【1】现象描述
列表分页查询接口,sql是用更新时间做降序排序。出现的问题就是第二页的最后一条数据,和第三页的第一条数据是一样的,也就是出现了分页数据重复的问题。
【2】问题分析
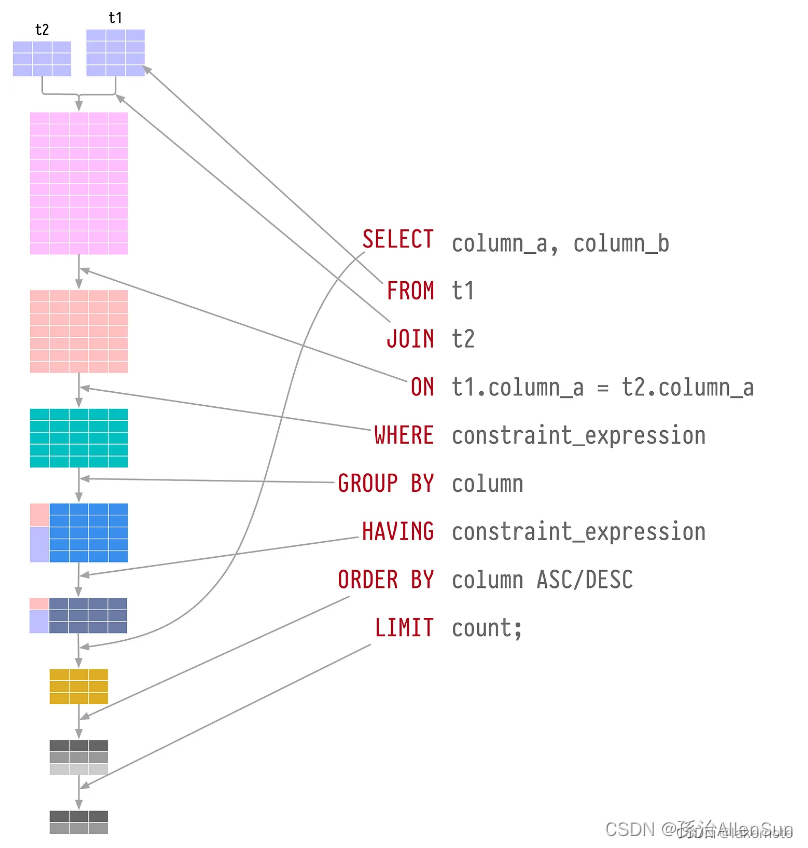
分页查询排序后的数据,是一个非常常见的业务场景;但当使用不唯一的字段排序时,分两页查询的数据可能出现数据重复和丢失的错觉。
在执行查询时,MySQL会根据查询优化器的决策来确定数据的检索顺序,如果没有明确的排序规则,结果集的顺序可能会随机,也就是说当我们用更新时间来做排序,而更新时间这个字段的值是不唯一的,同一个更新时间的数据有多条,那么在分页查询时,就可能会在不同页排序后取到相同的数据。
CREATE TABLE `video` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`video_name` varchar(100) DEFAULT NULL,
`video_type` int(11) DEFAULT NULL,
`create_by` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=18 DEFAULT CHARSET=utf8mb4;
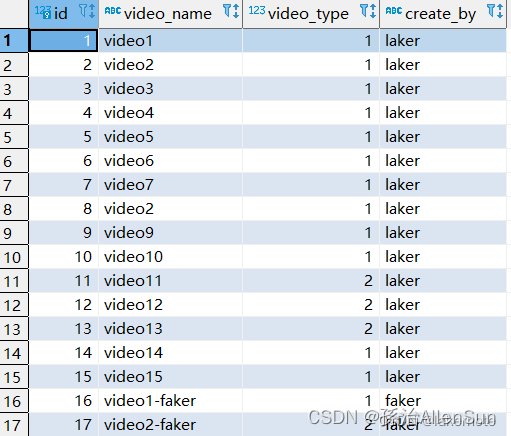
分页查询时出现重复数据:
【3】原因分析
这个问题在5.6以后的版本都会有,严格的说这并不算一个问题,MySQL官方对order by limit做了优化,就是在排序字段无索引并且列值不唯一时,会使用priority queue(优先队列)
这个优先队列的本质和Java中的堆一样的,可以根据limit的条数维护一个堆。
官方文档也对此做了解释:
如果将LIMIT row_count与ORDER BY结合使用,MySQL会在找到排序结果的前row_count行后立即停止排序,而不是对整个结果进行排序。 如果通过使用索引进行排序,这将非常快。 如果必须执行文件排序,则在找到第一个row_count之前,将选择所有与查询匹配的,没有LIMIT子句的行,并对其中的大多数或全部进行排序。 找到初始行后,MySQL不会对结果集的其余部分进行排序。此行为的一种体现是,带有和不带有LIMIT的ORDER BY查询可能以不同的顺序返回行,如本节后面所述。
如果多个行在ORDER BY列中具有相同的值,则服务器可以自由以任何顺序返回这些行,并且根据整体执行计划的不同,返回值可以不同。 换句话说,这些行的排序顺序相对于无序列是不确定的。
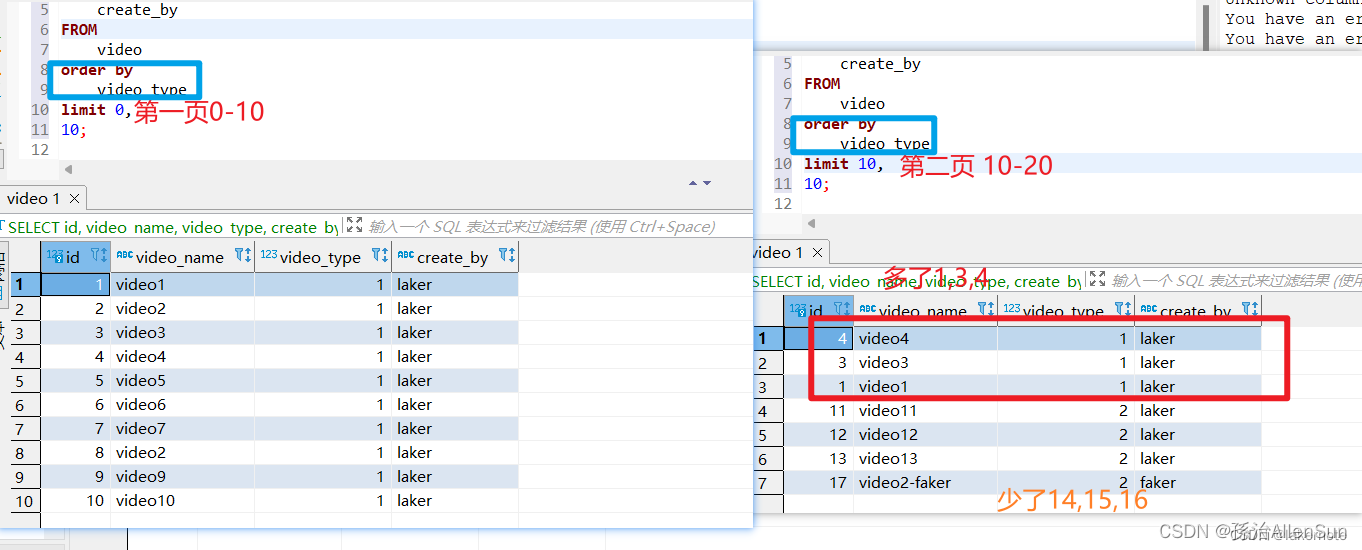
【4】解决方案
为了避免出现这种数据丢失的错觉,我们可以采取以下解决方案:
(1)明确指定ORDER BY子句
在查询中始终使用ORDER BY子句,并指定一个或多个字段,以确保结果按照您的预期顺序返回。例如:
SELECT * FROM video ORDER BY id;
(2)使用唯一字段进行排序
如果可能的话,尽量使用唯一字段进行排序,以确保结果的一致性。在上面的示例中,id字段是一个自增的主键,可以用来保证结果的唯一性。
如果没有唯一字段,联合索引构成的联合唯一索引也行。
// 上面的解决方案为 排序字段添加个id字段即可。
SELECT
id,
video_name,
video_type,
create_by
FROM
video
order by
video_type,id
limit 0,
10;
(3)注意查询性能
尽管我们强烈建议使用ORDER BY,但要谨慎选择排序字段,以避免对查询性能产生不利影响。确保排序字段上有适当的索引以提高查询性能。