数据迁移
一、数据分析
1. Hive数据分析
| 组件 | 数据分层情况 | 库/表数 | 数据量(T) | 备注 |
|---|---|---|---|---|
| hive |
2. Hbase数据分析
| 组件 | 库/表数 | 数据量(T) | 备注 |
|---|---|---|---|
| hive |
3. Kudu数据分析
二、数据迁移设
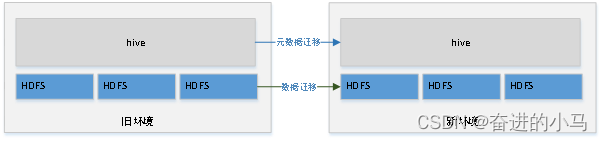
1. Hive数据迁移设计
使用自带命令工具进行迁
使用第三方迁移工具
2. Hbase数据迁移设计
使用自带命令工具迁移
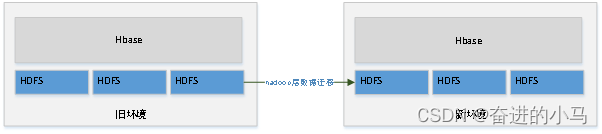
Hadoop层数据迁移
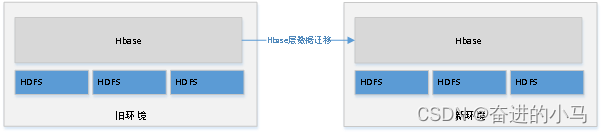
Hbas层数据迁移
使用第三方迁移工具
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2xezVuWv-1656582221192)(file:///C:\Users\Administrator\AppData\Local\Temp\ksohtml7316\wps11.png)]](/image/aHR0cHM6Ly9pbWctYmxvZy5jc2RuaW1nLmNuLzc2OWVmNmZkNmVkMDRlNTI4NDA0ODBlODA3YWVjOWMzLnBuZw%3D%3D)
3. Kudu数据迁移设
3.1. 基于impala迁移设计部
3.2. 离线迁移设计
三、数据迁移实
1. Hive数据迁移
1.1. Hive元数据迁移
1.1.1. Import方式迁移
说明:将hive数据中的表元数据导出,推荐使用这种方式
#!/bin/bash
1=“database”
# import是针对表的mingl,所以这里创建存储表数据和元数据的hdfs文件夹
mkHdfsDir(){
hdfs dfs -test -e /test/$1/$2
if [ $? -eq 0 ] ;then
hdfs dfs -rm -r -f /test/$1/$2
hdfs dfs -mkdir -p /test/$1/$2
else
hdfs dfs -mkdir /test/$1/$2
fi
}
# 打印对应的datbase所有表
hive -e "use $1;show tables;" > $1.txt
#打印出来的第一行是 table_name,要进行删除
sed -i '1d' $1.txt
# 遍历所有的表,export数据,这里的$1是你要导出的database
cat $1.txt | while read line
do
mkHdfsDir $1 $line
echo "---------------------- export db $1 table $line ------------------------"
hive -e "use $1; export table $line to '/test/$1/$line';"
done
-->取出库中的所有表
-->在HDFS上创建存放数据库表元信息的目录
-->将hive数据库中表元数据信息导出到创建的目录中
1.1.2. Sql方式迁移
-->导出数据库表元信息
#!/bin/bash
# 打印database下面的表
hive -e "use $1;show tables;" > $1.txt
sed -i '1d' $1.txt
# 遍历表,获取他们的ddl语句
cat tables.txt |while read line
do
hive -e "use $1;show create table $line" >> create_tables.txt
echo ";" >> tablesDDL.txt
done
-->在新环境中执行创建表结构
hive -f create_tables.txt
-->验证新环境的表结构
1.2. Hive全量数据迁移
1.2.1. Hadoop distcp迁移
前置要求
1、新环境和就环境的网络互通
2、新环境和旧环境的ip不能相同
hadoop distcp -skipcrccheck -update hdfs://<旧ip>:9000/database hdfs://<新ip>:9000:/databse
参数说明:
-->-skipcrccheck 省略crc检查,如果hadoop版本一样,可以不加,如果低版本向高版本迁移的话,最好带
-->-update 增量更新,通过文件名称,大小比较,源文件和目标文件不同则更新
1.2.2. 本地迁移
#将hive的数据get到本地
hdfs dfs -get /databes /dir
# 压缩减少传输
tar -zcvf /test test.tar.gz
#将数据包传输到新环境
#解压
tar -zxvf test.tar.gz -C /database
# 上传到目标hadoop集群
hdfs dfs -put /dataase/test
1.3. 元数据和数据关联
1.3.1. 基于sql元数据迁移
| 数据迁移方式 | 说明 | 操作 |
|---|---|---|
| Hadoop distcp | 这里注意表的目录和文件的目录要和之前的集群保持一致,然后使用 msck方式分区修复 | # 表会自动的扫描对应文件夹里面的数据,将其写到元数据里面,产生关联msck repair table |
| export | 使用import的方式,会把数据加载到创建表的文件夹里面,自动的产生关联 | use test;import table 表名 from /test/; |
1.3.2. 基于import元数据迁移
| 数据迁移方式 | 说明 | 操作 |
|---|---|---|
| export | 使用import恢复数据,比较推荐的是这一种 | #!/bin/bash1=”database”# 遍历所有的表,import数据cat $1.txt | while read linedo echo “---------------------- import db $1 table $line ------------------------” hive -e "use $1;import table l i n e f r o m ′ / t e s t / d e f a u l t / line from '/test/default/ linefrom′/test/default/line’;"done |
1.4 推荐迁移方
元数据迁移 import方式迁移
数据迁移 依据实际业务
元数据和数据关联 Import数据关联
1.5. 迁移流程
2. Hbase数据迁
目前的方案主要有四类,Hadoop层有一类,HBase层有三类。
2.1. Hadoop层数据
Hadoop层的数据迁移主要用到DistCp(Distributed Copy),官方描述是:DistCp(分布式拷贝)是用于大规模集群内部和集群之间拷贝的工具。它使用Map/Reduce实现文件分发,错误处理和恢复,以及报告生成。它把文件和目录的列表作为map任务的输入,每个任务会完成源列表中部分文件的拷贝
参考命令
hadoop distcp \
-Dmapreduce.job.name=distcphbase \
-Dyarn.resourcemanager.webapp.address=mr-master-ip:8088 \
-Dyarn.resourcemanager.resource-tracker.address=mr-master-dns:8093 \
-Dyarn.resourcemanager.scheduler.address=mr-master-dns:8091 \
-Dyarn.resourcemanager.address=mr-master-dns:8090 \
-Dmapreduce.jobhistory.done-dir=/history/done/ \
-Dmapreduce.jobhistory.intermediate-done-dir=/history/log/ \
-Dfs.defaultFS=hdfs://hbase-fs/ \
-Dfs.default.name=hdfs://hbase-fs/ \
-bandwidth 20 \
-m 20 \
hdfs://src-hadoop-address:9000/region-hdfs-path \
hdfs://dst-hadoop-address:9000/tmp/region-hdfs-path
参数说明
-m参数来设定要跑的map数量,默认设置是20
-bandwitdh考虑带宽问题,所以在跑任务时还需要设定
约束条件
源端集群到目的端集群策略是通的,同时hadoop/hbase版本也要注意是否一致,如果版本不一致,最终load表时会报错。
实施步骤
1、第一步,如果是迁移实时写的表,最好是停止集群对表的写入,迁移历史表的话就不用了,此处举例表名为test
2、flush表, 打开HBase Shell客户端,执行如下命令
hbase> flush 'test'
3、拷贝表文件到目的路径,检查源集群到目标集群策略、版本等,确认没问题后,执行如上带MR参数的命令
4、检查目标集群表是否存在,如果不存在需要创建与原集群相同的表结构
5、在目标集群上,Load表到线上,在官方Load是执行如下命令
hbase org.jruby.Main add_table.rb /hbase/data/default/test
#建议使用
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles -Dhbase.mapreduce.bulkload.max.hfiles.perRegion.perFamily=1024 hdfs://dst-hadoop-address:9000/tmp/region-hdfs-path/region-name table_ame
参数说明:hbase.mapreduce.bulkload.max.hfiles.perRegion.perFamily, 这个表示在bulkload过程中,每个region列族的HFile数的上限,这里我们是限定了1024,也可以指定更少,根据实际需求来定。
6、检查表数据是否OK,看bulkload过程是否有报错
2.2. Hbase层数据迁
2.2.1. copyTable方式
copyTable也是属于HBase数据迁移的工具之一,以表级别进行数据迁移。copyTable的本质也是利用MapReduce进行同步的,与DistCp不同的时,它是利用MR去scan 原表的数据,然后把scan出来的数据写入到目标集群的表。这种方式也有很多局限,如一个表数据量达到T级,同时又在读写的情况下,全量scan表无疑会对集群性能造成影响。
- copyTable支持的场景
-
表深度拷贝
相当于一个快照,不过这个快照是包含原表实际数据的,0.94.x版本之前是不支持snapshot快照命令的,所以用copyTable相当于可以实现对原表的拷贝
create 'table_snapshot',{NAME=>"i"}
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=tableCopy table_snapshot
-
集群间拷贝
在集群之间以表维度同步一个表数据
create 'table_test',{NAME=>"i"} #目的集群上先创建一个与原表结构相同的表
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --peer.adr=zk-addr1,zk-addr2,zk-addr3:2181:/hbase table_test
-
增量备份
增量备份表数据,参数中支持timeRange,指定要备份的时间范围
hbase org.apache.hadoop.hbase.mapreduce.CopyTable ... --starttime=start_timestamp --endtime=end_timestamp
-
部分表备份
只备份其中某几个列族数据,比如一个表有很多列族,但我只想备份其中几个列族数据,CopyTable提供了families参数,同时还提供了copy列族到新列族形式
hbase org.apache.hadoop.hbase.mapreduce.CopyTable ... --families=srcCf1,srcCf2 #copy cf1,cf2两个列族,不改变列族名字
hbase org.apache.hadoop.hbase.mapreduce.CopyTable ... --families=srcCf1:dstCf1, srcCf2:dstCf2 #copy srcCf1到目标dstCf1新列族
约束条件
CopyTable支持的范围还是很多的,但因其涉及的是直接HBase层数据的拷贝,所以效率上会很低,同样需要在使用过程中限定扫描原表的速度和传输的带宽,这个工具实际上使用比较少,因为很难控制
2.2.2. Export/Import方式
此方式与CopyTable类似,主要是将HBase表数据转换成Sequence File并dump到HDFS,也涉及Scan表数据,与CopyTable相比,还多支持不同版本数据的拷贝,同时它拷贝时不是将HBase数据直接Put到目标集群表,而是先转换成文件,把文件同步到目标集群后再通过Import到线上表。主要有两个阶段
Export阶
将原集群表数据Scan并转换成Sequence File到Hdfs上,因Export也是依赖于MR的,如果用到独立的MR集群的话,只要保证在MR集群上关于HBase的配置和原集群一样且能和原集群策略打通(master®ionserver策略),就可直接用Export命令,如果没有独立MR集群,则只能在HBase集群上开MR,若需要同步多个版本数据,可以指定versions参数,否则默认同步最新版本的数据,还可以指定数据起始结束时间
# output_hdfs_path可以直接是目标集群的hdfs路径,也可以是原集群的HDFS路径,如果需要指定版本号,起始结束时间
hbase org.apache.hadoop.hbase.mapreduce.Export <tableName> <ouput_hdfs_path> <versions> <starttime> <endtime>
Import阶段
将原集群Export出的SequenceFile导到目标集群对应表
#如果原数据是存在原集群HDFS,此处input_hdfs_path可以是原集群的HDFS路径,如果原数据存在目标集群HDFS,则为目标集群的HDFS路径
hbase org.apache.hadoop.hbase.mapreduce.Import <tableName> <input_hdfs_pa>
2.2.3. Snapshot方式
说明:建议使用这种方式进行数据迁移
此方式与上面几中方式有所区别,也是目前用得比较多的方案,snapshot字面意思即快照,snapshot的应用场景和上面CopyTable描述差不多,我们这里主要考虑的是数据迁移部分。数据迁移主要有以下几个步骤
创建快照
在原集群上,用snapshot命令创建快照
hbase> snapshot 'src_table', 'snapshot_src_table'
#查看创建的快照,可用list_snapshots命令
hbase> list_snapshots
#如果快照创建有问题,可以先删除,用delete_snapshot命令
hbase >delete_snapshot 'snapshot_src_table'
#可能用到的clone表
hbase> clone_snapshot 'snapshot_src_table' , 'new_te_name'
数据迁移
在上面创建好快照后,使用ExportSnapshot命令进行数据迁移,ExportSnapshot也是HDFS层的操作,本质还是利用MR进行迁移,这个过程主要涉及IO操作并消耗网络带宽,在迁移时要指定下map数和带宽,不然容易造成机房其它业务问题,如果是单独的MR集群。
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \
-snapshot snapshot_src_table \
-copy-from hdfs://src-hbase-root-dir/hbase \
-copy-to hdfs://dst-hbase-root-dir/hbase \
-mappers 20 \
-bandwith 20
其他说明
上面这些流程网上很多资料都有提到,对于我们业务来说,还有一种场景是要同步的表是正在实时写的,虽然用上面的也可以解决,但考虑到我们表数据规模很大,几十个T级别,同时又有实时业务在查的情况下,直接在原表上就算只是拷贝HFile,也会影响原集群机器性能,由于我们机器性能IO/内存方面本身就比较差,很容易导致机器异常,所以我们采用的其它一种方案,流程图如下。
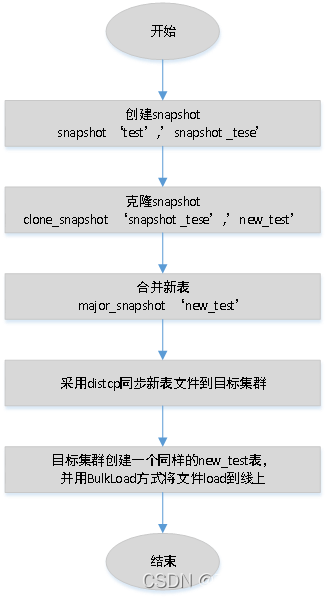
主要考虑的是直接对原表snapshot进行Export会影响集群性能,所以采用折中的方案,即先把老表clone成一个新表,再对新表进行迁移,这样可以避免直接对原表操作
2.2.4. 数据迁移方式对比
| 迁移方式 | 说明 |
|---|---|
| DistCp | 文件层的数据同步,也是我们常用的 |
| CopyTable | 这个涉及对原表数据Scan,然后直接Put到目标表,效率较低 |
| Export/Import | 类似CopyTable, Scan出数据放到文件,再把文件传输到目标集群作Import |
| Snapshot | 比较常用 , 应用灵活,采用快照技术,效率比较高 |
2.3 推荐迁移方式
Hbase数据迁移 Snapshot