
简介:本书《深入理解Linux内核》深入探讨了Linux操作系统的核心工作原理,包括内核的关键概念和技术细节。它旨在帮助读者理解、优化Linux系统,无论语言背景如何。书中覆盖了进程管理、内存管理、文件系统、网络协议栈、设备驱动、中断处理、I/O子系统、安全与权限以及性能分析和调试等多个方面。第三版增加了最新内核内容,而第二版中文版则适合初学者。
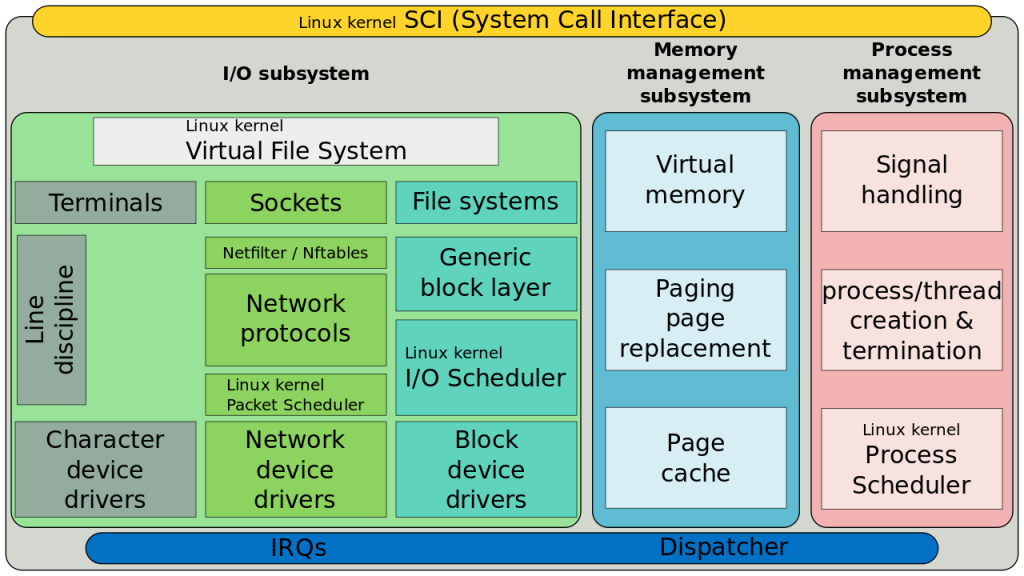
1. Linux内核基础
Linux操作系统作为开源世界的璀璨明珠,其强大生命力和广泛应用的背后,离不开其坚实的内核基础。内核是Linux系统的心脏,负责管理系统资源和硬件设备,确保各种软件能够高效、稳定地运行。
1.1 Linux内核的角色与功能
Linux内核是一个模块化的操作系统核心,它主要负责以下功能: - 进程管理 :调度各个进程在CPU上运行。 - 内存管理 :高效地分配和回收内存资源。 - 文件系统 :管理数据的存储和读取。 - 网络通信 :处理网络协议栈以及数据包的发送和接收。 - 设备驱动 :作为硬件设备与用户空间程序之间的桥梁。 - 中断和异常处理 :响应和处理各种突发事件,如硬件中断和程序异常。
1.2 Linux内核的组成
Linux内核主要由以下几个核心部分组成: - 进程调度器(Scheduler) :决定哪个进程获得CPU时间片。 - 内存管理器(Memory Manager) :处理物理和虚拟内存的映射,管理内存分配。 - 文件系统层 :提供一致的文件操作接口,支持多种文件系统。 - 网络子系统 :实现TCP/IP协议栈和其它网络功能。 - 设备驱动程序 :为计算机硬件提供软件接口。
1.3 内核版本和发行模型
Linux内核有主线(Mainline)和长期支持(LTS)版本之分。主线版本持续不断地更新,包含最新的功能和修复,而LTS版本提供更长期的稳定性和安全更新。
Linux内核的开发遵循特定的周期和版本控制策略,每一个发布版都经历了社区的广泛测试和评审,确保了其稳定性和性能。
通过理解Linux内核的这些基础知识,我们为深入了解其内核的各个组成部分打下了坚实的基础。随着我们对Linux内核更深入的探索,我们会涉及到进程管理、内存管理、文件系统、网络协议栈等方面的内容,这些将是IT专业人员必须要掌握的核心技能。
2. 进程管理详解
2.1 Linux进程的概念与结构
2.1.1 进程的定义与生命周期
Linux中的进程可以被视作执行中的程序的一个实例。它是一个动态的实体,包括程序代码、它当前的活动(通过程序计数器来标识)、处理机的寄存器内容、变量的值以及分配给它的系统资源。Linux使用进程识别符(PID)来唯一标识一个进程。
进程的生命周期从其创建开始,这通常发生在系统启动或某个运行中的程序调用fork()或exec()系统调用来生成一个新进程。进程的生命周期包括如下几个主要状态:
- 运行态(Running) : 进程正在CPU上执行。
- 就绪态(Ready) : 进程已具备运行条件,但由于CPU资源有限,它正在等待CPU分配资源。
- 阻塞态(Blocked) : 进程正在等待某个事件发生(如I/O操作完成),无法继续执行。
- 终止态(Terminated) : 进程执行完毕,或因为某些错误而被操作系统终止。
Linux内核使用 task_struct 数据结构来表示进程控制块(PCB),其中包含了进程的状态、堆栈、程序计数器等重要信息。
下面是一个简单的代码示例,演示了如何在C语言中创建一个新进程:
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <unistd.h>
int main() {
pid_t pid = fork(); // fork()创建一个新进程
if (pid < 0) {
// fork失败
perror("fork failed");
exit(1);
} else if (pid == 0) {
// 子进程
printf("Hello from child process!\n");
exit(0);
} else {
// 父进程
printf("Hello from parent process!\n");
wait(NULL); // 等待子进程结束
}
return 0;
}
在这个例子中, fork() 系统调用用于创建一个子进程。之后父子进程将继续执行接下来的代码,但彼此独立。
2.1.2 进程状态与转换
Linux内核中的进程状态转换通常是由内核调度器进行管理的。每个进程都可以通过其 task_struct 中的 state 字段表示当前状态。
进程状态的转换通常发生在以下情况:
- 从运行态(Running)转换到就绪态(Ready) : 进程的时间片用完或被高优先级进程抢占。
- 从就绪态(Ready)转换到运行态(Running) : 当前运行的进程被抢占,调度器选择另一个就绪态进程来运行。
- 从运行态(Running)转换到阻塞态(Blocked) : 进程请求资源,如磁盘I/O,直到资源可用前不能继续执行。
- 从阻塞态(Blocked)转换到就绪态(Ready) : 等待的资源已经准备就绪,进程可以继续执行。
进程状态的转换通过进程调度器进行管理,确保系统的公平、高效运行。下面的流程图展示了进程状态之间的转换关系:
graph LR
A[运行态(Running)] -->|时间片结束/高优先级进程| B[就绪态(Ready)]
B -->|调度器选择| A
A -->|请求资源| C[阻塞态(Blocked)]
C -->|资源就绪| B
调度器负责监控进程状态并作出正确的状态转换决策,这是确保操作系统高效运行的关键因素。
2.2 进程调度机制
2.2.1 Linux调度器的工作原理
Linux内核中的进程调度器负责决定哪个进程将获得CPU时间,何时获得,以及获得多久。现代Linux使用了一个叫做完全公平调度器(Completely Fair Scheduler, CFS)的调度器,它是基于虚拟运行时间(vruntime)的概念来进行进程选择和调度的。
CFS调度器的工作原理包括以下几个要点:
- 虚拟运行时间(vruntime) : 每个进程都有一个与其运行时间成正比的vruntime值,调度器选择vruntime最小的进程来运行。
- 调度实体(struct sched_entity) : CFS使用调度实体来表示进程,调度实体包含了vruntime等重要信息。
- 红黑树(Red-Black Tree) : CFS使用红黑树来维护所有可运行的进程,树的每个节点代表一个进程。该树按vruntime排序,使得最小vruntime的进程总是在树的最左侧,最容易被选中。
- 时间片分配 : 一个进程被选择运行后,会获得一个时间片。当进程用完时间片后,它会被放回红黑树,等待下一次调度。
CFS调度器通过这些机制确保了进程调度的公平性,避免了进程饥饿现象,并尽可能地减少了上下文切换带来的开销。
2.2.2 调度策略与优先级管理
Linux支持多种调度策略,以适应不同的工作负载和需求:
- SCHED_OTHER : 默认调度策略,适用于大多数通用任务。
- SCHED_FIFO : 实时调度策略,采用先进先出(FIFO)队列,优先级高的进程会持续占用CPU直到它自愿释放或被同优先级或更高优先级的进程抢占。
- SCHED_RR : 轮转调度策略,类似于SCHED_FIFO,但是有一个时间片限制,时间片用完后必须等待下一轮。
- SCHED_BATCH : 用于批量处理任务的调度策略。
- SCHED_IDLE : 低优先级调度策略,用于系统空闲时运行的进程。
每个策略可以通过nice值和实时优先级来控制进程的优先级。nice值范围是-20到19,数值越小,优先级越高;对于实时进程,优先级范围是1到99,数值越高优先级越高。
调度策略和优先级管理通过系统调用如 nice() , setpriority() , sched_setscheduler() 等进行修改和控制。
2.3 进程同步与通信
2.3.1 信号与信号量的应用
信号(Signal)是进程间通信的一种基本机制,用于通知进程系统发生了某个事件。在Linux中,每个信号都有一个唯一的编号和名称,比如SIGINT用于终止一个进程。
信号的发送通常使用 kill() 系统调用,而信号的处理可以通过信号处理函数(signal handlers)来实现。当进程接收到信号时,会暂停其当前执行的流程,转而执行信号处理函数。
示例代码展示如何为一个进程设置信号处理函数:
#include <stdio.h>
#include <signal.h>
#include <unistd.h>
void signal_handler(int signal) {
printf("Received signal %d\n", signal);
}
int main() {
signal(SIGINT, signal_handler); // 设置信号处理函数
while (1) {
pause(); // 阻塞并等待信号
}
return 0;
}
在这个例子中,如果发送SIGINT信号到这个程序(使用 kill -SIGINT <PID> ),它会打印出接收到的信号编号。
信号量(Semaphore)是一种广泛应用于进程同步的机制。信号量用一个整数表示可用资源的数量,进程在进入临界区前需要获得信号量,使用完毕后释放信号量。
信号量的一般用法是:进程在进入临界区前执行 sem_wait() ,如果信号量的值大于0,则将其减1并继续执行;如果信号量的值为0,则进程等待直到信号量的值变为正数。进程离开临界区时,使用 sem_post() 增加信号量的值。
2.3.2 管道、消息队列和共享内存
管道(Pipes)是一种简单的进程间通信机制,它提供了一个单向的数据流。父进程和子进程可以通过管道进行数据交换。
示例代码展示了如何创建一个管道并使用它:
#include <stdio.h>
#include <unistd.h>
int main() {
int pipefd[2];
char buf;
pid_t cpid;
char *msg = "Hello from child process";
if (pipe(pipefd) == -1) {
perror("pipe");
exit(EXIT_FAILURE);
}
cpid = fork();
if (cpid == -1) {
perror("fork");
exit(EXIT_FAILURE);
}
if (cpid == 0) { /* Child reads from pipe */
close(pipefd[1]); // 关闭写端
while (read(pipefd[0], &buf, 1) > 0) {
write(STDOUT_FILENO, &buf, 1);
}
write(STDOUT_FILENO, "\n", 1);
close(pipefd[0]);
_exit(EXIT_SUCCESS);
} else { /* Parent writes to pipe */
close(pipefd[0]); // 关闭读端
write(pipefd[1], msg, strlen(msg));
close(pipefd[1]);
wait(NULL); /* Wait for child */
exit(EXIT_SUCCESS);
}
}
消息队列(Message Queues)提供了一种在进程间传递数据块的方式。每个消息队列由一个唯一的标识符标识,进程可以向队列中添加消息或从队列中读取消息。
共享内存(Shared Memory)是最快的一种IPC(进程间通信)机制。通过允许两个或多个进程共享内存区,可以直接读写内存区中的数据。由于共享内存不涉及内核的介入,因此性能比其他IPC机制要好。
每种进程间通信机制都有其特定的使用场景和优缺点。选择合适的机制可以使程序的设计更加高效和安全。
3. 内存管理机制
3.1 Linux内存模型
3.1.1 物理与虚拟内存的映射
Linux 系统通过虚拟内存管理抽象物理内存,从而允许系统运行比物理内存大得多的程序。虚拟内存以页为单位进行管理,每个页框(page frame)通常为 4KB。当进程请求访问内存时,会发生页面错误(page fault),内核会负责将相应的页从磁盘的交换空间(swap space)或文件中映射到物理内存的页框中。
物理内存映射
物理内存映射是通过页表来实现的,每个进程都有自己的页表,映射进程虚拟地址空间到物理地址空间。页表存储在每个进程的内存描述符(mm_struct)中。
虚拟内存概念
虚拟内存空间分为几个区域,包括文本段(代码区)、数据段(全局变量等)、堆(动态分配的内存)、栈(局部变量和函数调用等)和特殊用途的区域(如内存映射文件)。每个区域通过内存管理单元(MMU)映射到物理地址空间。
3.1.2 内存分页与分段机制
Linux 使用分页系统来管理虚拟内存,这种机制将虚拟内存空间划分为固定大小的页,同时将物理内存划分为页框,两者通过页表进行映射。
分页机制
分页机制可以减少内存碎片,提高内存利用率。页表项(PTE)包含物理页框号、访问权限、脏位、存在位等信息。分页不仅提供了内存保护机制,还支持虚拟内存的实现。
分段机制
分段则是另一种内存管理方式,将内存分割为更灵活的段。段可以是数据、代码等,不同的段可以有不同的属性。Linux 主要采用分页机制,但内核本身依然使用段来实现隔离和保护机制。
3.2 内存分配策略
3.2.1 页框管理与分配
Linux 内核使用伙伴系统(buddy system)来管理页框的分配和回收。伙伴系统能够有效地减少内存碎片,并快速分配和回收页框。
伙伴系统的原理
伙伴系统将页框分组成块,每个块包含 2 的幂次个连续页框。分配时,根据请求的大小,从合适的块中取出一个块分配给请求者;回收时,如果相邻的伙伴块都是空闲的,则将它们合并成一个更大的块。
非连续内存分配
除了连续页框分配,Linux 还提供了非连续内存分配,比如 slab 分配器。slab 分配器用于管理小块内存,减少内存碎片,提高分配效率。
3.2.2 slab 分配器的工作原理
slab 分配器是 Linux 内核中用于内核对象内存分配的一种机制。它将对象缓存起来,当请求相同大小的对象时,直接从缓存中分配,而不必调用底层的页框分配函数。
slab 缓存
slab 缓存由一个或多个物理上连续的页框组成,被组织成不同的对象类型,如进程描述符、文件系统节点等。每个 slab 缓存都有一组管理对象的函数,负责初始化、分配和回收对象。
分配与回收
当请求一个对象时,slab 分配器会从相应的 slab 缓存中获取一个未使用的对象,或者如果缓存为空,则分配一个新的 slab。对象的回收也是直接放入缓存中,以供后续使用。
3.3 内存管理的高级特性
3.3.1 内存压缩与回收技术
随着系统运行时间的推移,内存可能逐渐变得碎片化。Linux 通过 KSM(Kernel Samepage Merging)和交换压缩等技术来回收和压缩内存。
KSM 技术
KSM 是一种内核特性,它能够合并那些内容相同的页框。通过定期扫描,KSM 找到内容相同的页框,并将它们合并成一个页框,只保留一份,以节省物理内存。
交换压缩
当物理内存不足时,Linux 内核会将一些不常访问的页框移动到交换分区。交换压缩是一种特殊形式的交换,它只交换那些压缩后能够节省空间的页框。
3.3.2 换页与交换空间管理
Linux 使用交换空间(swap space)来扩展物理内存。当物理内存耗尽时,内存页被移动到交换空间中,这一过程称为换页。
交换空间的使用
交换空间通常位于磁盘上,用来存放那些长时间不被访问的页。交换空间的使用可以增加系统的可用内存,但也比物理内存慢,因此使用应谨慎。
交换策略
Linux 通过交换策略控制页框的换入和换出。其中包括了不同的算法,比如最近最少使用(LRU)算法,它记录页的访问顺序,并在需要时移除最长时间未被访问的页。
代码块展示如何在 Linux 中查看和管理系统内存使用情况:
# 查看系统内存和交换空间的使用情况
free -m
# 释放缓存来回收内存
sync; echo 1 > /proc/sys/vm/drop_caches
sync; echo 2 > /proc/sys/vm/drop_caches
sync; echo 3 > /proc/sys/vm/drop_caches
# 清除回收页的缓存
echo 1 > /proc/sys/vm/overcommit_memory
在上述代码块中, free -m 命令用于查看当前的内存使用情况,包括物理内存和交换空间。 echo 命令用来清除缓存,以回收内存。
表格可以用来展示不同状态下的内存使用情况:
| 参数 | 描述 | | --- | --- | | Mem | 总物理内存 | | Swap | 总交换空间 | | -/+ buffers/cache | 缓存和缓冲区调整后的空闲/已使用内存 | | Available | 估计的可用于启动新应用程序的“可用”内存 |
mermaid 流程图展示内存分配和回收的流程:
flowchart LR
A[开始] --> B{内存请求}
B -- 是 --> C[伙伴系统分配页框]
B -- 否 --> D[slab分配器分配对象]
C --> E{是否成功}
D --> E
E -- 是 --> F[使用内存]
E -- 否 --> G[触发交换压缩]
F --> H[内存使用完毕]
G --> I[压缩内存]
H --> J[释放内存]
I --> J
J --> K[回收至空闲列表]
K --> L[结束]
在 mermaid 流程图中,展示了当内存请求发生时,系统根据请求大小选择伙伴系统或 slab 分配器进行分配。如果分配成功,进程使用内存;如果失败,则触发交换压缩。在内存使用完毕后,释放内存,并回收至空闲列表中。
4. 文件系统架构
4.1 Linux文件系统概述
Linux作为类Unix操作系统,在文件系统方面表现出了高度的灵活性和扩展性。它不仅支持多种文件系统,还可以通过虚拟文件系统(VFS)抽象层与不同的文件系统进行交云。
4.1.1 文件系统的层次结构
Linux文件系统遵循层次结构的设计原则,从用户视角来看,最顶层是挂载点,不同的文件系统可以挂载到这个层次结构的不同点上。这个设计使得Linux可以支持多样的存储设备和文件系统类型。
4.1.2 文件系统的挂载与卸载
挂载是指将一个文件系统与目录树上的某个点关联起来,卸载则是解除这种关联。执行挂载操作时,需要指定设备、挂载点、文件系统类型以及挂载选项等参数。卸载操作相对简单,只需要使用umount命令指定挂载点或设备即可。
4.2 VFS与具体文件系统的交互
Linux通过虚拟文件系统(VFS)统一了各种文件系统的接口,使得用户程序能够透明地访问不同的文件系统。
4.2.1 虚拟文件系统(VFS)的作用
VFS作为Linux内核的一个子系统,提供了统一的文件系统接口,包括文件打开、读写、关闭以及目录项的创建和删除等操作。它主要通过四个主要对象(超级块对象、索引节点对象、目录项对象和文件对象)来实现这些功能。
4.2.2 不同文件系统的特点与对比
Linux支持多种文件系统,例如ext4、xfs、btrfs等,它们在性能、可靠性、功能和用途上各有千秋。例如,ext4是目前最常用的文件系统之一,以其稳定性著称;xfs适用于需要大容量存储的场合;btrfs引入了诸如快照、数据校验等现代特性。
4.3 文件系统的性能优化
文件系统的性能优化是保持系统响应速度和效率的关键所在,包括磁盘I/O调度和文件系统缓存管理等。
4.3.1 磁盘I/O调度策略
Linux磁盘I/O调度器负责管理对物理存储设备的读写请求。常见的调度策略有CFQ(完全公平队列)、Deadline、NOOP(No Operation)和BFQ(Budget Fair Queueing)。CFQ适用于传统机械硬盘,NOOP适用于SSD等固态存储设备。
4.3.2 文件系统缓存与预读技术
文件系统缓存是通过使用系统内存来缓存常用数据,从而减少物理存储设备的读写操作。预读技术则是预先读取将要访问的数据到缓存中,这种技术可以减少读取延迟。Linux内核通过页缓存和dentry缓存来实现这些功能。
接下来的内容将是章节“4.2 VFS与具体文件系统的交互”下的更深层次的子章节。
. . . VFS对象及操作方法
虚拟文件系统的主要作用是创建一个通用的文件系统模型,该模型通过定义四个核心对象的结构来实现。每个对象都有一系列的操作方法,使得不同的文件系统可以为相同的抽象操作实现自己的方法。
struct inode_operations {
struct dentry * (*lookup) (struct inode *, struct dentry *, unsigned int);
const struct seq_operations *owner;
void * (*getpérfakefs) (struct inode *);
int (*permission) (struct inode *, int);
struct inode * (*follow_link) (struct dentry *, struct nameidata *);
void (*putpérfakefs) (struct inode *);
void (*truncate) (struct inode *);
int (*create) (struct inode *, struct dentry *, umode_t, bool);
int (*link) (struct dentry *, struct inode *, struct dentry *);
int (*unlink) (struct inode *, struct dentry *);
int (*symlink) (struct inode *, struct dentry *, const char *);
int (*mkdir) (struct inode *, struct dentry *, umode_t);
int (*rmdir) (struct inode *, struct dentry *);
int (*mknod) (struct inode *, struct dentry *, umode_t, dev_t);
int (*rename) (struct inode *, struct dentry *,
struct inode *, struct dentry *);
int (*readlink) (struct dentry *, char __user *, int);
const char * (*get pérfakefs) (struct inode *, struct dentry *);
int (*update_time) (struct inode *, struct iattr *);
int (*atomic_open) (struct inode *, struct dentry *,
struct file *, unsigned open_flag,
umode_t mode, int *error);
int (*tmpfile) (struct inode *, struct dentry *, umode_t);
};
以上代码定义了 inode_operations 结构体,展示了VFS抽象的一部分。每一个函数指针代表一个操作,例如 lookup 用于查找目录中的文件, create 用于创建新的文件等。这样的设计允许文件系统开发者根据自己的需求实现具体的文件操作方法。
. . . 文件系统注册与注销
不同的文件系统在系统初始化时需要注册自己的操作函数集到VFS中,当文件系统被卸载时,则需要注销这些操作。这是通过调用 register_filesystem 和 unregister_filesystem 函数完成的。
extern struct dentry *rootfs_get_super(struct file_system_type *, int,
const struct path *, unsigned long);
extern struct dentry *ramfs_get_super(struct file_system_type *, int,
const struct path *, unsigned long);
struct file_system_type {
const char *name;
int fs_flags;
struct dentry *(*get pérfakefs) (struct file_system_type *, int,
const struct path *, unsigned long);
void (*kill pérfakefs) (struct super_block *);
struct module *owner;
struct file_system_type * next;
struct list_head fs_supers;
struct lock_class_key s_lock_key;
struct lock_class_key s_writers_key;
struct lock_class_key s_vfs_rename_key;
struct lock_class_key s_vfs_unlink_key;
};
以上代码展示了 file_system_type 结构体的定义,这个结构体用于表示一种文件系统类型,并且包含了获取根文件系统和卸载文件系统的方法。系统初始化时,文件系统类型通过 register_filesystem 函数注册到内核中,相反地,通过 unregister_filesystem 注销。
. . . 文件系统的挂载与卸载流程
文件系统的挂载与卸载是文件系统与VFS交互的一个重要部分。挂载点的创建和文件系统自身初始化操作都是在挂载过程中完成的。当卸载文件系统时,相应的所有挂载点都需要被清除。
static int do_mount(struct path *path, char *dev_name, const char *dir_name,
void *data, int mnt_flags)
{
//...
err = do_new mount(path->mnt, path->dentry, format, sb, data, mnt_flags);
if (err)
goto outmnt;
//...
}
static int do_new mount(struct file_system_type *type, struct dentry *root,
const char *name, unsigned long flags, void *data, int mnt_flags)
{
struct path path;
struct vfsmount *mnt;
int retval = -ENOMEM;
mnt = alloc_vfsmnt(name);
if (!mnt)
goto out;
path.mnt = mnt;
path.dentry = root;
retval = type->mount(mnt->mnt_devname, &path, name, flags, data);
if (retval)
goto out_mnt;
//...
}
以上代码展示了在内核中挂载文件系统的主要流程。 do_mount 函数是挂载文件系统的主要入口,它最终调用 do_new_mount 来完成实际的挂载过程。该过程包括为文件系统分配数据结构并调用文件系统的 mount 方法完成挂载。
. . . VFS缓存策略
VFS缓存对于提高文件系统性能至关重要。VFS缓存主要通过页缓存(page cache)和名称缓存(dentry cache)来实现。页缓存是内存中存储的物理页的副本,名称缓存则存储了文件路径到文件索引节点的映射。
struct address_space {
struct inode *host;
struct radix_tree_root page_tree;
spinlock_t tree_lock;
unsigned int i_mmap_writable;
struct list_head private_list;
struct list_head i_mmap;
spinlock_t i_mmap_lock;
struct mutex i_mutex;
unsigned long nrpages;
struct address_space_operations *a_ops;
struct inode *host, *mapping;
struct address_space *assoc_mapping;
gfp_t gfp_mask;
unsigned long flags;
struct backing_dev_info *backing_dev_info;
spinlock_t tree_lock;
void *private_data;
struct list_head i_mmap_nonlinear;
struct list_head i_mmap头痛;
};
以上代码展示了 address_space 结构体的定义,这是一个核心的数据结构,用于描述文件系统中存储的数据与内核页缓存之间的关系。在进行文件读写操作时, address_space 可以大大减少对磁盘的操作,提高性能。
. . . VFS的权限检查与文件锁定
VFS在处理文件操作请求时,也需要对文件系统进行权限检查和文件锁定,以确保文件操作的正确性和数据的一致性。在Linux中,使用inode结构体中的权限位来标识文件权限。
struct inode {
umode_t i_mode; // 权限模式
uid_t i_uid; // 用户ID
gid_t i_gid; // 组ID
// ...
}
在执行如 open 、 read 、 write 等操作时,内核将根据文件的权限位和用户的有效身份来检查操作是否允许。如果一个文件正被一个进程读取或写入,内核会设置相应的文件锁,防止其他进程干扰。
接下来的内容将是章节“4.3 文件系统的性能优化”下的更深层次的子章节。
. . . 磁盘I/O调度策略的实现
Linux内核提供了多种I/O调度策略来优化不同磁盘的性能。调度策略会根据不同的工作负载来调整对磁盘操作的排序,以此来提高效率。例如,CFQ调度器为每个进程分配时间片,以保证I/O请求的公平性;而Deadline调度器则为读写请求设置了期限,以避免饥饿。
. . . 文件系统缓存的管理
Linux内核通过文件系统缓存来减少对物理存储设备的访问次数,提升性能。内核定期根据缓存页的使用频率、脏页数量等信息来调整缓存的大小。缓存管理的代码示例:
void balance_dirty_pages(struct address_space *mapping, unsigned int pages_dirtied)
{
// 根据内核参数和当前状态计算脏页阈值
int dirtied = dirty_pages(mapping);
int limit = dirty_background_bytes(mapping);
// ...
if (dirtied > limit) {
// 若脏页过多,触发刷盘操作
writeback_inodes(mapping->host->i_sb, WB.schedule | WB_async | WB溅斗);
}
// ...
}
此代码片段展示了在内核中,当检测到脏页超过限制时,触发写回操作的逻辑。 dirty_background_bytes 函数计算得到脏页的背景写入阈值, writeback_inodes 函数则根据这个阈值来启动写回操作。
. . . 文件预读与写回技术
文件系统的预读技术可以显著提高顺序读取的性能。当系统检测到顺序读取模式时,会自动启动预读功能。预读技术通过读取一些额外的数据到缓存来减少文件系统的访问次数。写回技术则负责将缓存的脏页数据写回到存储设备中。预读与写回是通过内核页缓存机制实现的。
#define FILE_PAGES_TO_READahead 128
#define MAX_READAHEADCoefficient 16
static void do_file_readahead(struct file *filp, pgoff_t index, unsigned long nr_pages)
{
struct address_space *mapping = filp->f_mapping;
unsigned long goal, offset;
if (filp->f_mode & FMODE_RANDOM) {
return;
}
goal = rounddown(index + (nr_pages / 2), MAX_READAHEADCoefficient);
if (goal > mapping->nrpages)
goal = mapping->nrpages;
offset = max_t(unsigned long, index, goal - FILE_PAGES_TO_READahead);
// ...
for ( ; offset < goal; offset += MAX_READAHEADCoefficient) {
// 启动预读
add_page_to_page_cache(mapping, offset, GFP_KERNEL);
if (unlikely(break_ion_readahead)) {
break;
}
}
}
该代码段提供了预读的实现逻辑。 do_file_readahead 函数会读取一定数量的页面到缓存中,以提高后续读取操作的性能。当检测到随机读取时,则不会触发预读。
. . . 优化文件系统读写性能的实践经验
在文件系统的使用中,合理配置和优化是提升性能的关键。经验表明,在创建文件系统时选择合适的块大小、文件系统的挂载选项(如noatime)以及确保有足够的内存来缓存文件数据都是提升性能的实践方法。此外,通过调整I/O调度器的参数也可以在特定场景下获得性能提升。
以上完成了从Linux文件系统的基本概念到优化技术的系统性介绍。通过深入理解文件系统的架构,用户和开发者可以更好地利用和优化Linux文件系统,为应用提供更加高效的存储解决方案。
5. 网络协议栈深入
5.1 网络协议栈概述
5.1.1 网络通信的基本原理
网络通信是基于分组交换技术,允许数据在不同设备间传输。在Linux系统中,这一过程通过网络协议栈实现,该协议栈遵循ISO/OSI模型,定义了网络通信的七层结构。
一个数据包在网络中的传输可以分解为以下步骤: 1. 应用层创建数据。 2. 传输层(如TCP或UDP)将数据封装成段或数据报,并处理端到端的可靠传输。 3. 网络层(如IP层)将传输层的数据封装成数据包,并处理网络间的数据传递。 4. 数据链路层(如以太网)将网络层的数据封装成帧,并在物理网络介质上传输。 5. 物理层则负责将帧转换为比特流,并在物理介质中进行传输。
5.1.2 协议栈的层次结构与数据流向
Linux网络协议栈的层次结构清晰,每一层都有明确的任务,数据从上层向下层传递,逐层封装,最终通过物理介质传输。在接收端,数据流向则完全相反,每一层剥去对应的封装信息,最终将数据呈现给应用层。
数据流向的示意图如下所示:
graph TD
A[应用层] --> B[传输层]
B --> C[网络层]
C --> D[数据链路层]
D --> E[物理层]
E --> F[物理介质]
F --> G[物理层]
G --> H[数据链路层]
H --> I[网络层]
I --> J[传输层]
J --> K[应用层]
5.2 核心网络功能的实现
5.2.1 TCP/IP协议族在Linux中的实现
Linux的TCP/IP实现是其网络能力的核心,该实现包括了协议栈的内核模块,负责处理网络通信中的各种协议。其中,IP模块负责数据包的路由和转发,而TCP模块提供可靠的数据流传输。
内核模块如 ip 和 tcp 是核心网络功能的基石,它们被集成在内核中,并提供了一套丰富的接口供用户空间程序调用。
5.2.2 网络设备的驱动与接口
Linux中的网络设备驱动负责硬件与内核之间的通信。每种网络硬件设备都有自己的驱动程序,驱动程序提供了发送和接收数据包的接口。
网络接口(如 eth0 、 wlan0 )是由内核管理和抽象的,允许用户空间通过标准的系统调用来操作网络硬件。例如,使用 ifconfig 命令可以配置和显示网络接口的参数。
5.3 高级网络特性与安全
5.3.1 防火墙与NAT技术
Linux的网络协议栈提供了一些高级网络功能,如防火墙和网络地址转换(NAT)。
防火墙功能通常由 iptables 或 nftables 实现,这些工具允许管理员设置规则来控制进入或离开系统的网络流量。
NAT是将私有网络地址转换为公有地址的过程,这通常在路由器或具有NAT能力的防火墙上完成。Linux系统可以作为路由器使用,它支持源地址转换(SNAT)和目的地址转换(DNAT)。
5.3.2 网络加密与认证机制
为确保数据传输的安全,Linux网络协议栈支持多种加密和认证机制。其中IPsec协议用于加密整个IP通信过程,确保数据的机密性和完整性。
传输层安全(TLS)协议用于加密TCP连接上的数据传输,它广泛用于HTTPS等安全通信。此外,Linux还支持SSH协议,为远程管理提供加密的通信渠道。
Linux网络协议栈的深入分析不仅仅是为了理解其工作原理,而且对于网络性能优化、故障排查和安全增强等任务至关重要。掌握这一部分的知识可以更好地管理和维护复杂的网络环境。
简介:本书《深入理解Linux内核》深入探讨了Linux操作系统的核心工作原理,包括内核的关键概念和技术细节。它旨在帮助读者理解、优化Linux系统,无论语言背景如何。书中覆盖了进程管理、内存管理、文件系统、网络协议栈、设备驱动、中断处理、I/O子系统、安全与权限以及性能分析和调试等多个方面。第三版增加了最新内核内容,而第二版中文版则适合初学者。