大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,所以创建了“AI信息Gap”这个公众号,专注于分享AI全维度知识,包括但不限于AI科普,AI工具测评,AI效率提升,AI行业洞察。关注我,AI之路不迷路,2024我们一起变强。
大语言模型(Large Language Model,简称LLM)是当下生成式AI应用的核心,可以理解为一辆汽车的“引擎”,一个应用程序的“大脑”。LLM模型的通用基础能力是AI工具性能表现的基础。今天是2024年5月25日,我们来聊一聊当前LLM模型的最新排名情况。
全球LLM模型综合排名
本排名的数据来源为LMSYS Chatbot Arena Leaderboard。LMSYS全称为LMSYS Organization,由加州大学伯克利分校、加州大学圣地亚哥分校和卡内基梅隆大学合作创立,是一个专注于LLM模型研究和评估的组织。他们开发了Chatbot Arena,这是一个开放的LLM模型测评平台,旨在通过收集用户反馈来评估和比较不同LLMs的性能。Chatbot Arena的核心功能包括模型对战(Arena Battle),实时聊天(Direct Chat),排行榜(Leaderboard)。

LMSYS采用了类似于国际象棋等竞技游戏中广泛使用的Elo评分系统,通过众包方式进行匿名、随机对抗测评。在Chatbot Arena中,系统会随机选择两个不同的大型语言模型进行比较,用户在与这些模型的互动中进行评估,并在匿名的情况下选择哪款模型的表现更佳。这种评测方式旨在提供一个公正、透明的评估环境,帮助研究者和开发者了解和改进他们的模型。
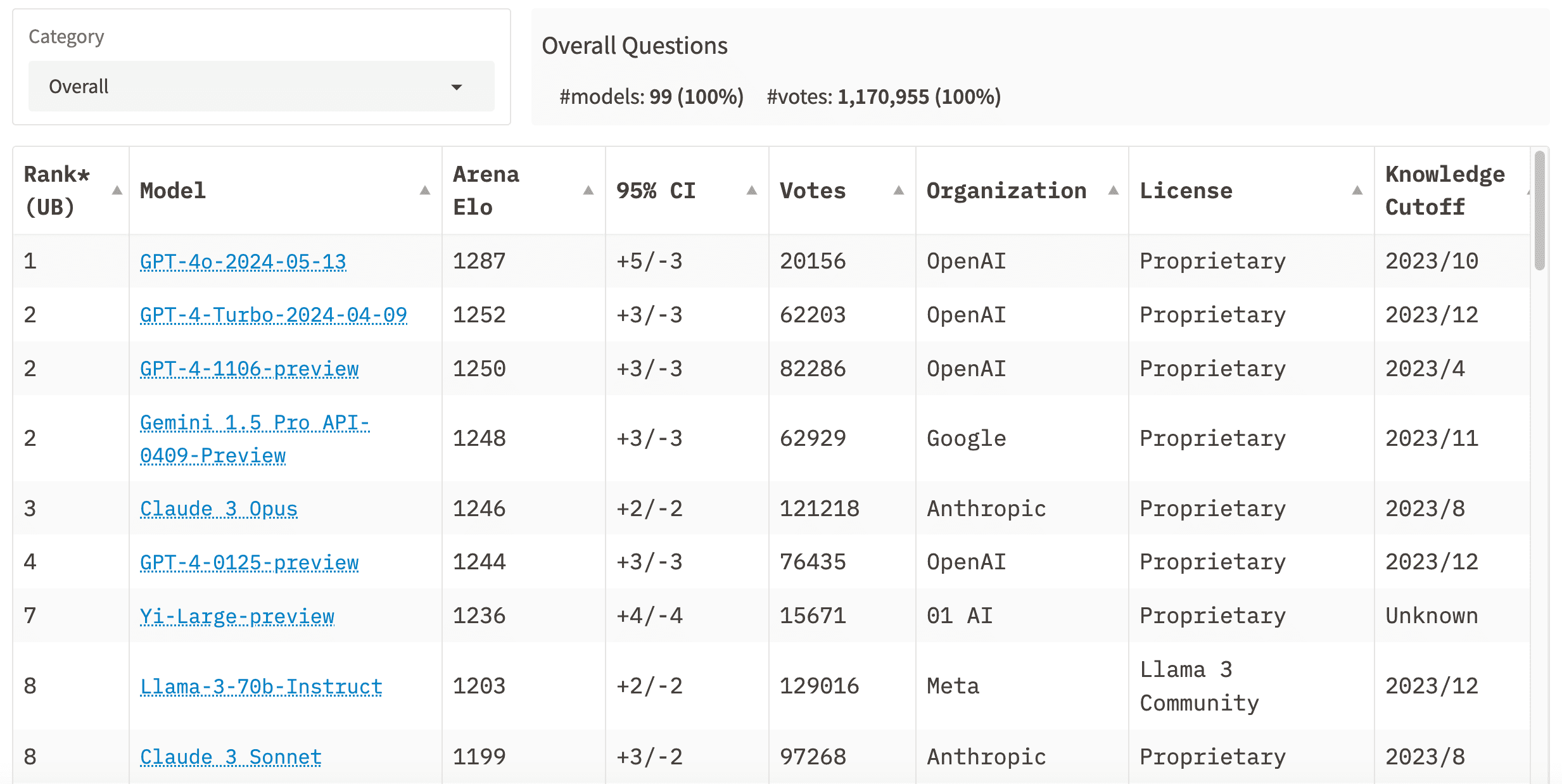
截至目前,LMSYS共有99个大语言模型参与测评,总投票数已超百万。
| 排名 | 模型 | 综合得分 | 投票数 | 组织 | 知识截止日期 |
|---|---|---|---|---|---|
| 🥇 1 | GPT-4o-2024-05-13 | 1287 | 20156 | OpenAI | 2023/10 |
| 🥈 2 | GPT-4-Turbo-2024-04-09 | 1252 | 62203 | OpenAI | 2023/12 |
| 🥉 3 | GPT-4-1106-preview | 1250 | 82286 | OpenAI | 2023/4 |
| 4 | Gemini 1.5 Pro API-0409-Preview | 1248 | 62929 | 2023/11 | |
| 5 | Claude 3 Opus | 1246 | 121218 | Anthropic | 2023/8 |
| 6 | GPT-4-0125-preview | 1244 | 76435 | OpenAI | 2023/12 |
| 7 | Yi-Large-preview | 1236 | 15671 | 01 AI | 未知 |
| 8 | Llama-3-70b-Instruct | 1203 | 129016 | Meta | 2023/12 |
| 9 | Claude 3 Sonnet | 1199 | 97268 | Anthropic | 2023/8 |
| 10 | Bard (Gemini Pro) | 1208 | 12387 | 在线 | |
| 11 | Reka-Core-20240501 | 1195 | 37076 | Reka AI | 未知 |
| 12 | GPT-4-0314 | 1188 | 55378 | OpenAI | 2021/9 |
| 13 | Command R+ | 1188 | 62689 | Cohere | 2024/3 |
| 14 | Qwen-Max-0428 | 1186 | 23568 | Alibaba | 未知 |
| 15 | Claude 3 Haiku | 1181 | 86889 | Anthropic | 2023/8 |
| 16 | GLM-4-0116 | 1175 | 6167 | Zhipu AI | 未知 |
GPT-4系列模型
几乎是毫无疑问地,GPT-4系列模型夺得前三甲,尤其是5月13日刚推出的GPT-4o模型,更是在刚发布就直接登顶,可谓是“出道即巅峰”,而排在第二和第三的分别是GPT-4-Turbo-2024-04-09和GPT-4-1106-preview。值得一提的是,本次排名的依据是LLM竞技场的综合得分,从上面的得分可以看到,GPT-4o和后面的模型在得分上差距还是非常明显的,领先第二名35分之多。

谷歌Gemini系列模型
在这个最新的排行榜里,谷歌的Gemini 1.5 Pro以微弱的优势打败了Claude 3 Opus,位居第四。在之前我也写了不少的文章来介绍Gemini 1.5 Pro模型,首先是它的上下文长度,达到了惊人的100万(确切的说是104万tokens),而5月份的谷歌I/O开发者大会上,更是宣布Gemini 1.5 Pro的上下文长度已经达到了200万,但这个长度需要提交申请排waitlist才能体验。其次是它的多模态能力。最重磅的是它支持视频输入,直接就能够分析视频内容。

根据谷歌最新的通知邮件,Gemini 1.5 ProAPI将于5月30日开始正式收费,但在Google AI Studio中使用该模型仍然免费。想体验的小伙伴可以看我这篇介绍文章:谷歌Gemini 1.5 Pro向所有人开放,无需waitlist!阿里通义千问升级1000万字长文档处理功能!。
Claude 3系列模型
Claude 3系列模型共有3档:Claude 3 Opus,Claude 3 Sonnet,Claude 3 Haiku。这三挡模型的能力依次降低,响应速度依次提高,价格依次降低。这其实也很好理解,推理能力越强的模型需要更多的时间来理解、推断,所以响应速度也就相对较慢。值得一提的是,Claude 3 Opus曾经超越GPT-4,登顶这个排行榜,后来又被反超。

目前Claude 3 Opus排在第5名,Claude 3 Sonnet第9,而Claude 3 Haiku则位列第15名。
国产模型:Yi-Large-preview
第7名,这是目前国产LLM模型在LMSYS榜单中的最高排名,来自零一万物的Yi-Large-preview。不得不说,这是国内AI领域的荣耀时刻。在此之前,仅有阿里的通义大模型跻身进入过前10名。
零一万物公司由创新工场创始人兼CEO李开复领导,成立于2023年,短短几个月内就发布了首款中英双语大模型Yi系列。Yi-Large模型是Yi系列模型的最新力作,是一款拥有千亿参数的闭源大模型。除了本文提到的LMSYS排行榜,在斯坦福大学最新的AlpacaEval 2.0评估中,Yi-Large在全球大模型的胜率排名第三,仅次于GPT-4o和GPT-4-Turbo,在中文SuperCLUE评估中则位于国产大模型的榜首。

国产模型:Qwen-Max-0428
来自阿里的通义系列模型之一的Qwen-Max-0428,当前排名为第14名。不得不说,最为去年才开始爆发的新兴领域,AI大模型真是卷的厉害。通义千问的这个模型前几天还是排名第10,过了几天就被打到了第14名。当然,卷意味着技术的进步,对我们用户来说是件好事。
注意,这里的Qwen-Max-0428是通义系列模型中的一个闭源的商用模型,而不是开源模型。

国产模型:GLM-4-0116
GLM-4-0116模型来自智谱AI,就是开发智谱清言这款AI工具的主体公司。目前GLM-4-0116排名第16名。智谱AI这家公司源自清华大学计算机系的技术成果转化,致力于打造新一代认知智能通用模型。根据公开资料,GLM-4-0116是智谱AI最新发布的第四代基座大模型,其性能逼近GPT-4,具备强大的多模态能力、长文本处理能力和智能体定制能力。该模型支持128K的上下文窗口长度,可以在一次提示词中处理高达300页的文本。在长文本处理能力测试中,GLM-4在128K文本长度内的精度召回率几乎达到100%。

精选推荐
都读到这里了,点个赞鼓励一下吧,小手一赞,年薪百万!😊👍👍👍。关注我,AI之路不迷路,原创技术文章第一时间推送🤖。