目录
1、概述
ring buffer称作环形缓冲区,也称作环形队列(circular queue),是一种用于表示一个固定尺寸、头尾相连的缓冲区的数据结构,适合缓存数据流。如下为环形缓冲区(ring buffer) 的概念示意图。
在任务间的通信、串口数据收发、log缓存、网卡处理网络数据包、音频/视频流处理中均有环形缓冲区(ring buffer) 的应用。在RT-Thread的ringbuffer.c和ringbuffer.h文件中,Linux内核文件kfifo.h和kfifo.c中也有环形缓冲区(ring buffer)的代码实现。
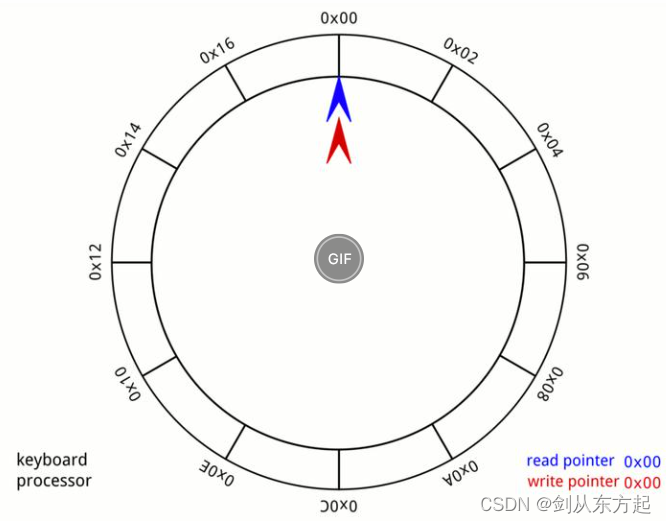
环形缓冲区的一些使用特点如下:
- 当一个数据元素被读取出后,其余数据元素不需要移动其存储位置;
- 适合于事先明确了缓冲区的最大容量的情形。缓冲区的容量(长度)一般固定,可以用一个静态数组来充当缓冲区,无需重复申请内存;
- 如果缓冲区的大小需要经常调整,就不适合用环形缓冲区,因为在扩展缓冲区大小时,需要搬移其中的数据,这种场合使用链表更加合适;
- 因为缓冲区成头尾相连的环形,写操作可能会覆盖未及时读取的数据,有的场景允许这种情况发生,有的场景又严格限制这种情况发生。选择何种策略和具体应用场景相关。
2、原理
由于计算机内存是线性地址空间,因此环形缓冲区(ring buffer)需要特别的算法设计才可以从逻辑上实现。
2.1、 一个简单例子
先不要想环形缓冲区(ring buffer)的具体实现细节,来看一个简单的例子。如下是一个空间大小为 7的环形缓冲区,其中底部的单线箭头表示“头尾相连”形成一个环形地址空间:
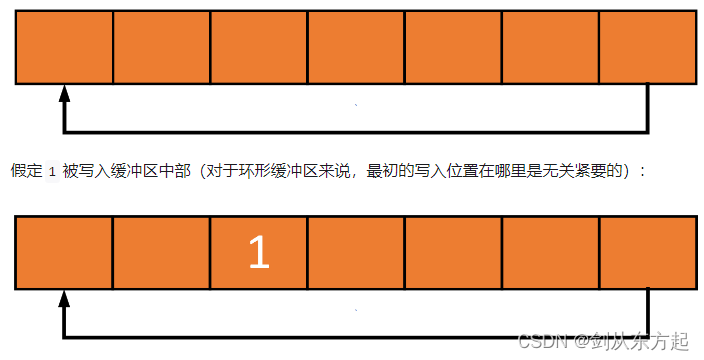
假定1被写入缓冲区中部(对于环形缓冲区来说,最初的写入位置在哪里是无关紧要的):
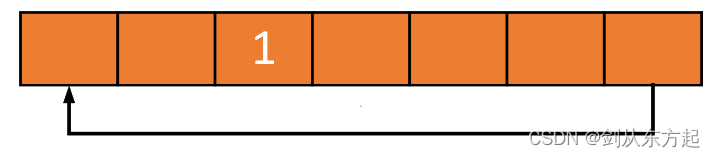
再写入两个元素,分别是2和3,这两个元素被追加到1之后:
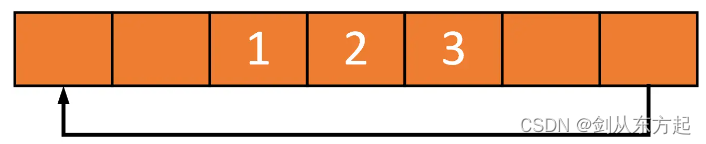
如果读出两个元素,那么环形缓冲区中最老的两个元素将被读出(先进先出原则)。在本例中1和2被读出,缓冲区中剩下3:
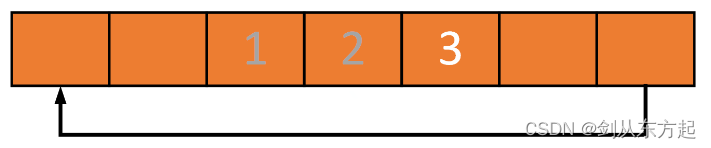
紧接着,向缓冲区中写入六个元素4、5、6、7、8、9,这时缓冲区会被装满:
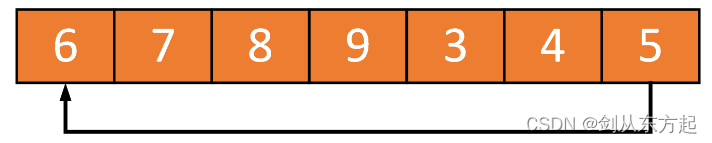
如果缓冲区是满的,又要写入新的数据,这时有两种策略:一种是覆盖掉最老的数据,也就是将老数据丢掉;另一种是返回错误码或者抛出异常。来看策略一,例如,这时写入两个元素A和B,就会覆盖掉3和4:
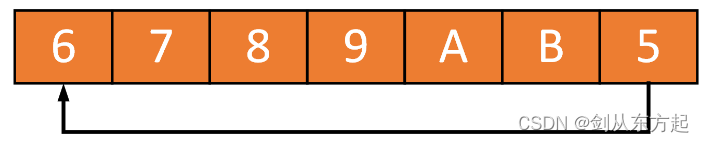
再看,这时如果读出两个元素,就不是3和4而是5和6(5和6这时最老),3和4已经被A和B覆盖掉。
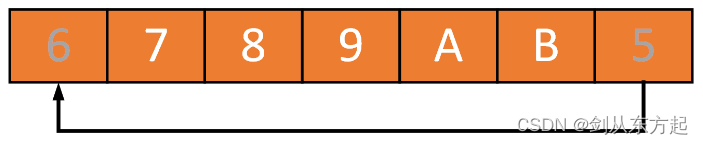
通过这个简单的例子,可以总结出要实现环形缓冲区(ring buffer)需要注意到几个问题点:
- 在缓冲区满的时候写数据,有两种策略可以使用:第一覆盖掉老数据;第二抛出异常;
- 读数据时,一定要读出缓冲区中最老的数据(缓冲区中数据满足FIFO特性);
- 怎样来判断缓冲区是满的;
- 如何实现一个线性地址空间的循环读写。
2.2、具体怎样做
一般的,对一个环形缓冲区进行读写操作,最少需要4个信息:
- 在内存中的实际开始位置(例如:一片内存的头指针,数组的第一个元素指针);
- 在内存中的实际结束位置(也可以是缓冲区实际空间大小,结合开始位置,可以算出结束位置);
- 在缓冲区中进行写操作时的写索引值;
- 在缓冲区中进行读操作时的读索引值。
缓冲区开始位置和缓冲区结束位置(或空间大小) 实际上定义了环形缓冲区的实际逻辑空间和大小。读索引和写索引标记了缓冲区进行读操作和写操作时的具体位置。如下图所示,为环形缓冲区的典型读写过程:
- 当环形缓冲区为空时,读索引和写索引指向相同的位置(因为是环形缓冲区,可以出现在任何位置);
- 当向缓冲区写入一个元素时,元素
A被写入写索引当前所指向位置,然后写索引加1,指向下一个位置; - 当再写如一个元素
B时,元素B继续被写入写索引当前所指向位置,然后写索引加1,指向下一个位置; - 当接着写入
C、D、E、F、G五个元素后,缓冲区就满了,这时写索引和写索引指向同一个位置(和缓冲区为空时一样); - 当从缓冲区中读出一个元素
A时,读索引当前所在位置的元素被读出,然后读索引加1,指向下一个位置; - 继续读出元素
B时,还是读索引当前所在位置的元素被读出,然后读索引加1,指向下一个位置。
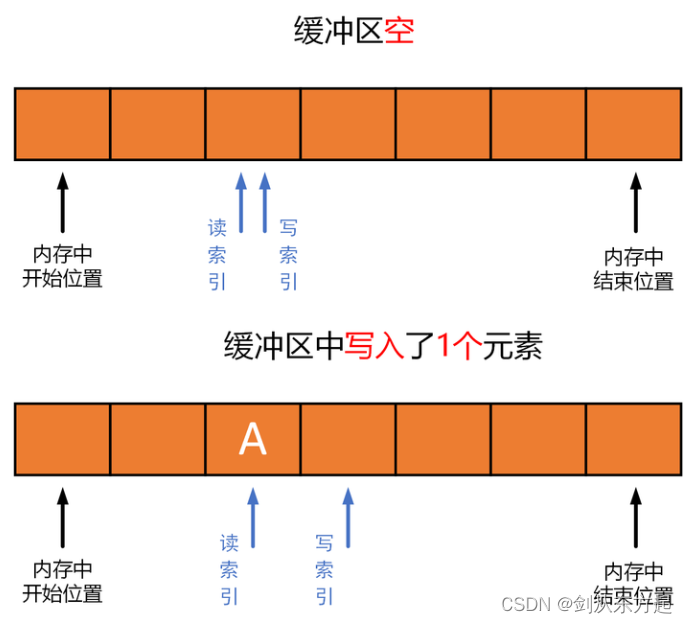
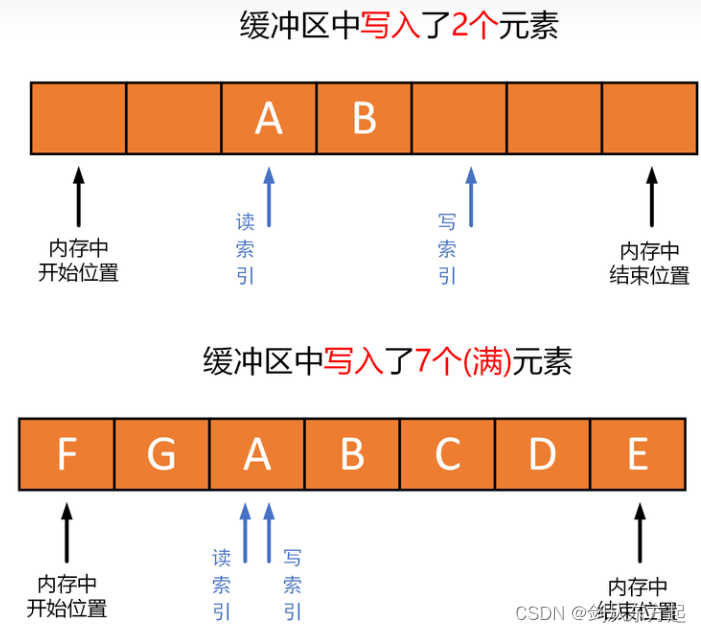
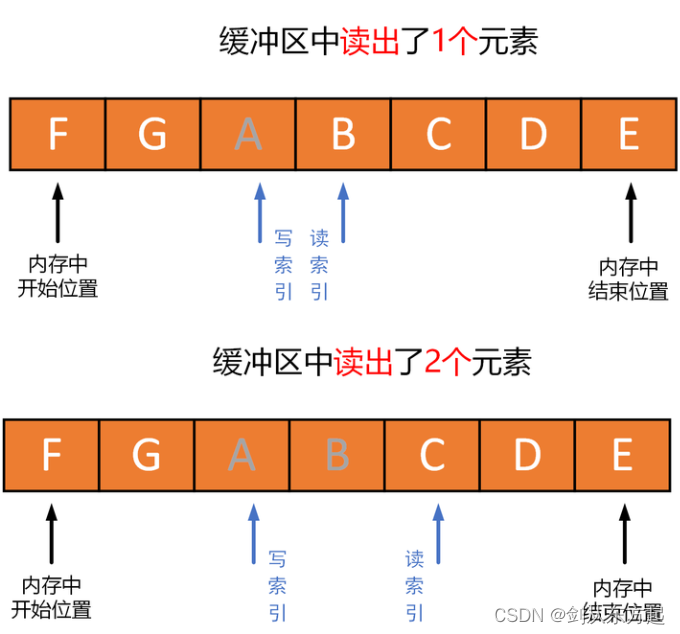
下面来探讨具体怎样做?在2.1节中提出了四个问题点,本节将会对这四个问题点进行回答,在回答完这四个问题点后,对于如何实现环形缓冲区(ring buffer)的脉络应该会清晰起来。
2.2.1、 在缓冲区满的时候写数据,有两种策略可以使用
缓冲区变满在环形缓冲区(ring buffer)中会实际发生,一般会有两种处理策略,第一覆盖掉老数据;第二抛出“异常”。这两种策略该如何选择要结合具体的应用场景。如音/视频流中,丢掉一些数据不要紧,可以选择第一种策略;在任务间通信的时候,要严格保证数据正确传输,这个时候就要选择第二种策略。
2.2.2 、读数据时,一定要读出缓冲区中最老的数据
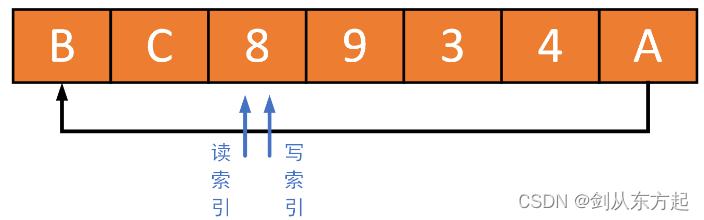
环形缓冲区(ring buffer)也是FIFO类型的数据结构,需要满足先进先出的原则。写就相当于进,读就相当于出。所以读数据时,一定要保证读最老的数据。一般的情况下不会有问题,但有一种场景需要小心。如下图所示环形缓冲区的大小为 七,缓冲区中已经存储了7,8,9,3,4五个元素。
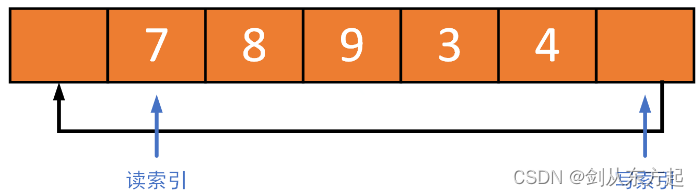
如果再向缓冲区中写入三个元素A,B,C,因为剩余空间为2了,所以要想写入这三个元素肯定会覆盖掉一个元素。此时,读/写索引变为如下图所示。读索引不再停留在元素7处,而是在元素8处,因为元素7已经被覆盖掉,而元素8变为最老的元素。这个例子说明,当缓冲区是满的时候,继续写入元素(覆盖),除了写索引要变,读索引也要跟着变,保证读索引一定是指向缓冲区中最老的元素。
2.2.3、 怎样来判断缓冲区是满的
如下图,缓冲区是满、或是空,都有可能出现读索引与写索引指向同一位置:
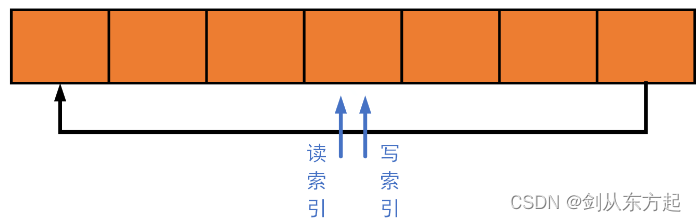
判断缓冲区是满还是空,在环形缓冲区(ring buffer)中是一个重点问题,在维基百科(http://en.wikipedia.org/wiki/Circular_buffer)中,讲解了五种判断方法,感兴趣可以看一下。在平衡各方优缺点后,本节重点讲解 镜像指示位方法,在linux和RT-Thread实现的环形缓冲区中,也都是用的该策略(或者说是该策略的扩展)。
镜像指示位:缓冲区的长度如果是n,逻辑地址空间则为0至n-1;那么,规定n至2n-1为镜像逻辑地址空间。本策略规定读写指针的地址空间为0至2n-1,其中低半部分对应于常规的逻辑地址空间,高半部分对应于镜像逻辑地址空间。当指针值大于等于2n时,使其折返(wrapped)到ptr-2n。使用一位表示写指针或读指针是否进入了虚拟的镜像存储区:置位表示进入,不置位表示没进入还在基本存储区。

在读写指针的值相同情况下,如果二者的指示位相同,说明缓冲区为空;如果二者的指示位不同,说明缓冲区为满。这种方法优点是测试缓冲区满/空很简单;不需要做取余数操作;读写线程可以分别设计专用算法策略,能实现精致的并发控制。 缺点是读写指针各需要额外的一位作为指示位。
如果缓冲区长度是2的幂,则本方法可以省略镜像指示位。如果读写指针的值相等,则缓冲区为空;如果读写指针相差n,则缓冲区为满,这可以用条件表达式(写指针 == (读指针 异或 缓冲区长度))来判断。—— 维基百科
上面是维基百科中对镜像指示位的整体描述,但是单凭上面这一个描述,去理解镜像指示位方法还是有一定困难,下面来进行一些讨论。
上面描述中提到了读/写指针的概念,注意这个读/写指针和上文提到的读索引和写索引不是一回事。读写指针的范围是,[0,2n−1],而读索引和写索引的范围是,[0,n−1],其必须和缓冲区的实际逻辑空间一致。但是读/写指针和读索引和写索引有一个转换关系:

其中%号,是求余运算符。但是如果缓冲区长度是2的幂,那么求余运算可以等价的转换为如下的按位与运算:

按位与的运算效率要比求余运算高的多,在linux内核中将缓冲区长度扩展为2的幂长度随处可见,都是为了用按位与操作代替求余操作。为了判断缓冲区是否为空或者满,镜像指示位策略引入了两个布尔变量(指示位),来分别标记读指针或写指针是否进入了镜像区间,[n,2n−1],在读写指针的值相同情况下,如果二者的指示位相同,说明缓冲区为空;如果二者的指示位不同,说明缓冲区为满。但如果缓冲区的长度是2的幂,则可以省略镜像指示位。如果读写指针的值相等,则缓冲区为空;如果读写指针相差n,则缓冲区为满。
2.2.4 如何实现一个线性地址空间的循环读写
理解了2.2.3节的描述,再来理解用一个线性地址空间来实现循环读写就比较容易。如一个环形缓冲区的长度为七,则其读写索引的区间为,[0,6]。当写索引的值为6,再向缓冲区中写入一个元素时,写索引应该要回到缓冲区的起始索引位置0,读索引在碰到这种情况也是类似处理。总结为一句话就是,当写索引或读索引已经到了环形缓冲区的结束位置时,进行下一步操作时,其应该要回到环形缓冲区的开始位置。
3、 实现
对于环形缓冲区的代码实现,本文会分析RT-Thread的ringbuffer.c和ringbuffer.h文件,Linux内核中的kfifo.h和kfifo.c文件。
3.1 、RT-Thread中实现的ring buffer
下面分析RT-Thread的ring buffer实现,主要会讨论环形缓冲区结构体、缓冲区初始化操作、写操作、读操作、判断缓冲区是否为空或满。
环形缓冲区结构体
RT-Thread中定义了结构体rt_ringbuffer,其中buffer_ptr、buffer_size、read_index、write_index和2.2节中介绍的4个信息是完全对应的。为了判断缓冲区是空还是满,还定义了两个布尔型变量read_mirror和write_mirror,其是通过位域的定义方式来实现。
struct rt_ringbuffer
{
rt_uint8_t *buffer_ptr;
rt_uint16_t read_mirror : 1;
rt_uint16_t read_index : 15;
rt_uint16_t write_mirror : 1;
rt_uint16_t write_index : 15;
rt_int16_t buffer_size;
};缓冲区初始化操作
初始化操作rt_ringbuffer_init很容易理解,就是将申请好的内存地址赋值给环形缓冲区,缓冲区实际逻辑大小也传入进去。read_index、write_index、read_mirror和write_mirror全部初始化为零。
void rt_ringbuffer_init(struct rt_ringbuffer *rb,
rt_uint8_t *pool,
rt_int16_t size)
{
RT_ASSERT(rb != RT_NULL);
RT_ASSERT(size > 0);
/* initialize read and write index */
rb->read_mirror = rb->read_index = 0;
rb->write_mirror = rb->write_index = 0;
/* set buffer pool and size */
rb->buffer_ptr = pool;
rb->buffer_size = RT_ALIGN_DOWN(size, RT_ALIGN_SIZE);
}写操作和读操作
写操作有两个接口rt_ringbuffer_put和rt_ringbuffer_put_force,当缓冲区满的时候,前一个不会写入,后一个会强制写入(覆盖);读操作有一个接口rt_ringbuffer_get。
这里先说明一下,RT-Thread的ring buffer实现虽然借鉴了上一章讲的镜像指示位策略,但其并没有使用读写指针,而是直接用的写索引和读索引,也就是说结构体中的read_index和write_index就是写索引和读索引,无需进行转换,直接可以用来操作缓冲区。这一点和linux的实现方式不同,在下面的linux章节中会看到。但read_mirror和write_mirror是和镜像指示位策略中讲的一样,用来标记是否进入了镜像区间。
先来看rt_ringbuffer_put的实现,该函数的返回值是实际写入大小,就是如果传入的length大于缓冲区的剩余空间,则length只有部分会被写入缓冲区。通过条件if (rb->buffer_size - rb->write_index > length)将写操作分成了如下两种情形:
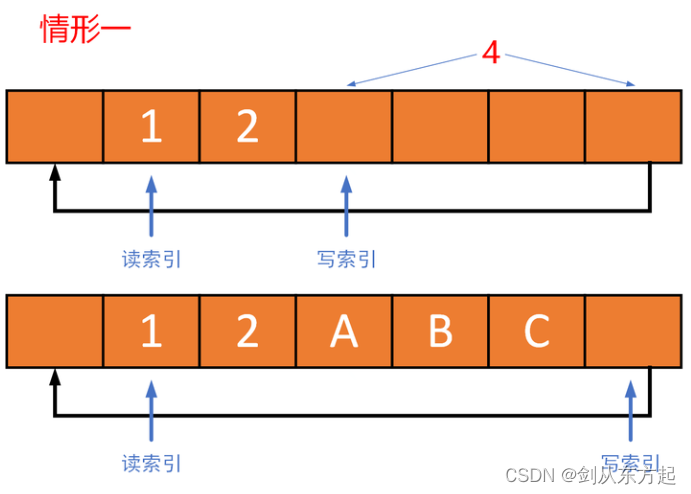

当if (rb->buffer_size - rb->write_index > length)为真时,其对应的是情形一。就是说从写索引到缓冲区结束位置这一段空间能容纳全部所写入数据。在图片情形一中,开始缓冲区中有两个元素1、2,接着继续写入A、B、C三个元素。可以看出从写索引到缓冲区结束位置还可以容纳4个元素,所以A、B、C三个元素可以一次性写入缓冲区,写索引无需回环。对应的代码就是rt_memcpy(&rb->buffer_ptr[rb->write_index], ptr, length);。
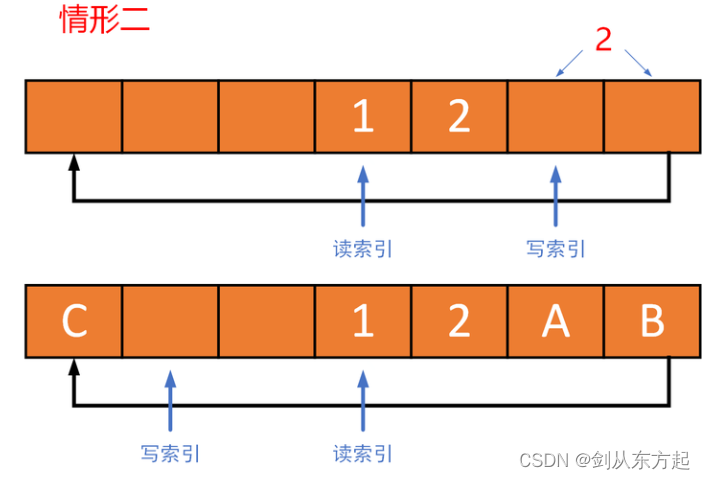
当if (rb->buffer_size - rb->write_index > length)为假时,其对应的是情形二。就是说从写索引到缓冲区结束位置这一段空间无法全部容纳所写入数据,写索引需要回环到缓冲区开头,写入剩下的数据。在图片情形二中,开始缓冲区中有两个元素1、2,接着继续写入A、B、C三个元素。可以看出从写索引到缓冲区结束位置还可以容纳2个元素,也就是说A、B两个元素可以写入从写索引到缓冲区结束位置这一段,而C只能回环到缓冲区的开头位置。对应代码就是rt_memcpy(&rb->buffer_ptr[rb->write_index],&ptr[0],rb->buffer_size - rb->write_index);rt_memcpy(&rb->buffer_ptr[0],&ptr[rb->buffer_size - rb->write_index],length - (rb->buffer_size - rb->write_index));。因为写索引已经回环了,所以要将write_mirror做一下取反操作:rb->write_mirror = ~rb->write_mirror;。
写操作接口rt_ringbuffer_put_force和上面介绍的基本一样,其实就是多了当传入的length大于缓冲区的剩余空间时,会将已有的元素覆盖掉。如果发生了元素覆盖,那缓冲区一定会变满,read_index和write_index回相等,对应语句if (length > space_length) rb->read_index = rb->write_index;(也即2.1节中讨论的问题2,读索引要指向最老元素)。因为会操作read_index元素,也要考虑其是否发生了回环,发生了回环后read_mirror需要取反,对应语句rb->read_mirror = ~rb->read_mirror;。图中对应的情形三描述了该过程,开始缓冲区中有两个元素1、2,接着继续写入A、B、C、D、E、F六个元素。此时元素1被覆盖掉,写索引和读索引都指向元素2。
读接口rt_ringbuffer_get和写接口的操作逻辑基本一致,也是通过条件if (rb->buffer_size - rb->write_index > length)将读操作分成了两种情形,过程和写操作接口rt_ringbuffer_put没有差异。
/**
* @brief Put a block of data into the ring buffer. If the capacity of ring buffer is insufficient, it will discard out-of-range data.
*
* @param rb A pointer to the ring buffer object.
* @param ptr A pointer to the data buffer.
* @param length The size of data in bytes.
*
* @return Return the data size we put into the ring buffer.
*/
rt_size_t rt_ringbuffer_put(struct rt_ringbuffer *rb,
const rt_uint8_t *ptr,
rt_uint16_t length)
{
rt_uint16_t size;
RT_ASSERT(rb != RT_NULL);
/* whether has enough space */
size = rt_ringbuffer_space_len(rb);
/* no space */
if (size == 0)
return 0;
/* drop some data */
if (size < length)
length = size;
if (rb->buffer_size - rb->write_index > length)
{
/* read_index - write_index = empty space */
rt_memcpy(&rb->buffer_ptr[rb->write_index], ptr, length);
/* this should not cause overflow because there is enough space for
* length of data in current mirror */
rb->write_index += length;
return length;
}
rt_memcpy(&rb->buffer_ptr[rb->write_index],
&ptr[0],
rb->buffer_size - rb->write_index);
rt_memcpy(&rb->buffer_ptr[0],
&ptr[rb->buffer_size - rb->write_index],
length - (rb->buffer_size - rb->write_index));
/* we are going into the other side of the mirror */
rb->write_mirror = ~rb->write_mirror;
rb->write_index = length - (rb->buffer_size - rb->write_index);
return length;
}
RTM_EXPORT(rt_ringbuffer_put);
/**
* @brief Put a block of data into the ring buffer. If the capacity of ring buffer is insufficient, it will overwrite the existing data in the ring buffer.
*
* @param rb A pointer to the ring buffer object.
* @param ptr A pointer to the data buffer.
* @param length The size of data in bytes.
*
* @return Return the data size we put into the ring buffer.
*/
rt_size_t rt_ringbuffer_put_force(struct rt_ringbuffer *rb,
const rt_uint8_t *ptr,
rt_uint16_t length)
{
rt_uint16_t space_length;
RT_ASSERT(rb != RT_NULL);
space_length = rt_ringbuffer_space_len(rb);
if (length > rb->buffer_size)
{
ptr = &ptr[length - rb->buffer_size];
length = rb->buffer_size;
}
if (rb->buffer_size - rb->write_index > length)
{
/* read_index - write_index = empty space */
rt_memcpy(&rb->buffer_ptr[rb->write_index], ptr, length);
/* this should not cause overflow because there is enough space for
* length of data in current mirror */
rb->write_index += length;
if (length > space_length)
rb->read_index = rb->write_index;
return length;
}
rt_memcpy(&rb->buffer_ptr[rb->write_index],
&ptr[0],
rb->buffer_size - rb->write_index);
rt_memcpy(&rb->buffer_ptr[0],
&ptr[rb->buffer_size - rb->write_index],
length - (rb->buffer_size - rb->write_index));
/* we are going into the other side of the mirror */
rb->write_mirror = ~rb->write_mirror;
rb->write_index = length - (rb->buffer_size - rb->write_index);
if (length > space_length)
{
if (rb->write_index <= rb->read_index)
rb->read_mirror = ~rb->read_mirror;
rb->read_index = rb->write_index;
}
return length;
}
RTM_EXPORT(rt_ringbuffer_put_force);
/**
* @brief Get data from the ring buffer.
*
* @param rb A pointer to the ring buffer.
* @param ptr A pointer to the data buffer.
* @param length The size of the data we want to read from the ring buffer.
*
* @return Return the data size we read from the ring buffer.
*/
rt_size_t rt_ringbuffer_get(struct rt_ringbuffer *rb,
rt_uint8_t *ptr,
rt_uint16_t length)
{
rt_size_t size;
RT_ASSERT(rb != RT_NULL);
/* whether has enough data */
size = rt_ringbuffer_data_len(rb);
/* no data */
if (size == 0)
return 0;
/* less data */
if (size < length)
length = size;
if (rb->buffer_size - rb->read_index > length)
{
/* copy all of data */
rt_memcpy(ptr, &rb->buffer_ptr[rb->read_index], length);
/* this should not cause overflow because there is enough space for
* length of data in current mirror */
rb->read_index += length;
return length;
}
rt_memcpy(&ptr[0],
&rb->buffer_ptr[rb->read_index],
rb->buffer_size - rb->read_index);
rt_memcpy(&ptr[rb->buffer_size - rb->read_index],
&rb->buffer_ptr[0],
length - (rb->buffer_size - rb->read_index));
/* we are going into the other side of the mirror */
rb->read_mirror = ~rb->read_mirror;
rb->read_index = length - (rb->buffer_size - rb->read_index);
return length;
}
RTM_EXPORT(rt_ringbuffer_get);判断缓冲区是否为空或满
判断缓冲区是否为空或满,通过函数rt_ringbuffer_status来实现。其逻辑就是在2.2.3节中介绍的:在读写指针的值相同情况下,如果二者的指示位相同,说明缓冲区为空;如果二者的指示位不同,说明缓冲区为满。注意这里的读写指针已经在读写(rt_ringbuffer_get和rt_ringbuffer_put)过程中转换为了读写索引。
rt_inline enum rt_ringbuffer_state rt_ringbuffer_status(struct rt_ringbuffer *rb)
{
if (rb->read_index == rb->write_index)
{
if (rb->read_mirror == rb->write_mirror)
return RT_RINGBUFFER_EMPTY;
else
return RT_RINGBUFFER_FULL;
}
return RT_RINGBUFFER_HALFFULL;
}小结
- 在多线程中,对同一个环形缓冲区进行读写操作时,需要加上锁,不然存在访问不安全问题;
- 当只有一个读线程和一个写线程时,用
rt_ringbuffer_put和rt_ringbuffer_get进行读写操作缓冲区是线程安全的,无需加锁;但是rt_ringbuffer_put_force不行,因为其可能对读写索引都进行操作的场景,这个时候再进行rt_ringbuffer_get读操作,就是不安全访问; - 读写指针已经在读写(
rt_ringbuffer_get和rt_ringbuffer_put)过程中转换为了读写索引。所以read_index(读索引)和write_index(写索引)可以直接用来操作缓冲区,无需转换; read_index和write_index的大小区间为[0,�−1],�为缓冲区大小;- RT-Thread的环形缓冲区不需要
buffer大小为2的幂。
3.2、 Linux中实现的ring buffer
在linux内核中,kfifo就是ring buffer的经典实现方式,本文将介绍linux 2.6版本中的ring buffer实现方式,主要介绍缓冲区结构体、缓冲区初始化、读操作、写操作、判断缓冲区是否为空或满。
缓冲区结构体
kfifo的ring buffer结构体定义如下,其中buffer、size、in、out和2.2节中介绍的环形缓冲区4个信息是一一对应的。但其中in、out分别是写指针和读指针,而不是写索引和读索引。它们之间的转换关系就是2.2.3节介绍的转化公式。参数lock是自旋锁,在多进程/线程对同一个环形缓冲区进行读写操作时,需要进行锁保护。和RT-Thread对比,可以看到其并没有读写的镜像指示位,判断缓冲区是否为空或满呢?在下一节会进行分析。
struct kfifo {
unsigned char *buffer; /* the buffer holding the data */
unsigned int size; /* the size of the allocated buffer */
unsigned int in; /* data is added at offset (in % size) */
unsigned int out; /* data is extracted from off. (out % size) */
spinlock_t *lock; /* protects concurrent modifications */
};缓冲区初始化
在kfifo的初始化kfifo_init中可以看出,其会对所传入的size大小进行扩展,使其满足size为2的幂。这样就可以使用2.2.3节中介绍的性质,如果缓冲区的长度是2的幂,则可以省略镜像指示位。如果读写指针的值相等,则缓冲区为空;如果读写指针相差n(缓冲区大小),则缓冲区为满。所以在传入buffer的size大小时,最好开始就将其确定为2的幂。
struct kfifo *kfifo_init(unsigned char *buffer, unsigned int size,
int gfp_mask, spinlock_t *lock)
{
struct kfifo *fifo;
/* size must be a power of 2 */
BUG_ON(size & (size - 1));
fifo = kmalloc(sizeof(struct kfifo), gfp_mask);
if (!fifo)
return ERR_PTR(-ENOMEM);
fifo->buffer = buffer;
fifo->size = size;
fifo->in = fifo->out = 0;
fifo->lock = lock;
return fifo;
}读操作和写操作
可以看到kfifo对读操作和写操作的实现非常简洁。在进行读操作和写操作时,其充分利用了无符号整型的性质。在__kfifo_put(写操作)和__kfifo_get(读操作)时,in(写指针)和out(读指针)都是正向增加的,当达到最大值时,产生溢出,使得从0开始,进行循环使用。in(写指针) 和out(读指针) 会恒定的保持如下关系:

其中读指针是out,写指针是in。out(读指针) 永远不会超过in(写指针) 的大小,最多两者相等,相等就是缓冲区为空的时候。再结合在2.2.3节中介绍的转换关系:

就可以对环形缓冲区进行读写操作了,下面来看源码。
先看__kfifo_put的源码。len = min(len, fifo->size - fifo->in + fifo->out);中表达的意思就是实际写入的长度一定要小于缓冲区的可用空间大小,防止发生覆盖已有元素的场景。来看这一句l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));,其中(fifo->in & (fifo->size - 1))就是将in(写指针) 转换为写索引,整体表达的意思是从写索引到缓冲区结束位置这一段所能写入数据的大小,这一段写入操作的代码为memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);。如果这一段还不够,需要折返到缓冲区的开始位置,将剩下的部分写入到缓冲区中,其代码为memcpy(fifo->buffer, buffer + l, len - l);。而且因为取的是较小值len>=l(因为l取的是较小值)),当len=l就说明第一段已经可以容纳所写入大小,缓冲区无需折返,第二个memcpy拷贝了零个字节,相当于什么也没有发生。
再看__kfifo_get的源码。其思路基本和__kfifo_put一致,了解了上面的转换关系,就比较好理解。
/*
* __kfifo_put - puts some data into the FIFO, no locking version
* @fifo: the fifo to be used.
* @buffer: the data to be added.
* @len: the length of the data to be added.
*
* This function copies at most 'len' bytes from the 'buffer' into
* the FIFO depending on the free space, and returns the number of
* bytes copied.
*
* Note that with only one concurrent reader and one concurrent
* writer, you don't need extra locking to use these functions.
*/
unsigned int __kfifo_put(struct kfifo *fifo,
unsigned char *buffer, unsigned int len)
{
unsigned int l;
len = min(len, fifo->size - fifo->in + fifo->out);
/* first put the data starting from fifo->in to buffer end */
l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);
/* then put the rest (if any) at the beginning of the buffer */
memcpy(fifo->buffer, buffer + l, len - l);
fifo->in += len;
return len;
}
EXPORT_SYMBOL(__kfifo_put);
unsigned int __kfifo_get(struct kfifo *fifo,
unsigned char *buffer, unsigned int len)
{
unsigned int l;
len = min(len, fifo->in - fifo->out);
/* first get the data from fifo->out until the end of the buffer */
l = min(len, fifo->size - (fifo->out & (fifo->size - 1)));
memcpy(buffer, fifo->buffer + (fifo->out & (fifo->size - 1)), l);
/* then get the rest (if any) from the beginning of the buffer */
memcpy(buffer + l, fifo->buffer, len - l);
fifo->out += len;
return len;
}
EXPORT_SYMBOL(__kfifo_get);判断缓冲区是否为空或满
kfifo中没有专门的函数判断缓冲区是否为空或满,但可以通过__kfifo_len函数获取缓冲区已存储数据长度。如果其值等于零就说明缓冲区为空,如果其值等于缓冲区大小,就说明缓冲区满。
static inline unsigned int __kfifo_len(struct kfifo *fifo)
{
return fifo->in - fifo->out;
}
4、 总结
- 环形缓冲区(ring buffer)适合于事先明确了缓冲区的最大容量的情形。缓冲区的容量(长度)一般固定,可以用一个静态数组来充当缓冲区,无需重复申请内存;
- 如果缓冲区的大小需要经常调整,就不适合用环形缓存区,因为在扩展缓冲区大小时,需要搬移其中的数据,这种场合使用链表更加合适;
- 因为缓冲区成头尾相连的环形,写操作可能会覆盖未及时读取的数据,有的场景允许这种情况发生,有的场景又严格限制这种情况发生。选择何种策略和具体应用场景相关;
- 环形缓冲区(ring buffer)特别适合于通信双方循环发送数据的场景;
- 镜像指示位是一种高效判断缓冲区是否为空或满的策略,在RT-Thread和linux中都使用了该策略(或者是该策略的扩展),其能够保证在只有一个读线程(或进程)和一个写线程(或进程)中无需锁也能做到线程安全;
- 注意区分写指针和写索引,读指针和读索引,最终对缓冲区进行操作还是需要写索引和读索引;
- 如果自己嵌入式项目中需要使用环形缓冲区(ring buffer),可以借鉴
linux 2.6版本的kfifo实现,很容易改写,而且非常高效。