视觉感知——深度学习之YOLOv3算法
博主之前就写过关于一篇关于自动驾驶传感器感知技术的博文——《汽车电子技术——传感器感知技术》,正如博文中所说的自动驾驶涉及的相关的知识非常广博及复杂,必然不是一篇博文或一本书就可以说明白的。当时自己也是基于在传感器项目的部分研发支持工作及积累,主要简单的介绍和呈现了关于传感器基本原理和结构相关的知识。现在就自己当前项目中所接触到的传感器融合感知这块,简单写写传感器融合算法相关的知识,也算是接着自己之前的传感器感知博文,来个延续讨论学习了。
不同的传感器一般先需要经过时间和空间的对齐,然后才是各传感器的数据采集、标注,再开展单传感器的不同程度的处理算法,最后是多传感器的融合算法的模型训练和预测输出。由于我们的项目主要是摄像头与激光雷达的融合感知,在这篇文章在算法这块,我就暂且在摄像头感知这块,简单讲讲视觉的深度学习YOLOv3。
1. 传感器融合
目前,单一传感器已不能满足车辆在复杂道路交通环境下的目标检测,造成人身安全隐患。数据融合被应用到各个领域,包括军事、物体识别、探测等多个领域。各国政府出台相应政策加大数据融合研究力度弥补单一传感器探测精度低、易受外界环境干扰(如室外天气、硬件设备故障、光线影响)无法应对复杂行驶环境等问题。数据融合通过传感器对周围环境感知,通过融合算法解决跟踪、识别、探测、定位等问题,增强监测系统精度的实时性。为满足复杂多变的环境,保证行驶安全,我国开始重点发展这一技术,大量科研人员在政府出台政策下对多传感器数据融合进行研究。
目前,多传感器融合技术主要有以下三种层次:
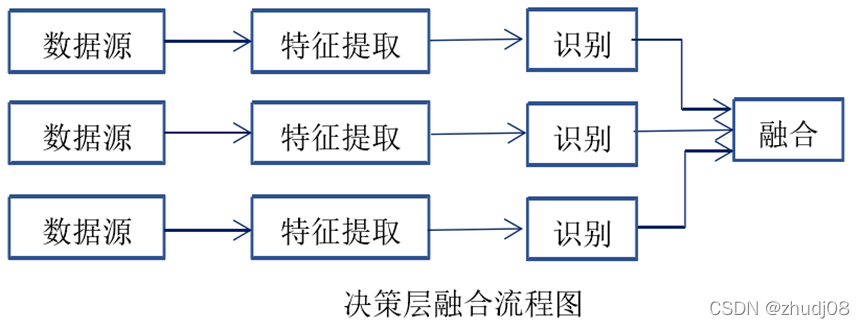
(1)Data像素级融合
像素级融合又被称为数据级融合。这种融合方式对各传感器输出的原始数据不进行处理或者处理较简单,该方法通过对传感器原始数据进行关联匹配,输入融合系统后系统自动完成特征提取与目标识别。虽然该融合方式属于低层次的融合方式,但它是目前信息融合研究的重点之一,因为这种方式可以保留较多的传感器原始数据,提供更加精确、更加精密的信息。但是,由于这种方式数据量较大,数据处理难度高,因而其实时性较差,且其数据预处理较少,因而数据容易受到外部环境的干扰,致使其抗干扰能力较差,且其对各传感器输出数据的类型有较为严格的要求。
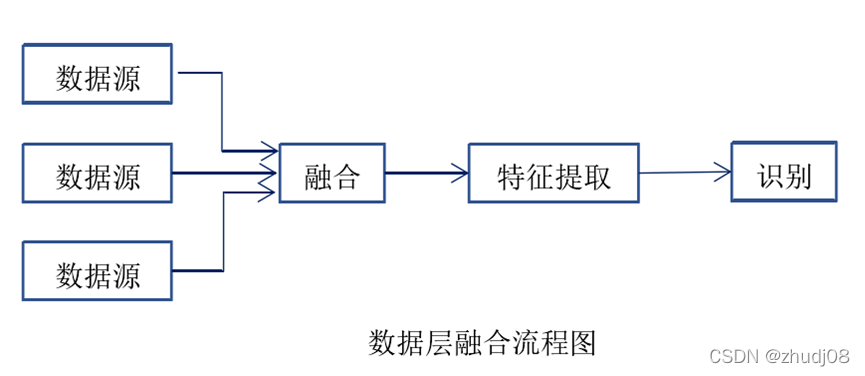
(2)Feature特征级融合
特征层融合属于中间层次的融合,这种方法先从每种传感器提供的观测数据中提取的有代表性的特征,再将这些特征融合成单一的特征向量,然后运用模式识别的方法进行处理。这种方法的计算量有所降低,实时性有所提高,但由于部分数据的舍弃使得其准确性有所下降。
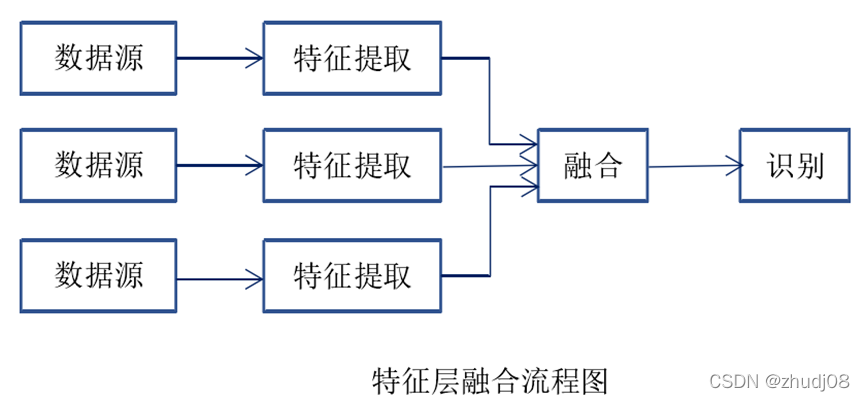
(3)Decision 决策级融合
决策级融合是最高层次的融合。决策级融合会将各传感器数据单独处理,得到目标结果后,对各传感器的结果进行匹配关联。决策级融合对各个传感器在数据预处理能力要求较高,但是其应用较广,原因主要是其容错性强,数据计算量低,且其对传感器数据类型无要求,传感器兼容性好。
在各类传感器中,毫米波雷达传感器判别位置信息能力强但覆盖区域局限,存在检测盲点。视觉摄像头能够有效获取目标特征,但无法获取位置信息。针对上述问题进行研究以适应现代交通发展趋势,与单一传感器相比,数据融合的优势在于同时处理多个数据信息,实时检测周边环境,综合人工智能技术减少数据处理的冗余矛盾,进行数据分析,从而减少事故风险。
利用传感器数据融合弥补单一传感器存在的问题,提高检测效率与实时性研究中传感器的选定类型与数量成为提升环境感知目标检测的方法,国内外研究学者针对不同算法作为目标检测的底层架构的课题开展研究,常用毫米波雷达与摄像头、激光雷达与摄像头融合结合的方式进行检测。数据融合能够满足当前汽车环境行驶需求,是未来国防发展必不可少的要素,因此,减少多传感器数据融合处理时间成为科研人员的研究新热点。
2. 深度学习算法
在卷积神经网络出现之前,传统的目标检测算法是通过人工设计特征学习的方式实现,并根据针对检测目标的不同有相应的方法。早期目标检测虽然满足当时的检测需求但仍有许多弊端,首先基于手工设计的前提是必须拥有丰富的先验知识,具备较强的专业性,其次传统的特征提取常基于形状、颜色、纹理、边缘、角点等视觉特点进行,那么特征的质量就决定了检测性能,当面对遮挡,光线等不可避免的实际问题时并没有很好的鲁棒性。
经典的神经网络 Le Net 诞生于 1998 年,由于当时更倾向于基于手工设计特征的传统目标检测技术并没有掀起波澜,在该技术停滞了两年之久后才终于在 2012 年发掘到神经网络的潜力,神经网络学习依靠逐步发展 GPU 算力成为以深度神经网络为核心的人工智能技术,也成为从学者的实验室走向大规模产业应用的转折点,迎来了历史性的突破。卷积神经网络依靠其强大的特征提取和卷积核自适应学习能力逐渐替代传统方法,获得了更可靠的结果,使计算机大数据呈现爆炸式发展成为并延续至今。
2.1 卷积神经网络CNN
卷积神经网络是基于深度学习目标检测的基础结构,也是最具有影响力的模型之一,其本质具有多层级构造的感知机,源于生物学家研究猫视觉皮层时发现的一种对视觉输入空间敏感的被称为感受野的区域,感受野的概念也被着重地应用于神经网络中。基于此概念,研究人员深入研究将一个图片的视觉模式分解成许多子特征,比如颜色、纹理、形状等信息,并对子特征局部感知特征进行分层递阶式处理,相邻像素特征关系强,根据像素关系的优先级逐层递进融合信息,最后全局融合得到了完整的识别任务。得益于卷积神经网络中使用局部感受野,权值共享的核心思想在图像处理与识别得到了令人惊喜的效果,卷积神经网络一般包含有卷积层,池化层,全联接层,这三种层级能够几乎同时的进行特征的提取、选择、分类,且特征的选取更倾向于易于分类的特征且网络结构较好地适应图像的结构,共享权值操作可以减少网络的训练参数避免训练的过拟合。
在CSDN上众多大神已经写了很多通俗易懂的文章,大家可以自己查找。我这里也给出一些博客及视频推荐,供大家参考学习:
博文——CNN笔记:通俗理解卷积神经网络
视频——大白话讲解卷积神经网络工作原理
2.2 YOLO算法
YOLO网络由 Joseph Redmon 等在 2016 年提出,即将物体检测问题处理成回归问题,用一个卷积神经网络采用端到端的处理方式同时对图像中目标的位置和所属类别进行预测。YOLO v3 由 YOLO v1,YOLO v2 改进而来,针对 YOLO v1 中的目标预测框召回率较低的问题上,通过使用基于锚框的目标区域采集方式,大幅增加了目标预测区域的数量,提升了目标区域的召回率,有效降低了 YOLO v1 在目标重叠时目标漏检数量。YOLO v3 在 YOLO v2 网络的基础上改进骨干提取网络,提升了骨干网络对输入图像的特征提取能力。同时针对 YOLO v2 浅层预测分支预测性能较差的问题,使用 FPN 结构,通过自顶向下的特征融合流,提升了浅层网络的检测能力。YOLO v3 作为一阶段目标检测网络中的代表性网络,由于其良好的泛化能力和较快的检测速度,以及高移植性,被广泛的应用于各个领域的检测任务中。
同样的,CSDN上众多的大佬们已经把YOLO相关算法核心知识做了很多的分享,大家也可以参考学习:
深入浅出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基础知识完整讲解
yolo系列之yolo v3【深度解析】
3. YOLO v3算法实践
3.1 官方数据集参考
自己当时研究该算法,主要也是直接参考官方数据集来做,查阅了较多的博主的博文分享,但是有些写得并不够详尽,众多对比看下来,下面这篇博文不错,论述详尽到位,也给出供大家参考。
【YOLO】使用VOC数据集训练自己的YOLOv3模型
(Keras/TensorFlow)
3.2 环境配置
关于深度学习相关的环境配置及相关库描述,大家可以参考博主之前的博文,里面已经论述过:
机器学习实战之路 —— 专栏汇总目录
Python提供了大量机器学习与深度学习相关的库,博主电脑中都是较早之前安装的,所以版本较老,现在有更新的版本,大家可以安装新版做好匹配即可,不过在此也给出自己电脑的相关主要python库版本以供参考。以下这些Python库的版本相互匹配都没有问题的。自己电脑的配置主要如下:
Tensorflow 1.5.0 + Keras 2.1.6(确认可用)
3.3 算法调试
博主在自己电脑进行算法实践和调试的过程中,还是碰上了一些经典问题的,在此也给出给小伙伴们参考,大家在实践的过程中如果同样碰上了,则可参考解决。
keras版本yolov3提示str object has no attribute decode
解决办法:卸载原来的h5py模块,安装2.10版本
pip install h5py==2.10 -i https://pypi.tuna.tsinghua.edu.cn/simple/
YOLOv3出现OSError: Couldn‘t open webcam or video
解决办法: 只需要在yolo_video的Edit Configuration里的Parameters加上–image
3.4 识别输出
经过一轮的实践调试,程序调通后,则可以正常运行yolo_video.py,你可以在cmd命令中调用执行,同样也可在Python IDE(集成开发环境)中直接运行执行,由于博主用的是PyCharm,所以程序运行如下:
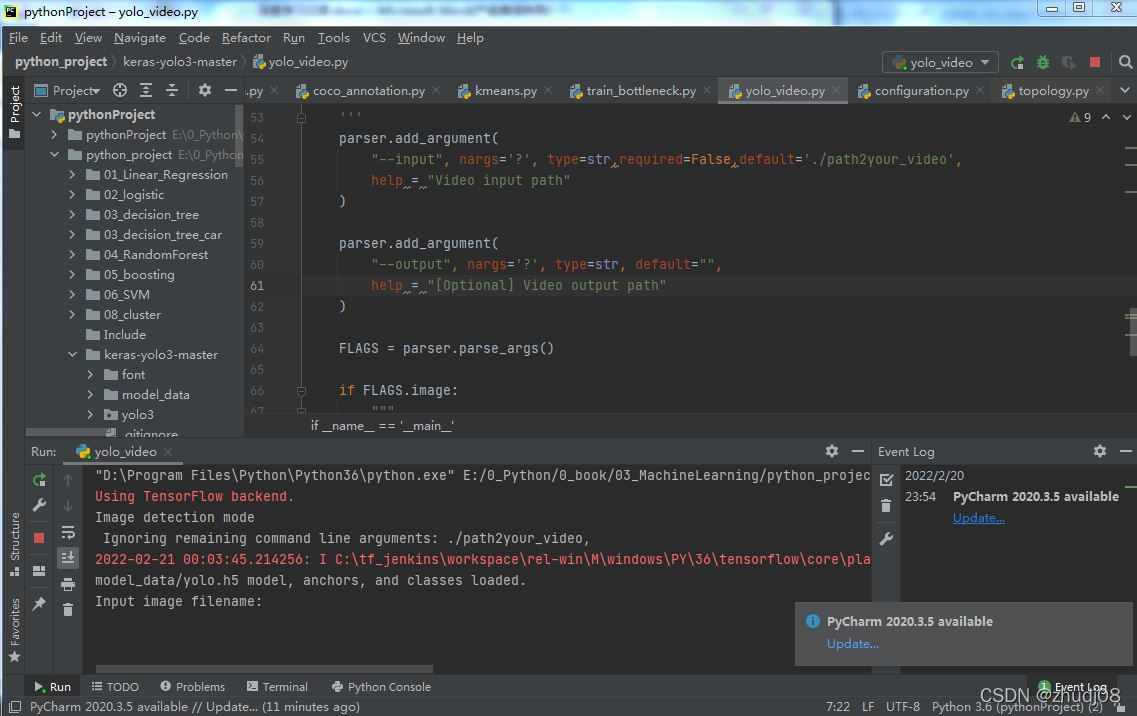
看到提示Input image filename: 之后,就可以输入自己需要识别的图片了,博主直接在一个实际的道路交叉口拍了三张照片,命名分别为street1.jpg,street2.jpg,street3.jpg,依次输入图片名然后进行识别,程序运行结果示例如下:
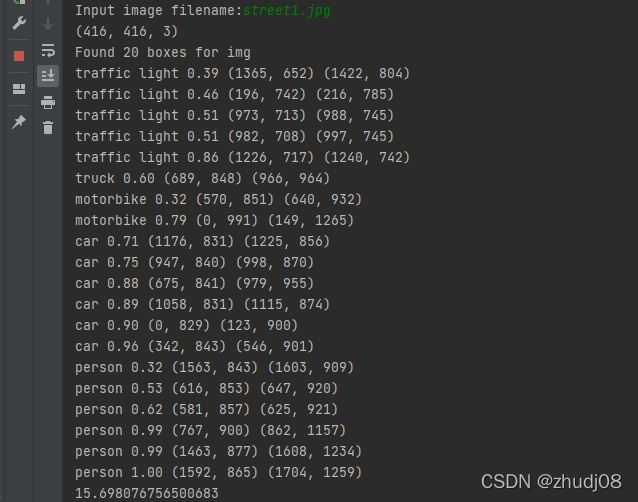
最终三张图片的识别结果如下;

由于自己电脑比较久,就没有自己再找数据来训练,也直接用官方的数据集和训练好的算法做分类,从结果上可以看出:
(1) 检测分类的效果还是可以的,准确率也较高,并且目标离得越近,目标越清晰,检测分类更准确。
(2) 骑摩托的目标,会对摩托检测出一个结果motorbike,对摩托上的人也检测出一个结果person,但我们在实际工程项目中,其实一个目标只给出一个结果类即motorbike即可。
4.参考学习的书目及论文
- 《TensorFlow机器学习项目实战》Rodolfo Bonnin
- 《TensorFlow+keras深度学习人工智能实践应用》林大贵
- 《基于雷达与视觉融合的车辆检测方法研究》贾文博 2021 硕士论文
- 《基于激光雷达和毫米波雷达融合的目标检测方法研究》李朝 2021 硕士论文
- 《基于YOLOv3的密集行人检测算法研究》张政 2021 硕士论文
- 《基于深度学习的车辆检测跟踪及预测算法研究》李磊 2021 硕士论文
=文档信息=
本学习笔记由博主整理编辑,仅供非商用学习交流使用
由于水平有限,错误和纰漏之处在所难免,欢迎大家交流指正
如本文涉及侵权,请随时留言博主,必妥善处置
版权声明:非商用自由转载-保持署名-注明出处
署名(BY) :zhudj
文章出处:https://zhudj.blog.csdn.net/