文章目录
前言
RabbitMQ 的分布式高可用性(High Availability, HA)是通过多种机制和技术来确保消息传递系统的稳定性和可靠性,即使在部分组件或节点出现故障时也能持续提供服务。为了实现这一点,RabbitMQ 提供了集群配置、镜像队列、持久化以及负载均衡等多种手段
一、持久化与内存管理
1、持久化机制
RabbitMQ 的持久化分为消息持久化、队列持久化、交换器持久化。无论是持久化消息还是非持久化消息都可以被写入磁盘。
- 持久化消息,则会储存在内存中,同时也会写入磁盘
- 非持久化消息,则只会存在内存中
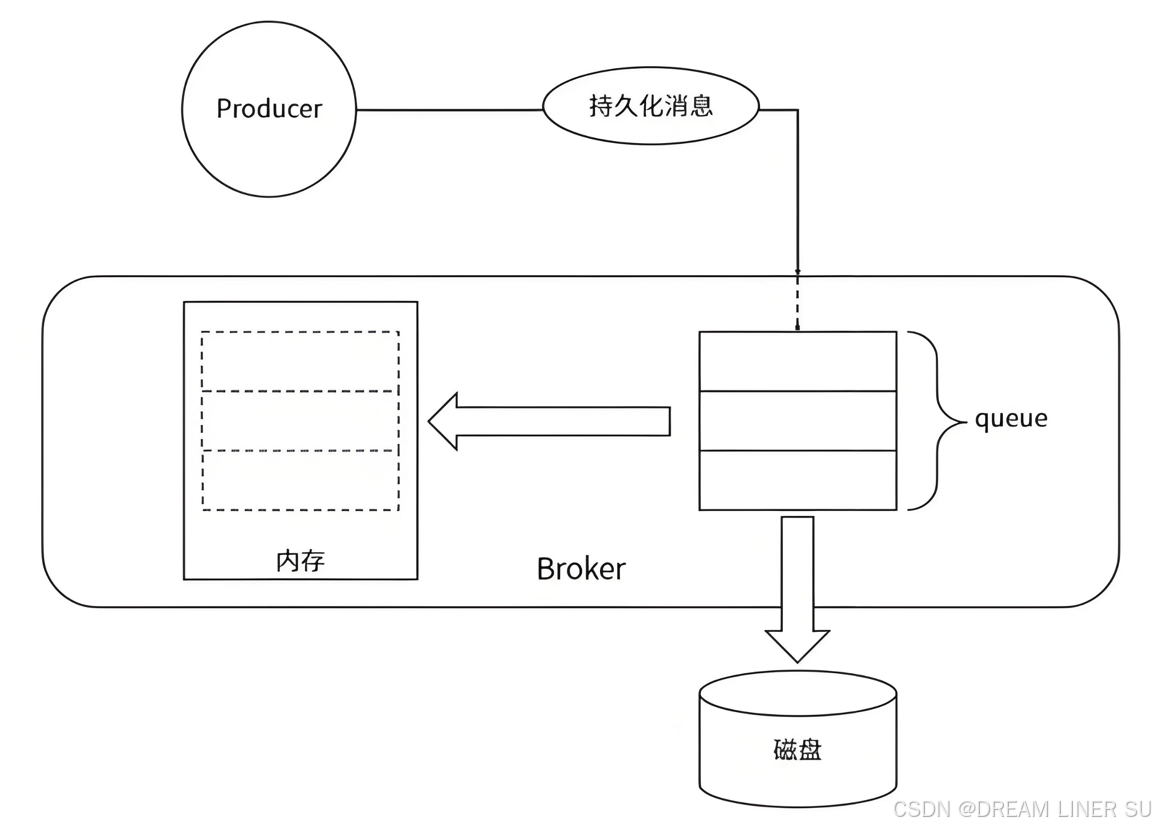
当内存使用达到 RabbitMQ 的临界值时,内存中的数据会被交换到磁盘,持久化消息由于本就存在于磁盘中,不会被重复写入。
消息的持久化是在发消息时,通过 deliveryMode 设置,队列、交换器也可以通过参数持久化,在单服务中,非持久化的消息、队列、交换器重启后会消失,即使内存换页写入磁盘了,也会消失。
2、内存控制
1、命令行
RabbitMQ 中通过内存阈值参数控制内存的使用量,当内存使用超过配置的阈值时,RabbitMQ 会阻塞客户端的连接并停止接收从客户端发来的消息,以免服务崩溃。
同时,会发出内存告警,此时客户端于与服务端的心跳检测也会失效。 当出现内存告警时,可以通过管理命令临时调整
rabbitmqctl set_vm_memory_high_watermark <fraction>
# rabbitmqctl set_vm_memory_high_watermark absolute <memory_limit>
- fraction, 为内存阈值,默认是0.4,建议 0.4~0.66,表示 RabbitMQ 使用的内存超过系统内存的40%时,会产生内存告警,
- memory_limit,代表大小,单位为 KB、MB、GB
这种方式修改,实时生效,重启后失效。
2、配置文件
可以通过修改配置文件的方式,使之永久生效,但是需要重启服务。
rabbitmq.conf
vm_memory_high_watermark.relative = 0.4
# 或者直接配置成大小
# vm_memory_high_watermark.absolute = "1GB"
RabbitMQ 提供 relative 与 absolute 两种配置方式
- relative:相对值,也就是前面的 fraction 参数,建议 0.4~0.66,不能太大
- absolute:绝对值,固定大小,单位为 KB、MB、GB
3、内存换页
除了定义高水位线外,还可以配置何时开始将队列内容分页到磁盘以释放内存。
默认情况下,当内存使用率达到高水位线的一半时,RabbitMQ就开始执行Paging操作。
可以通过修改vm_memory_high_watermark_paging_ratio来调整这一行为:
vm_memory_high_watermark_paging_ratio = 0.75
vm_memory_high_watermark.relative = 0.4
上述配置意味着在内存使用率达到 40% * 75% = 30% 时,RabbitMQ就会开始分页动作
当换页阈值vm_memory_high_watermark_paging_ratio大于 1 时,相当于禁用了换页功能
内存换页涉及到大量的I/O操作,因为数据必须从RAM转移到硬盘,并且在某些情况下还需要再次加载回内存,对性能有一定影响
4、磁盘控制
当RabbitMQ所在的服务器磁盘空间接近耗尽时,可能会导致服务不可用,因为此时操作系统可能无法创建新的文件或者写入现有文件。
为了避免这种情况发生,RabbitMQ提供了一套磁盘控制机制来监控可用磁盘空间,并在必要时采取预防措施。
配置磁盘阈值
可以通过命令行工具rabbitmqctl或者直接编辑配置文件来调整磁盘阈值。
- 命令行
rabbitmqctl set_disk_free_limit mem_relative 1.0
# 绝对值
rabbitmqctl set_disk_free_limit absolute 1GB
- 配置文件配置
disk_free_limit.relative = 1.0
# 绝对值
disk_free_limit.absolute = 1GB
一旦磁盘空间低于配置的阈值,RabbitMQ将停止接收新消息,并阻止基于内存的消息page到磁盘。这意味着直到有足够的空闲磁盘空间为止,所有的生产者都将被阻塞。
如果检测到磁盘空间不足,应该立即采取行动清理不必要的文件、归档旧日志或者扩展存储容量。此外,还可以考虑优化消息生产和消费的速度,减少未处理消息积压的可能性。
二、集群
RabbitMQ集群是一种通过多节点架构来提高消息传递系统可靠性和性能的技术,它允许在分布式环境中部署多个RabbitMQ实例,并让它们协同工作以提供更强大的服务
1、Erlang的分布式特性
RabbitMQ是基于Erlang语言开发的消息队列中间件,而Erlang本身具有很强的分布式能力,这使得RabbitMQ能够天然支持集群化部署。
Erlang通过同步各节点间的magic cookie(一种认证令牌)来实现节点之间的通信和识别。
服务的端口是 5672,UI 的端口是 15672,集群的端口是 25672。
需要注意的是, RabbitMQ 集群无法搭建在广域网上, 除非使用 federation 或者 shovel 等插件(没这个必要,在同一个机房做集群)。
2、RabbitMQ的节点类型
RabbitMQ的节点类型主要分为两种:磁盘节点(Disk Node)和内存节点(RAM Node)。这两种类型的节点在集群中扮演着不同的角色
2.1、磁盘节点 (Disk Node)
磁盘节点是将所有元数据持久化存储到磁盘上的节点。这意味着即使节点重启或发生故障,这些信息也不会丢失。
在单节点系统或者集群环境中,至少需要有一个磁盘节点来保证数据的持久性。磁盘节点确保了关键配置如队列、交换器、绑定关系、用户权限等不会因为服务中断而消失。
当集群中有新的节点加入或有旧节点离开时,必须通知至少一个磁盘节点以更新集群的状态。
2.2、内存节点 (RAM Node)
与磁盘节点不同,内存节点将所有的元数据存储在内存中而不是磁盘上。这使得内存节点能够提供更高的性能,因为内存访问速度远快于磁盘访问。 但是内存不是持久化的,如果节点重启,所有的数据都会丢失。
当有新的内存节点被添加到集群时,它会通知所有磁盘节点。内存节点唯一写入磁盘的信息就是集群中磁盘节点的地址, 只要它可以找到至少一个磁盘节点,就能在重启后重新加入集群。
注意:
如果 RabbitMQ 集群只有一个磁盘节点,然后磁盘节点挂了,可以正常的投递消息和消费消息,但是不能做以下事:
- 1、不能创建队列
- 2、不能创建交换机
- 3、不能创建用户绑定关系
- 4、不能修改用户权限
因此,在建立集群时应确保有两个或更多个磁盘节点,以便提高系统的可用性和可靠性。
# 加入集群时设置节点为内存节点
rabbitmqctl join_cluster --ram <existing_node_name>
# 从磁盘节点转换为内存节点
rabbitmqctl change_cluster_node_type disc | ram
3、构建集群
RabbitMQ 有两种集群模式:普通集群模式和镜像队列模式。
3.1 普通集群
普通集群模式下,不同的节点之间只会相互同步元数据(交换机、队列、绑定关系、Vhost 的定义),而不会同步消息。
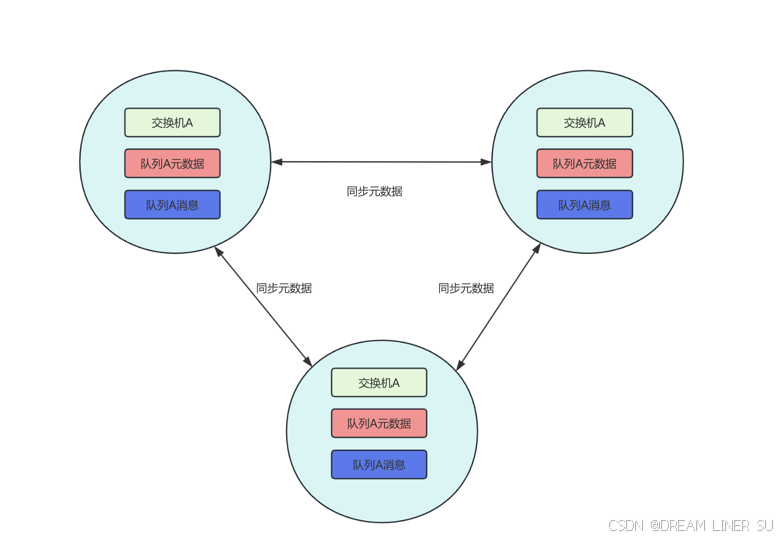
队列 A 的消息只存储在节点 A 上。节点 B 和节点 C 只同步了队列 A 的定义,但是没有同步消息。
假如生产者连接的是节点 C,要将消息通过交换机 A 路由到队列 A,最终消息还是会转发到节点 A 上存储,因为队列 A 的内容只在节点 A 上。
同理,如果消费者连接是节点 B,要从队列 A 上拉取消息,消息会从节点 A 转发 到节点 B。其它节点起到一个路由的作用,类似于指针。
出于存储和同步数据的网络开销的考虑, 如果所有节点都存储相同的数据, 就无法达到线性地增加性能和存储容量的目的(堆机器),所以不会同步所有数据
如果需要保证队列的高可用性,就不能用这种集群模式了,因为节点失效将导致相关队列不可用。
3.2 镜像队列
镜像队列模式下,消息内容会在镜像节点间同步,可用性更高。不过也有一定的副作用,系统性能会降低,节点过多的情况下同步的代价比较大。
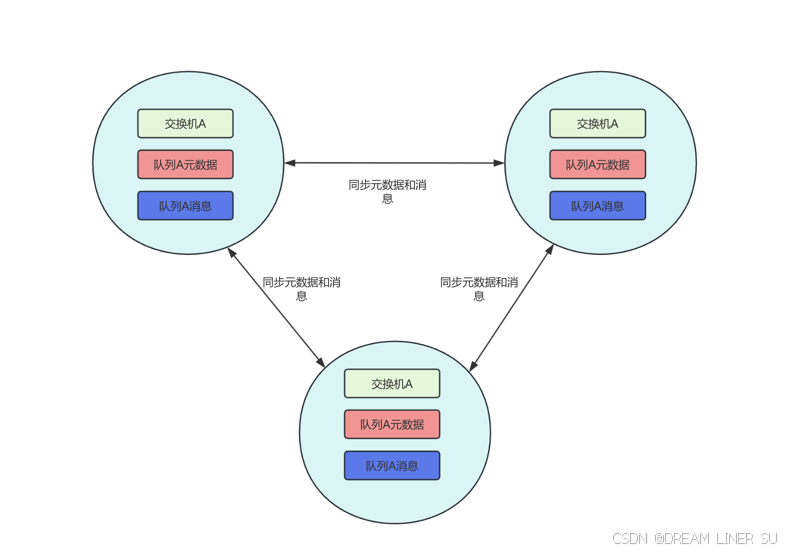
一旦集群建立,你可以创建镜像队列。例如,在任一节点上:
docker exec -it rabbit1 bash
# 将名称以ha开头的队列同步至所有节点:
rabbitmqctl set_policy ha-all "^ha.*" '{"ha-mode": "all"}'
# 将所有队列至少同步至两个节点:
rabbitmqctl set_policy ha-two "^.*" '{"ha-mode": "exactly", "ha-params": 2, "ha-sync-mode": "automatic"}'
也可以为特定队列设置镜像策略:
rabbitmqctl set_policy my-queue-policy 'my-queue' '{"ha-mode":"all"}'
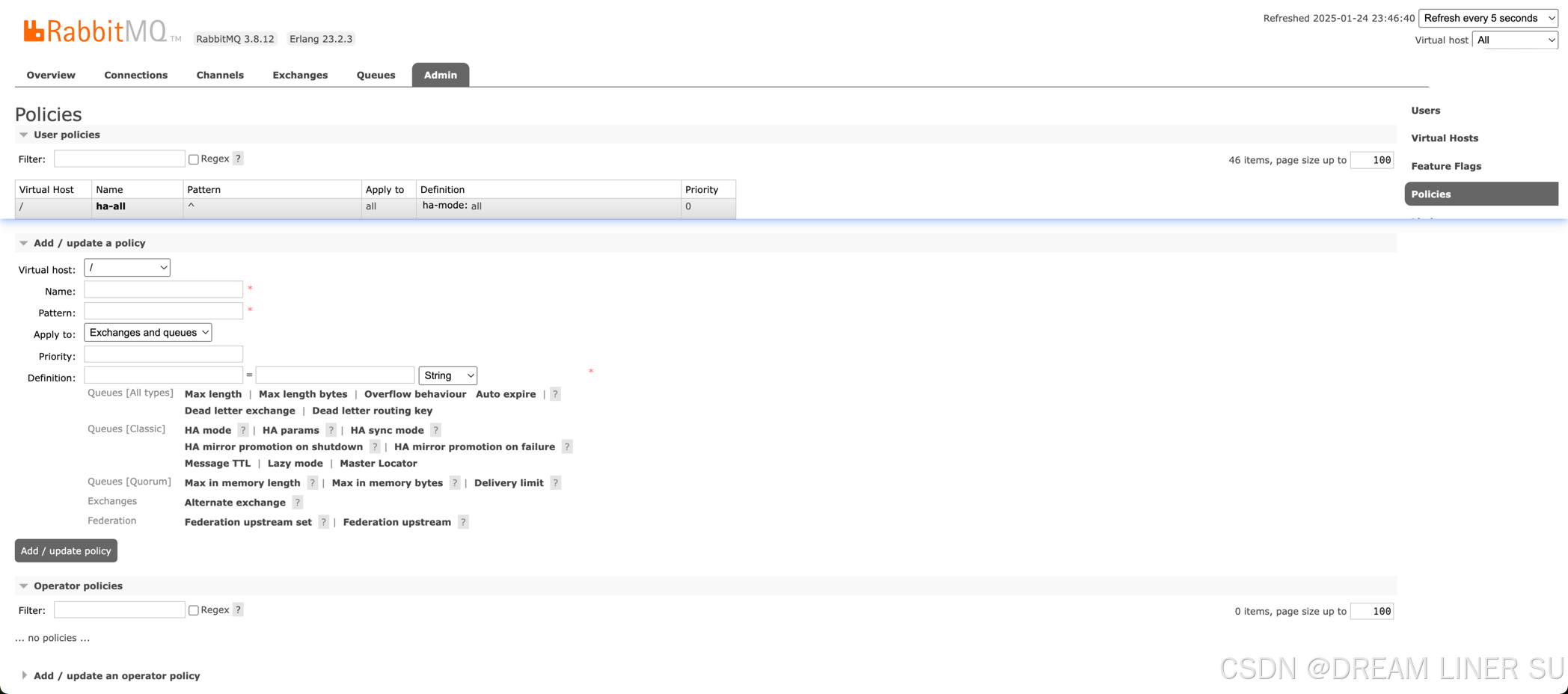
查看镜像队列配置
# 在任意节点上查看相应的策略:
rabbitmqctl list_policies
Listing policies for vhost "/" ...
vhost name pattern apply-to definition priority
/ ha-all ^ha.* all {"ha-mode":"all"} 0
/ ha-two ^.* all {"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"} 0
我们也可以根据 web 页进行查看,也可以在 web 页上进行镜像队列的配置
3.3、高可用实现方案
3.3.1、选择节点
集群搭建成功后,如果有多个内存节点,那么生产者和消费者应该连接到哪个内存节点?
如果我们在客户端代码中,需要根据一定的策略来选择要使用的服务器,那每个地方都要修改,客户端的代码就会出现很多的重复,修改起来也比较麻烦。
如果需要升级,那维护量可想而知的复杂,不建议使用
3.3.2、负载均衡
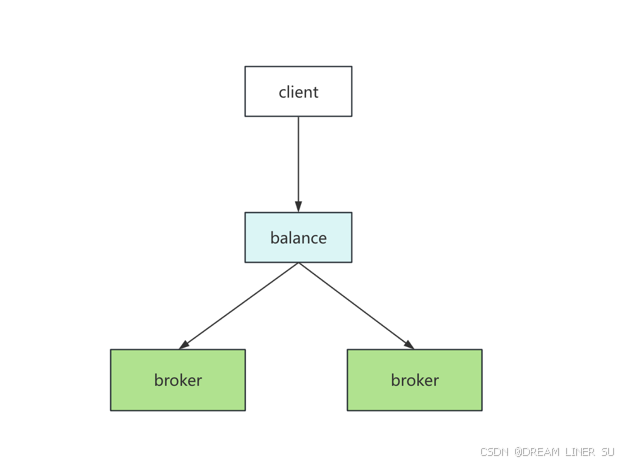
所以需要一个负载均衡的组件(例如 HAProxy,LVS,Nignx),由负载的组件来做路由。这个时候,只需要连接到负载组件的 IP 地址就可以了。
如果这个负载的组件也挂了呢?那再加集群,再路由,这样就死循环了
我们应该需要这样一个组件:
- 1、它本身有路由(负载)功能,可以监控集群中节点的状态(比如监控 HAProxy), 如果某个节点出现异常或者发生故障,就把它剔除掉。
- 2、为了提高可用性, 它也可以部署多个服务, 但是只有一个自动选举出来的 MASTER 服务器(叫做主路由器),通过广播心跳消息实现。
- 3、MASTER 服务器对外提供一个虚拟 IP,提供各种网络功能。也就是谁抢占到 VIP, 就由谁对外提供网络服务。应用端只需要连接到这一个 IP 就行了。
这个组件就是 Keepalived,它具有 Load Balance 和 High Availability 的功能。它的协议为VRRP协议(虚拟路由冗余协议Virtual Router Redundancy Protocol)。
3.3.3、基于 HAproxy+Keepalived 搭建高可用
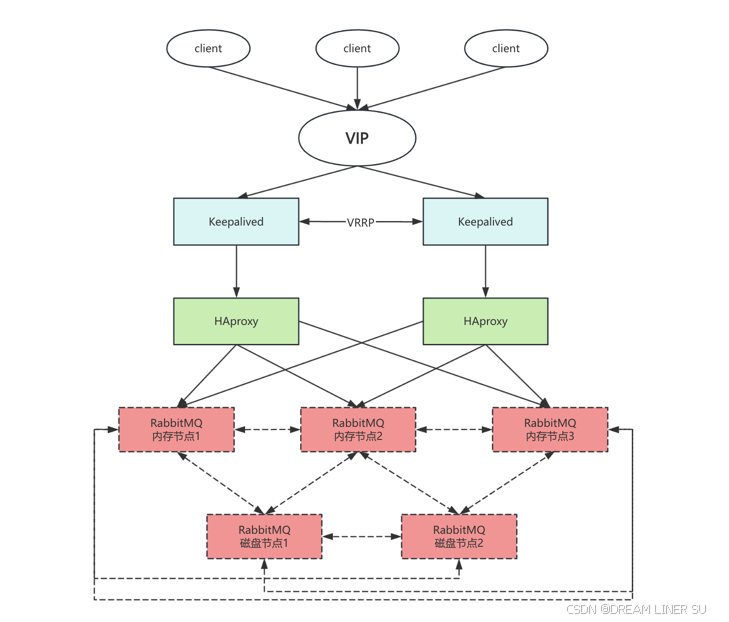
规划:
- 内存节点1:192.168.8.143
- 内存节点2:192.168.8.144
- 内存节点3:192.168.8.145
- 磁盘节点1:192.168.8.146
- 磁盘节点2:192.168.8.147
- VIP:192.172.8.10
应用
- 1、我们规划了三个内存节点,两个磁盘节点。内存节点之间通过镜像队列的方式同步数据。内存节点用来给应用访问,磁盘节点用来持久化元数据。
- 2、为了实现对三个内存节点的负载,我们安装了两个 HAProxy,监听两个 5672 和 15672 的端口。
- 3、安装两个 Keepalived,一主一备。 两个 Keepalived 抢占一个 VIP 192.172.8.10。 谁抢占到这个 VIP,应用就连接到谁,来执行对 MQ 的负载。
如果出现故障,我们分析一下是否能够实现高可用
- 我们的 Keepalived 挂了一个节点,没有影响, 因为 BACKUP 会变成 MASTER,抢占 VIP。
- HAProxy 挂了一个节点,没有影响,我们的 VIP 会自 动路由的可用的 HAProxy 服务。
- RabbitMQ 挂了一个节点,没有影响, 因为 HAProxy 会自动负载到可用的节点。