计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-10-25
0. 前言
大语言模型在很多领域都有成功的应用,在本期计算机前沿技术进展研究介绍中,我们将带来一篇用大语言模型进行诺贝尔文学作品分析的论文。虽然有一定趁最近诺贝尔奖热潮的意味,但是这也探索了人文学科中人类与人工智能合作的潜力,为文学研究及其它领域开辟了新的机会。其他几篇文章则是对大语言模型能力的探索,值得一读。
目录
文章目录
- 计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-10-25
- 0. 前言
- 目录
- 1. Should We Really Edit Language Models? On the Evaluation of Edited Language Models
- 2. Improving Small-Scale Large Language Models Function Calling for Reasoning Tasks
- 3. Analyzing Nobel Prize Literature with Large Language Models
- 4. Meaning Typed Prompting: A Technique for Efficient, Reliable Structured Output Generation
- 5. Future Token Prediction -- Causal Language Modelling with Per-Token Semantic State Vector for Multi-Token Prediction
- 后记
1. Should We Really Edit Language Models? On the Evaluation of Edited Language Models
Authors: Qi Li, Xiang Liu, Zhenheng Tang, Peijie Dong, Zeyu Li, Xinglin Pan, Xiaowen Chu
https://arxiv.org/abs/2410.18785
我们真的应该编辑语言模型吗?关于编辑后语言模型的评估
摘要
本文探讨了语言模型编辑的普遍做法,这是一种更新语言模型内部知识的有效方法。当前的编辑方法主要关注可靠性、泛化能力和局部性,许多方法在这些标准上表现出色。然而,一些最新的研究揭示了这些编辑方法的潜在问题,例如知识失真或冲突。尽管如此,编辑后语言模型的一般能力尚未被充分探索。本文对不同的编辑方法和语言模型进行了全面评估,发现现有编辑方法在一般基准测试中不可避免地导致性能下降,表明现有编辑方法只能在少数几次编辑内保持模型的一般能力。当编辑数量稍微增加时,模型的内在知识结构可能会受到干扰甚至完全损坏。此外,我们还发现,经过指令调整的模型对编辑更加健壮,大型语言模型比小型模型更耐编辑。编辑模型的安全性显著降低,即使是那些与安全性对齐的模型也是如此。我们的发现表明,当前的编辑方法只适用于语言模型内小规模的知识更新,这激发了对更实用、可靠的编辑方法的进一步研究。
研究背景
大型语言模型(LLM)如ChatGPT、Claude和Llama等,在各种知识密集型任务中展现了卓越的性能。然而,这些模型学到的大量知识可能是错误的、有害的或过时的。直接在校准知识上微调LLM可以帮助缓解这个问题,但由于硬件限制和资源预算,这是不可行的。因此,模型编辑被提出作为一种在LLM内高效更新知识的方法。现有的编辑研究集中在通过特定的知识样本(例如,将错误的元组(Tim Cook, is the CEO of, Google)修改为正确的一个(Tim Cook, is the CEO of, Apple))来精确调整模型的行为。

问题与挑战
尽管在编辑语言模型方面取得了成功,但最近的研究表明,现有编辑方法存在不可避免的问题,如知识失真和灾难性遗忘。在顺序编辑设置中,随着编辑数量的增加,需要平衡两个方面:保留模型的原始知识和保留通过更新获得的新知识。这两个目标在某种程度上是相互冲突的。LLM的一般能力是解决广泛复杂任务的基础,模型的一般能力的变化反映了其原始知识的保留情况。然而,编辑后语言模型的一般能力尚未被探索,这使得当前的编辑方法不可靠,无法用于实际应用。
如何解决
为了解决这个问题,文章提出了对编辑后的LLM进行全面理解和分析的方法。具体来说,作者使用不同的编辑方法对多个LLM进行编辑,并在各种基准测试中评估它们,以验证可能影响一般能力的背后因素。研究的重点是模型的一般能力(包括世界知识、阅读理解、推理、安全性等),而不是在效用、泛化和局部性或下游任务(如NER、QA和NLI)上的表现。
创新点
文章的主要贡献包括:
- 对不同模型编辑方法对LLM一般能力的影响进行了详细评估,发现现有模型编辑方法只适用于有限数量的编辑,通常不超过几十次。
- 使用不同的编辑方法对不同模型进行了广泛的探索,以验证影响编辑模型基本能力的潜在因素。这些见解广泛适用于不同的编辑方法和各种模型。
- 通过不同的编辑方法对不同模型的实证研究揭示了即使只有几十次编辑,LLM的安全性也会受到到一定程度的损害。
- 对编辑LLM的副作用、操作效率和部署进行了深入分析,讨论了它们在生产中的实用。
算法模型
文章中提到了多种语言模型编辑方法,包括基于元学习的方法(如MEND)、基于定位然后编辑的方法(如ROME、MEMIT、PMET)、基于检索的方法(如SERAC)和基于额外参数的方法(如GRACE)。这些方法在不同的基准测试和不同的LLM上进行了评估。
实验效果
实验结果表明,大多数现有的编辑方法在不超过几十次编辑的情况下不会显著影响模型的基本能力。然而,在接近一百次编辑后,一些方法导致性能迅速下降,而其他方法在几百次编辑甚至几千次编辑后只稍微影响性能。当对模型进行高达10,000次的编辑时,观察到模型的内在知识结构被彻底破坏,对任何输入的响应都是空字符串或随机字符,这种现象被称为模型编辑的“静音效应”。
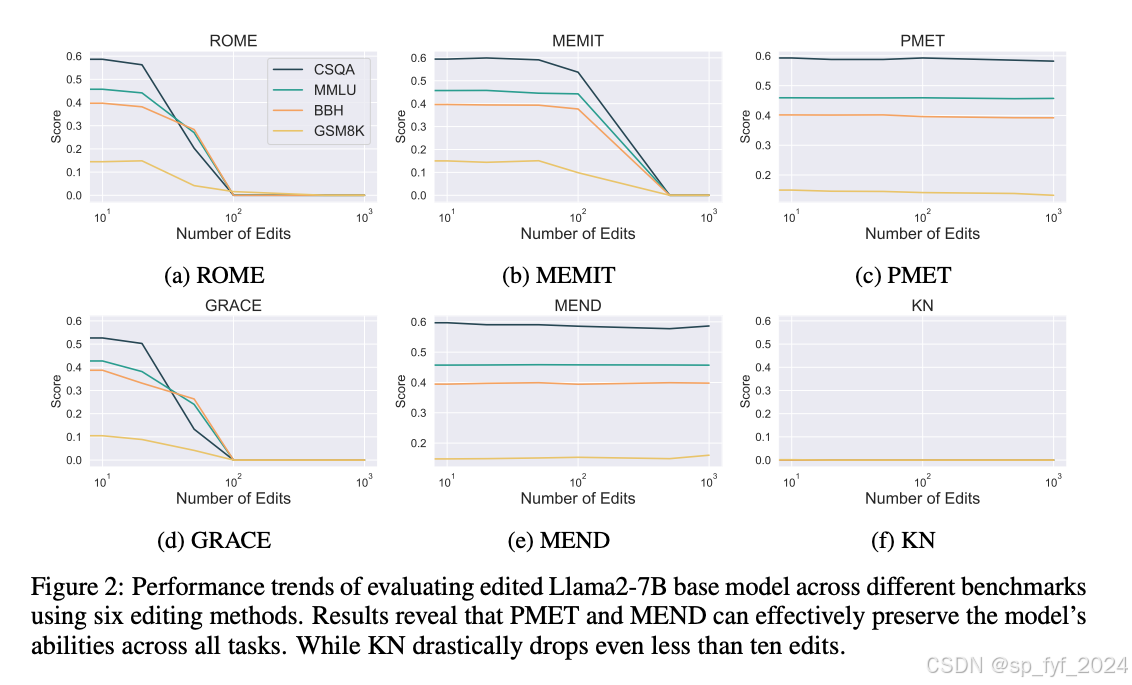
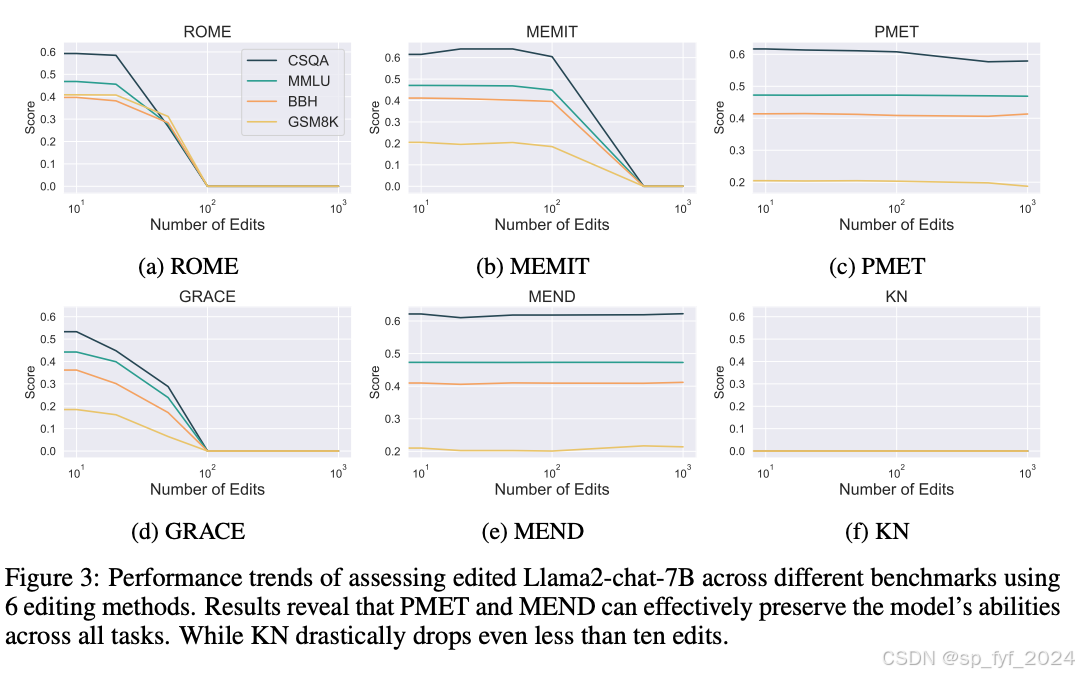
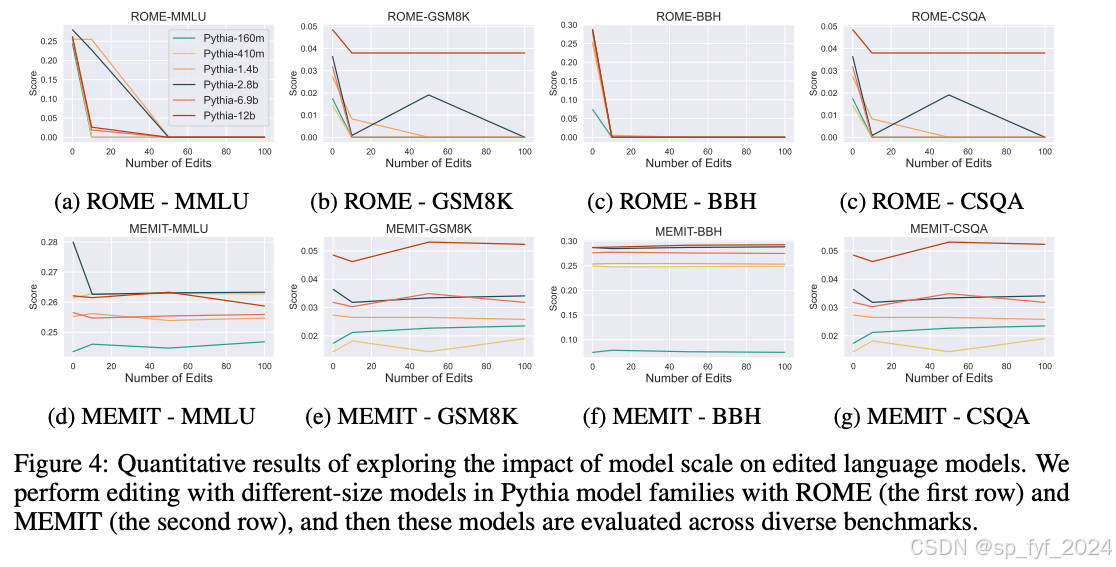
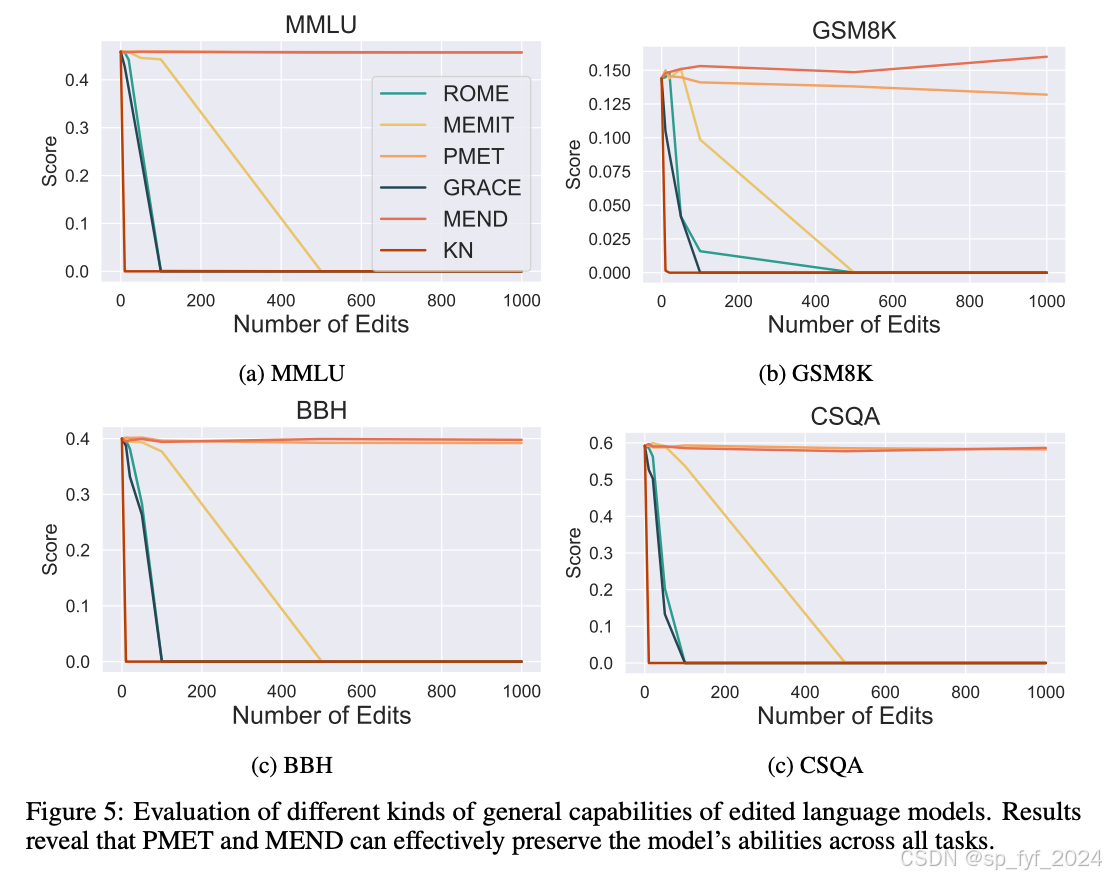
重要数据与结论
文章中的实验数据表明,经过指令调整的模型在编辑后表现出更慢的性能下降率,而小型模型更容易受到编辑引起的损害。此外,不同模型编辑方法对模型能力的各个方面的影响大致相同。研究还探讨了编辑模型的安全性问题,发现即使是几十次编辑,安全性也会受到到一定程度的损害。
推荐阅读指数
⭐⭐⭐⭐☆
论文核心代码:
https://github.com/lqinfdim/EditingEvaluation.git
import os
import torch
import transformers
import fastedit
import argparse
import json
import time
import shutil
import numpy as np
import pandas as pd
from transformers import PreTrainedModel
from fastedit import (
FTHyperParams,
IKEHyperParams,
KNHyperParams,
MEMITHyperParams,
ROMEHyperParams,
LoRAHyperParams,
MENDHyperParams,
SERACHparams,
PMETHyperParams,
MALMENHyperParams,
GraceHyperParams,
MELOHyperParams
)
from fastedit import BaseEditor
from fastedit import ZsreDataset, CounterFactDataset
from fastedit.trainer import EditTrainer
from datasets import load_dataset
from tqdm import tqdm
DATASET_MAPPING = {
"zsre" : ZsreDataset,
"cf" : CounterFactDataset,
}
METHOD_MAPPING = {
"FT" : FTHyperParams,
"IKE" : IKEHyperParams,
"MEMIT" : MEMITHyperParams,
"ROME" : ROMEHyperParams,
"KN" : KNHyperParams,
"PMET" : PMETHyperParams,
"MEND" : MENDHyperParams,
"MALMEN": MALMENHyperParams,
"LORA" : LoRAHyperParams,
"SERAC": SERACHparams,
"GRACE" : GraceHyperParams,
"MELO":MELOHyperParams
}
DATASET_PATH = {
"cf" : ("/dataset/counterfact/counterfact-train.json", "/dataset/counterfact/counterfact-val.json"),
"zsre" : ("/dataset/zsre/zsre_mend_train.json", "/dataset/zsre/zsre_mend_eval.json"),
}
def get_method_hyperparameter_class(method_name : str):
return METHOD_MAPPING[method_name]
def get_dataset_class(dataset_name : str):
return DATASET_MAPPING[dataset_name]
def get_mend_dataset_path(ds_name):
return DATASET_PATH[ds_name]
def create_or_clear_dir(path_name):
if os.path.exists(path_name):
shutil.rmtree(path_name)
os.makedirs(path_name)
os.makedirs(os.path.join(path_name, 'result'))
os.makedirs(os.path.join(path_name, "final_model"))
def editing_parse_arg():
parser = argparse.ArgumentParser("hyperparameters for model editing")
parser.add_argument("--model_name", type=str, default=None, required=True)
parser.add_argument("--editing_method", type=str, default=None, required=True)
parser.add_argument("--hparams_file", type=str, default=None, required=True)
parser.add_argument("--is_sequential_editing", type=bool, default=True)
parser.add_argument("--data_dir", type=str, default="/dataset")
parser.add_argument("--output_dir", type=str, default=None, required=True)
parser.add_argument("--editing_dataset", type=str, default=None, required=True, choices=['zsre', "cf"])
parser.add_argument("--editing_dataset_size", type=int, default=None)
args = parser.parse_args()
return args
def main():
args = editing_parse_arg()
dataset_cls = get_dataset_class(args.editing_dataset)
editor_hyperparameter_class = get_method_hyperparameter_class(args.editing_method)
edit_ds = dataset_cls(size=args.editing_dataset_size)
print(f"[INFO] The editing method is {args.editing_method} . \n")
print(f"[INFO] The size of editing dataset is {len(edit_ds)} . \n")
hparams = editor_hyperparameter_class.from_hparams(args.hparams_file)
roll_back_weight = not args.is_sequential_editing
if not roll_back_weight:
print("[INFO] Performing Sequential Editing. \n")
else:
print("[INFO] Performing Single Editing. \n")
print(f'[INFO] Editing {hparams.model_name} Model. \n')
if args.editing_method in ["MEND", "SERAC"]:
if (not hasattr(hparams, "archive") and args.editing_method == "IKE") or (hparams.archive is None) :
print(f"Pre-training for {args.editing_method}")
train_path, eval_path = get_mend_dataset_path(args.editing_dataset)
train_ds = dataset_cls(train_path, config=hparams)
eval_ds = dataset_cls(eval_path, config=hparams)
trainer = EditTrainer(
config=hparams,
train_set=train_ds,
val_set=eval_ds
)
trainer.run()
editor = BaseEditor.from_hparams(hparams)
metrics, edited_model, _ = editor.edit_dataset(
edit_ds,
keep_original_weight=roll_back_weight
)
if isinstance(edited_model, PreTrainedModel):
returned_model = edited_model
elif hasattr(edited_model, "model"):
returned_model = edited_model.model
else:
raise NotImplementedError
returned_model = returned_model.cpu()
returned_tokenizer = editor.tok
torch.cuda.empty_cache()
create_or_clear_dir(args.output_dir)
json.dump(metrics, open(os.path.join(args.output_dir, "result" , f'{args.model_name}_{args.editing_method}_results.json'), 'w'), indent=4)
if args.editing_method not in ["GRACE", "SERAC"]:
returned_model.save_pretrained(os.path.join(args.output_dir, "final_model"))
returned_tokenizer.save_pretrained(os.path.join(args.output_dir, "final_model"))
print("[INFO] Editing Finish, the edited model is saved at ", args.output_dir)
if __name__ == "__main__":
main()
2. Improving Small-Scale Large Language Models Function Calling for Reasoning Tasks
Authors: Graziano A. Manduzio, Federico A. Galatolo, Mario G. C. A. Cimino, Enzo Pasquale Scilingo, Lorenzo Cominelli
https://arxiv.org/abs/2410.18890
改进小型大规模语言模型在推理任务中的函数调用能力
摘要
本文探讨了在执行逻辑和数学推理任务时,如何改善小型大规模语言模型(LLMs)的函数调用能力。尽管大型语言模型(LLMs)在自然语言理解和生成方面表现出色,但在数学问题解决和逻辑推理方面仍面临挑战。为了解决这些限制,研究者探索了函数调用能力,允许LLMs执行提供的函数并利用它们的输出来完成任务。然而,针对特定任务的训练和推理阶段需要大量的计算资源,这对于大型LLMs来说效率不高。本研究介绍了一个新颖的框架,用于训练小型语言模型在函数调用方面的能力,专注于特定的逻辑和数学推理任务。该方法旨在通过函数调用改善小型模型在这些任务中的性能,并确保高精度。我们的框架使用一个代理,给定一个问题和一组可调用函数,通过注入函数描述和示例到提示中,并管理逐步推理链中的函数调用来查询LLM。这个过程用于创建正确和不正确的推理链聊天补全数据集,该数据集用于使用人类反馈的强化学习(RLHF)训练一个更小的LLM,特别是采用直接偏好优化(DPO)技术。实验结果表明,所提出的方法在模型大小和性能之间取得了平衡,提高了小型模型在推理任务中函数调用的能力。
研究背景
近年来,LLMs在自然语言理解和生成方面取得了显著进展。这些模型在完成文本预测的主要训练任务之外,还展现出了意外的能力。例如,它们在软件API的函数调用方面表现出了潜力,这得益于GPT-4插件功能的推出。尽管LLMs在一般复杂推理基准测试中显示出了希望,但它们在数学问题解决和逻辑能力方面仍然面临挑战。为了解决这些限制,研究者提出了各种技术,包括函数调用的能力,这允许LLMs执行提供的函数并利用它们的输出来协助完成任务。然而,仅依赖于大型模型(如GPT-4)进行特定任务的集中训练,由于训练和推理阶段所需的显著计算资源,效率不高。因此,研究者寻求创建更小、特定于任务的LLMs,以保持核心功能,同时降低运营成本。
问题与挑战
LLMs在数学问题解决和逻辑推理方面面临的挑战包括:
- 需要大量的计算资源进行训练和推理。
- 在特定任务上可能存在效率低下的问题。
- 小型LLMs在输出格式化的准确性方面可能存在问题,这可能影响软件应用的鲁棒性。
如何解决
为了解决上述挑战,文章提出了一个新颖的框架,该框架通过以下步骤来改善小型LLMs在逻辑和数学推理任务中的函数调用能力:
- 定义任务和问题:确定需要解决的推理任务类型。
- 定义一组函数:为每个问题定义一组可调用的函数,这些函数帮助LLM解决推理步骤、控制链流并验证中间和最终响应。
- 使用预训练的大型LLM生成数据集:通过代理与大型LLM交互,注入函数描述和示例到提示中,并管理适当的函数调用,以找到解决方案。
- 使用RLHF训练小型LLM:使用生成的数据集,通过DPO技术训练一个更小的模型。
创新点
文章的创新点包括:
- 提出了一个新颖的框架,用于训练小型LLM在函数调用方面的能力,专注于特定的逻辑和数学推理任务。
- 使用代理系统与大型LLM交互,生成包含正确和不正确逐步推理链聊天补全的数据集。
- 采用RLHF和DPO技术来训练小型LLM,提高了模型在推理任务中的性能。
算法模型
文章中提到的算法模型包括:
- 基于代理的系统:与大型LLM交互,生成数据集。
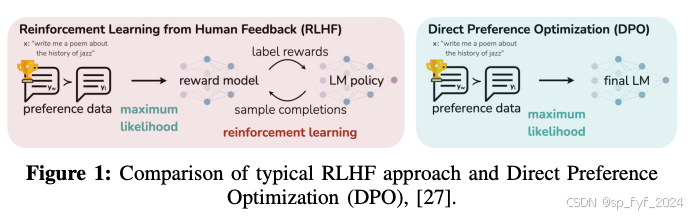
- 人类反馈的强化学习(RLHF):使用DPO技术训练小型LLM。
- 直接偏好优化(DPO):一种优化算法,通过直接从用户偏好数据中学习策略,消除了对显式奖励函数的需求。
实验效果
实验结果表明,所提出的方法在模型大小和性能之间取得了平衡,提高了小型模型在推理任务中函数调用的能力。具体数据和结论包括:
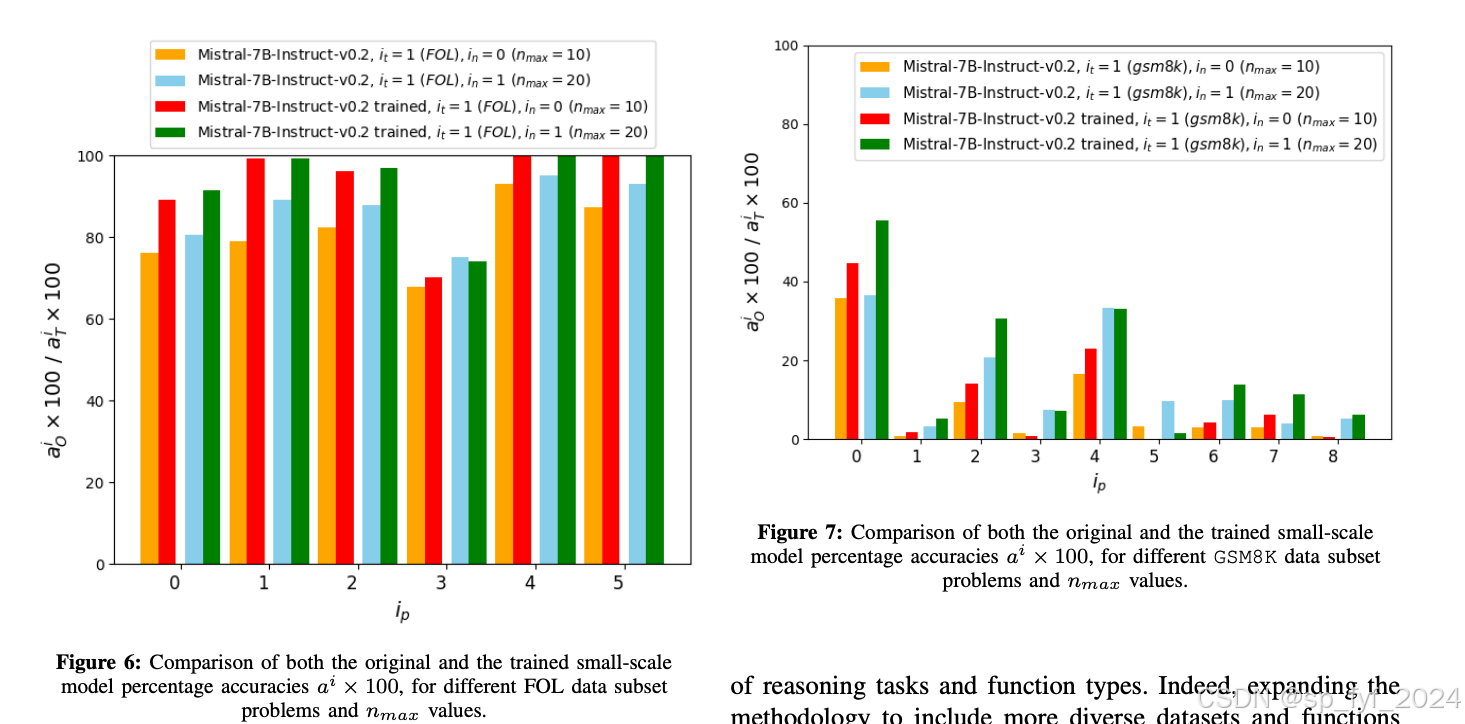
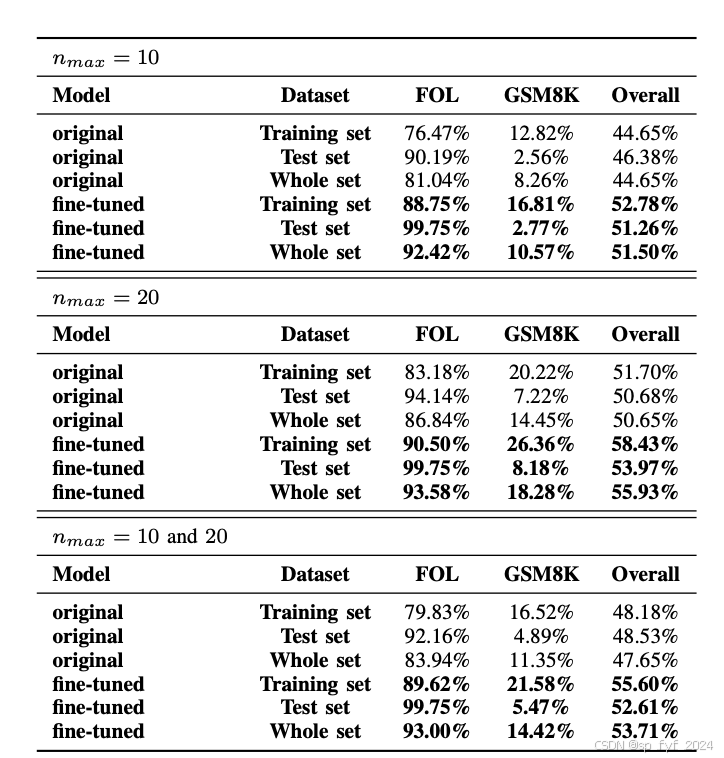
- 在FOL任务中,训练后的小型模型性能得到了显著提升,大多数情况下接近完美准确率。
- 在GSM8K数学问题上,虽然改进幅度较小,但训练后的模型在整体准确率上仍然优于原始模型。
- 训练过程仅使用单个GPU完成,这对于在计算资源有限的设备上部署AI系统具有重要意义。
推荐阅读指数
⭐⭐⭐☆☆
3. Analyzing Nobel Prize Literature with Large Language Models
Authors: Yang Zhenyuan, Liu Zhengliang, Zhang Jing, Lu Cen, Tai Jiaxin, Zhong
Tianyang, Li Yiwei, Zhao Siyan, Yao Teng, Liu Qing, Yang Jinlin, Liu Qixin, et.al.
https://arxiv.org/abs/2410.18142
使用大型语言模型分析诺贝尔文学奖文学作品
摘要
本研究考察了先进的大型语言模型(LLMs),特别是o1模型,在文学分析方面的能力。这些模型的输出直接与研究生水平的人类参与者产生的输出进行比较。通过关注两个诺贝尔奖获奖短篇小说,韩江的《九章》(2024年获奖者)和乔恩·福斯的《友谊》(2023年获奖者),研究探索了人工智能在涉及主题分析、互文性、文化和历史背景、语言和结构创新、角色发展等复杂文学元素方面的参与程度。鉴于诺贝尔奖的声望及其对文化、历史和语言丰富的强调,将LLMs应用于这些作品为我们提供了对人类和人工智能解释方法的更深入理解。研究使用定性和定量评估来衡量连贯性、创造力和对文本的忠实度,揭示了人工智能在通常保留给人类专家的任务中的优缺点。虽然LLMs在结构化任务中表现出强大的分析能力,但在情感细腻度和连贯性方面常常不足,这些领域是人类解释的强项。本研究强调了人文学科中人类与人工智能合作的潜力,为文学研究及其它领域开辟了新的机会。
研究背景
自20世纪50年代人工智能(AI)诞生以来,研究者一直在探索AI在创意任务中的表现。无论是生成艺术、作曲还是分析文学,理解和通过机器复制人类创造力的目标一直是研究的重点。哲学家路德维希·维特根斯坦曾说:“我的语言的极限就是我的世界的极限。”这一理念在当今先进AI的时代产生了强烈的共鸣,其中大型语言模型(LLMs)的突破,如GPT-4、Gemini、Llama和OpenAI新发布的o1模型,似乎让我们更接近人工通用智能(AGI)。这些模型在数十亿参数和大量自然语言语料库的神经网络上进行训练,提供了文本生成、理解和分析方面的前所未有的能力。它们在自然语言理解和生成方面的令人印象深刻的能力引起了人们对其在自然语言处理和文本分析中潜力的极大关注。但AI在触及人类思想边界的程度上能走多远?探索这个问题也是探索我们能复制人类智能多远的问题。
问题与挑战
LLMs在更微妙的领域,如解释和批评文学,的有效性尚未充分探索。本研究旨在填补这一空白,通过评估先进的LLM与人类参与者在文学分析中的性能,重点关注诺贝尔奖得主的作品。具体来说,我们的研究围绕韩江的《九章》和乔恩·福斯的《友谊》展开。研究考察了o1模型在涉及复杂文学维度方面的能力,包括:主题分析;互文性和文学影响;文化和历史背景;语言和结构创新;角色发展;道德和哲学见解;叙事技巧和时间结构;以及情感基调和心理深度。通过将模型的输出与研究生水平的人类参与者的输出进行比较,这项调查旨在评估人工智能在文学解释中的优势和局限性,探索人工智能是否能在这一传统人文领域与人类分析相媲美或互补。
如何解决
研究采用了比较框架,涉及人类参与者和o1模型。他们被赋予分析两部获得诺贝尔奖的短篇小说的任务:《九章》和《友谊》。参与者,无论是人类还是AI,都专注于几个文学因素进行分析:主题探索、互文性联系、历史文化背景、语言和结构创新、角色描绘、道德和哲学解释、叙事策略以及情感和心理深度。研究通过定性和定量评估来衡量连贯性、创造力和对文本的忠实度,为人类与AI文学分析的相对优势和劣势提供了全面的分析。
创新点
文章的创新点包括:
- 将先进的LLM,特别是o1模型,应用于诺贝尔文学奖获奖文学作品的分析,这是首次将LLMs作为文学作品的评估者。
- 通过结合定性和定量评估,提出了一个结构化的框架,用于评估AI在文学批判中如何补充或挑战传统的文学批评模式。
- 研究不仅量化了文学价值,还评估了LLM分析与人类视角在文学方面的一致性,为理解文学价值提供了更全面的理解。
算法模型
文章中提到的算法模型主要是OpenAI的o1模型,这是一个先进的大型语言模型,能够在文本生成、理解和分析方面提供前所未有的能力。o1模型通过神经网络和大量自然语言语料库进行训练,使其在处理各种文本任务和格式方面表现出色。
实验效果
实验结果表明,o1模型在几个方面与人类参与者表现相当,特别是在创造力和对文本的忠实度方面。模型能够在文学框架内生成创新的联系,如识别互文性和文化背景,展示了其在文学分析中贡献的潜力。然而,o1模型在连贯性和情感深度方面表现出明显的不足。人类参与者在这些领域的表现一直优于模型,反映了人类在需要高度主观性和情感共鸣的任务中的优越能力。
重要数据与结论
研究结果表明,虽然像o1这样的LLMs能够在文本分析中提供客观、基于文本的解释,它们最适合于优先考虑客观准确性和创造力而非情感和审美解释的角色。这为人文学科中人类与AI的合作提供了机会,其中LLMs可以提供初步分析,识别互文性和文化模式,并执行详细的主题评估,允许人类专家专注于文学批评中更具解释性和情感方面的工作。
推荐阅读指数
⭐⭐⭐⭐☆
4. Meaning Typed Prompting: A Technique for Efficient, Reliable Structured Output Generation
Authors: Chandra Irugalbandara
https://arxiv.org/abs/2410.18146
意义类型提示:一种用于高效、可靠结构化输出生成的技术

摘要
本文介绍了一种名为意义类型提示(Meaning Typed Prompting, MTP)的技术,旨在提高大型语言模型(LLMs)在生成结构化输出时的效率和可靠性。现有的方法通常依赖于严格的JSON模式,这可能导致输出不可靠、推理能力下降和计算开销增加,限制了LLMs在复杂任务中的适应性。MTP通过将类型、含义和抽象(如变量和类)集成到提示过程中,利用富有表现力的类型定义来增强输出清晰度,减少对复杂抽象的依赖,简化开发并提高实施效率。这使得LLMs能够更有效地理解关系并生成结构化数据。在多个基准测试上的实证评估表明,MTP在准确性、可靠性、一致性和令牌效率方面均优于现有框架。文章还介绍了一个实现MTP的框架Semantix,并提供了对其应用的实际见解。
研究背景
大型语言模型(LLMs)在开发复杂任务自动化和特定领域解决方案方面取得了显著进展。在这些应用中,对格式标准的严格遵守至关重要。结构化输出通过提供一致的输出结构、简化错误处理,使LLM生成的响应更可靠,从而更好地融入开发工具。随着代理框架的兴起,结构化输出对于无缝数据解析尤为重要,无需外部输出验证器。
问题与挑战
现有的结构化输出生成方法通常采用零样本(zero-shot)或少样本(few-shot)提示,开发者需要提供指令和JSON模板或模式来定义期望的输出格式。然后使用后处理技术提取和验证生成的数据。虽然OpenAI的约束解码策略可以确保可靠性,但由于依赖于JSON模式的限制,它限制了推理能力。此外,详细的JSON模式增加了令牌消耗,并在保持语法正确性方面引入了挑战,常常导致无效输出。
如何解决
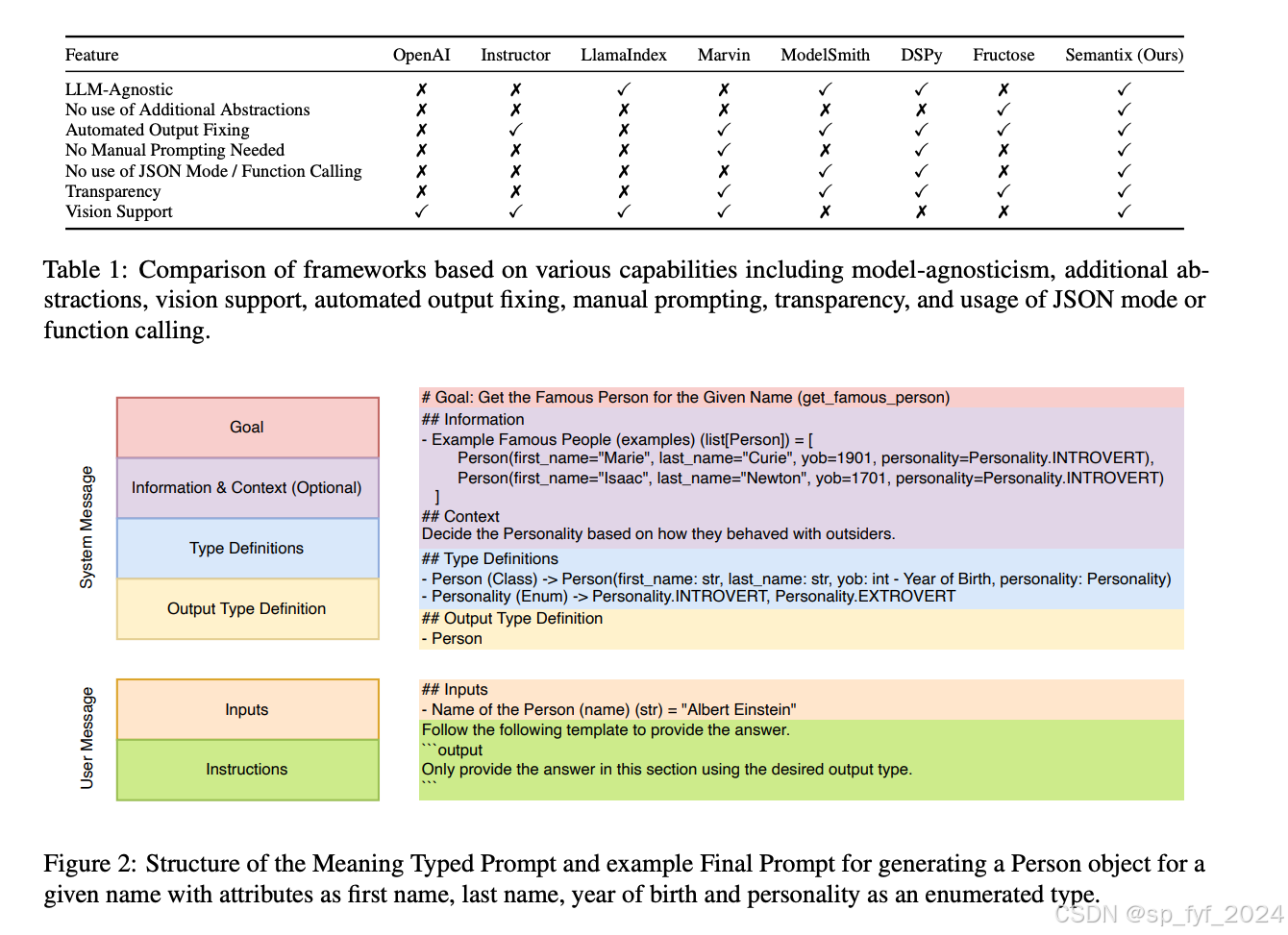
为了解决这些限制,文章提出了意义类型提示(MTP),这是一种新颖的结构化输出生成方法。基于MTP,文章介绍了Semantix框架,该框架在核心中使用MTP将语义信息直接嵌入到具有表现力的类型定义中,消除了对额外抽象的需求。这种方法减少了对提示配置的依赖,并简化了框架的学习曲线。Semantix通过直接在运行时将语义信息嵌入类型定义中,消除了对JSON模式、函数调用或特定领域语言的需求。这种方法简化了开发,减少了令牌消耗,并确保了与广泛LLMs的兼容性,提供了一个更灵活、透明和高效的解决方案。
创新点
文章的创新点包括:
- 提出了意义类型提示(MTP),这是一种新颖的结构化输出生成技术,通过将类型、含义和抽象集成到提示过程中,提高了输出的清晰度和可靠性。
- 引入了Semantix框架,该框架实现了MTP,并直接在类型定义中嵌入语义信息,消除了对JSON模式的依赖。
- Semantix框架提供了一种灵活、透明和高效的方法来生成结构化输出,与现有的基于JSON的方法相比,在多个基准测试中表现出更好的性能。
算法模型
文章中提出的算法模型主要基于意义类型提示(MTP),该技术通过使用富有表现力的类型定义来增强输出清晰度,减少对复杂抽象的依赖。MTP的核心思想是将语义信息直接嵌入到类型定义中,而不是依赖于JSON模式或函数调用。这种方法简化了开发过程,提高了实施效率,并使得LLMs能够更有效地理解关系并生成结构化数据。
实验效果
实验结果表明,Semantix在多个基准测试中表现出色,包括多标签分类、命名实体识别和合成数据生成。在这些任务中,Semantix在准确性、可靠性、一致性和令牌效率方面均优于现有框架。具体数据和结论如下:
- 在多标签分类任务中,Semantix在0次重试和2次重试的情况下,均获得了最高的几何平均分数(GMS)和一致性。
- 在命名实体识别任务中,Semantix在0次重试和2次重试的情况下,均获得了最高的GMS和一致性。
- 在合成数据生成任务中,Semantix在0次重试和2次重试的情况下,均获得了最高的GMS和一致性。
推荐阅读指数
⭐⭐⭐⭐⭐
5. Future Token Prediction – Causal Language Modelling with Per-Token Semantic State Vector for Multi-Token Prediction
Authors: Nicholas Walker
https://arxiv.org/abs/2410.18160
未来词元预测 - 用于多词元预测的每个词元语义状态向量的因果语言建模
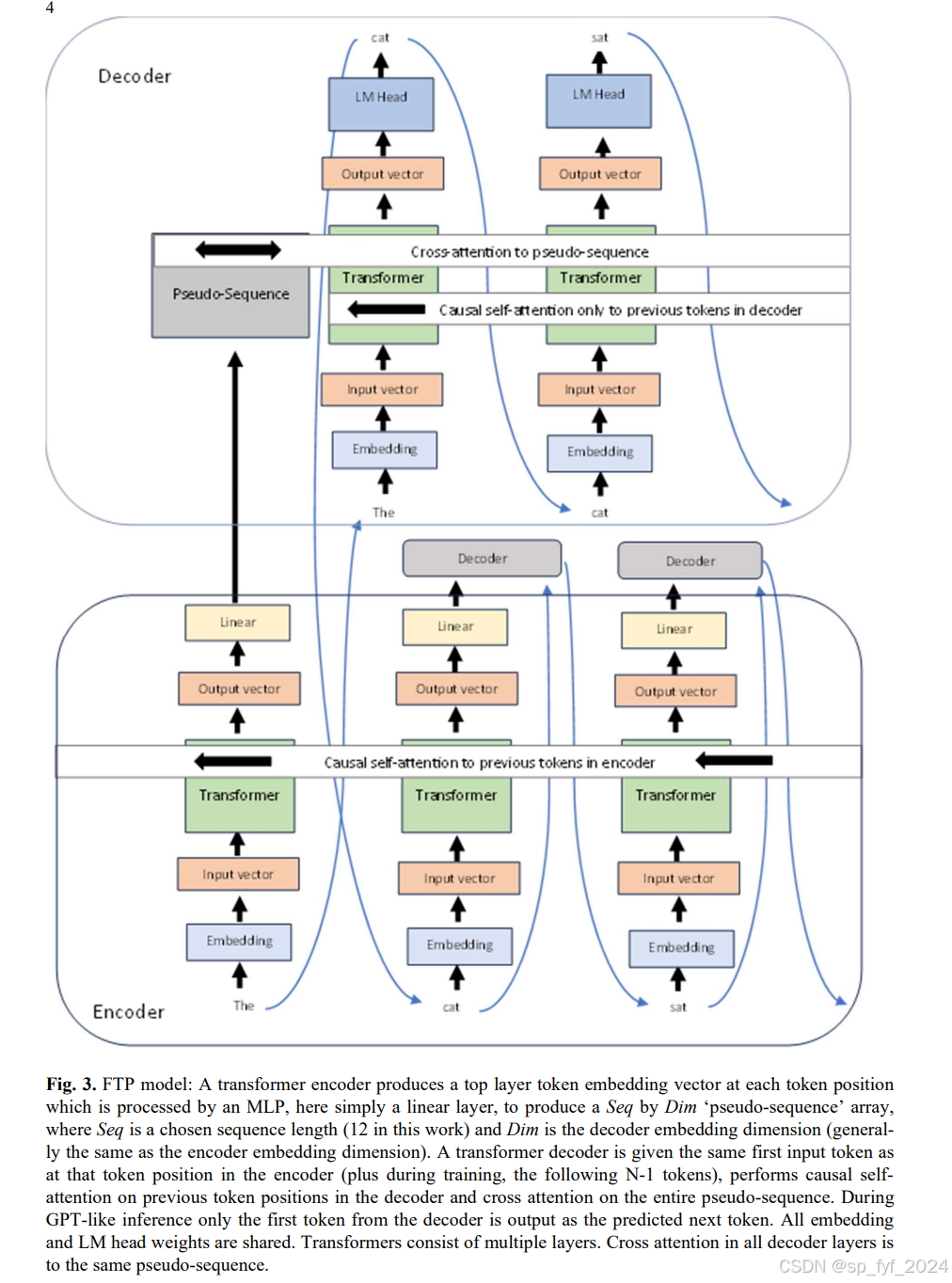
摘要
本研究探讨了一种新的预训练方法,称为未来词元预测(FTP)。在FTP中,大型变换器编码器为每个词元位置生成顶层嵌入向量,这些向量不是被传递到语言头部,而是被线性和扩张性地投影到一个“伪序列”上,然后由小型变换器解码器交叉注意,以预测序列中该位置之后的下一个N个词元。FTP模型的顶层嵌入向量与标准GPT类模型相比具有不同的特性,沿着文本序列平滑变化。FTP模型生成的文本在主题连贯性方面比标准GPT类模型有改进。基于文本分类示例的结果表明,这些向量能更好地表示文本的主题。在一个玩具(但复杂)的编码问题上,FTP网络产生的结果明显优于GPT网络。
研究背景
因果自回归大型语言模型(LLMs),如生成预训练变换器(GPT),在预测序列中的下一个词元方面表现出了强大的AI能力。然而,仅预测下一个词元会导致顶层嵌入向量高度关注词元,可能无法充分捕捉更长文本序列的整体含义。最近的研究表明,人类在听或读时也会预测即将出现的单词,但考虑的是多个未来词元而非仅仅一个。
问题与挑战
尽管LLMs在生成文本方面取得了成功,但它们在长序列生成中容易偏离主题,尤其是在需要生成长序列文本时。此外,现有的LLMs在预测未来词元时,通常只关注下一个词元,而不是未来一系列词元。这种方法可能无法充分利用模型的预测能力,导致生成的文本在语义上不够连贯。
如何解决
为了解决这些问题,研究者提出了FTP方法。FTP通过使用大型变换器编码器生成的顶层嵌入向量,而不是直接用于生成下一个词元的概率分布,而是将这些向量线性和扩张性地投影到一个“伪序列”上。然后,一个小型的变换器解码器被用来交叉注意这个“伪序列”,并预测从该位置开始的序列中的下一个N个词元。这种方法允许模型在生成文本时考虑更远的未来词元,从而提高文本的语义连贯性。
创新点
FTP的主要创新点包括:
- 引入了“伪序列”的概念,通过线性层将顶层嵌入向量扩张性地投影到一个固定长度的序列上,使得解码器可以对其进行交叉注意。
- 通过FTP模型生成的顶层嵌入向量在文本序列中的变化更加平滑,这表明模型能更好地捕捉长文本序列的整体含义。
- FTP模型在预测未来词元时,不仅考虑下一个词元,而是考虑未来一系列词元,这有助于提高文本生成的语义连贯性。
算法模型
FTP模型的核心是一个大型变换器编码器,它为每个输入词元生成一个顶层嵌入向量。这些向量被线性层投影到一个“伪序列”上,然后由一个小型变换器解码器进行交叉注意,以预测序列中的下一个N个词元。在训练过程中,使用教师强制方法,将解码器的输入设置为从编码器输入的最后一个词元开始的N个词元,并以这些词元作为目标进行训练。
实验效果
实验结果表明,FTP模型在生成文本的主题连贯性方面优于标准GPT模型。此外,FTP模型在文本分类任务上的表现也优于GPT模型,表明其生成的向量能更好地代表文本的主题。在一个复杂的编码问题上,FTP网络产生的结果明显优于GPT网络。这些结果表明,FTP模型在多词元预测任务中具有显著的优势。
重要数据与结论
FTP模型的顶层嵌入向量在文本序列中的余弦相似性显著高于GPT模型,表明FTP模型生成的向量在文本序列中的变化更加平滑。在预测未来词元的任务中,FTP模型的表现明显优于GPT模型。在文本生成任务中,FTP模型生成的文本在语义上更接近实际的后续文本,显示出更好的主题连贯性。在编码问题上,FTP模型的生成结果明显优于GPT模型,表明FTP模型在复杂任务中具有更好的性能。
推荐阅读指数
⭐⭐⭐⭐☆
后记
如果觉得我的博客对您有用,欢迎 打赏 支持!三连击 (点赞、收藏、关注和评论) 不迷路,我将持续为您带来计算机人工智能前沿技术(尤其是AI相关的大语言模型,深度学习和计算机视觉相关方向)最新学术论文及工程实践方面的内容分享,助力您更快更准更系统地了解 AI前沿技术。