如果执行引擎是MapReduce 的话, hive 会将 Hql 翻译成MR进行数据的计算。
使用Hive的原因
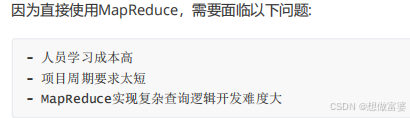
Hive的优缺点

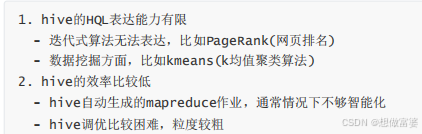
Hive的使用方式
使用第三方工具连接Hive
通过Web UI 访问Hive , 比如Hue
User Interface(用户界面)

DBeaver
(hive的有些功能不能用)
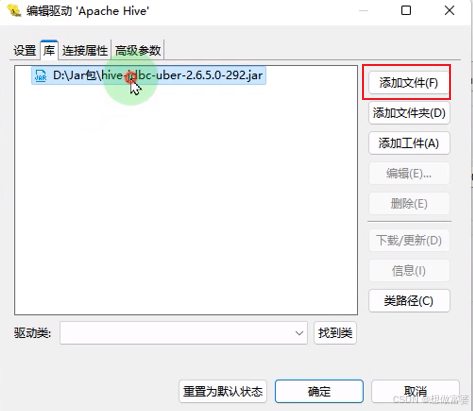
连接数据库>>Hive>>填写JDBC链接设置>>>编辑驱动设置>>库>>添加文件>>选择驱动包>>测试连接
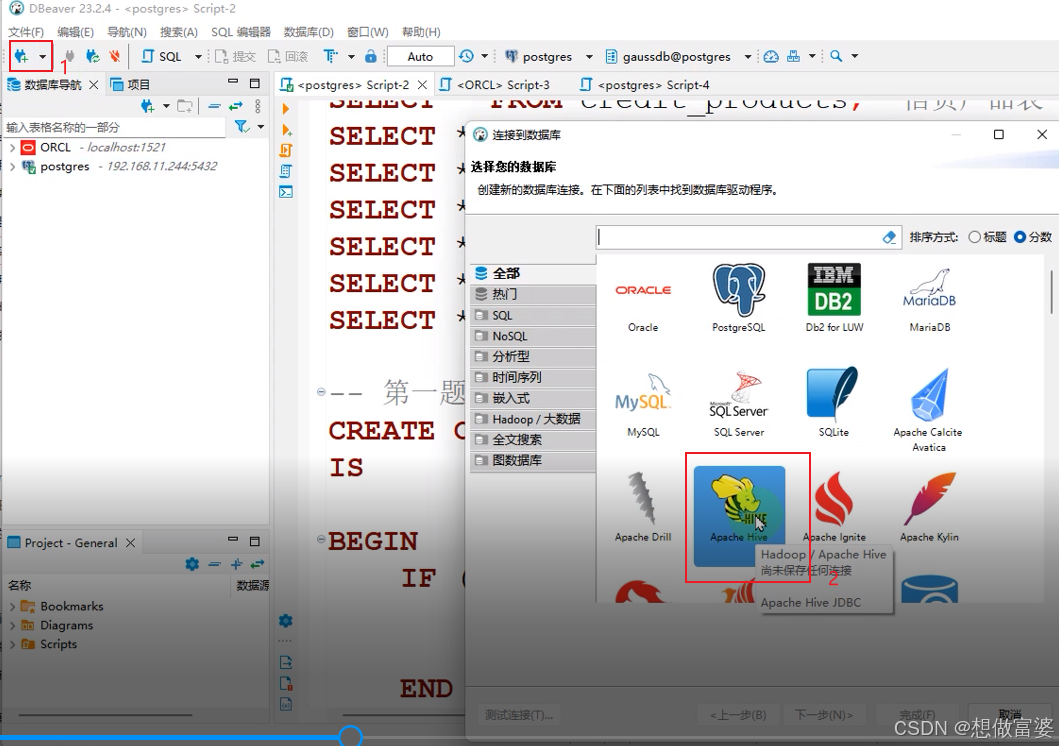
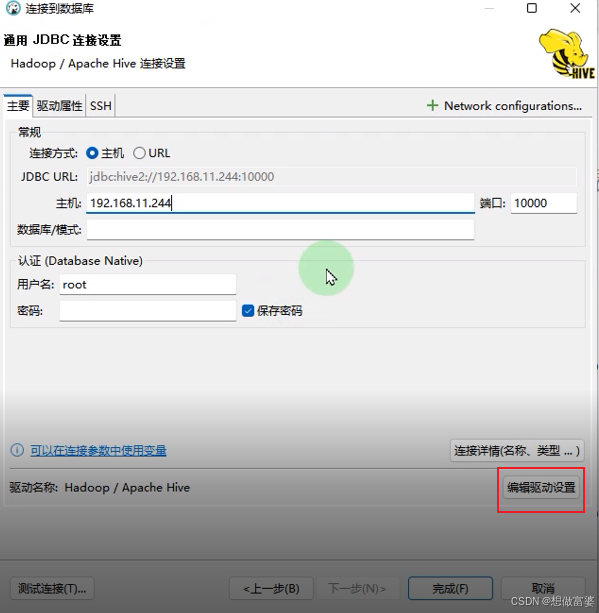
进入库之后,空间2个红色的文件包,全选删掉后,添加想要使用的驱动包
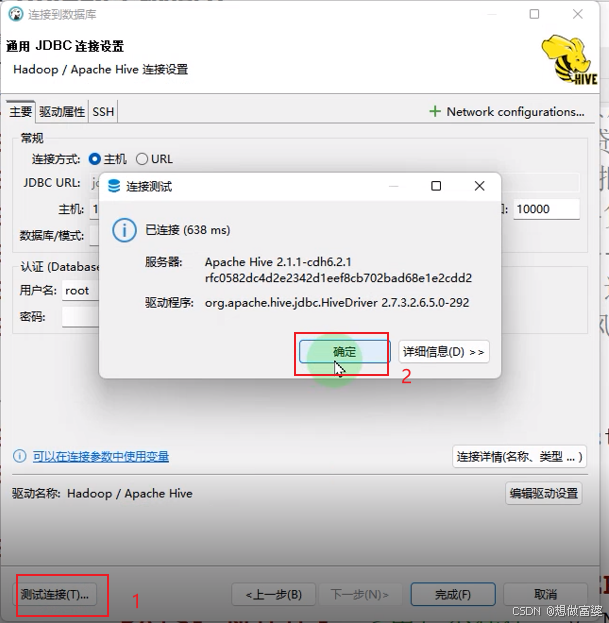
连接完成左侧会出现Hive的图标
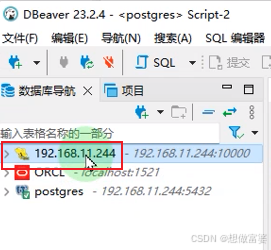
DataGrip
(功能强大,能自动补全命令,但是收费)
下载
官网首页
DataGrip 类似DBeaver,可以连很多种数据库,但是连不了高斯
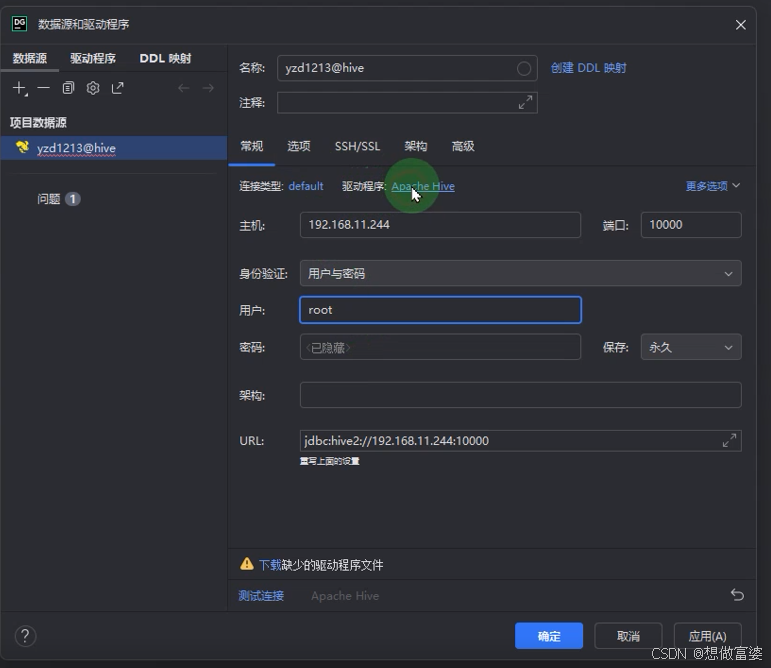
DataGrip 连接Hive
方法一: 文件>>新建>>数据源>>Hive
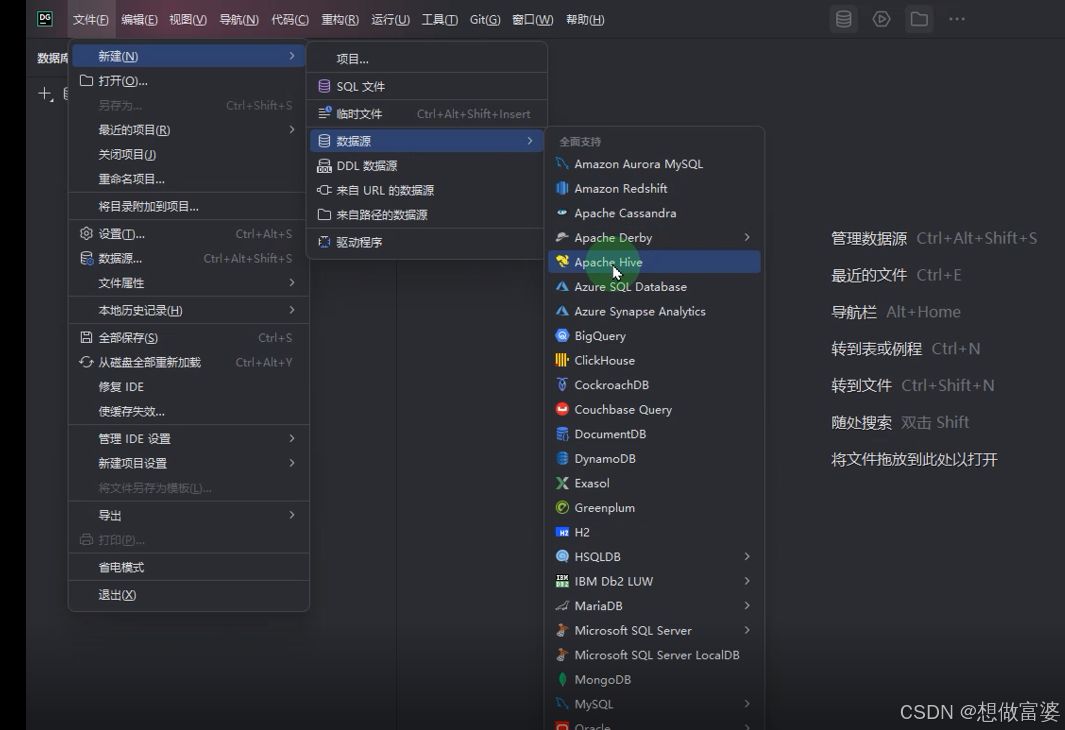
方法二: 数据库>>数据源>>Hive
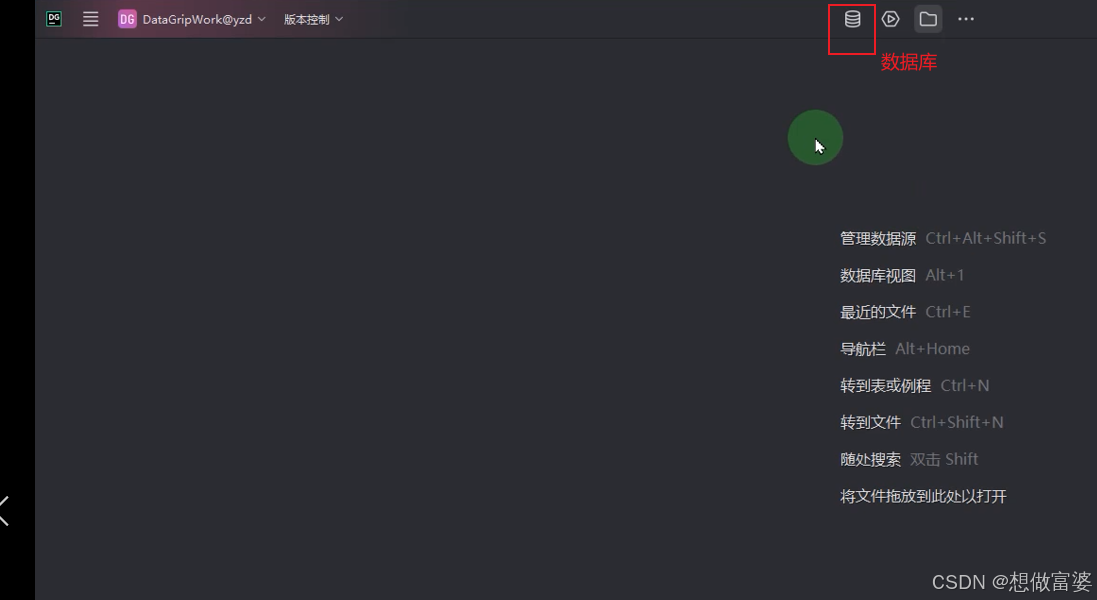
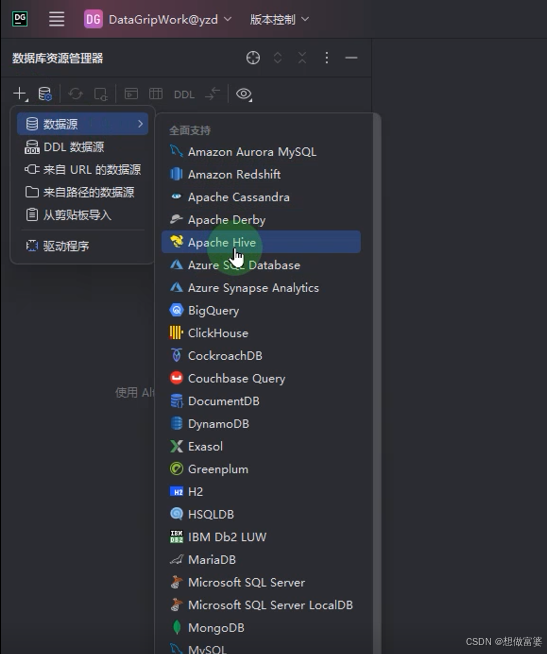
名称: 自定义
主机: IP地址
密码不需要
如果点击下方的下载,下载的是Hadoop官网最新的驱动, 点击驱动程序的Apache Hive
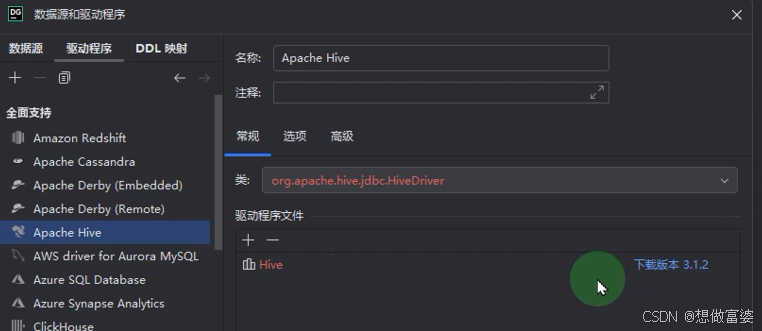
如果版本不对,点击 - 号删掉,再点击+号>>自定义>>选择你已经准备好的驱动器版本
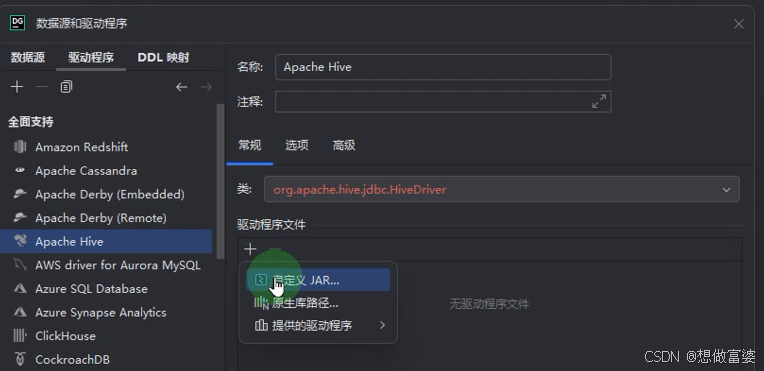
后退一步,点击测试>>测试成功>>应用
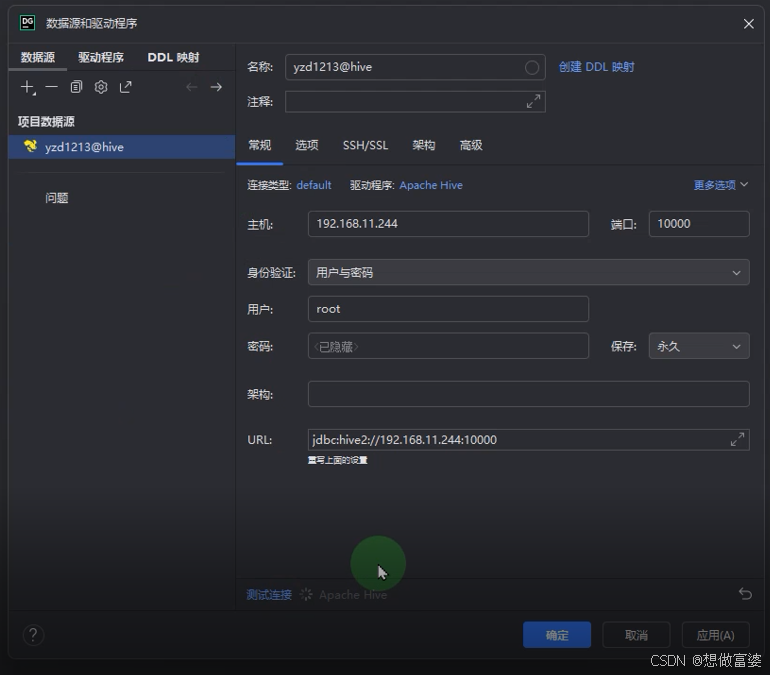
连接成功后左侧会出现Hive
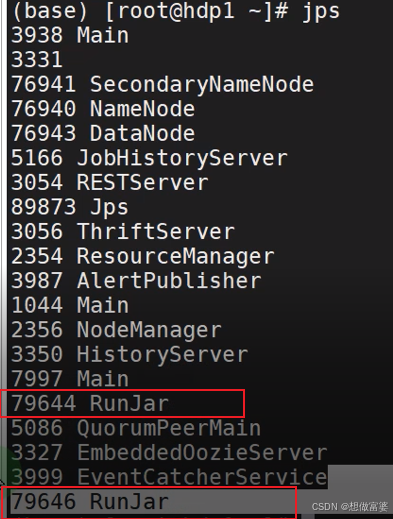
如何判断Hive是否启动 jps
命令行输入jps ,出现2个RunJar即表明Hive已经启动(一个是元数据服务,一个远程访问服务)
Hive有自己的Metastore服务(用于存储元数据)和HiveServer2(用于处理客户端请求)。如果这两个服务都是通过 java -jar 命令启动的,都显示为 RunJar
如果只启动Metastore服务,那么只有一个RunJar,那么只能在命令行访问Hive
端口号
Hive和mysql一样,一个用户可以拥有多个库(oracle是一个库里面有多个用户),
Hive的默认端口号是10000,
oracle的默认端口号 1521
mysql的默认端口号 3306
高斯200的默认端口号 5433
Hive元数据的存储
即Metastore,Hive 有三种配置模式:内嵌模式、本地模式和远程模式
内嵌模式: 元数据存储在内置的Derby数据库中,单用户模式,只适合测试环境
本地模式和远程模式: 元数据存储在MYSQl

Hive和Hadoop的关系


Hive和关系型数据库的比较
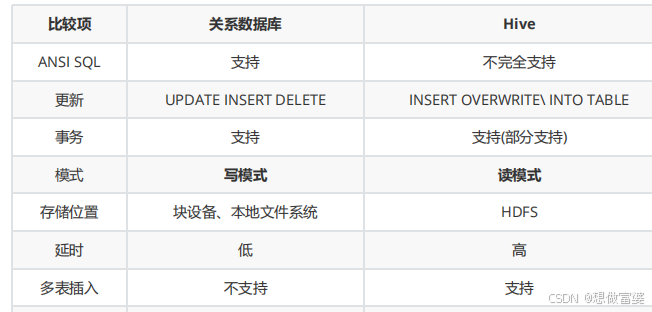
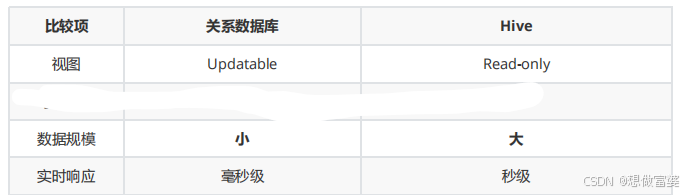

hive对于数据只支持追加和覆盖