第54天:项目总结与经验分享
目标:整理项目经验
一、课程概述
在经过前53天的学习后,今天我们将系统性地总结项目开发经验,包括架构设计、代码规范、性能优化、测试策略等方面的最佳实践。
二、项目经验总结表
| 领域 | 关键点 | 最佳实践 | 常见问题 |
|---|---|---|---|
| 架构设计 | 1. 模块划分 2. 依赖管理 3. 接口设计 | 1. 遵循Clean Architecture 2. 使用依赖注入 3. 接口隔离原则 | 1. 循环依赖 2. 耦合度过高 3. 接口膨胀 |
| 并发处理 | 1. goroutine管理 2. 通道使用 3. 并发控制 | 1. 使用context控制 2. 合理设置缓冲区 3. 使用sync包 | 1. goroutine泄露 2. 死锁 3. 竞态条件 |
| 错误处理 | 1. 错误定义 2. 错误传播 3. 日志记录 | 1. 自定义error 2. 错误包装 3. 结构化日志 | 1. 错误信息不明确 2. 异常处理不完整 3. 日志过于冗余 |
| 性能优化 | 1. 内存管理 2. CPU优化 3. I/O优化 | 1. 对象池化 2. 并发控制 3. 批处理操作 | 1. 内存泄露 2. CPU占用高 3. I/O阻塞 |
三、项目最佳实践示例
让我们通过一个完整的项目示例来展示这些最佳实践:
// main.go
package main
import (
"context"
"fmt"
"log"
"sync"
"time"
)
// Domain层 - 领域模型
type Order struct {
ID string
UserID string
Products []string
Status string
CreatedAt time.Time
}
// Repository接口 - 数据访问层
type OrderRepository interface {
Save(ctx context.Context, order *Order) error
FindByID(ctx context.Context, id string) (*Order, error)
}
// Service层 - 业务逻辑
type OrderService interface {
CreateOrder(ctx context.Context, userID string, products []string) (*Order, error)
GetOrder(ctx context.Context, id string) (*Order, error)
}
// 自定义错误
type OrderError struct {
Code string
Message string
}
func (e *OrderError) Error() string {
return fmt.Sprintf("OrderError: %s - %s", e.Code, e.Message)
}
// Repository实现
type OrderRepositoryImpl struct {
mu sync.RWMutex
orders map[string]*Order
}
func NewOrderRepository() OrderRepository {
return &OrderRepositoryImpl{
orders: make(map[string]*Order),
}
}
func (r *OrderRepositoryImpl) Save(ctx context.Context, order *Order) error {
select {
case <-ctx.Done():
return ctx.Err()
default:
r.mu.Lock()
defer r.mu.Unlock()
r.orders[order.ID] = order
return nil
}
}
func (r *OrderRepositoryImpl) FindByID(ctx context.Context, id string) (*Order, error) {
select {
case <-ctx.Done():
return nil, ctx.Err()
default:
r.mu.RLock()
defer r.mu.RUnlock()
if order, exists := r.orders[id]; exists {
return order, nil
}
return nil, &OrderError{Code: "NOT_FOUND", Message: "Order not found"}
}
}
// Service实现
type OrderServiceImpl struct {
repo OrderRepository
}
func NewOrderService(repo OrderRepository) OrderService {
return &OrderServiceImpl{repo: repo}
}
func (s *OrderServiceImpl) CreateOrder(ctx context.Context, userID string, products []string) (*Order, error) {
if len(products) == 0 {
return nil, &OrderError{Code: "INVALID_INPUT", Message: "Products cannot be empty"}
}
order := &Order{
ID: fmt.Sprintf("ORD-%d", time.Now().UnixNano()),
UserID: userID,
Products: products,
Status: "PENDING",
CreatedAt: time.Now(),
}
if err := s.repo.Save(ctx, order); err != nil {
return nil, fmt.Errorf("failed to save order: %w", err)
}
return order, nil
}
func (s *OrderServiceImpl) GetOrder(ctx context.Context, id string) (*Order, error) {
return s.repo.FindByID(ctx, id)
}
// 并发订单处理器
type OrderProcessor struct {
service OrderService
concurrency int
jobs chan processJob
}
type processJob struct {
userID string
products []string
result chan<- processResult
}
type processResult struct {
order *Order
err error
}
func NewOrderProcessor(service OrderService, concurrency int) *OrderProcessor {
processor := &OrderProcessor{
service: service,
concurrency: concurrency,
jobs: make(chan processJob),
}
processor.start()
return processor
}
func (p *OrderProcessor) start() {
for i := 0; i < p.concurrency; i++ {
go p.worker()
}
}
func (p *OrderProcessor) worker() {
for job := range p.jobs {
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
order, err := p.service.CreateOrder(ctx, job.userID, job.products)
cancel()
job.result <- processResult{order: order, err: err}
}
}
func (p *OrderProcessor) ProcessOrder(userID string, products []string) (*Order, error) {
resultChan := make(chan processResult, 1)
p.jobs <- processJob{
userID: userID,
products: products,
result: resultChan,
}
result := <-resultChan
return result.order, result.err
}
// 示例使用
func main() {
// 初始化依赖
repo := NewOrderRepository()
service := NewOrderService(repo)
processor := NewOrderProcessor(service, 5)
// 模拟并发订单处理
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func(orderNum int) {
defer wg.Done()
products := []string{fmt.Sprintf("Product-%d", orderNum)}
order, err := processor.ProcessOrder(fmt.Sprintf("user-%d", orderNum), products)
if err != nil {
log.Printf("Failed to process order %d: %v", orderNum, err)
return
}
log.Printf("Successfully processed order: %+v", order)
}(i)
}
wg.Wait()
log.Println("All orders processed")
}
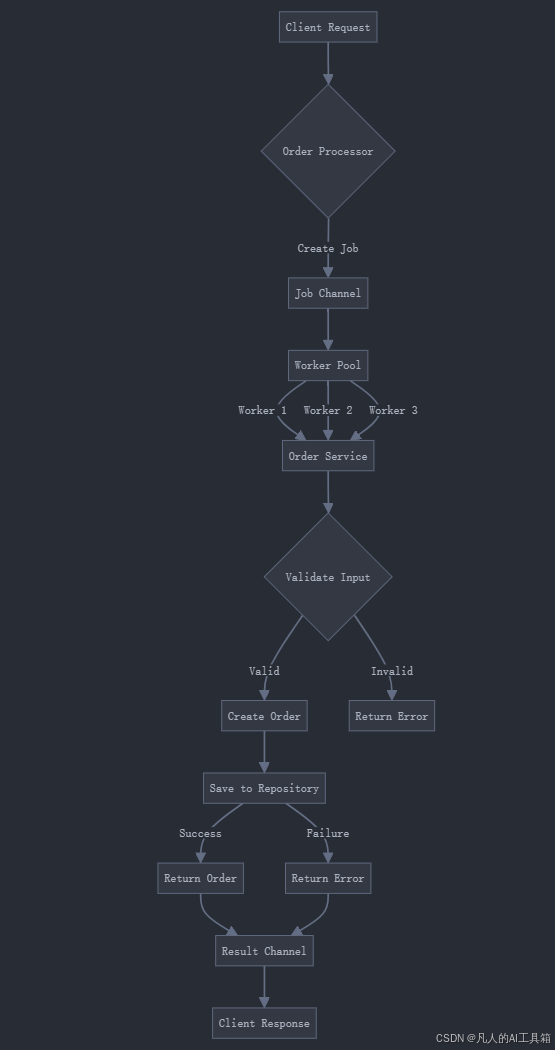
四、代码结构说明
-
领域模型设计
- Order结构体包含必要的订单信息
- 使用强类型确保数据一致性
- 时间戳记录创建时间
-
接口设计
- OrderRepository定义数据访问接口
- OrderService定义业务逻辑接口
- 接口隔离原则体现在职责划分
-
错误处理
- 自定义OrderError包含错误码和消息
- 使用error wrapping进行错误传播
- context用于超时控制
-
并发处理
- 使用Worker Pool模式处理并发订单
- channel用于任务分发和结果收集
- sync.WaitGroup确保并发任务完成
-
数据访问层
- 使用sync.RWMutex保护并发访问
- context用于取消操作
- 实现基本的CRUD操作
五、性能优化要点
- 内存优化
// 使用对象池
var orderPool = sync.Pool{
New: func() interface{} {
return &Order{}
},
}
// 获取对象
order := orderPool.Get().(*Order)
defer orderPool.Put(order)
- CPU优化
// 使用buffer channel减少阻塞
jobs := make(chan Job, 100)
// 批量处理
func batchProcess(orders []*Order) {
// 使用并发处理
results := make(chan error, len(orders))
for _, order := range orders {
go func(o *Order) {
results <- processOrder(o)
}(order)
}
}
- I/O优化
// 使用bufio优化I/O
func readOrders(filename string) ([]*Order, error) {
file, err := os.Open(filename)
if err != nil {
return nil, err
}
defer file.Close()
scanner := bufio.NewScanner(file)
var orders []*Order
for scanner.Scan() {
// 处理每一行
}
return orders, scanner.Err()
}
六、测试策略
- 单元测试
func TestOrderService_CreateOrder(t *testing.T) {
// 准备测试数据
repo := NewMockOrderRepository()
service := NewOrderService(repo)
// 执行测试
ctx := context.Background()
order, err := service.CreateOrder(ctx, "user1", []string{"product1"})
// 断言结果
assert.NoError(t, err)
assert.NotNil(t, order)
assert.Equal(t, "user1", order.UserID)
}
- 性能测试
func BenchmarkOrderProcessor(b *testing.B) {
repo := NewOrderRepository()
service := NewOrderService(repo)
processor := NewOrderProcessor(service, 5)
b.ResetTimer()
for i := 0; i < b.N; i++ {
_, err := processor.ProcessOrder(
fmt.Sprintf("user-%d", i),
[]string{fmt.Sprintf("product-%d", i)},
)
if err != nil {
b.Fatal(err)
}
}
}
七、代码审查清单
-
基础检查
- 代码是否遵循Go的命名规范
- 是否有适当的注释和文档
- 是否处理所有错误情况
- 是否有适当的日志记录
-
设计检查
- 是否遵循SOLID原则
- 是否有适当的抽象和接口
- 是否避免过度设计
- 是否考虑了可扩展性
-
性能检查
- 是否有潜在的内存泄露
- 是否有不必要的对象分配
- 是否有适当的并发控制
- 是否有性能瓶颈
八、项目经验总结
-
架构设计经验
- 始终遵循清晰的分层架构
- 使用依赖注入提高代码可测试性
- 通过接口隔离实现模块化
- 保持代码简洁,避免过度设计
-
开发流程经验
- 先写测试,后写实现
- 持续重构,保持代码整洁
- 定期代码审查
- 持续集成和部署
-
性能优化经验
- 先做性能分析,再做优化
- 注意内存管理和对象复用
- 合理使用并发和异步
- 注意I/O操作的优化
让我继续完成剩余内容。
九、常见陷阱和解决方案(续)
- goroutine泄露处理
package main
import (
"context"
"fmt"
"sync"
"time"
)
// 错误的实现 - 可能导致goroutine泄露
func leakyWorker() {
messages := make(chan string)
go func() {
for {
msg := <-messages
fmt.Println("Processing:", msg)
}
}()
// messages channel永远不会关闭,goroutine将永远存在
}
// 正确的实现 - 使用context控制生命周期
type Worker struct {
ctx context.Context
cancel context.CancelFunc
wg sync.WaitGroup
messages chan string
}
func NewWorker() *Worker {
ctx, cancel := context.WithCancel(context.Background())
return &Worker{
ctx: ctx,
cancel: cancel,
messages: make(chan string, 100),
}
}
func (w *Worker) Start() {
w.wg.Add(1)
go func() {
defer w.wg.Done()
for {
select {
case <-w.ctx.Done():
fmt.Println("Worker shutting down...")
return
case msg := <-w.messages:
fmt.Println("Processing:", msg)
}
}
}()
}
func (w *Worker) Stop() {
w.cancel()
w.wg.Wait()
close(w.messages)
}
func (w *Worker) Process(msg string) error {
select {
case <-w.ctx.Done():
return fmt.Errorf("worker is stopped")
case w.messages <- msg:
return nil
default:
return fmt.Errorf("channel is full")
}
}
func main() {
// 示例使用
worker := NewWorker()
worker.Start()
// 处理一些消息
for i := 0; i < 5; i++ {
if err := worker.Process(fmt.Sprintf("Message %d", i)); err != nil {
fmt.Printf("Failed to process message: %v\n", err)
}
}
// 等待一会儿让消息处理完
time.Sleep(time.Second)
// 优雅关闭
worker.Stop()
}
- 并发安全处理
package main
import (
"fmt"
"sync"
"time"
)
// 计数器接口
type Counter interface {
Increment()
GetCount() int64
}
// 不安全的计数器实现
type UnsafeCounter struct {
count int64
}
func (c *UnsafeCounter) Increment() {
c.count++ // 非原子操作,在并发环境下不安全
}
func (c *UnsafeCounter) GetCount() int64 {
return c.count
}
// 安全的计数器实现方式1:使用互斥锁
type MutexCounter struct {
mu sync.Mutex
count int64
}
func (c *MutexCounter) Increment() {
c.mu.Lock()
defer c.mu.Unlock()
c.count++
}
func (c *MutexCounter) GetCount() int64 {
c.mu.Lock()
defer c.mu.Unlock()
return c.count
}
// 安全的计数器实现方式2:使用原子操作
type AtomicCounter struct {
count int64
}
func (c *AtomicCounter) Increment() {
atomic.AddInt64(&c.count, 1)
}
func (c *AtomicCounter) GetCount() int64 {
return atomic.LoadInt64(&c.count)
}
// 性能测试函数
func testCounter(c Counter, numGoroutines int) {
var wg sync.WaitGroup
start := time.Now()
for i := 0; i < numGoroutines; i++ {
wg.Add(1)
go func() {
defer wg.Done()
for j := 0; j < 1000; j++ {
c.Increment()
}
}()
}
wg.Wait()
elapsed := time.Since(start)
fmt.Printf("Counter type: %T\n", c)
fmt.Printf("Final count: %d (expected: %d)\n", c.GetCount(), numGoroutines*1000)
fmt.Printf("Time taken: %s\n\n", elapsed)
}
func main() {
numGoroutines := 100
// 测试不安全的计数器
unsafeCounter := &UnsafeCounter{}
testCounter(unsafeCounter, numGoroutines)
// 测试互斥锁计数器
mutexCounter := &MutexCounter{}
testCounter(mutexCounter, numGoroutines)
// 测试原子操作计数器
atomicCounter := &AtomicCounter{}
testCounter(atomicCounter, numGoroutines)
}
- 资源管理流程图
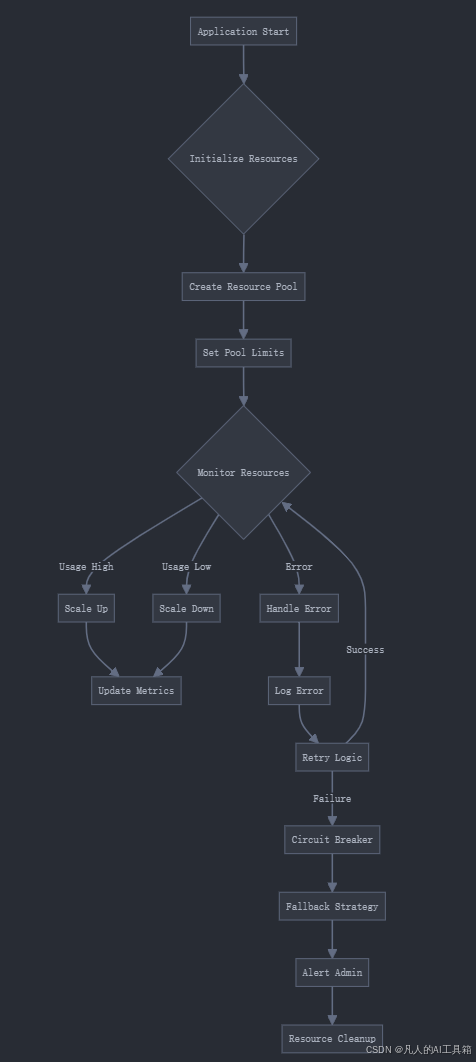
十、项目优化建议清单
-
代码质量优化
- 实施代码静态分析
- 建立代码评审制度
- 完善单元测试覆盖
- 规范化错误处理
-
性能优化方向
- 实施性能监控
- 优化资源使用
- 改进并发模型
- 优化内存管理
-
可维护性提升
- 完善技术文档
- 标准化项目结构
- 统一编码规范
- 建立持续集成
十一、项目管理经验
- 版本控制最佳实践
- 使用语义化版本号
- 建立分支管理策略
- 规范提交信息格式
- 定期代码合并和发布
- 文档管理体系
- API文档
- 技术文档
- 操作手册
- 故障处理手册
- 持续集成/持续部署(CI/CD)
# .gitlab-ci.yml 示例
stages:
- test
- build
- deploy
test:
stage: test
script:
- go test ./...
- go vet ./...
build:
stage: build
script:
- go build -o app
deploy:
stage: deploy
script:
- docker build -t myapp .
- docker push myapp
十二、技术债务管理
- 识别技术债务
- 代码复杂度过高
- 测试覆盖率不足
- 文档更新滞后
- 依赖版本过期
- 处理优先级
高优先级:
- 影响系统稳定性的问题
- 安全漏洞
- 性能瓶颈
中优先级:
- 代码重构需求
- 测试覆盖率提升
- 文档更新
低优先级:
- 代码风格优化
- 依赖更新
- 工具链更新
- 还技术债务计划
短期计划(1-2周):
- 修复已知bug
- 更新关键依赖
- 补充核心测试
中期计划(1-2月):
- 重构问题模块
- 提升测试覆盖
- 更新技术文档
长期计划(3-6月):
- 架构优化
- 技术栈更新
- 工具链升级
十三、知识沉淀与分享
- 建立知识库
- 技术文档
- 最佳实践
- 踩坑记录
- 解决方案
- 团队分享机制
- 周技术分享
- 月度总结
- 季度复盘
- 年度计划
- 持续学习计划
- 新技术调研
- 源码阅读
- 技术认证
- 外部交流
总结
在完成这54天的Go语言学习后,通过这次总结,我们系统性地回顾了项目开发过程中的各个关键点。从代码规范到架构设计,从性能优化到测试策略,这些经验和最佳实践将帮助我们在未来的项目中更好地应用Go语言。记住,编程不仅是一门科学,也是一门艺术,需要我们不断学习和实践,才能真正掌握其精髓。
怎么样今天的内容还满意吗?再次感谢观众老爷的观看,关注GZH:凡人的AI工具箱,回复666,送您价值199的AI大礼包。最后,祝您早日实现财务自由,还请给个赞,谢谢!