文章目录
第九章 细化XML 语句构建器

背景
技术背景
迪米特法则
迪米特法则(Law of Demeter),也被称为最少知识原则,是一种软件设计原则,旨在减少系统中的类和对象之间的耦合度,提高代码的可维护性和可扩展性。通俗来说,迪米特法则的核心思想就是:一个对象应该对其他对象知道得尽量少,只与它直接交互的对象沟通,不要与它知道的所有对象都进行交互。
1. 通俗解释:
假设你是一个班级的老师,你可以直接与学生沟通,但不需要去了解每个学生家里的事情,也不需要直接与学生的父母沟通。你只要关心学生在学校的表现,与你直接相关的信息就够了。
在编程中,假设你有一个对象A,它与另一个对象B进行交互,B又调用了对象C。如果A直接与C交互,那么A就需要了解C的具体实现细节,这样就违反了迪米特法则。按照迪米特法则,A应该只与B交互,B再决定如何与C交互。
2. 迪米特法则的要点:
- 一个对象应该只与以下类型的对象进行交互:
- 自己(自身对象)
- 传入参数的对象
- 自己创建的对象
- 直接拥有的对象(成员变量)
- 不要和“陌生人”打交道。如果你需要了解某个对象的内部实现,最好通过一个简单的接口来访问,而不是直接操作它。
3. 举例:
假设我们有一个汽车对象,它包含一个发动机对象,而发动机对象又包含一个油箱对象。我们希望通过调用汽车的启动方法来启动整个系统。如果汽车直接去调用油箱的某些细节,就违反了迪米特法则。
违反迪米特法则的代码:
class Engine {
private FuelTank fuelTank;
public Engine(FuelTank fuelTank) {
this.fuelTank = fuelTank;
}
public boolean isFuelEmpty() {
return fuelTank.getFuelLevel() == 0;
}
}
class Car {
private Engine engine;
public Car(Engine engine) {
this.engine = engine;
}
public void start() {
if (engine.isFuelEmpty()) {
System.out.println("Not enough fuel!");
} else {
System.out.println("Car is starting...");
}
}
}
在上面的代码中,Car类直接调用了engine.isFuelEmpty(),而engine又通过fuelTank.getFuelLevel()来判断油箱的燃料是否用完。Car类不应该直接与fuelTank进行交互,它应该只关心engine是否准备好。
改进后的代码(符合迪米特法则):
class FuelTank {
private int fuelLevel;
public FuelTank(int fuelLevel) {
this.fuelLevel = fuelLevel;
}
public boolean isEmpty() {
return fuelLevel == 0;
}
}
class Engine {
private FuelTank fuelTank;
public Engine(FuelTank fuelTank) {
this.fuelTank = fuelTank;
}
public boolean canStart() {
return !fuelTank.isEmpty();
}
}
class Car {
private Engine engine;
public Car(Engine engine) {
this.engine = engine;
}
public void start() {
if (engine.canStart()) {
System.out.println("Car is starting...");
} else {
System.out.println("Not enough fuel!");
}
}
}
在改进后的代码中,Car类只与Engine类交互,Engine类内部会决定如何与FuelTank类交互。这样,Car类不需要知道油箱的具体细节,符合迪米特法则,降低了类之间的耦合度。
业务背景
实现到本章节前,关于 Mybatis ORM 框架的大部分核心结构已经逐步体现出来了,包括:解析、绑定、映射、事务、执行、数据源等。
但随着更多功能的逐步完善,我们需要对模块内的实现进行细化处理,而不单单只是完成功能逻辑。
这就有点像把 CRUD 使用设计原则进行拆分解耦,满足代码的易维护和可扩展性。
而这里我们首先着手要处理的就是关于 XML 解析的问题,把之前粗糙的实现进行细化,满足我们对解析时一些参数的整合和处理。
private void mapperElement(Element mappers) throws Exception {
//获取mappers标签下的所有mapper标签.
List<Element> mapperList = mappers.elements("mapper");
for (Element mapper : mapperList) {
//获取mapper标签的resource属性.
String resource = mapper.attributeValue("resource");
Reader reader = Resources.getResourceAsReader(resource);
SAXReader saxReader = new SAXReader();
Document document = saxReader.read(new InputSource(reader));
Element root = document.getRootElement();
//命名空间
String namespace = root.attributeValue("namespace");
//SELECT 解析语句.
List<Element> selectNodes = root.elements("select");
for (Element node : selectNodes) {
String id = node.attributeValue("id");
String parameterType = node.attributeValue("parameterType");
String resultType = node.attributeValue("resultType");
String sql = node.getText();
// ?匹配
Map<Integer, String> parameter = new HashMap<>();
Pattern pattern = Pattern.compile("(#\\{(.*?)})");
Matcher matcher = pattern.matcher(sql);
//匹配到的参数替换为?
for (int i = 1; matcher.find(); i++) {
String g1 = matcher.group(1);
String g2 = matcher.group(2);
parameter.put(i, g2);
sql = sql.replace(g1, "?");
}
String msId = namespace + "." + id;
String nodeName = node.getName();
SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH));
// 构建BoundSql.
BoundSql boundSql = new BoundSql(sql, parameter, parameterType, resultType);
MappedStatement mappedStatement = new MappedStatement.Builder(configuration, msId, sqlCommandType,
boundSql).build();
// 添加解析SQL
configuration.addMappedStatement(mappedStatement);
}
// 注册Mapper映射器.
configuration.addMapper(Resources.classForName(namespace));
}
}
- 这一部分的解析,是XMLConfigBuilder#mapperElement 方法中的操作。能实现功能,但不够规整。如果按照我们平常开发CRUD的习惯,功能代码揉在一块,虽然什么流程都能处理,但后续代码会越来越混乱,最后难逃重构的结果。
- 本章节把上述部分解析处理,使用设计原则将流程和职责进行解耦,并结合我们的当前诉求,优先
处理静态 SQL 内容。 - 待框架结构逐步完善,再进行一些动态SQL和更多参数类型的处理,满足读者以后在阅读 Mybatis 源码,或者需要开发自己的 X-ORM 框架的时候,可以有一些经验积累。
目标
基于当前框架实现,使用设计原则将XML解析的流程和职责进行解耦,优先处理静态 SQL 内容。
设计
参照设计原则,对于 XML 信息的读取,各个功能模块的流程上应该符合单一职责,而每一个具体的实现又得具备迪米特法则,这样实现出来的功能才能具有良好的扩展性。通常这类代码也会看着很干净 那么基于这样的诉求,我们则需要给解析过程中,所属解析的不同内容,按照各自的职责类进行拆解和串联调用。整体设计如图 :
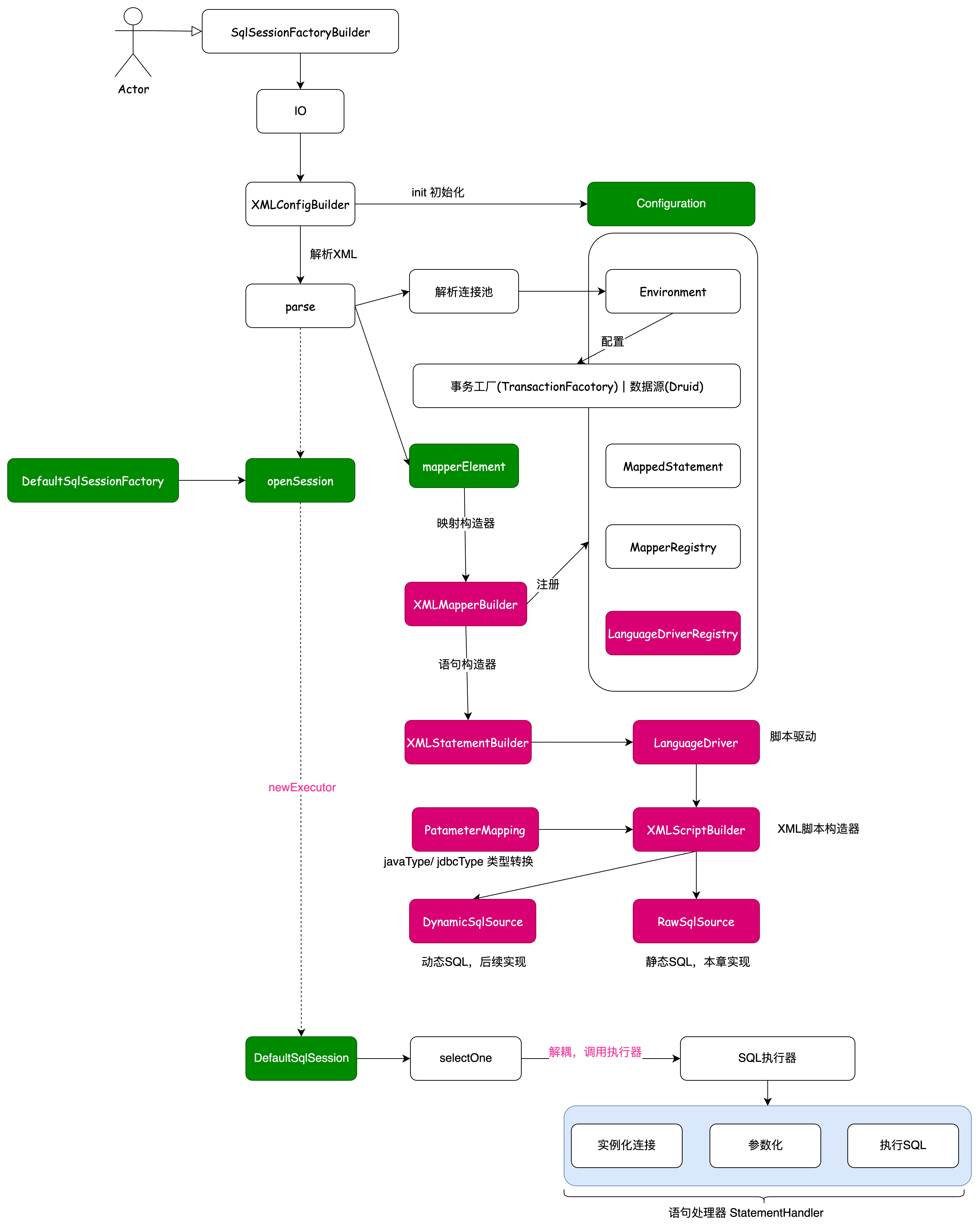
- 之前的解析代码,把所有的解析都在一个循环中处理。 现在解析过程中,引入 XMLMapperBuilder解析Mapper,引入XMLStatementBuilder 解析MappedStatement,按照不同的职责分别进行解析。
- 在语句构建器中,引入脚本语言驱动器,默认实现的是 XML语言驱动器 XMLLanguageDriver,这个类来具体操作静态和动态 SQL 语句节点的解析。这部分的解析处理实现方式很多,为了保持与 Mybatis 的统一,我们直接参照源码 Ognl 的方式进行处理。对应的类是 DynamicContext。
- 这里所有的解析铺垫,通过解耦的方式实现,都是为了后续在 executor 执行器中,更加方便的处理 setParameters 参数的设置。后面参数的设置,也会涉及到前面我们实现的元对象反射工具类的使用。
实现
工程代码
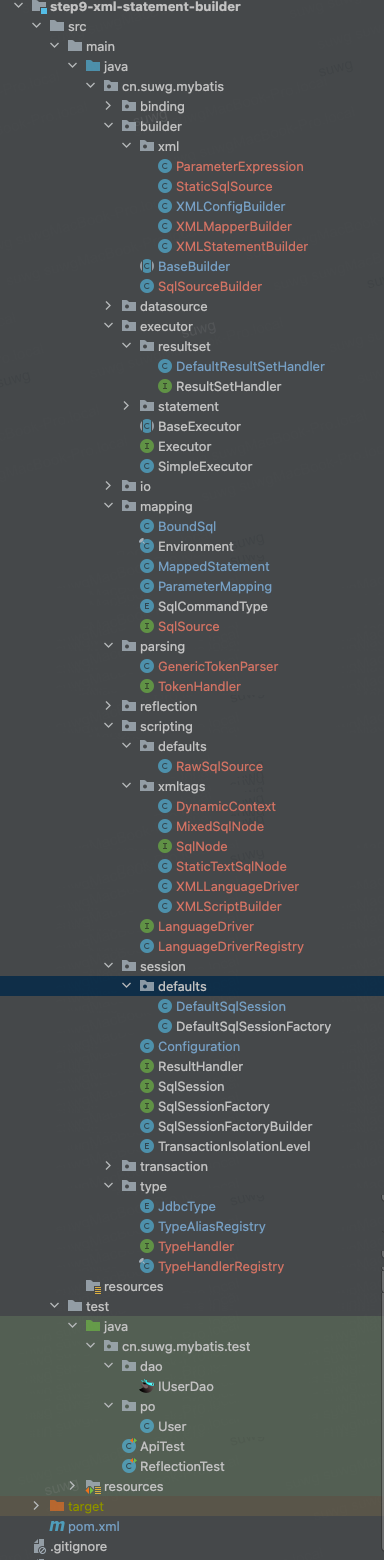
类图
- 解耦原 XMLConfigBuilder 中对 XML 的解析,扩展映射构建器、语句构建器,处理 SQL 的提取和参数的包装,整个核心流图以 XMLConfigBuilder#mapperElement 为入口进行串联调用。
- 在 XMLStatementBuilder#parseStatementNode 方法中解析
<select> ...</select>配置语句内容,提取参数类型、结果类型。 - 这里的语句处理流程稍微较长,因为需要用到脚本语言驱动器,进行解析处理,创建出 SqlSource 语句信息。
- SqlSource 包含了 BoundSql,同时扩展了
ParameterMapping 作为参数包装传递类,而不是仅仅作为 Map 结构包装。因为通过这样的方式,可以封装解析后的 javaType/jdbcType 信息。
实现步骤
-
1.解耦映射解析
XMLMapperBuilder
- 提供单独的 XML 映射构建器 XMLMapperBuilder 类,把关于 Mapper 内的 SQL 进行解析处理。
- configuration.isResourceLoaded 资源判断避免重复解析,做了个记录。
- configuration.addMapper 绑定映射器主要是把 namespace
cn.suwg.mybatis.test.dao.IUserDao绑定到 Mapper 上。也就是注册到映射器注册机里。
public class XMLMapperBuilder extends BaseBuilder { private Element element; private String resource; private String currentNamespace; public XMLMapperBuilder(InputStream inputStream, Configuration configuration, String resource) throws DocumentException { this(new SAXReader().read(inputStream), configuration, resource); } private XMLMapperBuilder(Document document, Configuration configuration, String resource) { super(configuration); this.element = document.getRootElement(); this.resource = resource; } /** * 解析. * * @throws Exception */ public void parse() throws Exception { // 如果当前资源没有加载过再加载,防止重复加载 if (!configuration.isResourceLoaded(resource)) { // 配置mapper元素 configurationElement(element); // 标记一下,已经加载过了 configuration.addLoadedResource(resource); // 绑定映射器到namespace configuration.addMapper(Class.forName(currentNamespace)); } } // <mapper namespace="org.mybatis.example.BlogMapper"> // <select id="selectBlog" parameterType="int" resultType="Blog"> // select * from Blog where id = #{id} // </select> // </mapper> /** * 配置mapper元素. */ private void configurationElement(Element element) { // 1.配置namespace currentNamespace = element.attributeValue("namespace"); if (currentNamespace.equals("")) { throw new RuntimeException("Mapper's namespace cannot be empty"); } // 2.解析sql语句,配置select | insert | update | delete buildStatementFromContext(element.elements("select")); } private void buildStatementFromContext(List<Element> list) { for (Element element : list) { final XMLStatementBuilder statementParser = new XMLStatementBuilder(configuration, element, currentNamespace); statementParser.parseStatementNode(); } } }
XMLMapperBuilder
- 在 XMLConfigBuilder#mapperElement 中,把原来流程化的处理进行解耦,调用 XMLMapperBuilder#parse 方法进行解析处理。
public class XMLConfigBuilder extends BaseBuilder {
private Element root;
...
private void mapperElement(Element mappers) throws Exception {
//获取mappers标签下的所有mapper标签.
List<Element> mapperList = mappers.elements("mapper");
for (Element mapper : mapperList) {
//获取mapper标签的resource属性.
String resource = mapper.attributeValue("resource");
//获取输入流
InputStream inputStream = Resources.getResourceAsStream(resource);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource);
mapperParser.parse();
}
}
}
-
2. 语句构建器
XMLStatementBuilder
-
XMLStatementBuilder 语句构建器主要解析 XML 中
select|insert|update|delete中的语句,当前我们先以 select 解析为案例,后续再扩展其他的解析流程。 -
这部分内容的解析,实现了 XMLConfigBuilder中关于 Mapper 语句的解析,通过这样解耦设计,会让整个流程更加清晰。
-
XMLStatementBuilder#parseStatementNode 方法是解析 SQL 语句节点的过程,包括了语句的ID、参数类型、结果类型、命令(
select|insert|update|delete),以及使用语言驱动器处理和封装SQL信息,当解析完成后写入到 Configuration 配置文件中的Map<String, MappedStatement>映射语句存放中。
public class XMLStatementBuilder extends BaseBuilder {
private String currentNamespace;
private Element element;
public XMLStatementBuilder(Configuration configuration, Element element, String currentNamespace) {
super(configuration);
this.element = element;
this.currentNamespace = currentNamespace;
}
//解析语句(select|insert|update|delete)
//<select
// id="selectPerson"
// parameterType="int"
// parameterMap="deprecated"
// resultType="hashmap"
// resultMap="personResultMap"
// flushCache="false"
// useCache="true"
// timeout="10000"
// fetchSize="256"
// statementType="PREPARED"
// resultSetType="FORWARD_ONLY">
// SELECT * FROM PERSON WHERE ID = #{id}
//</select>
public void parseStatementNode() {
String id = element.attributeValue("id");
// 参数类型
String parameterType = element.attributeValue("parameterType");
Class<?> parameterTypeClass = resolveAlias(parameterType);
// 结果类型
String resultType = element.attributeValue("resultType");
Class<?> resultTypeClass = resolveAlias(resultType);
// 获取命令类型(select|insert|update|delete)
String nodeName = element.getName();
SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH));
// 获取默认语言驱动器
Class<?> langClass = configuration.getLanguageRegistry().getDefaultDriverClass();
LanguageDriver langDriver = configuration.getLanguageRegistry().getDriver(langClass);
SqlSource sqlSource = langDriver.createSqlSource(configuration, element, parameterTypeClass);
MappedStatement mappedStatement = new MappedStatement.Builder(configuration, currentNamespace + "." + id,
sqlCommandType, sqlSource, resultTypeClass)
.build();
// 添加解析 SQL
configuration.addMappedStatement(mappedStatement);
}
}
3. 脚本语言驱动
- 在 XMLStatementBuilder#parseStatementNode 语句构建器的解析中,本章节获取默认语言驱动器并解析SQL的操作。
- 这部分就是 XML 脚本语言驱动器所实现的功能,在 XMLScriptBuilder 中处理静态SQL和动态SQL,不过目前我们只是实现了其中的一部分,待后续这部分框架都完善后在进行扩展,避免一次引入过多的代码。
3-1 定义语言驱动接口
LanguageDriver
- 定义脚本语言驱动接口,提供创建 SQL 信息的方法,入参包括了配置、元素、参数。其实它的实现类一共有3个;
XMLLanguageDriver、RawLanguageDriver、VelocityLanguageDriver,这里我们只是实现了默认的第一个即可。
public interface LanguageDriver {
SqlSource createSqlSource(Configuration configuration, Element script, Class<?> parameterType);
}
3-2 XML语言驱动器实现
XMLLanguageDriver
- 关于 XML 语言驱动器的实现比较简单,只是封装了对 XMLScriptBuilder 的调用处理。
public class XMLLanguageDriver implements LanguageDriver {
@Override
public SqlSource createSqlSource(Configuration configuration, Element script, Class<?> parameterType) {
// 用XML脚本构建器解析
XMLScriptBuilder builder = new XMLScriptBuilder(configuration, script, parameterType);
return builder.parseScriptNode();
}
}
3-3 XML脚本构建器解析
XMLScriptBuilder
- XMLScriptBuilder#parseScriptNode 解析SQL节点的处理其实没有太多复杂的内容,主要是对
RawSqlSource 的包装处理。其他小细节可以阅读源码进行学习
public class XMLScriptBuilder extends BaseBuilder {
private Element element;
private boolean isDynamic;
private Class<?> parameterType;
public XMLScriptBuilder(Configuration configuration, Element element, Class<?> parameterType) {
super(configuration);
this.element = element;
this.parameterType = parameterType;
}
public SqlSource parseScriptNode() {
List<SqlNode> contents = parseDynamicTags(element);
MixedSqlNode rootSqlNode = new MixedSqlNode(contents);
return new RawSqlSource(configuration, rootSqlNode, parameterType);
}
private List<SqlNode> parseDynamicTags(Element element) {
List<SqlNode> contents = new ArrayList<>();
// element.getText 拿到 SQL
String data = element.getText();
contents.add(new StaticTextSqlNode(data));
return contents;
}
}
3-4 SQL源码构建器
SqlSourceBuilder
- BoundSql.parameterMappings 的参数就是来自于 ParameterMappingTokenHandler#buildParameterMapping 方法进行构建处理的。
- 具体的 javaType、jdbcType 会体现到 ParameterExpression 参数表达式中完成解析操作。这个解析过程直接是 Mybatis 自己的源码,整个过程功能较单一,直接对照学习即可
public class SqlSourceBuilder extends BaseBuilder {
private static final String parameterProperties = "javaType,jdbcType,mode,numericScale,resultMap,typeHandler,jdbcTypeName";
public SqlSourceBuilder(Configuration configuration) {
super(configuration);
}
public SqlSource parse(String originalSql, Class<?> parameterType, Map<String, Object> additionalParameters) {
ParameterMappingTokenHandler handler = new ParameterMappingTokenHandler(configuration, parameterType, additionalParameters);
GenericTokenParser parser = new GenericTokenParser("#{", "}", handler);
String sql = parser.parse(originalSql);
// 返回静态 SQL
return new StaticSqlSource(configuration, sql, handler.getParameterMappings());
}
private static class ParameterMappingTokenHandler extends BaseBuilder implements TokenHandler {
private List<ParameterMapping> parameterMappings = new ArrayList<>();
private Class<?> parameterType;
private MetaObject metaParameters;
public ParameterMappingTokenHandler(Configuration configuration, Class<?> parameterType, Map<String, Object> additionalParameters) {
super(configuration);
this.parameterType = parameterType;
this.metaParameters = configuration.newMetaObject(additionalParameters);
}
public List<ParameterMapping> getParameterMappings() {
return parameterMappings;
}
@Override
public String handleToken(String content) {
parameterMappings.add(buildParameterMapping(content));
return "?";
}
// 构建参数映射
private ParameterMapping buildParameterMapping(String content) {
// 先解析参数映射,就是转化成一个 HashMap | #{favouriteSection,jdbcType=VARCHAR}
Map<String, String> propertiesMap = new ParameterExpression(content);
String property = propertiesMap.get("property");
Class<?> propertyType = parameterType;
ParameterMapping.Builder builder = new ParameterMapping.Builder(configuration, property, propertyType);
return builder.build();
}
}
}
4. DefaultSqlSession 调用调整
本章中调整了解析过程,细化了 SQL 的创建。在 MappedStatement 映射语句中,使用 SqlSource 替换了 BoundSql,所以在 DefaultSqlSession 中也会有相应的调整,主要体现在获取SQL操作
ms.getSqlSource().getBoundSql(parameter)
public class DefaultSqlSession implements SqlSession {
/**
* 配置项.
*/
private Configuration configuration;
private Executor executor;
public DefaultSqlSession(Configuration configuration, Executor executor) {
this.configuration = configuration;
this.executor = executor;
}
public Configuration getConfiguration() {
return configuration;
}
/**
* 根据给定的执行SQL获取一条记录的封装对象.
*
* @param statement
* @param <T>
* @return
*/
@Override
public <T> T selectOne(String statement) {
return this.selectOne(statement, null);
}
@Override
public <T> T selectOne(String statement, Object parameter) {
//映射语句
MappedStatement mappedStatement = configuration.getMappedStatement(statement);
//使用执行器.
List<T> list = executor.query(mappedStatement, parameter, Executor.NO_RESULT_HANDLER, mappedStatement.getSqlSource()
.getBoundSql(parameter));
return list.get(0);
}
@Override
public <T> T getMapper(Class<T> type) {
return configuration.getMapper(type, this);
}
}
测试
事先准备
创建库表
-- 建表
CREATE TABLE `my_user` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '自增ID',
`user_id` varchar(9) DEFAULT NULL COMMENT '用户ID',
`user_head` varchar(16) DEFAULT NULL COMMENT '用户头像',
`create_time` timestamp NULL DEFAULT NULL COMMENT '创建时间',
`update_time` timestamp NULL DEFAULT NULL COMMENT '更新时间',
`user_name` varchar(64) DEFAULT NULL COMMENT '用户名',
`user_password` varchar(64) DEFAULT NULL COMMENT '用户密码',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 ;
-- 插入数据
INSERT INTO my_user (user_id, user_head, create_time, update_time, user_name, user_password) VALUES('1', '头像', '2024-12-13 18:00:12', '2024-12-13 18:00:12', '小苏', 's123asd');
定义一个数据库接口 IUserDao
IUserDao
public interface IUserDao {
String queryUserInfoById(String uid);
}
配置数据源
- 通过
mybatis-config-datasource.xml配置数据源信息,包括:driver、url、username、password - 这里DataSource 配置的是 DRUID,因为我们实现的是这个数据源的处理方式。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="UNPOOLED"> #无池化时配置成这个类型值
<dataSource type="POOLED"> #池化时配置城这个类型值
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://127.0.0.1:3306/mybatis?useUnicode=true"/>
<property name="username" value="root"/>
<property name="password" value="123456"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="mapper/User_Mapper.xml"/>
</mappers>
</configuration>
定义对应的mapper xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="cn.suwg.mybatis.test.dao.IUserDao">
<select id="queryUserInfoById" parameterType="java.lang.Long" resultType="cn.suwg.mybatis.test.po.User">
SELECT id, user_id, user_head, create_time
FROM user
where id = #{id}
</select>
</mapper>
测试用例
- 单元测试,传递一个 1L 的 long 类型参数,进行方法的调用处理。通过单元测试验证执行器的处理过程,读者在学习的过程中可以进行断点测试,学习每个过程的处理内容。
- mybatis-config-datasource.xml 中 dataSource 数据源类型的调整
dataSource type="DRUID/POOLED/UNPOOLED",按需配置验证.
单元测试
- 这里的测试不需要调整,因为我们本章节的开发内容,主要以解耦 XML 的解析,只要能保持和之前章节一样,正常输出结果就可以。
public class ApiTest {
private Logger logger = LoggerFactory.getLogger(ApiTest.class);
// 测试SqlSessionFactory
@Test
public void testSqlSessionFactory() throws IOException {
// 1.从xml文件读取mybatis配置项, 从SqlSessionFactory获取SqlSession.
Reader reader = Resources.getResourceAsReader("mybatis-config-datasource.xml");
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(reader);
SqlSession sqlSession = sqlSessionFactory.openSession();
// 2.获取映射器对象
IUserDao userDao = sqlSession.getMapper(IUserDao.class);
// 4.测试验证
User user = userDao.queryUserInfoById(1L);
logger.info("测试结果:{}", JSON.toJSONString(user));
}
}
测试结果
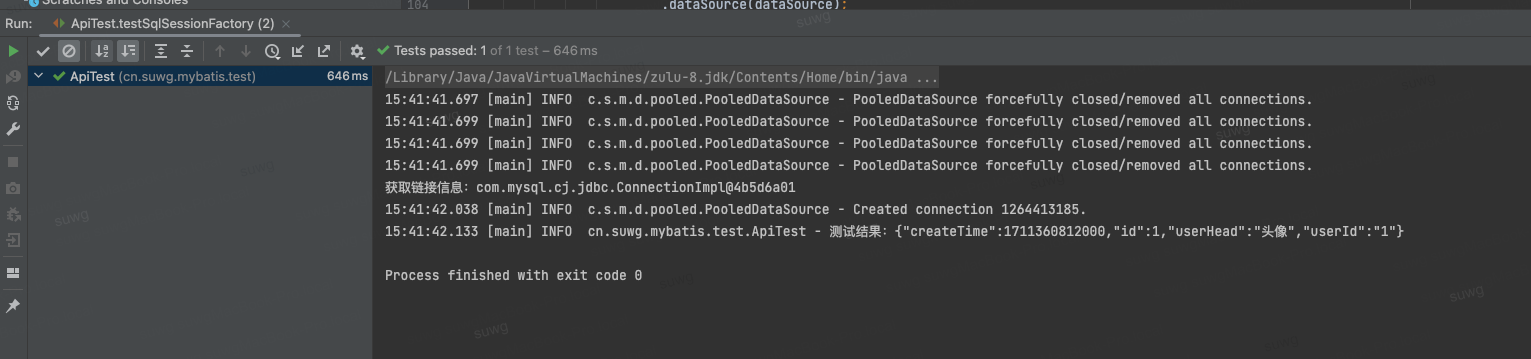
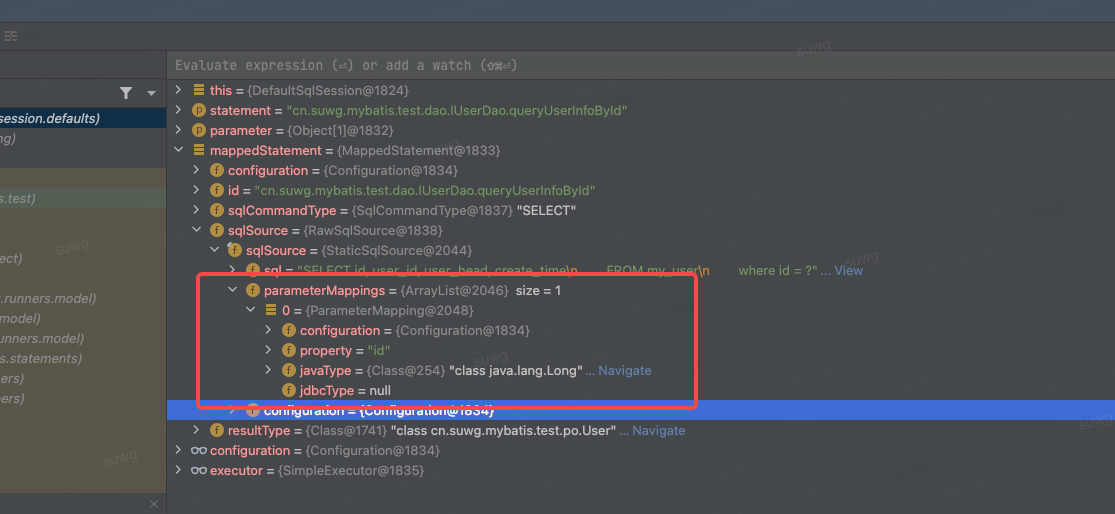
- 从输出的结果来看,我们的XML解析处理已经顺利根据职责进行解耦。整个流程更加清晰了,后续我们扩展就更方便了。
总结
- 本章节把一整块实现功能流程的代码块,通过设计原则进行拆分和解耦,运用不用的类来承担不同的职责,完成整个功能的实现。包括:
映射构建器、语句构建器、源码构建器的综合使用,以及对应的引用脚本语言驱动和脚本构建器解析,处理我们的 XML 中的 SQL 语句。 - 通过这样的
重构代码,也能让我们对平常的业务开发中的大片面向过程的流程代码有所感悟,当你可以细分拆解职责功能到不同的类中去以后,你的代码会更加的清晰并易于维护。 - 后续我们将继续按照现在的扩展结构底座,完成其他模块的功能逻辑开发,因为了这些基础内容的建造,再继续补充功能也会更加容易。当然这些代码还是需要你熟悉以后才能驾驭,在学习的过程中可以尝试断点调试,看看每一个步骤都在完成哪些工作。
参考书籍:《手写Mybatis渐进式源码实践》
书籍源代码:https://github.com/fuzhengwei/book-small-mybatis