油菜提取
遥感图像农作物提取是遥感图像处理中重要的应用之一。当前遥感图像油菜提取主要采用基于分割的方法,包括传统的基于阈值、区域生长等方法和基于机器学习的方法,如基于支持向量机和随机森林等方法,以及深度学习模型,如语义分割。本文尝试使用阈值法、传统机器学习以及深度学习模型等方法,探讨适合油菜提取的可行性方案。
使用的数据
选取2-5月哨兵2影像的2波段、3波段、4波段以及8波段(分别对应BGR和近红外)4个波段的油菜花期影像。
阈值法
1. 观察油菜花期影像
肉眼观察出的特征是油菜在遥感影像中呈现黄绿色。如果想提取油菜,最简单的办法是将图像中的黄绿色部分提取出来。
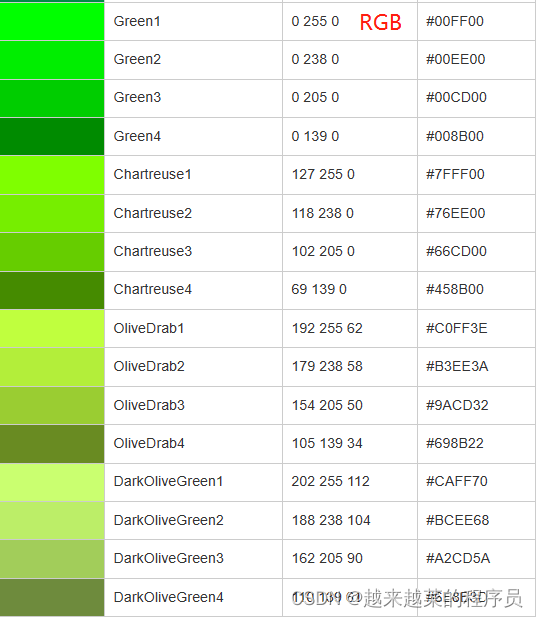
我们可以看到rgb颜色对照表发现呈现出黄绿的颜色的rgb值有一个特征,就是红色波段和绿色波段的值比较高,蓝色波段的值比较低,这个规律也很容易想到,因为 #ffff00是纯黄色,黄绿色是纯黄色接近的颜色,也应该满足红绿波段高于蓝波段这个特点。
考虑如何利用这个特征,我们可以尝试用以下公式:
归一化黄度指数 = (绿波段 + 红波段 - 蓝波段) / (绿波段 + 红波段 + 蓝波段)
用公式表示为: NDYI = (G + R - B) / (G + R + B)
利用上述公式计算出的归一化油菜指数如下图:
上述两幅图分别是原图和归一化黄度指数,可以看到,该指数可以一定程度上反应油菜的分布,接下来我们在NDYI指数上设置一个合适的阈值,尝试使用阈值法提取油菜,提取的结果如下:
上图展示了使用阈值法提取的油菜,从结果上看效果还是很不错的,基本上肉眼看到的油菜都被提取出来了,那是不是这个方法能使用与所有区域呢?我继续尝试了其他区域结果如下:



我们可以看到换到另外一个区域,得到的结果非常差,显示光秃秃的雪山附近长满了油菜,这显然是错误的。

2. 阈值法的局限性
尽管上述方法对有些区域效果还不错,但阈值法有一个通病,即只能很好地提取设置阈值范围内的值。遥感图像复杂,可能出现异物同普、同物异普的特性。当换一个区域或者遇到遥感图像云覆盖或者质量不好区域时,阈值法的效果就会变差。
阈值法提取代码:
def extract_target_area2(band1_file, band2_file, band3_file, output_file, geotransform=True,
project=True):
'''
计算归一化差分黄体指数:(band2+band3-2*band1)/(band2+band3+2*band1)
:param band1_file: 遥感影像文件1 蓝波段
:param band2_file: 遥感影像文件2 红波段
:param band3_file: 遥感影像文件3 绿波段
:param output_file: 输出油菜植被区域(二值图)
:param geotransform: 如果为True则用input_file的信息,否则用传入的geotransform
:param project: 如果为True则用input_file的信息,否则用传入的project
:return:
'''
gdal.AllRegister()
gdal.SetConfigOption('gdal_FILENAME_IS_UTF8', 'YES')
band1_dataset = gdal.Open(band1_file, gdal.GA_ReadOnly)
band2_dataset = gdal.Open(band2_file, gdal.GA_ReadOnly)
band3_dataset = gdal.Open(band3_file, gdal.GA_ReadOnly)
raster_cols = band1_dataset.RasterXSize
raster_rows = band1_dataset.RasterYSize
rows_block_size = 1000
cols_block_size = 1000
if geotransform is True:
geotransform = band1_dataset.GetGeoTransform()
if project is True:
project = band1_dataset.GetProjection()
yc_data = np.zeros([raster_rows, raster_cols], dtype=float)
# bz_arr = []
for j in range(0, raster_rows, rows_block_size):
for i in range(0, raster_cols, cols_block_size):
# 数据竖向步长
if j + rows_block_size < raster_rows:
rows_step = rows_block_size
else:
rows_step = raster_rows - j
# 数据横向步长
if i + cols_block_size < raster_cols:
cols_step = cols_block_size
else:
cols_step = raster_cols - i
# 分块读取数据
array1 = GdalUtils.read_block_data(band1_dataset, 1, cols_step, rows_step, start_col=i,
start_row=j) # blue_block
array2 = GdalUtils.read_block_data(band2_dataset, 1, cols_step, rows_step, start_col=i,
start_row=j) # green_block
array3 = GdalUtils.read_block_data(band3_dataset, 1, cols_step, rows_step, start_col=i,
start_row=j) # red_block
# 油菜rgb波段之间的关系
# 绿波段比红波段多 5%~25%
row1, col1 = array2.shape
grcz = np.zeros((row1, col1))
cz23 = (array2 > array3) & ((array2 - array3) > 0.05 * array3) & ((array2 - array3) < 0.30 * array3)
grcz[cz23] = 1
# 红波段 比 蓝波段至少高10%
rbcz = np.zeros((row1, col1))
cz31 = (array3 > array1) & ((array3 - array1) > 0.10 * array1)
rbcz[cz31] = 1
# 绿色比蓝波段至少高15%
gbcz = np.zeros((row1, col1))
cz21 = (array2 > array1) & ((array2 - array1) > 0.15 * array1)
gbcz[cz21] = 1
# 绿波段 + 红波段 > 2 * 蓝波段
rgbcz = array3 + array2 - 2 * array1
rgbcz[rgbcz > 0] = 1
rgbcz[rgbcz < 0] = 0
# 条件叠加 得到最终的油菜种植区域
gmvy = grcz + rbcz + gbcz + rgbcz
gmvy[gmvy < 4] = 0
gmvy[gmvy == 4] = 1
yc_data[j:j + rows_step, i:i + cols_step] = gmvy
del array1, array2, array3, grcz, rgbcz, gmvy, rbcz
points_break = detect_breakpoints(yc_data)
yc_data[points_break == 1] = 0
GdalUtils.write_file(yc_data, geotransform, project, output_file, 'GTiff')
dataset = None
del yc_data
机器学习方法
这里我们使用大家比较熟悉的随机森林来提取油菜。
- 样本:使用阈值法提取效果好的油菜区域作为训练样本。
- 特征:选择RGBN四个波段。
直接给大家展示提取结果,下图展示了使用随机森林提取油菜的结果,从图像上来看油菜区域基本上被提取出来了,我们继续尝试其他区域看看提取效果。
下图是使用随机森林提取的另外一个区域的油菜结果,从图像上可以看来很多非油菜区域也被提取出来了,这是因为随机森林只关注孤立的点是否满足油菜特征,忽略了油菜的上下文语义信息,导致很多非油菜也被误认为是油菜。

随机森林代码如下:

# 训练随机森林模型
def get_random_class(rgbn, yc, rgbn1, rgbn2):
rgbn_arr = GdalUtils.read_file(rgbn)
blue_file = rgbn_arr[0]
green_file = rgbn_arr[1]
red_file = rgbn_arr[2]
nir_file = rgbn_arr[3]
# 添加非油菜区域1
rgbn_arr1 = GdalUtils.read_file(rgbn1)
blue_file1 = rgbn_arr1[0]
green_file1 = rgbn_arr1[1]
red_file1 = rgbn_arr1[2]
nir_file1 = rgbn_arr1[3]
width1, height1 = GdalUtils.get_file_size(rgbn1)
fyc1 = np.zeros((height1, width1), dtype=int)
arr_combine_fyc1 = np.column_stack(
(blue_file1.flatten(), green_file1.flatten(), red_file1.flatten(), nir_file1.flatten(), fyc1.flatten()))
arr_combine_fyc1 = arr_combine_fyc1.reshape(-1, 5)
# 添加啊非油菜区域2
rgbn_arr2 = GdalUtils.read_file(rgbn2)
blue_file2 = rgbn_arr2[0]
green_file2 = rgbn_arr2[1]
red_file2 = rgbn_arr2[2]
nir_file2 = rgbn_arr2[3]
width2, height2 = GdalUtils.get_file_size(rgbn2)
fyc2 = np.zeros((height2, width2), dtype=int)
arr_combine_fyc2 = np.column_stack(
(blue_file2.flatten(), green_file2.flatten(), red_file2.flatten(), nir_file2.flatten(), fyc2.flatten()))
arr_combine_fyc2 = arr_combine_fyc2.reshape(-1, 5)
# output_dir = os.path.join(out_dir, input_name[0:-12])
# # 文件夹检测 文件输出路径设置
# create_folder(output_dir)
yc_file = GdalUtils.read_file(yc)
# 油菜数据
arr_cond = yc_file != 0
yc1 = yc_file[yc_file == 1]
arr1_yc = blue_file[arr_cond]
arr2_yc = green_file[arr_cond]
arr3_yc = red_file[arr_cond]
arr4_yc = nir_file[arr_cond]
arr_combine_yc = np.column_stack(
(arr1_yc.flatten(), arr2_yc.flatten(), arr3_yc.flatten(), arr4_yc.flatten(), yc1.flatten()))
arr_combine_yc = arr_combine_yc.reshape(-1, 5)
# 非油菜数据
arr_cond1 = yc_file == 0
yc0 = yc_file[yc_file == 0]
arr1_fyc = blue_file[arr_cond1]
arr2_fyc = green_file[arr_cond1]
arr3_fyc = red_file[arr_cond1]
arr4_fyc = nir_file[arr_cond1]
arr_combine_fyc = np.column_stack(
(arr1_fyc.flatten(), arr2_fyc.flatten(), arr3_fyc.flatten(), arr4_fyc.flatten(), yc0.flatten()))
arr_combine_fyc = arr_combine_fyc.reshape(-1, 5)
random_columns_fyc = np.random.choice(arr_combine_fyc.shape[0], size=40000, replace=False)
selected_columns_fyc = arr_combine_fyc[random_columns_fyc, :]
yc_data = np.concatenate((arr_combine_yc, selected_columns_fyc, arr_combine_fyc1, arr_combine_fyc2), axis=0)
x = yc_data[:, :4]
y = yc_data[:, -1]
# 拆分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)
# 创建模型并训练
# model = DecisionTreeClassifier()
# 创建随机森林分类器
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
rf_classifier.fit(X_train, y_train)
# 将分类模型保存到本地文件
with open('model.pickle', 'wb') as f:
pickle.dump(rf_classifier, f)
# 预测
y_pred = rf_classifier.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
# 打印准确率
print('Accuracy:', accuracy)
# 将矩阵转换为 Pandas 数据帧
df = pd.DataFrame(yc_data)
# 将数据帧保存为 CSV 文件
df.to_csv('data.csv', header=['blue', 'green', 'red', 'nir', 'yc'], index=False)
return yc_data
使用卷积神经网络(CNN)
使用Unet + ResNet网络进行油菜的图像分割。通过训练样本,网络可以学习如何分割出油菜区域。
接下来展示分割效果如下图,从下面图像上来看使用卷积神经网络提取油菜,看起来确实是注意到了上下文语义信息,不存在大面积的错题现象。但是它也不是完美的,可以放大一个区域仔细观察一下。
通过观察我们发现,unet模型提取油菜样本时候,存在错提、漏提、以及无法提取油菜细节轮廓等问题,这是因为unet在做这种像素级别的语义分割时,在上采样到原图尺寸时候很难避免信息的丢失,其实这是常规语义分割的通病,他们更适合大目标的提取,对于小目标甚至像素界别的提取,使用一般的语义分割往往不能满足要求。
unet-resnet 网络结构代码如下:


from torch import nn
from torch.nn import functional as F
import torch
from torchvision import models
import torchvision
__all__ = ['UNetResNet', 'unetresnet']
def unetresnet(pretrained=False, **kwargs):
""""UNetResNet model architecture
"""
model = UNetResNet(pretrained=pretrained, **kwargs)
if pretrained:
# model.load_state_dict(state['model'])
pass
return model
def conv3x3(in_, out):
return nn.Conv2d(in_, out, 3, padding=1)
class ConvRelu(nn.Module):
def __init__(self, in_, out):
super().__init__()
self.conv = conv3x3(in_, out)
self.activation = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.activation(x)
return x
class DecoderBlockV2(nn.Module):
def __init__(self, in_channels, middle_channels, out_channels, is_deconv=True):
super(DecoderBlockV2, self).__init__()
self.in_channels = in_channels
if is_deconv:
"""
Paramaters for Deconvolution were chosen to avoid artifacts, following
link https://distill.pub/2016/deconv-checkerboard/
"""
self.block = nn.Sequential(
ConvRelu(in_channels, middle_channels),
nn.ConvTranspose2d(middle_channels, out_channels, kernel_size=4, stride=2,
padding=1),
nn.ReLU(inplace=True)
)
else:
self.block = nn.Sequential(
nn.Upsample(scale_factor=2, mode='bilinear'),
ConvRelu(in_channels, middle_channels),
ConvRelu(middle_channels, out_channels),
)
def forward(self, x):
return self.block(x)
class UNetResNet(nn.Module):
"""PyTorch U-Net model using ResNet(34, 101 or 152) encoder.
UNet: https://arxiv.org/abs/1505.04597
ResNet: https://arxiv.org/abs/1512.03385
Proposed by Alexander Buslaev: https://www.linkedin.com/in/al-buslaev/
Args:
encoder_depth (int): Depth of a ResNet encoder (34, 101 or 152).
num_classes (int): Number of output classes.
num_filters (int, optional): Number of filters in the last layer of decoder. Defaults to 32.
dropout_2d (float, optional): Probability factor of dropout layer before output layer. Defaults to 0.2.
pretrained (bool, optional):
False - no pre-trained weights are being used.
True - ResNet encoder is pre-trained on ImageNet.
Defaults to False.
is_deconv (bool, optional):
False: bilinear interpolation is used in decoder.
True: deconvolution is used in decoder.
Defaults to False.
"""
def __init__(self, encoder_depth=34, num_classes=4, in_channels=3, num_filters=32, dropout_2d=0.2,
pretrained=False, is_deconv=False):
super().__init__()
self.num_classes = num_classes
self.dropout_2d = dropout_2d
if encoder_depth == 34:
self.encoder = torchvision.models.resnet34(pretrained=pretrained)
bottom_channel_nr = 512
elif encoder_depth == 101:
self.encoder = torchvision.models.resnet101(pretrained=pretrained)
bottom_channel_nr = 2048
elif encoder_depth == 152:
self.encoder = torchvision.models.resnet152(pretrained=pretrained)
bottom_channel_nr = 2048
else:
raise NotImplementedError('only 34, 101, 152 version of Resnet are implemented')
self.pool = nn.MaxPool2d(2, 2)
self.relu = nn.ReLU(inplace=True)
self.conv1 = nn.Sequential(self.encoder.conv1,
self.encoder.bn1,
self.encoder.relu,
self.pool)
self.conv2 = self.encoder.layer1
self.conv3 = self.encoder.layer2
self.conv4 = self.encoder.layer3
self.conv5 = self.encoder.layer4
self.center = DecoderBlockV2(bottom_channel_nr, num_filters * 8 * 2, num_filters * 8, is_deconv)
self.dec5 = DecoderBlockV2(bottom_channel_nr + num_filters * 8, num_filters * 8 * 2, num_filters * 8, is_deconv)
self.dec4 = DecoderBlockV2(bottom_channel_nr // 2 + num_filters * 8, num_filters * 8 * 2, num_filters * 8,
is_deconv)
self.dec3 = DecoderBlockV2(bottom_channel_nr // 4 + num_filters * 8, num_filters * 4 * 2, num_filters * 2,
is_deconv)
self.dec2 = DecoderBlockV2(bottom_channel_nr // 8 + num_filters * 2, num_filters * 2 * 2, num_filters * 2 * 2,
is_deconv)
self.dec1 = DecoderBlockV2(num_filters * 2 * 2, num_filters * 2 * 2, num_filters, is_deconv)
self.dec0 = ConvRelu(num_filters, num_filters)
self.final = nn.Conv2d(num_filters, num_classes, kernel_size=1)
def forward(self, x):
conv1 = self.conv1(x)
conv2 = self.conv2(conv1)
conv3 = self.conv3(conv2)
conv4 = self.conv4(conv3)
conv5 = self.conv5(conv4)
pool = self.pool(conv5)
center = self.center(pool)
dec5 = self.dec5(torch.cat([center, conv5], 1))
dec4 = self.dec4(torch.cat([dec5, conv4], 1))
dec3 = self.dec3(torch.cat([dec4, conv3], 1))
dec2 = self.dec2(torch.cat([dec3, conv2], 1))
dec1 = self.dec1(dec2)
dec0 = self.dec0(dec1)
return self.final(F.dropout2d(dec0, p=self.dropout_2d))
if __name__ == '__main__':
net = UNetResNet(34, 3)
input = torch.randn((2, 3, 512, 512))
output = net(input)
print(output.size())
在油菜提取任务中,有几个特点,数据分辨率很低,无法清晰看见目标轮廓,由于一个分辨率代表实际地块的10M*10M,这就要求我们需要更进细化的提取油菜地块,针对上述问题,提出了针对油菜数据特点的深度学习模型YcNet模型,该模型主要特点是引入了特征金字塔结构,将输入数据重采样到不同尺度,将深层语义特征和浅层语义特征进行多尺度融合,使得模型在学习上下文语义特征是,也注意到油菜细节信息,很大程度改善了油菜错误、遗提、模型忽略细节等问题。
YcNet模型
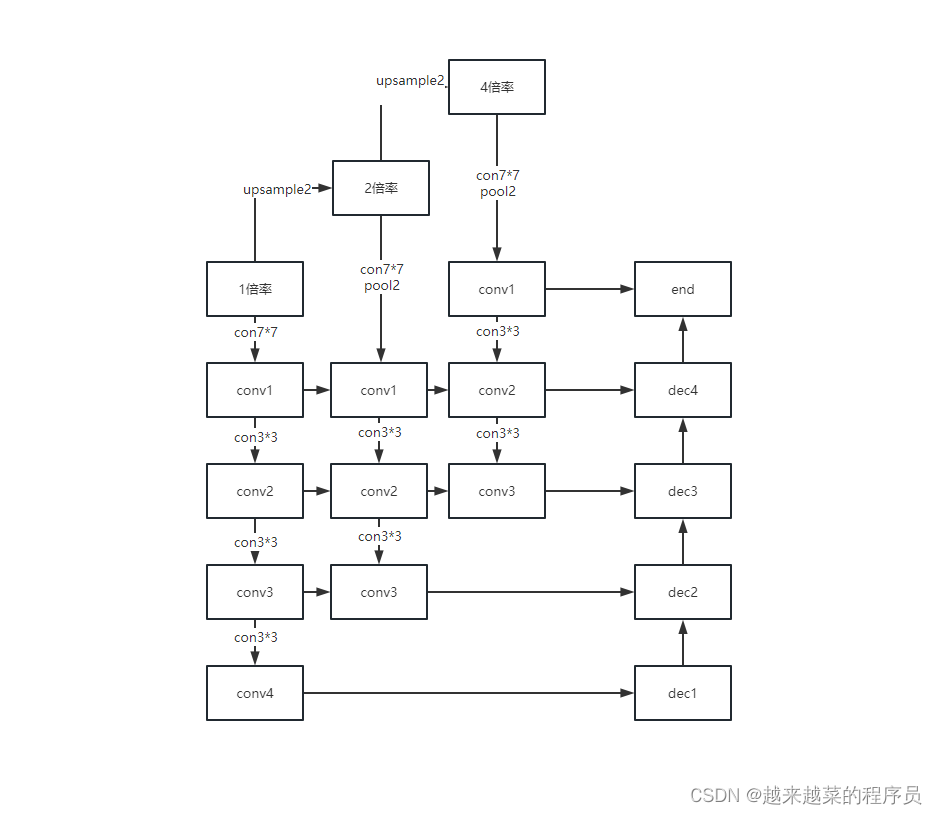
针对油菜数据特点,和常规语义风格的缺点,我们提出了YcNet模型,引入了不同倍率上采样的特征金字塔结构,将不同尺度的特征进行融合,大大的改善了油菜提取效果。YcNet更能注意到细节和小地块的同时保证模型的轻量级。
模型结构图如下,对原图进行了二倍上采样和四倍上采样,分别对不同尺度的数据进行编码解码,再进行特征融合得,保证数据在学习到深层的语义特征同时也不忽略对浅层的学习,将不同尺度特征进行融合得到最终的输出。
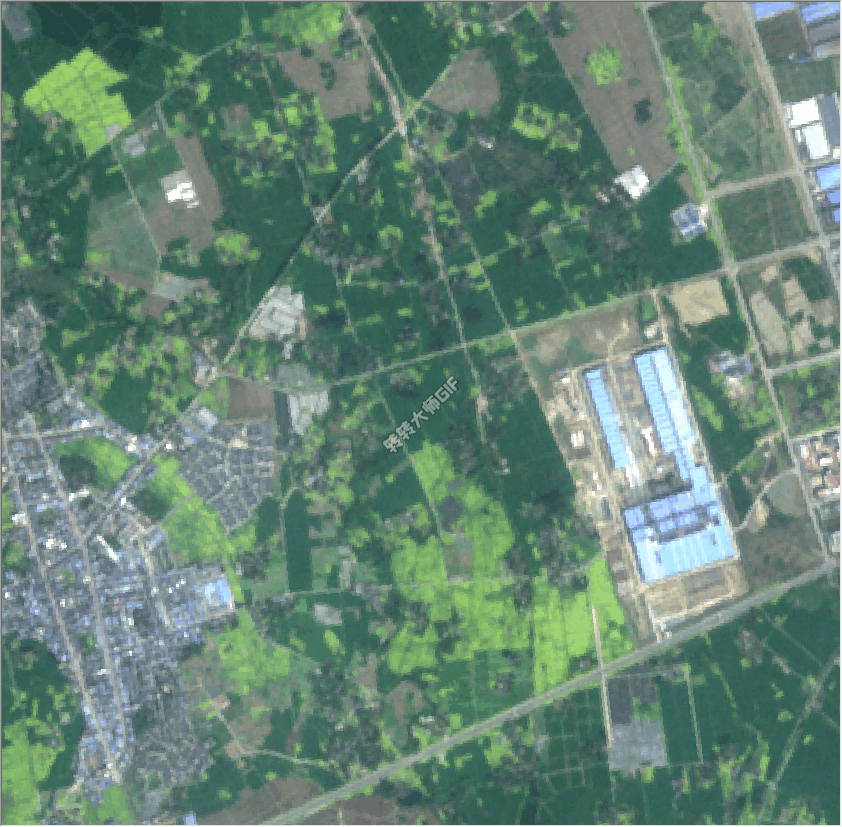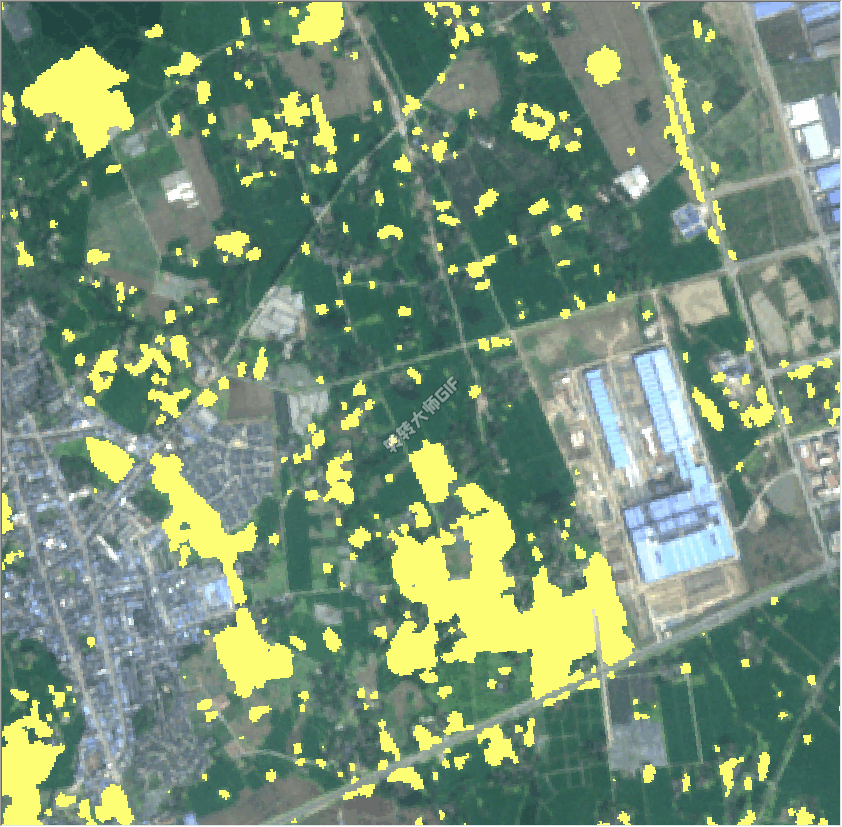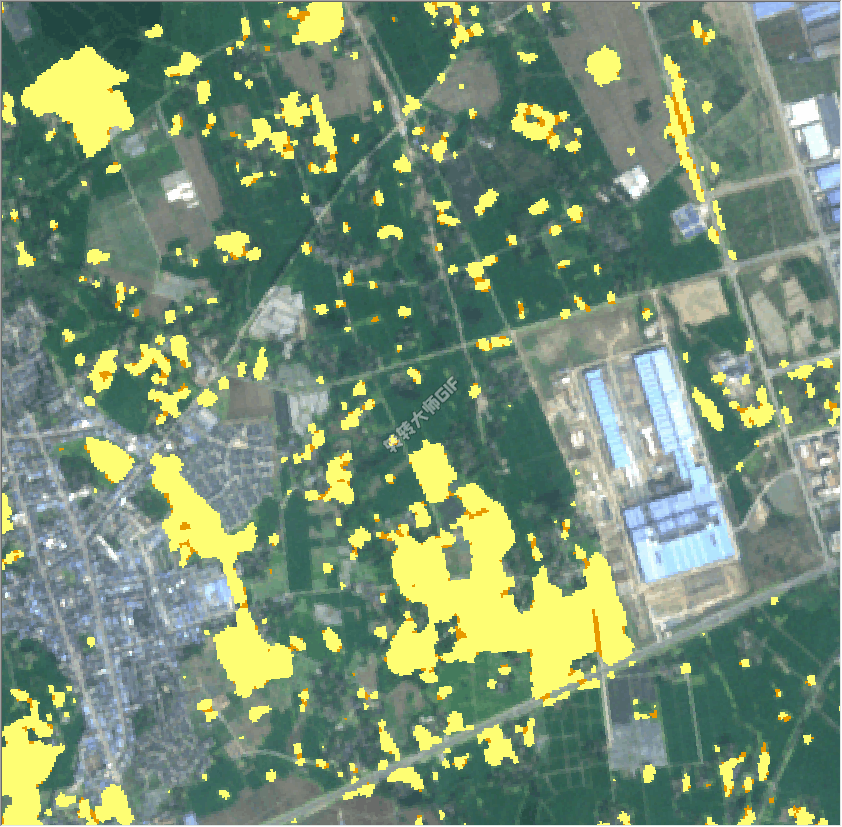
YcNet模型的运行效果如下图,可以看出来能基本上提取油菜区域,继续展示细节信息对比说明YcNet模型相较与unet的优势和适用性。
下图展示了使用Ycnet模型后预测结果更加能注意到油菜的细节轮廓和改善了错提现象,其中黄色为YcNet模型提取结果,褐色为Unet模型提取的结果。
下图展示了YcNet模型相较与unet模型更加注意细小的地块,大大改善了小地块漏提问题,其中黄色为YcNet模型提取结果,褐色为Unet模型提取的结果。
YcNet网络结果代码如下:


from torch import nn
from torch.nn import functional as F
import torch
from torchvision import models
import torchvision
__all__ = ['UNetResNet', 'unetresnet']
def unetresnet(pretrained=False, **kwargs):
""""UNetResNet model architecture
"""
model = UNetResNet(pretrained=pretrained, **kwargs)
if pretrained:
# model.load_state_dict(state['model'])
pass
return model
def conv3x3(in_, out):
return nn.Conv2d(in_, out, 3, padding=1)
class ConvRelu(nn.Module):
def __init__(self, in_, out):
super().__init__()
self.conv = conv3x3(in_, out)
self.activation = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.activation(x)
return x
class DecoderBlockV2(nn.Module):
def __init__(self, in_channels, middle_channels, out_channels, is_deconv=True):
super(DecoderBlockV2, self).__init__()
self.in_channels = in_channels
if is_deconv:
"""
Paramaters for Deconvolution were chosen to avoid artifacts, following
link https://distill.pub/2016/deconv-checkerboard/
"""
self.block = nn.Sequential(
ConvRelu(in_channels, middle_channels),
nn.ConvTranspose2d(middle_channels, out_channels, kernel_size=4, stride=2,
padding=1),
nn.ReLU(inplace=True)
)
else:
self.block = nn.Sequential(
nn.Upsample(scale_factor=2, mode='bilinear'),
ConvRelu(in_channels, middle_channels),
ConvRelu(middle_channels, out_channels),
)
def forward(self, x):
return self.block(x)
class DecoderBlockV1(nn.Module):
def __init__(self, in_channels, middle_channels, out_channels, is_deconv=True):
super(DecoderBlockV1, self).__init__()
self.in_channels = in_channels
if is_deconv:
"""
Paramaters for Deconvolution were chosen to avoid artifacts, following
link https://distill.pub/2016/deconv-checkerboard/
"""
self.block = nn.Sequential(
ConvRelu(in_channels, middle_channels),
nn.ConvTranspose2d(middle_channels, out_channels, kernel_size=4, stride=2,
padding=1),
nn.ReLU(inplace=True)
)
else:
self.block = nn.Sequential(
# nn.Upsample(scale_factor=2, mode='bilinear'),
ConvRelu(in_channels, middle_channels),
ConvRelu(middle_channels, out_channels),
)
def forward(self, x):
return self.block(x)
class BasicConv(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, relu=True,
bn=True, bias=False):
super(BasicConv, self).__init__()
self.out_channels = out_planes
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding,
dilation=dilation, groups=groups, bias=bias)
self.bn = nn.BatchNorm2d(out_planes, eps=1e-5, momentum=0.01, affine=True) if bn else None
self.relu = nn.ReLU(inplace=True) if relu else None
def forward(self, x):
x = self.conv(x)
if self.bn is not None:
x = self.bn(x)
if self.relu is not None:
x = self.relu(x)
return x
class UNetResNet(nn.Module):
def __init__(self, encoder_depth=34, num_classes=4, in_channels=3, num_filters=32, dropout_2d=0.2,
pretrained=False, is_deconv=False):
super().__init__()
self.num_classes = num_classes
self.dropout_2d = dropout_2d
self.upsample_4d = torch.nn.Upsample(scale_factor=4, mode='bilinear', align_corners=False)
if encoder_depth == 34:
self.encoder = torchvision.models.resnet34(pretrained=pretrained)
bottom_channel_nr = 512
elif encoder_depth == 101:
self.encoder = torchvision.models.resnet101(pretrained=pretrained)
bottom_channel_nr = 2048
elif encoder_depth == 152:
self.encoder = torchvision.models.resnet152(pretrained=pretrained)
bottom_channel_nr = 2048
else:
raise NotImplementedError('only 34, 101, 152 version of Resnet are implemented')
self.upsample_2d = torch.nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False)
self.upsample_4d = torch.nn.Upsample(scale_factor=4, mode='bilinear', align_corners=False)
self.upsample_8d = torch.nn.Upsample(scale_factor=8, mode='bilinear', align_corners=False)
self.bn16 = nn.BatchNorm2d(16, eps=1e-5, momentum=0.01, affine=True)
self.bn32 = nn.BatchNorm2d(32, eps=1e-5, momentum=0.01, affine=True)
self.pool = nn.MaxPool2d(2, 2)
self.relu = nn.ReLU(inplace=True)
# self.conv3x3 = Model3x3(64)
self.conv1 = nn.Sequential(
# self.upsample_2d,
self.encoder.conv1,
self.encoder.bn1,
self.encoder.relu,
# self.pool
)
self.conv2 = nn.Sequential(
self.upsample_2d,
self.encoder.conv1,
self.encoder.bn1,
self.encoder.relu,
self.pool
)
self.conv4 = nn.Sequential(
self.upsample_4d,
self.encoder.conv1,
self.encoder.bn1,
self.encoder.relu,
self.pool
)
self.conv8 = nn.Sequential(
self.upsample_8d,
self.encoder.conv1,
self.encoder.bn1,
self.encoder.relu,
self.pool
)
self.convn1 = self.encoder.layer1
self.convn2 = self.encoder.layer2
self.convn3 = self.encoder.layer3
self.convn4 = self.encoder.layer4
self.center = DecoderBlockV2(bottom_channel_nr, num_filters * 8 * 2, num_filters * 8, is_deconv)
self.dec5 = DecoderBlockV2(bottom_channel_nr + num_filters * 8, num_filters * 8 * 2, num_filters * 8, is_deconv)
self.dec4 = DecoderBlockV2(bottom_channel_nr + num_filters * 8, num_filters * 8 * 2, num_filters * 8,
is_deconv)
self.dec3 = DecoderBlockV2(bottom_channel_nr + num_filters * 8, num_filters * 8 * 2, num_filters * 8,
is_deconv)
self.dec2 = DecoderBlockV2(bottom_channel_nr // 2 + num_filters * 4 * 2, num_filters * 8 * 2, num_filters * 8,
is_deconv)
self.dec1 = DecoderBlockV1(bottom_channel_nr // 2 + num_filters * 2 , num_filters * 2 * 4, num_filters * 2 * 2, is_deconv)
self.dec0 = ConvRelu(num_filters * 2 * 2, num_filters * 2)
self.final = nn.Conv2d(num_filters * 2, num_classes, kernel_size=1)
def forward(self, x):
conv1 = self.conv1(x)
conv2 = self.conv2(x)
conv4 = self.conv4(x)
conv8 = self.conv8(x)
# ----- 原始倍率
conv1d1 = self.convn1(conv1) # 64 64
conv1d2 = self.convn2(conv1d1) # 32 128
conv1d3 = self.convn3(conv1d2) # 16 256
conv1d4 = self.convn4(conv1d3) # 8 512
pool = self.pool(conv1d4) # 4 512
center = self.center(pool) # 8 256
# ----- 2倍率
conv2d1 = self.convn1(conv2) # 64 64
conv2d2 = self.convn2(conv2d1) # 32 128
conv2d3 = self.convn3(conv2d2) # 16 256
# ----- 4倍率
conv4d1 = self.convn1(conv4) # 128 64
conv4d2 = self.convn2(conv4d1) # 64 128
conv4d3 = self.convn3(conv4d2) # 32 256
# # ----- 8倍率
# conv8d1 = self.convn1(conv8) # 256 64
# conv8d2 = self.convn2(conv8d1) # 128 128
# conv8d3 = self.convn3(conv8d2) # 64 256
# # print(len(self.convn))
dec5 = self.dec5(torch.cat([center, conv1d4], 1)) # 8 256
dec4 = self.dec4(torch.cat([dec5, conv1d3, conv2d3], 1)) # 16 256
dec3 = self.dec3(torch.cat([dec4, conv1d2, conv2d2, conv4d3], 1)) # 32 256
dec2 = self.dec2(torch.cat([dec3, conv1d1, conv4d2, conv2d1], 1)) # 64 128
dec1 = self.dec1(torch.cat([dec2, conv4d1], 1)) # 128 128
dec0 = self.dec0(dec1)
return self.final(F.dropout2d(dec0, p=self.dropout_2d))
if __name__ == '__main__':
net = UNetResNet(34, 2)
# print(model)
input = torch.randn((2, 4, 128, 128))
output = net(input)
print(output.size())
结论
不同的提取方法在油菜提取任务中有不同的表现。阈值法简单但在复杂情况下可能效果不佳;机器学习方法和CNN能够一定程度上提取出油菜,但也可能存在错误。YcNet模型针对油菜数据特点进行优化,能够更好地提取油菜区域。
以下是四种提取方案的部分结果对比,可以看出来在YcNet提取效果最佳、其次是unet、然后是随机森林、最后是阈值法。其中黄色表示Ycnet提取结果、褐色表示unet提取结果、绿色标色随机森林提取结果、红色表示阈值法提取结果。

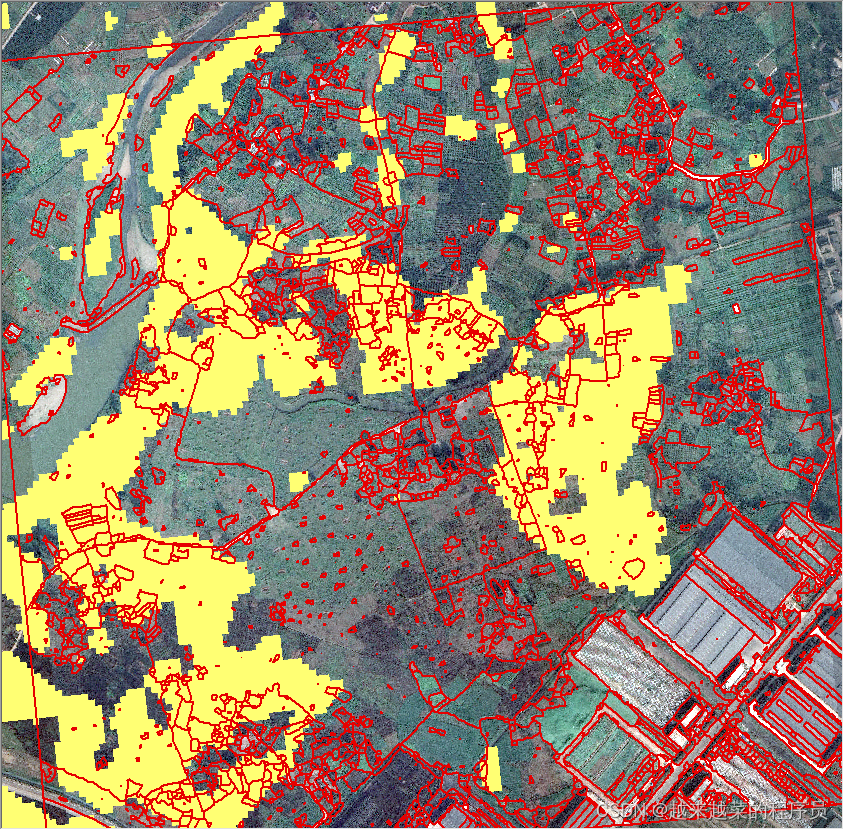
地块提取
我们将上述提取油菜最好的方法YcNet得到的结果作为最终的油菜提取,接下来我们要做的是将油菜提取结果以耕地地块为单位做成矢量图,如果使用哨兵2的10米分辨影像是无法获得耕地地块信息,我们可以从网上下载0.5m分辨率的谷歌底图作为我们地块提取的数据。下图展示了来自谷歌20级rgb真彩图像,从图像上我们可以清晰的看见耕地的边缘轮廓。

紧接着将我们刚刚提取的油菜数据叠加在谷歌底图上,如下图所示,可以看出来叠加油菜数据以后,两则不能很好的贴合,这是因为两者的分辨率相差太大了。
通过上述的结果展示,接下来我们需要将谷歌底图的地块提取出来然后和我们提取油菜做适配,最终得到地块界别的油菜shp数据。
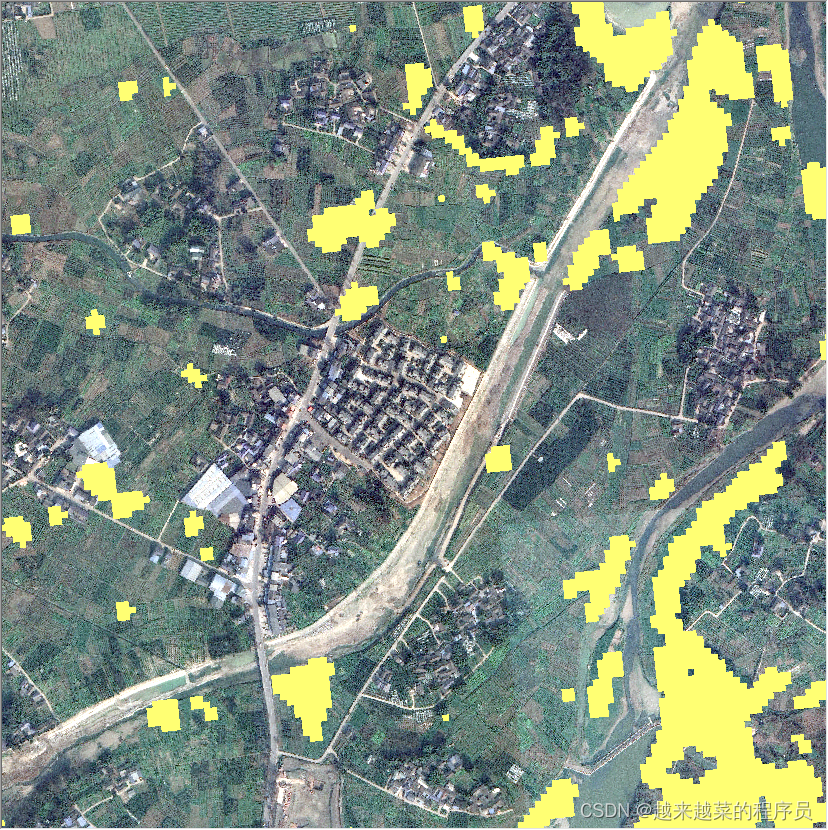
最后我们将耕地和油菜叠加起来得到以地块为单位油菜耕地分布