Multiple Instance Detection Network with Online Instance Classifier Refinement
Contributions
-
We propose a framework for weakly supervised learning that combines MIDN with multi-stage instance classifiers. With only supervision of the outputs from its preceding stage, the discriminatory power of the instance classifier can be enhanced iteratively.
-
We further design a novel OICR algorithm that integrates the basic detection network and the multi-stage instance-level classifier into a single network. The proposed network is end-to-end trainable. Compared with the alternatively training strategy, we demonstrate that our method can not only reduce the training time, but also boost the performance.
-
Our method achieves significantly better results over previous state-of-the-art methods on the challenging PASCAL VOC 2007 and 2012 benchmarks for weakly supervised object detection.
Method
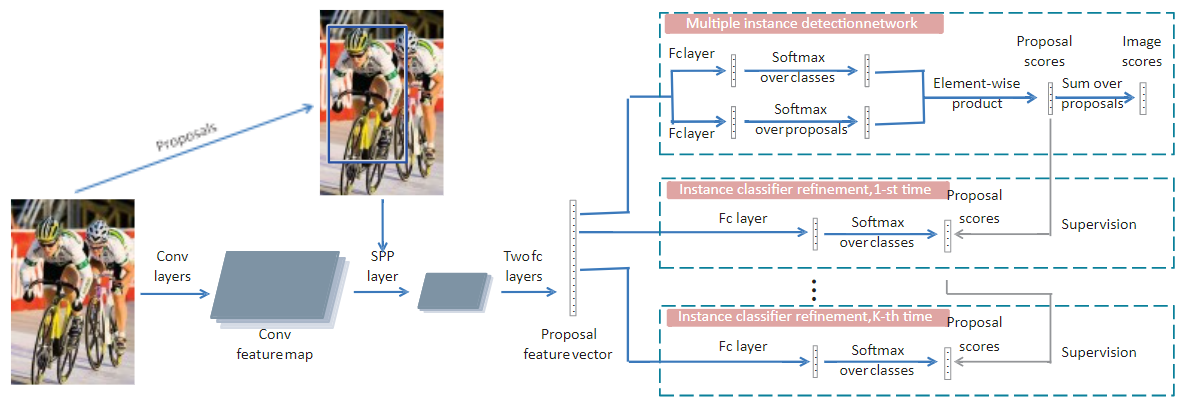
MIDN(Multiple instance detection network)

- Proposal feature vector 经过FC层分别得到 x c , x d ∈ R C × ∣ R ∣ \mathbf{x}^{c},\mathbf{x}^{d} \in \mathbb{R}^{C \times|R|} xc,xd∈RC×∣R∣
- x c \mathbf{x}^{c} xc经过Sofrmax层得到 [ σ ( x c ) ] i j = e x i j c ∑ k = 1 C e x k j c \left[\sigma\left(\mathbf{x}^{c}\right)\right]_{i j}=\frac{e^{x_{i j}^{c}}}{\sum_{k=1}^{C} e^{x_{k j}^{c}}} [σ(xc)]ij=∑k=1Cexkjcexijc, 表示建议区域 j j j属于类别 i i i的概率。
- x d \mathbf{x}^{d} xd经过Sofrmax层得到 [ σ ( x d ) ] i j = e x i j c ∑ k = 1 ∣ R ∣ e x i k c \left[\sigma\left(\mathbf{x}^{d}\right)\right]_{i j}=\frac{e^{x_{i j}^{c}}}{\sum_{k=1}^{|R|} e^{x_{ik}^{c}}} [σ(xd)]ij=∑k=1∣R∣exikcexijc, 表示图片被分类为 i i i类时建议区域 j j j作的贡献。
- 初始建议得分矩阵 x R = σ ( x c ) ⊙ σ ( x d ) \mathbf{x}^{R}=\sigma\left(\mathbf{x}^{c}\right) \odot \sigma\left(\mathbf{x}^{d}\right) xR=σ(xc)⊙σ(xd),其中每个元素 x i j R x^R_{ij} xijR 表示建议区域 r j r_j rj 对类别 i i i的得分,用于后续迭代。
- 对所有区域建议求和得到图像分数 ϕ c = ∑ r = 1 ∣ R ∣ x c r R \phi_{c}=\sum_{r=1}^{|R|} x_{c r}^{R} ϕc=∑r=1∣R∣xcrR,表示图像对类别 c c c的得分。
- 基本实例分类器多类交叉熵损失函数 L b = − ∑ c = 1 C { y c log ϕ c + ( 1 − y c ) log ( 1 − ϕ c ) } \mathrm{L}_{\mathrm{b}}=-\sum_{c=1}^{C}\left\{y_{c} \log \phi_{c}+\left(1-y_{c}\right) \log \left(1-\phi_{c}\right)\right\} Lb=−∑c=1C{yclogϕc+(1−yc)log(1−ϕc)}
OICR(Online instance classifier refinement)
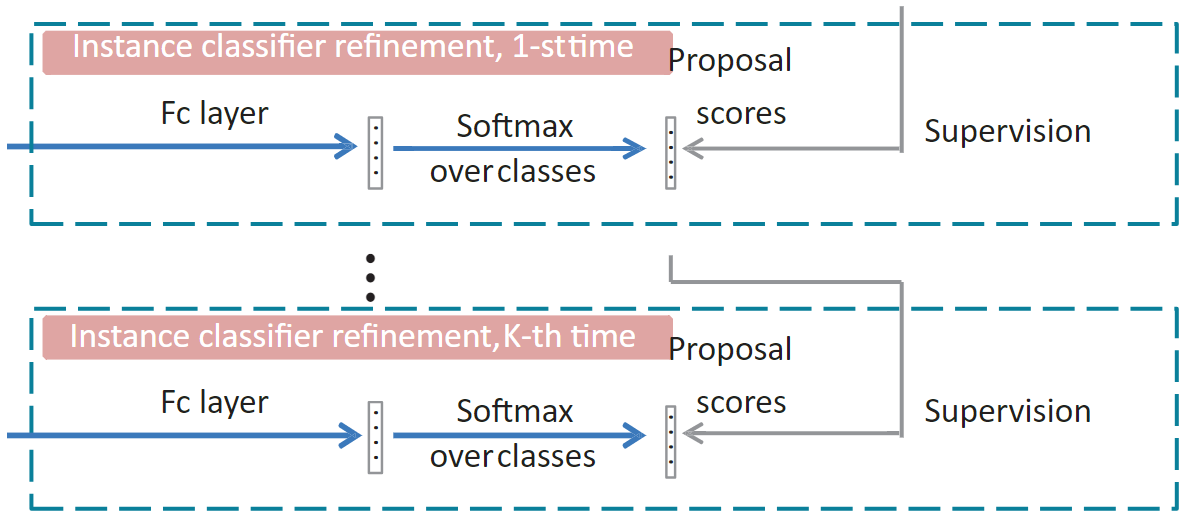
精炼分类器的一种自然方式是一种交替策略,即固定分类器并标记提议,固定提议标签并训练分类器。但它有一些局限性:1)非常耗时,因为它需要多次训练分类器; 2)在不同的细化步骤中分别训练不同的分类器可能会损害性能,因为它阻碍了从共享表示中受益的过程。因此,我们将基本的 MIDN 和不同的分类器精炼阶段集成到一个网络中,并对其进行端到端的训练。
通过利用
W
S
D
D
N
WSDDN
WSDDN 作为初始定位网络,逐步训练多个实例分类器以细化定位结果并获得性能良好的检测器。这里,设
K
K
K 是实例分类器的数量,
x
R
k
∈
R
(
C
+
1
)
×
∣
R
∣
\textbf{x}^{Rk}\in R^{(C+1)\times |R|}
xRk∈R(C+1)×∣R∣ 是第
k
k
k 个实例分类器的输出建议得分。与
x
R
\textbf{x}^R
xR 不同,
x
R
k
(
k
∈
1
,
.
.
.
,
K
)
\textbf{x}^{Rk}(k\in {1, ..., K})
xRk(k∈1,...,K) 具有第
{
C
+
1
}
\{C +1\}
{C+1} 个背景维度。为了逐步训练多实例分类器,第
k
k
k 个实例分类器的真实标签 由最后一个实例分
x
R
k
∈
R
(
C
+
1
)
×
∣
R
∣
\textbf{x}^{Rk}\in R^{(C+1)\times |R|}
xRk∈R(C+1)×∣R∣ 类器的输出
x
R
(
k
−
1
)
\textbf{x}^{R(k-1)}
xR(k−1) 制成。基于
y
k
\textbf{y}^{k}
yk,训练每个实例分类器以最小化以下损失:
L
r
k
=
−
1
∣
R
∣
∑
j
=
1
∣
R
∣
∑
c
=
1
C
+
1
y
c
j
k
log
x
c
j
k
L_{r}^{k}=-\frac{1}{|R|} \sum_{j=1}^{|R|} \sum_{c=1}^{C+1} y_{c j}^{k} \log x_{c j}^{k}
Lrk=−∣R∣1j=1∑∣R∣c=1∑C+1ycjklogxcjk
在
O
I
C
R
OICR
OICR 中,实例标注是如何从最后的定位结果
x
R
(
k
−
1
)
\textbf{x}^{R(k-1)}
xR(k−1)生成实例标签
y
k
\textbf{y}^{k}
yk 的问题。假设图像
X
X
X 具有类标签
c
c
c,他们首先选择得分最高的区域建议
r
j
c
r_{j_c}
rjc,
j
c
k
−
1
=
arg
max
j
x
c
j
R
(
k
−
1
)
j_{c}^{k-1}=\arg \max _{j} x_{c j}^{R(k-1)}
jck−1=argjmaxxcjR(k−1)
并受到高度重叠区域应具有相同标签这一事实的启发,制定了以下标签算法,
y
c
j
k
=
{
1
if
IoU
(
r
j
k
−
1
,
r
j
c
k
−
1
)
>
I
t
0
otherwise
y_{c j}^{k}= \begin{cases}1 & \text { if } \operatorname{IoU}\left(r^{k-1}_{j}, r^{k-1}_{j_{c}}\right)>I_{t} \\ 0 & \text { otherwise }\end{cases}
ycjk={10 if IoU(rjk−1,rjck−1)>It otherwise
其中
IoU
\operatorname{IoU}
IoU 是计算两个区域之间的交并比 (
IoU
\operatorname{IoU}
IoU ) 的函数,
I
t
I_t
It 是一个阈值。当多个类满足
IoU
(
r
j
k
−
1
,
r
j
c
k
−
1
)
>
I
t
\operatorname{IoU}\left(r^{k-1}_{j}, r^{k-1}_{j_{c}}\right)>I_{t}
IoU(rjk−1,rjck−1)>It 时,
y
c
j
k
y_{c j}^{k}
ycjk 其
c
=
a
r
g
m
a
x
c
′
IoU
(
r
j
k
−
1
,
r
j
c
k
−
1
)
>
I
t
c = {\rm arg max}_{c'} \operatorname{IoU}\left(r^{k-1}_{j}, r^{k-1}_{j_{c}}\right)>I_{t}
c=argmaxc′IoU(rjk−1,rjck−1)>It 为
1
1
1,其他为
0
0
0。如果一个区域没有分配任何对象类,即
y
c
j
k
y_{c j}^{k}
ycjk 为
0
0
0 对于所有
c
∈
{
1
,
.
.
.
,
C
}
c\in \{1, ..., C\}
c∈{1,...,C},该区域被标记为背景,
y
(
C
+
1
)
j
k
=
1
y_{(C+1) j}^{k}=1
y(C+1)jk=1
但是,最后一个定位结果生成的标签是不可靠的,尤其是在训练开始时。这会导致训练的不稳定性。为了解决这个问题,方程中的损失函数。精炼的实例分类器损失函数改为加权版本如下,
w
j
k
=
x
c
j
c
k
−
1
w_{j}^{k}=x_{c j_{c}}^{k-1}
wjk=xcjck−1
当图像具有多个类时,在上式,
c
=
a
r
g
m
a
x
c
′
IoU
(
r
j
,
r
j
c
′
)
>
I
t
c = {\rm arg max}_{c'} \operatorname{IoU}\left(r_{j}, r_{j_{c'}}\right)>I_{t}
c=argmaxc′IoU(rj,rjc′)>It。在训练开始时或对于难以定位的图像,权重
w
j
k
w_{j}^{k}
wjk 取低值,对训练的贡献变小。进而每一个精炼的实例分类器损失函数重写为加权版本:
L r k = − 1 ∣ R ∣ ∑ r = 1 ∣ R ∣ ∑ c = 1 C + 1 w r k y c r k log x c r R k \mathrm{L}_{\mathrm{r}}^{k}=-\frac{1}{|R|} \sum_{r=1}^{|R|} \sum_{c=1}^{C+1} w_{r}^{k} y_{c r}^{k} \log x_{c r}^{R k} Lrk=−∣R∣1r=1∑∣R∣c=1∑C+1wrkycrklogxcrRk

总损失函数如下:
L = L b + ∑ k = 1 K L r k \mathrm{L}=\mathrm{L}_{\mathrm{b}}+\sum_{k=1}^{K} \mathrm{~L}_{r}^{k} L=Lb+k=1∑K Lrk