文章目录
1 介绍
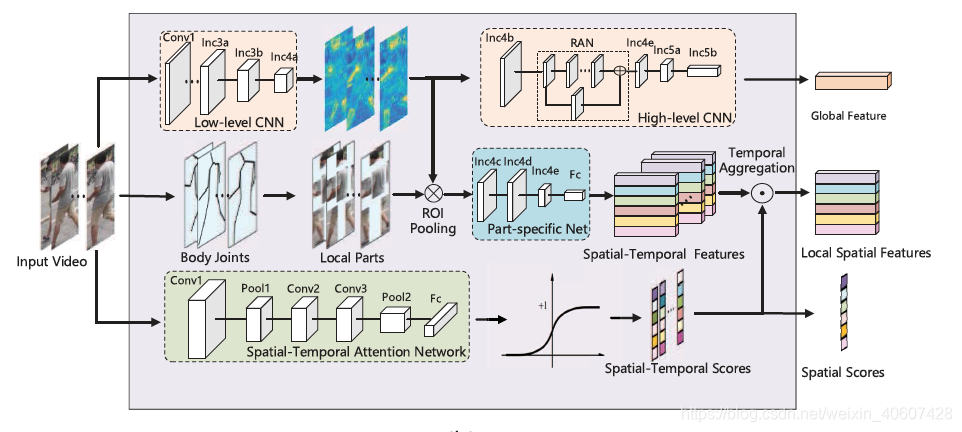
本文提出了一种时空注意力模型,来解决基于视频的行人重识别问题中一段视频个别帧遮挡情况严重从而干扰整段序列的行人表达的问题。整个模型主要包含三个部分:
- global representation branch: CNN网络提取行人的全局特征
- local representation branch: 根据姿势估计算法,提取行人不同身体部分的局部特征
- spatial-temporal attention branch: 为每帧图像不同身体部位生成scores与局部特征进行加权作为最终表示
2 方法
2.1 整体结构
给定一段视频序列
X
=
X=
X={
x
t
x^t
xt}
t
=
1
:
T
_{t=1:T}
t=1:T,
T
T
T表示帧数,
x
t
x^t
xt是第t帧。
如图所示,
-
全局特征的提取: 先将图像输入到一个低层CNN网络得到低层特征表示,接着通过一个RAN网络得到高层全局特征 g t = G ( x t ) g^t=G(x^t) gt=G(xt)。再通过temporal pooling layer得到整段图像序列的特征表示,两个不同行人之间的全局特征距离为:
-
局部特征的提取: 先用一个姿势估计算法确定行人的14个关节点,然后根据关节点将行人分成6个部分(该算法先在MPII行人姿势数据集上预训练)。采用ROI池化层将低层特征按照划分好的行人的身体部分表示,通过一个part-specific网络后得到最终的局部特征表示:
-
注意力模型: 根据输入的图像序列生成score map a r , t = A ( X ) a^{r,t}=A(X) ar,t=A(X),其中时间注意力关注具有丰富的显著性信息的关键帧,空间注意力关注未被遮挡的身体部分。最后定义一个aggregation function用来计算两个不同行人的video clips之间的距离:
整个网络通过三种损失来约束:
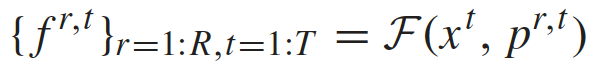
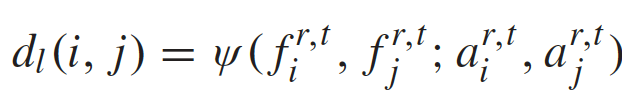
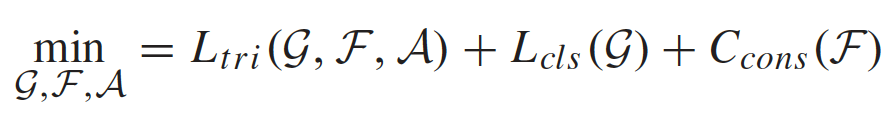
1. Triplet Loss 三元组损失
2. Softmax Loss
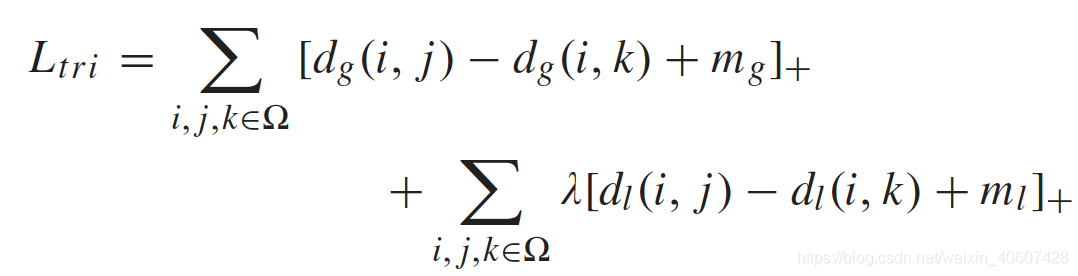
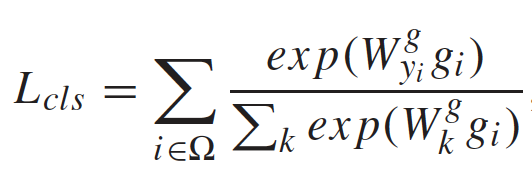
y i y_i yi是第i个行人的标签, W y i g W_{y_i}^g Wyig和 W k g W_k^g Wkg是softmax矩阵的第 y i y_i yi和第 k k k列。
3. Consistency Constraint 一致性约束
用于保证局部特征和全局特征的一致性,即单个局部特征具有和全局特征相同的标签。
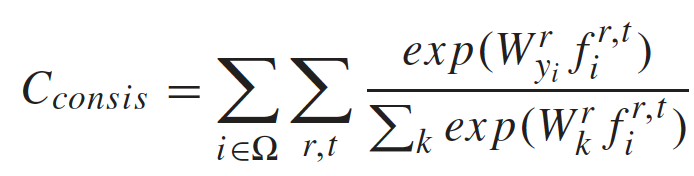
不同帧中相同的身体部分享有一样的softmax矩阵。
(这里第二、三个损失似乎都少了负号?)
2.2 全局特征提取网络
特征提取过程采用GoogleNet作为backbone,并且从Inception 4b层将其分成low-level和high-level两段,以Inc 4a的输出作为low-level特征,同时用于局部特征的整合过程和全局high-level特征的提取。(这是因为Inc 4c层能够保证语义信息和分辨率达到较好的平衡)
全局特征提取的high-level提取过程中,在Inc 4b和Inc 4e之间插入一个residual attention structure,如下图所示:
即将Inc 4b的输出同时输给attend block和原本GoogleNet在Inc 4b和Inc 4e之间的CNN block,然后把两个block的输出相乘,再把结果输给Inc 4e继续完成整个GoogleNet网络从而得到最终的全局特征。
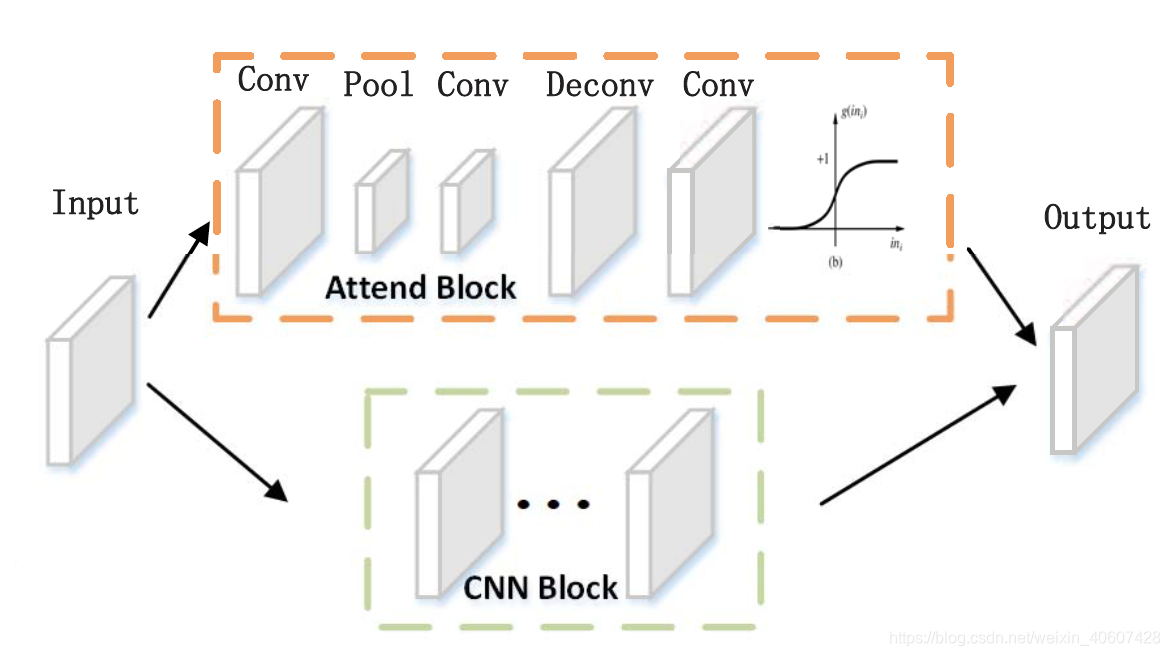
Residual Attention Network(RAN) 1的作用:highlight the human body。
RAN包括三个部分:
- downpooling module
2个卷积层和一个最大池化层,用于提取输入的feature map的显著性信息(mask) - uppooling module
一个反卷积层和一个卷积层,将得到的mask还原成初始输入的分辨率大小 - sigmoid layer
将attention mask缩放到[0,1]区间内
2.3 局部特征提取
首先在MPII数据集上预训练一个行人姿势估计网络,将训练好的网络在reID数据集上refine,用于定位行人的14个关节点位置 J i ∈ R X × Y i = 1 : 14 J_i \in {R^{X\times Y}}_{i=1:14} Ji∈RX×Yi=1:14。
然后按照关节点将行人分成头、躯干、右臂、左臂、右腿和左腿六个身体部分,每个部分的边框是能够包含全部相应关节点的最小矩形框:
将得到的每个部分的矩形框坐标
p
r
p^r
pr和前面提取的low-level特征(
14
×
14
14\times14
14×14)进行ROI池化,为每个身体部分提取一个middle representations(
8
×
8
8\times8
8×8)。
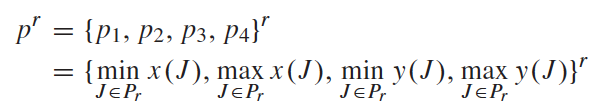
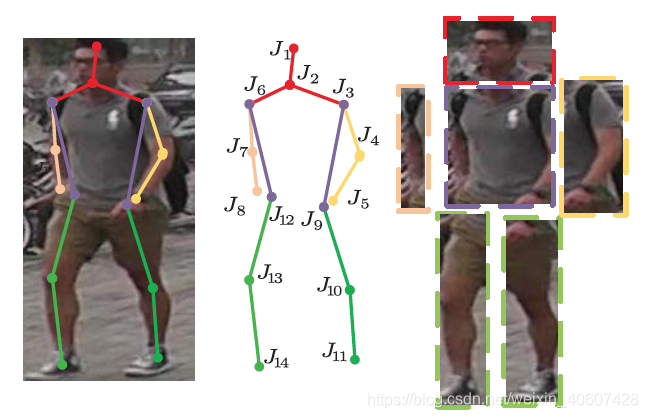
按照每个矩形框的坐标得到六个感兴趣的区域,再将每个感兴趣的区域划分成 8 × 8 8\times8 8×8个部分,取每个部分的最大值,最终每个区域都得到一个 8 × 8 8\times8 8×8的特征。
接着这个中间特征表示将通过一个part-specific CNN网络,从而生成最终的局部特征。每个身体部位的网络是相互独立的,只是采用相同的结构。
2.4 时空注意力模型
这一分支包括一个 7 × 7 7\times7 7×7的卷积层,两个 3 × 3 3\times3 3×3的卷积层,一个 7 × 7 7\times7 7×7的最大池化层,一个全连接层和一个激活层,输出一个 T × R T\times R T×R的attention scores。
为了避免scale offset带来的mismatch问题,得到的scores进行一个 L 1 L_1 L1正则化,最终输出一个score map { a r , t a^{r,t} ar,t},对应R个身体部分和T帧图像。
第i个行人的第r个身体部位的特征表示为:
第i个行人和第j个行人的局部特征距离计算如下:
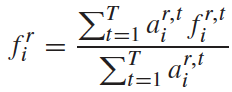
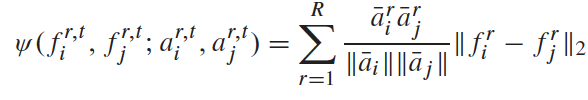
a ˉ i r \bar a^r_i aˉir表示特征 f i r f^r_i fir的attention score在时间维度上的平均值, ∥ a ˉ i ∥ \|\bar a_i\| ∥aˉi∥表示空间维度上的正则项。
a ˉ i r = 1 T ∑ t a i r , t \bar a^r_i=\dfrac{1}{T}\sum_t{a^{r,t}_i} aˉir=T1∑tair,t
∥ a ˉ i ∥ = ∑ r ( a ˉ i r ) 2 \|\bar a_i\|=\sqrt{\sum_r(\bar a^r_i)^2} ∥aˉi∥=∑r(aˉir)2
3 实验分析
3.1 与其他方法对比
本文在PRID-2011、iLIDS-VID和MARS三个数据集上进行测试。
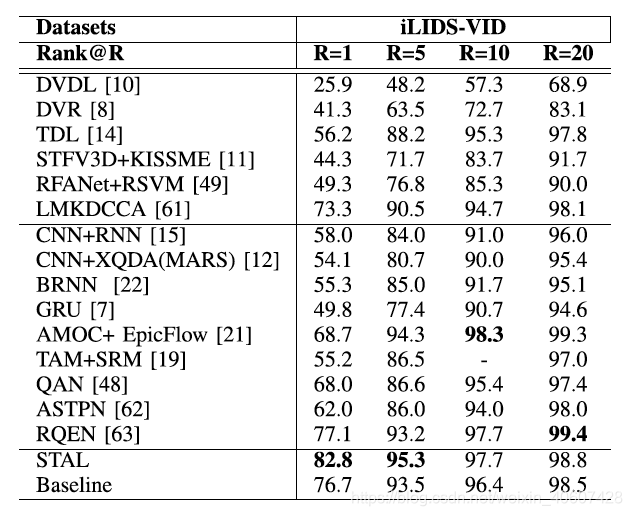
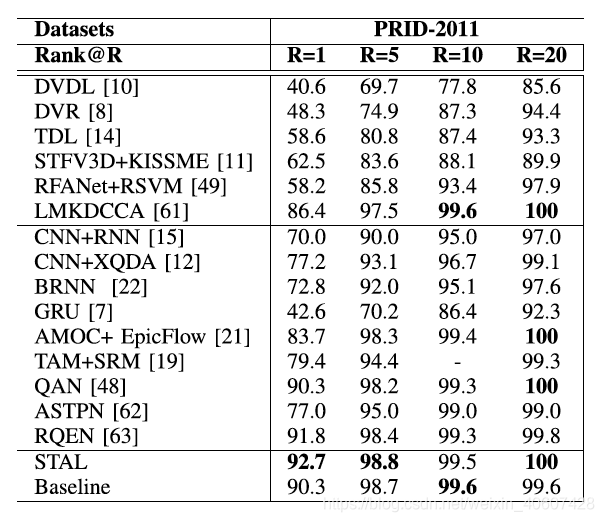
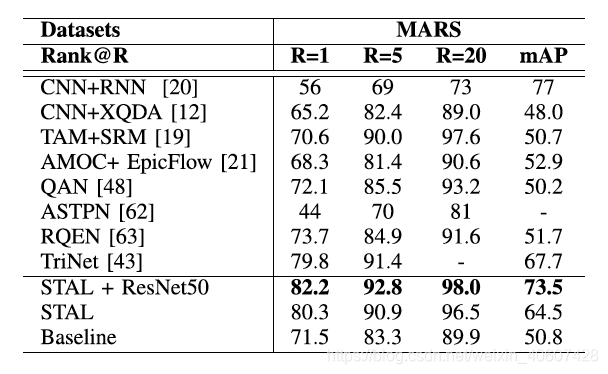
3.2 消融实验
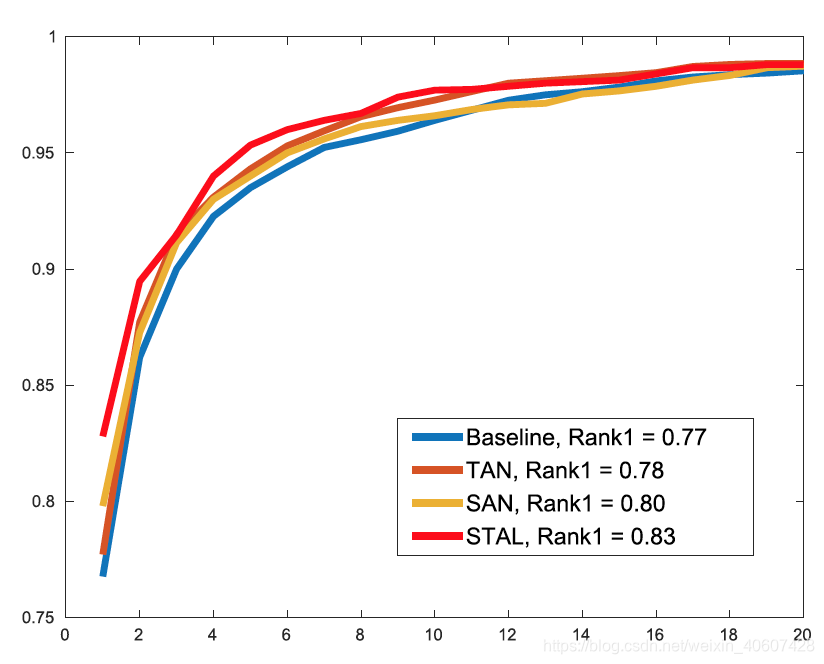
- 各个attention model的作用
比较baseline、TAN(加入时间注意力)、SAN(加入空间注意力)、STAL(时间空间都加入)的结果:
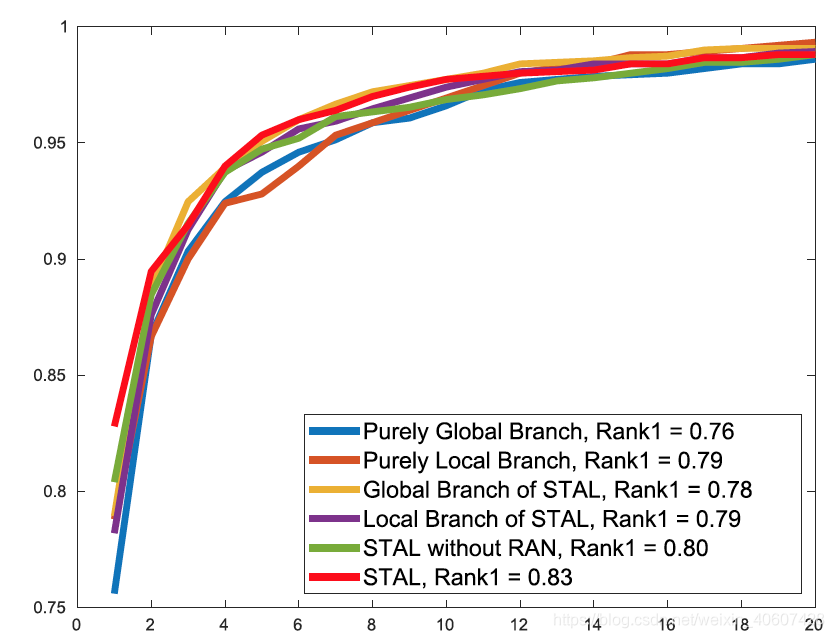
- 各个特征分支的作用
比较六种设定:
- PGB & PLB: 训练和测试都只用global或者local
- GB & LB: 训练时两个都用,测试时只用global或者local
- STAL without RAN: 验证RAN的作用
- STAL
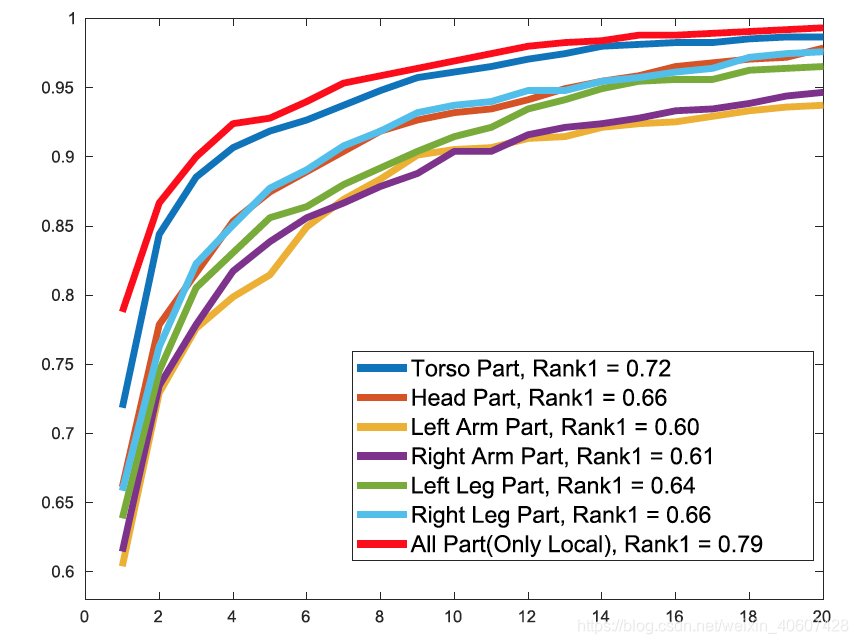
3. 比较各个身体部位的重要性 - 为了避免全局特征分支的干扰,只用局部特征进行测试。
- 提取不同身体部位的特征,然后分别计算各个身体部分的特征距离用来衡量不同行人之间的相似性来进行排序。
3.3 参数分析
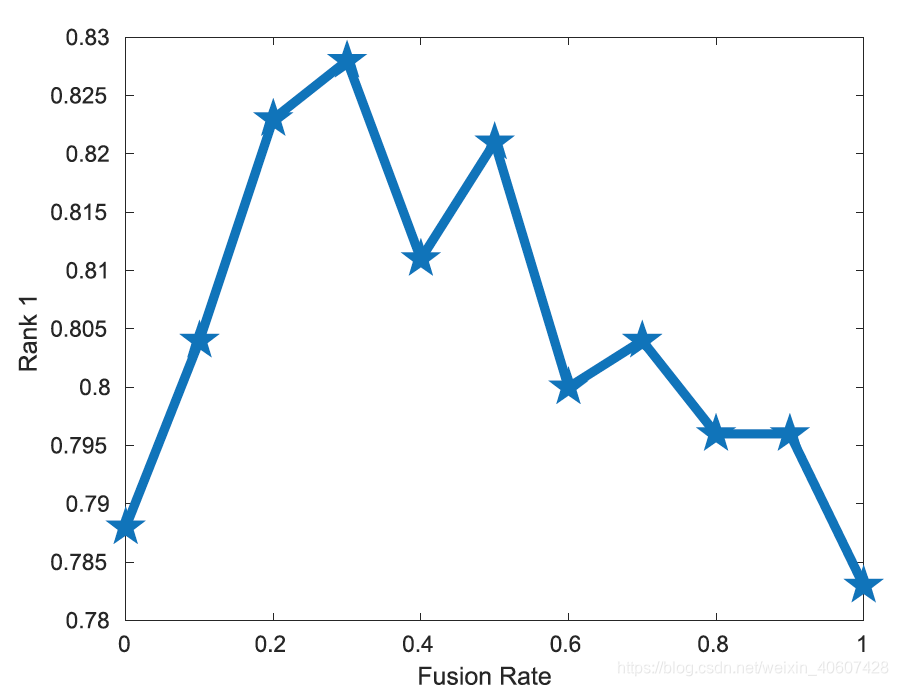
1. fusion rate
前面计算三元组损失时同时计算了全局特征和局部特征的距离,
λ
\lambda
λ的取值对结果的影响如下图:
最后取
λ
=
0.3
\lambda =0.3
λ=0.3。
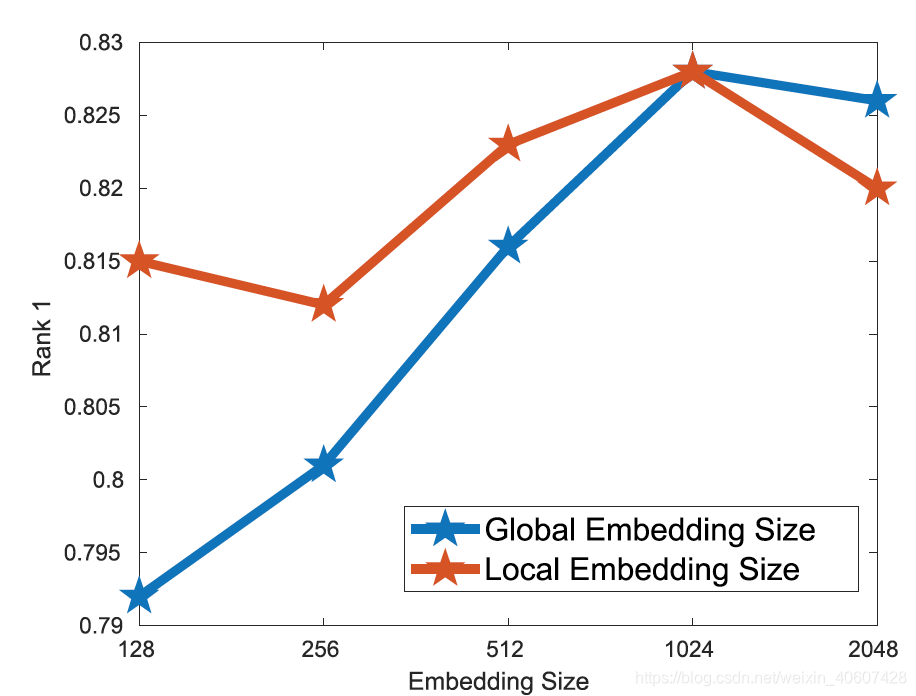
2. Embedding size
设定不同特征维度值{128,256,512,1024,2048}来比较结果,为了方便比较,当我们比较全局特征维度时将局部特征维度固定为1024,比较局部特征维度时将全局特征维度固定为1024。
如下图所示,当两种特征维度都取1024时效果最好。
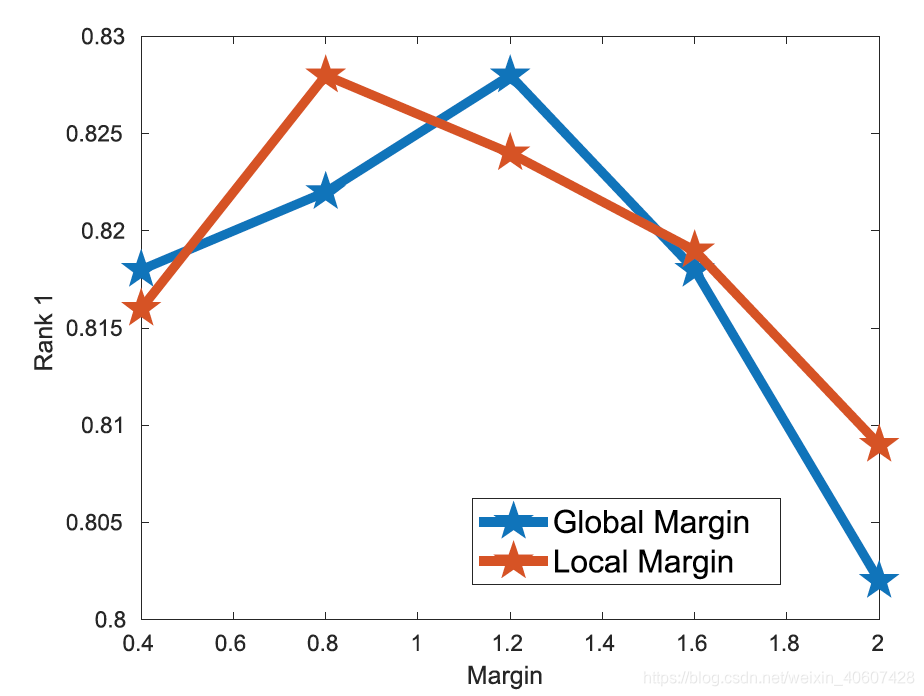
3. Margin
计算triplet loss的时候用到了两个margins,比较margin从0.4变化到2的结果。测试global margin的时候,固定local margin为0.8;测试local margin的时候,固定global margin为1.2。
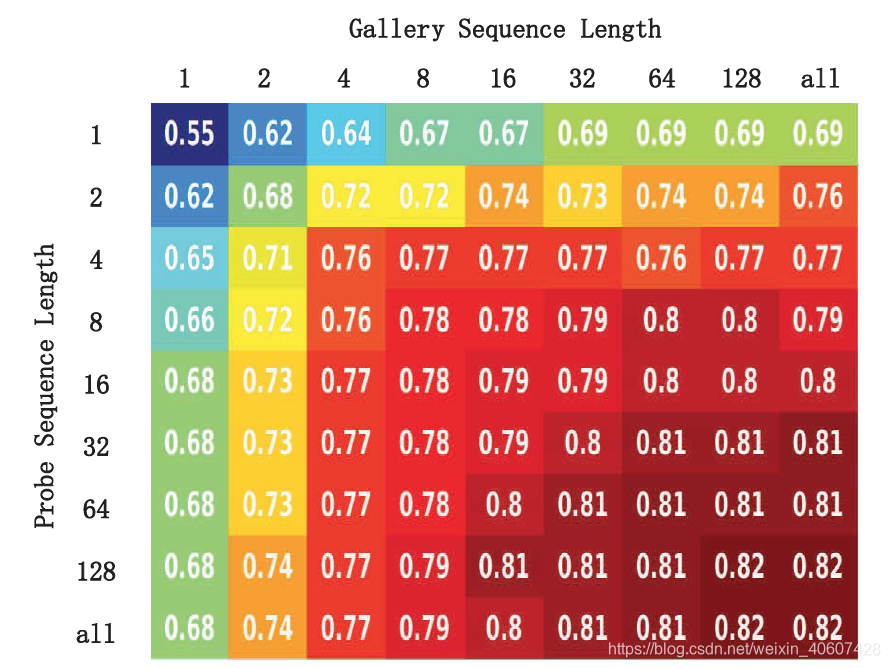
4. Sequence Length
训练的时候保留原始设定,对于每段图像序列随机抽取8帧进行训练。测试时改变选取probe和gallery时的长度,从1-128(以2倍为间隔),并且与将所有帧全用上的结果来对比。
3.4 鲁棒性分析
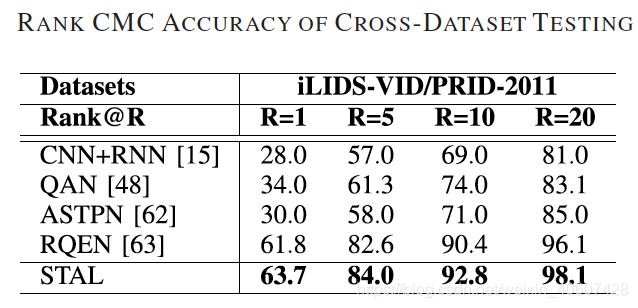
1. 跨数据集测试
在iLIDS-VID上训练,在PRID2011上测试。
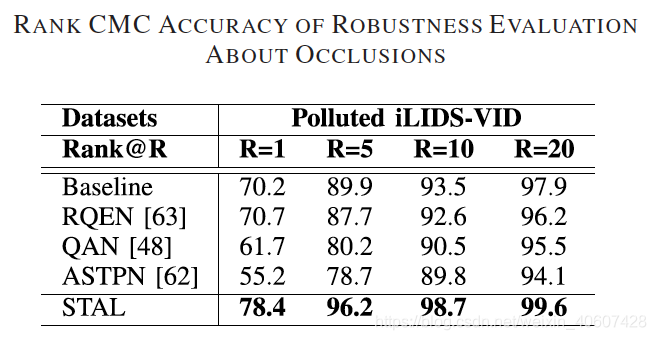
2. 对于遮挡的鲁棒性
自行构造一个“polluted”数据集,用大小
25
×
25
25\times 25
25×25的黑色矩形对数据集中的每帧图像进行遮挡,如下图:
比较不同方法在这样一个数据集上的结果:

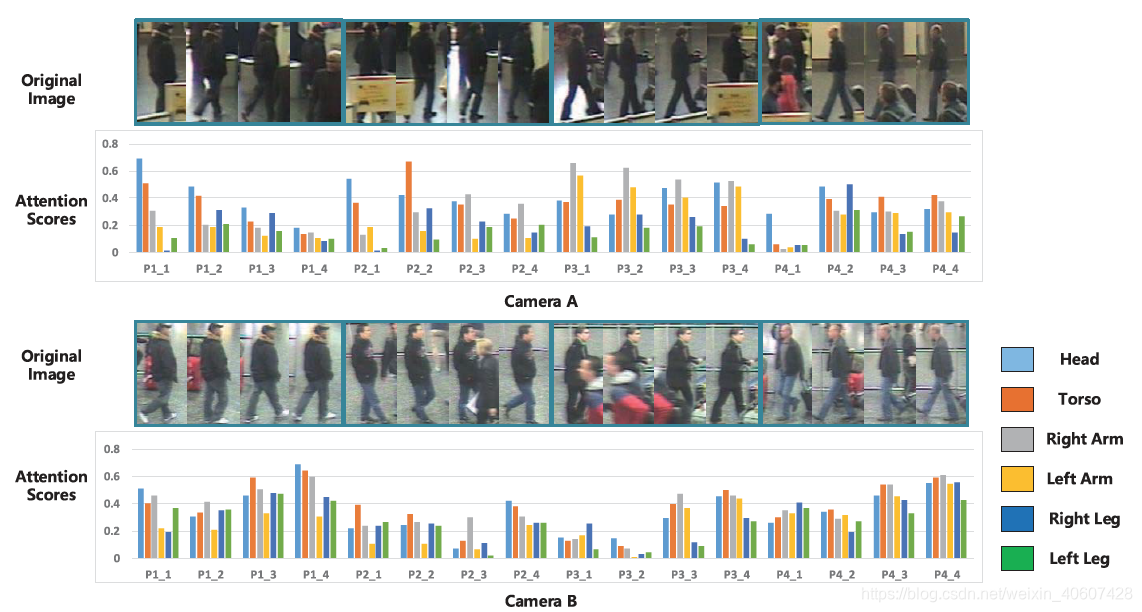
3.5 注意力模型可视化
F. Wang et al., “Residual attention network for image classification,” in Proc. CVPR, Jul. 2017, pp. 3156–3164. ↩︎