(一)安装hadoop,在/home/hadoop下创建目录
app 存放所有的软件的安装目录
data 存放测试数据
lib 存放jar
software 存放软件安装包的目录
source 存放框架源码
(二)hadoop生态系统:5.7.0
所有的Hadoop生态的的软件下载地址:http://archive.cloudera.com/cdh5/cdh/5/
jdk: 1.8(被依赖于spark)
spark: 2.2
scala: 2.11.8
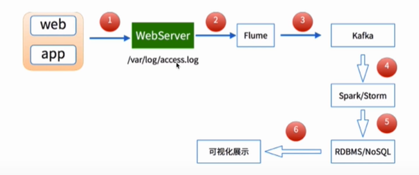
(三)项目架构
日志收集:Flume
离线分析:MapReduce/Spark
统计结果图形化展示
(四)问题:耗时长
解决办法==>实时流处理框架
(五)
1.实时流处理产生背景
时效性高 数据量大
2.概述
实时计算 流式计算 实时流式计算
(六)
1.离线计算与实时计算的对比
1)数据来源
离线:HDFS历史数据 数据量比较大
实时:消息队列Kafka,实时新增/修改记录过来的某一笔数据
2)处理过程
离线:MapReduce :map + reduce
实时:Spark(DStream/SS)
3) 处理速度
离线:慢
实时:快速
4)进程
离线:启动 + 销毁
实时:24小时
2.实时流处理框架对比
>Apache storm
>Apache Spark Streaming
>IBM Stream
>Yahoo!S4
>Kafka(流处理上不太用,不太广泛)
>Flink
3.实时流处理架构及技术选型