1lvs 的由来
1公司的钱大部分都花在了获客,营销上,营销效果好就会带来新的流量,如果自身应用承接不住大的流量将会造成很大的经济损失。所以lvs负载均衡技术就此诞生了。当然不差钱也可以使用F5 等硬件
lvs 学名
Linux虚拟服务器
LVS是Linux Virtual Server的简写,意即Linux虚拟服务器,是一个虚拟的服务器集群系统。本项目在1998年5月由章文嵩博士成立,是中国国内最早出现的自由软件项目之一。
想要说明白lvs 需要一定的网络知识,我就先从一个案例说起吧
比如你要访问百度,访问这一个动作 经历了这么一个过程,
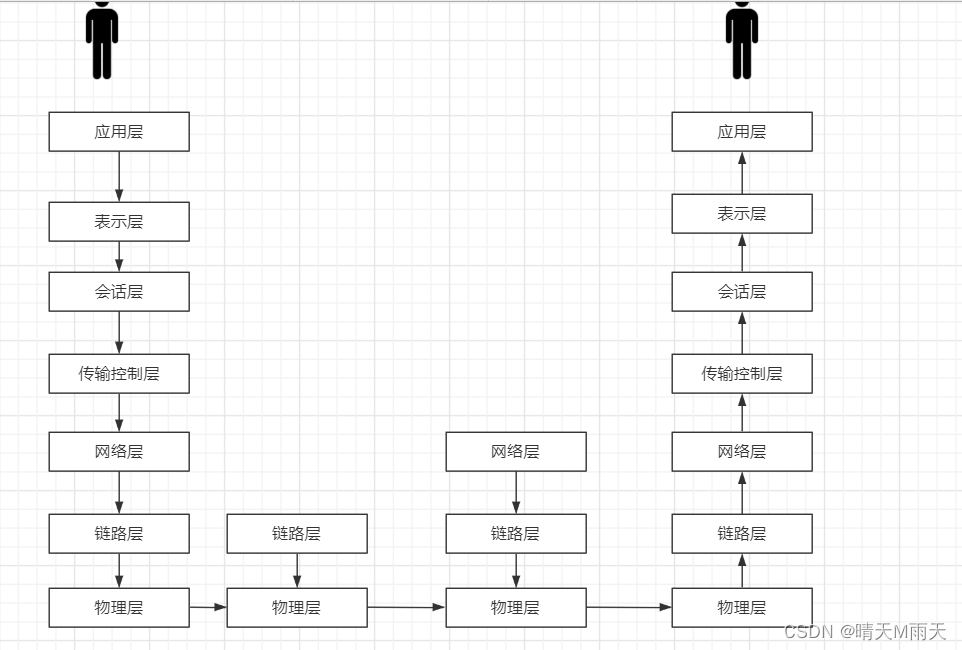
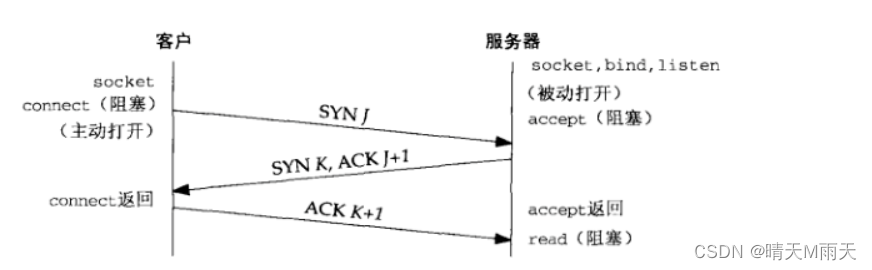
我们都知道通信体系架构中采用分层的架构,这7成表示了一个请求从发送到解析,再由解析到显示的整个过程,我们都知道会话层是我们的session信息,tcp是在传输控制层实现的,而操作系统只有在3次握手之后才会去创建socket 执行请求,这里说一下为啥是3次握手,对于客户端而言,发送了sync请求,并且收到了sync+ack,说明客户端发送和接收都没有问题,对于服务端而言,接收到了 sync 和ack 并且发送了sync+ack,说明自己接收和发送也没有问题,双方都确定通信没有问题,才开始传送数据。可以结合下面的图理解
当数据传输完毕,客户端和服务端就会进行4次挥手断开连接,流程如下
(1)首先客户端想要释放连接,向服务器端发送一段TCP报文,其中:
标记位为FIN,表示“请求释放连接“;
序号为Seq=U;
随后客户端进入FIN-WAIT-1阶段,即半关闭阶段。并且停止在客户端到服务器端方向上发送数据,但是客户端仍然能接收从服务器端传输过来的数据。
注意:这里不发送的是正常连接时传输的数据(非确认报文),而不是一切数据,所以客户端仍然能发送ACK确认报文。
(2)服务器端接收到从客户端发出的TCP报文之后,确认了客户端想要释放连接,随后服务器端结束ESTABLISHED阶段,进入CLOSE-WAIT阶段(半关闭状态)并返回一段TCP报文,其中:
标记位为ACK,表示“接收到客户端发送的释放连接的请求”;
序号为Seq=V;
确认号为Ack=U+1,表示是在收到客户端报文的基础上,将其序号Seq值加1作为本段报文确认号Ack的值;
随后服务器端开始准备释放服务器端到客户端方向上的连接。
客户端收到从服务器端发出的TCP报文之后,确认了服务器收到了客户端发出的释放连接请求,随后客户端结束FIN-WAIT-1阶段,进入FIN-WAIT-2阶段
前"两次挥手"既让服务器端知道了客户端想要释放连接,也让客户端知道了服务器端了解了自己想要释放连接的请求。
于是,可以确认关闭客户端到服务器端方向上的连接了
(3)服务器端自从发出ACK确认报文之后,经过CLOSED-WAIT阶段,做好了释放服务器端到客户端方向上的连接准备,再次向客户端发出一段TCP报文,其中:
标记位为FIN,ACK,表示“已经准备好释放连接了”。注意:这里的ACK并不是确认收到服务器端报文的确认报文。
序号为Seq=W;
确认号为Ack=U+1;表示是在收到客户端报文的基础上,将其序号Seq值加1作为本段报文确认号Ack的值。
随后服务器端结束CLOSE-WAIT阶段,进入LAST-ACK阶段。并且停止在服务器端到客户端的方向上发送数据,但是服务器端仍然能够接收从客户端传输过来的数据。
(4)客户端收到从服务器端发出的TCP报文,确认了服务器端已做好释放连接的准备,结束FIN-WAIT-2阶段,进入TIME-WAIT阶段,并向服务器端发送一段报文,其中:
标记位为ACK,表示“接收到服务器准备好释放连接的信号”。
序号为Seq=U+1;表示是在收到了服务器端报文的基础上,将其确认号Ack值作为本段报文序号的值。
确认号为Ack=W+1;表示是在收到了服务器端报文的基础上,将其序号Seq值作为本段报文确认号的值。
随后客户端开始在TIME-WAIT阶段等待2MSL
为什么要客户端要等待2MSL呢?见后文。
服务器端收到从客户端发出的TCP报文之后结束LAST-ACK阶段,进入CLOSED阶段。由此正式确认关闭服务器端到客户端方向上的连接。
客户端等待完2MSL之后,结束TIME-WAIT阶段,进入CLOSED阶段,由此完成“四次挥手”。
后“两次挥手”既让客户端知道了服务器端准备好释放连接了,也让服务器端知道了客户端了解了自己准备好释放连接了。
于是,可以确认关闭服务器端到客户端方向上的连接了,由此完成“四次挥手”。
与“三次挥手”一样,在客户端与服务器端传输的TCP报文中,双方的确认号Ack和序号Seq的值,都是在彼此Ack和Seq值的基础上进行计算的,这样做保证了TCP报文传输的连贯性,一旦出现某一方发出的TCP报文丢失,便无法继续"挥手",以此确保了"四次挥手"的顺利完成。
为什么“握手”是三次,“挥手”却要四次?
建立连接时,被动方服务器端结束CLOSED阶段进入“握手”阶段并不需要任何准备,可以直接返回SYN和ACK报文,
开始建立连接。
释放连接时,被动方服务器,突然收到主动方客户端释放连接的请求时并不能立即释放连接,
因为还有必要的数据需要处理,所以服务器先返回ACK确认收到报文,经过CLOSE-WAIT阶段准备好释放连接之后,
才能返回FIN释放连接报文。
为什么客户端在TIME-WAIT阶段要等2MSL?
为的是确认服务器端是否收到客户端发出的ACK确认报文
当客户端发出最后的ACK确认报文时,并不能确定服务器端能够收到该段报文。所以客户端在发送完ACK确认报文之后,会设置一个时长为2MSL的计时器。MSL指的是Maximum Segment Lifetime:一段TCP报文在传输过程中的最大生命周期。2MSL即是服务器端发出为FIN报文和客户端发出的ACK确认报文所能保持有效的最大时长。
服务器端在1MSL内没有收到客户端发出的ACK确认报文,就会再次向客户端发出FIN报文;
当tcp 连接建立好以后,我们就需要发送数据了,这里和写信一样,需要发件人地址和收件人地址,tcp层封装完数据格式大致如下
源端口号->目标端口号
经过网络层封装以后
会带上 IP地址
此时的报文内容
源端口号->目标端口号
源IP地址->目标IP地址
最后经过链路层带上Mac地址
源端口号->目标端口号
源IP地址->目标IP地址
源MAC地址->目标MAC地址
好了,此时数据包已经好了,可是这个数据包怎么能到达百度服务器呢?
这里需要补充一个知识就是我们的上网流程;
比如我们家里有两个手机都需要上网,都需要访问百度
手机A IP地址192.168.1.8
手机B IP地址192.168.1.6
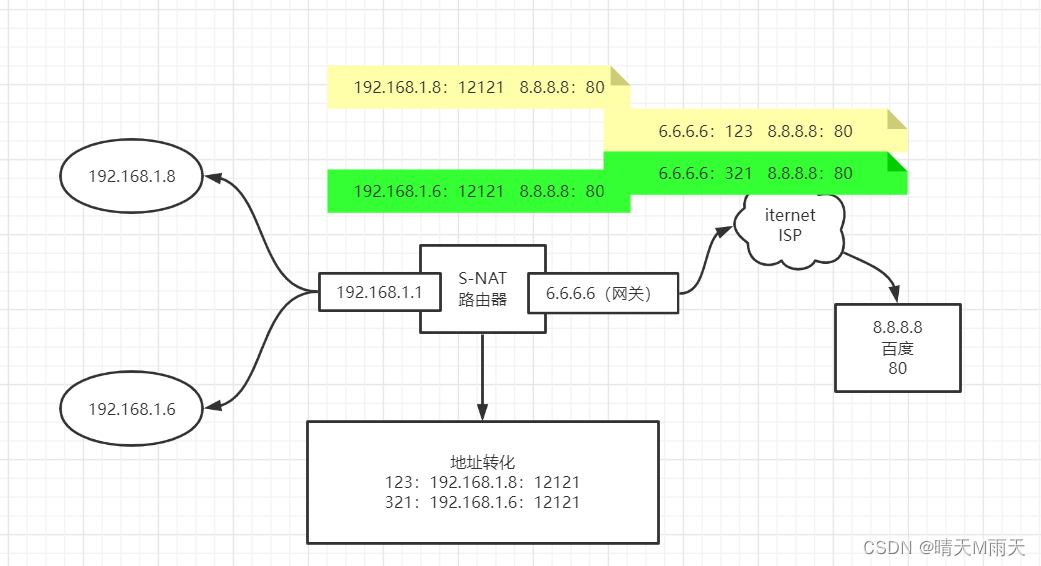
还有一个设备是路由器 ,路由器有一个功能就是网络地址转换
他要把手机A 和B的地址 通过自己的转化功能,转发到网关出口,然后通过下一跳机制,通过城域网 广域网 最终跳到百度服务器所属的网络 并找到对应的IP地址。
看图比较好理解。
好了知道了这个问题,就知道了数据包是怎么到达百度的,但是百度每天要接受很多访问,肯定一台服务器是不行了,假如有3台,但是这个www.baidu.com 到底分给那一台计算机呢,分给那一台都不行,所以就出现了 负载均衡这一个概念,多台服务器对外是一个ip。这时候就需要一台机器专门做流量的承接与分发工作,然后现在的拓扑图简化后就是如下所示。
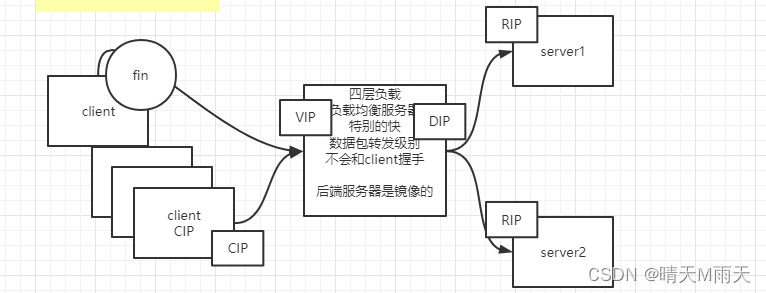
图中的CIP为客户端,vip为数据转发的 DIP是目标ip RIP是真实接受服务的ip。
首先说一下为什么这里不用7层负载,因为7层负载很慢,7层需要3次握手才能建立连接,而且如果之前用的Tomcat服务器,操作系统需要从内核转到工作内存,再转到java的虚拟机,还要开辟资源,cpu还要切换转态,所以比较慢。这里用的4层负载不用握手,就像一个流量的中转站,所以很快。这就是vip的诞生了,知道了为什么慢,才知道如何做能变快。
这里我们总结一下负载均衡的好处
在业务刚起步时,一般先使用单台服务器对外进行提供服务。随着后期的业务增长,流量也越来越大。当这单台服务器的访问量越大时,服务器所承受的压力也就越大,性能也将无法满足业务需求,超出自身所指定的访问压力就会崩掉,避免发生此类事情的发生。
我们将采取其他方案,将多台服务器组成集群系统从而来提高整体服务器的处理性能,使用统一入口(流量调度器)的方式通过均衡的算法进行对外提供服务,将用户大量的请求均衡地分发到后端集群不同的服务器上。因此也就有了负载均衡来分担服务器的压力。
使用负载均衡给我们所带来的好处:提高系统的整体性能、提高系统的扩展性、提高系统的高可用性;
接下来我们会介绍下一个东西,也就是lvs的3中工作模式,这里我们现将流程黑盒化,先来看第一种
DR 模型
再说DR模型之前,还有一个知识点就是netfilter 的基本原理
因为 LVS 是基于 Linux 内核中 netfilter 框架实现的负载均衡系统,netfilter 其实很复杂也很重要,平时说的 Linux 防火墙就是 netfilter,不过我们操作的还是 iptables,iptables 和 netfilter 是 Linux 防火墙组合工具,是一起来完成系统防护工作的。
iptables 是位于用户空间,而 Netfilter 是位于内核空间。iptables 只是用户空间编写和传递规则的工具而已,真正工作的还是 netfilter。
两者间的区别:
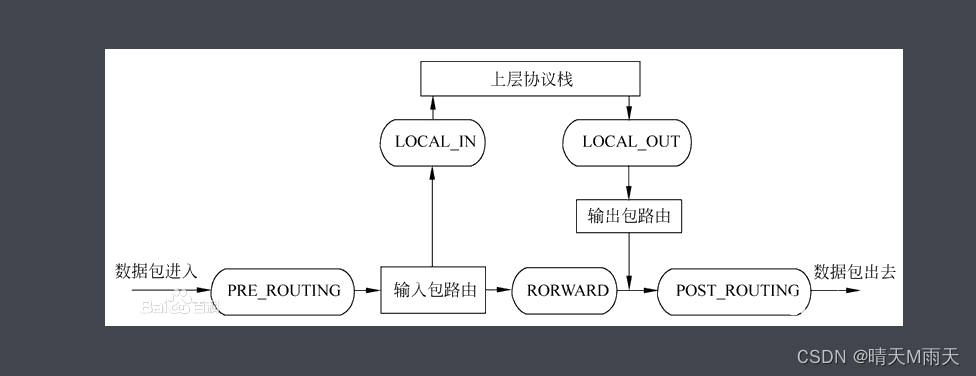
Netfilter 是内核态的 Linux 防火墙机制,它作为一个通用、抽象的框架,提供了一整套的 hook 函数管理机制,提供数据包过滤、网络地址转换、基于协议类型的连接跟踪的功能,可在数据包流经过程中,根据规则设置若干个关卡(hook 函数)来执行相关操作,共设置了 5 个点,包括:PREROUTING、INPUT、FORWARD、OUTPUT、POSTROUTING。
● prerouting: 在对数据包做路由选择之前,将应用此链中的规则;
● input: 当收到访问防火墙本机地址的数据包时,将应用此链中的规则;
● forward: 当收到需要通过防火中转发给其他地址的数据包时,将应用此链中的规则;
● output: 当防火墙本机向外发送数据包时,将应用此链中的规则;
● postrouting: 在对数据包做路由选择之后,将应用此链中的规则;
一个图看一下工作原理
当数据包通过网络接口进入时,经过链路层之后进入网络层到达PREROUTING,然后根据目标 IP 地址进行查找路由。
如目标 IP 是本机,数据包会传到INPUT上,经过协议栈后根据端口将数据送到相应的应用程序;应用程序将请求处理后把响应数据包发送至OUTPUT里,最终通过POSTROUTING后发送出网络接口。
如目标 IP 不是本机,并且服务器开启了FORWARD参数,这时会将数据包递送给 FORWARD,最后通过POSTROUTING后发送出网络接口。
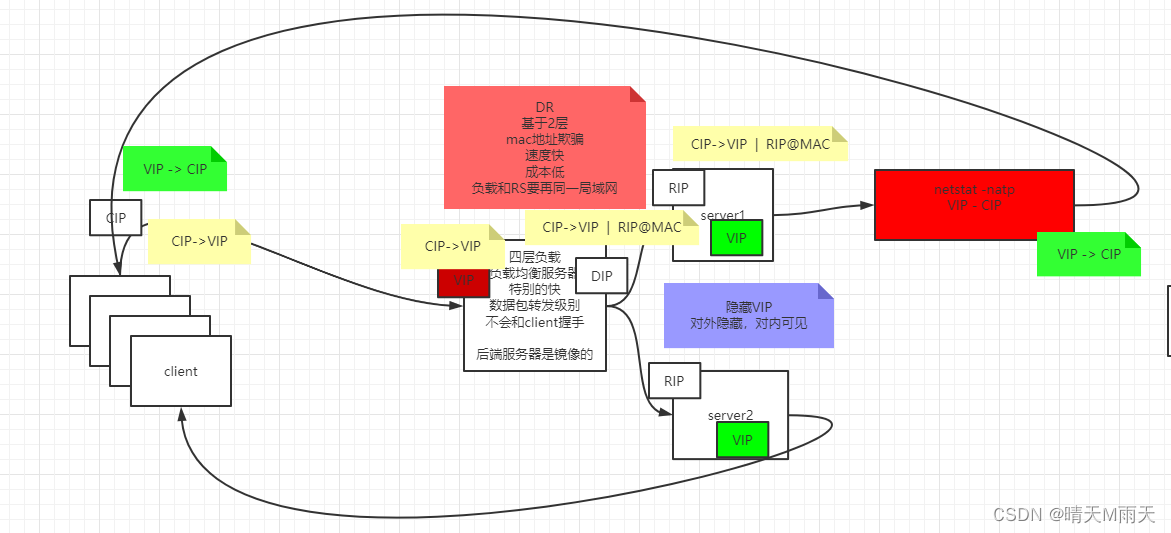
DR 实现原理过程
1、 当客户端用户发送请求给 www.baidu.com 网站时,首先经过 DNS 解析到 IP 后并向百度服务器发送请求,数据包经过网络路由到百度 LVS 负载均衡服务器,这时到达 LVS 网卡时的数据包包括:源 IP 地址(客户端地址CIP)、目的 IP 地址(百度对外服务器 IP 地址,也就是 VIP)、源 MAC 地址(CMAC / LVS 连接路由器的 MAC 地址)、目标 MAC 地址(VMAC / VIP 对应的 MAC 地址)。
2、 数据包到达网卡后,Netfilter 开始工作,经过链路层到达 PREROUTING 链,进行查找路由,发现目的 IP 是 LVS 的 VIP,这时就会发送至 INPUT 链中并且数据包的 IP 地址、MAC 地址、Port 都未经过修改。
3、 数据包到达 INPUT 链中,LVS 会根据目的 IP 和 Port(端口)确认是否为 LVS 定义的服务,如是定义过的 VIP 服务,会根据配置的服务信息(DIP),从 RealServer 中选择一个后端服务器 Server1,然后 Server1 作为目标出方向的路由,确定下一跳信息及数据包通过具体的哪个网卡发出,最好将数据包通过 OUTPUT 链中。
4、 数据包通过 POSTROUTING 链后,目的 MAC 地址将会修改为 Server1服务器 MAC 地址(RMAC)源 MAC 地址修改为 LVS 同网段的 IP 地址的 MAC 地址(DMAC)此时,数据包将会发至 Server1服务器。
5、 数据包到达 Server1服务器后,发现请求报文的 MAC 地址是自己的网卡 MAC 地址,将会接受此报文,待处理完成之后,将响应报文通过 lo 接口传送给 eth0 网卡然后向外发出。此时的源 IP 地址为 VIP,目标 IP 为 CIP,源 MAC 地址为 Server1的 RMAC,目的 MAC 地址为下一跳路由器的 MAC 地址(CMAC),最终数据包通过 Server1相连的路由器转发给客户端。
这里有个重点就是回来的数据包是不经过vip服务器的,这里vip就只对内可见,需要对外隐藏。
这个实现需要用到RIP 的网络知识 稍后说
DR 模式的优缺点:
优点:
● 响应数据不经过 LVS,性能高;
● 对数据包修改小,信息完整性好;
缺点:
● LVS 与 RS 必须在同一个物理网络;
● RS 上必须配置 lo 和其他内核参数;
● 不支持端口映射;
DS 模式的使用场景:
● 对性能要求高的,可首选 DR 模式,还可透传客户端源 IP 地址。
NAT 实现原理过程
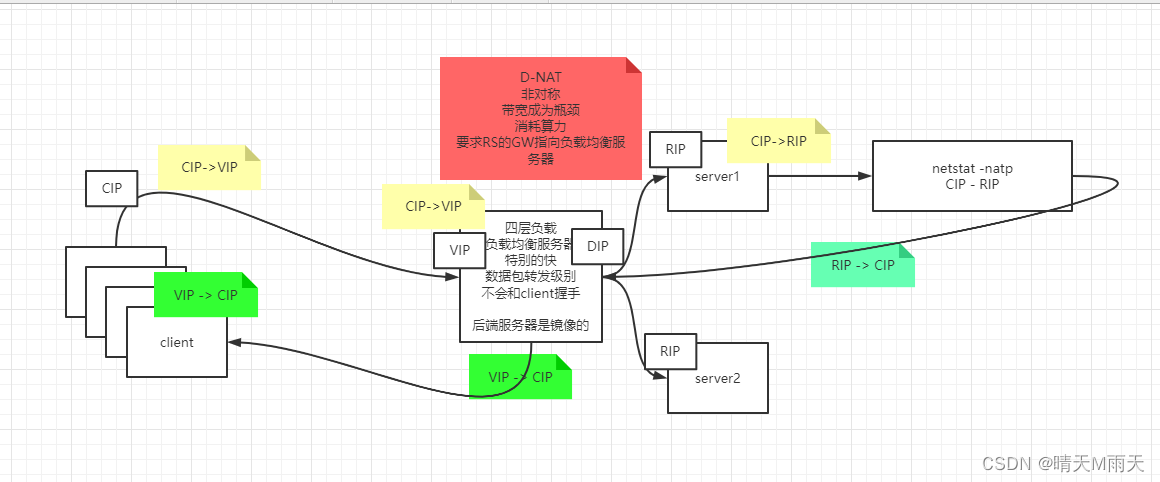
1、 客户端发出的请求数据包经过网络到达 LVS 网卡,数据包源 IP 为 CIP,目的 IP 为 VIP。
2、然后进入 PREROUTING 链中,根据目的 IP 查找路由,确定是否为本机 IP 地址,随后将数据包转发至 INPUT 链中,源 IP 和 目的 IP 不变。
3、 到达 LVS 后,通过目的 IP 和目的 PORT 查找是否为 IPVS 服务,如是 IPVS 服务,将会选择一个 RS 来作为后端服务器,数据包的目的 IP 地址将会修改为 RIP,这时并以 RIP 为目的 IP 去查找路由,确定下一跳及 PORT 信息后,数据包将会转发至 OUTPUT 链中。
4、 被修改过的数据包经过 POSTROUTING 链后,到达 RS 服务器,数据包源 IP 为 CIP,目的 IP 为 RIP。
5、 RS 服务器经过处理后,将会把数据包发送至用户空间的应用程序,待处理完成后,发送响应数据包,RS 服务器的默认网关为 LVS 的 IP,应用程序将会把数据包转发至下一跳 LVS 服务器,数据包源 IP 为 RIP,目的 IP 为 CIP。
6、 LVS 服务器收到 RS 服务器响应的数据包后,查找路由,目的 IP 不是本机 IP并且 LVS 服务器开启了 FORWARD 模式,会将数据包转发给它,数据包不变。
7、 LVS 服务器收到响应数据包后,根据目的 IP 和 目的 PORT 查找相应的服务,这时,源 IP 为 VIP,通过查找路由,确定下一跳信息并将数据包发送至网关,最终回应给客户端用户。
NAT 模式的优缺点:
优点:
● 支持 Windows 操作系统;
● 支持端口映射,如 RS 服务器 PORT 与 VPORT 不一致的话,LVS 会修改目的 IP 地址和 DPORT 以支持端口映射;
缺点:
● RS 服务器需配置网关;
● 双向流量对 LVS 会产生较大的负载压力;带宽会成为瓶颈。
NAT 模式的使用场景:
● 对 windows 操作系统的用户比较友好,使用 LVS ,必须选择 NAT 模式。
TUN 实现原理过程
1、 客户端发送数据包经过网络后到 LVS 网卡,数据包源 IP 为 CIP,目的 IP 为 VIP。
2、 进入 PREROUTING 链后,会根据目的 IP 去查找路由,确定是否为本机 IP,数据包将转发至 INPUT 链中,到 LVS,源 IP 和 目的 IP 不变。
3、 到 LVS 后,通过目的 IP 和目的 PORT 查找是否为 IPVS 服务,如是 IPVS 服务,将会选择一个 RS 后端服务器, 源 IP 为 DIP,目标 IP 为 RIP,数据包将会转发至 OUTPUT 链中。
4、 数据包根据路由信息到达 LVS 网卡,发送至路由器网关,最终到达后端服务器。
5、 后端服务器收到数据包后,会拆掉最外层的 IP 地址后,会发现还有一层 IP 首部,源 IP 为 CIP,目的 IP 为 VIP,TUNL0 上配置 VIP,查找路由后判断为本机 IP 地址,将会发给用户空间层的应用程序响应后 VIP 为源 IP,CIP 为目的 IP 数据包发送至网卡,最终返回至客户端用户。
TUN 模式的优缺点:
优点:
● 单臂模式,LVS 负载压力小;
● 数据包修改小,信息完整性高;
● 可跨机房;
缺点:
● 不支持端口映射;
● 需在 RS 后端服务器安装模块及配置 VIP;
● 隧道头部 IP 地址固定,RS 后端服务器网卡可能会不均匀;
● 隧道头部的加入可能会导致分片,最终会影响服务器性能;
TUN 模式的使用场景:
● 如对转发性要求较高且具有跨机房需求的,可选择 TUN 模式。
lvs DR 模型实战
LVS:
node01:
ifconfig eth0:8 192.168.150.100/24
node02~node03:
1)修改内核:对外隐藏 对内可见
echo 1 > /proc/sys/net/ipv4/conf/eth0/arp_ignore
echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
echo 2 > /proc/sys/net/ipv4/conf/eth0/arp_announce
echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
2)设置隐藏的vip:
ifconfig lo:3 192.168.150.100 netmask 255.255.255.255
RS中的服务:
node02~node03:
yum install httpd -y
service httpd start
vi /var/www/html/index.html
from 192.168.150.1x
LVS服务配置
node01:
yum install ipvsadm
ipvsadm -A -t 192.168.150.100:80 -s rr
ipvsadm -a -t 192.168.150.100:80 -r 192.168.150.12 -g -w 1
ipvsadm -a -t 192.168.150.100:80 -r 192.168.150.13 -g -w 1
ipvsadm -ln
验证:
浏览器访问 192.168.150.100 看到负载 疯狂F5
node01:
netstat -natp 结论看不到socket连接
node02~node03:
netstat -natp 结论看到很多的socket连接
node01:
ipvsadm -lnc 查看偷窥记录本
TCP 00:57 FIN_WAIT 192.168.150.1:51587 192.168.150.100:80 192.168.150.12:80
FIN_WAIT: 连接过,偷窥了所有的包
SYN_RECV: 基本上lvs都记录了,证明lvs没事,一定是后边网络层出问题