TopN的原生MapReduce算法-普遍适用
目录
来源篇
原理篇
实现篇
来源篇
书名
数据算法-Hadoop/Spark大数据处理技巧
作者
Mahmoud Parsian著;
苏金国 杨健康两位老师翻译的一本书
序号
书中54页的Top10列表
书中大致列举如下形式
Hadoop的MapReduce实现:唯一键情况
Spark实现形式:唯一键情况
Spark实现形式:非唯一键
tackOrderd()的Spark的解决方案
MapReduce/Hadoop的非唯一键解决方案
困惑
以上困惑只针对个人理解,非抨击著者,相反我非常崇拜^
书中的大致形式是将非唯一的键转化为唯一的键,这相当于对键进行多一步的统计操作。
书中的一些示例只是对整数形式的唯一做讨论,其结果不具备普适性。
原理篇
目标
本篇文章将针对书中55-62页内容进行普适化改造,方便自己深入理解TopN的实现。
TopN的实现原理
-
在唯一键存在的情况下,需要得到键的加权值。此处构造结构体为猫的信息Cat<catId,catName,catWeight>。注意此处的catWeight可能不唯一
-
假设数量为10W条,不存在规约器瓶颈(书中假设)。部分数据如下图所示
3,cat_3,23 4,cat_4,48 5,cat_5,125 6,cat_6,169 7,cat_7,73 8,cat_8,114 9,cat_9,1 10,cat_10,21 11,cat_11,42 12,cat_12,55 13,cat_13,49 14,cat_14,145 15,cat_15,191 16,cat_16,23 17,cat_17,13 18,cat_18,86 19,cat_19,13 -
每个map的映射器在传入reduce规约器之前,用一个可排序的数据结构来保存前topN的结果,由于键是唯一的,故结果一定在映射器保留的前topN结果中。此处选择可排序的数据结构为SortedMap<Cat,String>
-
在每个映射器的map阶段将结果保存在SortMap中。
-
在每个映射器的结束阶段**(cleanUp)**阶段将结果写入reduce规约器中。输入值结构<Null,String>
-
reduce规约器阶段也用一个SortedMap保存topN的结果,相当于重复map阶段的操作
-
将SortedMap遍历写入到hdfs中
-
最后编写MapReduce驱动类进行整个操作流程
原理篇总结
输入输出什么的都是常规操作
最为重要的还是中间数据结构SortedMap。等下会详细介绍它的实现和坑
实战篇
前置准备
如果运行的环境为windows,需要安装hadoop的插件
需要虚拟机上有Hadoop的单机/集群环境(方便输出到hdfs上),或者你输出到本地也可
依赖导入-Maven项目
如下图所示,这里既有hadoop运行必要的依赖,也有spark运行必要的依赖
<groupId>edu.sicau.ping</groupId>
<artifactId>hadoop-learn</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<java.version>1.8</java.version>
<spark.version>3.1.2</spark.version>
<maven-assembly-plugin.version>2.4.1</maven-assembly-plugin.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<maven.compiler.compilerVersion>1.8</maven.compiler.compilerVersion>
<scala.version>2.12.13</scala.version>
</properties>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.1</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/junit/junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.projectlombok/lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
代码实现
数据生成器
通过文件流的方式生成模拟数据文件-catTopNUnique.txt
@Test
public void testCatGenerateUnique() throws IOException {
CatGenerate catGenerate = new CatGenerate();
catGenerate.generate(100000, 200, "D:\\Destop\\hadooplearn\\src\\data\\catTopNUnique.txt");
}
public void generate(int quantity, int maxWeight, String path) throws IOException {
File file = new File(path);
FileOutputStream fileOutputStream = new FileOutputStream(file);
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(fileOutputStream);
for (int i = 0; i < quantity; i++) {
Cat cat = new Cat();
cat.setCatId(i);
cat.setCatName(String.format("cat_%s", i));
cat.setCatWeight((int) (Math.random() * maxWeight));
bufferedOutputStream.write(cat.toString().getBytes());
}
bufferedOutputStream.close();
fileOutputStream.close();
}
@Data
public static class Cat {
private int catId;
private String catName;
private Integer catWeight;
@Override
public String toString() {
return String.format("%s,%s,%s\n", catId, catName, catWeight);
}
}
猫的实现类
import lombok.Data;
/**
* 猫的模型
*/
@Data
public class Cat {
/**
* 猫的id
*/
private String catId;
/**
* 猫的名称
*/
private String catName;
/**
* 猫的体重
*/
private Integer catWeight;
}
Map+Reduce总体代码
/**
* 猫的信息唯一的情况
*
* @author ping
*/
public class CatTopNUnique {
public static final Integer TOP_N = 1000;
public static class CatTopNMapper extends Mapper<LongWritable, Text, NullWritable, Text> {
/**
* 猫的体重排行Map
*/
private SortedMap<Cat, String> catWeightMap = new TreeMap<>(new Comparator<Cat>() {
/**
* 一定要添加一个比较
*
* @param o1 第一个对象
* @param o2 第二个对象
* @return 对象的比较情况
*/
@Override
public int compare(Cat o1, Cat o2) {
if (o1.getCatWeight() < o2.getCatWeight()) {
return -1;
} else if (o1.getCatWeight() > o2.getCatWeight()) {
return 1;
}
return o1.getCatId().compareTo(o2.getCatId());
}
});
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// map阶段和reduce阶段的代码都是相似的
CatTopNReducer.putToCatMap(value, catWeightMap);
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
Set<Map.Entry<Cat, String>> entrySet = catWeightMap.entrySet();
for (Map.Entry<Cat, String> entry : entrySet) {
String value = entry.getValue();
context.write(NullWritable.get(), new Text(value));
}
}
}
public static class CatTopNReducer extends Reducer<NullWritable, Text, IntWritable, Text> {
/**
* 猫的体重排行Map
*/
private SortedMap<Cat, String> catWeightMap = new TreeMap<>(new Comparator<Cat>() {
/**
* 一定要添加一个比较
*
* @param o1 第一个对象
* @param o2 第二个对象
* @return 对象的比较情况
*/
@Override
public int compare(Cat o1, Cat o2) {
if (o1.getCatWeight() < o2.getCatWeight()) {
return -1;
} else if (o1.getCatWeight() > o2.getCatWeight()) {
return 1;
}
return o1.getCatId().compareTo(o2.getCatId());
}
});
@Override
protected void reduce(NullWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text value : values) {
putToCatMap(value, catWeightMap);
}
Set<Map.Entry<Cat, String>> entrySet = catWeightMap.entrySet();
for (Map.Entry<Cat, String> entry : entrySet) {
Cat cat = entry.getKey();
Integer catWeight = cat.getCatWeight();
String value = entry.getValue();
context.write(new IntWritable(catWeight), new Text(value));
}
}
private static void putToCatMap(Text value, SortedMap<Cat, String> catWeightMap) {
String inputString = value.toString();
String[] split = inputString.split(",");
String catId = split[0];
String catName = split[1];
int catWeight = Integer.parseInt(split[2]);
Cat cat = new Cat();
cat.setCatId(catId);
cat.setCatName(catName);
cat.setCatWeight(catWeight);
catWeightMap.put(cat, inputString);
if (catWeightMap.size() > TOP_N) {
Cat firstKey = catWeightMap.firstKey();
catWeightMap.remove(firstKey);
}
}
}
}
map端实现
- 定义一个SortedMap<Cat, String>,注意重写它的Comparator方法。如果不重写这个方法。默认抛出ClassCastException异常,说这玩意不能转化为java.lang.Comparable
- 注意Comparator中返回0的情况,在SortedMap中,返回0认为key为重复的,后续添加可能会被覆盖。但是一定不能完全不写返回0的情况,否则这个SortedMap将无法去除元素.obj.remove(obj.firstKey)失效
- 最后注意是在cleanup阶段将SortedMap中的元素写出。不然相当于map阶段没用(导致规约器遍历全部的数据量)
代码
public static class CatTopNMapper extends Mapper<LongWritable, Text, NullWritable, Text> {
/**
* 猫的体重排行Map
*/
private SortedMap<Cat, String> catWeightMap = new TreeMap<>(new Comparator<Cat>() {
/**
* 一定要添加一个比较
*
* @param o1 第一个对象
* @param o2 第二个对象
* @return 对象的比较情况
*/
@Override
public int compare(Cat o1, Cat o2) {
if (o1.getCatWeight() < o2.getCatWeight()) {
return -1;
} else if (o1.getCatWeight() > o2.getCatWeight()) {
return 1;
}
return o1.getCatId().compareTo(o2.getCatId());
}
});
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
CatTopNReducer.putToCatMap(value, catWeightMap);
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
Set<Map.Entry<Cat, String>> entrySet = catWeightMap.entrySet();
for (Map.Entry<Cat, String> entry : entrySet) {
String value = entry.getValue();
context.write(NullWritable.get(), new Text(value));
}
}
}
reduce端实现
- reduce端几乎完全重复map阶段的过程
- 主要是写出可以按照你自己的输出要求来即可
代码
public static class CatTopNReducer extends Reducer<NullWritable, Text, IntWritable, Text> {
/**
* 猫的体重排行Map
*/
private SortedMap<Cat, String> catWeightMap = new TreeMap<>(new Comparator<Cat>() {
/**
* 一定要添加一个比较
*
* @param o1 第一个对象
* @param o2 第二个对象
* @return 对象的比较情况
*/
@Override
public int compare(Cat o1, Cat o2) {
if (o1.getCatWeight() < o2.getCatWeight()) {
return -1;
} else if (o1.getCatWeight() > o2.getCatWeight()) {
return 1;
}
return o1.getCatId().compareTo(o2.getCatId());
}
});
@Override
protected void reduce(NullWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text value : values) {
putToCatMap(value, catWeightMap);
}
Set<Map.Entry<Cat, String>> entrySet = catWeightMap.entrySet();
for (Map.Entry<Cat, String> entry : entrySet) {
Cat cat = entry.getKey();
Integer catWeight = cat.getCatWeight();
String value = entry.getValue();
context.write(new IntWritable(catWeight), new Text(value));
}
}
private static void putToCatMap(Text value, SortedMap<Cat, String> catWeightMap) {
String inputString = value.toString();
String[] split = inputString.split(",");
String catId = split[0];
String catName = split[1];
int catWeight = Integer.parseInt(split[2]);
Cat cat = new Cat();
cat.setCatId(catId);
cat.setCatName(catName);
cat.setCatWeight(catWeight);
catWeightMap.put(cat, inputString);
if (catWeightMap.size() > TOP_N) {
Cat firstKey = catWeightMap.firstKey();
catWeightMap.remove(firstKey);
}
}
}
驱动类实现
驱动类非常常规
- 定义job
- 定义mapper执行类,输出类的键值结构
- 定义reducer执行类,输出的键值结构
- 最后就是输入文件的位置。输出文件的位置
- 等待job计算完成
代码
@Test
public void driverUnique() throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = new Job(conf, "CatTopNUniqueDriver");
job.setMapperClass(CatTopNUnique.CatTopNMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(CatTopNUnique.CatTopNReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path("D:\\Destop\\hadooplearn\\src\\data\\catTopNUnique.txt"));
Path outputPath = new Path("hdfs://spark01:9000/test/catTopNUniqueResult");
FileOutputFormat.setOutputPath(job, outputPath);
job.waitForCompletion(true);
}
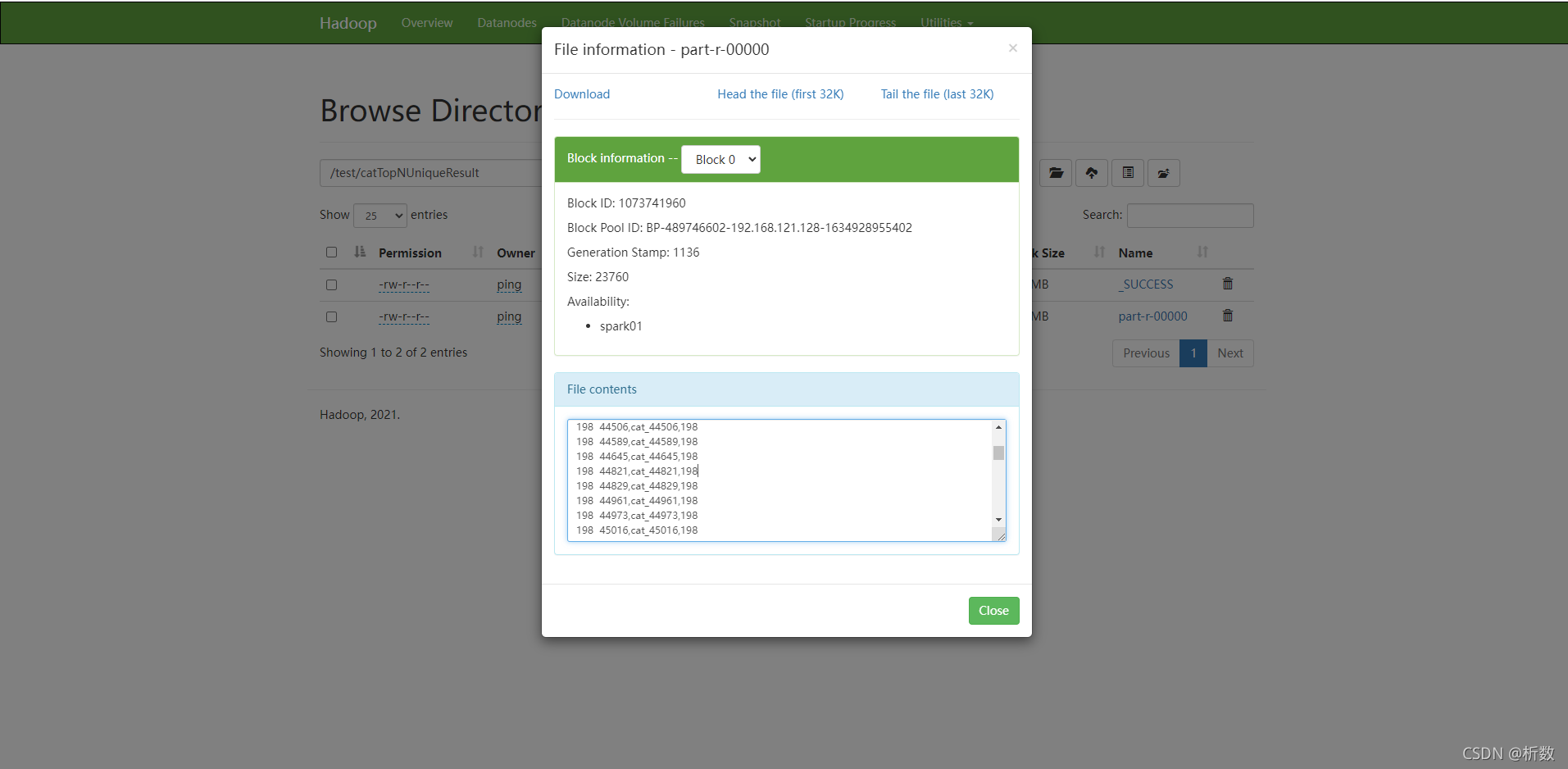
最终结果
部分结果
198 44589,cat_44589,198
198 44645,cat_44645,198
198 44821,cat_44821,198
198 44829,cat_44829,198
截图
[外链图片转存中…(img-Yxj5cpK9-1637555319742)]
敬读者
Hadoop的MapReduce相对繁琐,我这里还有Spark版本的Java和scala实现。
需要资料或者想交流的可以私信我。谢谢各位。
有任何的问题都可以随时提出,愿洗耳恭听!