Elastic-Job
一、What is elastic-job?
Elastic-Job是当当网推出的分布式任务调度框架,用于解决分布式任务的协调调度问题,保证任务不重复不遗漏地执行;
在我们的项目开发中,使用定时任务是避免不了的,我们在部署定时任务时,通常只部署一台机器,如果部署多台机器时,同一个任务会执行多次,比如给用户计算收益定时任务,每天定时给用户计算收益,如果部署了多台,同一个用户将重复计算多次收益(业务错误),但如果只部署一台机器,可用性又无法保证,如果定时任务机器宕机,无法故障转移;
Elastic-Job是当当网在2015年开源的基于Zookepper、Quartz开发的Java分布式定时任务解决方案,它由两个相互独立的子项目Elastic-Job-Lite和Elastic-Job-Cloud组成;
ElasticJob已于 2020 年 5 月 28 日成为 Apache ShardingSphere 的子项目;
Elastic-Job-Lite
定位为轻量级无中心化任务调度解决方案,使用jar包的形式提供分布式任务的协调服务,Elastic-Job-Lite 为纯粹的作业中间件,仅关注分布式调度、协调以及分片等核心功能;
Elastic-Job-Cloud
采用自研 Mesos Framework 的解决方案,额外提供资源治理、应用分发以及进程隔离等功能,Mesos 是apache下开源的分布式集群管理软件:
https://mesos.apache.org/
官网地址:https://shardingsphere.apache.org/elasticjob/
项目的开源地址:
https://github.com/apache/shardingsphere-elasticjob
Elastic-job开发环境要求
目前elastic-job最新稳定版本为2.1.5 (2017年),目前3.0版本还只发布3.0.0-alpha;
1、使用 JDK 1.8 及其以上版本;
2、Zookeeper 请使用 Zookeeper 3.6.0 及其以上版本;
Elastic-Job 需要依赖 Zookeeper 中间件,用于注册和协调作业分布式行为的组件,目前仅支持 Zookeeper;
3、Mesos(仅 ElasticJob-Cloud 使用)
请使用 Mesos 1.1.0 及其兼容版本;
Elastic-Job配置开发
ElasticJob
ElasticJob-UI
Elastic-Job 提供了3种配置方式启动分布式任务调度;
(1)Java Code配置方式;(纯Java开发,main方法执行)
(2)Spring命名空间配置方式;
(3)Springboot开发;
1、 使用Java配置方式启动
- 1、添加依赖
<!-- elasticjob-lite-core -->
<dependency>
<groupId>org.apache.shardingsphere.elasticjob</groupId>
<artifactId>elasticjob-lite-core</artifactId>
<version>3.0.0-alpha</version>
</dependency>
- 2、任务开发
(1)public class JavaSimpleJob implements SimpleJob
@Override
(2)public void execute(final ShardingContext shardingContext)
(3)看例子代码,基本上模版式的代码;
2、使用Spring配置方式启动
1、添加依赖
<!-- elasticjob-lite-core -->
<dependency>
<groupId>org.apache.shardingsphere.elasticjob</groupId>
<artifactId>elasticjob-lite-core</artifactId>
<version>3.0.0-alpha</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.2.7.RELEASE</version>
</dependency>
2、任务开发
和使用Java配置中作业开发一样;
3、任务配置
通过spring.xml进行配置;
4、启动任务
将配置Spring命名空间的xml通过Spring启动,任务将自动加载;
public static void main(String[] args) {
new ClassPathXmlApplicationContext(“classpath:applicationContext.xml”);
}
Elastic-Job的作业开发配置
Elastic-Job 提供了3种作业类型:
Simple类型作业
Simple类型即为简单实现,未经任何封装的类型,需实现SimpleJob接口,该接口仅提供单一方法用于覆盖,此方法将定时执行,与Quartz原生接口相似,但提供了弹性扩缩容和分片等功能;
DataFlow类型作业
Dataflow类型用于处理数据流,需实现DataflowJob接口,该接口提供2个方法可供覆盖,分别用于抓取(fetchData)和处理(processData)数据;
可通过DataflowJobConfiguration配置是否流式处理。
流式处理数据只有fetchData方法的返回值为null或集合长度为空时,作业才停止抓取,否则作业将一直运行下去; 非流式处理数据则只会在每次作业执行过程中执行一次fetchData方法和processData方法,随即完成本次作业。
如果采用流式作业处理方式,建议processData处理数据后更新其状态,避免fetchData再次抓取到,从而使得作业永不停止,适用于不间歇的数据处理。
Script类型作业
Script类型作业意为脚本类型作业,支持shell,python,perl等所有类型脚本。只需通过控制台或代码配置scriptCommandLine即可,无需编码。执行脚本路径可包含参数,参数传递完毕后,作业框架会自动追加最后一个参数为作业运行时信息;
#!/bin/bash
echo sharding execution context is $*
作业运行时输出
sharding execution context is {"jobName":"scriptElasticDemoJob","shardingTotalCount":10,"jobParameter":"","shardingItem":0,"shardingParameter":"A"}
Elastic-job控制台
Elastic-job控制台部署
1.下载或者克隆shardingsphere-elasticjob-ui源码,外面这里使用官方准备好的二进制包:
https://shardingsphere.apache.org/elasticjob/current/cn/downloads/
2.解压下载下来的二进制包:
tar -zxvf apache-shardingsphere-elasticjob-3.0.0-alpha-lite-ui-bin.tar.gz
3.切换到解压后的bin目录下,执行./start.sh启动
打开启动脚本看到启动的端口:8088
访问:linuxip:8088 ,登录用户名:root,密码:root
提供两种账户,管理员及访客,管理员拥有全部操作权限,访客仅拥有察看权限;默认管理员用户名和密码是root/root,访客用户名和密码是guest/guest,可通过conf/application.properties修改管理员及访客用户名及密码;
Elastic-job控制台功能
Elastic-job管控台和elastic-job-lite并无直接关系,Elastic-job管控台是通过读取作业注册中心数据展现作业状态,或更新注册中心数据修改全局配置。控制台只能控制作业本身是否运行,但不能控制作业进程的启动,因为控制台和作业本身服务器是完全分离的,控制台并不能控制作业服务器;
控制台的功能列表:
1、登录安全控制
2、注册中心、事件追踪数据源管理
3、快捷修改作业设置
4、作业和服务器维度状态查看
5、操作作业禁用\启用、停止和删除等生命周期
6、事件追踪查询
(1)运维平台和elastic-job-lite并无直接关系,是通过读取作业注册中心数据展现作业状态,或更新注册中心数据修改全局配置;
(2)控制台只能控制作业本身是否运行,但不能控制作业进程的启动,
因为控制台和作业本身服务器是完全分离的,控制台并不能控制作业服务器;
二、Elastic-Job分片机制
1、Elastic-Job作为分布式作业中间件有一个重要的概念就是:分片;
2、分片是指将一个任务拆分成多个任务执行,比如:现在要对一些数据进行处理,为了快速的执行任务,我们用2台服务器,让每台服务器执行任务的50%;
(1w条数据,分成2片,每片任务要执行的就是5k条数据)
(100w条数据,分成100片,每片任务要执行的就是1w条数据)
这样任务执行就比较快,可以充分利用服务器资源,你可以部署很多台机器来执行这些分片任务;
Elastic-job提供的分片功能,能够让任务通过分片进行水平扩展,可以通过多部署几台服务器,支撑海量数据量的任务调度,当任务减少,可以缩减服务器,实现了动态伸缩(扩容和缩容);
任务分片策略
比如有1个任务,分5片,但只部署两台机器,那么这5片任务怎么分配到2台机器上执行,这就是任务的分片策略;
Elastic-Job自带了三种分片策略,默认是平均分配策略:AVG_ALLOCATION;
1、平均分片策略
类型:AVG_ALLOCATION
根据分片项平均分片;
如果任务服务器数量与分片总数无法整除,多余的分片将会顺序的分配至每一个任务服务器;
举例说明:
- 1、如果3台任务服务器且分片总数为9,则分片结果为:1=[0,1,2], 2=[3,4,5], 3=[6,7,8];
- 2、如果3台任务服务器且分片总数为8,则分片结果为:1=[0,1,6], 2=[2,3,7], 3=[4,5];
- 3、如果3台任务服务器且分片总数为10,则分片结果为:1=[0,1,2,9], 2=[3,4,5], 3=[6,7,8];
2、奇偶分片策略
类型:ODEVITY
根据任务名称哈希值的奇偶数决定按照任务服务器 IP 升序或是降序的方式分片;
- 如果任务名称哈希值是偶数,则按照 IP 地址进行升序分片;
- 如果作业名称哈希值是奇数,则按照 IP 地址进行降序分片;
可用于让服务器负载在多个任务共同运行时分配的更加均匀;
举例说明: - 1、如果 3 台作业服务器,分片总数为2且作业名称的哈希值为偶数,则分片结果为:1 = [0], 2 = [1], 3 = [];
- 2、如果 3 台作业服务器,分片总数为2且作业名称的哈希值为奇数,则分片结果为:3 = [0], 2 = [1], 1 = [];
3、轮询分片策略
类型:ROUND_ROBIN
根据作业名称轮询分片;
设置分片策略
1)Java API开发采用如下代码:
JobConfiguration.newBuilder("javaSimpleOneOffJob", 3)
.shardingItemParameters("0=Beijing,1=Shanghai,2=Guangzhou")
.jobShardingStrategyType("ODEVITY")//这是奇偶性策略
(2)Spring开发进行如下配置:
<elasticjob:job id="${simple.id}"
job-ref="simpleJob"
registry-center-ref="regCenter"
tracing-ref="elasticJobTrace"
sharding-total-count="${simple.shardingTotalCount}"
cron="${simple.cron}"
sharding-item-parameters="${simple.shardingItemParameters}"
monitor-execution="${simple.monitorExecution}"
failover="${simple.failover}"
description="${simple.description}"
disabled="${simple.disabled}"
job-sharding-strategy-type="ROUND_ROBIN"
job-executor-service-handler-type="SINGLE_THREAD"
job-error-handler-type="LOG"
overwrite="${simple.overwrite}" />
(3)springboot开发采用如下配置:
#一个简单的定时任务
simpleJob2:
elasticJobClass: org.apache.shardingsphere.elasticjob.lite.example.job.SpringBootSimpleJob2
cron: 0/3 * * * * ?
shardingTotalCount: 3
shardingItemParameters: 0=Beijing,1=Shanghai,2=Guangzhou
jobShardingStrategyType: ODEVITY
monitorExecution: true
failover: true
jobExecutorServiceHandlerType: SINGLE_THREAD
jobErrorHandlerType: LOG
分片项
ElasticJob并不直接提供数据处理的功能,而是将分片项分配至各个运行中的作业服务器,开发者需要自行处理分片项与业务的对应关系,分片项为数字,从0开始 到 分片总数-1结束;
个性化分片参数
个性化参数可以和分片项匹配对应关系,用于将分片项的数字转换为更加可读的业务代码;
例如:按照地区水平拆分数据库,数据库 A 是北京的数据;数据库 B 是上海的数据;数据库 C 是广州的数据。 如果仅按照分片项配置,开发者需要了解 0 表示北京;1 表示上海;2 表示广州;
合理使用个性化参数可以让代码更可读,如果配置为 0=北京,1=上海,2=广州,那么代码中直接使用北京,上海,广州的枚举值即可完成分片项和业务逻辑的对应关系;
//比如动态查询该分片下要执行的用户
SELECT * FROM account WHERE mod(id, #{shardingTotalCount}) = #{shardingItem};
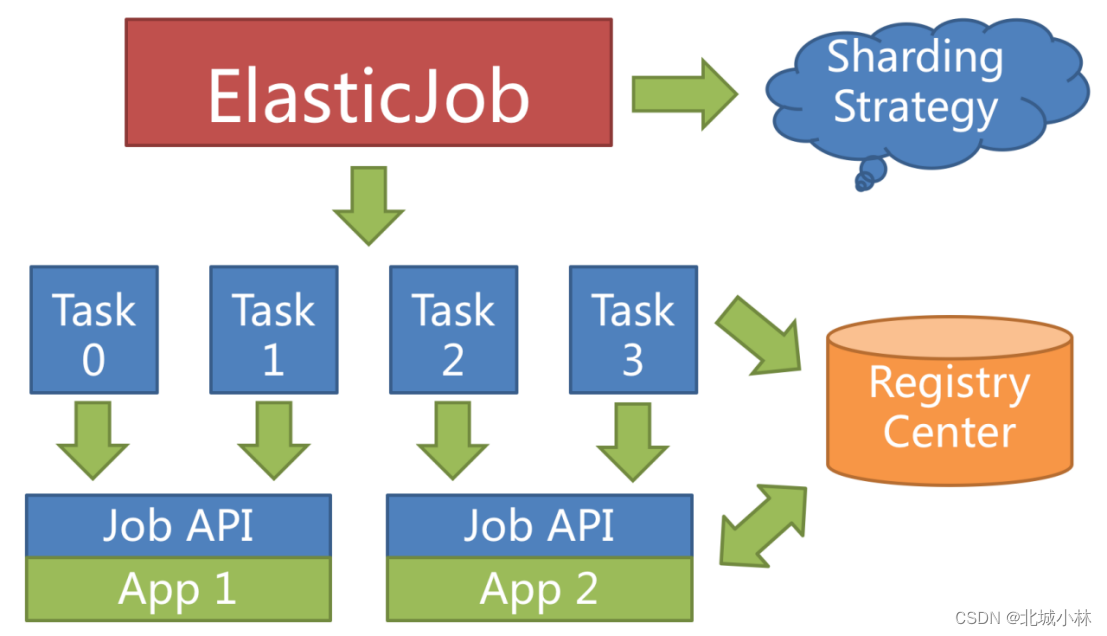
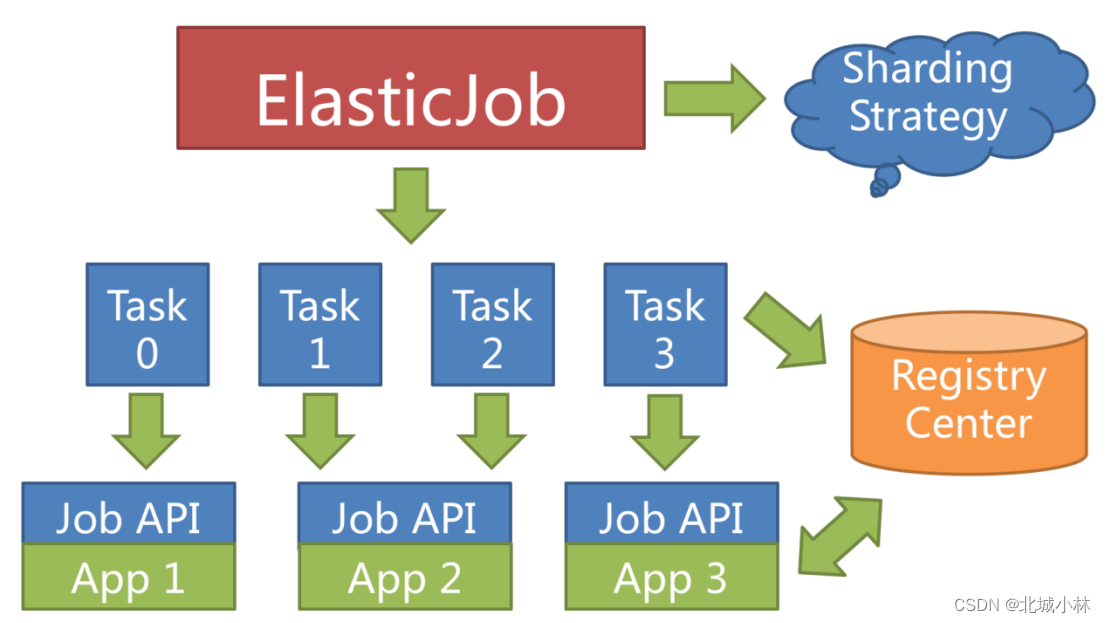
资源最大限度利用
ElasticJob提供最灵活的方式,最大限度的提高执行作业的吞吐量,当新增加任务服务器时,ElasticJob 会通过注册中心的临时节点的变化感知到新服务器的存在,并在下次任务调度的时候重新分片,新的服务器会承载一部分任务分片;
将分片项设置为大于服务器的数量,最好是大于服务器倍数的数量,作业将会合理的利用分布式资源,动态的分配分片项;
例如:3 台服务器,分成10片,则分片项分配结果为服务器A = 0,1,2;服务器B = 3,4,5;服务器C = 6,7,8,9,如果服务器C崩溃,则分片项分配结果为服务器A = 0,1,2,3,4; 服务器B = 5,6,7,8,9,在不丢失分片项的情况下,最大限度的利用现有资源提高吞吐量;
高可用
当任务服务器在运行中宕机时,注册中心同样会通过临时节点感知到,并将在下次运行时将分片转移至仍存活的服务器,以达到任务高可用的效果,本次由于服务器宕机而未执行完的任务,则可以通过失效转移的方式继续执行;
将分片总数设置为 1,并使用多于 1 台的服务器执行任务,任务将会以 1 主 n 从的方式执行,一旦执行任务的服务器宕机,等待执行的服务器将会在下次任务启动时替补执行;
如果开启失效转移功能效果更好,可以保证在本次作业在执行时宕机的情况下,备机立即启动替补执行;
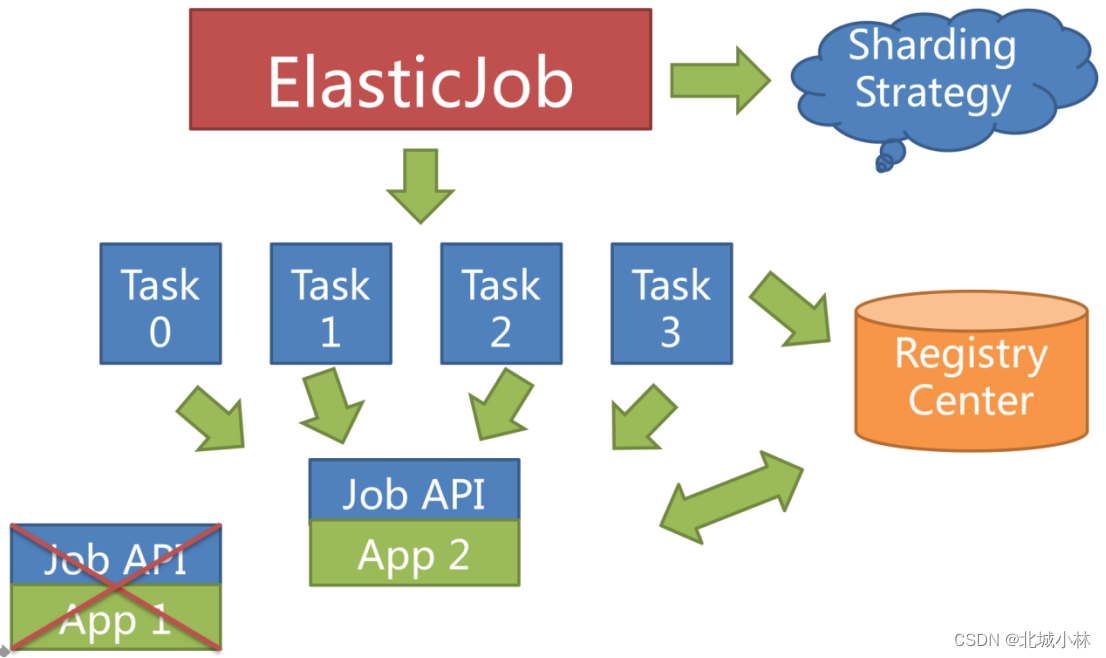
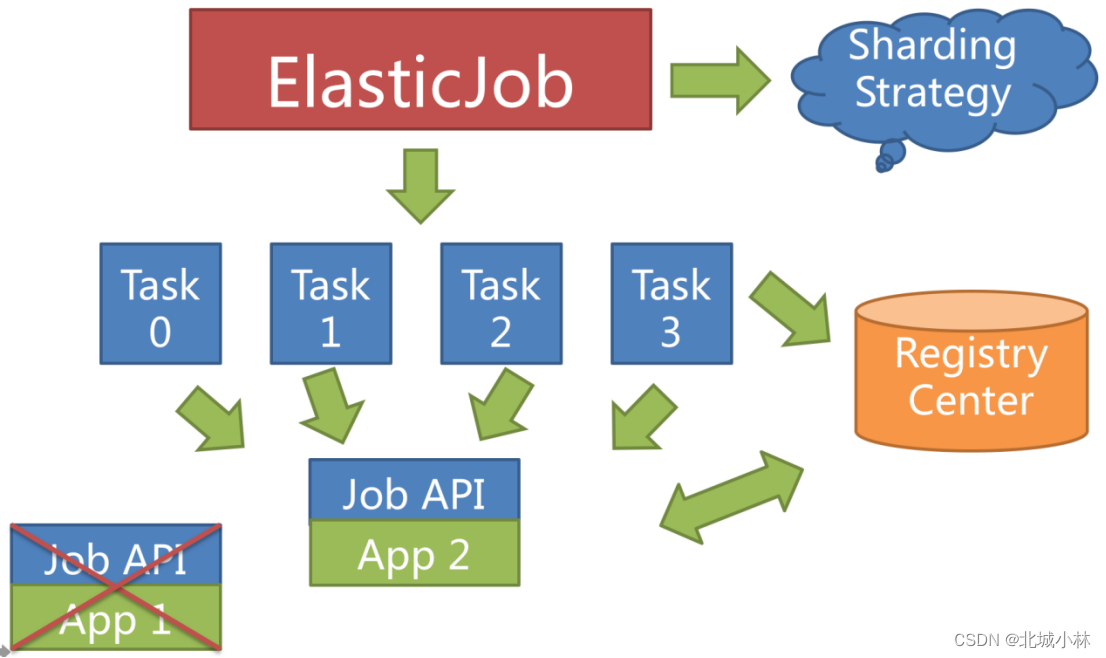
失效转移
Elastic-Job不会在本次执行过程中进行重新分片,而是等待下次调度之前才开启重新分片流程,当任务执行过程中服务器宕机,失效转移允许将该次未完成的任务在另一任务节点上补偿执行;
失效转移需要与监听作业运行时状态同时开启才可生效;
失效转移是当前执行任务的临时补偿执行机制,再下次任务运行时,会通过重分片对当前任务分配进行调整;
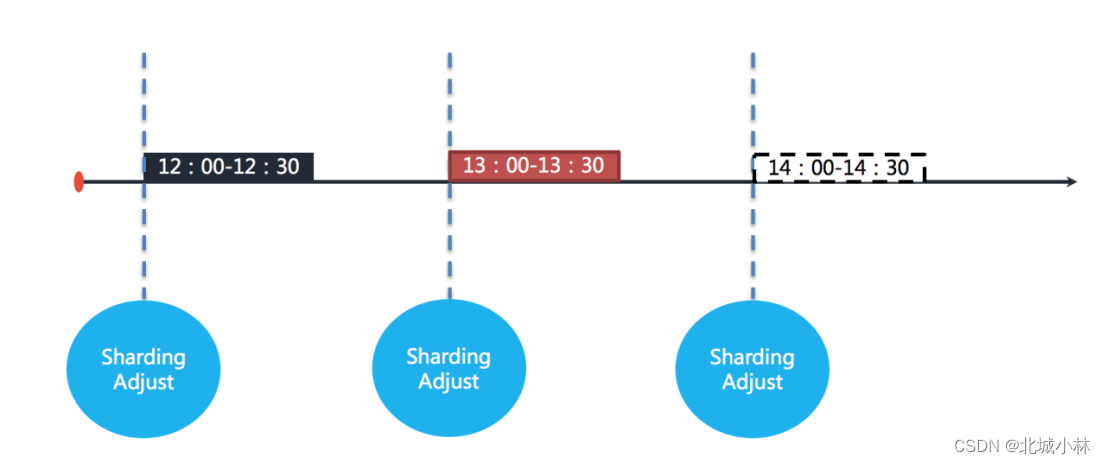
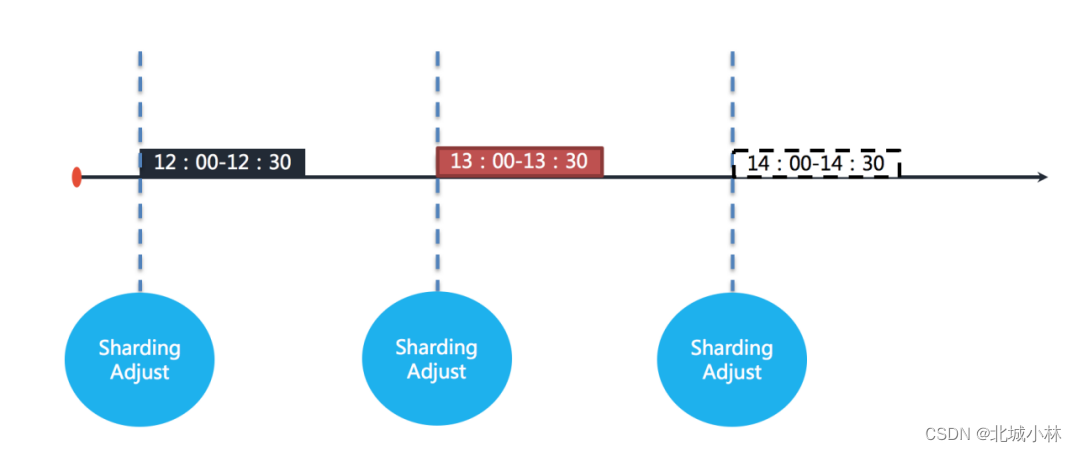
举例说明,若任务以每小时为间隔执行,每次执行耗时 30 分钟,如下如图所示。
图中表示任务分别于 12:00,13:00 和 14:00 执行,图中显示的当前时间点为 13:00 的任务执行中;
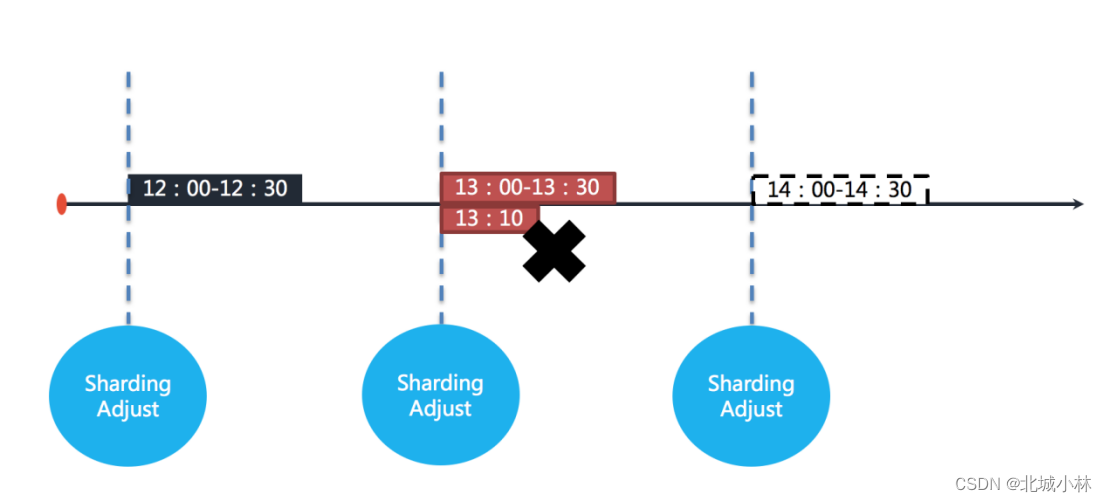
如果任务的其中一个分片服务器在 13:10 的时候宕机,那么剩余的 20 分钟应该处理的业务未得到执行,并且需要在 14:00 时才能再次开始执行下一次任务,也就是说,在不开启失效转移的情况下,位于该分片的任务有 50 分钟空档期,如下如图所示;
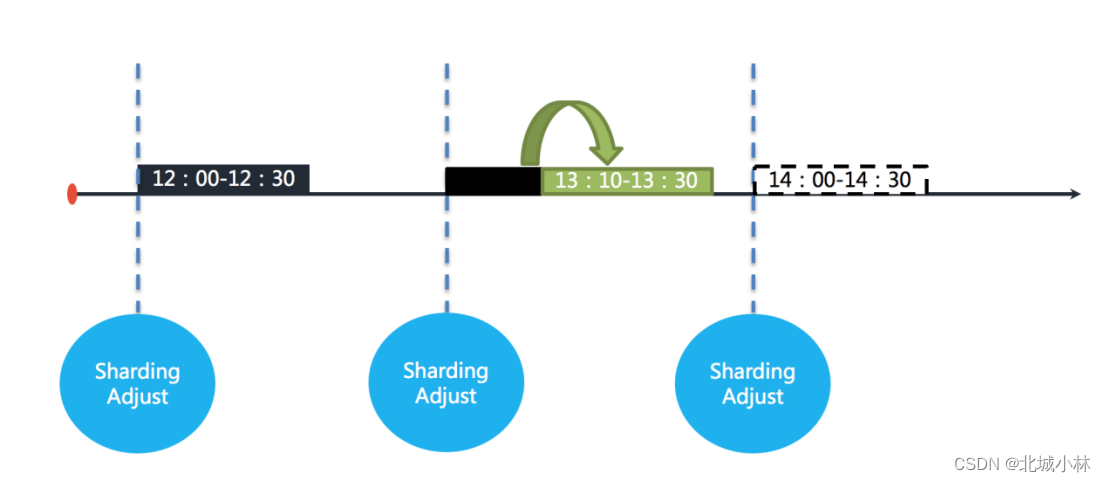
在开启失效转移功能之后,ElasticJob 的其他服务器能够在感知到宕机的任务服务器之后,补偿执行该分片任务,如下图所示;
在资源充足的情况下,任务仍然能够在13:30完成执行;
失效转移适用场景
开启失效转移功能,ElasticJob会监控作业每一分片的执行状态,并将其写入注册中心,供其他节点感知;
在一次运行耗时较长且间隔较长的作业场景,失效转移是提升作业运行实时性的有效手段;对于间隔较短的作业,会产生大量与注册中心的网络通信,对集群的性能产生影响,而且间隔较短的作业并非必要要关注单次作业的实时性,可以通过下次作业执行的重分片使所有的分片正确执行,因此不建议短间隔作业开启失效转移;
另外需要注意的是,作业本身的幂等性,即故障转移到新的节点上执行时,不要把业务数据执行重复了,已经执行过的数据要在业务代码上进行幂等性的处理,以保证失效转移的正确性;
失效转移通过如下两个参数控制,都需要设置为true;
错过任务重执行
private final boolean misfire; 通过该参数控制
ElasticJob不允许作业在同一时间内叠加执行,当作业的执行时长超过其运行间隔,错过任务重执行能够保证作业在完成上次的任务后继续执行逾期的作业;
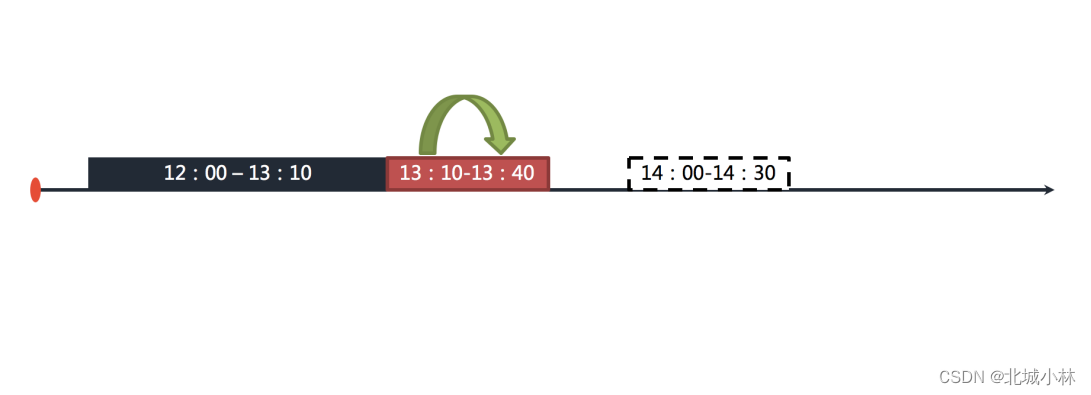
错过任务重执行功能可以使逾期未执行的作业在之前作业执行完成之后立即执行,举例说明,若作业以每小时为间隔执行,每次执行耗时30分钟,如下如图所示;
图中表示作业分别于 12:00,13:00 和 14:00 执行。图中显示的当前时间点为 13:00 的作业执行中;
如果12:00开始执行的作业在13:10才执行完毕,那么本该由 13:00 触发的作业则错过了触发时间,需要等待至14:00的下次作业触发, 如下如图所示;
在开启错过任务重执行功能之后,ElasticJob 将会在上次作业执行完毕后,立刻触发执行错过的作业,如下图所示;
在 13:00 和 14:00 之间错过的作业将会重新执行;
适用场景
在一次运行耗时较长且间隔较长的作业场景,错过任务重执行是提升作业运行实时性的有效手段,对于未见得关注单次作业的实时性的短间隔的作业来说,开启错过任务重执行并无必要;
配置参数:`misfire=true表示开启`
线程池策略
类型:CPU
根据 CPU 核数 * 2 创建作业处理线程池;
单线程策略
类型:SINGLE_THREAD
使用单线程处理作业;
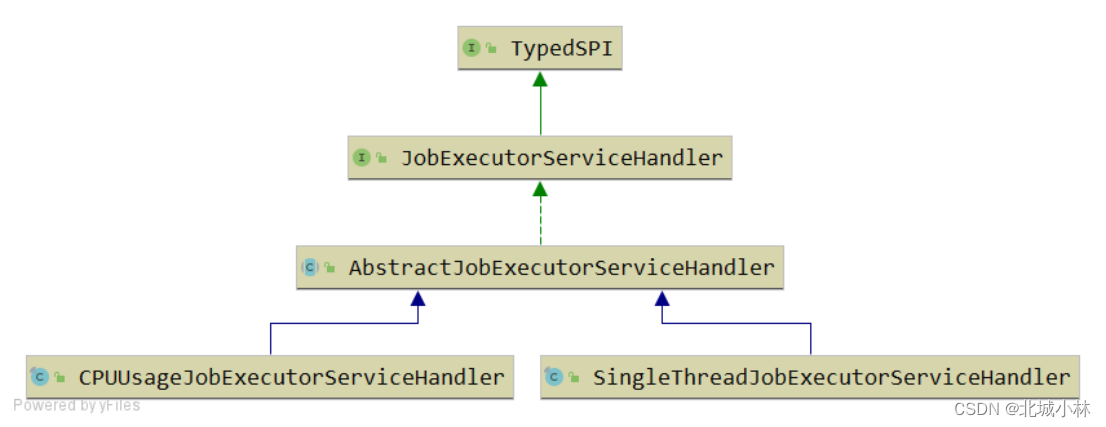
接口为:JobExecutorServiceHandler
默认是CPU资源策略
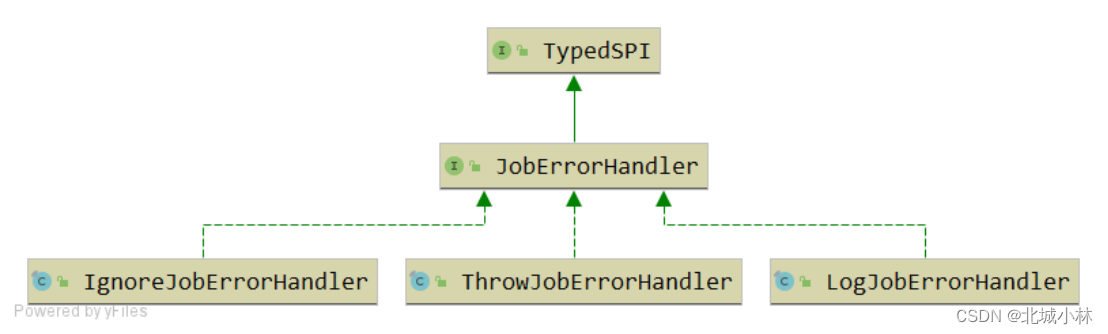
错误处理策略
1、记录日志策略
类型:LOG
记录作业异常日志,但不中断作业执行;
2、抛出异常策略
类型:THROW
抛出系统异常并中断作业执行;
3、忽略异常策略
类型:IGNORE
忽略系统异常且不中断作业执行;
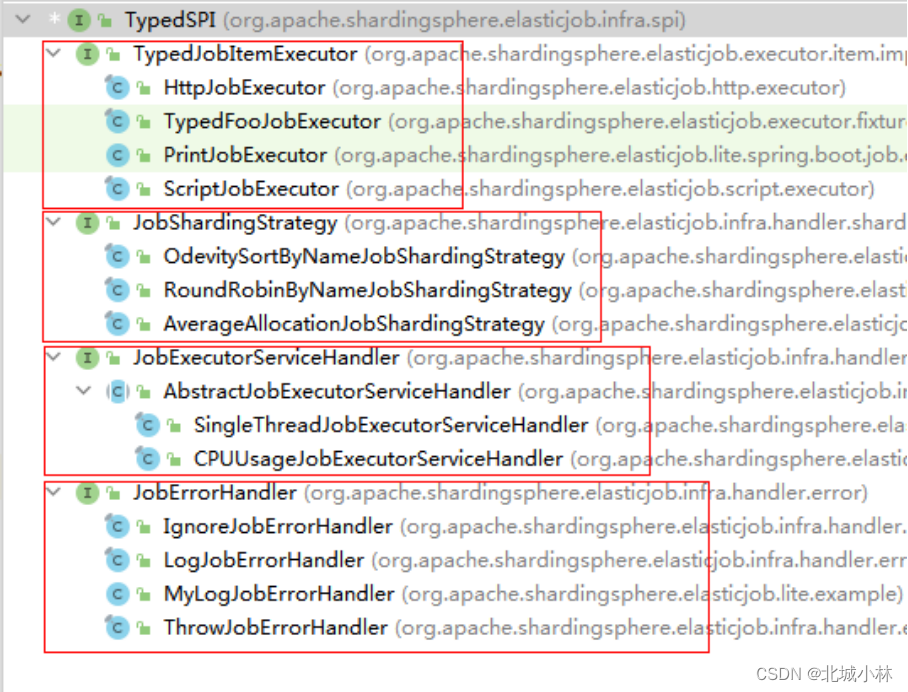
任务开放生态
灵活定制化任务是ElasticJob 3.x版本的最重要设计变革,新版本基于Apache ShardingSphere可插拔架构的设计理念,打造了全新任务API,意在使开发者能够更加便捷且相互隔离的方式拓展任务类型,打造ElasticJob作业的生态圈;
ElasticJob提供了对任务的弹性伸缩、分布式治理等功能的同时,并未限定作业的类型,它通过灵活的任务API,将任务解耦为任务接口和执行器接口,用户可以定制化全新的作业类型,诸如脚本执行、HTTP服务执行、大数据类作业、文件类作业等;
目前 ElasticJob 内置了简单作业、数据流作业和脚本执行作业,并且完全开放了扩展接口,开发者可以通过SPI的方式引入新的作业类型;
任务接口
ElasticJob的任务可划分为基于class 类型和基于type类型两种;
Class类型的任务由开发者直接使用,需要由开发者实现该任务接口实现业务逻辑,典型代表:Simple 类型、Dataflow 类型,Type类型的作业只需提供类型名称即可,开发者无需实现该作业接口,而是通过外置配置的方式使用,典型代表:Script 类型、HTTP 类型;
执行器接口
用于执行用户定义的作业接口,通过Java 的SPI机制织入ElasticJob生态;