文章目录
Datawhale AI 夏令营 Task2 学习笔记
1 深度学习是什么?
深度学习(Deep Learning)是一种机器学习方法,属于人工智能(AI)的一个子领域。它模仿人类大脑的神经元结构,通过多层次的神经网络模型来学习和处理数据,能够自动从大量数据中提取特征并进行复杂的任务,如图像识别、自然语言处理和语音识别等。
1.1 神经网络的概念
深度学习依赖于多层神经网络,这些网络由多个层次的神经元组成。每一层神经元接受前一层神经元的输出,通过权重和激活函数进行计算,然后将结果传递到下一层神经元。如下图所示,一个7层神经元组成的全连接神经网络的每一层中,每个神经元都接收前一层所有神经元的输出,这种结构称为全连接神经网络。
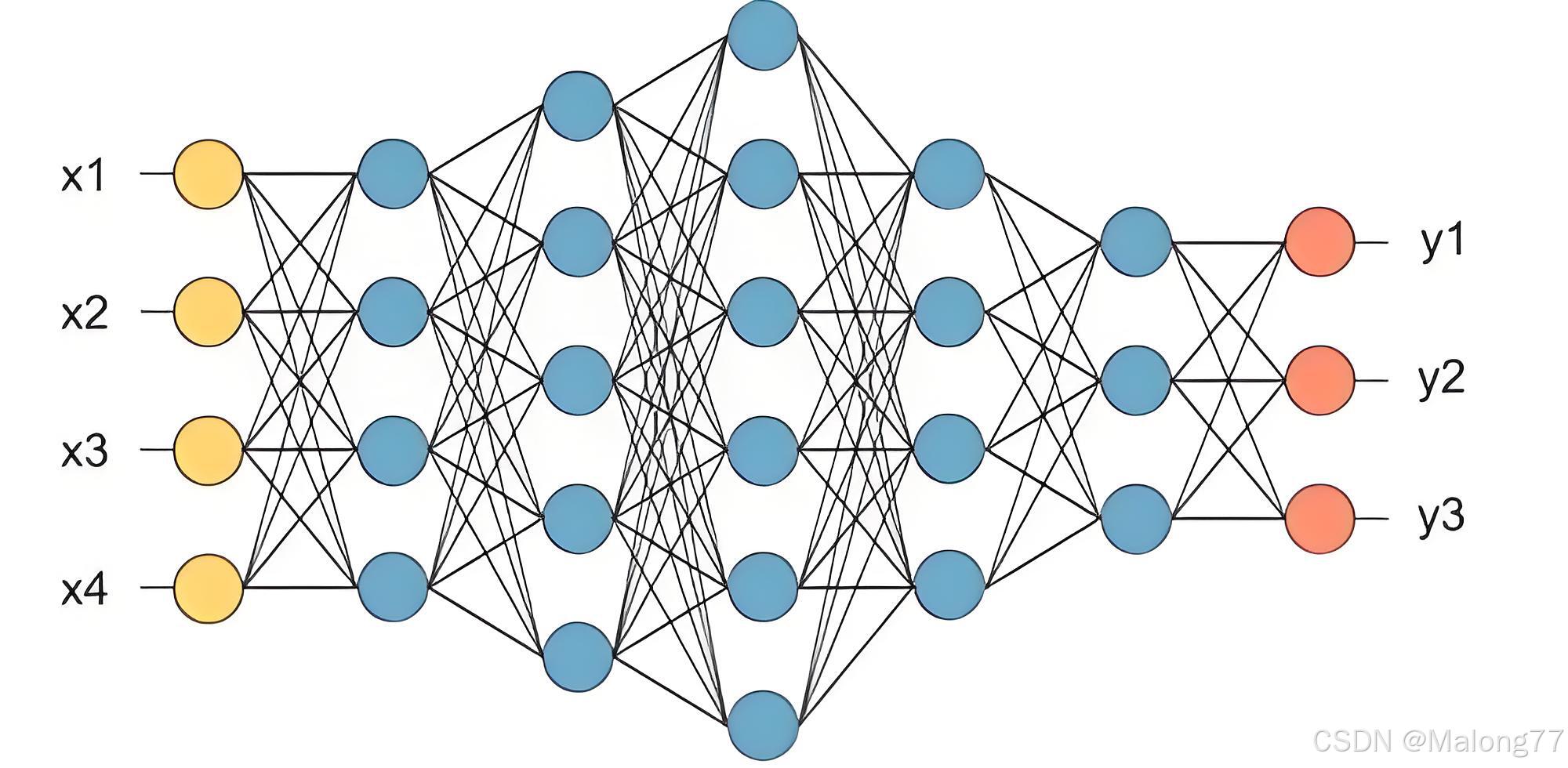
1.2 神经元模型
下图为神经元模型的结构。该神经元有三个输入x1,x2,x3。
- 首先每个神经元会接收上一层的输出并且给每一个输入分别赋予权重
wi。 - 接着对权重进行加权求和即 x 1 w 1 + x 2 w 2 + x 3 w 3 = ∑ i x i w i x_1w_1+x_2w_2+x_3w_3=\sum_{i}x_iw_i x1w1+x2w2+x3w3=∑ixiwi 然后再加上偏置项 b b b得到最终的计算结果 z = ∑ i x i w i + b z=\sum_{i}x_iw_i + b z=∑ixiwi+b
- 最后使用激活函数
f
(
x
)
f(x)
f(x) 对输出激活得到该神经元的输出
a
a
a。
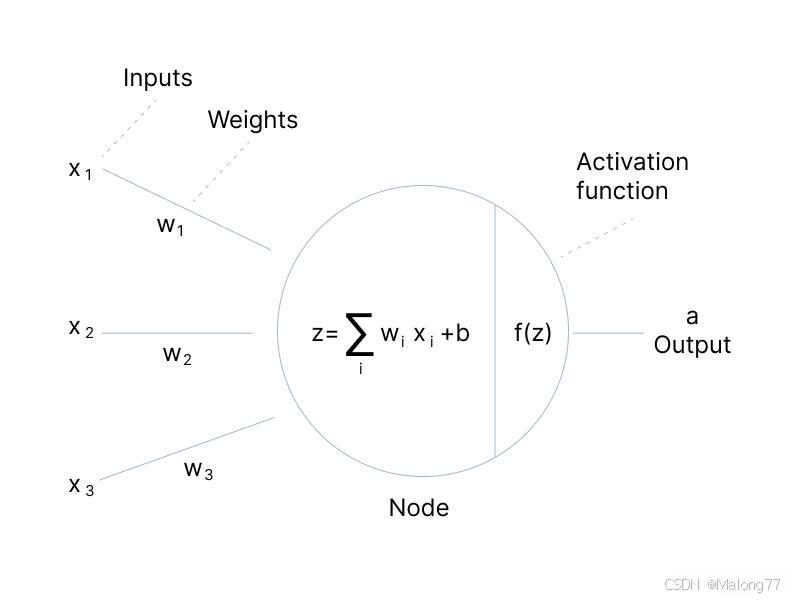
什么是激活函数?
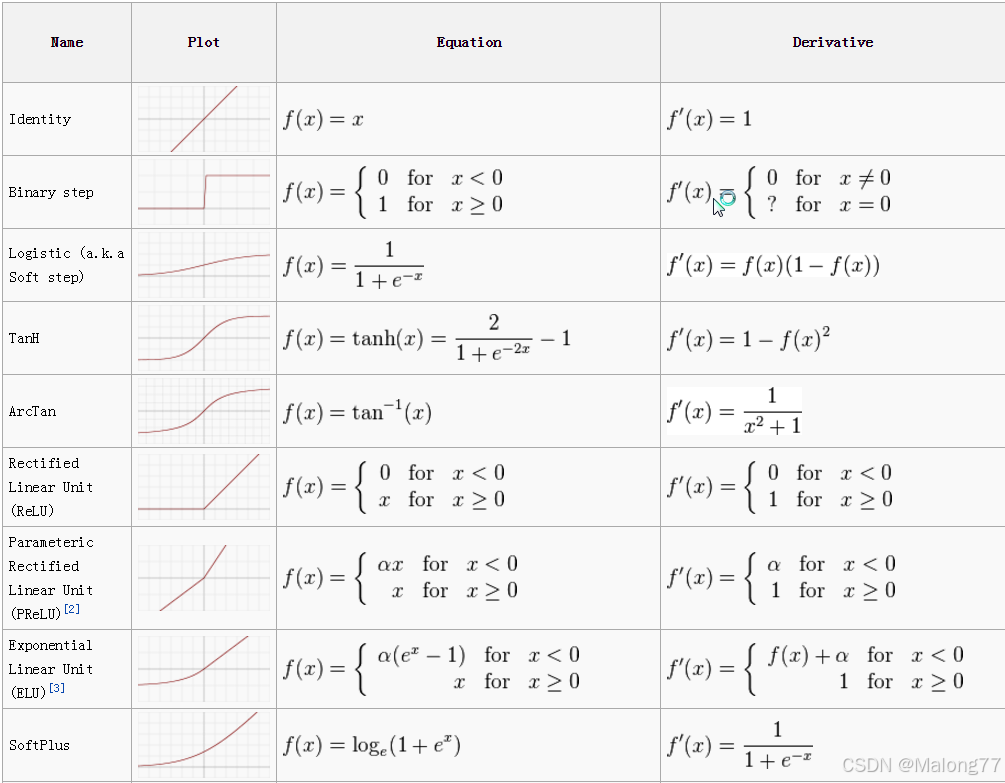
激活函数(Activation Function)是神经网络中的一个关键组件。它在神经元接收到前一层的输出后,对其进行非线性变换,再将结果传递到下一层。激活函数的引入使神经网络能够表达和学习复杂的模式和非线性关系。
激活函数有什么用?
-
引入非线性:
- 如果没有激活函数,神经网络中的每一层只进行线性变换,整个网络就相当于一个线性模型,无论有多少层,最终都只能表示线性关系。激活函数通过引入非线性,使神经网络能够逼近任何复杂的函数和模式。
-
帮助梯度下降:
- 适当的激活函数可以帮助梯度下降算法更有效地更新权重。激活函数的选择会影响梯度的传播和更新速度,有些激活函数(如ReLU)能够避免梯度消失问题,从而加速训练过程。
常见的激活函数
2 深度学习如何训练的?
神经网络处理问题可以看成是一个包含了很多参数( w 1 , w 2 , w 3 . . . w_1,w_2,w_3... w1,w2,w3...)的函数过程: Y = F ( X ) Y=F(X) Y=F(X)。其中 X X X是模型的输入(可以是图片、音频、文本等), Y Y Y是模型的输出(可以是类别或),函数 F F F就是神经网络本身。
以本次的Deepfake比赛为例,输入是图片,输出是类别(例如,图片是否伪造)。然而,当神经网络刚创建时,如果没有指定初始化方法或加载预训练模型,参数通常是随机的。因此,网络并不知道如何判断图片是否伪造。这就需要用数据来训练模型,即用现有的数据来调整和优化网络的参数,使其能够正确分类输入的图片。
2.1 梯度下降算法
训练神经网络必不可少的就是Loss。Loss是模型参数优化的核心指标,它衡量了模型预测值与真实值之间的差距。在训练过程中,通过计算Loss,可以指导模型的参数更新,使得模型在下一次预测时能够更接近真实值。
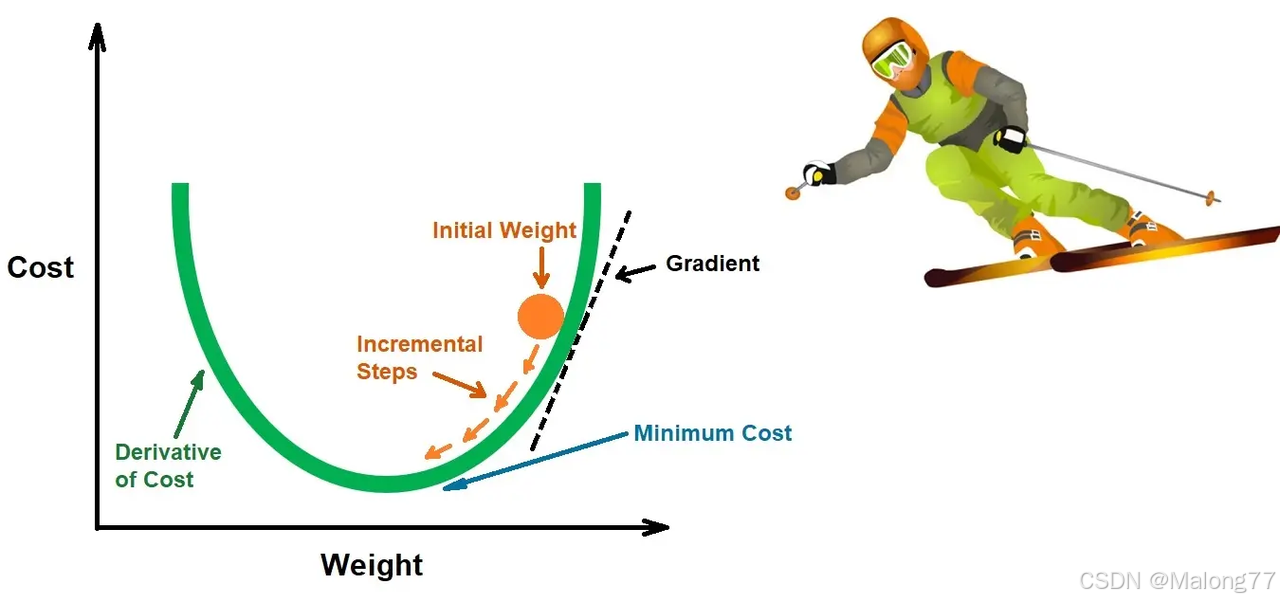
梯度下降是一种优化算法,用于最小化Loss函数。
梯度下降算法基于这样一个原理:损失函数的梯度指向函数增长最快的方向。
因此,如果我们希望减少损失函数的值,我们就需要沿着梯度的反方向调整模型的参数。这样,每次迭代都会使模型参数朝着减少损失的方向移动。
2.2 Pytorch训练代码
def train(train_loader, model, criterion, optimizer, epoch):
# switch to train mode
model.train()
end = time.time()
for i, (input, target) in enumerate(train_loader):
input = input.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
# compute output
output = model(input)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
上述代码是baseline中的训练代码,模型的训练过程主要是在这个函数中完成的。
- 首先会使用
model.train()函数开启模型的训练模式。接着for循环从train_loader中取出一个batch的数据。并且把input和target转移到GPU上进行加速运算。 - 随后,把输入数据
input放入模型进行前向传播,计算模型预测的输出output。计算预测值output和真实值target之间的损失函数loss即误差。 - 在反向传播前需要先调用
optimizer.zero_grad()将optimizer优化器中的上一次的梯度进行清零,然后调用loss.backward()反向传播计算这一个batch的梯度。 - 在计算完梯度之后就可以调用
optimizer.step()通过梯度来更新当前参数。
训练过程总结
- 初始化参数:随机初始化网络的权重和偏置。
model = timm.create_model('xxxnet', pretrained=True, num_classes=2) - 前向传播:将输入数据通过网络得到预测输出。
output = model(input) - 计算损失:使用损失函数计算预测结果和真实标签之间的差距。
loss = criterion(output, target) - 反向传播:清空先前的梯度,然后计算损失函数对每个参数的梯度。
optimizer.zero_grad(); loss.backward() - 更新参数:根据梯度和优化算法更新权重和偏置。
optimizer.step() - 重复以上步骤:重复上述步骤,直到损失函数收敛或达到预定的训练轮数。
3 迁移学习
迁移学习通过将预训练模型在一个任务中的知识迁移到另一个相关任务,从而提高新任务的学习效率和性能。迁移学习特别适用于深度学习领域,因为训练大型神经网络通常需要大量的计算资源和数据。
为什么要使用迁移学习:
在大型数据集(例如,ImageNet)上训练好的模型,这些数据集通常包含丰富的特征和模式。预训练模型可以捕捉到数据的基本特征,具有良好的泛化能力。也可以理解为模型可以提取到一些通用的特征。
使用微调技术(Fine-tuning),可以只调整某些层的参数,来大幅度减少计算资源的使用。
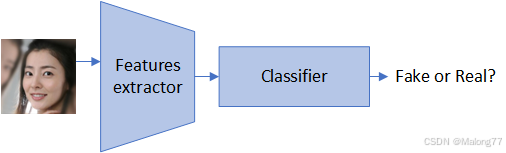
图片分类模型其实可以分为两个阶段:
- 特征提取;
- 分类。
如下图所示,用于图片分类的模型可以看作是·特征提取器·和·分类器·两部分组成的。一般来说特征提取器部分参数较多,因此我们在微调时可以冻结特征提取器的参数仅训练分类器。接下来给大家展示冻结模型特征提取层只训练末尾的分类器的代码。
import timm
import torch
import torch.nn as nn
class FineTuning_Resnet18(nn.Module):
def __init__(self, model_name='resnet18'):
super(FineTuning_Resnet18, self).__init__()
# 创建一个预训练的resnet18模型,不包含分类器和池化层
self.features_extractor = timm.create_model(model_name, pretrained=True, num_classes=0, global_pool='')
# 全局平均池化层
self.maxpool = nn.AdaptiveMaxPool2d((1, 1))
# 分类器,因为是2分类任务,可以用0,1表示,因此分类器的输出为1
self.classifier = nn.Linear(512, 1)
def forward(self, x):
features = self.features_extractor(x) # shape: torch.Size([batch, 512, 7, 7])
pooled_features = self.maxpool(features) # shape: torch.Size([batch, 512, 1, 1])
# 把特征图展平
pooled_features = pooled_features.view(pooled_features.size(0), -1) # shape: torch.Size([batch, 512])
pooled_features = self.classifier(pooled_features) # shape: torch.Size([batch, 1])
return pooled_features
data = torch.randn(32, 3, 224, 224)
model = FineTuning_Resnet18(model_name='resnet18')
model.train()
# 冻结特征提取器,仅训练分类器
for name, param in model.named_parameters():
if 'features_extractor' in name:
param.requires_grad = False
else:
param.requires_grad = True
# 打印参数的 requires_grad 属性
for name, param in model.named_parameters():
print(f"{name}: {param.requires_grad}")
# 接下来是正常的训练代码...
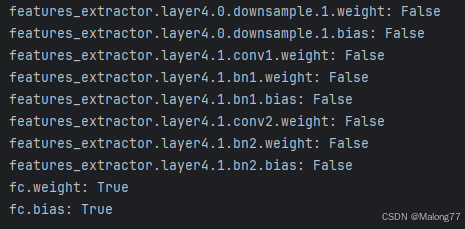
运行代码后可以看到,只有最后一层分类器的梯度属性开启,特征提取器的梯度全被关闭,这样在训练的时候就会只更新分类器参数不更新特征提取器的参数。
timm.create_model(model_name, pretrained=True, num_classes=0, global_pool='')可以近加载模型的特征提取部分不加载后面的分类器,因此我们可以使用改代码构建特征提取器,然后自己写一个分类器用于微调。
此外还可以使用timm.create_model('swin_base_patch4_window7_224', features_only=True, pretrained=True)来构建一个提取每一层特征的特征提取器。
# Create a feature map extraction model
m = timm.create_model('swin_base_patch4_window7_224', features_only=True, pretrained=True)
# Print the feature channels
print(f'Feature channels: {m.feature_info.channels()}')
o = m(torch.randn(2, 3, 224, 224))
for x in o:
print(x.shape)
# torch.Size([2, 56, 56, 128])
# torch.Size([2, 28, 28, 256])
# torch.Size([2, 14, 14, 512])
# torch.Size([2, 7, 7, 1024])
4 常见的图片分类网络
AlexNet
AlexNet包含八个层次结构,前五个是卷积层,其中一些后跟最大池化层,最后三个是全连接层。具体结构如下:
- 卷积层:AlexNet的前五个层次都是卷积层,每个卷积层后面跟着一个ReLU激活函数,以引入非线性。这些卷积层旨在提取图像的特征。
- 局部响应归一化(LRN):在某些卷积层后使用了局部响应归一化,这是一种提高模型泛化能力的正则化方法。
- 最大池化层:在部分卷积层之后使用最大池化层来降低特征的空间维度,减少计算量和过拟合的风险。
- 全连接层:网络的最后三个层次是全连接层,其中最后两个全连接层后跟有Dropout,以进一步防止过拟合。
- 输出层:最后一个全连接层后是线性层,然后是softmax激活函数,输出1000个类别上的概率分布。
ResNet
ResNet(残差网络)是一种深度卷积神经网络架构,由微软研究院的研究员何恺明等人提出。ResNet在2015年的ImageNet图像识别大赛中取得了冠军,并在深度学习领域产生了重大影响。它的主要创新点是引入了残差学习的概念,允许训练非常深的网络,从而缓解了深度神经网络训练中的梯度消失和梯度爆炸问题。
[图片]
ResNet的核心是残差块(residual block),网络通过堆叠这些残差块来构建。一个基本的残差块包含以下几部分:
- 跳跃连接(Skip Connections):这是ResNet最关键的创新,通过跳跃连接,输入可以直接绕过一个或多个层传到输出,输出是输入与这些层的输出的加和。这种结构使得网络可以学习输入到输出的残差,而不是直接学习输出,这有助于缓解梯度消失问题。
- 卷积层:残差块内部包含多个卷积层,通常使用小尺寸的卷积核(如3x3),并且通常会有批量归一化(Batch Normalization)和ReLU激活函数。
- 池化层:在某些残差块之间会插入最大池化层来降低特征图的空间维度。
EfficientNet
EfficientNet是一种高效的卷积神经网络(CNN)架构,它通过一种新颖的网络缩放方法来提升模型的性能和效率。EfficientNet 的核心是其 compound scaling 方法,该方法通过一个复合系数统一缩放网络的深度、宽度和分辨率。在过去,网络缩放通常是通过任意选择深度、宽度或分辨率的增加来实现的,而EfficientNet的方法则是通过一系列固定的缩放系数来同时增加这三个维度。例如,如果想要使用更多的计算资源,可以通过增加网络深度、宽度和图像大小的特定比例来实现,其中的比例系数是通过在小型模型上进行小规模的网格搜索确定的。
5 自己的思考
训练一个自编码器(Auto Encoder, AE)模型用于对输入图片进行重建。由于Fake图片本来就是模型生成的,那么应该更容易重建,即重建图与原图差别小,如果是对Real图片重建则重建图与原图应该差别会更大。因此可以从中提取到一些有用的信息进行融合作为最后分类器的一部分补充信息。此外,把Encoder提取到的特征与多尺度Decoder特征进行融合用于后续分类。
如下图所示,使用Encoder-Decoder架构重建输入X得到重建图片
X
^
\hat{X}
X^。然后重建图片与真实图片求差得到差值图后,进行特征提取得到特征权重
δ
\delta
δ 用于多尺度融合特征的加权。
多尺度特征融合模块对Encoder阶段提取到的特征和不同阶段的Decoder特征进行融合,得到一个富含多尺度信息的特征。
损失函数有两部分组成,重建损失
L
r
\mathcal{L}_{r}
Lr 和分类损失
L
c
l
s
\mathcal{L}_{cls}
Lcls 。重建损失用于约束模型的重建能力,分类损失用于约束模型的分类能力。
对应代码如下:

import timm
import torch
import torch.nn as nn
class DecoderBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super(DecoderBlock, self).__init__()
self.upsample = nn.ConvTranspose2d(in_channels, in_channels, 2, 2)
self.block = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, 1, 1),
nn.BatchNorm2d(out_channels),
nn.GELU())
def forward(self, x):
x = self.upsample(x)
x = self.block(x)
return x
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.decoder1 = DecoderBlock(768, 384)
self.decoder2 = DecoderBlock(384, 192)
self.decoder3 = DecoderBlock(192, 96)
self.decoder4 = DecoderBlock(96, 64)
self.decoder5 = DecoderBlock(64, 3)
def forward(self, x):
x1 = self.decoder1(x)
x2 = self.decoder2(x1)
x3 = self.decoder3(x2)
x = self.decoder4(x3)
x = self.decoder5(x)
return x1, x2, x3, x
class Multi_Scale_Feature_Fusion(nn.Module):
def __init__(self):
super(Multi_Scale_Feature_Fusion, self).__init__()
self.conv1 = nn.Sequential(nn.MaxPool2d(2, 2))
self.conv2 = nn.Sequential(
nn.Conv2d(192, 192, 3, 2, 1),
nn.BatchNorm2d(192),
nn.GELU(),
nn.MaxPool2d(2, 2))
self.conv3 = nn.Sequential(
nn.Conv2d(96, 192, 3, 2, 1),
nn.BatchNorm2d(192),
nn.GELU(),
nn.Conv2d(192, 192, 3, 2, 1),
nn.BatchNorm2d(192),
nn.GELU(),
nn.MaxPool2d(2, 2))
def forward(self, encoder_out, decoder_1, decoder_2, decoder_3):
# encoder_out: torch.Size([batch, 768, 7, 7])
# decoder_1: torch.Size([batch, 384, 14, 14])
# decoder_2: torch.Size([batch, 192, 28, 28])
# decoder_3: torch.Size([batch, 96, 56, 56])
x1 = self.conv1(decoder_1) # [batch, 384, 14, 14] -> [batch, 384, 7, 7]
x2 = self.conv2(decoder_2) # [batch, 192, 28, 28] -> [batch, 192, 7, 7]
x3 = self.conv3(decoder_3) # [batch, 96, 56, 56] -> [batch, 192, 7, 7]
x = torch.cat([x1, x2, x3], dim=1) # [batch, 384+192+192, 7, 7] = [batch, 768, 7, 7]
# 把encoder与x点乘
x = x * encoder_out # [batch, 768, 7, 7]
return x
class AEClassifier(nn.Module):
def __init__(self):
super(AEClassifier, self).__init__()
# 使用Swin Transformer作为特征提取器
self.encoder = timm.create_model('swin_tiny_patch4_window7_224', pretrained=True, num_classes=0, global_pool='')
self.decoder = Decoder()
self.mff = Multi_Scale_Feature_Fusion()
# 使用Swin Transformer作为相减后的特征提取器
self.reduce_encoder = timm.create_model('swin_tiny_patch4_window7_224', pretrained=True, num_classes=0,
global_pool='')
self.maxpool = nn.AdaptiveMaxPool2d((1, 1))
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classfier = nn.Linear(768 + 768, 1)
def forward(self, x):
# 提取输入图片X的特征
encoder_out = self.encoder(x) # shape: [batch, 7, 7, 768]
# 调整特征的维度
encoder_out = encoder_out.permute(0, 3, 1, 2) # shape: [batch, 768, 7, 7]
# 重构图片得到不同尺度的特征和重构图片x_hat
decoder_1, decoder_2, decoder_3, x_hat = self.decoder(encoder_out)
# 相减后的特征
reduce_encoder_out = self.reduce_encoder(x - x_hat) # shape: [batch, 7, 7, 768]
# 调整特征的维度
reduce_encoder_out = reduce_encoder_out.permute(0, 3, 1, 2) # shape: [batch, 768, 7, 7]
# 多尺度特征融合,把encoder_out与decoder_1, decoder_2, decoder_3融合
x = self.mff(encoder_out, decoder_1, decoder_2, decoder_3) # shape: [batch, 768, 7, 7]
# 把encoder_out与x点乘后跳跃连接x
x = x * reduce_encoder_out + x # shape: [batch, 768, 7, 7]
# 最大池化和平均池化
x_max = self.maxpool(x) # shape: [batch, 768, 1, 1]
x_avg = self.avgpool(x) # shape: [batch, 768, 1, 1]
x = torch.cat([x_max, x_avg], dim=1) # shape: [batch, 768+768, 1, 1] = [batch, 1536, 1, 1]
# 把特征展平
x = x.view(x.size(0), -1) # shape: [batch, 1536]
cls = self.classfier(x) # shape: [batch, 1]
return cls, x_hat
class AELoss(nn.Module):
def __init__(self, alpha=1.0, beta=1.0):
super(AELoss, self).__init__()
self.alpha = alpha
self.beta = beta
self.bce_loss = nn.BCEWithLogitsLoss()
self.mse_loss = nn.MSELoss()
def forward(self, cls, x_hat, labels, x):
# 分类损失
cls_loss = self.bce_loss(cls, labels)
# 重构损失
recon_loss = self.mse_loss(x_hat, x)
# 组合损失
total_loss = self.alpha * cls_loss + self.beta * recon_loss
return total_loss
参考文献
- Cao J, Ma C, Yao T, et al. End-to-end reconstruction-classification learning for face forgery detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 4113-4122.
- https://datawhaler.feishu.cn/wiki/CsS2weZvgigEKok6IzycdiVunuy
- https://www.v7labs.com/blog/neural-networks-activation-functions
- https://www.kaggle.com/discussions/getting-started/429326
- https://ml-cheatsheet.readthedocs.io/en/latest/activation_functions.html
- https://blog.csdn.net/google19890102/article/details/69942970