引入线程
在C++网络编程(四):多进程并发服务器一文中,使用fork函数实现了多进程并发服务器,但是也提到了一些问题:
- fork是昂贵的。fork时需要复制父进程的所有资源,包括内存映象、描述字等;
- 目前的实现使用了一种写时拷贝(copy-on-write)技术,可有效避免昂贵的复制问题,但fork仍然是昂贵的;
- fork子进程后,父子进程间、兄弟进程间的通信需要进程间通信IPC机制,给通信带来了困难; 多进程在一定程度上仍然不能有效地利用系统资源
- 系统中进程个数也有限制。
除此之外最重要的还有一点:每秒少则数十次、多则上千次的“上下文切换”是创建进程的最大开销。
为了保持多进程优点并克服缺点,我们需要引入线程,线程具有以下优点:
- 线程的创建和上下文切换比进程更快
- 线程间交换数据时无需特殊技术
具体原因如下:多个线程之间会共享全局变量和堆等资源,具体可见多线程之间共享哪些资源?,这种方式可以带来上述的两种优点:
- 上下文切换时不需要切换全局数据区和堆
- 可以利用全局数据区和堆交换数据
线程创建及运行
线程具有单独的执行流,需要单独定义线程的main函数,还需要请求操作系统在单独的执行流中执行该函数,创建线程的函数如下:
#include<pthread.h>
int pthread_create(
pthread_t * restrict thread,const pthread_attr_t * restrict attr,
void * (*start_routine)(void *),void * restrict arg
);
返回值:成功时返回0,失败时返回其它值
参数:
thread:保存新创建线程ID的变量地址值。
attr:用于传递线程属性的参数,传递NULL时创建默认属性的线程
start_routine:相当于线程main函数的、在单独执行流中执行的函数地址值(函数指针)。
arg:通过第三个参数传递调用函数时包含传递参数信息的变量地址值。
代码示例:
thread1.c
#include<stdio.h>
#include<pthread.h>
void *thread_main(void *arg);
int main(){
pthread_t t_id;
int thread_param=5;
if(pthread_create(&t_id,NULL,thread_main,(void*)&thread_param)!=0){
puts("pthread_create() error");
return -1;
}
sleep(10);
puts("end of main");
return 0;
}
void *thread_main(void *arg){
int i;
int cnt=*((int*)arg);
for(i=0;i<cnt;i++){
sleep(1);
puts("running thread");
}
return NULL;
}
使用以下命令编译运行(-l用于指定动态链接库):
gcc thread1.c -o thread1 -lpthread
./thread1
运行结果:
(注:linux的sleep以秒为单位)
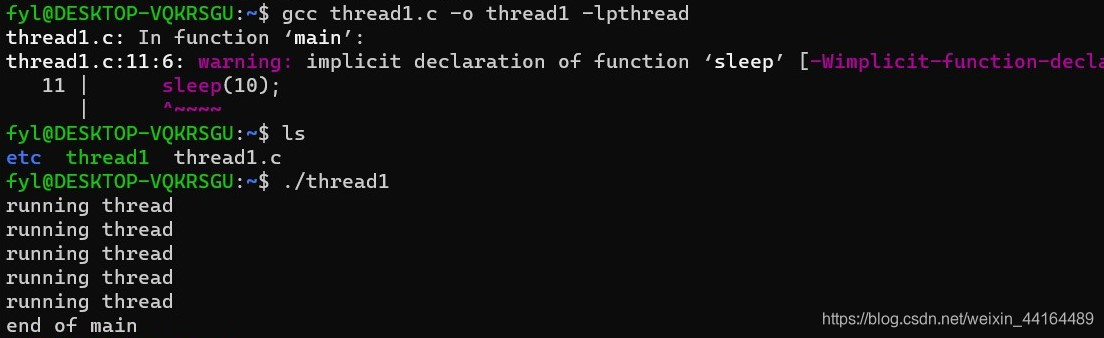
thread1.c的执行流程如下:
显然,如果我们把上面代码中的sleep(10)改成sleep(2),就不会输出5次“running thread”了,因为main函数返回后整个进程将被销毁,执行过程将变成下面这样:
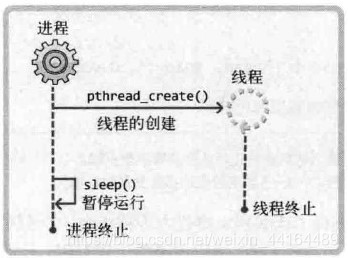
由此可以看出,为线程提供足够的运行时间是很重要的一件事情,但如果我们使用sleep设定一个时间就相当于要预测程序的执行流程,这是不可能准确预测的事情。
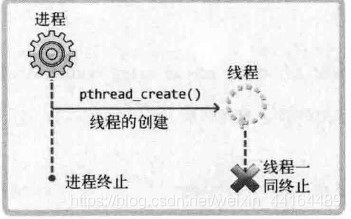
因此,我们不用sleep函数,而是通常利用pthread_join函数来控制线程的执行流,如下:
#include<pthread.h>
int pthread_join(pthread_t thread,void ** status);
返回值:成功返回0,失败返回其他值
参数:
thread:该参数值ID的线程终止后才会从函数返回
status:保存线程的main函数返回值的指针变量地址值
调用该函数的进程或线程会进入等待状态,直到第一个参数为ID的线程终止为止,而且可以得到线程的main函数返回值。
代码示例:
thread2.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <pthread.h>
void *thread_main(void *arg);
int main(int argc, char *argv[])
{
pthread_t t_id;
int thread_param = 5;
void *thr_ret;
// 请求创建一个线程,从 thread_main 调用开始,在单独的执行流中运行。同时传递参数
if (pthread_create(&t_id, NULL, thread_main, (void *)&thread_param) != 0)
{
puts("pthread_create() error");
return -1;
}
//main函数将等待 ID 保存在 t_id 变量中的线程终止
if (pthread_join(t_id, &thr_ret) != 0)
{
puts("pthread_join() error");
return -1;
}
printf("Thread return message : %s \n", (char *)thr_ret);
free(thr_ret);
return 0;
}
void *thread_main(void *arg) //传入的参数是 pthread_create 的第四个
{
int i;
int cnt = *((int *)arg);
char *msg = (char *)malloc(sizeof(char) * 50);
strcpy(msg, "Hello,I'am thread~ \n");
for (int i = 0; i < cnt; i++)
{
sleep(1);
puts("running thread");
}
return (void *)msg; //返回值是 thread_main 函数中内部动态分配的内存空间地址值
}
使用以下命令编译运行(-l用于指定动态链接库):
gcc thread2.c -o thread2 -lpthread
./thread1
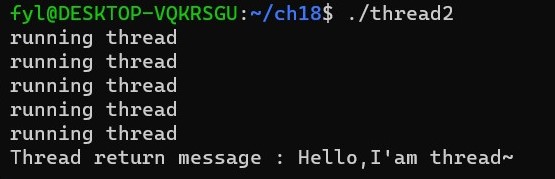
运行结果:
执行流程图如下:
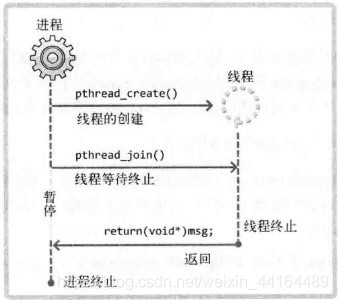
线程安全
我们需要考虑多个线程同时执行临界区代码带来的问题,我们可将函数分为:
- 线程安全函数
- 非线程安全函数
线程安全函数被多个线程同时调用也不会引发问题,在linux中线程安全函数的名称后缀通常为_r,通过声明头文件前定义_REENTRANT宏可以自动将函数名gethostbyname变成gethostbyname_r,具体可见-D_REENTRANT 宏作用。
同时我们可以不必为了上述宏定义特意添加#define语句,可以在编译时通过添加-D_REENTRANT选项定义宏。
如:
gcc -D_REENTRANT mythread.c -o mthread -lpthread
工作线程模型
接下来介绍创建多个线程的情况。
比如我们要计算1到10的和,创建两个线程,一个线程计算1到5的和,另一个线程计算6-10的和,main函数只负责输出运算结果。这种编程模型叫做“工作线程模型”,计算1到5之和与计算6到10之和的线程将成为main线程管理的工作。
执行流程如下:
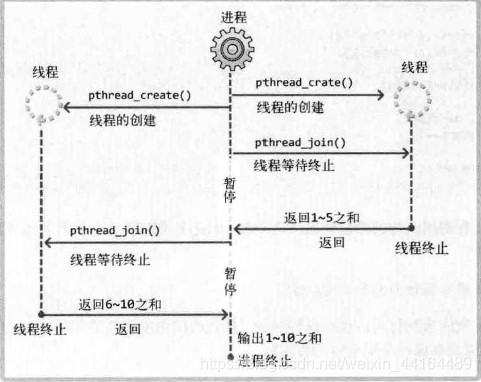
代码示例:
注意以下代码有临界区相关问题
#include <stdio.h>
#include <pthread.h>
void *thread_summation(void *arg);
int sum = 0;
int main(int argc, char *argv[])
{
pthread_t id_t1, id_t2;
int range1[] = {
1, 5