0、前言
在《LeNet5及手势识别案例》文章中,我们基于LeNet-5网络结构,根据【gestures】手势数据集做了模型训练和预测
YOLO作为目前CV领域的扛把子,分类、检测等任务样样精通,本文将根据之前的gestures】手势数据集,换用YOLO来做手势预测的分类任务,看看效果如何
1、准备工作
要进行模型训练,首先要导入对应的数据集
安装YOLO之后,通常会有一个默认的数据集路径,运行YOLO程序时也是去对应的路径下找数据集,如果找不到,则程序也会无法正常跑下去,需要自己每次手动指定数据集的路径,这样就会相对麻烦,也不够规范
因此,我们需要找到这个默认数据集路径,将其调整到电脑中合适的目录下,方便后面使用
下面以windows电脑为例,介绍查找和调整这个路径的方法:
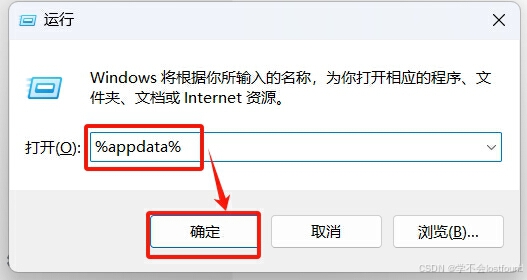
Step1: 依次先后按下 win + R 键,打开windows运行窗口
Step2: 输入%appdata%,然后按下回车键或点击【确定】按钮
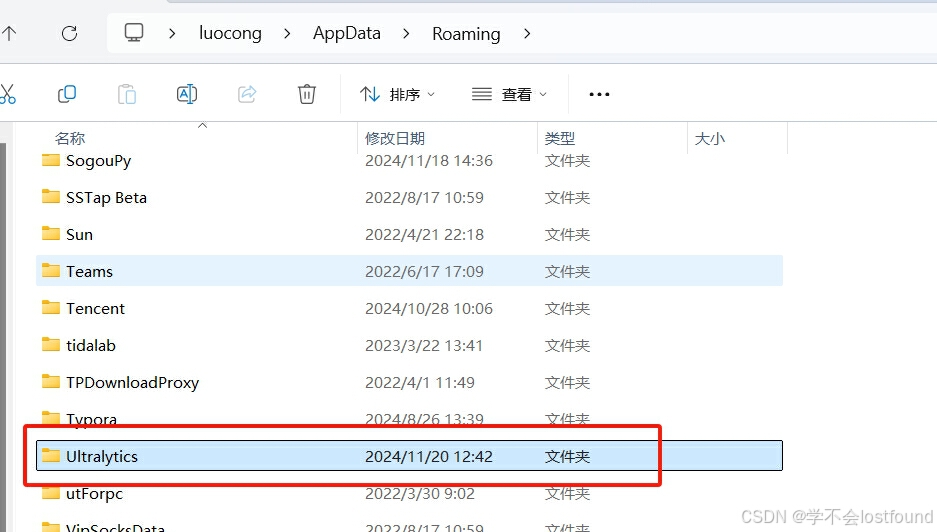
Step3: 找到Ultralytics文件夹,点击进入
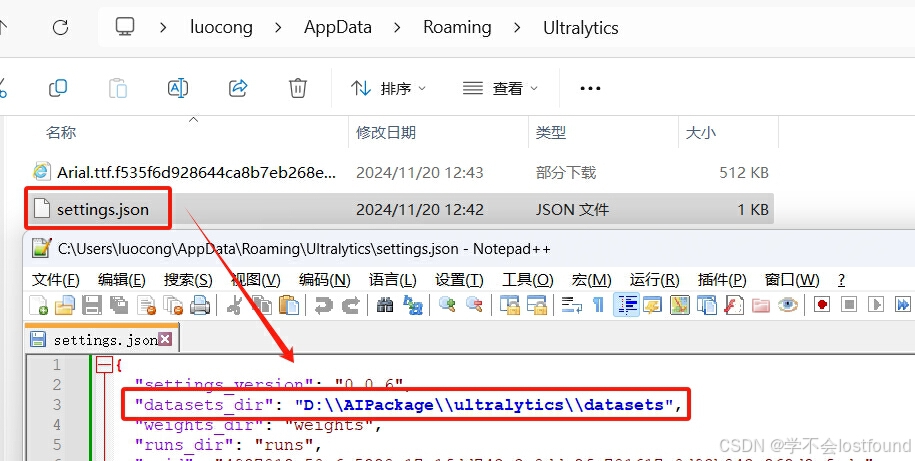
Step4: 找到setting文件(根据版本不同,可能叫做setting.yaml,也可能叫做setting.json),打开文件,并对datasets_dir配置进行编辑,改成合适的目录(一般选一个磁盘比较大的目录即可,方便放很多以后要用的数据集)
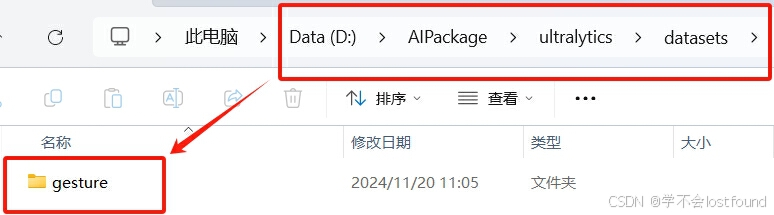
在做完上述操作之后,将手势数据集放置到上面配置好的默认数据集目录下即可
2、模型训练
依旧是三行代码(from、YOLO()、model.train())打天下
# 解决OMP问题
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'
# 1. 引入 YOLO
from ultralytics import YOLO
# 2. 加载/从零构建模型
model = YOLO("yolo11n-cls.yaml")
# 3. 训练模型
if __name__ == '__main__':
# data="gesture": 指定训练数据集的路径和名称
# epochs=10: 设置训练多少轮(10轮)
# imgsz=128: 设置输入图像的大小(128*128像素)
# batch=8: 设置每一轮训练中每一批次多少个图像(10轮,每轮每批次8张图)
results = model.train(data="gesture", epochs=10, imgsz=128, batch=8)训练完成之后,会自动保存best.pt,可根据训练过程的日志来查看其路径(也可以一个一个找,一般在最后一个trainxx文件夹里面)
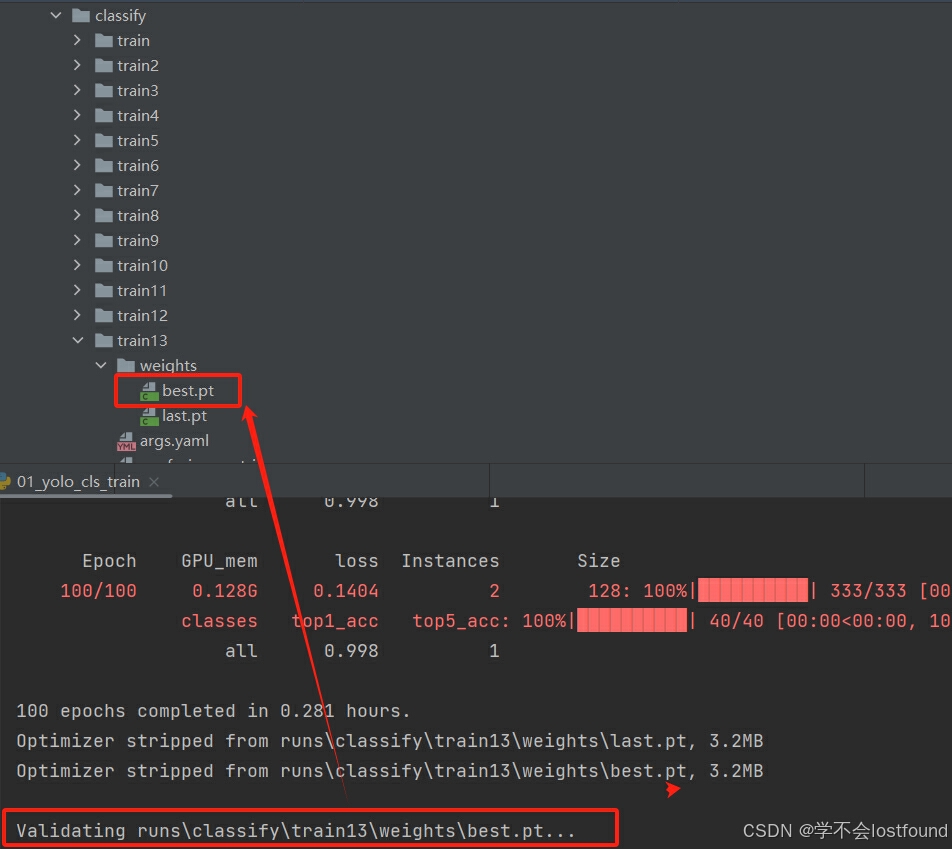
3、页面展示
新建一个modelApp.py文件,将下面代码复制粘贴到文件中,并将上面得到的best.pt文件放置于modelApp.py文件的同级别目录
import streamlit as st
import torch
from PIL import Image
from ultralytics import YOLO
if __name__ == "__main__":
# 显示当前设备是GPU设备还是CPU
device = "cuda" if torch.cuda.is_available() else "cpu"
st.write(f"当前设备是:{device}")
# 加载模型
model = YOLO("best.pt")
# 上传一张图片
uploaded_img = st.file_uploader("请上传一张图片", type=["png", "jpg", "jpeg"])
# 将上传的图像文件保存到临时文件
if uploaded_img is not None:
with open(file="temp_img.jpg", mode="wb") as f:
f.write(uploaded_img.getvalue())
img_path = "temp_img.jpg"
if img_path:
# 加载训练好的best.pt模型
pred = model(img_path)
print(pred)
# 显示上传好的图片
img = Image.open(fp=img_path)
st.image(image=img, caption="上传的图片", use_column_width=True)
# 使用plot方法可视化
pred_img = pred[0].plot()
st.image(pred_img, caption="预测结果", use_column_width=True)使用以下命令运行modelApp.py,通过streamlit页面进行使用
streamlit run modelApp.py效果展示(显示了每个可能的手势对应的概率),比LetNet-5的准确率要高(对于非纯色背景的手势更友好,可以尝试拍自己手掌试一试)
