,110 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local1414008937_0001 running in uber mode : false
2016-12-12 15:07:54,112 INFO [org.apache.hadoop.mapreduce.Job] - map 0% reduce 0%
2016-12-12 15:07:55,068 INFO [org.apache.hadoop.mapred.LocalJobRunner] -
2016-12-12 15:07:55,068 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
2016-12-12 15:07:55,068 INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output
2016-12-12 15:07:55,068 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufend = 747379; bufvoid = 104857600
2016-12-12 15:07:55,068 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396(104857584); kvend = 26101152(104404608); length = 113245/6553600
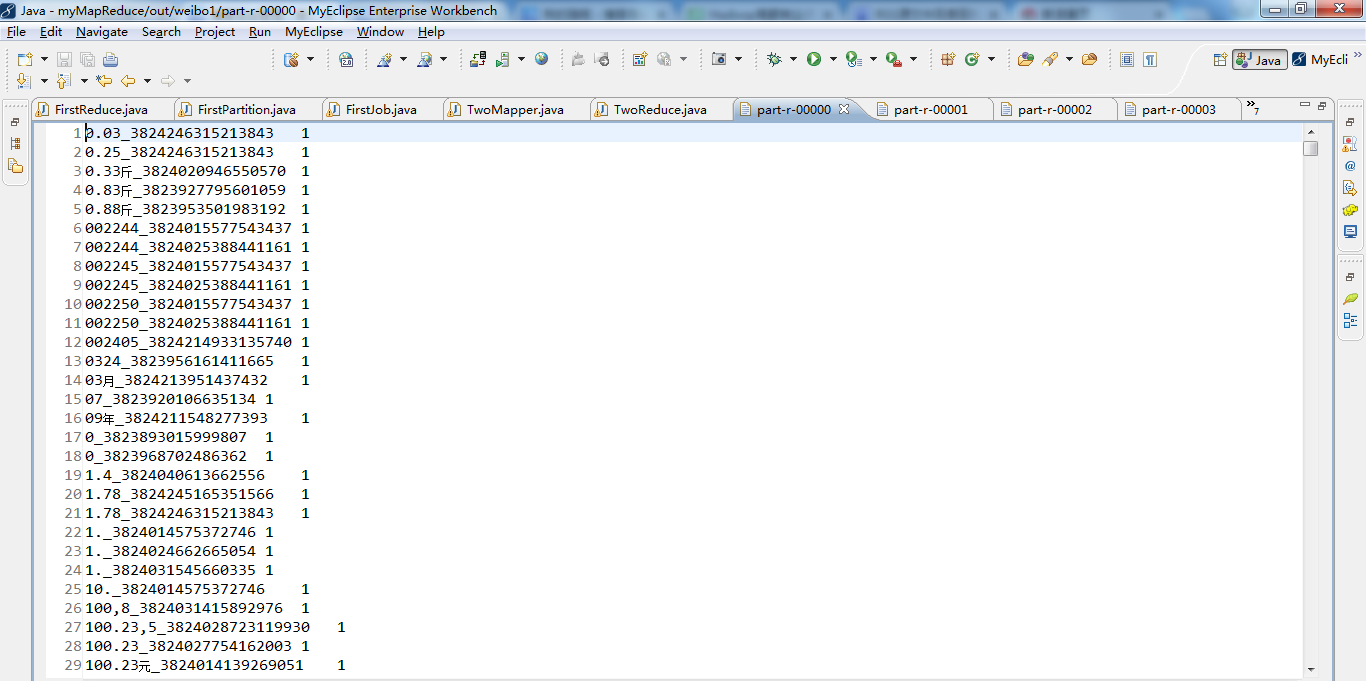
count___________1065
2016-12-12 15:07:55,674 INFO [org.apache.hadoop.mapred.MapTask] - Finished spill 0
2016-12-12 15:07:55,685 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local1414008937_0001_m_000000_0 is done. And is in the process of committing
2016-12-12 15:07:55,706 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
2016-12-12 15:07:55,706 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local1414008937_0001_m_000000_0' done.
2016-12-12 15:07:55,706 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local1414008937_0001_m_000000_0
2016-12-12 15:07:55,707 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map task executor complete.
2016-12-12 15:07:55,714 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Waiting for reduce tasks
2016-12-12 15:07:55,714 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local1414008937_0001_r_000000_0
2016-12-12 15:07:55,727 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2016-12-12 15:07:55,754 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@24a11405
2016-12-12 15:07:55,758 INFO [org.apache.hadoop.mapred.ReduceTask] - Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@12efdb85
2016-12-12 15:07:55,776 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - MergerManager: memoryLimit=1327077760, maxSingleShuffleLimit=331769440, mergeThreshold=875871360, ioSortFactor=10, memToMemMergeOutputsThreshold=10
2016-12-12 15:07:55,778 INFO [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] - attempt_local1414008937_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
2016-12-12 15:07:55,810 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#1 about to shuffle output of map attempt_local1414008937_0001_m_000000_0 decomp: 222260 len: 222264 to MEMORY
2016-12-12 15:07:55,818 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 222260 bytes from map-output for attempt_local1414008937_0001_m_000000_0
2016-12-12 15:07:55,863 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 222260, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->222260
2016-12-12 15:07:55,865 INFO [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] - EventFetcher is interrupted.. Returning
2016-12-12 15:07:55,866 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 1 / 1 copied.
2016-12-12 15:07:55,867 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
2016-12-12 15:07:55,876 INFO [org.apache.hadoop.mapred.Merger] - Merging 1 sorted segments
2016-12-12 15:07:55,876 INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with 1 segments left of total size: 222236 bytes
2016-12-12 15:07:55,952 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merged 1 segments, 222260 bytes to disk to satisfy reduce memory limit
2016-12-12 15:07:55,953 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merging 1 files, 222264 bytes from disk
2016-12-12 15:07:55,954 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merging 0 segments, 0 bytes from memory into reduce
2016-12-12 15:07:55,955 INFO [org.apache.hadoop.mapred.Merger] - Merging 1 sorted segments
2016-12-12 15:07:55,987 INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with 1 segments left of total size: 222236 bytes
2016-12-12 15:07:55,989 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 1 / 1 copied.
2016-12-12 15:07:55,994 INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
2016-12-12 15:07:56,124 INFO [org.apache.hadoop.mapreduce.Job] - map 100% reduce 0%
2016-12-12 15:07:56,347 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local1414008937_0001_r_000000_0 is done. And is in the process of committing
2016-12-12 15:07:56,349 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 1 / 1 copied.
2016-12-12 15:07:56,349 INFO [org.apache.hadoop.mapred.Task] - Task attempt_local1414008937_0001_r_000000_0 is allowed to commit now
2016-12-12 15:07:56,357 INFO [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] - Saved output of task 'attempt_local1414008937_0001_r_000000_0' to file:/D:/Code/MyEclipseJavaCode/myMapReduce/out/weibo1/_temporary/0/task_local1414008937_0001_r_000000
2016-12-12 15:07:56,358 INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce > reduce
2016-12-12 15:07:56,359 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local1414008937_0001_r_000000_0' done.
2016-12-12 15:07:56,359 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local1414008937_0001_r_000000_0
2016-12-12 15:07:56,359 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local1414008937_0001_r_000001_0
2016-12-12 15:07:56,365 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2016-12-12 15:07:56,391 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@464d02ee
2016-12-12 15:07:56,392 INFO [org.apache.hadoop.mapred.ReduceTask] - Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@69fb7b50
2016-12-12 15:07:56,394 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - MergerManager: memoryLimit=1327077760, maxSingleShuffleLimit=331769440, mergeThreshold=875871360, ioSortFactor=10, memToMemMergeOutputsThreshold=10
2016-12-12 15:07:56,395 INFO [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] - attempt_local1414008937_0001_r_000001_0 Thread started: EventFetcher for fetching Map Completion Events
2016-12-12 15:07:56,399 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#2 about to shuffle output of map attempt_local1414008937_0001_m_000000_0 decomp: 226847 len: 226851 to MEMORY
2016-12-12 15:07:56,401 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 226847 bytes from map-output for attempt_local1414008937_0001_m_000000_0
2016-12-12 15:07:56,401 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 226847, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->226847
2016-12-12 15:07:56,402 INFO [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] - EventFetcher is interrupted.. Returning
2016-12-12 15:07:56,402 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 1 / 1 copied.
2016-12-12 15:07:56,402 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
2016-12-12 15:07:56,407 INFO [org.apache.hadoop.mapred.Merger] - Merging 1 sorted segments
2016-12-12 15:07:56,407 INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with 1 segments left of total size: 226820 bytes
2016-12-12 15:07:56,488 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merged 1 segments, 226847 bytes to disk to satisfy reduce memory limit
2016-12-12 15:07:56,488 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merging 1 files, 226851 bytes from disk
2016-12-12 15:07:56,489 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merging 0 segments, 0 bytes from memory into reduce
2016-12-12 15:07:56,489 INFO [org.apache.hadoop.mapred.Merger] - Merging 1 sorted segments
2016-12-12 15:07:56,490 INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with 1 segments left of total size: 226820 bytes
2016-12-12 15:07:56,491 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 1 / 1 copied.
2016-12-12 15:07:56,581 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local1414008937_0001_r_000001_0 is done. And is in the process of committing
2016-12-12 15:07:56,584 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 1 / 1 copied.
2016-12-12 15:07:56,584 INFO [org.apache.hadoop.mapred.Task] - Task attempt_local1414008937_0001_r_000001_0 is allowed to commit now
2016-12-12 15:07:56,591 INFO [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] - Saved output of task 'attempt_local1414008937_0001_r_000001_0' to file:/D:/Code/MyEclipseJavaCode/myMapReduce/out/weibo1/_temporary/0/task_local1414008937_0001_r_000001
2016-12-12 15:07:56,593 INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce > reduce
2016-12-12 15:07:56,593 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local1414008937_0001_r_000001_0' done.
2016-12-12 15:07:56,593 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local1414008937_0001_r_000001_0
2016-12-12 15:07:56,593 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local1414008937_0001_r_000002_0
2016-12-12 15:07:56,596 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2016-12-12 15:07:56,640 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@36d0c62b
2016-12-12 15:07:56,640 INFO [org.apache.hadoop.mapred.ReduceTask] - Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@44824d2a
2016-12-12 15:07:56,641 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - MergerManager: memoryLimit=1327077760, maxSingleShuffleLimit=331769440, mergeThreshold=875871360, ioSortFactor=10, memToMemMergeOutputsThreshold=10
2016-12-12 15:07:56,643 INFO [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] - attempt_local1414008937_0001_r_000002_0 Thread started: EventFetcher for fetching Map Completion Events
2016-12-12 15:07:56,648 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#3 about to shuffle output of map attempt_local1414008937_0001_m_000000_0 decomp: 224215 len: 224219 to MEMORY
2016-12-12 15:07:56,650 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 224215 bytes from map-output for attempt_local1414008937_0001_m_000000_0
2016-12-12 15:07:56,650 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 224215, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->224215
2016-12-12 15:07:56,651 INFO [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] - EventFetcher is interrupted.. Returning
2016-12-12 15:07:56,651 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 1 / 1 copied.
2016-12-12 15:07:56,652 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
2016-12-12 15:07:56,658 INFO [org.apache.hadoop.mapred.Merger] - Merging 1 sorted segments
2016-12-12 15:07:56,658 INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with 1 segments left of total size: 224191 bytes
2016-12-12 15:07:56,675 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merged 1 segments, 224215 bytes to disk to satisfy reduce memory limit
2016-12-12 15:07:56,676 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merging 1 files, 224219 bytes from disk
2016-12-12 15:07:56,676 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merging 0 segments, 0 bytes from memory into reduce
2016-12-12 15:07:56,676 INFO [org.apache.hadoop.mapred.Merger] - Merging 1 sorted segments
2016-12-12 15:07:56,677 INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with 1 segments left of total size: 224191 bytes
2016-12-12 15:07:56,678 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 1 / 1 copied.
2016-12-12 15:07:56,711 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local1414008937_0001_r_000002_0 is done. And is in the process of committing
2016-12-12 15:07:56,714 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 1 / 1 copied.
2016-12-12 15:07:56,714 INFO [org.apache.hadoop.mapred.Task] - Task attempt_local1414008937_0001_r_000002_0 is allowed to commit now
2016-12-12 15:07:56,725 INFO [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] - Saved output of task 'attempt_local1414008937_0001_r_000002_0' to file:/D:/Code/MyEclipseJavaCode/myMapReduce/out/weibo1/_temporary/0/task_local1414008937_0001_r_000002
2016-12-12 15:07:56,726 INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce > reduce
2016-12-12 15:07:56,727 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local1414008937_0001_r_000002_0' done.
2016-12-12 15:07:56,727 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local1414008937_0001_r_000002_0
2016-12-12 15:07:56,727 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local1414008937_0001_r_000003_0
2016-12-12 15:07:56,729 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2016-12-12 15:07:56,749 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@42ed705f
2016-12-12 15:07:56,750 INFO [org.apache.hadoop.mapred.ReduceTask] - Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@726c8f4c
2016-12-12 15:07:56,751 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - MergerManager: memoryLimit=1327077760, maxSingleShuffleLimit=331769440, mergeThreshold=875871360, ioSortFactor=10, memToMemMergeOutputsThreshold=10
2016-12-12 15:07:56,752 INFO [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] - attempt_local1414008937_0001_r_000003_0 Thread started: EventFetcher for fetching Map Completion Events
2016-12-12 15:07:56,757 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#4 about to shuffle output of map attempt_local1414008937_0001_m_000000_0 decomp: 14 len: 18 to MEMORY
2016-12-12 15:07:56,758 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 14 bytes from map-output for attempt_local1414008937_0001_m_000000_0
2016-12-12 15:07:56,758 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 14, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->14
2016-12-12 15:07:56,759 INFO [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] - EventFetcher is interrupted.. Returning
2016-12-12 15:07:56,759 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 1 / 1 copied.
2016-12-12 15:07:56,759 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
2016-12-12 15:07:56,764 INFO [org.apache.hadoop.mapred.Merger] - Merging 1 sorted segments
2016-12-12 15:07:56,764 INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with 1 segments left of total size: 6 bytes
2016-12-12 15:07:56,765 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merged 1 segments, 14 bytes to disk to satisfy reduce memory limit
2016-12-12 15:07:56,765 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merging 1 files, 18 bytes from disk
2016-12-12 15:07:56,765 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merging 0 segments, 0 bytes from memory into reduce
2016-12-12 15:07:56,765 INFO [org.apache.hadoop.mapred.Merger] - Merging 1 sorted segments
2016-12-12 15:07:56,766 INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with 1 segments left of total size: 6 bytes
2016-12-12 15:07:56,766 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 1 / 1 copied.
count___________1065
2016-12-12 15:07:56,770 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local1414008937_0001_r_000003_0 is done. And is in the process of committing
2016-12-12 15:07:56,771 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 1 / 1 copied.
2016-12-12 15:07:56,771 INFO [org.apache.hadoop.mapred.Task] - Task attempt_local1414008937_0001_r_000003_0 is allowed to commit now
2016-12-12 15:07:56,777 INFO [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] - Saved output of task 'attempt_local1414008937_0001_r_000003_0' to file:/D:/Code/MyEclipseJavaCode/myMapReduce/out/weibo1/_temporary/0/task_local1414008937_0001_r_000003
2016-12-12 15:07:56,778 INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce > reduce
2016-12-12 15:07:56,778 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local1414008937_0001_r_000003_0' done.
2016-12-12 15:07:56,778 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local1414008937_0001_r_000003_0
2016-12-12 15:07:56,779 INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce task executor complete.
2016-12-12 15:07:57,127 INFO [org.apache.hadoop.mapreduce.Job] - map 100% reduce 100%
2016-12-12 15:07:57,137 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local1414008937_0001 completed successfully
2016-12-12 15:07:57,186 INFO [org.apache.hadoop.mapreduce.Job] - Counters: 33
File System Counters
FILE: Number of bytes read=4937350
FILE: Number of bytes written=8113860
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=1065
Map output records=28312
Map output bytes=747379
Map output materialized bytes=673352
Input split bytes=127
Combine input records=28312
Combine output records=23098
Reduce input groups=23098
Reduce shuffle bytes=673352
Reduce input records=23098
Reduce output records=23098
Spilled Records=46196
Shuffled Maps =4
Failed Shuffles=0
Merged Map outputs=4
GC time elapsed (ms)=165
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=1672478720
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=174116
File Output Format Counters
Bytes Written=585532

执行
2016-12-12 15:10:36,011 INFO [org.apache.hadoop.metrics.jvm.JvmMetrics] - Initializing JVM Metrics with processName=JobTracker, sessionId=
2016-12-12 15:10:36,436 WARN [org.apache.hadoop.mapreduce.JobSubmitter] - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2016-12-12 15:10:36,438 WARN [org.apache.hadoop.mapreduce.JobSubmitter] - No job jar file set. User classes may not be found. See Job or Job#setJar(String).
2016-12-12 15:10:36,892 INFO [org.apache.hadoop.mapreduce.lib.input.FileInputFormat] - Total input paths to process : 4
2016-12-12 15:10:36,959 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - number of splits:4
2016-12-12 15:10:37,215 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - Submitting tokens for job: job_local564512176_0001
2016-12-12 15:10:37,668 INFO [org.apache.hadoop.mapreduce.Job] - The url to track the job: http://localhost:8080/
2016-12-12 15:10:37,670 INFO [org.apache.hadoop.mapreduce.Job] - Running job: job_local564512176_0001
2016-12-12 15:10:37,672 INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter set in config null
2016-12-12 15:10:37,685 INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
2016-12-12 15:10:37,757 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Waiting for map tasks
2016-12-12 15:10:37,759 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local564512176_0001_m_000000_0
2016-12-12 15:10:37,822 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2016-12-12 15:10:37,854 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@12633e10
2016-12-12 15:10:37,861 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: file:/D:/Code/MyEclipseJavaCode/myMapReduce/out/weibo1/part-r-00001:0+195718
2016-12-12 15:10:37,924 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)
2016-12-12 15:10:37,924 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100
2016-12-12 15:10:37,925 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080
2016-12-12 15:10:37,925 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600
2016-12-12 15:10:37,925 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600
2016-12-12 15:10:37,932 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2016-12-12 15:10:38,401 INFO [org.apache.hadoop.mapred.LocalJobRunner] -
2016-12-12 15:10:38,402 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
2016-12-12 15:10:38,402 INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output
2016-12-12 15:10:38,402 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufend = 78968; bufvoid = 104857600
2016-12-12 15:10:38,402 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396(104857584); kvend = 26183268(104733072); length = 31129/6553600
2016-12-12 15:10:38,673 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local564512176_0001 running in uber mode : false
2016-12-12 15:10:38,676 INFO [org.apache.hadoop.mapreduce.Job] - map 0% reduce 0%
2016-12-12 15:10:38,724 INFO [org.apache.hadoop.mapred.MapTask] - Finished spill 0
2016-12-12 15:10:38,730 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local564512176_0001_m_000000_0 is done. And is in the process of committing
2016-12-12 15:10:38,744 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
2016-12-12 15:10:38,744 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local564512176_0001_m_000000_0' done.
2016-12-12 15:10:38,745 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local564512176_0001_m_000000_0
2016-12-12 15:10:38,745 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local564512176_0001_m_000001_0
2016-12-12 15:10:38,748 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2016-12-12 15:10:38,778 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@43aa735f
2016-12-12 15:10:38,784 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: file:/D:/Code/MyEclipseJavaCode/myMapReduce/out/weibo1/part-r-00002:0+193443
2016-12-12 15:10:38,820 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)
2016-12-12 15:10:38,820 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100
2016-12-12 15:10:38,820 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080
2016-12-12 15:10:38,821 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600
2016-12-12 15:10:38,821 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600
2016-12-12 15:10:38,822 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2016-12-12 15:10:39,017 INFO [org.apache.hadoop.mapred.LocalJobRunner] -
2016-12-12 15:10:39,017 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
2016-12-12 15:10:39,018 INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output
2016-12-12 15:10:39,018 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufend = 78027; bufvoid = 104857600
2016-12-12 15:10:39,018 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396(104857584); kvend = 26183624(104734496); length = 30773/6553600
2016-12-12 15:10:39,157 INFO [org.apache.hadoop.mapred.MapTask] - Finished spill 0
2016-12-12 15:10:39,162 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local564512176_0001_m_000001_0 is done. And is in the process of committing
2016-12-12 15:10:39,166 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
2016-12-12 15:10:39,166 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local564512176_0001_m_000001_0' done.
2016-12-12 15:10:39,166 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local564512176_0001_m_000001_0
2016-12-12 15:10:39,167 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local564512176_0001_m_000002_0
2016-12-12 15:10:39,171 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2016-12-12 15:10:39,219 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@405f4f03
2016-12-12 15:10:39,222 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: file:/D:/Code/MyEclipseJavaCode/myMapReduce/out/weibo1/part-r-00000:0+191780
2016-12-12 15:10:39,265 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)
2016-12-12 15:10:39,265 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100
2016-12-12 15:10:39,265 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080
2016-12-12 15:10:39,265 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600
2016-12-12 15:10:39,265 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600
2016-12-12 15:10:39,270 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2016-12-12 15:10:39,311 INFO [org.apache.hadoop.mapred.LocalJobRunner] -
2016-12-12 15:10:39,311 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
2016-12-12 15:10:39,311 INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output
2016-12-12 15:10:39,311 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufend = 77478; bufvoid = 104857600
2016-12-12 15:10:39,312 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396(104857584); kvend = 26183920(104735680); length = 30477/6553600
2016-12-12 15:10:39,360 INFO [org.apache.hadoop.mapred.MapTask] - Finished spill 0
2016-12-12 15:10:39,365 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local564512176_0001_m_000002_0 is done. And is in the process of committing
2016-12-12 15:10:39,368 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
2016-12-12 15:10:39,369 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local564512176_0001_m_000002_0' done.
2016-12-12 15:10:39,369 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local564512176_0001_m_000002_0
2016-12-12 15:10:39,369 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local564512176_0001_m_000003_0
2016-12-12 15:10:39,372 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2016-12-12 15:10:39,416 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@4e5497cb
2016-12-12 15:10:39,419 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: file:/D:/Code/MyEclipseJavaCode/myMapReduce/out/weibo1/part-r-00003:0+11
2016-12-12 15:10:39,461 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)
2016-12-12 15:10:39,461 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100
2016-12-12 15:10:39,461 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080
2016-12-12 15:10:39,461 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600
2016-12-12 15:10:39,462 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600
2016-12-12 15:10:39,463 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2016-12-12 15:10:39,466 INFO [org.apache.hadoop.mapred.LocalJobRunner] -
2016-12-12 15:10:39,466 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
2016-12-12 15:10:39,479 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local564512176_0001_m_000003_0 is done. And is in the process of committing
2016-12-12 15:10:39,482 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
2016-12-12 15:10:39,482 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local564512176_0001_m_000003_0' done.
2016-12-12 15:10:39,482 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local564512176_0001_m_000003_0
2016-12-12 15:10:39,482 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map task executor complete.
2016-12-12 15:10:39,487 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Waiting for reduce tasks
2016-12-12 15:10:39,488 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local564512176_0001_r_000000_0
2016-12-12 15:10:39,497 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2016-12-12 15:10:39,519 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@6d565f45
2016-12-12 15:10:39,523 INFO [org.apache.hadoop.mapred.ReduceTask] - Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@1f719a8d
2016-12-12 15:10:39,538 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - MergerManager: memoryLimit=1327077760, maxSingleShuffleLimit=331769440, mergeThreshold=875871360, ioSortFactor=10, memToMemMergeOutputsThreshold=10
2016-12-12 15:10:39,541 INFO [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] - attempt_local564512176_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
2016-12-12 15:10:39,583 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#1 about to shuffle output of map attempt_local564512176_0001_m_000002_0 decomp: 37768 len: 37772 to MEMORY
2016-12-12 15:10:39,589 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 37768 bytes from map-output for attempt_local564512176_0001_m_000002_0
2016-12-12 15:10:39,638 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 37768, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->37768
2016-12-12 15:10:39,644 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#1 about to shuffle output of map attempt_local564512176_0001_m_000001_0 decomp: 37233 len: 37237 to MEMORY
2016-12-12 15:10:39,646 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 37233 bytes from map-output for attempt_local564512176_0001_m_000001_0
2016-12-12 15:10:39,647 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 37233, inMemoryMapOutputs.size() -> 2, commitMemory -> 37768, usedMemory ->75001
2016-12-12 15:10:39,652 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#1 about to shuffle output of map attempt_local564512176_0001_m_000000_0 decomp: 37343 len: 37347 to MEMORY
2016-12-12 15:10:39,653 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 37343 bytes from map-output for attempt_local564512176_0001_m_000000_0
2016-12-12 15:10:39,654 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 37343, inMemoryMapOutputs.size() -> 3, commitMemory -> 75001, usedMemory ->112344
2016-12-12 15:10:39,658 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#1 about to shuffle output of map attempt_local564512176_0001_m_000003_0 decomp: 2 len: 6 to MEMORY
2016-12-12 15:10:39,659 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 2 bytes from map-output for attempt_local564512176_0001_m_000003_0
2016-12-12 15:10:39,660 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 2, inMemoryMapOutputs.size() -> 4, commitMemory -> 112344, usedMemory ->112346
2016-12-12 15:10:39,660 INFO [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] - EventFetcher is interrupted.. Returning
2016-12-12 15:10:39,661 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 4 / 4 copied.
2016-12-12 15:10:39,662 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - finalMerge called with 4 in-memory map-outputs and 0 on-disk map-outputs
2016-12-12 15:10:39,673 INFO [org.apache.hadoop.mapred.Merger] - Merging 4 sorted segments
2016-12-12 15:10:39,674 INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with 3 segments left of total size: 112332 bytes
2016-12-12 15:10:39,678 INFO [org.apache.hadoop.mapreduce.Job] - map 100% reduce 0%
2016-12-12 15:10:39,780 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merged 4 segments, 112346 bytes to disk to satisfy reduce memory limit
2016-12-12 15:10:39,781 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merging 1 files, 112344 bytes from disk
2016-12-12 15:10:39,783 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merging 0 segments, 0 bytes from memory into reduce
2016-12-12 15:10:39,784 INFO [org.apache.hadoop.mapred.Merger] - Merging 1 sorted segments
2016-12-12 15:10:39,785 INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with 1 segments left of total size: 112336 bytes
2016-12-12 15:10:39,785 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 4 / 4 copied.
2016-12-12 15:10:39,792 INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
2016-12-12 15:10:40,343 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local564512176_0001_r_000000_0 is done. And is in the process of committing
2016-12-12 15:10:40,346 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 4 / 4 copied.
2016-12-12 15:10:40,346 INFO [org.apache.hadoop.mapred.Task] - Task attempt_local564512176_0001_r_000000_0 is allowed to commit now
2016-12-12 15:10:40,353 INFO [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] - Saved output of task 'attempt_local564512176_0001_r_000000_0' to file:/D:/Code/MyEclipseJavaCode/myMapReduce/out/weibo2/_temporary/0/task_local564512176_0001_r_000000
2016-12-12 15:10:40,363 INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce > reduce
2016-12-12 15:10:40,364 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local564512176_0001_r_000000_0' done.
2016-12-12 15:10:40,364 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local564512176_0001_r_000000_0
2016-12-12 15:10:40,364 INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce task executor complete.
2016-12-12 15:10:40,678 INFO [org.apache.hadoop.mapreduce.Job] - map 100% reduce 100%
2016-12-12 15:10:40,678 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local564512176_0001 completed successfully
2016-12-12 15:10:40,701 INFO [org.apache.hadoop.mapreduce.Job] - Counters: 33
File System Counters
FILE: Number of bytes read=2579152
FILE: Number of bytes written=1581170
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=23098
Map output records=23097
Map output bytes=234473
Map output materialized bytes=112362
Input split bytes=528
Combine input records=23097
Combine output records=8774
Reduce input groups=5567
Reduce shuffle bytes=112362
Reduce input records=8774
Reduce output records=5567
Spilled Records=17548
Shuffled Maps =4
Failed Shuffles=0
Merged Map outputs=4
GC time elapsed (ms)=48
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=2114977792
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=585564
File Output Format Counters
Bytes Written=50762
执行job成功

执行
2016-12-12 15:12:33,225 INFO [org.apache.hadoop.metrics.jvm.JvmMetrics] - Initializing JVM Metrics with processName=JobTracker, sessionId=
2016-12-12 15:12:33,823 WARN [org.apache.hadoop.mapreduce.JobSubmitter] - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2016-12-12 15:12:33,824 WARN [org.apache.hadoop.mapreduce.JobSubmitter] - No job jar file set. User classes may not be found. See Job or Job#setJar(String).
2016-12-12 15:12:34,364 INFO [org.apache.hadoop.mapreduce.lib.input.FileInputFormat] - Total input paths to process : 4
2016-12-12 15:12:34,410 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - number of splits:4
2016-12-12 15:12:34,729 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - Submitting tokens for job: job_local671371338_0001
2016-12-12 15:12:35,471 INFO [org.apache.hadoop.mapred.LocalDistributedCacheManager] - Creating symlink: \tmp\hadoop-Administrator\mapred\local\1481526755080\part-r-00003 <- D:\Code\MyEclipseJavaCode\myMapReduce/part-r-00003
2016-12-12 15:12:35,516 INFO [org.apache.hadoop.mapred.LocalDistributedCacheManager] - Localized file:/D:/Code/MyEclipseJavaCode/myMapReduce/out/weibo1/part-r-00003 as file:/tmp/hadoop-Administrator/mapred/local/1481526755080/part-r-00003
2016-12-12 15:12:35,521 INFO [org.apache.hadoop.mapred.LocalDistributedCacheManager] - Creating symlink: \tmp\hadoop-Administrator\mapred\local\1481526755081\part-r-00000 <- D:\Code\MyEclipseJavaCode\myMapReduce/part-r-00000
2016-12-12 15:12:35,544 INFO [org.apache.hadoop.mapred.LocalDistributedCacheManager] - Localized file:/D:/Code/MyEclipseJavaCode/myMapReduce/out/weibo2/part-r-00000 as file:/tmp/hadoop-Administrator/mapred/local/1481526755081/part-r-00000
2016-12-12 15:12:35,696 INFO [org.apache.hadoop.mapreduce.Job] - The url to track the job: http://localhost:8080/
2016-12-12 15:12:35,697 INFO [org.apache.hadoop.mapreduce.Job] - Running job: job_local671371338_0001
2016-12-12 15:12:35,703 INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter set in config null
2016-12-12 15:12:35,715 INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
2016-12-12 15:12:35,772 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Waiting for map tasks
2016-12-12 15:12:35,772 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local671371338_0001_m_000000_0
2016-12-12 15:12:35,819 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2016-12-12 15:12:35,852 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@50b97c8b
2016-12-12 15:12:35,858 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: file:/D:/Code/MyEclipseJavaCode/myMapReduce/out/weibo1/part-r-00001:0+195718
2016-12-12 15:12:35,926 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)
2016-12-12 15:12:35,926 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100
2016-12-12 15:12:35,926 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080
2016-12-12 15:12:35,926 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600
2016-12-12 15:12:35,927 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600
2016-12-12 15:12:35,938 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
******************
2016-12-12 15:12:36,701 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local671371338_0001 running in uber mode : false
2016-12-12 15:12:36,703 INFO [org.apache.hadoop.mapreduce.Job] - map 0% reduce 0%
2016-12-12 15:12:36,965 INFO [org.apache.hadoop.mapred.LocalJobRunner] -
2016-12-12 15:12:36,966 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
2016-12-12 15:12:36,966 INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output
2016-12-12 15:12:36,966 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufend = 239755; bufvoid = 104857600
2016-12-12 15:12:36,966 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396(104857584); kvend = 26183268(104733072); length = 31129/6553600
2016-12-12 15:12:37,135 INFO [org.apache.hadoop.mapred.MapTask] - Finished spill 0
2016-12-12 15:12:37,141 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local671371338_0001_m_000000_0 is done. And is in the process of committing
2016-12-12 15:12:37,153 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
2016-12-12 15:12:37,153 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local671371338_0001_m_000000_0' done.
2016-12-12 15:12:37,154 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local671371338_0001_m_000000_0
2016-12-12 15:12:37,154 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local671371338_0001_m_000001_0
2016-12-12 15:12:37,156 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2016-12-12 15:12:37,191 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@70849e34
2016-12-12 15:12:37,194 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: file:/D:/Code/MyEclipseJavaCode/myMapReduce/out/weibo1/part-r-00002:0+193443
2016-12-12 15:12:37,229 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)
2016-12-12 15:12:37,229 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100
2016-12-12 15:12:37,229 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080
2016-12-12 15:12:37,230 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600
2016-12-12 15:12:37,230 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600
2016-12-12 15:12:37,230 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
******************
2016-12-12 15:12:37,601 INFO [org.apache.hadoop.mapred.LocalJobRunner] -
2016-12-12 15:12:37,602 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
2016-12-12 15:12:37,602 INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output
2016-12-12 15:12:37,602 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufend = 237126; bufvoid = 104857600
2016-12-12 15:12:37,602 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396(104857584); kvend = 26183624(104734496); length = 30773/6553600
2016-12-12 15:12:37,651 INFO [org.apache.hadoop.mapred.MapTask] - Finished spill 0
2016-12-12 15:12:37,683 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local671371338_0001_m_000001_0 is done. And is in the process of committing
2016-12-12 15:12:37,687 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
2016-12-12 15:12:37,687 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local671371338_0001_m_000001_0' done.
2016-12-12 15:12:37,687 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local671371338_0001_m_000001_0
2016-12-12 15:12:37,687 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local671371338_0001_m_000002_0
2016-12-12 15:12:37,690 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2016-12-12 15:12:37,722 INFO [org.apache.hadoop.mapreduce.Job] - map 100% reduce 0%
2016-12-12 15:12:37,810 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@544b0d4c
2016-12-12 15:12:37,813 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: file:/D:/Code/MyEclipseJavaCode/myMapReduce/out/weibo1/part-r-00000:0+191780
2016-12-12 15:12:37,851 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)
2016-12-12 15:12:37,851 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100
2016-12-12 15:12:37,851 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080
2016-12-12 15:12:37,851 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600
2016-12-12 15:12:37,852 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600
2016-12-12 15:12:37,853 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
******************
2016-12-12 15:12:37,915 INFO [org.apache.hadoop.mapred.LocalJobRunner] -
2016-12-12 15:12:37,915 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
2016-12-12 15:12:37,916 INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output
2016-12-12 15:12:37,916 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufend = 234731; bufvoid = 104857600
2016-12-12 15:12:37,916 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396(104857584); kvend = 26183920(104735680); length = 30477/6553600
2016-12-12 15:12:37,939 INFO [org.apache.hadoop.mapred.MapTask] - Finished spill 0
2016-12-12 15:12:37,943 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local671371338_0001_m_000002_0 is done. And is in the process of committing
2016-12-12 15:12:37,946 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
2016-12-12 15:12:37,946 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local671371338_0001_m_000002_0' done.
2016-12-12 15:12:37,946 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local671371338_0001_m_000002_0
2016-12-12 15:12:37,947 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local671371338_0001_m_000003_0
2016-12-12 15:12:37,950 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2016-12-12 15:12:37,999 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@6c241f31
2016-12-12 15:12:38,002 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: file:/D:/Code/MyEclipseJavaCode/myMapReduce/out/weibo1/part-r-00003:0+11
2016-12-12 15:12:38,046 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)
2016-12-12 15:12:38,046 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100
2016-12-12 15:12:38,046 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080
2016-12-12 15:12:38,046 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600
2016-12-12 15:12:38,046 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600
2016-12-12 15:12:38,047 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
******************
2016-12-12 15:12:38,050 INFO [org.apache.hadoop.mapred.LocalJobRunner] -
2016-12-12 15:12:38,050 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
2016-12-12 15:12:38,060 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local671371338_0001_m_000003_0 is done. And is in the process of committing
2016-12-12 15:12:38,063 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
2016-12-12 15:12:38,063 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local671371338_0001_m_000003_0' done.
2016-12-12 15:12:38,064 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local671371338_0001_m_000003_0
2016-12-12 15:12:38,064 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map task executor complete.
2016-12-12 15:12:38,067 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Waiting for reduce tasks
2016-12-12 15:12:38,067 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local671371338_0001_r_000000_0
2016-12-12 15:12:38,079 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2016-12-12 15:12:38,104 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@777da320
2016-12-12 15:12:38,116 INFO [org.apache.hadoop.mapred.ReduceTask] - Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@76a01b4b
2016-12-12 15:12:38,133 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - MergerManager: memoryLimit=1327077760, maxSingleShuffleLimit=331769440, mergeThreshold=875871360, ioSortFactor=10, memToMemMergeOutputsThreshold=10
2016-12-12 15:12:38,135 INFO [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] - attempt_local671371338_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
2016-12-12 15:12:38,165 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#1 about to shuffle output of map attempt_local671371338_0001_m_000001_0 decomp: 252516 len: 252520 to MEMORY
2016-12-12 15:12:38,169 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 252516 bytes from map-output for attempt_local671371338_0001_m_000001_0
2016-12-12 15:12:38,216 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 252516, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->252516
2016-12-12 15:12:38,221 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#1 about to shuffle output of map attempt_local671371338_0001_m_000002_0 decomp: 249973 len: 249977 to MEMORY
2016-12-12 15:12:38,223 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 249973 bytes from map-output for attempt_local671371338_0001_m_000002_0
2016-12-12 15:12:38,224 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 249973, inMemoryMapOutputs.size() -> 2, commitMemory -> 252516, usedMemory ->502489
2016-12-12 15:12:38,230 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#1 about to shuffle output of map attempt_local671371338_0001_m_000000_0 decomp: 255323 len: 255327 to MEMORY
2016-12-12 15:12:38,233 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 255323 bytes from map-output for attempt_local671371338_0001_m_000000_0
2016-12-12 15:12:38,233 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 255323, inMemoryMapOutputs.size() -> 3, commitMemory -> 502489, usedMemory ->757812
2016-12-12 15:12:38,235 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#1 about to shuffle output of map attempt_local671371338_0001_m_000003_0 decomp: 2 len: 6 to MEMORY
2016-12-12 15:12:38,236 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 2 bytes from map-output for attempt_local671371338_0001_m_000003_0
2016-12-12 15:12:38,236 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 2, inMemoryMapOutputs.size() -> 4, commitMemory -> 757812, usedMemory ->757814
2016-12-12 15:12:38,237 INFO [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] - EventFetcher is interrupted.. Returning
2016-12-12 15:12:38,238 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 4 / 4 copied.
2016-12-12 15:12:38,238 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - finalMerge called with 4 in-memory map-outputs and 0 on-disk map-outputs
2016-12-12 15:12:38,252 INFO [org.apache.hadoop.mapred.Merger] - Merging 4 sorted segments
2016-12-12 15:12:38,253 INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with 3 segments left of total size: 757755 bytes
2016-12-12 15:12:38,413 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merged 4 segments, 757814 bytes to disk to satisfy reduce memory limit
2016-12-12 15:12:38,414 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merging 1 files, 757812 bytes from disk
2016-12-12 15:12:38,415 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merging 0 segments, 0 bytes from memory into reduce
2016-12-12 15:12:38,415 INFO [org.apache.hadoop.mapred.Merger] - Merging 1 sorted segments
2016-12-12 15:12:38,416 INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with 1 segments left of total size: 757789 bytes
2016-12-12 15:12:38,433 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 4 / 4 copied.
2016-12-12 15:12:38,439 INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
2016-12-12 15:12:38,844 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local671371338_0001_r_000000_0 is done. And is in the process of committing
2016-12-12 15:12:38,846 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 4 / 4 copied.
2016-12-12 15:12:38,846 INFO [org.apache.hadoop.mapred.Task] - Task attempt_local671371338_0001_r_000000_0 is allowed to commit now
2016-12-12 15:12:38,857 INFO [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] - Saved output of task 'attempt_local671371338_0001_r_000000_0' to file:/D:/Code/MyEclipseJavaCode/myMapReduce/out/weibo3/_temporary/0/task_local671371338_0001_r_000000
2016-12-12 15:12:38,861 INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce > reduce
2016-12-12 15:12:38,861 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local671371338_0001_r_000000_0' done.
2016-12-12 15:12:38,861 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local671371338_0001_r_000000_0
2016-12-12 15:12:38,862 INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce task executor complete.
2016-12-12 15:12:39,724 INFO [org.apache.hadoop.mapreduce.Job] - map 100% reduce 100%
2016-12-12 15:12:39,726 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local671371338_0001 completed successfully
2016-12-12 15:12:39,841 INFO [org.apache.hadoop.mapreduce.Job] - Counters: 33
File System Counters
FILE: Number of bytes read=4124093
FILE: Number of bytes written=5365498
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=23098
Map output records=23097
Map output bytes=711612
Map output materialized bytes=757830
Input split bytes=528
Combine input records=0
Combine output records=0
Reduce input groups=1065
Reduce shuffle bytes=757830
Reduce input records=23097
Reduce output records=1065
Spilled Records=46194
Shuffled Maps =4
Failed Shuffles=0
Merged Map outputs=4
GC time elapsed (ms)=30
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=2353528832
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=585564
File Output Format Counters
Bytes Written=340785
执行job成功
代码
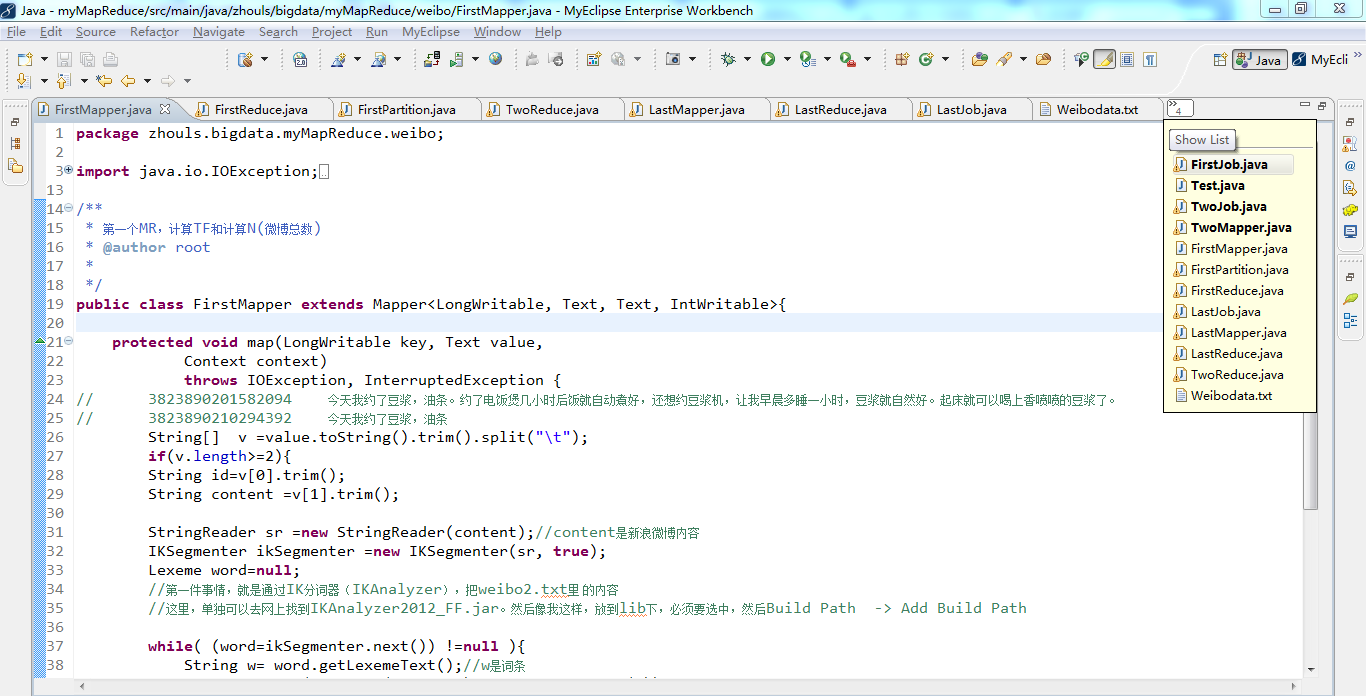
1 package zhouls.bigdata.myMapReduce.weibo; 2 3 import java.io.IOException; 4 5 import java.io.StringReader; 6 7 import org.apache.hadoop.io.IntWritable; 8 import org.apache.hadoop.io.LongWritable; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapreduce.Mapper; 11 import org.wltea.analyzer.core.IKSegmenter; 12 import org.wltea.analyzer.core.Lexeme; 13 14 /** 15 * 第一个MR,计算TF和计算N(微博总数) 16 * @author root 17 * 18 */ 19 public class FirstMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ 20 21 protected void map(LongWritable key, Text value, 22 Context context) 23 throws IOException, InterruptedException { 24 // 3823890201582094 今天我约了豆浆,油条。约了电饭煲几小时后饭就自动煮好,还想约豆浆机,让我早晨多睡一小时,豆浆就自然好。起床就可以喝上香喷喷的豆浆了。 25 // 3823890210294392 今天我约了豆浆,油条 26 String[] v =value.toString().trim().split("\t"); 27 if(v.length>=2){ 28 String id=v[0].trim(); 29 String content =v[1].trim(); 30 31 StringReader sr =new StringReader(content);//content是新浪微博内容 32 IKSegmenter ikSegmenter =new IKSegmenter(sr, true); 33 Lexeme word=null; 34 //第一件事情,就是通过IK分词器(IKAnalyzer),把weibo2.txt里 的内容 35 //这里,单独可以去网上找到IKAnalyzer2012_FF.jar。然后像我这样,放到lib下,必须要选中,然后Build Path -> Add Build Path 36 37 while( (word=ikSegmenter.next()) !=null ){ 38 String w= word.getLexemeText();//w是词条 39 context.write(new Text(w+"_"+id), new IntWritable(1)); 40 } 41 context.write(new Text("count"), new IntWritable(1)); 42 }else{ 43 System.out.println(value.toString()+"-------------");//为什么要来----------,是因为方便统计TF,因为TF是某一篇微博词条的词频。 44 } 45 } 46 47 48 49 }
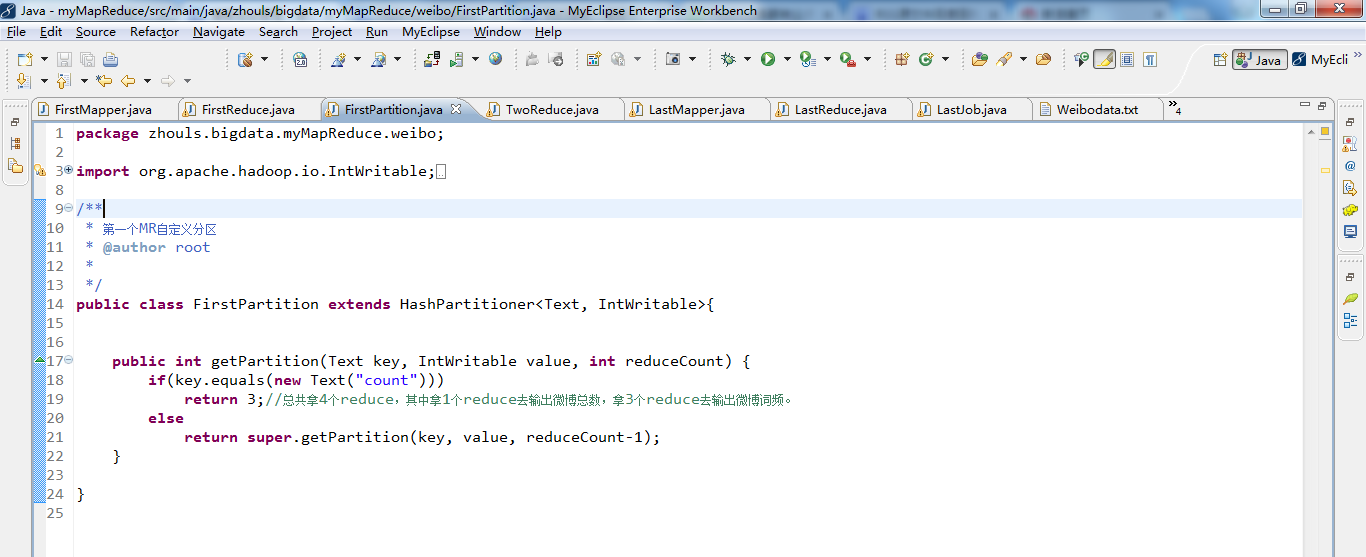
1 package zhouls.bigdata.myMapReduce.weibo; 2 3 import org.apache.hadoop.io.IntWritable; 4 import org.apache.hadoop.io.LongWritable; 5 import org.apache.hadoop.io.Text; 6 import org.apache.hadoop.mapreduce.Partitioner; 7 import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner; 8 9 /** 10 * 第一个MR自定义分区 11 * @author root 12 * 13 */ 14 public class FirstPartition extends HashPartitioner<Text, IntWritable>{ 15 16 17 public int getPartition(Text key, IntWritable value, int reduceCount) { 18 if(key.equals(new Text("count"))) 19 return 3;//总共拿4个reduce,其中拿1个reduce去输出微博总数,拿3个reduce去输出微博词频。 20 else 21 return super.getPartition(key, value, reduceCount-1); 22 } 23 24 }
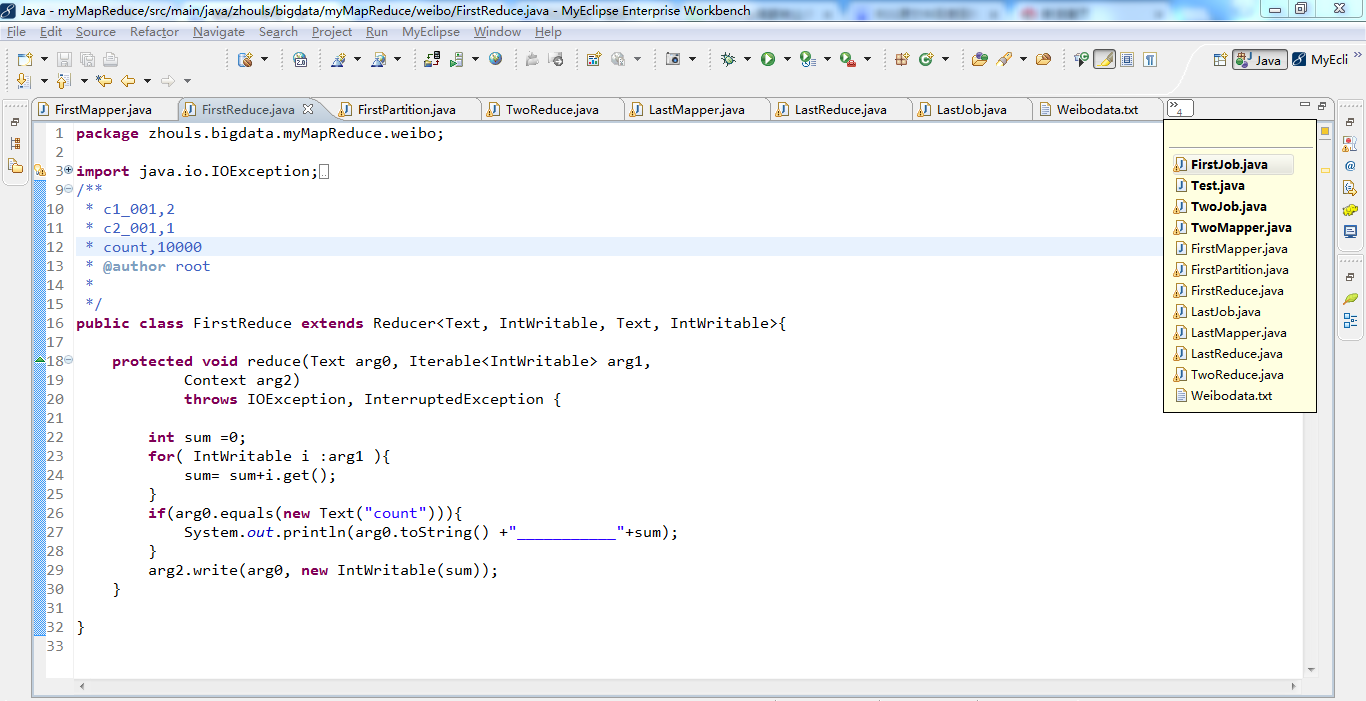
1 package zhouls.bigdata.myMapReduce.weibo; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.io.IntWritable; 6 import org.apache.hadoop.io.LongWritable; 7 import org.apache.hadoop.io.Text; 8 import org.apache.hadoop.mapreduce.Reducer; 9 /** 10 * c1_001,2 11 * c2_001,1 12 * count,10000 13 * @author root 14 * 15 */ 16 public class FirstReduce extends Reducer<Text, IntWritable, Text, IntWritable>{ 17 18 protected void reduce(Text arg0, Iterable<IntWritable> arg1, 19 Context arg2) 20 throws IOException, InterruptedException { 21 22 int sum =0; 23 for( IntWritable i :arg1 ){ 24 sum= sum+i.get(); 25 } 26 if(arg0.equals(new Text("count"))){ 27 System.out.println(arg0.toString() +"___________"+sum); 28 } 29 arg2.write(arg0, new IntWritable(sum)); 30 } 31 32 }
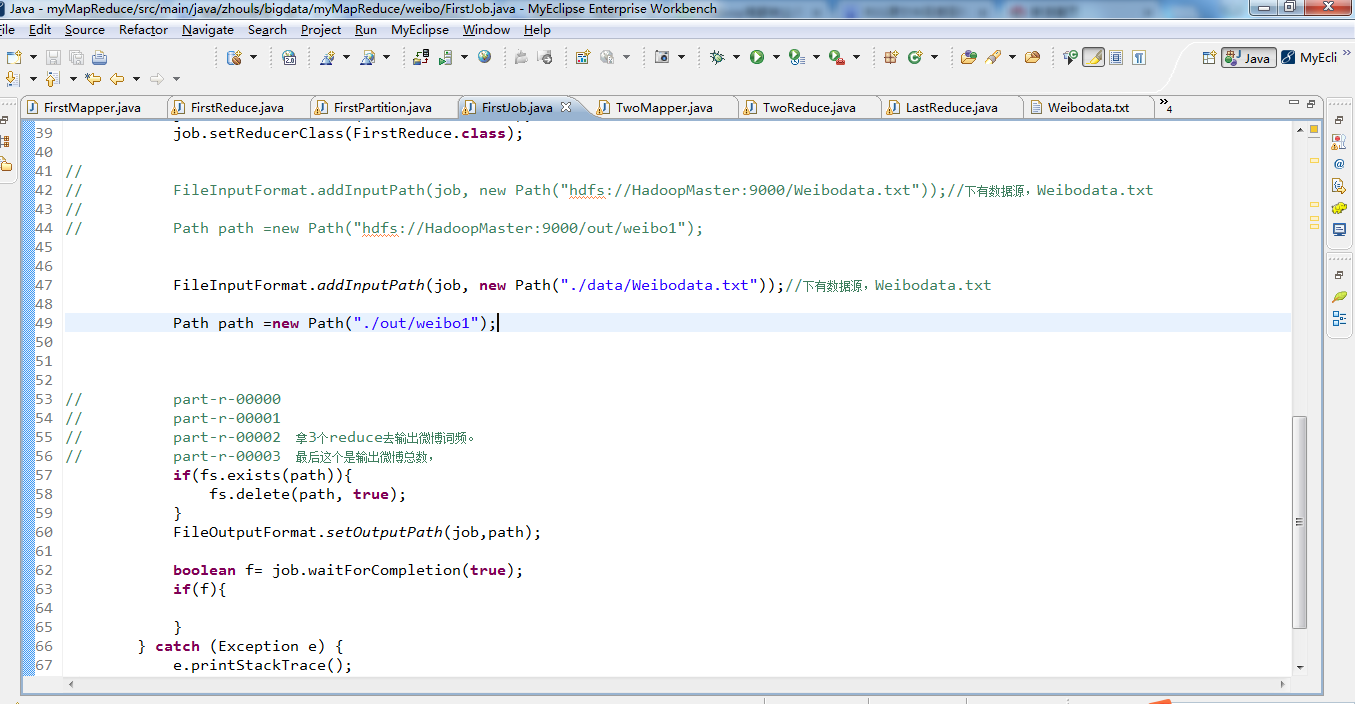
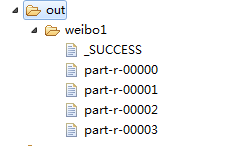
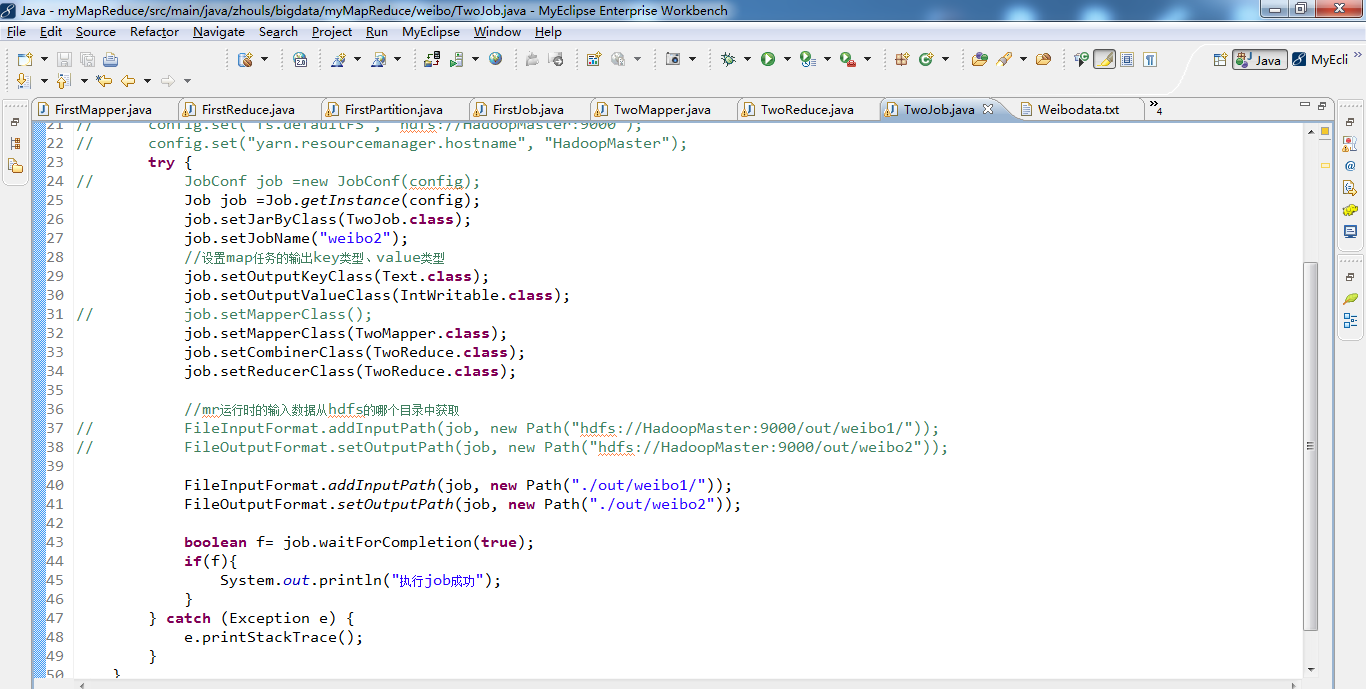
1 package zhouls.bigdata.myMapReduce.weibo; 2 3 4 import java.io.IOException; 5 6 import org.apache.hadoop.conf.Configuration; 7 import org.apache.hadoop.fs.FileSystem; 8 import org.apache.hadoop.fs.Path; 9 import org.apache.hadoop.io.IntWritable; 10 import org.apache.hadoop.io.LongWritable; 11 import org.apache.hadoop.io.Text; 12 import org.apache.hadoop.mapred.JobConf; 13 import org.apache.hadoop.mapred.TextInputFormat; 14 import org.apache.hadoop.mapreduce.Job; 15 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 16 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 17 18 19 public class FirstJob { 20 21 public static void main(String[] args) { 22 Configuration config =new Configuration(); 23 // config.set("fs.defaultFS", "hdfs://HadoopMaster:9000"); 24 // config.set("yarn.resourcemanager.hostname", "HadoopMaster"); 25 try { 26 FileSystem fs =FileSystem.get(config); 27 // JobConf job =new JobConf(config); 28 Job job =Job.getInstance(config); 29 job.setJarByClass(FirstJob.class); 30 job.setJobName("weibo1"); 31 32 job.setOutputKeyClass(Text.class); 33 job.setOutputValueClass(IntWritable.class); 34 // job.setMapperClass(); 35 job.setNumReduceTasks(4); 36 job.setPartitionerClass(FirstPartition.class); 37 job.setMapperClass(FirstMapper.class); 38 job.setCombinerClass(FirstReduce.class); 39 job.setReducerClass(FirstReduce.class); 40 41 // 42 // FileInputFormat.addInputPath(job, new Path("hdfs://HadoopMaster:9000/Weibodata.txt"));//下有数据源,Weibodata.txt 43 // 44 // Path path =new Path("hdfs://HadoopMaster:9000/out/weibo1"); 45 46 47 FileInputFormat.addInputPath(job, new Path("./data/weibo/Weibodata.txt"));//下有数据源,Weibodata.txt 48 49 Path path =new Path("./out/weibo1"); 50 51 52 53 // part-r-00000 54 // part-r-00001 55 // part-r-00002 拿3个reduce去输出微博词频。 56 // part-r-00003 最后这个是输出微博总数, 57 if(fs.exists(path)){ 58 fs.delete(path, true); 59 } 60 FileOutputFormat.setOutputPath(job,path); 61 62 boolean f= job.waitForCompletion(true); 63 if(f){ 64 65 } 66 } catch (Exception e) { 67 e.printStackTrace(); 68 } 69 } 70 }
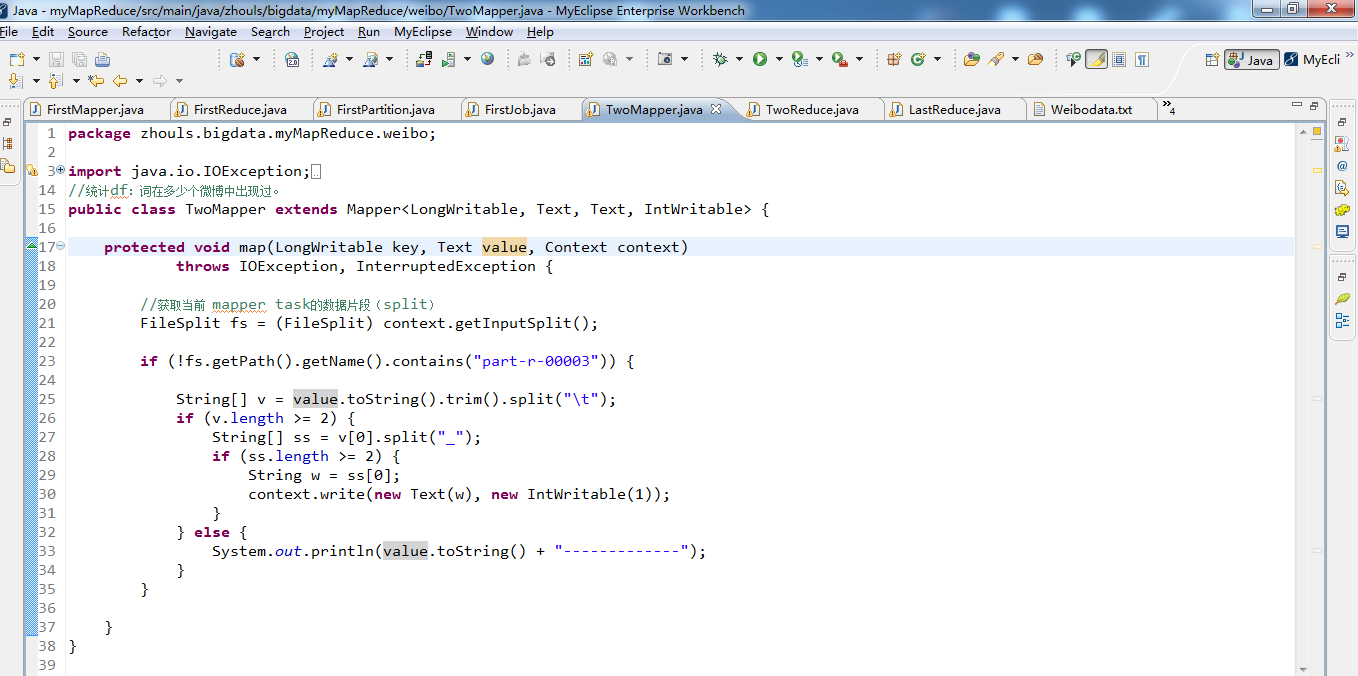
1 package zhouls.bigdata.myMapReduce.weibo; 2 3 import java.io.IOException; 4 5 import java.io.StringReader; 6 7 import org.apache.hadoop.io.IntWritable; 8 import org.apache.hadoop.io.LongWritable; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapreduce.Mapper; 11 import org.apache.hadoop.mapreduce.lib.input.FileSplit; 12 import org.wltea.analyzer.core.IKSegmenter; 13 import org.wltea.analyzer.core.Lexeme; 14 //统计df:词在多少个微博中出现过。 15 public class TwoMapper extends Mapper<LongWritable, Text, Text, IntWritable> { 16 17 protected void map(LongWritable key, Text value, Context context) 18 throws IOException, InterruptedException { 19 20 //获取当前 mapper task的数据片段(split) 21 FileSplit fs = (FileSplit) context.getInputSplit(); 22 23 if (!fs.getPath().getName().contains("part-r-00003")) { 24 25 String[] v = value.toString().trim().split("\t"); 26 if (v.length >= 2) { 27 String[] ss = v[0].split("_"); 28 if (ss.length >= 2) { 29 String w = ss[0]; 30 context.write(new Text(w), new IntWritable(1)); 31 } 32 } else { 33 System.out.println(value.toString() + "-------------"); 34 } 35 } 36 37 } 38 }
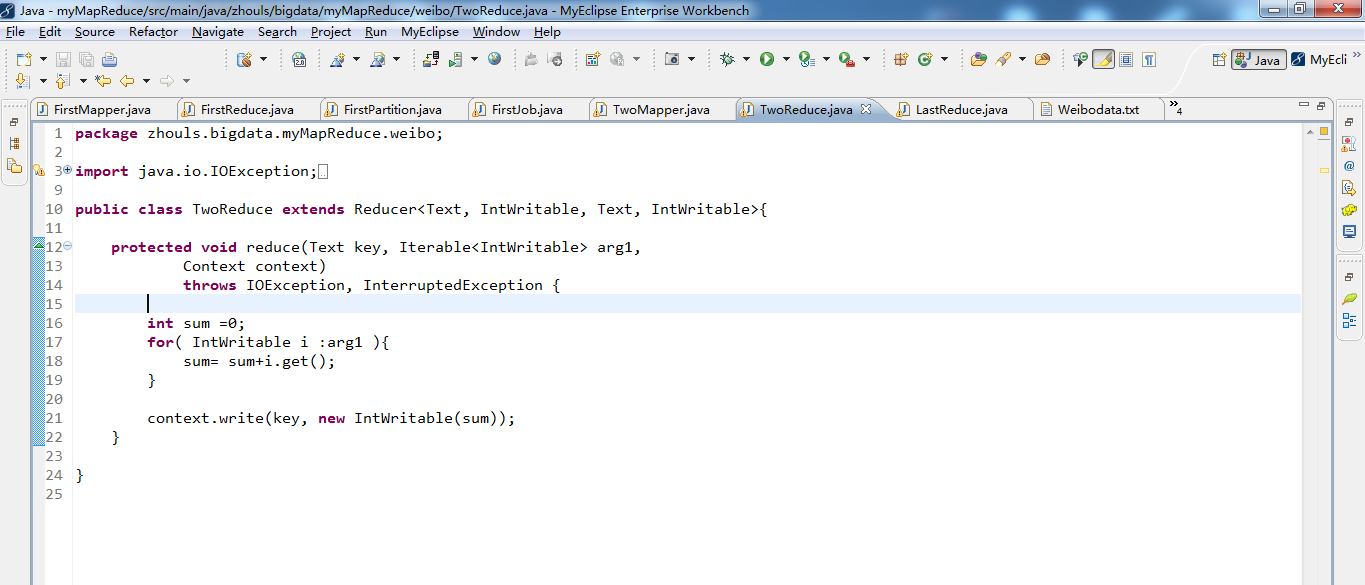
1 package zhouls.bigdata.myMapReduce.weibo; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.io.IntWritable; 6 import org.apache.hadoop.io.LongWritable; 7 import org.apache.hadoop.io.Text; 8 import org.apache.hadoop.mapreduce.Reducer; 9 10 public class TwoReduce extends Reducer<Text, IntWritable, Text, IntWritable>{ 11 12 protected void reduce(Text key, Iterable<IntWritable> arg1, 13 Context context) 14 throws IOException, InterruptedException { 15 16 int sum =0; 17 for( IntWritable i :arg1 ){ 18 sum= sum+i.get(); 19 } 20 21 context.write(key, new IntWritable(sum)); 22 } 23 24 }
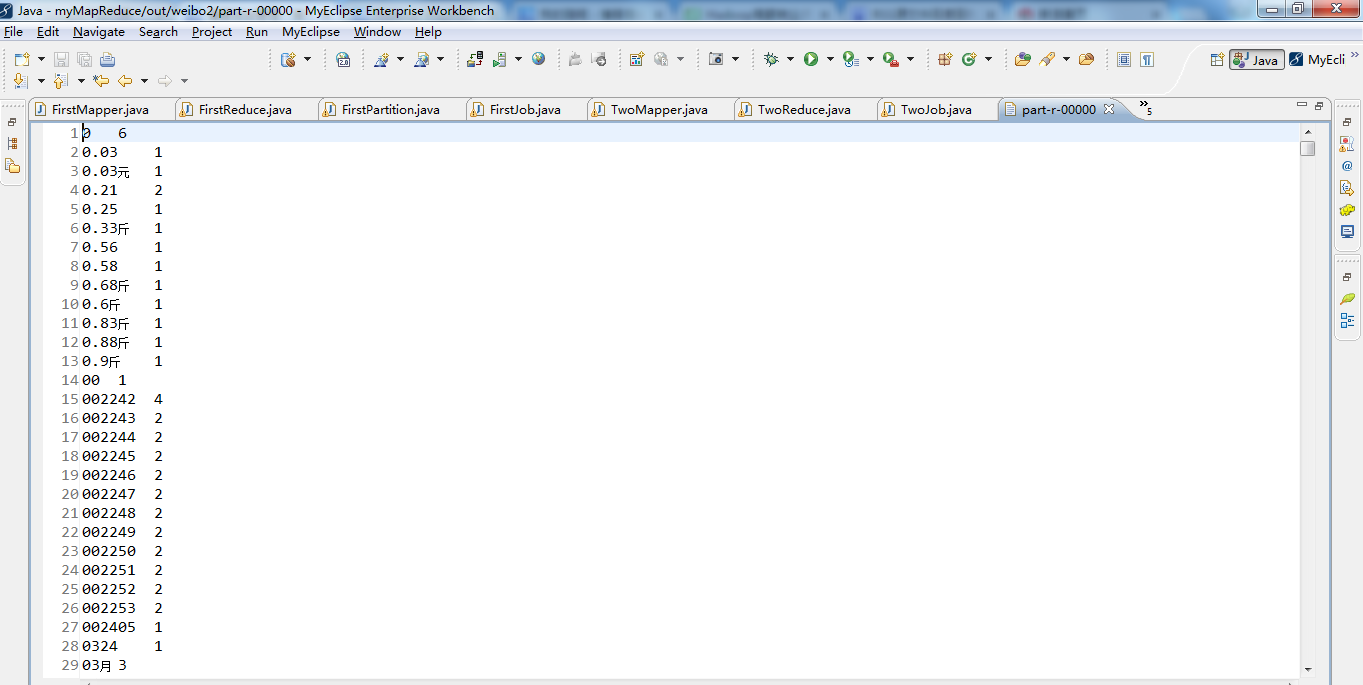
1 package zhouls.bigdata.myMapReduce.weibo; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.conf.Configuration; 6 import org.apache.hadoop.fs.Path; 7 import org.apache.hadoop.io.IntWritable; 8 import org.apache.hadoop.io.LongWritable; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapred.JobConf; 11 import org.apache.hadoop.mapred.TextInputFormat; 12 import org.apache.hadoop.mapreduce.Job; 13 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 14 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 15 16 17 public class TwoJob { 18 19 public static void main(String[] args) { 20 Configuration config =new Configuration(); 21 // config.set("fs.defaultFS", "hdfs://HadoopMaster:9000"); 22 // config.set("yarn.resourcemanager.hostname", "HadoopMaster"); 23 try { 24 // JobConf job =new JobConf(config); 25 Job job =Job.getInstance(config); 26 job.setJarByClass(TwoJob.class); 27 job.setJobName("weibo2"); 28 //设置map任务的输出key类型、value类型 29 job.setOutputKeyClass(Text.class); 30 job.setOutputValueClass(IntWritable.class); 31 // job.setMapperClass(); 32 job.setMapperClass(TwoMapper.class); 33 job.setCombinerClass(TwoReduce.class); 34 job.setReducerClass(TwoReduce.class); 35 36 //mr运行时的输入数据从hdfs的哪个目录中获取 37 // FileInputFormat.addInputPath(job, new Path("hdfs://HadoopMaster:9000/out/weibo1/")); 38 // FileOutputFormat.setOutputPath(job, new Path("hdfs://HadoopMaster:9000/out/weibo2")); 39 40 FileInputFormat.addInputPath(job, new Path("./out/weibo1/")); 41 FileOutputFormat.setOutputPath(job, new Path("./out/weibo2")); 42 43 boolean f= job.waitForCompletion(true); 44 if(f){ 45 System.out.println("执行job成功"); 46 } 47 } catch (Exception e) { 48 e.printStackTrace(); 49 } 50 } 51 }
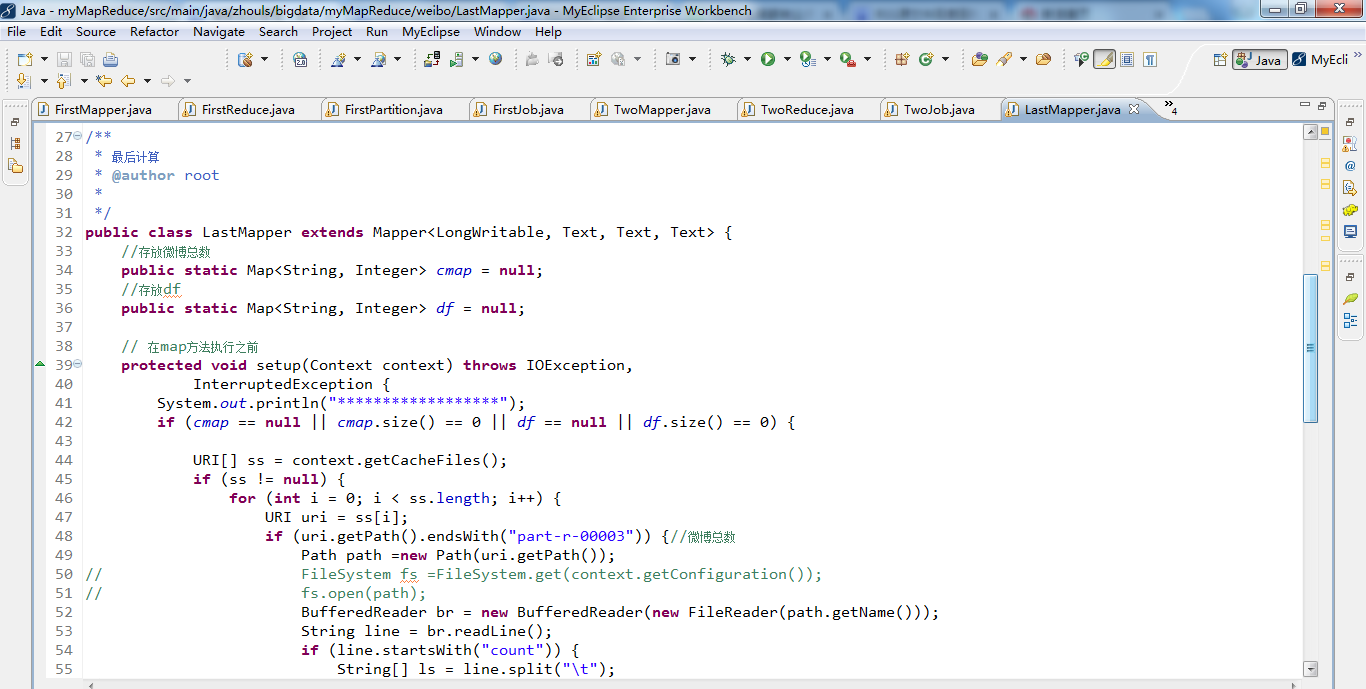
1 package zhouls.bigdata.myMapReduce.weibo; 2 3 import java.io.BufferedReader; 4 5 import java.io.File; 6 import java.io.FileInputStream; 7 import java.io.FileReader; 8 import java.io.IOException; 9 import java.io.InputStreamReader; 10 import java.io.StringReader; 11 import java.net.URI; 12 import java.text.NumberFormat; 13 import java.util.HashMap; 14 import java.util.Map; 15 16 import org.apache.hadoop.conf.Configuration; 17 import org.apache.hadoop.fs.FileSystem; 18 import org.apache.hadoop.fs.Path; 19 import org.apache.hadoop.io.IntWritable; 20 import org.apache.hadoop.io.LongWritable; 21 import org.apache.hadoop.io.Text; 22 import org.apache.hadoop.mapreduce.Mapper; 23 import org.apache.hadoop.mapreduce.lib.input.FileSplit; 24 import org.wltea.analyzer.core.IKSegmenter; 25 import org.wltea.analyzer.core.Lexeme; 26 27 /** 28 * 最后计算 29 * @author root 30 * 31 */ 32 public class LastMapper extends Mapper<LongWritable, Text, Text, Text> { 33 //存放微博总数 34 public static Map<String, Integer> cmap = null; 35 //存放df 36 public static Map<String, Integer> df = null; 37 38 // 在map方法执行之前 39 protected void setup(Context context) throws IOException, 40 InterruptedException { 41 System.out.println("******************"); 42 if (cmap == null || cmap.size() == 0 || df == null || df.size() == 0) { 43 44 URI[] ss = context.getCacheFiles(); 45 if (ss != null) { 46 for (int i = 0; i < ss.length; i++) { 47 URI uri = ss[i]; 48 if (uri.getPath().endsWith("part-r-00003")) {//微博总数 49 Path path =new Path(uri.getPath()); 50 // FileSystem fs =FileSystem.get(context.getConfiguration()); 51 // fs.open(path); 52 BufferedReader br = new BufferedReader(new FileReader(path.getName())); 53 String line = br.readLine(); 54 if (line.startsWith("count")) { 55 String[] ls = line.split("\t"); 56 cmap = new HashMap<String, Integer>(); 57 cmap.put(ls[0], Integer.parseInt(ls[1].trim())); 58 } 59 br.close(); 60 } else if (uri.getPath().endsWith("part-r-00000")) {//词条的DF 61 df = new HashMap<String, Integer>(); 62 Path path =new Path(uri.getPath()); 63 BufferedReader br = new BufferedReader(new FileReader(path.getName())); 64 String line; 65 while ((line = br.readLine()) != null) { 66 String[] ls = line.split("\t"); 67 df.put(ls[0], Integer.parseInt(ls[1].trim())); 68 } 69 br.close(); 70 } 71 } 72 } 73 } 74 } 75 76 protected void map(LongWritable key, Text value, Context context) 77 throws IOException, InterruptedException { 78 FileSplit fs = (FileSplit) context.getInputSplit(); 79 // System.out.println("--------------------"); 80 if (!fs.getPath().getName().contains("part-r-00003")) { 81 82 String[] v = value.toString().trim().split("\t"); 83 if (v.length >= 2) { 84 int tf =Integer.parseInt(v[1].trim());//tf值 85 String[] ss = v[0].split("_"); 86 if (ss.length >= 2) { 87 String w = ss[0]; 88 String id=ss[1]; 89 90 double s=tf * Math.log(cmap.get("count")/df.get(w)); 91 NumberFormat nf =NumberFormat.getInstance(); 92 nf.setMaximumFractionDigits(5); 93 context.write(new Text(id), new Text(w+":"+nf.format(s))); 94 } 95 } else { 96 System.out.println(value.toString() + "-------------"); 97 } 98 } 99 } 100 }
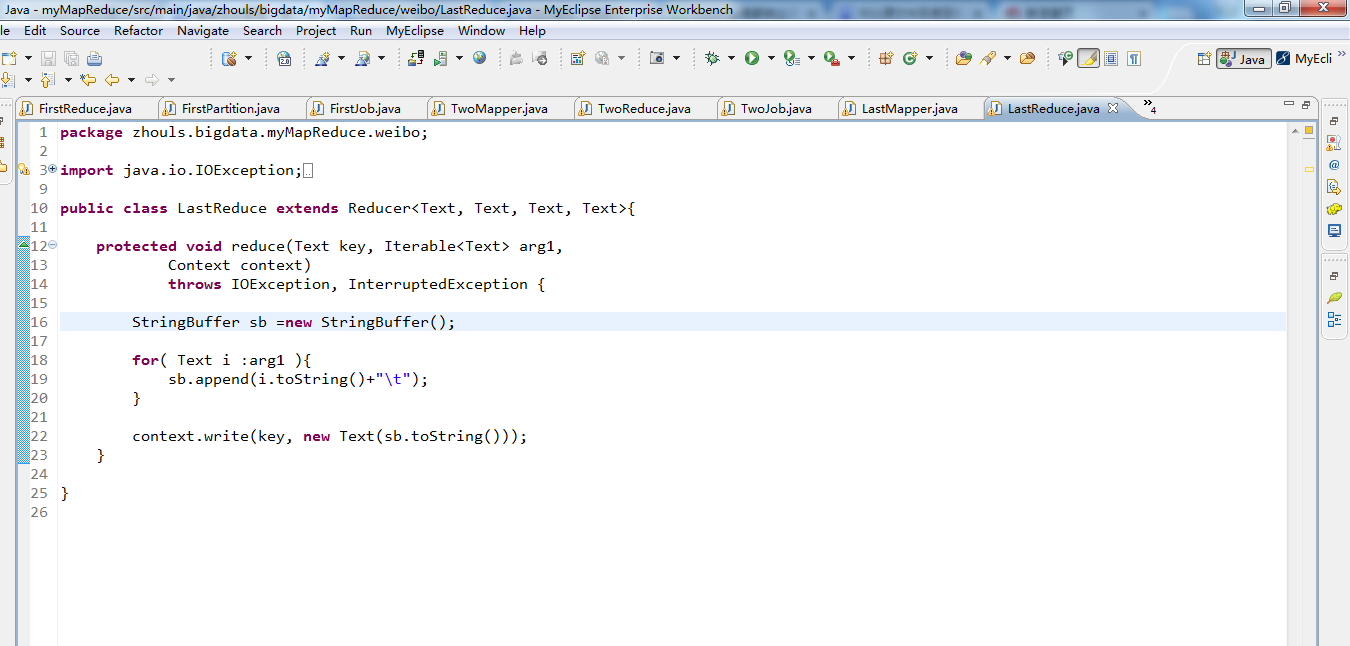
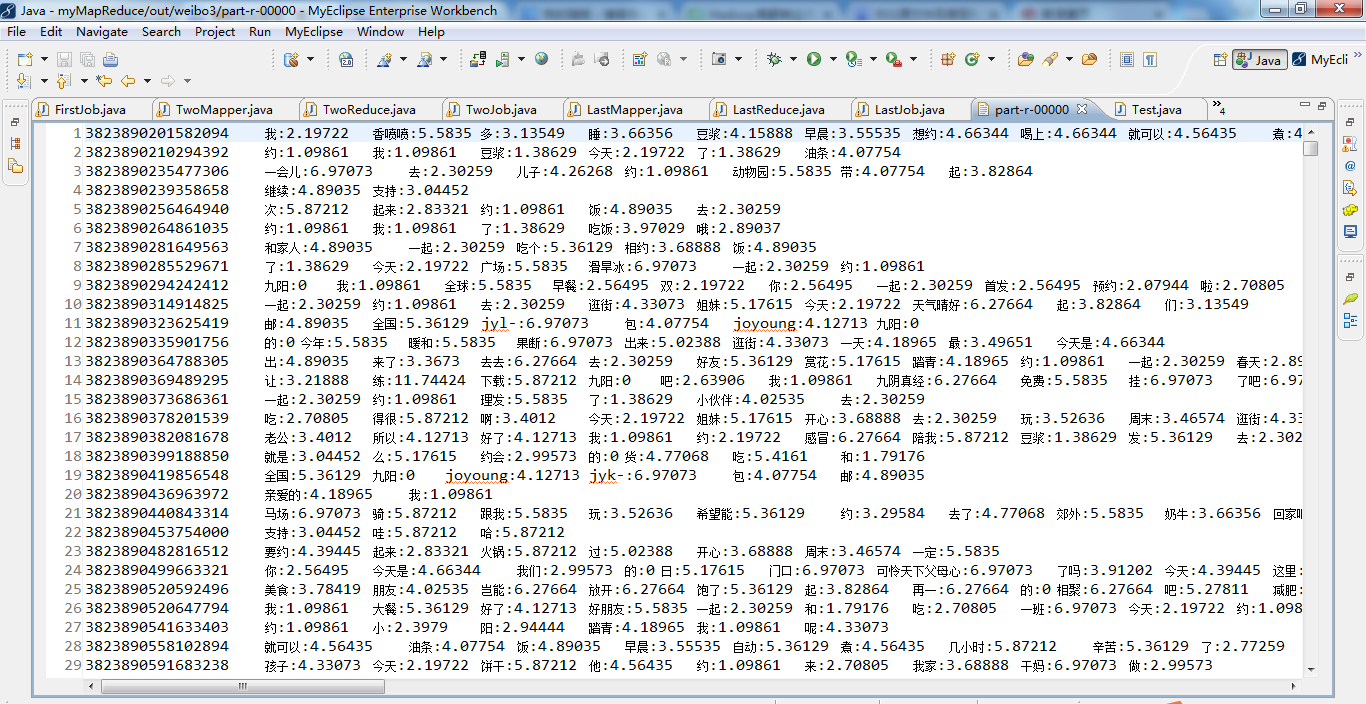
1 package zhouls.bigdata.myMapReduce.weibo; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.io.IntWritable; 6 import org.apache.hadoop.io.LongWritable; 7 import org.apache.hadoop.io.Text; 8 import org.apache.hadoop.mapreduce.Reducer; 9 10 public class LastReduce extends Reducer<Text, Text, Text, Text>{ 11 12 protected void reduce(Text key, Iterable<Text> arg1, 13 Context context) 14 throws IOException, InterruptedException { 15 16 StringBuffer sb =new StringBuffer(); 17 18 for( Text i :arg1 ){ 19 sb.append(i.toString()+"\t"); 20 } 21 22 context.write(key, new Text(sb.toString())); 23 } 24 25 }
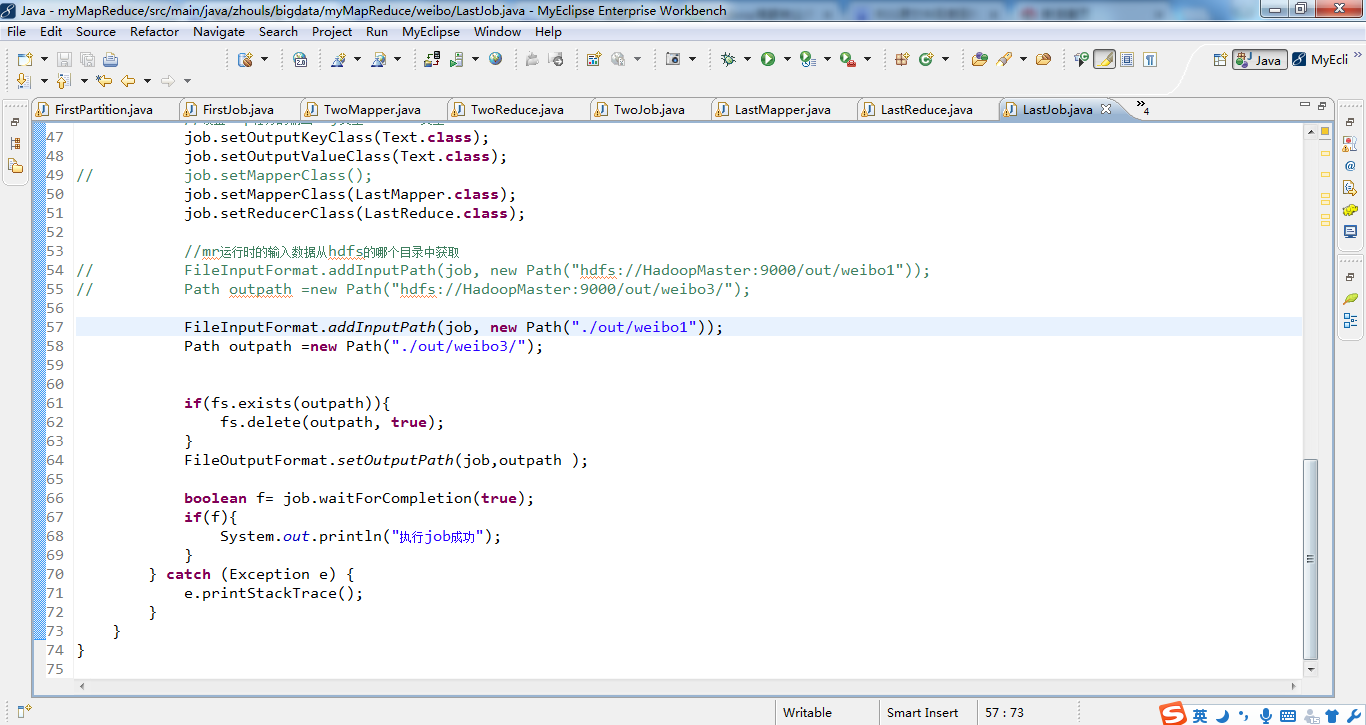
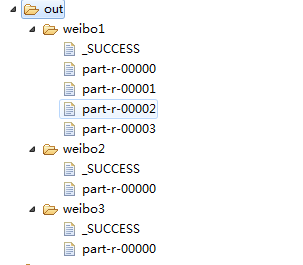
1 package zhouls.bigdata.myMapReduce.weibo; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.conf.Configuration; 6 import org.apache.hadoop.filecache.DistributedCache; 7 import org.apache.hadoop.fs.FileSystem; 8 import org.apache.hadoop.fs.Path; 9 import org.apache.hadoop.io.IntWritable; 10 import org.apache.hadoop.io.LongWritable; 11 import org.apache.hadoop.io.Text; 12 import org.apache.hadoop.mapred.JobConf; 13 import org.apache.hadoop.mapred.TextInputFormat; 14 import org.apache.hadoop.mapreduce.Job; 15 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 16 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 17 18 19 public class LastJob { 20 public static void main(String[] args) { 21 Configuration config =new Configuration(); 22 // config.set("fs.defaultFS", "hdfs://HadoopMaster:9000"); 23 // config.set("yarn.resourcemanager.hostname", "HadoopMaster"); 24 // config.set("mapred.jar", "C:\\Users\\Administrator\\Desktop\\weibo3.jar"); 25 try { 26 FileSystem fs =FileSystem.get(config); 27 // JobConf job =new JobConf(config); 28 Job job =Job.getInstance(config); 29 job.setJarByClass(LastJob.class); 30 job.setJobName("weibo3"); 31 32 // DistributedCache.addCacheFile(uri, conf); 33 //2.5 34 //把微博总数加载到内存 35 // job.addCacheFile(new Path("hdfs://HadoopMaster:9000/out/weibo1/part-r-00003").toUri()); 36 // //把df加载到内存 37 // job.addCacheFile(new Path("hdfs://HadoopMaster:9000/out/weibo2/part-r-00000").toUri()); 38 39 40 job.addCacheFile(new Path("./out/weibo1/part-r-00003").toUri()); 41 //把df加载到内存 42 job.addCacheFile(new Path("./out/weibo2/part-r-00000").toUri()); 43 44 45 46 //设置map任务的输出key类型、value类型 47 job.setOutputKeyClass(Text.class); 48 job.setOutputValueClass(Text.class); 49 // job.setMapperClass(); 50 job.setMapperClass(LastMapper.class); 51 job.setReducerClass(LastReduce.class); 52 53 //mr运行时的输入数据从hdfs的哪个目录中获取 54 // FileInputFormat.addInputPath(job, new Path("hdfs://HadoopMaster:9000/out/weibo1")); 55 // Path outpath =new Path("hdfs://HadoopMaster:9000/out/weibo3/"); 56 57 FileInputFormat.addInputPath(job, new Path("./out/weibo1")); 58 Path outpath =new Path("./out/weibo3/"); 59 60 61 if(fs.exists(outpath)){ 62 fs.delete(outpath, true); 63 } 64 FileOutputFormat.setOutputPath(job,outpath ); 65 66 boolean f= job.waitForCompletion(true); 67 if(f){ 68 System.out.println("执行job成功"); 69 } 70 } catch (Exception e) { 71 e.printStackTrace(); 72 } 73 } 74 }
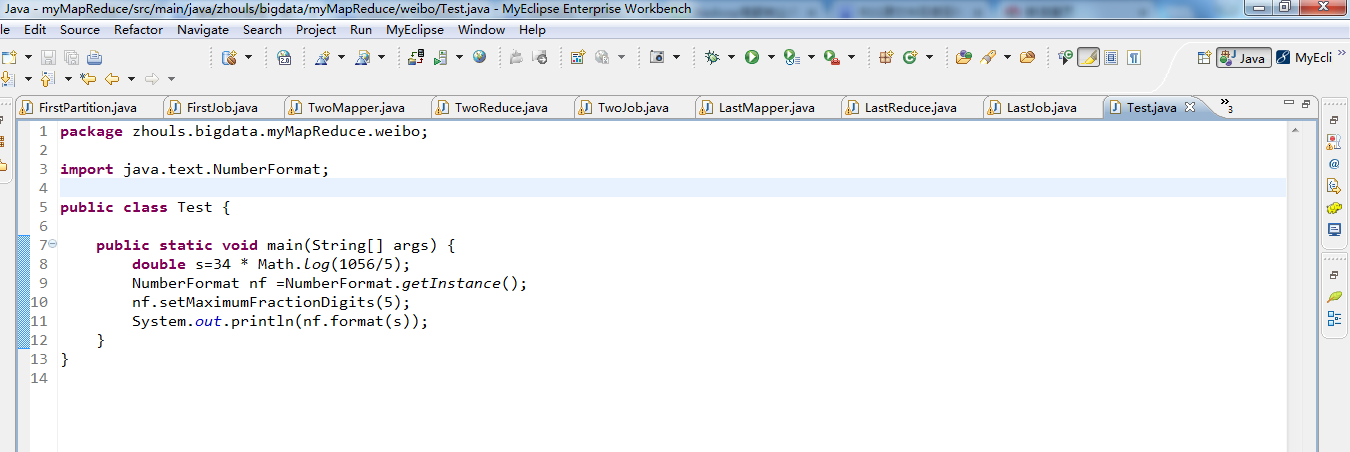
1 package zhouls.bigdata.myMapReduce.weibo; 2 3 import java.text.NumberFormat; 4 5 public class Test { 6 7 public static void main(String[] args) { 8 double s=34 * Math.log(1056/5); 9 NumberFormat nf =NumberFormat.getInstance(); 10 nf.setMaximumFractionDigits(5); 11 System.out.println(nf.format(s)); 12 } 13 }