💖 欢迎来到我的博客! 非常高兴能在这里与您相遇。在这里,您不仅能获得有趣的技术分享,还能感受到轻松愉快的氛围。无论您是编程新手,还是资深开发者,都能在这里找到属于您的知识宝藏,学习和成长。
🔍 博客内容包括:
- Java核心技术与微服务:涵盖Java基础、JVM、并发编程、Redis、Kafka、Spring等,帮助您全面掌握企业级开发技术。
- 大数据技术:涵盖Hadoop(HDFS)、Hive、Spark、Flink、Kafka、Redis、ECharts、Zookeeper等相关技术。
- 开发工具:分享常用开发工具(IDEA、Git、Mac、Alfred、Typora等)的使用技巧,提升开发效率。
- 数据库与优化:总结MySQL及其他常用数据库技术,解决实际工作中的数据库问题。
- Python与大数据:专注于Python编程语言的深度学习,数据分析工具(如Pandas、NumPy)和大数据处理技术,帮助您掌握数据分析、数据挖掘、机器学习等技术。
- 数据结构与算法:总结数据结构与算法的核心知识,提升编程思维,帮助您应对大厂面试挑战。
🌟 我的目标:持续学习与总结,分享技术心得与解决方案,和您一起探索技术的无限可能!在这里,我希望能与您共同进步,互相激励,成为更好的自己。
📣 欢迎订阅本专栏,与我一起在这个知识的海洋中不断学习、分享和成长!💻🚀
📍版权声明:本博客所有内容均为原创,遵循CC 4.0 BY-SA协议,转载请注明出处。
特别声明:该文章是自2025.1.9开始写,日更,持续更新直至完结,可借鉴Spring5全面完结。还望耐心等待...
图片截取自尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优
链接如下: 尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放_哔哩哔哩_bilibili
Hadoop版本为 3.1.3
1. 大数据介绍
1.1 大数据的概念
大数据是指数据量大、类型多样、生成速度快、价值密度低的数据集合。其核心特征通常总结为4V:
- Volume(数据量大):数据规模从TB级别扩展到PB甚至ZB级别。
- Variety(数据类型多样):包括结构化数据、半结构化数据(如JSON、XML)、非结构化数据(如图片、视频、音频)。
- Velocity(处理速度快):数据生成和处理速度需要实时或近实时完成。
- Value(价值密度低):从海量数据中提取有用信息的难度高,但商业价值巨大。
重点:大数据通过高效的技术和工具,从复杂的数据中提取有用的知识和洞察,用于决策支持、优化和预测。
在这里不得不重点提及一下数据存储单位(我觉得还是很重要的,最起码要了解并且学会做一个转换):

1Byte = 8bit 1K = 1024Byte 1MB = 1024KB 1G = 1025M 1T = 1024G 1P = 1024T
那我们的大数据一般用到的单位就是 TB 、 PB 、EB。
1.2 大数据应用场景
- 抖音:推荐你最常刷,最爱看的视频类型(Ps:我真不爱看!我不刷抖音!)

2. 电商内的广告:根据你常买的东西进行内容推荐
3. 零售:分析用户的消费习惯,为用户购买商品提供方便,从而提升商品销量。
4. 物流仓储:京东物流,上午下单下午送达。下午下单次日上午送达。
5. 保险:海量数据挖掘及风险预测,助力保险行业精准营销。
6. ......
ok到这里其实也没什么好了解的,我们直接进入正题,Hadoop!

2.Hadoop概述
2.1 Hadoop是什么
- Hadoop是一个由Apache基金会开发的分布式系统基础架构。
- Hadoop主要解决
- 海量数据的存储
- 海量数据的分析计算问题
- 广义上来说,Hadoop通常是指一个更广泛的概念 —— Hadoop生态圈!
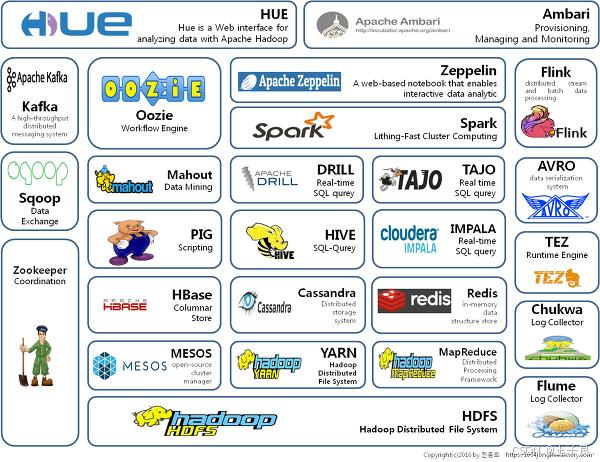
根据服务对象和层次分为:数据来源层、数据传输层、数据存储层、资源管理层、数据计算层、任务调度层、业务模型层。
2.2 Hadoop的发展历史
我觉得放一张创始人大头照算了。

2.3 Hadoop的三大发行版本(了解)
- 分别是 Apache、Cloudera、Hortonworks
- Apache 版本最原始(最基础),对于入门学习非常好
- 官网地址:http://hadoop.apache.org
- 下载地址:https://hadoop.apache.org/releases.html
- Cloudera 内部集成了很多大数据框架,对应产品CDH。
- Hortonworks 文档较好,对应产品HDP。
- Apache 版本最原始(最基础),对于入门学习非常好
2.4 Hadoop的优势(4高)
分别是
- 高可靠性:Hadoop底层维护多个数据副本,即使某个计算元素或者存储出现问题,也不会导致数据的丢失。
- 高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
- 高效性:在MapReduce的思想下,Hadoop是并行工作,以加快任务处理速度。
- 高容错性:能够自动将失败的任务重新分配。
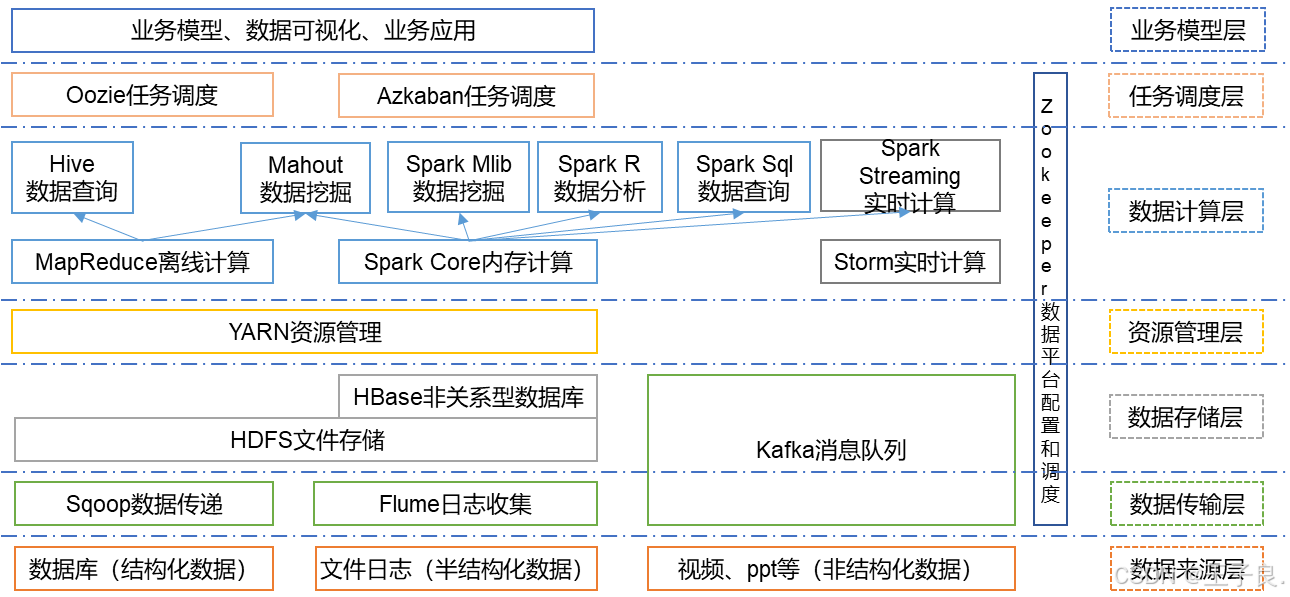
2.5 Hadoop 组成(面试重点)
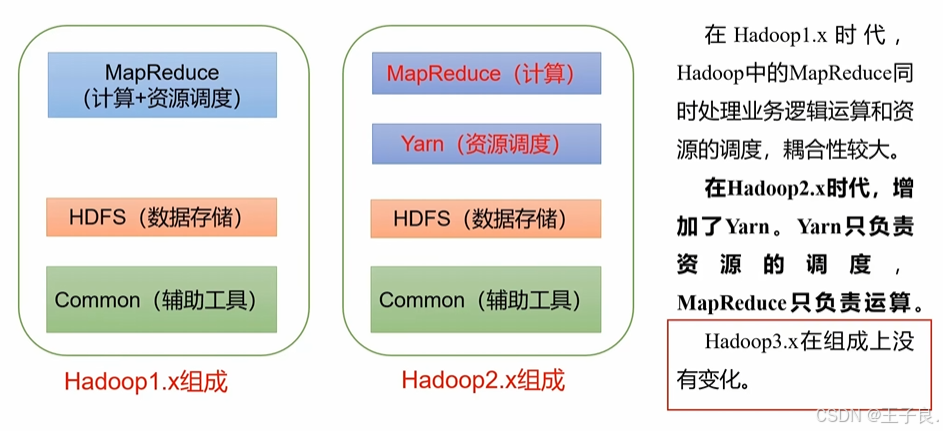
2.5.1 Hadoop 1.x 、2.x、3.x的区别
2.5.2 HDFS架构概述
Hadoop Distributed File System
- NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
- DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
- SecondaryNameNode(2nn):每隔一段时间对NameNode元数据备份。
明天再写。