什么是数据倾斜
在使用一些大数据处理框架进行海量数据处理的过程中,可能会遇到数据倾斜的问题,由于大数据处理框架本身架构的原因,在框架层面,数据倾斜问题是无法避免的,只能在业务层面来缓解或者避免。
因为要处理海量的数据,常用的大数据处理框架都会采用分布式架构,将海量数据分成多个小的分片,再将每个小分片分配给不同的计算节点来处理,通过对计算节点进行横向扩容,来快速提升框架的数据处理性能,因此即使是海量数据,也可以在较短的时间内完成处理,但是也正是由于这种架构设计,导致了数据倾斜问题的产生。
试想,如果小分片中的数据分布不均匀,有某个或者某几个小分片中包含了80%的数据量,那么处理这些分片的计算节点压力就会比较大,就会导致,整个分布式集群中,大部分节点是空闲的,只有某几个比较繁忙,无法使计算资源得到重复利用,最终导致框架的整体效率比较低。
如何解决数据倾斜
因为产生数据倾斜问题的直接原因就是数据分布不均匀,要解决这个问题最直接的方法就是:在业务层面将数据的分布变得均匀一些,让分布式集群中每个计算节点的资源得到重复利用。
因为数据分布不均匀是业务层面的问题,将数据分布变均匀的方案,也要结合业务场景来设计,下面我们以wordCount为例来演示以下数据倾斜问题,以及相应的解决方案。后面当遇到数据倾斜问题时,希望对你有一定的启发。
实践案例
下面是一个wordCount的程序的实现:
public class ShuffleWindowFunctionTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvBase.getStreamEnv(9091);
DataStreamSource<Tuple2<String,Integer>> sourceStream = env.addSource(StreamExecutionEnvBase.getRandomStringSource(1000000, 1));
(sourceStream.keyBy(new KeySelector<Tuple2<String,Integer>, String>() {
@Override
public String getKey(Tuple2<String,Integer> value) throws Exception {
return value.f0 ;
}
})
.timeWindow(Time.seconds(5))
.process(new ProcessWindowFunction<Tuple2<String,Integer>, String, String, TimeWindow>() {
Map<String, Integer> map = new HashMap<>();
@Override
public void process(String s, Context context, Iterable<Tuple2<String,Integer>> iterable, Collector<String> collector) throws Exception {
for (Tuple2<String,Integer> tuple2 : iterable) {
String key = tuple2.f0;
if (map.containsKey(key)) {
map.put(key, map.get(key) + 1);
} else {
map.put(key, 1);
}
}
for (Map.Entry<String, Integer> entry : map.entrySet()) {
collector.collect(String.format("key:%s,count:%s", entry.getKey(), entry.getValue()));
}
}
})).setParallelism(8)
.print("total").setParallelism(8);
env.execute("shuffle stream");
}
}
public class StreamExecutionEnvBase {
public static StreamExecutionEnvironment getStreamEnv(Integer webUiPort) {
Configuration conf = new Configuration();
conf.setString("rest.port",String.valueOf(webUiPort));
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
return env;
}
public static SourceFunction<Tuple2<String,Integer>> getRandomStringSource(int count, Integer sleep) {
return new SourceFunction<Tuple2<String,Integer>>() {
Random random = new Random();
String[] values = {"hadoop","flink","spark","redis","redis","redis","redis","redis","redis","redis","redis","redis","redis","redis","redis","redis","redis"
,"redis","redis","redis","redis","redis","redis","redis","redis","redis","redis","redis","redis","redis","redis","redis","redis","redis","redis"
,"redis","redis","redis","redis","redis","redis","redis","redis","redis","redis","redis","redis","redis","redis","redis","redis","redis","redis","redis"};
volatile boolean running = true;
int c = count;
@Override
public void run(SourceContext<Tuple2<String,Integer>> ctx) throws Exception {
while (running && c-- > 0) {
String target = values[c % values.length];
ctx.collect(new Tuple2<>(target,random.nextInt(100)));
TimeUnit.MILLISECONDS.sleep(sleep);
}
}
@Override
public void cancel() {
running = false;
System.out.println("cancel job ...");
}
};
}
}
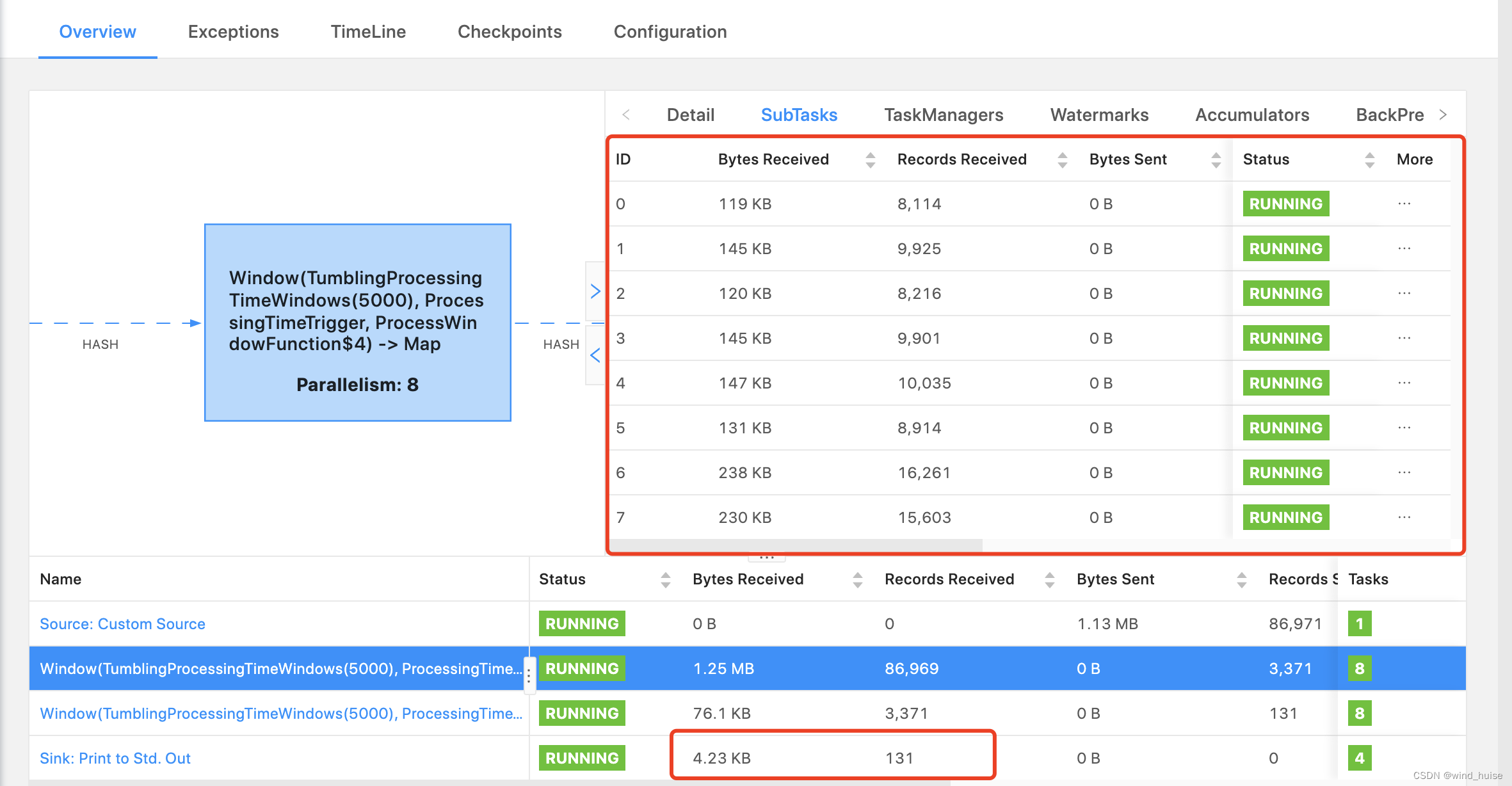
上面的source代码中,word为"redis"的数据量比较大,明显多于其他word的数据量。此时,对于处理"reids"的subTask的压力会比较大,我们可以通过flink的监控来进行验证,具体如下图:
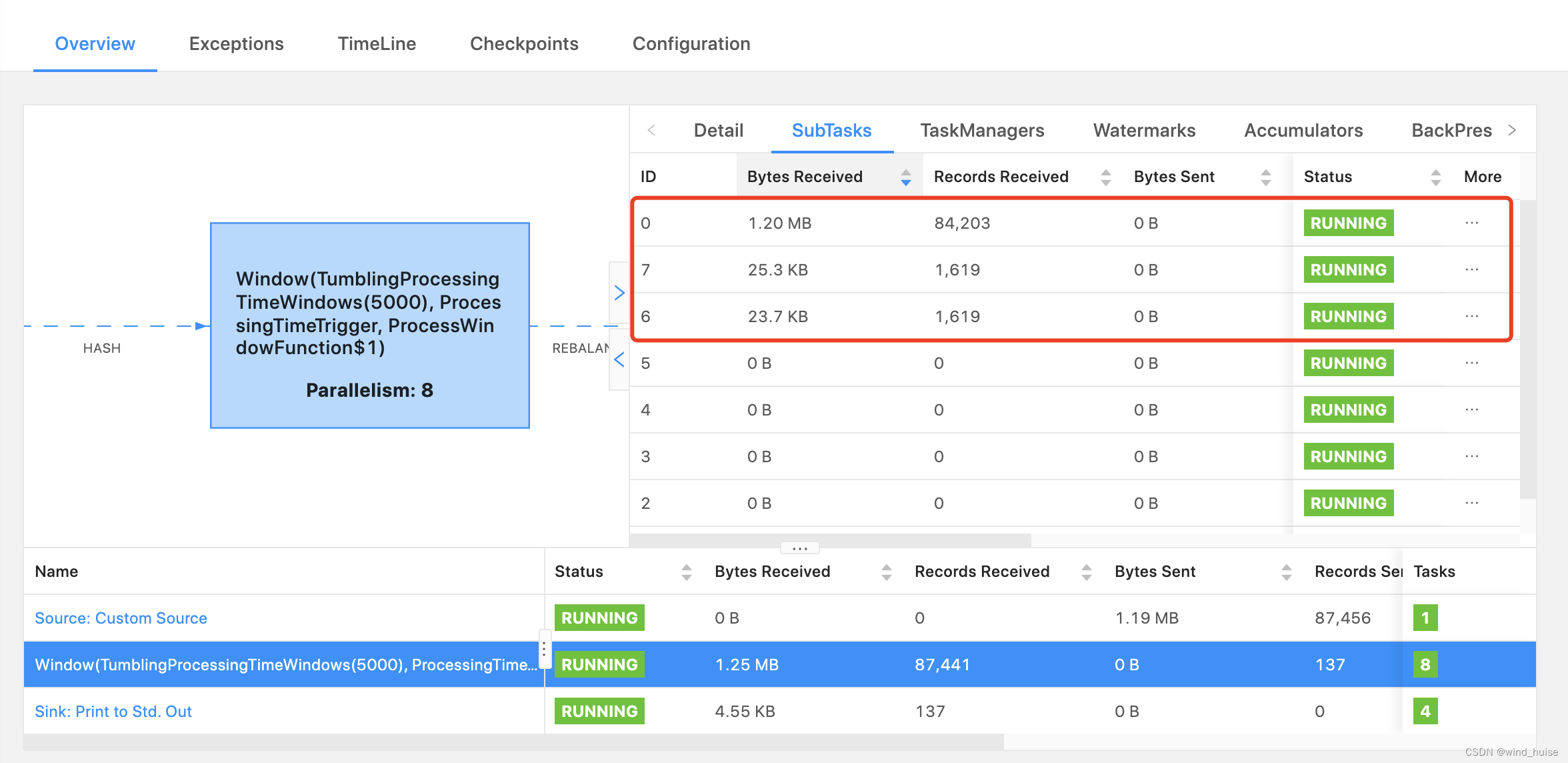
在上图中,可以发现subTask0处理的数据量,是其他SubTask的40倍左右,此时产生了明显的数据倾斜问题。
为了解决"redis"倾斜的问题,我们可以将"redis"生成key的过程进行优化,将生成的key进行"打散",具体实现过程如下:
sourceStream.keyBy(new KeySelector<Tuple2<String,Integer>, String>() {
@Override
public String getKey(Tuple2<String,Integer> value) throws Exception {
if("redis".equals(value.f0))
return value.f0 + value.f1;
return value.f0;
}
}
这样word为redis的数据,生成的key就会被打散成多个,打散的多个key分散到不同的subTask中处理,这样数据倾斜的问题就得到了解决,执行结果如下图:
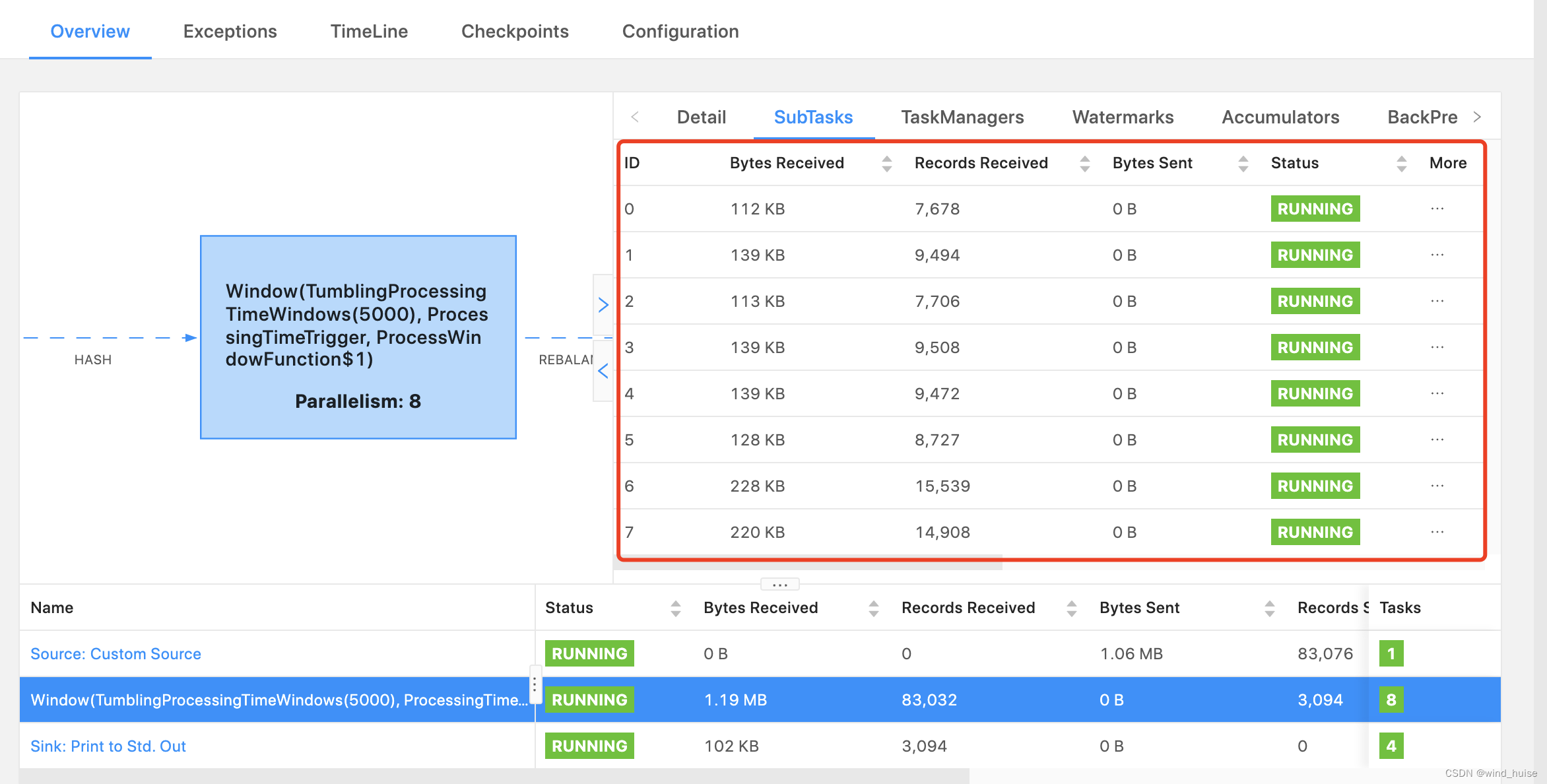
到这里,我们解决了数据倾斜的问题,但是细心的读者会发现,将key打散后,数据倾斜问题虽然解决了,但是sink到下游的数据量也变多了,也就是说,发送到下游的数据聚合度降低了,数据变得更散了,如下图:
优化前:
优化后:
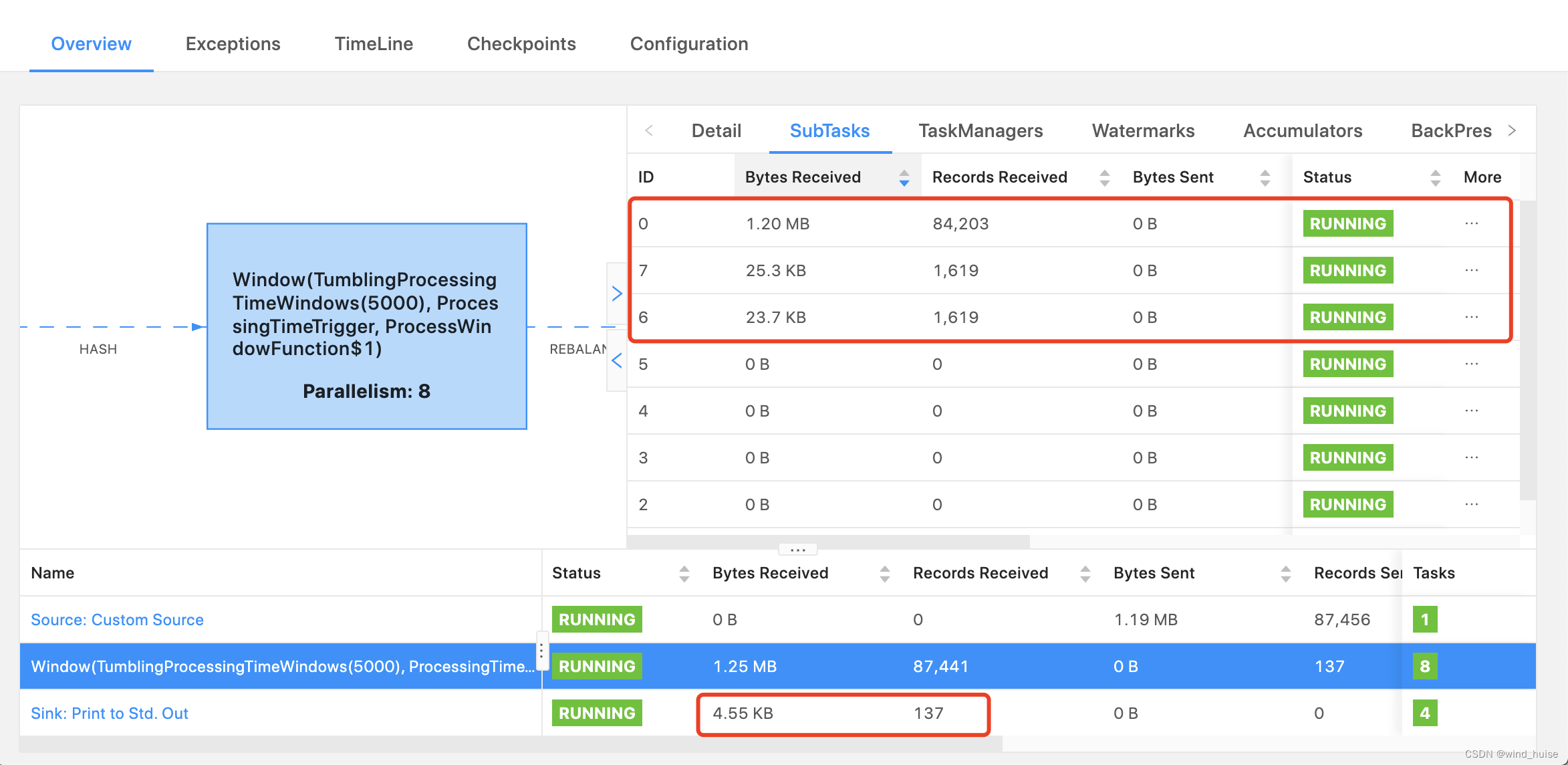
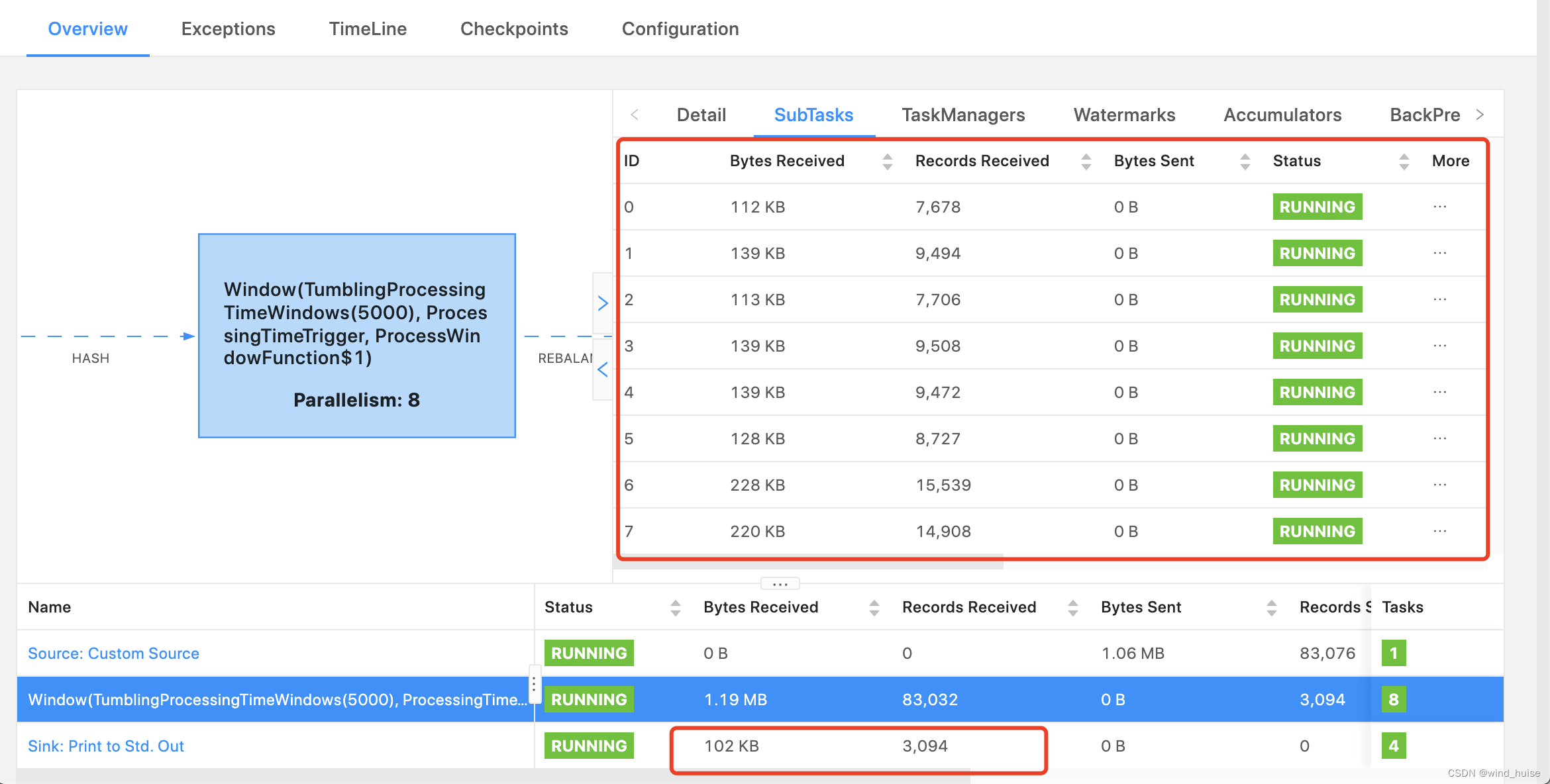
结合之前文章Flink中的Window计算-增量计算&全量计算,我们可以知道,发送下游数据量变多的原因:key变多了,每个key都会对应一个 ProcessWindowFunction 实例,也就是 ProcessWindowFunction 实例个数变得更多,聚合结果 "map"的聚合度就变小了,发送到下游的数据量也就变得更多了。
如果flink的下游是存储层,如mysql,那么大批量的数据写到mysql中,对mysql的并发处理能力和存储都会是巨大的挑战。
那么该如何解决这个问题呢?解决方案其实也很简单:对发送给下游的数据,进行二次聚合,将分散的数据再次聚合一下,具体实现,可以参考如下代码:
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvBase.getStreamEnv(9091);
DataStreamSource<Tuple2<String,Integer>> sourceStream = env.addSource(StreamExecutionEnvBase.getRandomStringSource(1000000, 1));
(sourceStream.keyBy(new KeySelector<Tuple2<String,Integer>, String>() {
@Override
public String getKey(Tuple2<String,Integer> value) throws Exception {
if("redis".equals(value.f0))
return value.f0 + value.f1;
return value.f0;
}
})
.timeWindow(Time.seconds(5))
.process(new ProcessWindowFunction<Tuple2<String,Integer>, String, String, TimeWindow>() {
Map<String, Integer> map = new HashMap<>();
@Override
public void process(String s, Context context, Iterable<Tuple2<String,Integer>> iterable, Collector<String> collector) throws Exception {
for (Tuple2<String,Integer> tuple2 : iterable) {
String key = tuple2.f0;
if (map.containsKey(key)) {
map.put(key, map.get(key) + 1);
} else {
map.put(key, 1);
}
}
for (Map.Entry<String, Integer> entry : map.entrySet()) {
collector.collect(String.format("key:%s,count:%s", entry.getKey(), entry.getValue()));
}
}
}))
.map(new MapFunction<String, Tuple2<String,Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
String[] split = value.split(",");
return new Tuple2<String,Integer>(split[0].split(":")[1],
Integer.valueOf(split[1].split(":")[1]));
}
}).keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
}).timeWindow(Time.seconds(5))
.process(new ProcessWindowFunction<Tuple2<String,Integer>, String, String, TimeWindow>() {
Map<String, Integer> map = new HashMap<>();
@Override
public void process(String s, Context context, Iterable<Tuple2<String,Integer>> iterable, Collector<String> collector) throws Exception {
for (Tuple2<String,Integer> tuple2 : iterable) {
String key = tuple2.f0;
if (map.containsKey(key)) {
map.put(key, map.get(key) + 1);
} else {
map.put(key, 1);
}
}
for (Map.Entry<String, Integer> entry : map.entrySet()) {
collector.collect(String.format("key:%s,count:%s", entry.getKey(), entry.getValue()));
}
}
}).setParallelism(8)
.print().setParallelism(4);
env.execute("shuffle stream");
}
执行效果,如下图所示:
此时,数据倾斜问题得到了解决,同时发送给下游的数据量也变小了。这时,可能还会有读者剔除疑问:二次聚合的过程中是否还会产生数据倾斜?答案是:会的。
只是这个数据倾斜的程度是可控的,因为第一次聚合后的数据量的最大值为:业务key的个数 * 离散度(可能的后缀的个数,在上面的例子中是:random.nextInt(100),也就是100种)。倾斜问题,不会随着数据量增大而增大,这种倾斜问题不会产生太大影响,基本可以忽略。