数据库保护通过四个方面来实现
- 完整性控制
- 安全性控制
- 数据库的恢复
- 并行控制
一、事务的状态及原语操作
一个不可分割的操作序列,其中的操作要么都做,要么都不做
比如银行转账:A账户转到B账户100元。该处理包括两个更新步骤:A=A-100,B=B+100。这两个操作时不可分的。
1. 事务的ACID性质
- 原子性 Atomicity。事务是不可分的原子,其中的操作要么都做,要么都不做
- 一致性 Consistency。事务的执行保证数据库从一个一致状态转到另一个一致状态
- 隔离性 Isolation。多个事务一起执行时相互独立
- 持久性 Durability。事务一旦成功提交,就在数据库永久保存
2. 事务的原语操作

二、数据库的一致性和正确性
- 如果数据库在事务开始执行时是一致的,并且事务执行结束后数据库仍处于一致状态,则数据库满足正确性.
三、数据库故障
1. 故障类型
- 事务故障
- 可预期的事务故障:转账时余额不足
- 不可预期的事故故障:运算溢出
- 介质故障:硬故障(Hard Crash),磁盘损坏。
- 系统故障:软故障(Soft Crash),内存数据丢失,但磁盘数据仍在。
2. 数据库恢复(针对系统故障)
- 基本原则:冗余
- 实现方法:通过备份和日志
四、日志
- 事务日志记录了所有更新操作的具体细节
- 日志文件的登记严格按事务执行的时间次序
- 先写日志(Write-Ahead Log)原则:先把日志记录<T, x, value>写到磁盘,再把数据写到磁盘
1. Undo日志
- Undo日志文件中的内容
- 事务的开始标记(<Start, T>)
- 事务的结束标记(或)
- 日志记录<T, x, old-value>分别表示事务标识,操作对象,更新前值(插入为空)
- 先把数据写入磁盘后,将日志记录写到磁盘
- 日志记录<T, x, v>
- 数据写到磁盘
- 结束<commit, T>
- 有的事务肯定已写回磁盘
没有记录的结果可能还未写回磁盘,因此在恢复时要Undo
基于Undo日志的恢复
- 从头扫描日志,找出没有<commit, T>或者<abort, T>的所有事务,放入一个事务列表L中。
- 从尾部开始扫描日志记录<T, x, v>,如果T∈L,则write(x, v),out(x)
- 对L中的每一个事务T,把<abort, T>写到日志中。
2. Redo日志
- Redo日志文件中的内容
- 事务的开始标记()
- 事务的结束标记(或)
- 日志记录<T, x, new-value>分别表示事务标识,操作对象,更新后值
- 先日志记录写到磁盘,再把数据写入磁盘
- 日志记录<T, x, v>
- 结束<commit, T>
- 数据写到磁盘
- 没有记录的操作必定没有改写磁盘数据,因此在恢复时可以不理会
有记录的结果可能还未写回磁盘,因此在恢复时要Redo
基于Redo日志的恢复
- 从头扫描日志,找出有<commit, T>的所有事务,访日一个事务列别L中。
- 从头部开始扫描日志记录<T, x, v>,如果T∈L,则write(x, v),out(x)
- 对于每一个事物T!∈L,把<abort, T>写到日志中
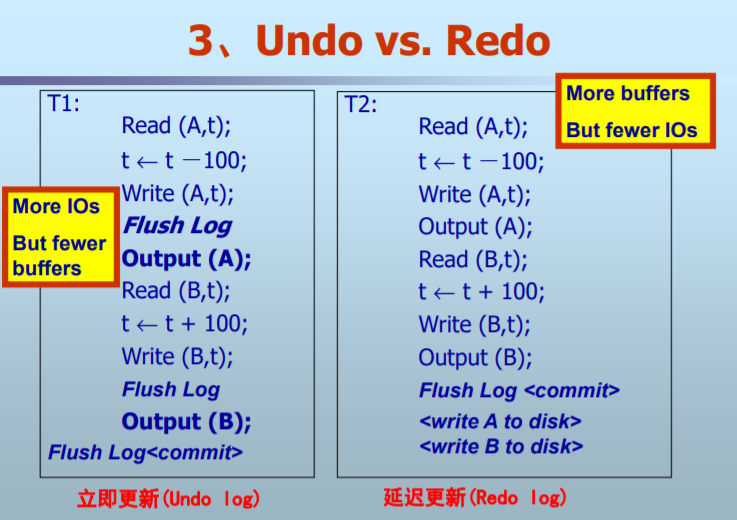
3. Undo vs Redo
Undo基于立即更新(immidate update)
- 日志记录<T, x, v>
- 数据写到磁盘
- 结束<commit, T>
Redo基于延迟更新(Deferred update)
- 日志记录<T, x, v>
- 结束<commit, T>
- 数据写到磁盘
4. Undo/Redo日志
- 日志中的数据修改记录<T, x, v, w>,v是旧值,w是新值。
- 可以立即更新,也可以延迟更新
基于Undo/Redo日志的恢复
- 正向扫描日志,将的事务放入Redo列表中,将没有结束的事务放入Undo列表
- 反向扫描日志,对于<T,x,v,w>,若T在Undo列表中,则Write(x,v); Output(x)
- 正向扫描日志,对于<T,x,v,w>,若T在Redo列表中,则Write(x,w); Output(x)
- 对于Undo列表中的T,写入<abort,T>
 |  |
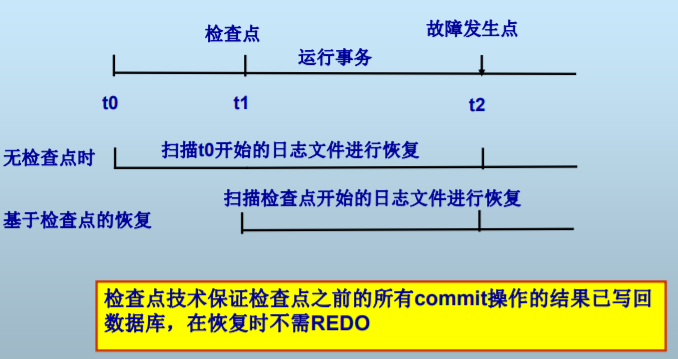
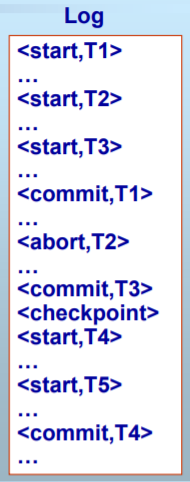
七、检查点技术(Checkpoint)
当系统故障发生时,必须扫描日志。需要搜索整个日志来确定UNDO列表和REDO列表
- 搜索过程太耗时,因为日志文件增长很快
- 会导致最后产生的REDO列表很大,使恢复过程变得很长
检查点技术保证检查点之前的所有commit操作的结果已写回数据库,在恢复时不需REDO