人工智能咨询培训老师叶梓 转载标明出处
如何有效利用多个大模型(LLM)代理解决复杂任务一直是一个研究热点。由美国南加州大学、宾夕法尼亚州立大学、华盛顿大学、早稻田大学和谷歌DeepMind的研究人员联合提出了一种新的解决方案——自适应团队构建(Adaptive In-conversation Team Building),旨在通过动态管理和组建团队来提高问题解决的效率和准确性。
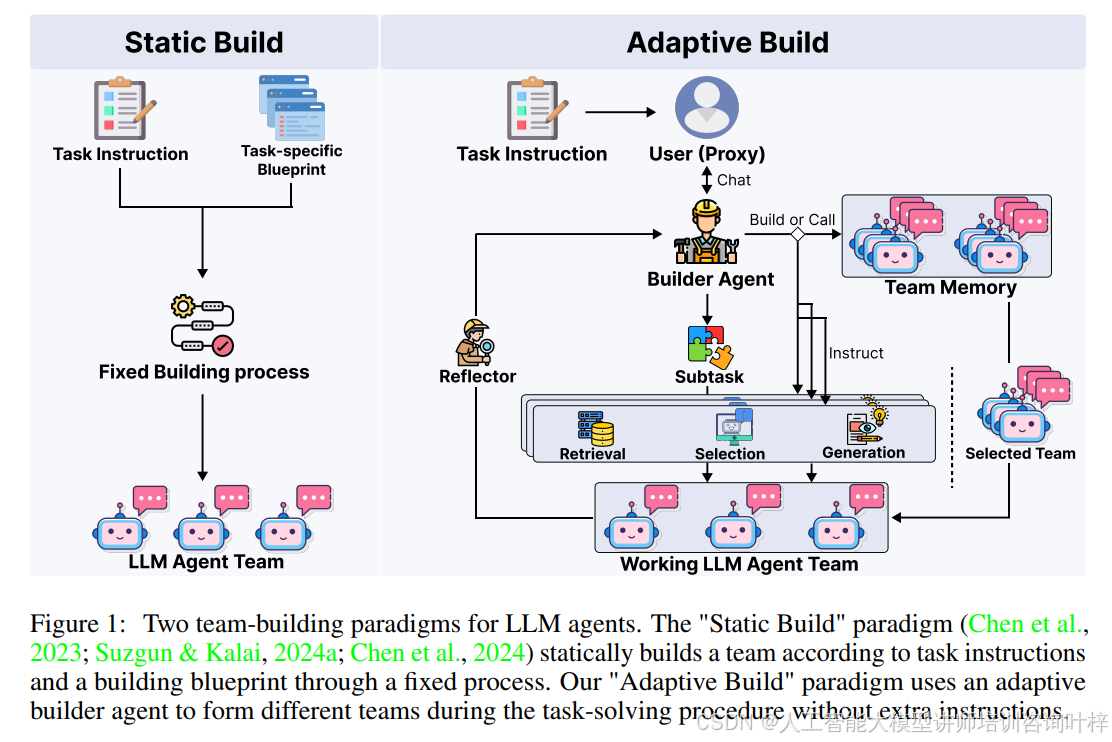
Figure1展示了两种团队构建范式,即“静态构建”和“自适应构建”。传统的静态构建是根据任务指令和构建蓝图通过固定流程构建团队,而自适应构建则是在任务解决过程中由自适应构建代理(Captain Agent)动态形成不同团队,无需额外指令。在面对任务需求变化时静态构建方法缺乏灵活性,而自适应构建方法则可以根据任务解决过程中的需求动态调整团队成员,以适应任务的动态变化。
方法
该方法通过Captain Agent实现,包含两个关键组件:(1) 自适应多代理团队构建,涉及代理和工具的检索、选择和生成;(2) 嵌套群组对话及反思机制。
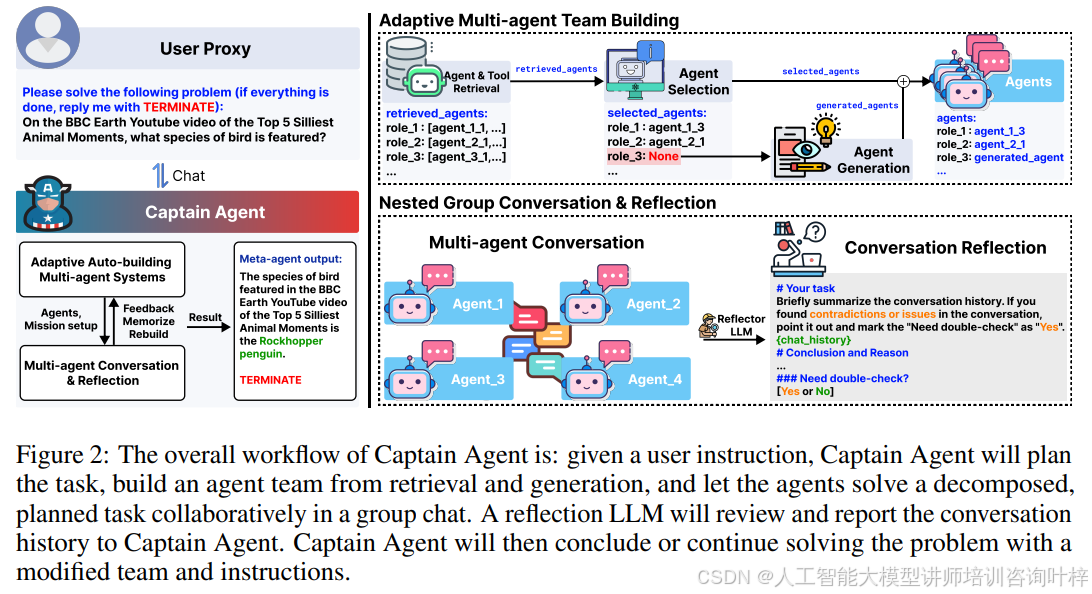
Captain Agent的工作流程在Figure 2中进行了说明。给定一个任务,Captain Agent会首先制定计划,然后重复以下两个步骤,直到认为任务完成并输出结果:
Step 1,Captain Agent识别由提示指导的子任务,列出所需的几个角色,并据此通过检索、选择和生成创建相应的代理团队。每个代理都会配备从工具库中检索到的预定义工具;
Step 2,这些代理将尝试通过与自由形式工具的对话来解决子任务。完成后,一个反思型大模型(LLM)将为Captain Agent提供反思报告,以决定是否调整团队或子任务指令,或终止并输出结果。
在Step 1中,Captain Agent根据相应的提示识别子任务后,会列出几个角色。这些角色将进入由检索增强生成(Retrieval-Augmented Generation, RAG)引导的检索、选择和生成过程。创建的代理将配备设计良好的个人资料(系统消息1)和高质量的工具。整个流程在Figure 3中进行了说明。包括根据Captain Agent提示的角色描述检索候选代理和工具,将候选代理与角色绑定,选择最合适的代理,并在没有合适代理的情况下生成新代理。
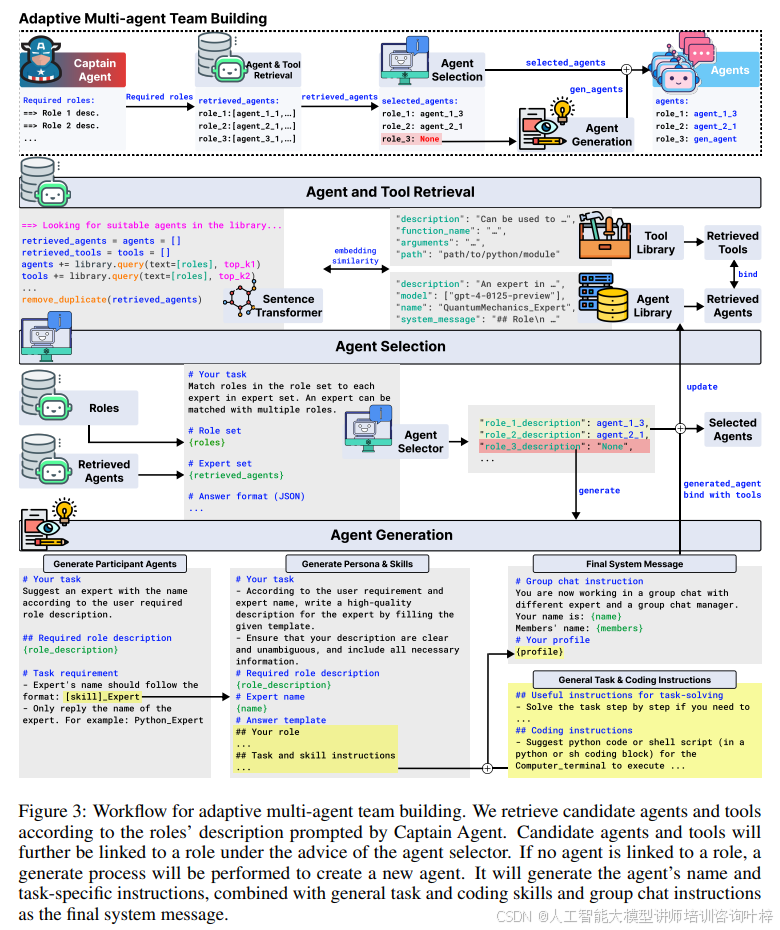
代理和工具检索:Captain Agent会提示n个所需的角色{ri|i ∈ 1, · · · , n},包括所需的技能和可能的角色名称。然后根据角色描述和代理/工具库中记录的代理/工具描述之间的句嵌入相似度,检索top-k1代理和top-k2工具。使用Sentence Transformer计算角色和库代理/工具之间的描述嵌入,并使用余弦相似度作为衡量两个句子相似度的指标,如下所示:
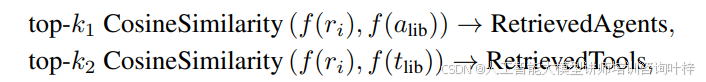
其中k1和k2分别是从代理库alib和工具库tlib中检索的代理和工具的数量,f(·)表示从Sentence Transformer提取的句子嵌入。检索后,每个角色将被分配k1个代理候选和k2个有价值的工具。通过将工具使用指令注入到相应代理的系统消息中,将代理候选与检索到的工具绑定。
代理选择:提示一个基于LLM的代理选择器,根据Captain Agent给出的角色描述和检索到的代理描述,选择最合适的代理。设计了一个JSON模板以确保格式正确。特别地,为代理选择器设计了一个弃权机制,如果top-k1检索候选列表中没有适合某个角色的代理,代理选择器可以输出"None"。这可以防止不相关或多余的代理被强制选入当前任务。标记为"None"的角色将进入下一步的生成过程。
代理生成:为上一步中没有链接代理的角色设计了一个代理生成过程。具体来说,根据Captain Agent给出的角色描述生成代理的名称和所需技能。这些指令将与一般任务和编码指令以及群聊指令结合,作为最终的系统消息。手动设计了一般任务和编码指令,受到思维链(Chain-of-thought, CoT)和反思(Reflexion)的启发。最终的系统消息也将被压缩成单句描述,供嵌套群聊使用。然后根据描述从工具库中检索工具,并将工具使用指令注入到生成的系统消息中。
团队记忆:一旦团队建立,Captain Agent会将其缓存到本地内存中,包括团队名称和每个代理的详细信息,如名称、系统消息和分配的工具。Captain Agent可以在与用户代理的对话中随时调用缓存的团队。调用缓存的团队不会引入任何API调用,因此不会引入额外的成本。
Step 2中,在自适应多代理团队构建过程中选出和创建的代理将加入一个嵌套群组聊天室。他们将被提示从用户任务中收集信息,并通过嵌套对话解决Captain Agent的子任务。然后提示一个反思型LLM检索和审查对话历史,并在预设计模板中填写结论、结论原因、可能的矛盾和问题,并标记结果是否需要双重检查。
嵌套群组对话:通过利用AutoGen框架和新设计的工具使用范式,将所有代理放入一个聊天室,并由群聊管理器LLM根据对话历史和每个代理的身份选择每个回合的发言人。从代理的个人资料中生成一个简短的描述,供群聊管理器使用。代理的代码和工具调用将被执行并立即反馈到对话中。将工具的描述、Python模块路径和响应案例注入到相关代理的系统消息中。然后代理可以按照工具的描述和路径自由编写代码,自然地将工具融入到更大的程序中。所有代理编写的程序将由用户代理代理在一个共享代码执行环境中执行,并将结果实时反馈到对话中。
对话反思:代理在对话中的输出可能不一致,包括事实错误、幻觉和刻板印象。尽管其他代理有机会在对话中进行调整和纠正,但有时也可能陷入困境,导致问题解决失败。因此,提出了通过提示一个反思型LLM与精心设计的对话总结提示模板来检测对话中的矛盾和问题。反思器在检测到这种不一致内容时会标记“需要双重检查”为“Yes”,并提供详细理由。这将触发Captain Agent启动一个验证过程,通过构建一个新的嵌套对话来双重检查先前的结果,在收到“Yes”关于“需要双重检查”后。
静态团队由于成员数量有限,可能无法全面覆盖所需能力。尽管构建大量具备全面人物设定或技能的代理可以扩展能力范围,但LLM智能体介绍所有参与者的长上下文存在难度,这会降低对话质量。同时,功能重叠的智能体也可能参与到问题解决中。与之相对,Captain Agent能够根据当前任务的具体情况,自适应地选择和构建更加优化的智能体团队,既减轻了LLM的提示负担,也减少了不相关智能体的冗余输出,同时保证了团队的多样性。
评估
Table 1 展示了进行主要实验选择的场景和对应的数据集。除了数学问题(MATH)外,对整个数据集进行了主要比较实验。对于MATH,根据每种问题类型的原始分布抽取了一个小样本子集。

- 数学问题:MATH数据集包含196个问题,例如求解方程
中m不能取的实数值。
- 编程问题:HumanEval数据集包含164个编程问题,例如定义一个函数
truncate_number,将一个正浮点数分解为整数部分和小于1的小数部分。 - 数据分析:DABench数据集包含257个数据分析问题,例如通过求和“SibSp”和“Parch”列生成一个新特征“FamilySize”,然后计算“FamilySize”和“Fare”列之间的皮尔逊相关系数。
- 世界信息检索:GAIA数据集包含165个问题,例如BBC Earth YouTube视频中“Top 5 Silliest Animal Moments”中出现了哪种鸟类。
- 科学问题(化学和物理):SciBench数据集包含41个化学问题和34个物理问题,例如计算1.25克氮气在250立方厘米的烧瓶中在20°C时产生的压力,以及计算在静态摩擦系数为0.4时,块体开始滑动的角度θ。
这些场景和数据集的选择旨在全面评估Captain Agent与基线模型的性能,覆盖计算和认知技能的关键维度。由于成本限制,对MATH数据集进行了样本抽取。
对于数学、编程、数据分析和科学场景,比较了Captain Agent和四种不同的方法,包括Vanilla LLM、AutoAgents、Meta-prompting、AgentVerse和DyLAN。所有这些方法都使用gpt-4-0125-preview作为底层模型,并使用相同的任务特定提示。
对于世界信息检索场景,将Captain Agent与GAIA验证排行榜上的前五个基线进行比较,所有基线都使用gpt-4-1106-preview作为底层模型。
对于数学、数据分析和科学场景,通过比较每种方法的最终结果和真实情况来报告准确性。为确保评估的公平性,将不同的结果格式转换为统一格式。对于编程场景,运行每种方法提供的代码,并在代码成功通过所有测试时输出一个唯一标记。
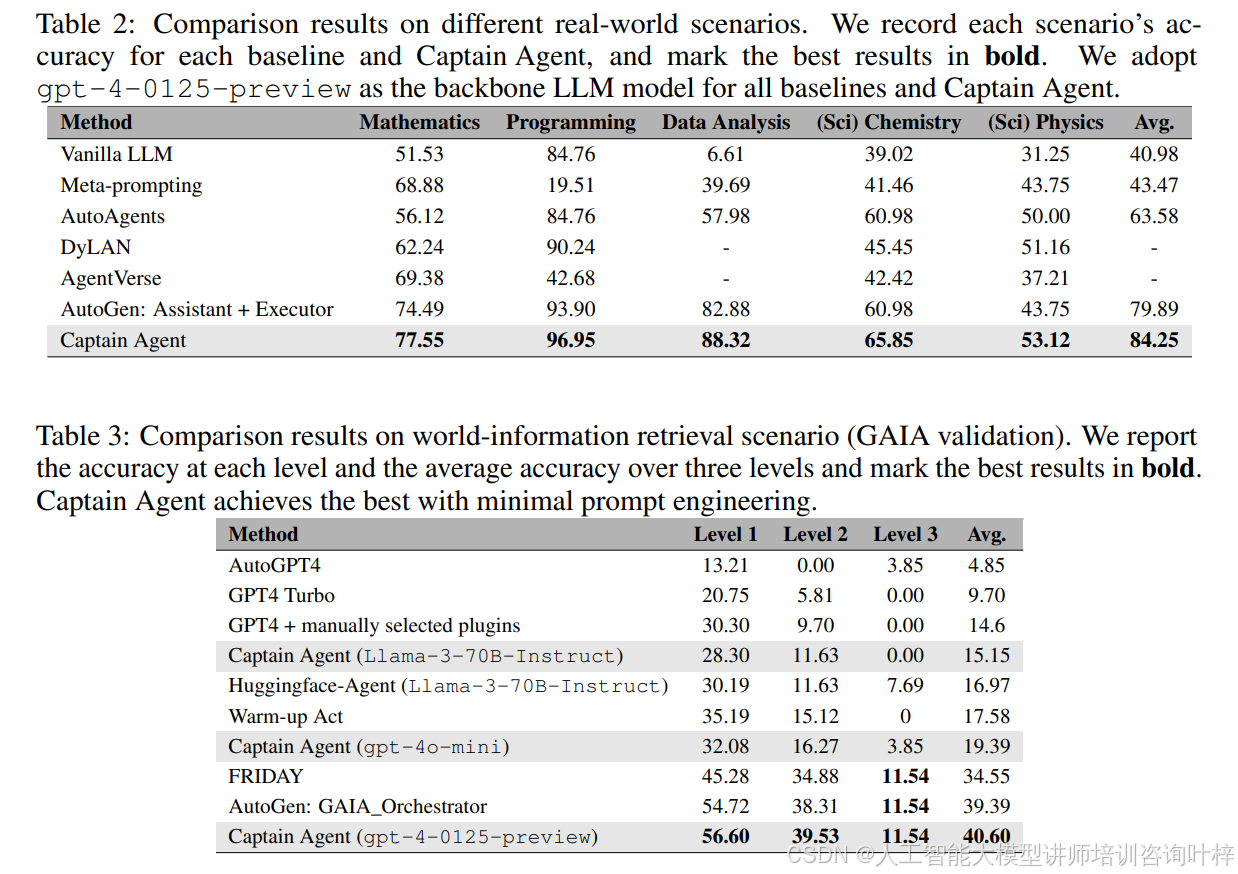
Table 2 和 Table 3 报告了Captain Agent和八个不同的基线在六个真实场景中的比较结果。
-
发现1:多样化的代理可以帮助触发解决问题所需的专业知识输出。通过比较Captain Agent、AutoAgents和AutoGen助手+执行者的结果,观察到Captain Agent和AutoAgents平均性能优于AutoGen助手+执行者。这些场景需要专业知识,而AutoGen助手由于固定系统消息的限制,难以完成。
-
发现2:自适应团队构建在没有任务偏好的情况下提高了性能。Captain Agent在所有场景中的出色表现表明其不受任务类型的限制。适时引入不同的代理,使Captain Agent能够逐步解决复杂问题。
在Table 1的子集上进行消融研究。具体来说,根据AutoGenBench随机选择了MATH的17个问题和HumanEval的25个问题,这些问题是从GPT-4失败集中随机选择的。对于DABench,随机选择了25个问题,对于SciBench,根据教科书的数量随机选择了化学和物理的19个问题。评估协议与前面相同。
-
静态与自适应团队构建:为了进一步探索自适应团队构建的力量,比较了自适应团队构建与静态团队构建。具体来说,通过在每个任务开始时以与Captain Agent相同的方式构建代理团队,并让它们解决每个问题。Table 4中总结的结果表明,自适应团队构建范式全面优于静态团队构建范式。
-
工具库和代理库的消融研究:对工具库和代理库的效用进行了消融研究。轮流移除工具库、代理库以及两个库,并评估在世界信息检索任务上的性能,即GAIA数据集。Table 5显示,移除代理库和工具库都会显著损害系统的性能。虽然工具库和代理库可以独立提高性能,但只有在两个库同时使用时才能获得最佳结果。处理1级任务需要适度的网络浏览和推理步骤,这可以通过几次单轮次工具调用或专家编写和迭代执行代码来实现。引入代理库和工具库可以使系统在网络交互中更稳定、更健壮,从而提高性能。值得注意的是,如果没有代理库,Captain Agent在2级任务上的表现要差得多。这些任务更加复杂,主要涉及大量的网络导航和推理步骤。网络浏览涉及复杂且动态的交互,这不适合静态工具库。这些任务要求代理协调多个工具来解决问题,这是一个在充满不确定性的网络场景中容易出错的过程。
-
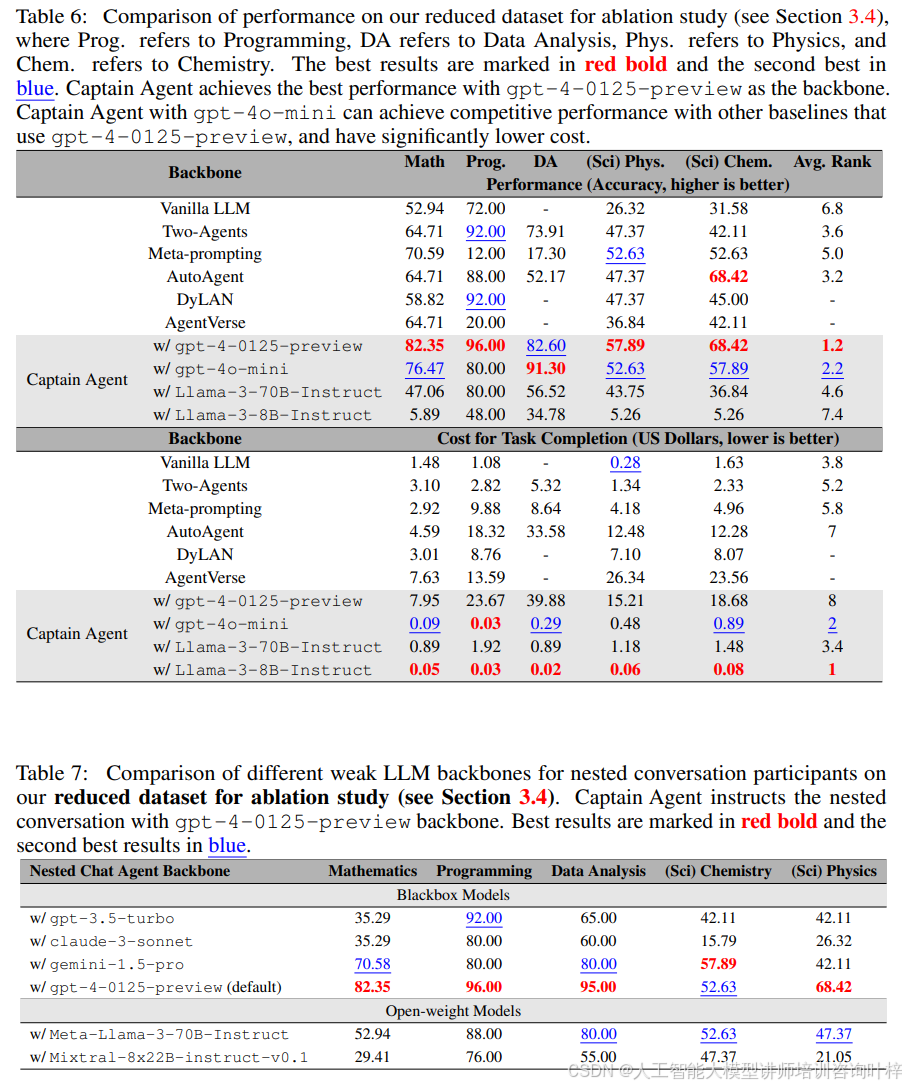
LLM主干的消融研究:探索了LLM主干选择对Captain Agent性能的影响。进行了两种实验设置:Captain Agent和团队成员使用弱LLM,Captain Agent使用强主干,嵌套聊天成员使用弱LLM。首先为Captain Agent及其嵌套专家配备了四种不同的主干,即gpt-4-0125-preview、gpt-4o-mini、LLaMA-3-70B-Instruct和LLaMA-3-8BInstruct,并与所有使用gpt-4-0125-preview作为基线的基线进行比较。Table 6显示,使用gpt-4o-mini的Captain Agent超越了所有其他基线。然后,将Captain Agent的主干固定为gpt-4-0125-preview,并为嵌套聊天的专家使用不同的主干LLM,包括gpt-3.5-turbo、claude-3-sonnet、gemini-1.5-pro以及开放权重模型如LLaMA-3-70B和Mixtral-8x22B。Table 7记录了结果。带有gemini-1.5-pro的聊天成员在大多数场景中表现第二好。比较这两种设置的结果,可以观察到通过在Captain Agent中使用更强的LLM主干来指导嵌套对话,系统的性能得到了显著提升。
-
成本分析:与LLM相关的高令牌成本一直是实际部署代理的一个重大障碍,使其在经济上不可行。计算了Captain Agent工作流程的总成本,包括生成Captain Agent输出、执行代理和工具选择、专家生成和嵌套聊天对话。成本在Table 6中报告。通过利用更小、成本效益更高的gpt-4o-mini,该方法在保持强大性能的同时显著降低了成本,每项任务的平均成本低至0.33美元。


论文中提到的相关工作和框架可以通过以下链接进一步了解:AutoGen | AutoGen