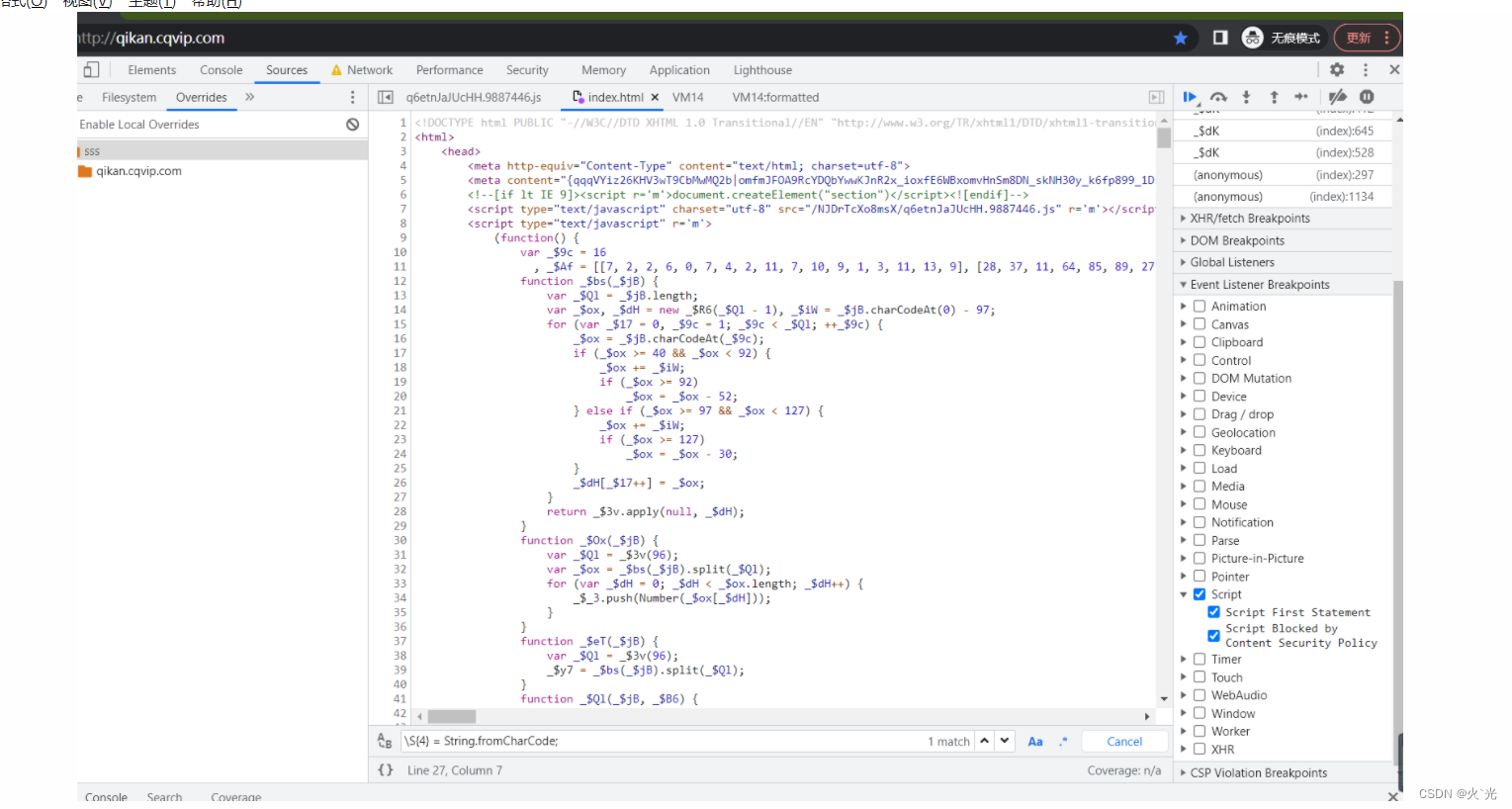
瑞数5解密
首先看请求,请求返回202大概率是(瑞数3,4).返回412是瑞数5
还可以看后缀值 MmEwMD=4xxxxx 就是4代瑞数,bX3Xf9nD=5xxxxx 就是5代瑞数
区别4带上来有1-2个无限debugger,这个直接过掉就好,还会有一个假cookie,5带没有
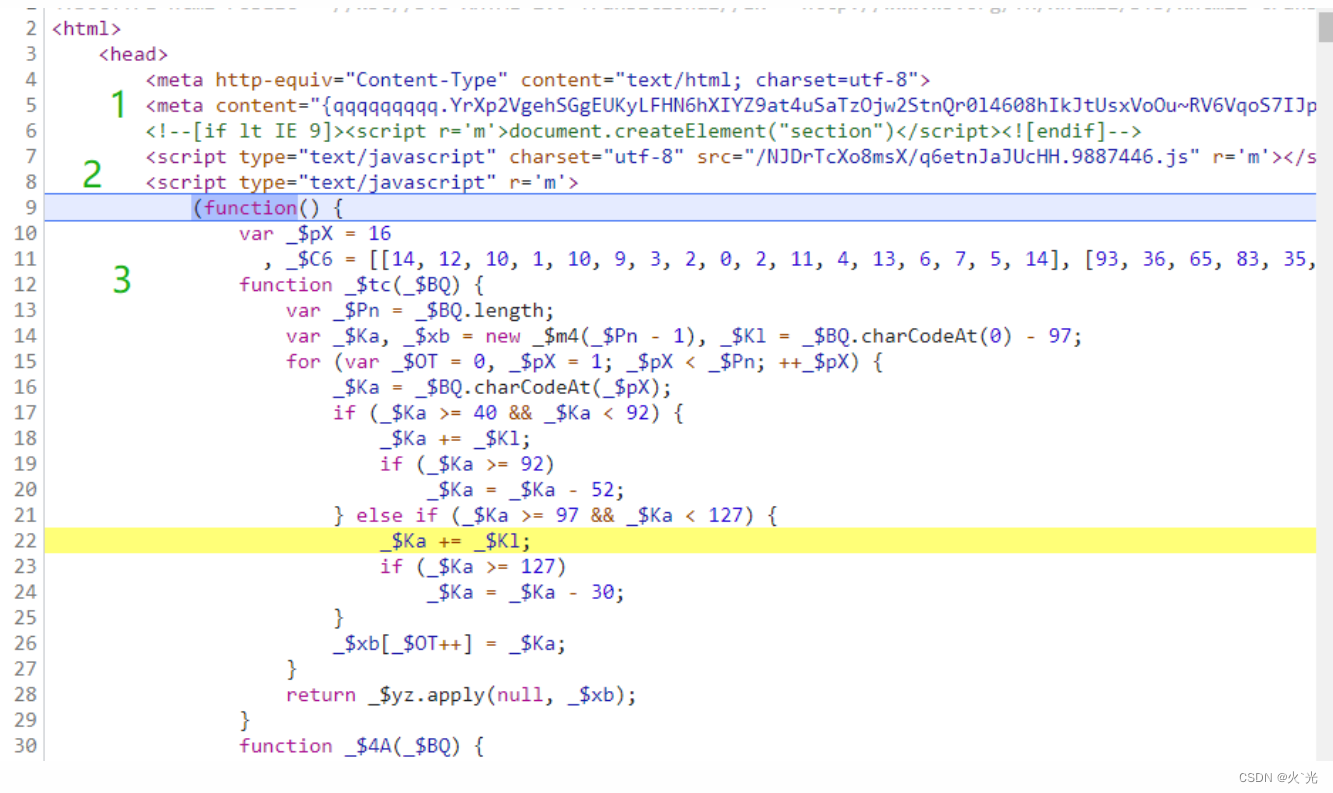
1.meta content 动态的每次请求都会变化(在eval执行到第二层js代码会用到)
2.外链js,内容固定的,自执行函数会解密文件内容生成eval执行时需要的JS源码
3.自执行函数,逻辑不会变,但是名称会变,主要是解密外链JS内容,给window添加一些属性如$_ts,会在vm中使用;
像下图这样,JS来源显示为VM+数字的形式,这就说明这些JS代码是后来加载进引擎的。
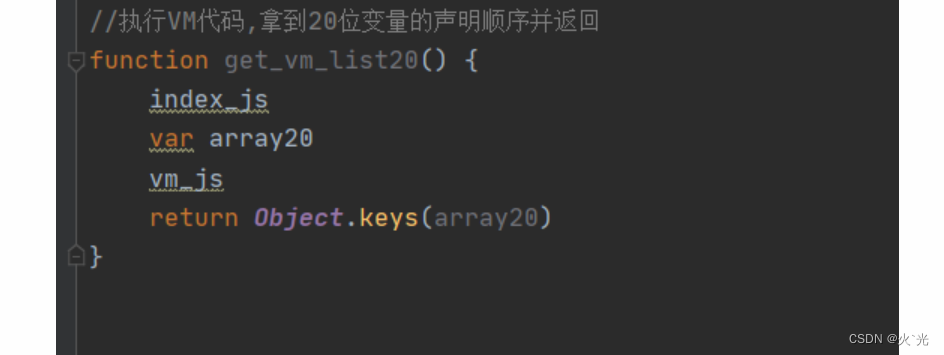
1.首先找到vm入口call调用的 正则入口:\S{4} = \S{4}[\S{4}[\d{2}]](\S{4}, \S{4})
2.进去hookcooki,找到cookie初始位置
cookie初始位置 正则入口:return \S{4}[.+] + \S{4} + \S{4}(\S{4}(\S{4}, \S{4}))

3.找到生成cookie函数的入口
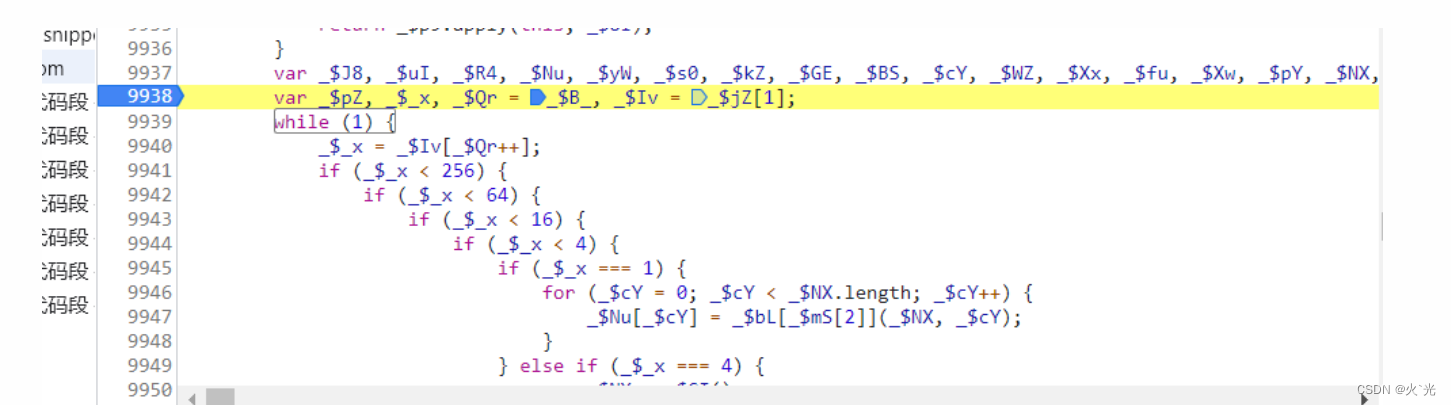
下生断点,接着下日志断分析出4个参数的生成逻辑
第一个参数代表瑞数版本,不用分析
第二个参数,下日志断,生成位置

找到生成参数的逻辑,是由真假时间戳生成4个参数,生成一个16位数组,进行异或运算,转换成字符串来的

16位数组生成逻辑,正则入口;\S{4} = \S{4}([\S{4}, \S{4}, \S{4}, \S{4}])

第三个参数生成位置正则入口;return \S{4}[\S{4}[\d+]][\S{4}[\d+]][\S{4}[\d+]]([], \S{4});

把128位的大数组,去除空值,拆分成一个大数组(核心关键)
第三个参数的参数位置,正则入口\S{4}[\S{4}[\d+]](\S{4}, \S{4}.length - \S{4});

此处为去除128数组的空值
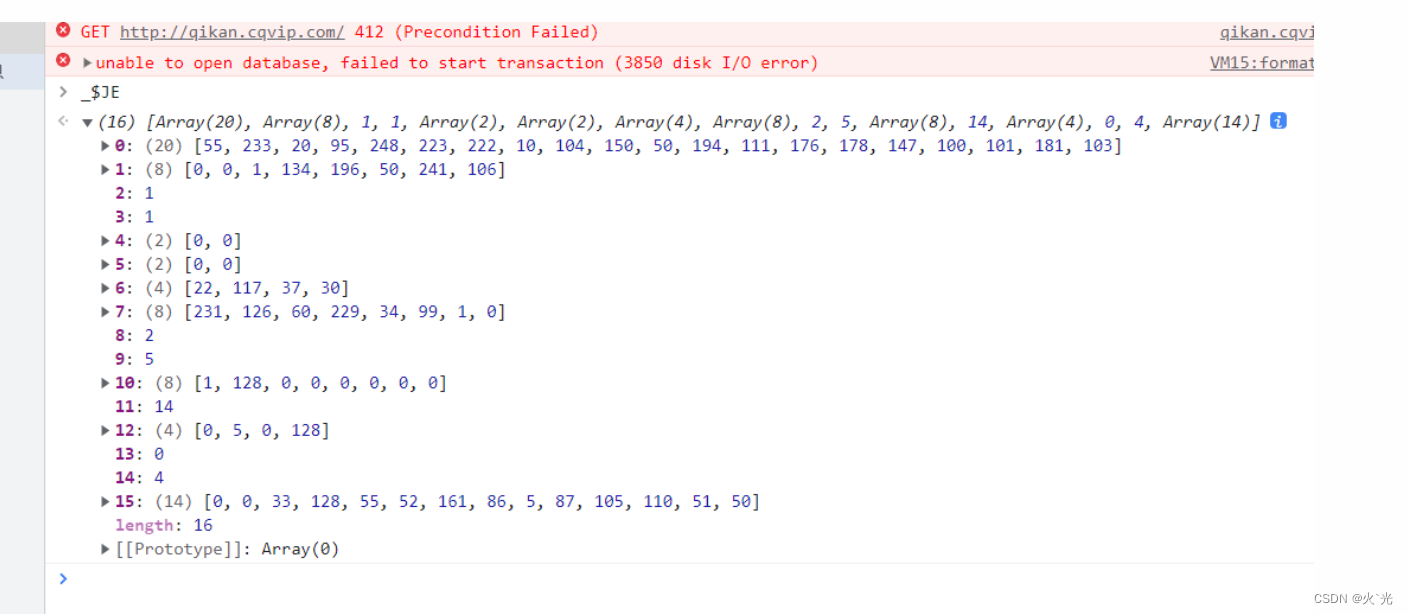
此处多开几次分析后得出 就0,1,6,7需要找出其逻辑,其他参数固定不变的,扣出即可

创建一个128位的空数组,下面表示起始位置0
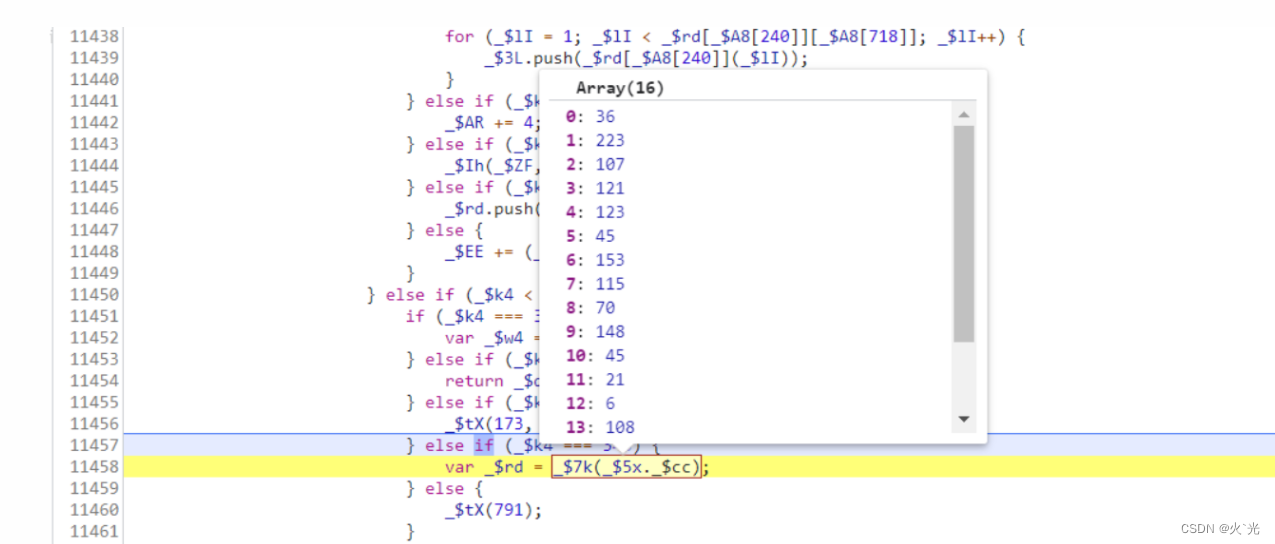
128[0]的生成逻辑,_ 5 x 就是 w i n d o w . 5x就是window. 5x就是window._ts, 赋值层代码后续给出,这个就是window.$_ts的参数生成一个16位数组,是128[0]20位数组中的一部分
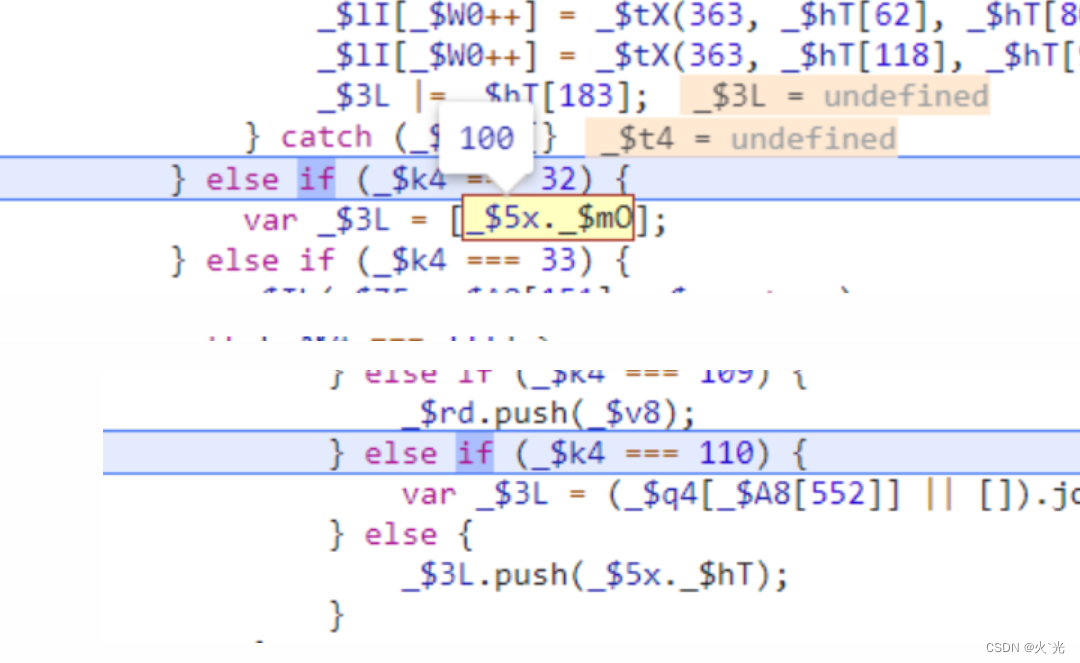
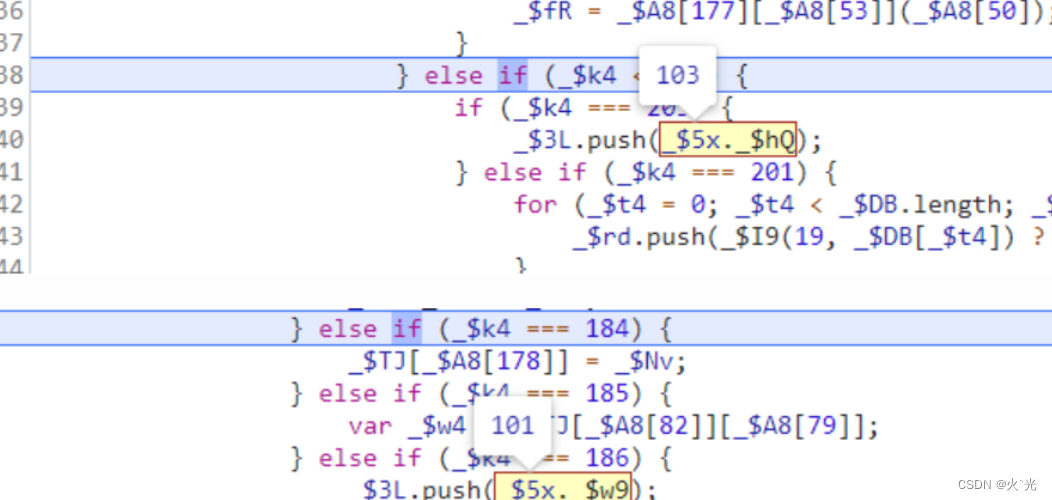
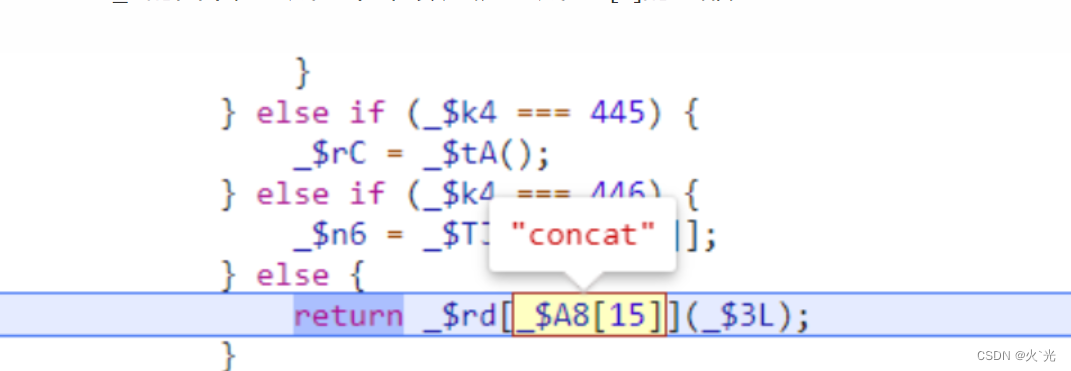
此处是取出window.$_ts的四个值生成一个4位数组,是组成128[0]的一部分
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HhbtoCpl-1679590866003)(瑞数5解密.assets/image-20230323232152704.png)]
此处就是,16位数组拼接4位数组,生成128[0]的20位数组,这里面的难点在于4位数组,该4位数组的顺序和值的映射很重要,需要分析出映射关系,当你扣出代码时,会发现window.$_ts的4个值是4个参数,这时候就要跟栈分析出20位参数,找到对应关系.个人感觉这是这里面最难的,麻烦的
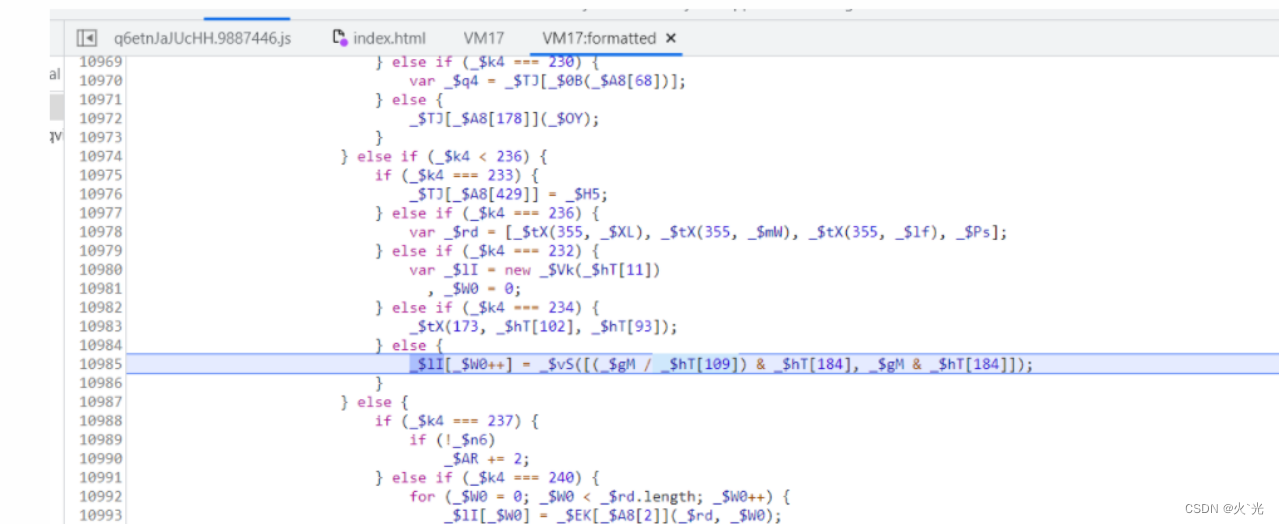
128[1]数组,这里的_$gM就是之前时间戳差值(这里注意一下,这里的插值和第2个参数用的是相同的,需要参数赋值固定)
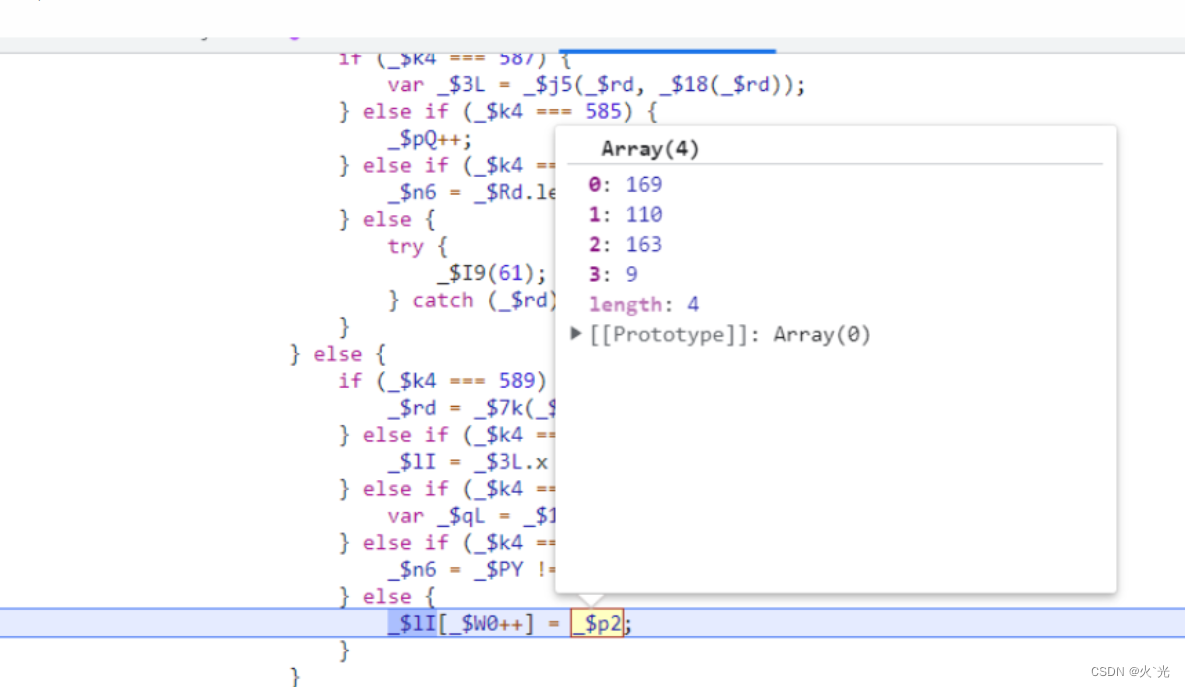
128[6]位,找到入口
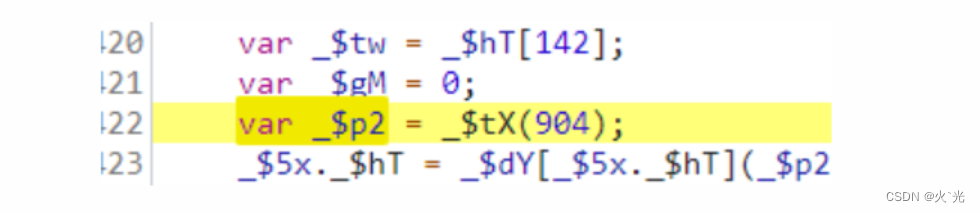
下日志段跟进去分析,下段技巧后面在分享
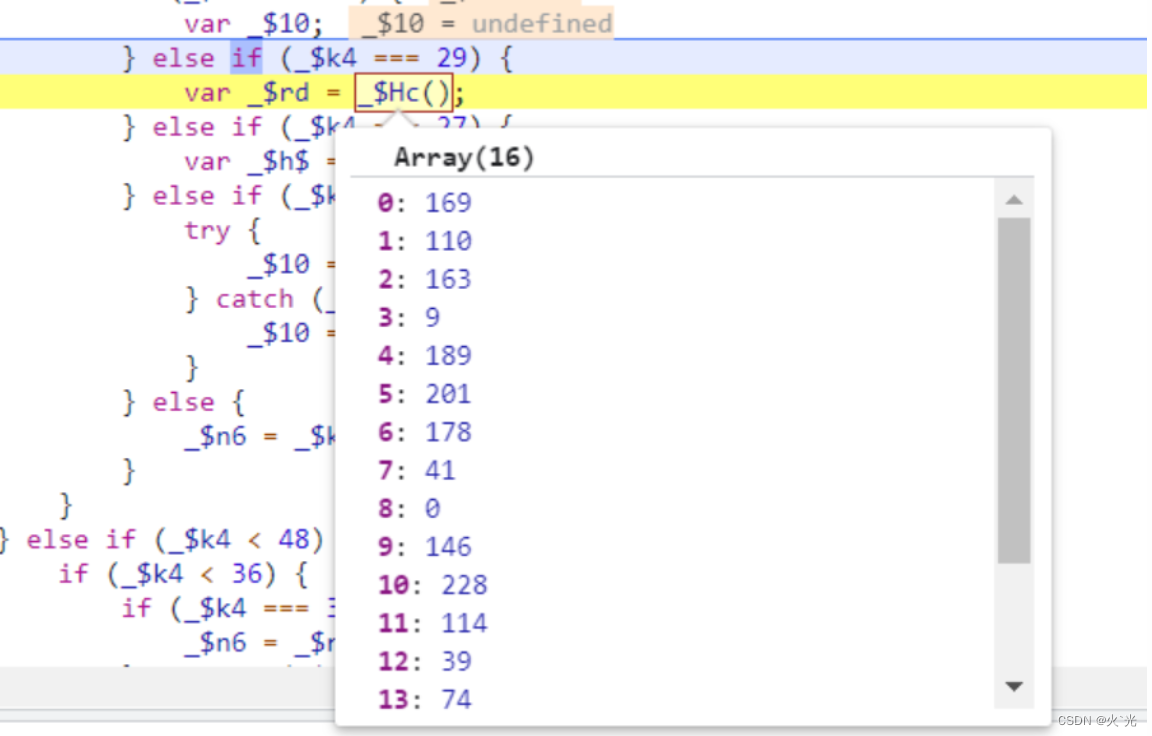
首先生成了一个16位数组,扣出即可
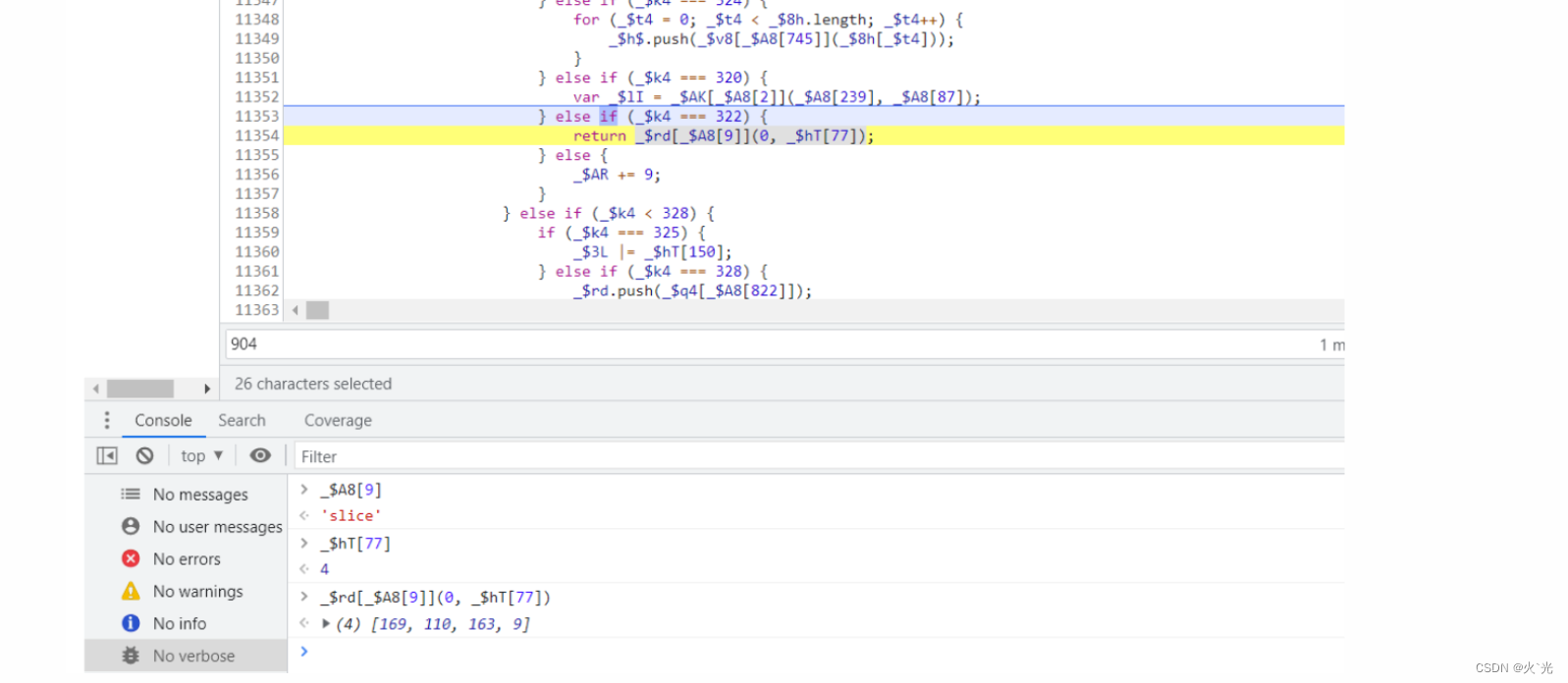
截取16位数组前4位生成128[6]
128[7]位,这里面需要多跟几遍,没啥技巧,我直接给出,我跟的流程,
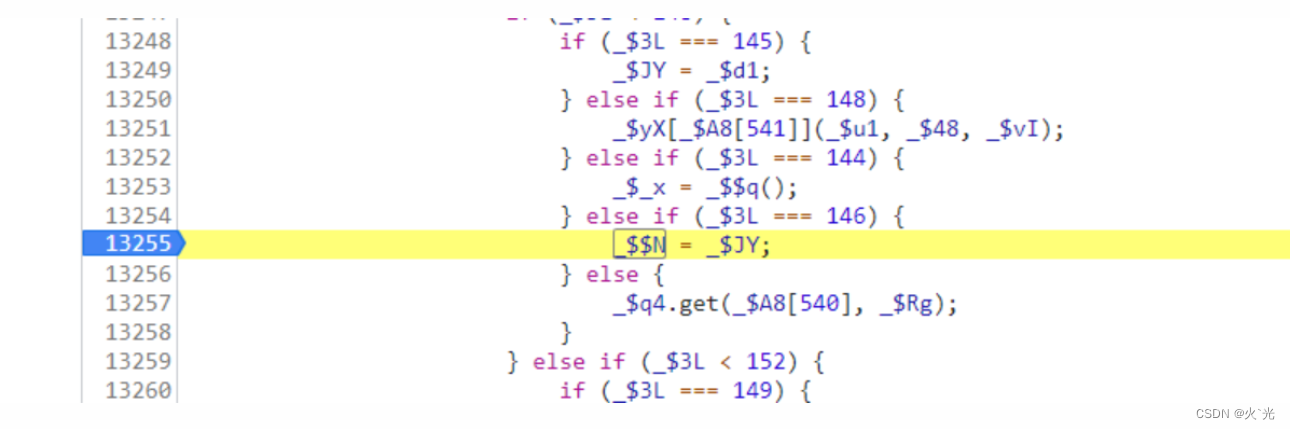
这里下日志段找到的,分析找到在哪赋值的,下断点,单步跟进去,进到支循环在跟
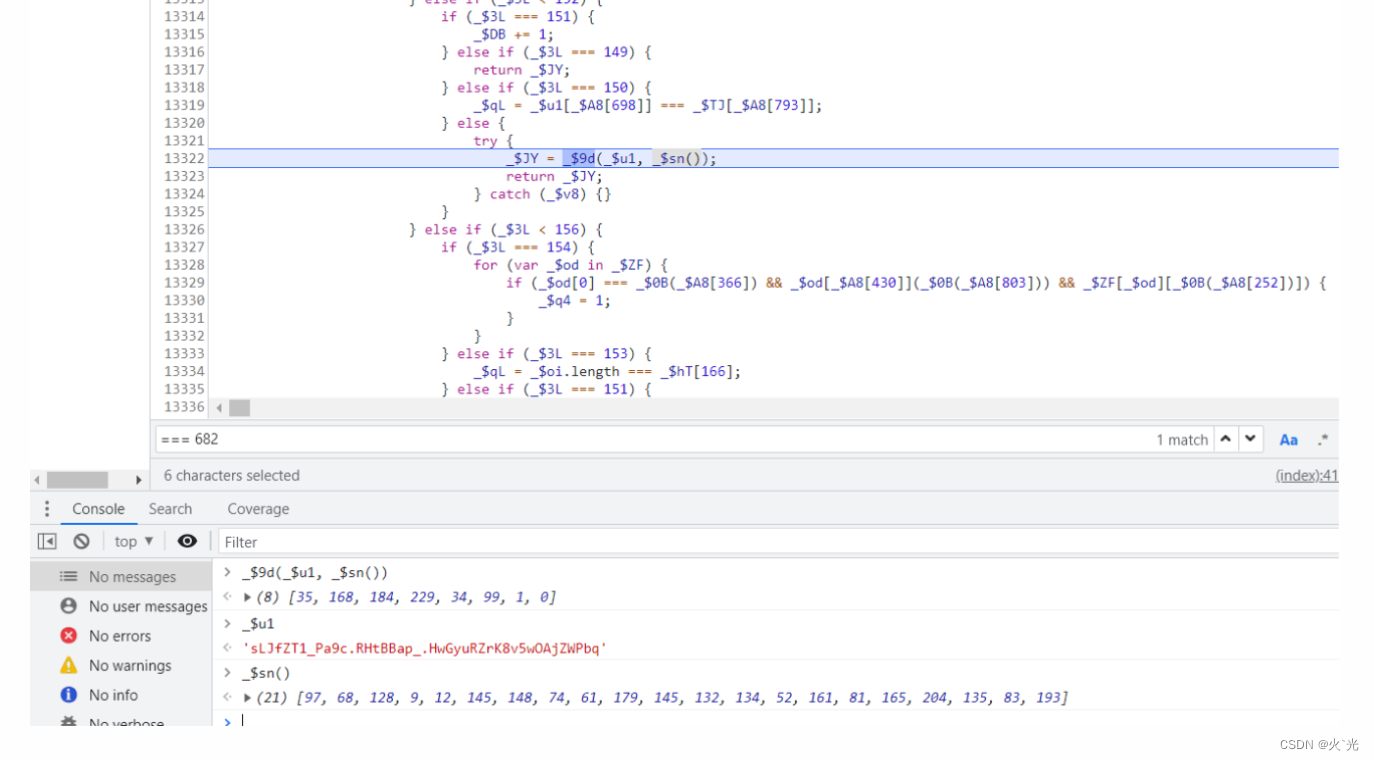
这里面很乱,大小分支,多跟几遍到这里就好了,看下面输出,函数简单扣除即可,这个字符串要找到生成逻辑其实就是![]https://img-blog.csdnimg.cn/42600e1a343c4c9ba09d0188988a56ea.png)
这里赋的值,扣除即可
参数找齐了
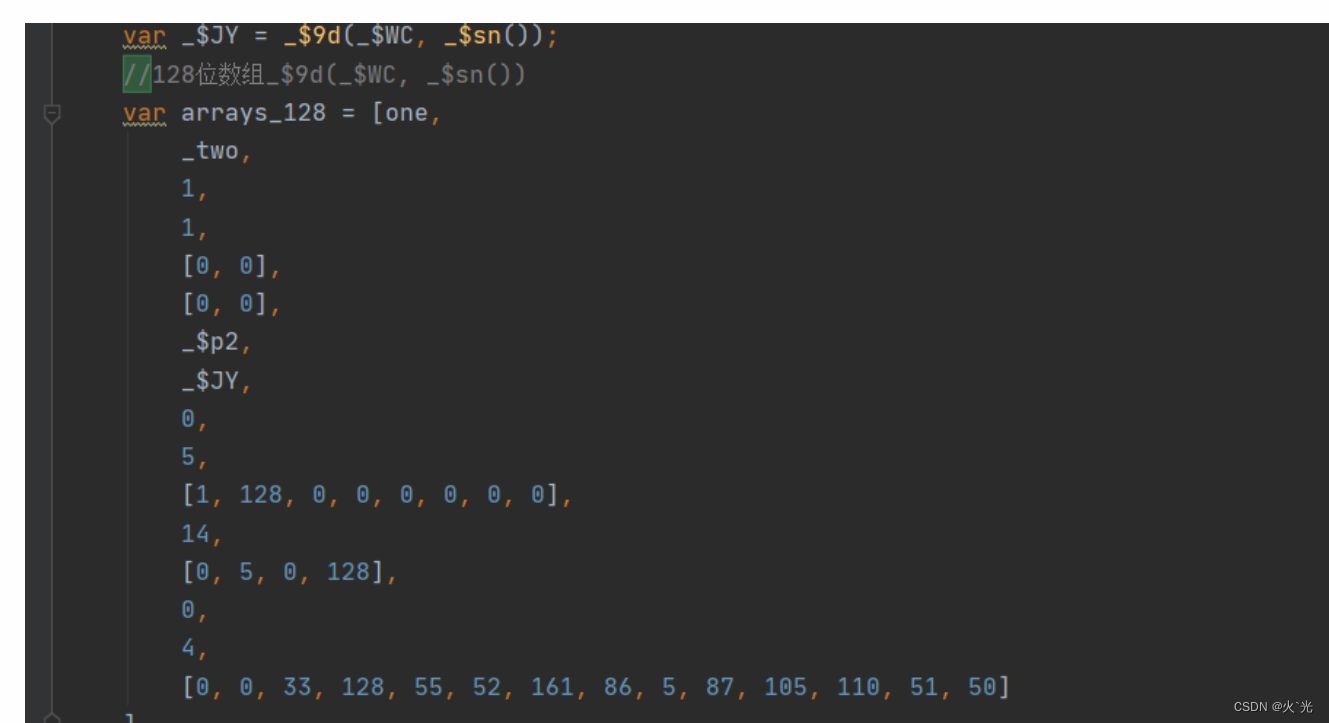
下面最后一位参数,这个参数是2个16位数组拼接而成
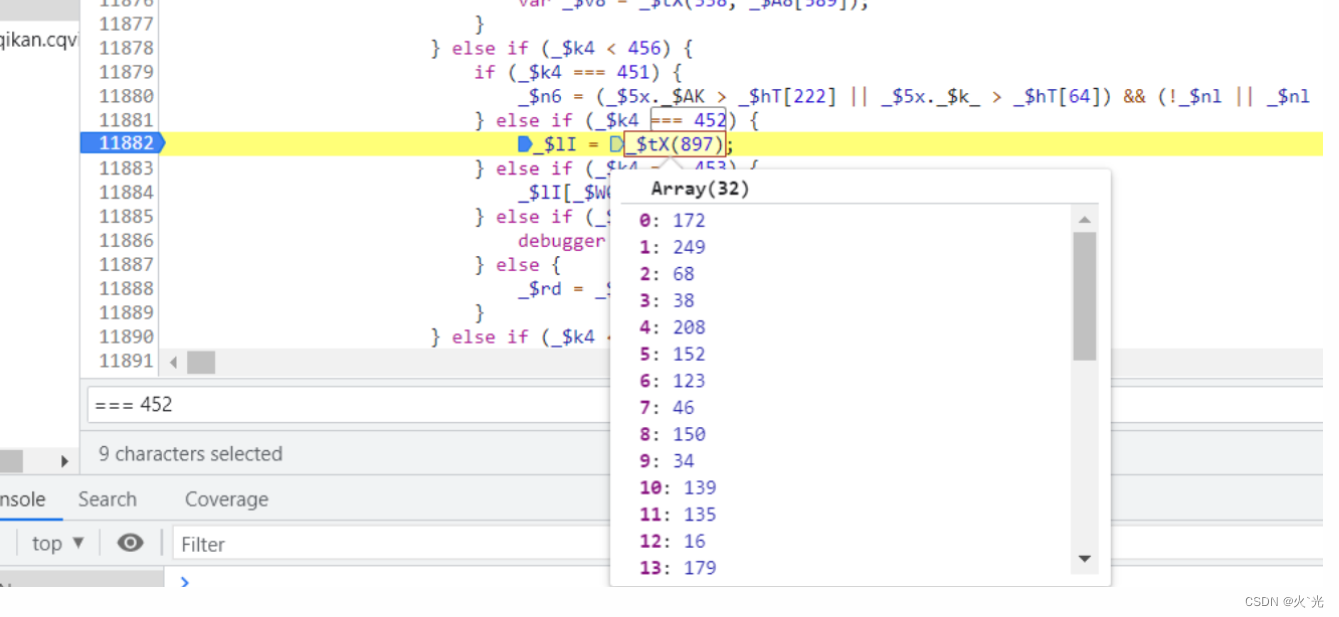
断点进去跟
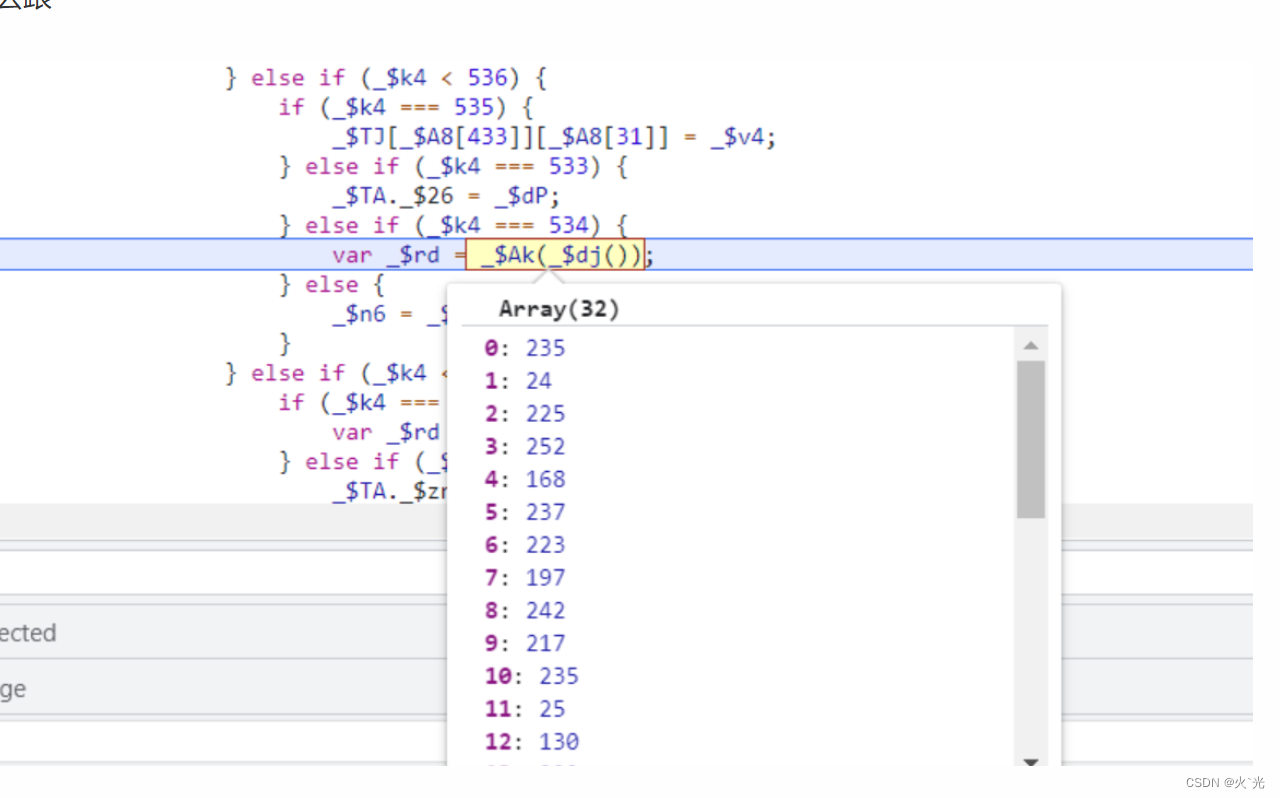
生成一个32位数组
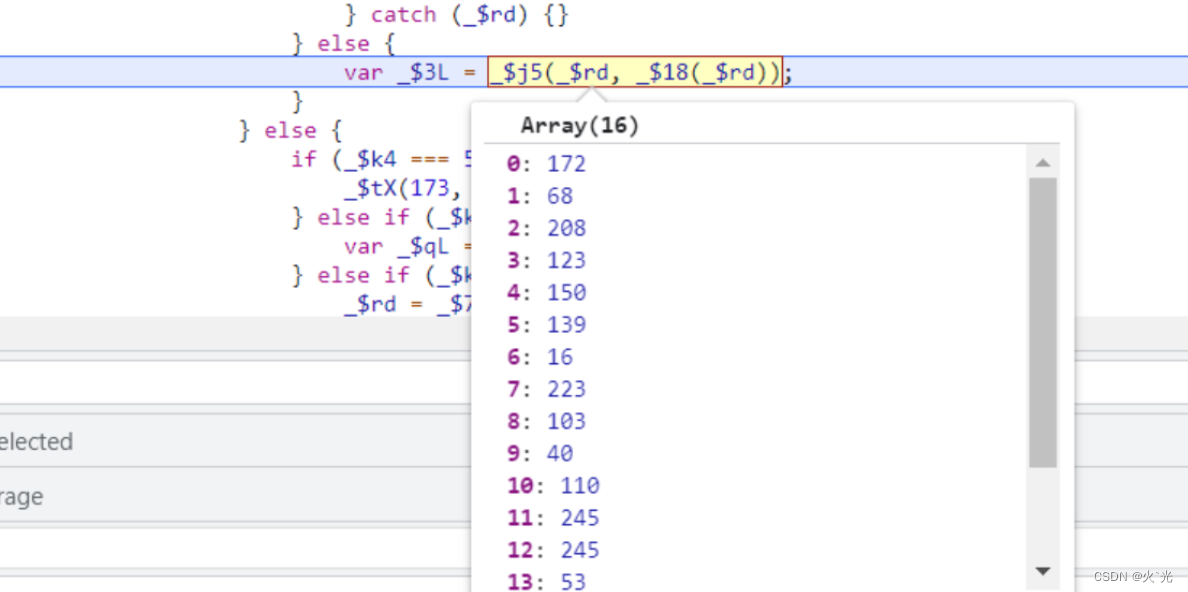
从32位数组中,抽出一个16位数组,是第4参数中的第一个16位数组
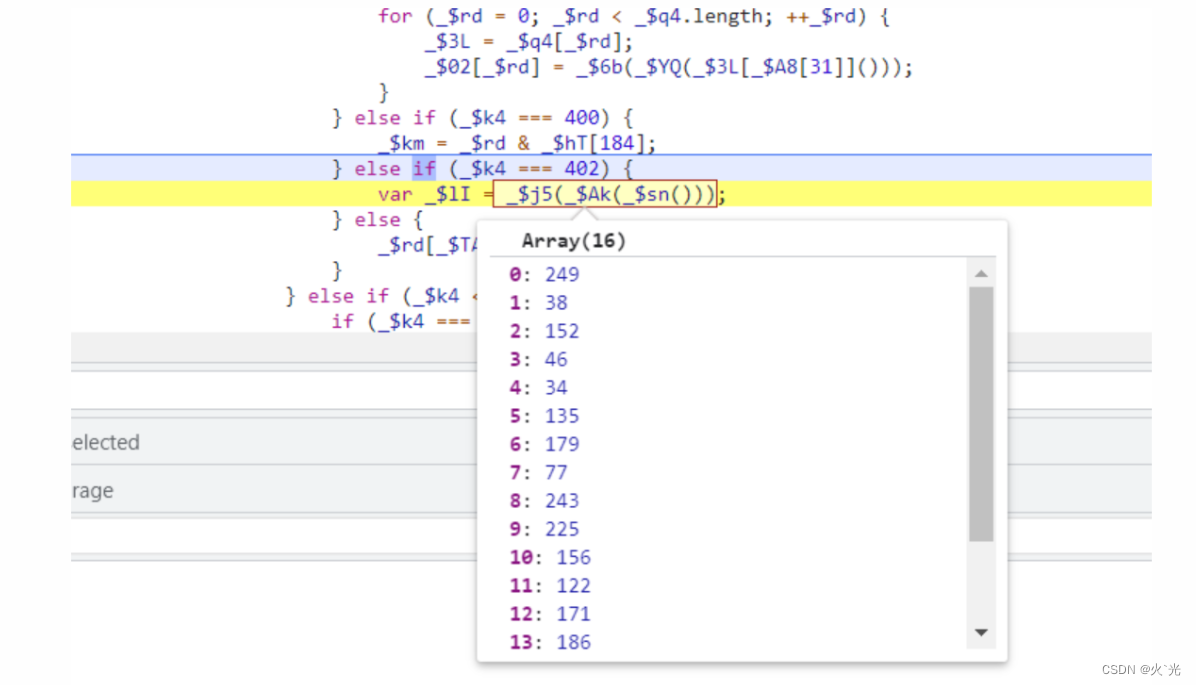
第二个16位数组

生成32位数组,参数齐了,有点乱,下面详细分析一遍
下面是赋值层分析
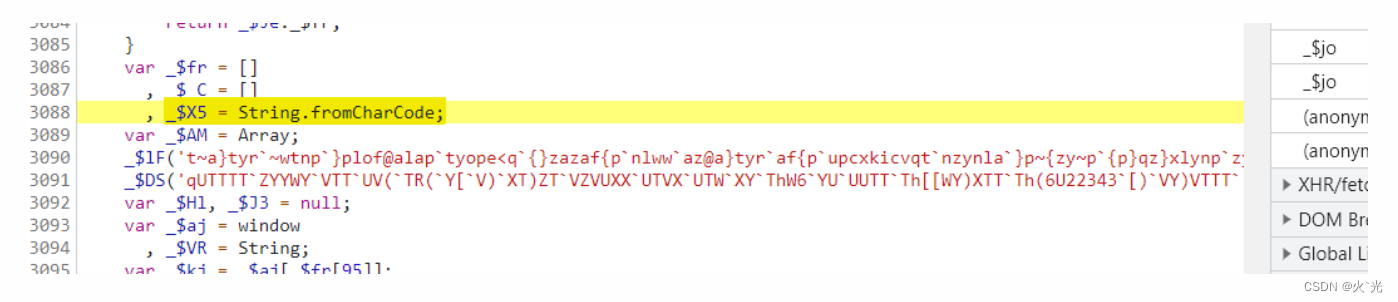
定义两个数组,下面是向数组赋值,关键,后续要常用
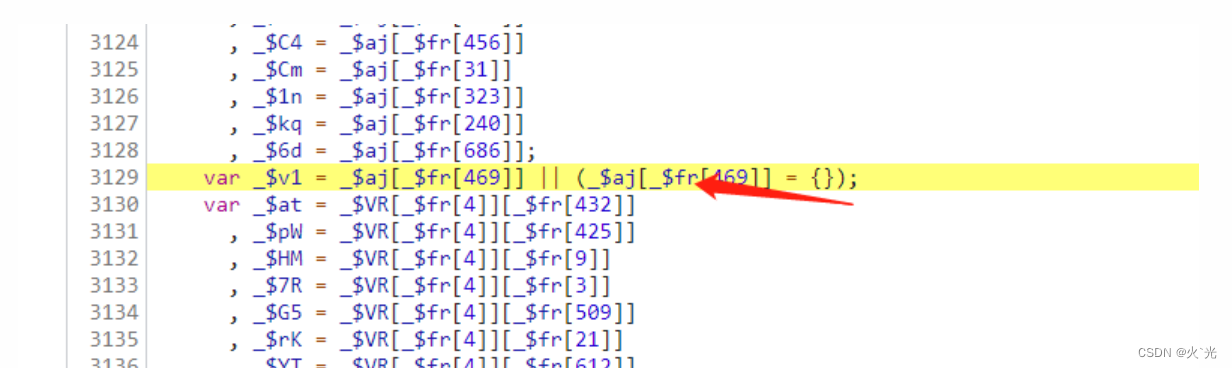
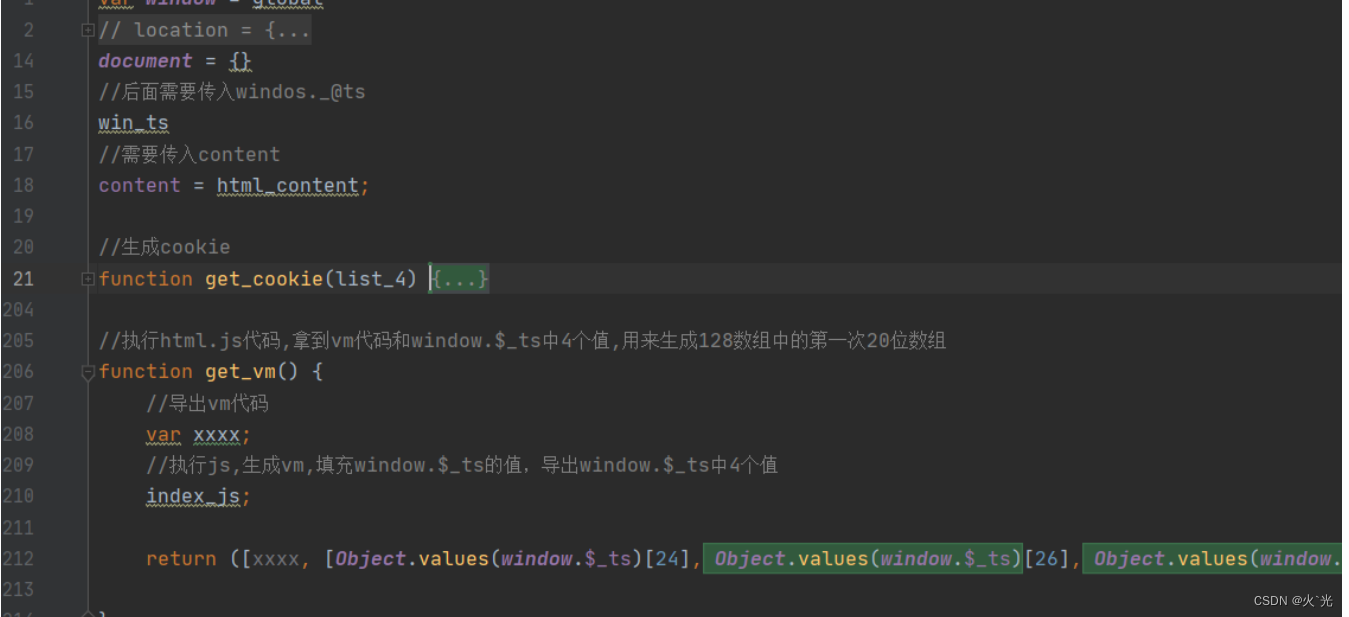
赋值window.$_ts,并清空,扣代码时,删除即可
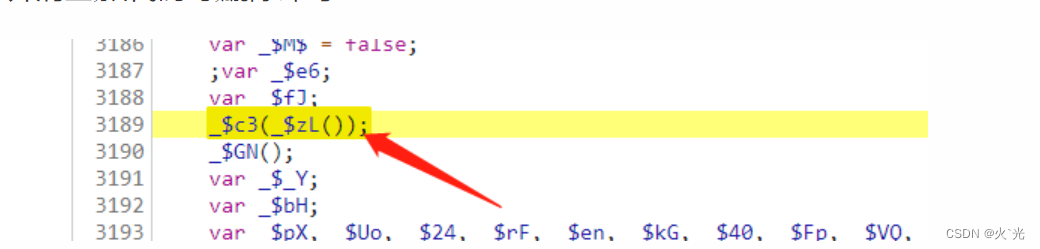
读取content,扣代码时,直接填写进来就行了
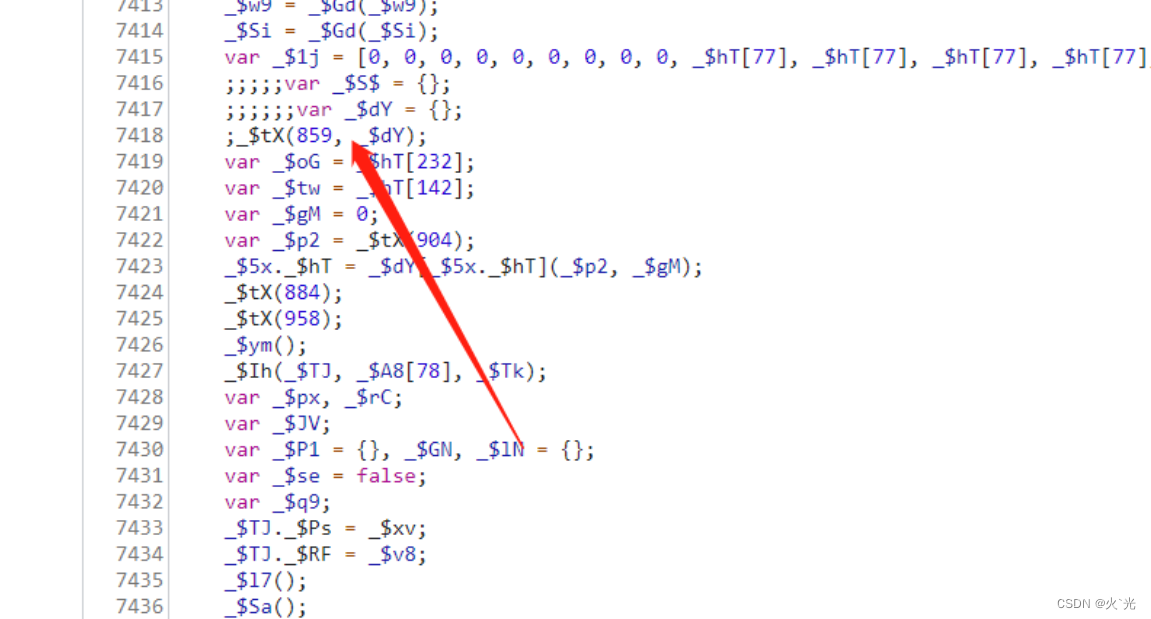
20位key函数的映射关系,128[0]的后四位会用到
KaTeX parse error: Expected group after '_' at position 4: 5x._̲hT = $dY[KaTeX parse error: Expected group after '_' at position 4: 5x._̲hT](KaTeX parse error: Expected group after '_' at position 5: p2, _̲gM);这里是4为参数的生成逻辑,理解下就行了,补环境会用到
我这纯扣算法用不到,理解下就行了

这个分支生成了一个4位数组,充当第6位就是128[6]
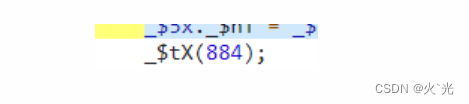
此分支生成的真假时间戳,懒得放图了,
赋值层分析完毕
逆向分析,下面都是重点
_window. t s 初始值 , 和经过 i n d e x . j s 的 w i n d o w . _ts初始值,和经过index.js的_window. ts初始值,和经过index.js的window._ts值
content读取,计算,vm入口
上面的两个大数组
一个填充的20位函数(生成128[0]中的4位数组关键)
一个生成第6位数组的分支,分支后面替换出扣出的代码即可
时间戳的分支(涉及到第二位参数,和128[1]数组)
128位数组
32位数组
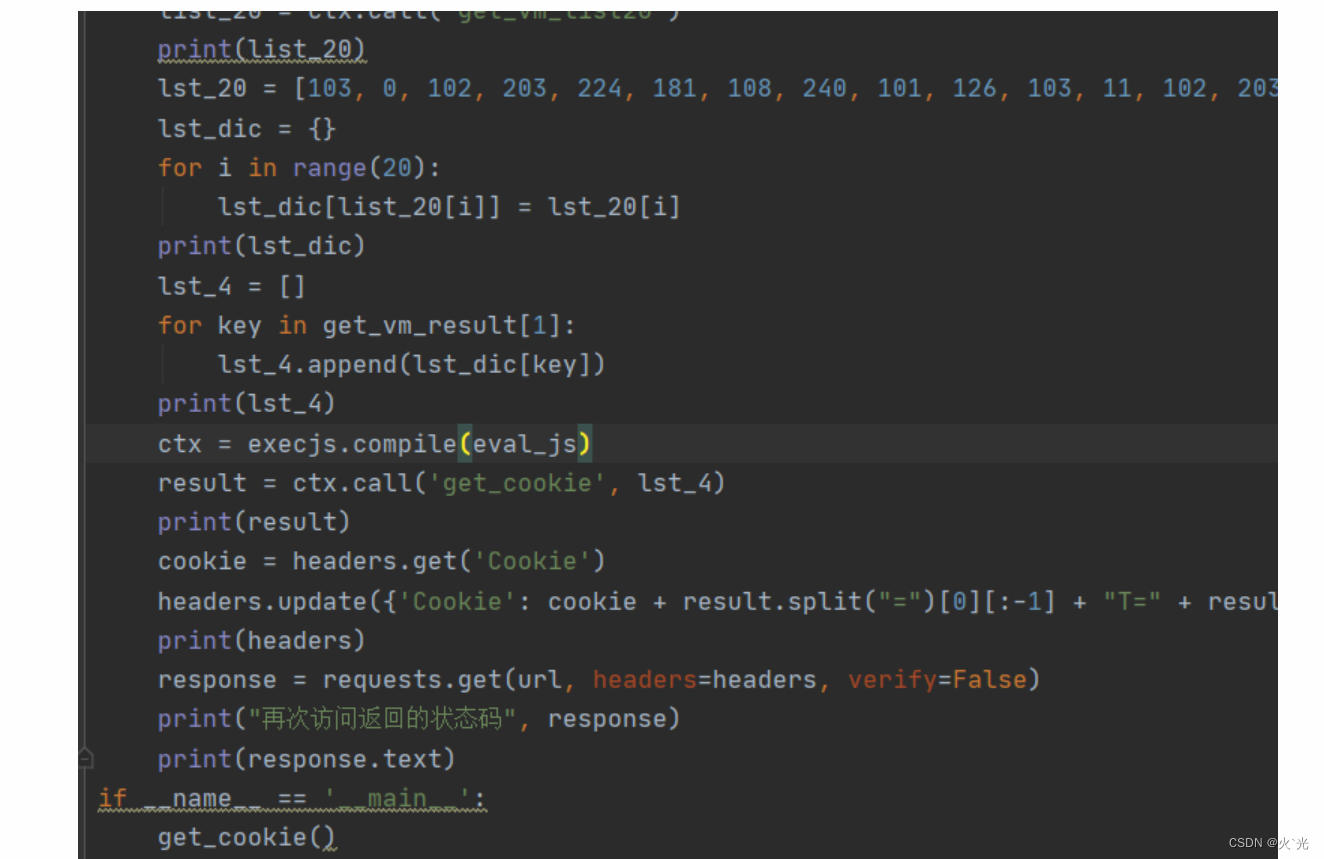
下面是扣的一部分关键代码
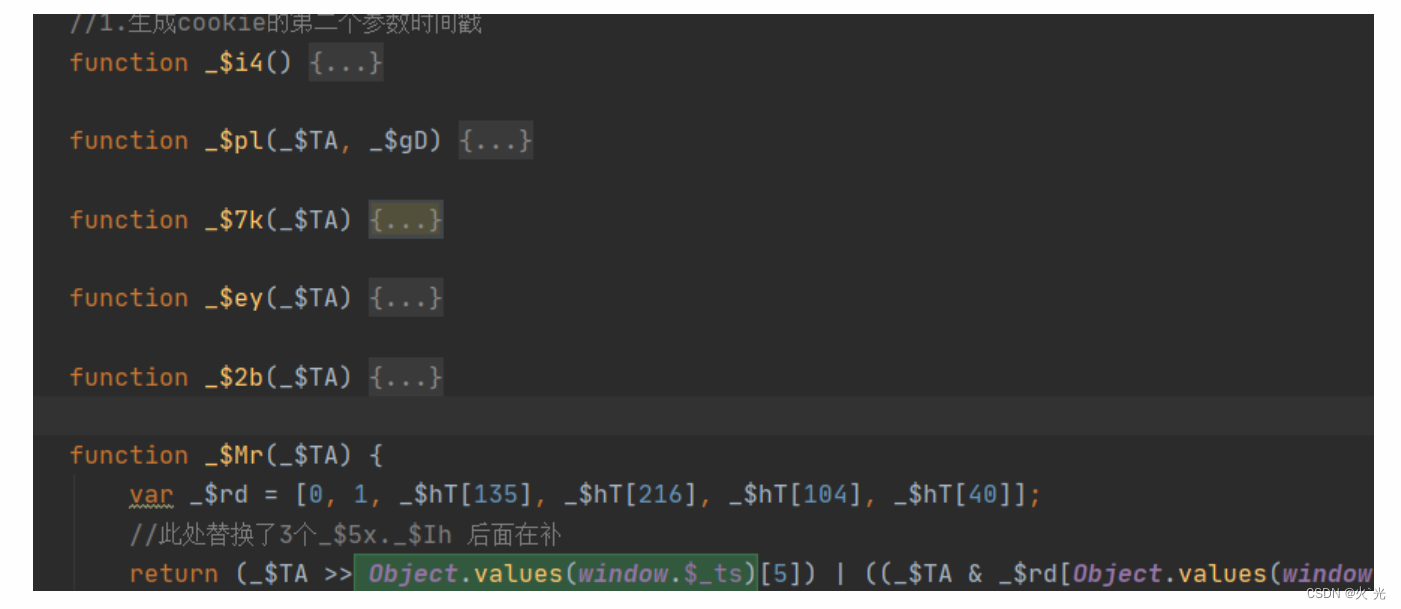
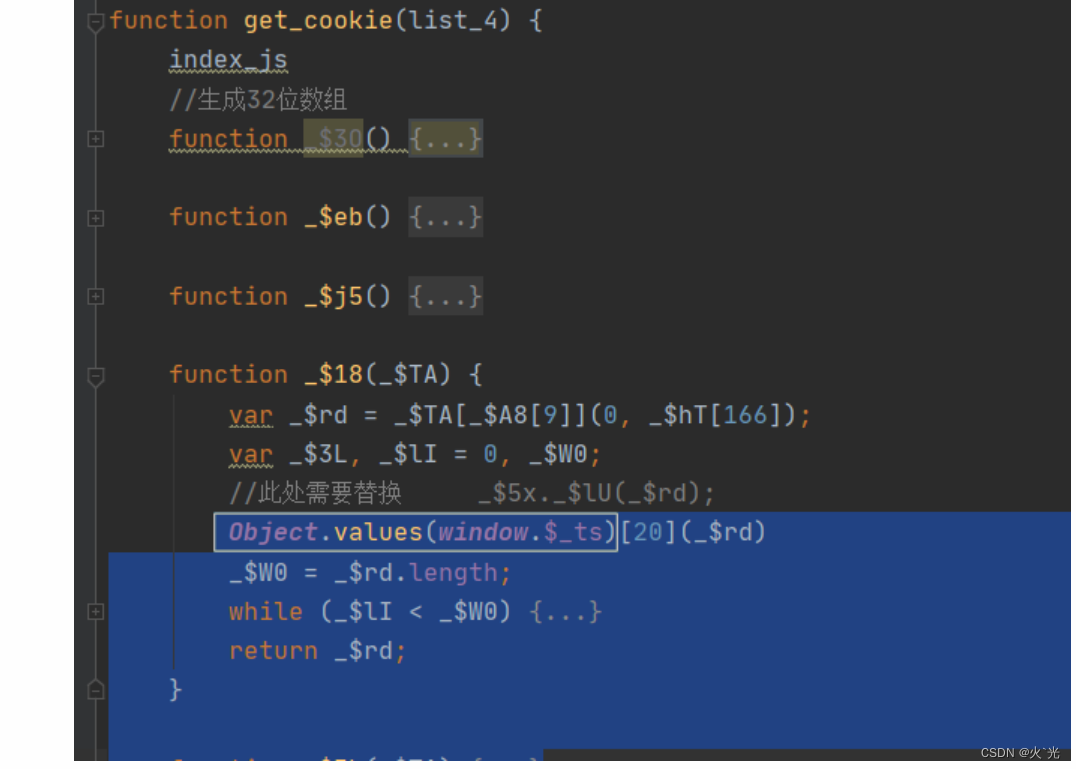
需要替换
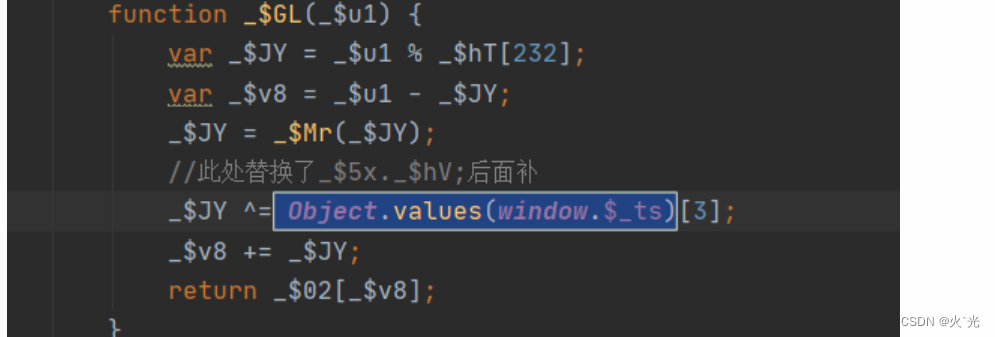
扣操作content时需要替换

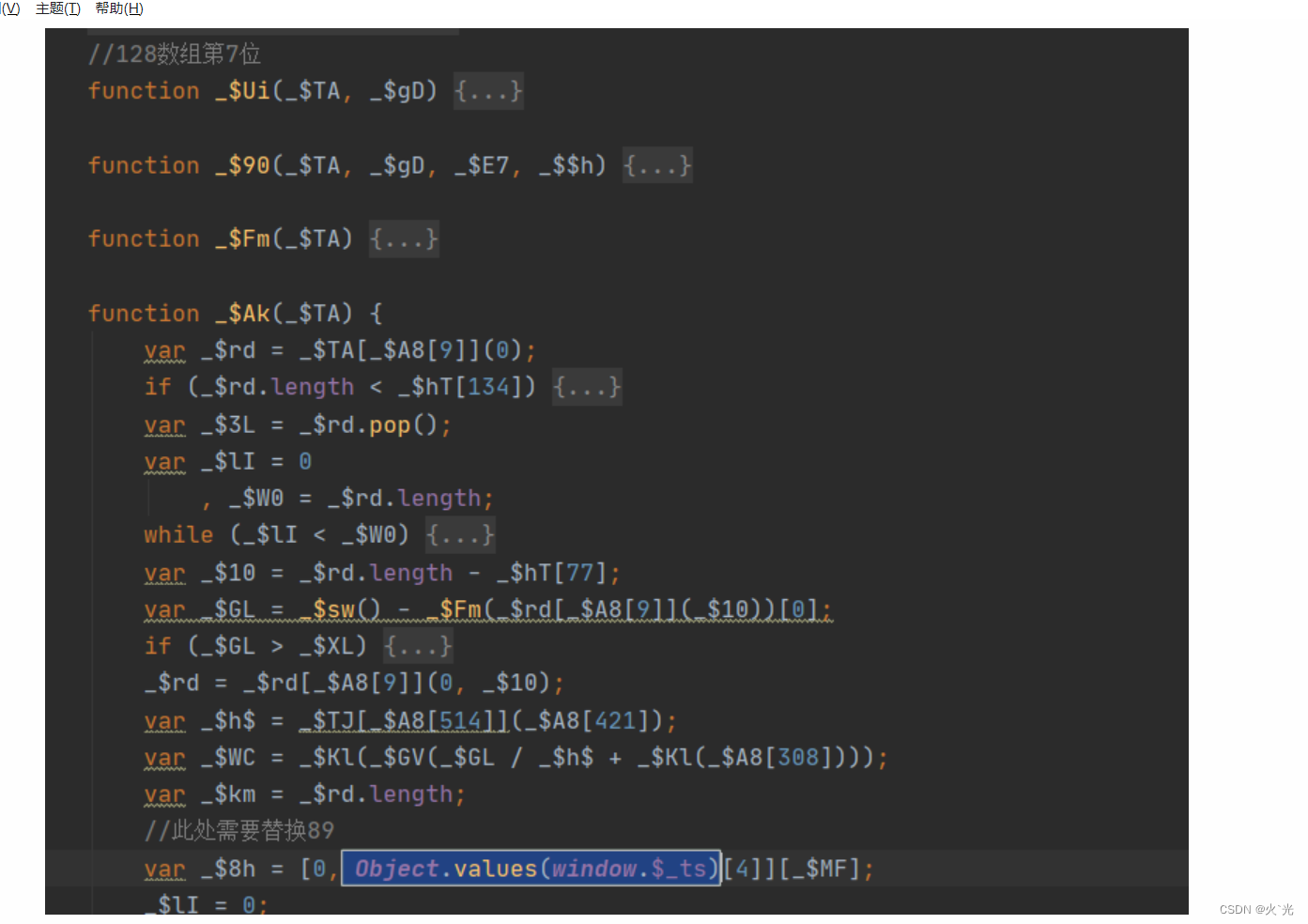

这些都是之前赋值window.$_ts需要替换,第20位有可坑那个函数需要二次加载在能出来,要不会显示空

最后一点分享
插装输出的前提是,在每生成目标值之前,下日志,然后等执行输出日志结果然后分析
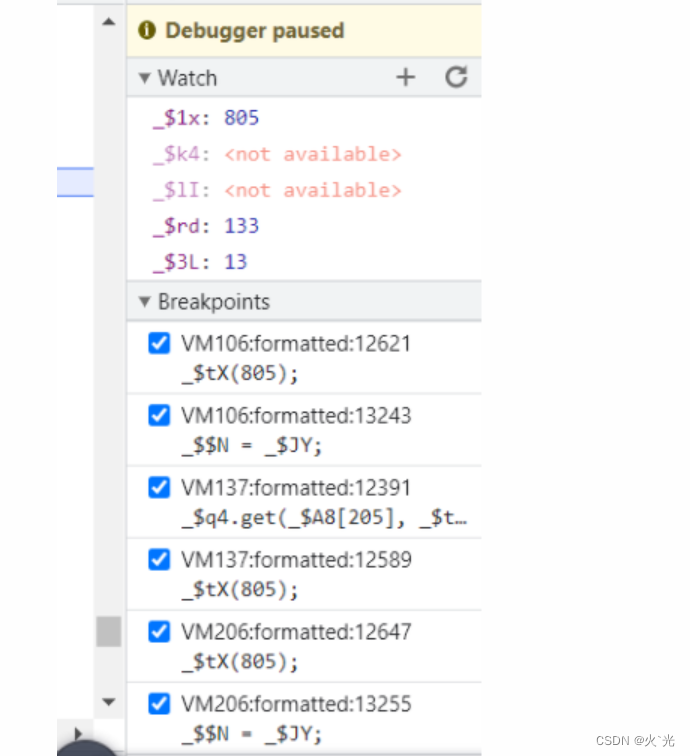
此图第一个参数是主分支,第二是支分支,后面两个是需要分析的参数,这样的好处是因为有的时候跟着跟着
就会找不到自己处在那个位置很容易跟丢,这样就不会很乱,所以大家下段最好学会用Watch
'索引1_KaTeX parse error: Expected group after '_' at position 5: ZX',_̲ZX,'索引2 _KaTeX parse error: Expected group after '_' at position 6: qQ', _̲qQ,'目标1 KaTeX parse error: Expected group after '_' at position 6: lI', _̲lI,‘参考’,$lE()
下日志断,不要图省事,写清楚不至于乱,最好弄个参考值,可以是时间戳啥的,这样知道自己是不是在主分支里,不至于跟丢
推荐无痕模式下,Script,还有在VM中逻辑不变,但是名称会变,这时候最好固定一套在本地分析,扣代码方便