2023年第十三届MathorCup高校数学建模挑战赛
A题 量子计算机在信用评分卡组合优化中的应用
原题再现:
在银行信用卡或相关的贷款等业务中,对客户授信之前,需要先通过各种审核规则对客户的信用等级进行评定,通过评定后的客户才能获得信用或贷款资格。规则审核过程实际是经过一重或者多重组合规则后对客户进行打分,这些规则就被称为信用评分卡,每个信用评分卡又有多种阈值设置(但且只有一个阈值生效),这就使得不同的信用评分卡在不同的阈值下,对应不同的通过率和坏账率,一般通过率越高,坏账率也会越高,反之,通过率越低,坏账率也越低。
对银行来说,通过率越高,通过贷款资格审核的客户数量就越多,相应的银行获得的利息收入就会越多,但高通过率一般对应着高坏账率,而坏账意味着资金的损失风险,因此银行最终的收入可以定义为: 最终收入 = 贷款利息收入 - 坏账损失
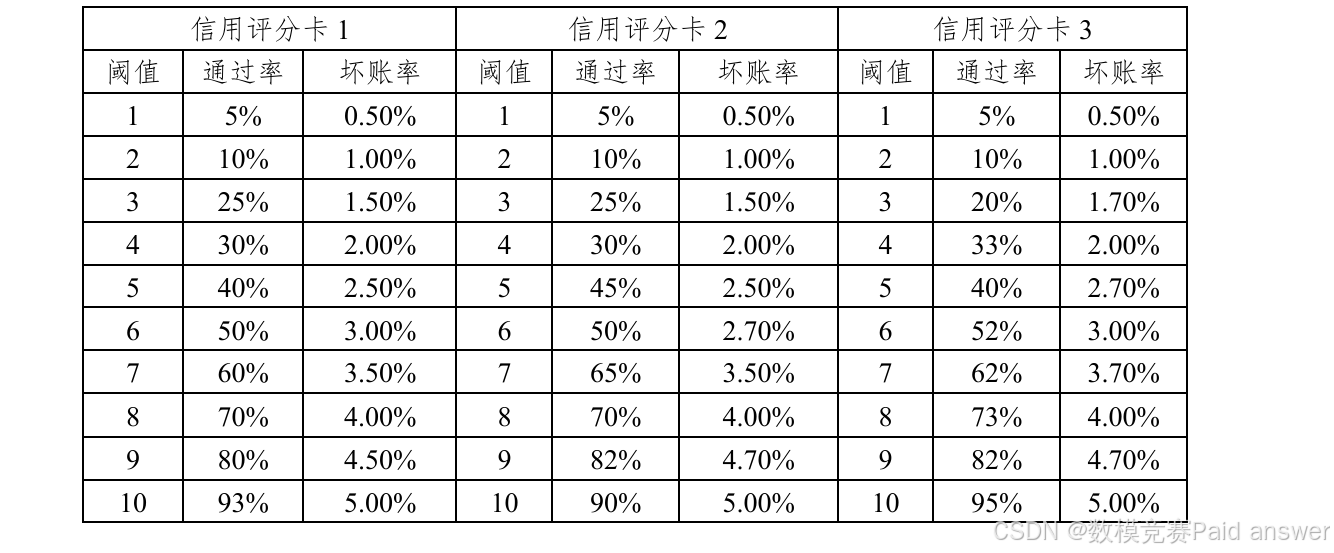
下表举例3个不同的信用评分卡,可以看到每种信用评分卡有10个阈值,每种阈值对应不同的坏账率和通过率:
赛题说明1:流程简化及示例
由于银行场景的复杂性,往往需要采用选择多个不同的信用评分卡进行组合来实现最佳的风险控制策略。而实际中的信用评分卡组合是一个非常复杂的过程,为便于建模,我们将该问题进行做如下简化(本简化只适用本次比赛赛题,不能完全代表实际场景)。
假设贷款资金为1000000元,银行贷款利息收入率为8%,并以上面列举的三个信用评分卡作为选定的信用评分卡组合来测算银行最终收入。
由于每一信用评分卡有且只可选择1个阈值,假设信用评分卡1的阈值设置为8,则通过表格可知,对应通过率为70%,坏账率为4.00%,信用评分卡2的阈值设置为6,则通过率为 50%,坏账率为 2.70%,信用评分卡3 的阈值设置为7,则通过率为62%,坏账率为3.70%。
例如如果我们选择三重信用卡组合策略,那么这三种信用评分卡组合后的总通过率为所有信用评分卡通过率相乘,即: 0.7×0.5×0.62 = 0.217
总坏账率为三种信用评分卡对应坏账率的平均值,即: 1/3×(0.04+0.027+0.037) = 0.0367
基于以上条件可求得,本次贷款利息收入为: 贷款资金×利息收入率×总通过率×(1-总坏账率),即:1000000×0.08×(0.7×0.5×0.62) ×(1-1/3×(0.04+0.027+0.037)) = 16758.18(元)
由坏账带来的坏账损失为: 贷款资金×总通过率×总坏账率,即:1000000×(0.7×0.5×0.62) ×(1/3×(0.04+0.027+0.037))=7522.666(元)
那么银行的最终收入为: 贷款利息收入-坏账损失,即 16758.18-7522.666 = 9235.514 (元)
由此可见,选择不同的信用评分卡,不同的阈值组合,会给银行带来不同的收入与损失,由此决定银行最终收入。因此,银行的目标是选择最合理的信用评分卡组合以及其阈值,使得银行最终收入最多。
赛题说明2:QUBO模型简介
QUBO模型是指二次无约束二值优化(Quadratic Unconstrained Binary Optimization)模 型 ,它 是 一 种 用 于 解 决 组 合 优 化 问 题 的 数 学 模 型 。 在QUBO模型中,需要将问题转化为一个决策变量为二值变量,目标函数是一个二次函数形式优化模型。
QUBO 模型可以运行在量子计算机硬件上,通过量子计算机进行毫秒
级的加速求解。这种模型和加速方式在未来各行业中将得到广泛的实际应用。因此现阶段研究基于QUBO模型的量子专用算法十分有应用价值。例如典型的图着色、旅行商问题、车辆路径优化问题等,都可以转化为QUBO模型并借助于量子计算机求解。
相关的QUBO的转化方法与例子可参考附件2中的参考文献。
赛题说明3:赛题数据
附件1中共包含100张信用评分卡,每张卡可设置10种阈值之一,并对应各自的通过率与坏账率共200列,其中t_1代表信用评分卡1的通过率共10项,h_1代表信用评分卡1的坏账率共10项,依次类推t_100代表信用评分卡100的通过率,h_100代表信用评分卡100的坏账率。
根据上面的赛题说明及附件1中的数据,请你们团队通过建立数学模型完成如下问题1至问题3。
问题1:在100 个信用评分卡中找出1张及其对应阈值,使最终收入最多,请针对该问题进行建模,将该模型转为QUBO形式并求解。
问题2:假 设 赛 题 说 明 3目前已经选定了数据集中给出的信用评分卡1、信用评分卡 2、信用评分卡 3 这三种规则,如何设置其对应的阈值,使最终收入最多,请针对该问题进行建模,将模型转为QUBO形式并求解。
问题3:从所给附录中100个信用评分卡中任选取3种信用评分卡,
并设置合理的阈值,使得最终收入最多,请针对该问题进行建模,并将模型转为QUBO形式并求解。
整体求解过程概述(摘要)
本文基于银行信用评分卡的组合优化背景与题中提供的信用卡典型数据,基于QUBO模型研究了信用评分卡组合优化的问题。首先,针对不同问题分别构建以最大化最终收入为目标的组合优化模型。其次,根据不同目标函数形式,通过换元降幂等数学技巧进行变换,转化为QUBO形式,并运用量子退火算法求解出使得最终收入最大时的信用评分卡组合。最后,本文运用简单随机抽样法、贪心算法、遗传算法对量子退火算法的结果进行对比检验分析,凸显量子退火算法优越性并总结不同算法优劣及适用场景。
针对问题一:首先,将问题转化为从1000 张具有唯一阈值的信用评分卡中选择一张的形式。其次,构建以最大化最终收入为目标的组合优化模型,并将其转化为QUBO形式,并运用量子退火算法进行求解。计算得出,当选择第49张信用评分卡的第1个阈值时,最终收入最大,为61172.0,对应通过率和坏账率分别为0.82和0.005。最后,通过简单随机抽样进行结果检验,确保所求信用评分卡阈值组合可以使最终总收入最大。
针对问题二:首先,构建以最大化最终收入为目标的组合优化模型,由于目标函数最高次幂大于2,运用两次换元降幂的技巧对模型进行处理,最终将模型转化为QUBO形式,并运用量子退火算法进行求解。计算得出,最佳信用评分卡组合为:第一张信用评分卡的第8个阈值,第二张信用评分卡的第1个阈值,第三张信用评分卡的第2个阈值,最大收入为27914.82。最后,通过贪心算法对结果进行检验,结果表明量子退火算法结果优于贪心算法,确保了QUBO模型结果可信度。
针对问题三:首先,构建以最大化最终收入为目标的组合优化模型,由于目标函数最高次幂大于2,运用两次换元降幂的技巧对模型进行处理,最终将模型转化为QUBO形式,由于问题复杂度过高,本文借助 Kaggle 平台云服务,运用量子退火算法进行求解。计算得出,最佳信用评分卡组合为:第8张信用评分卡的第2个阈值,第33张信用评分卡的第6个阈值,第49张信用评分卡的第3个阈值,最大收入为43880.97。最后,通过贪心算法和遗传算法对结果进行检验,结果表明量子退火算法效果最佳、遗传算法次之、贪心算法较差,有力确保了QUBO模型结果可信度。另外本文还总结了三种算法的优劣及使用场景。
模型假设:
(1)赛题提供的数据来源于权威的原始数据,并且这些数据都是真实可靠的。
(2)每个问题之间的信息相互独立,没有必然的联系。
(3)每个问题的最终收入、贷款利息收入、坏账损失的计算方式依据赛题信息进行计算,不考虑赛题之外的信息,不考虑特殊情况的发生。
(4)每一个问题的贷款资金为1000000元,银行贷款利息收入率为8%。
问题分析:
本题可以看作一个二次无约束二值优化问题,问题的关键点在于将问题的公式转化为QUBO(Quadratic Unconstrained Binary Optimization)形式来求解,即目标函数应当是一个最高次为二次,决策变量为0-1型变量的多项式公式。问题一、问题二、问题三依次要求从100个信用评分卡中找出特定数量的信用评分卡并确定其阈值,使得最终总收入最大。本文通过问题转化,根据问题信息设置决策变量等方式构建QUBO公式,运用量子退火算法等对问题进行求解检验。
问题一分析
对于问题一,题目要求从100个信用评分卡中找出1张及其对应阈值,使得最终总收入最多。首先,将问题等价转化为从 1000 张信用评分卡(每一张信用评分卡只有一个阈值)中找出一张信用卡。其次,针对转化后的问题建立QUBO等式,并运用量子退火算法进行求解。最后,针对求解出的结果运用简单随机抽样进行对比检验。
问题二分析
对于问题二,要求从题中所给信用评分卡1、信用评分卡2、信用评分卡3这三种规则,分别设置对应阈值,使得最终总收入最多。首先对问题进行数学刻画,将问题二中每一张信用卡的某一个阈值是否会被采样用二元决策变量𝑥𝑙𝑖表示,其中𝑙表示所选择的信用卡序号,𝑙∈[1,3],其中𝑖表示对应信用卡所选择的阈值,𝑖∈[1,10]。其次,由于目标函数中最高次幂大于2,对目标函数进行两次换元降幂处理后建立QUBO等式,并运用量子退火算法进行求解。最后,针对求解出的结果运用贪心算法进行对比分析。
问题三分析
对于问题三,题目要求从100张信用评分卡中分别选择三张信用评分卡及其对应阈值,使得最终总收入最多。首先对问题进行数学刻画,将问题三中每一张信用卡的某一个阈值是否会被采样用二元决策变量𝑥𝑙𝑖表示,其中𝑙表示所选择的信用卡序号,𝑙∈ [1,100],其中𝑖表示对应信用卡所选择的阈值,𝑖∈[1,10]。其次,由于目标函数中最高次幂仍大于2,对目标函数进行两次换元处理后建立QUBO等式,并运用量子退火算法进行求解。最后,针对求解出的结果运用贪心算法、遗传算法进行对比分析。
模型的建立与求解整体论文缩略图


全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
程序代码:
1. # coding=gb
2. import pandas as pd
3. import neal
4. from pyqubo import Binary, Constraint, Placeholder, Array, OneHotEncInteger
5. def load_data_100():
6. list1 = []
7. list2 = []
8. for i in range(0, 200):
9. if i % 2 == 0:
10. list1.append(i)
11. list2.append(i)
12. pass_rate_list = []
13. bad_rate_list = []
14. namelist = []
15. df = pd.read_csv("data_100.csv")
16. for index, col in df.iteritems():
17. namelist.append(index)
18. for a in list1:
19. rows = df[namelist[a]].tolist()
20. pass_rate_list.extend(rows)
21. for b in list2:
22. rows = df[namelist[b]].tolist()
23. bad_rate_list.extend(rows)
24. print("信用卡的通过率为:", pass_rate_list)
25. print("信用卡的坏账率为:", bad_rate_list)
26. return pass_rate_list, bad_rate_list
27. pass_rate_list, bad_rate_list = load_data_100()
28.
29. # 加载信用卡的通过率和坏账率,把100个信用卡转化为1000个信用卡
30. pass_weights = pass_rate_list
31. values = bad_rate_list
32.
33. # 创建决策变量Xi,一共有n个决策变量,n=1000
34. n = len(values)
35. items = Array.create('item', shape=n, vartype="BINARY")
36.
37. # 构建通过率和坏账率两部分的因式
38. pass_weight = sum(pass_weights[i] * items[i] for i in range(n))
39. bad_weight = sum(values[i] * items[i] for i in range(n))
40. constraint_weight = 1 - sum(items[i] for i in range(n))
41.
42. # 定义惩罚函数
43. lmd2 = Placeholder("lmd2")
44. Ha = Constraint((constraint_weight) ** 2, "weight_constraint")
45. Hb = -1080000 * bad_weight * pass_weight + 80000 * pass_weight
46. H = -Hb + lmd2 * Ha
47. model = H.compile()
48. sampler = neal.SimulatedAnnealingSampler()
49. feasible_sols = []
50.
51. # 设置惩罚函数,惩罚函数尽量设置大
52. feed_dict = {"lmd2": 1000000000000000000}
53. qubo, offset = model.to_qubo(feed_dict=feed_dict)
54. bqm = model.to_bqm(feed_dict=feed_dict)
55. bqm.normalize()
56. sampleset = sampler.sample(bqm, num_reads=1000, sweeps=1000, beta_range=(1.
0, 50.0))
57. # 采样的集,每一次采样的结果函数值都为energy,然后存在dec_sample中
58. dec_samples = model.decode_sampleset(sampleset, feed_dict=feed_dict)
59. # 选择所有采样值中最小的那一个,即为最优值
60. best = min(dec_samples, key=lambda x: x.energy)
61.
62. # 判断每一次迭代的结果是否满足约束条件
63. if not best.constraints(only_broken=True):
64. feasible_sols.append(best)
65.
66. # 获得最小值
67. best_feasible = min(feasible_sols, key=lambda x: x.energy)
68. print(f"selection = {[best_feasible.sample[f'item[{i}]'] for i in range(n)]
}")
69. print(f"sum of the values = {-best_feasible.energy}")
1. # coding=gbk
2. import math
3. import numpy as np
4. import pandas as pd
5. import neal
6. from pyqubo import Binary, Constraint, Placeholder, Array, OneHotEncInteger
7.
8. # 转化为数据,将提供的坏账率和通过率由一维数组转化为二维数组
9. def reload_data(inputlist):
10. outputlist = [[0 for x in range(10)] for y in range(3)]
11. for i in range(3):
12. for j in range(10):
13. outputlist[i][j] = inputlist[i * 10 + j]
14. return outputlist
15. def load_data_100_2():
16. list1 = []
17. list2 = []
18. for i in range(0, 6):
19. if i % 2 == 0:
20. list1.append(i)
21. else:
22. list2.append(i)
23. pass_rate_list = []
24. bad_rate_list = []
25. namelist = []
26. df = pd.read_csv("data_100.csv")
27. for index, col in df.iteritems():
28. namelist.append(index)
29. for a in list1:
30. rows = df[namelist[a]].tolist()
31. pass_rate_list.extend(rows)
32. for b in list2:
33. rows = df[namelist[b]].tolist()
34. bad_rate_list.extend(rows)
35. print("信用卡的通过率为:", pass_rate_list)
36. print("信用卡的坏账率为:", bad_rate_list)
37. return pass_rate_list, bad_rate_list
38. pass_rate_list, bad_rate_list = load_data_100_2()
39.
40. # 加载信用卡的通过率和坏账率,把100个信用卡转化为1000个信用卡
41. pass_weights = reload_data(pass_rate_list)
42. values = reload_data(bad_rate_list)
43.
44. # 创建决策变量Xi,一共有n个决策变量,n=shape=100*10
45. items_X1 = Array.create('items_X1', shape=10, vartype="BINARY")
46. items_X2 = Array.create('items_X2', shape=10, vartype="BINARY")
47. items_X3 = Array.create('items_X3', shape=10, vartype="BINARY")
48. items_Y = Array.create('items_Y', shape=(10, 10), vartype="BINARY")
49. items_T = Array.create('items_T', shape=(10, 10, 10), vartype="BINARY")
50.
51. # 构建通过率和坏账率两部分的因式
52. pass_weight = sum(pass_weights[0][i]*pass_weights[1][j]*pass_weights[2][z]*
items_T[i][j][z] for i in range(10) for j in range(10) for z in range(10))
53. bad_weight = sum(values[0][i] * items_X1[i] for i in range(10))+ sum(values [1][j] * items_X2[j] for j in range(10)) + sum(values[2][z] * items_X3[z] f or z in range(10))
54.
55. # 构建约束条件
56. constraint_weight1 = 1 - sum(items_X1[i] for i in range(10))
57. constraint_weight2 = 1 - sum(items_X2[i] for i in range(10))
58. constraint_weight3 = 1 - sum(items_X3[i] for i in range(10))
59.
60. # 定义惩罚因子
61. alpha = 1000000000000000000
62. beta = 1000000000000000000
63. constraint_weight_alpha = alpha * sum(
64. items_X1[i] * items_X2[j] - 2 * items_Y[i][j] * (items_X1[i] + items_X2
[j]) + 3 *items_Y[i][j] for i in range(10) for j in range(10))
65. constraint_weight3_beta = beta * sum(
66. items_X3[z] * items_Y[i][j] - 2 * items_T[i][j][z] * (items_X3[z] + ite
ms_Y[i][j]) + 3 *items_T[i][j][z] for i in range(10) for j in range(10) for
z in range(10))
67.
68. # 定义惩罚函数
69. lmd1 = Placeholder("lmd1")
70. lmd2 = Placeholder("lmd2")
71. lmd3 = Placeholder("lmd3")
72. Halpha = Constraint(constraint_weight_alpha , "weight_constraint_alpha")
73. Hbeta = Constraint(constraint_weight3_beta, "weight_constraint_beta")
74. Ha = 360000 * bad_weight * pass_weight - 80000 * pass_weight
75. H1 = Constraint(constraint_weight1 ** 2, "weight_constraint1")
76. H2 = Constraint(constraint_weight2 ** 2, "weight_constraint2")
77. H3 = Constraint(constraint_weight3 ** 2, "weight_constraint3")
78. H = Ha + lmd1 * H1 + lmd2 * H2 + lmd3 * H3+ Halpha + Hbeta
79. model = H.compile()
80. sampler = neal.SimulatedAnnealingSampler()
81. feasible_sols = []
82.
83. # 设置惩罚函数,惩罚函数尽量设置大
84. feed_dict = {"lmd1": 1000000000000000000, "lmd2": 1000000000000000000, "lmd
3": 1000000000000000000}
85. qubo, offset = model.to_qubo(feed_dict=feed_dict)
86. bqm = model.to_bqm(feed_dict=feed_dict)
87. bqm.normalize()
88. sampleset = sampler.sample(bqm, num_reads=1000, sweeps=1000, beta_range=(1.
0, 50.0))
89.
90. # 采样的集,每一次采样的结果函数值都为energy,然后存在dec_sample中
91. dec_samples = model.decode_sampleset(sampleset, feed_dict=feed_dict)
92.
93. # 选择所有采样值中最小的那一个,即为最优值
94. best = min(dec_samples, key=lambda x: x.energy)
95.
96. # 判断每一次迭代的结果是否满足约束条件
97. if not best.constraints(only_broken=True):
98. feasible_sols.append(best)
99.
100. # 获得最小值
101. best_feasible = min(feasible_sols, key=lambda x: x.energy)
102. print(f"selection = {[best_feasible.sample[f'items_X1[{i}]'] for i in r
ange(10)]}")
103. print(f"selection = {[best_feasible.sample[f'items_X2[{i}]'] for i in r
ange(10)]}")
104. print(f"selection = {[best_feasible.sample[f'items_X3[{i}]'] for i in r
ange(10)]}")
105. print(f"selection = {[best_feasible.sample[f'items_Y[{i}][{j}]'] for i
in range(10) for j in range(10)]}")
106. print(f"selection = {[best_feasible.sample[f'items_T[{i}][{j}][{z}]'] fo
r i in range(10) for j in range(10) for z in range(10)]}")
107. print(f"sum of the values = {-best_feasible.energy}")