1 PSM简介
倾向评分匹配(Propensity Score Matching,简称PSM)是一种统计学方法,用于处理观察研究(Observational Study)的数据。
在观察研究中,由于种种原因,数据偏差(bias)和混杂变量(confounding variable)较多,倾向评分匹配的方法正是为了减少这些偏差和混杂变量的影响,以便对实验组和对照组进行更合理的比较。
这种方法最早由Paul Rosenbaum和Donald Rubin在1983年提出,一般常用于医学、公共卫生、经济学等领域。
在医学领域,常用于比较两种干预因素的研究效果
以SEER数据库挖掘过程中,碰到的常见选题,简单举例:
胃癌患者中,手术联合化疗,对比单纯手术,比价两种治疗模式效果
一般情况下,我们直接在文章的表1里面,摆放患者基线特点clinical characteristics
如果此时两种治疗模式下,患者年龄或者性别,存在分布差异
这时候就存在了研究人群变量选择偏移,误差因素就存在里面,结果准确性就值得怀疑,因为我们说不清,两组患者生存差异,是治疗模式加上化疗,带来的差异,还是由于本身两组人群在年龄、性别等因素分布差异所致
PSM的存在,正是为了消除这种基线差异,使我们的分析,更接近于RCT研究,也越来越受到研究者青睐。

2 输入文件及脚本准备
下面带大家演示R语言进行PSM操作
演示文件:data.csv
关注微信公众号,后台回复 PSM ,获取本文示范所用 演示文件、代码及nonrandom本地安装包
2个主要R包:nonrandom 和 tableone
其中nonrandom 包,已被移除,无法通过install.package() 正常安装
不过可以采用本地R包导入的方法
到R package 官网搜索下载即可
下载链接:https://cran.r-project.org/src/contrib/Archive/nonrandom/
这里我们下载最新版本(额。。虽说是最新,也已经是6年前了)
通过R studio-Packages-install-install from Archive. zip or tar.gz, 导入即可
3 匹配过程
install.packages(“nonrandom”)
install.packages(“tableone”)
library(Matching)
library(tableone)
library(nonrandom)
library(reshape2)
library(survey)
library(nonrandom)
mydata
以是否接受化疗,将总人群分为两组
stable
print(stable,showAllLevels = TRUE)
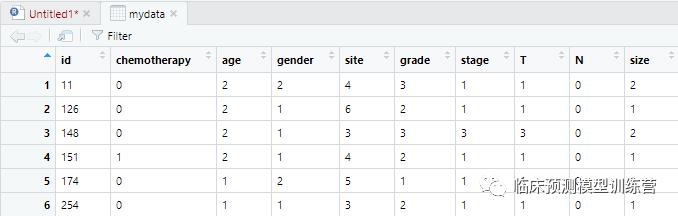
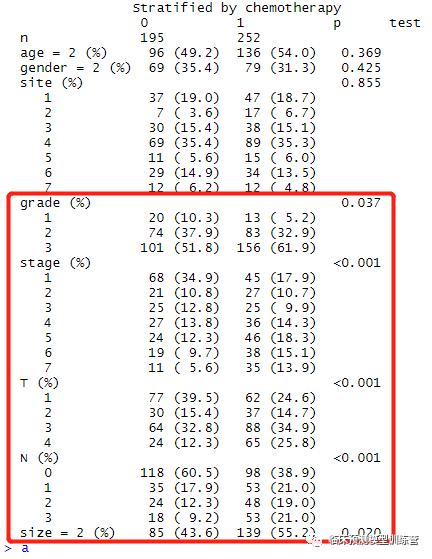
首先,观察两组人群,基线差异
结果如下:变量grade, stage, T分期,N分期,以及tumor size存在分布差异
及混杂、偏移因素,需进行进一步匹配
将分布差异变量,纳入进行匹配
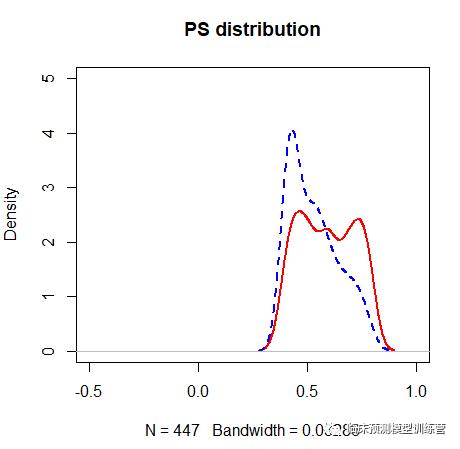
mydata.ps plot.pscore(mydata.ps,with.legend=T,legend.cex=0.6,
main = “PS distribution”,
par.1=list(col=”red”,lwd=2), par.0=list(col=”blue”,lwd=2,lty=2),
xlim=c(-0.5,1))
分布如下:
summary(mydata.ps) #显示logistic回归模型
mydata.ps$data #显示倾向评分数据

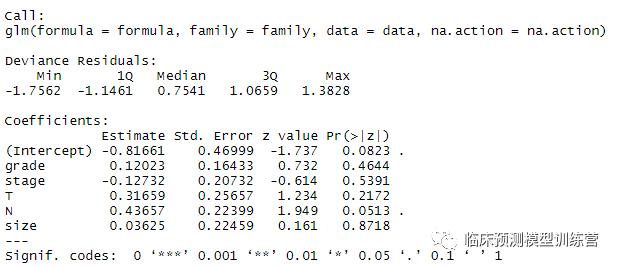
#按照1:1进行匹配,同时通过logit回归,计算每个样本的倾向性分数,即propensity score,也就是被分配为RHC的概率
mydata.match who.treated =1,
ratio = 1,
caliper = “logit”,
x =0.1,
givenTmatchingC = T,
matched.by = “pscore”,
setseed = 12345)
summary(mydata.match)
pairdim(pair)
#最终按照1:1,匹配,各组剩余190名患者,共计380人
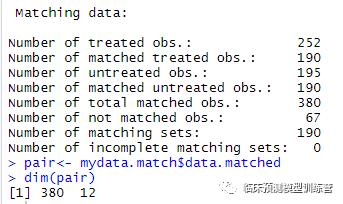
#生成匹配后数据pair.csv
write.csv(pair,”pair.csv”)
#以stage为例,匹配后,依次进行检验,如图所示,两组间分布差异相对变小
dist.plot(object=mydata.match,
sel=c(“stage”),
compare=T,
lable.match=c(“original data”,”matched sample”))
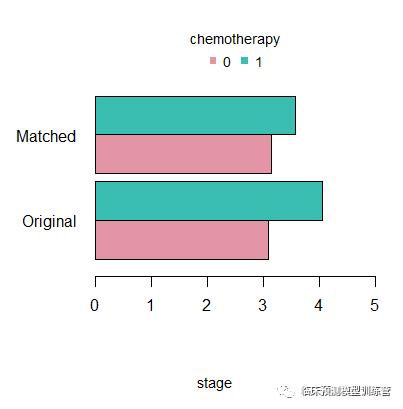
匹配过程结束,后续可直接使用匹配后数据,pair.csv 进行预后或诊断分析。
4 PSM注意事项
- 需要对匹配前后基线特点进行描述
- 需要观察匹配前后,各个变量在组间的分布差异,以评估匹配效果
- 对现有资料,可采用多种统计手段进行验证,若结果一致,则研究可信度增加
- 发挥优势:综合多个协变量信息;可以利用倾向性评分,即propensity score 作为一个新的研究变量,,应用到多个模型中,作为变量创新的一种手段
- 规避缺点:PSM较大依赖于选择的协变量是否合适,即经过PSM,也无法完全规避变量选择偏移。需要较大的样本量进行支持可能导致检验功效power降低,因为匹配过程,伴随样本量削减
- 认识局限性:对未知的/未测量的混杂因素无效对时间依赖性混杂变量无效。

以上是小编对PSM应用的一些心得体会,虚心交流,共同进步~
接下来会示范,采用易侕软件进行PSM操作,更加方便,欢迎关注~
关注 同名微信公众号,后台回复 PSM ,获取本文示范所用 演示文件、代码及nonrandom本地安装包
