1 Degradation Problem💦
- 深度卷积神经网络在图像分类方面取得了一系列突破。深度网络自然地将低/中/高级特征和分类器以端到端的多层方式集成在一起,特征的“层次”可以通过堆叠层数(深度)来丰富。最近的研究揭示了网络深度是至关重要的,在具有挑战性的ImageNet数据集上的主要结果都利用了“非常深的”模型。许多其他重要的视觉识别任务也极大地受益于非常深度的模型。
- 在深度重要性的驱动下,一个问题出现了:学习更好的网络就像堆叠更多层一样简单吗?回答这个问题的一个障碍是臭名昭著的梯度消失/爆炸问题,它从一开始就阻碍了收敛。目前针对这种问题已经有了解决的方法:对输入数据和中间层的数据进行归一化操作,这种方法可以保证网络在反向传播中采用随机梯度下降(SGD),从而让网络达到收敛。但是,这个方法仅对几十层的网络有用,当网络再往深处走的时候,这种方法就无用武之地了。
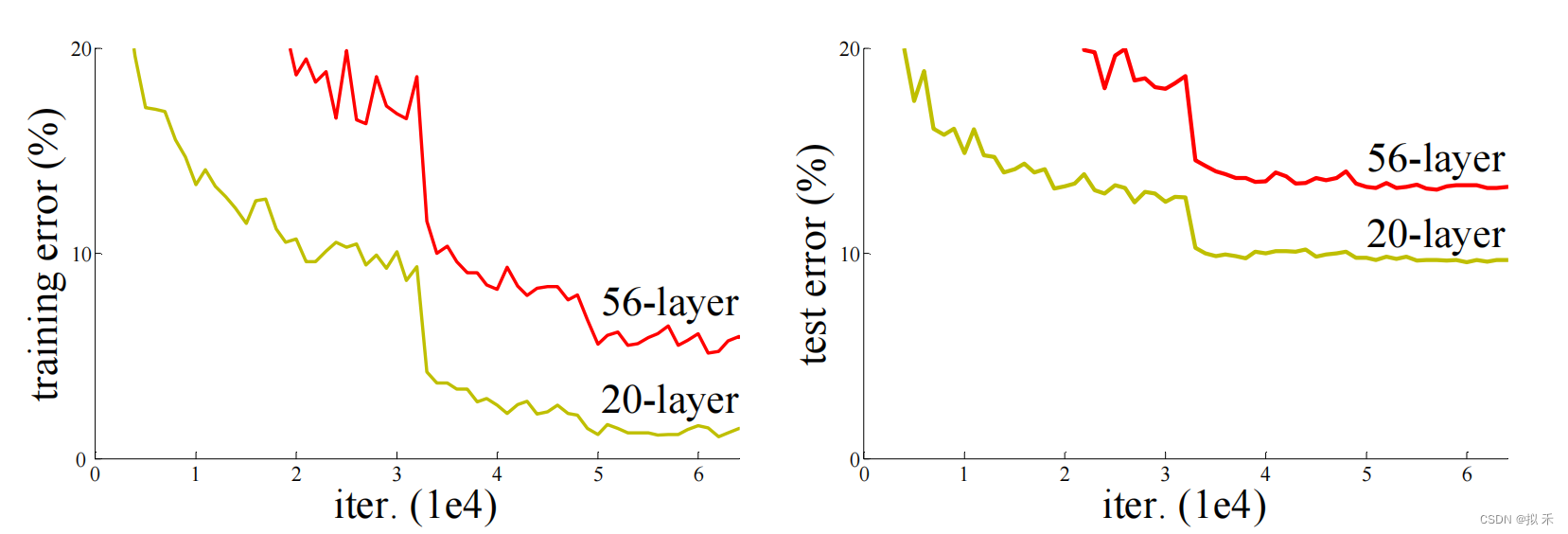
- 上图是使用20层和56层“普通”网络(plain network)的CIFAR-10上的训练误差(左)和测试误差(右)。网络越深,训练误差越大,测试误差越大。在ImageNet上的也有类似现象。
- 网络层数不是太多的时候,模型的正确率确实会随着网络层数的增加而提升,但随着网络层数的增加,正确率也会达到饱和,这个时候如果再继续增加网络的层数,那么正确率就会下降。论文中把这种现象称为退化问题(Degradation Problem),出乎意料的是,这种退化并不是由过拟合引起的,并且在适当深度的模型中增加更多的层会导致更高的训练误差。如果是overfitting的话,则会出现训练误差小,测试误差大的现象,但是二者的结果都相较于浅层网络的误差较大。
2 Residual Block🔥
ResNet 之所以叫残差网络(Residual Network),是因为 ResNet 是由很多残差块(Residual Block)组成的。而残差块的使用,可以解决前面说到的退化问题。残差块如下图所示。
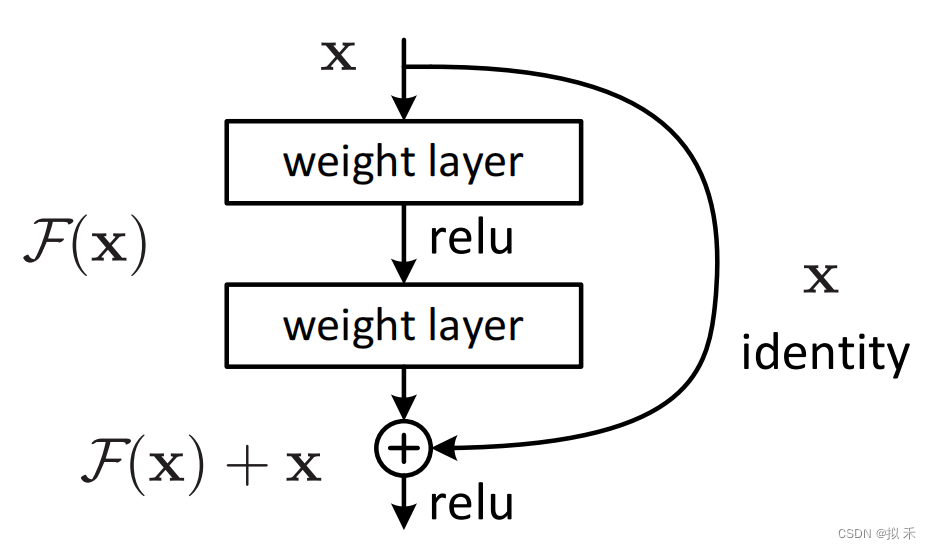
- 残差(residual)在数理统计中是指实际观察值(观测值)与估计值(拟合值)之间的差。
- 假设上图中的 weight layer 是 3×3 的卷积层;F(x) 表示经过两个卷积层计算后得到的结果;identity x 表示恒等映射(identity
mapping),也称为shortcut connections。- 其实就是把 x 的值是不做任何处理直接传过去。最后计算 F(x)+x,这里的 F(x) 跟 x 是种类相同的信号,所以将其对应位置进行相加。
- 我们让 H(x) = F(x)+x ,所以 H(x) 就是观测值(实际的特征映射,就是真实的输出),x 就是估计值(也就是上一层ResNet输出的特征映射)。
- 我们如果使用plain networks(一般的卷积神经网络)那么 H(x) = F(x) ,这样某一层达到最优之后在加深就会出现退化问题。
- 残差就体现在:F(x) = H(x)-x ,我们假设优化残差映射比优化原始的、未引用残差的映射更容易。在极端情况下,如果一个恒等映射 x 是最优的,那么将残差 F(x) 推到 0 比通过一堆非线性层来拟合一个恒等映射要容易得多。
- 进一步理解:因为 x 是当前输出的最优解,为了让它成为下一层的最优解也就是希望咱们的真实输出 H(x)=x 的话,只要让 F(x)=0 就行了,也就是为了保证下一层的网络状态仍然是最优状态,只需要令 F(x)=0 ,这也就是残差网络需要训练和学习的地方,也说明了深层网络不会变的比浅层网络差,可以选择原地踏步,但不会后退(不绝对)。如果更深层网络学习到了好的特征,整个模型的性能就会提升。
- 如果模型发现 F(x) 很难训练,或者训练没有好处的话,F(x) 就拿不到梯度,模型发现直接拿 x 过去效果就很好了,加上一个 F(x) 对我的loss下降没有什么明显作用的话,那么在梯度反传的时候就拿不到什么梯度,所以 F(x) 的权重就不会被更新了,权重就有可能变得很小,梯度甚至可能变为零,所以ResNet在加深的时候通常不会使模型的效果变坏。
- Identity shortcut connections既不会增加额外的参数,也不会增加计算复杂度。
- 我们在ImageNet上进行了全面的实验,以显示退化问题并评估我们的方法。结果表明:我们的深度残差网络很容易优化,但对应的“普通”网络(简单地堆叠层)在深度增加时表现出更高的训练误差;我们的深度残差网络可以很容易地从深度的大幅增加中获得精度收益,产生的结果比以前的网络要好得多。
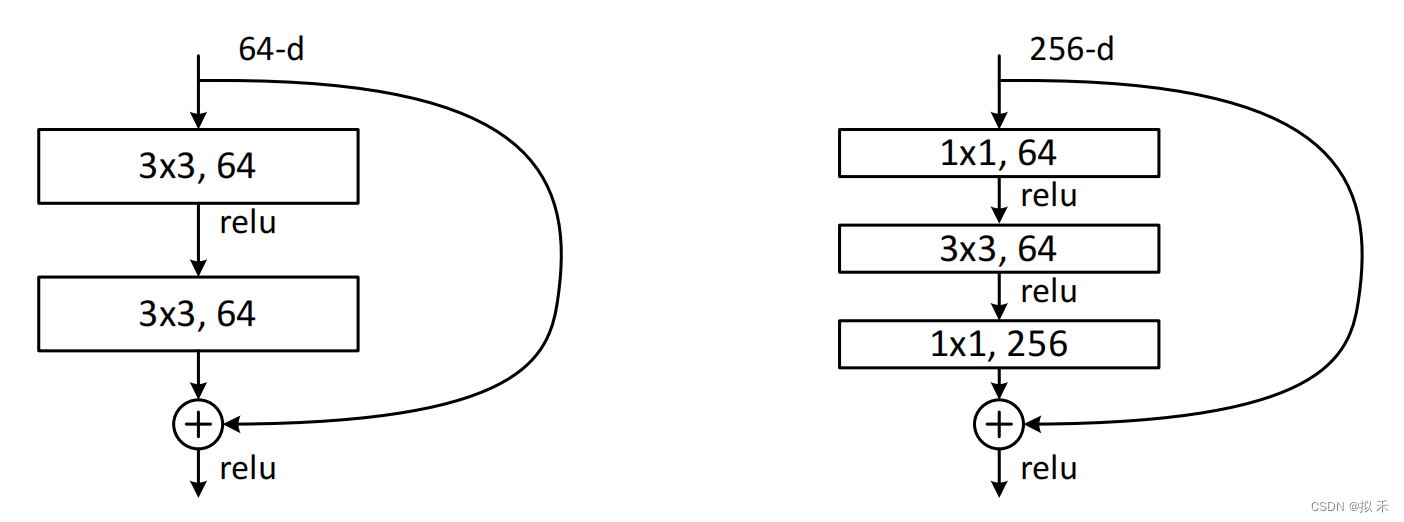
残差块可以有多种设计方式,如改变残差块中卷积层的数量,或者残差块中卷积窗口的大小,或者卷积计算后先 ReLU 后 BN,就像搭积木一样,我们可以随意设置。ResNet 研究团队经过很多的测试最终定下了两种他们觉得最好的残差块的结构,如上图所示。
3 Architecture💑
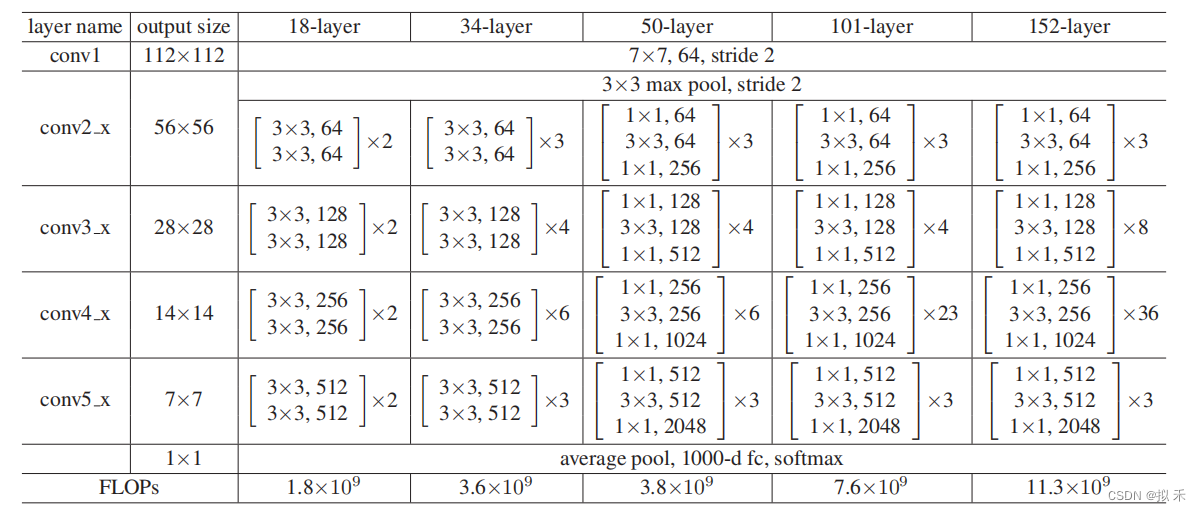
上图是论文中提出的五种ResNet网络结构。若残差映射 F(x) 的结果的维度与跳跃连接 x 的维度不同时,就必须对 x 进行维度变换,维度相同时二者才能进行相加运算。具体方法有:
- Zero-Padding
- 1 * 1卷积(Projection Shortcut)
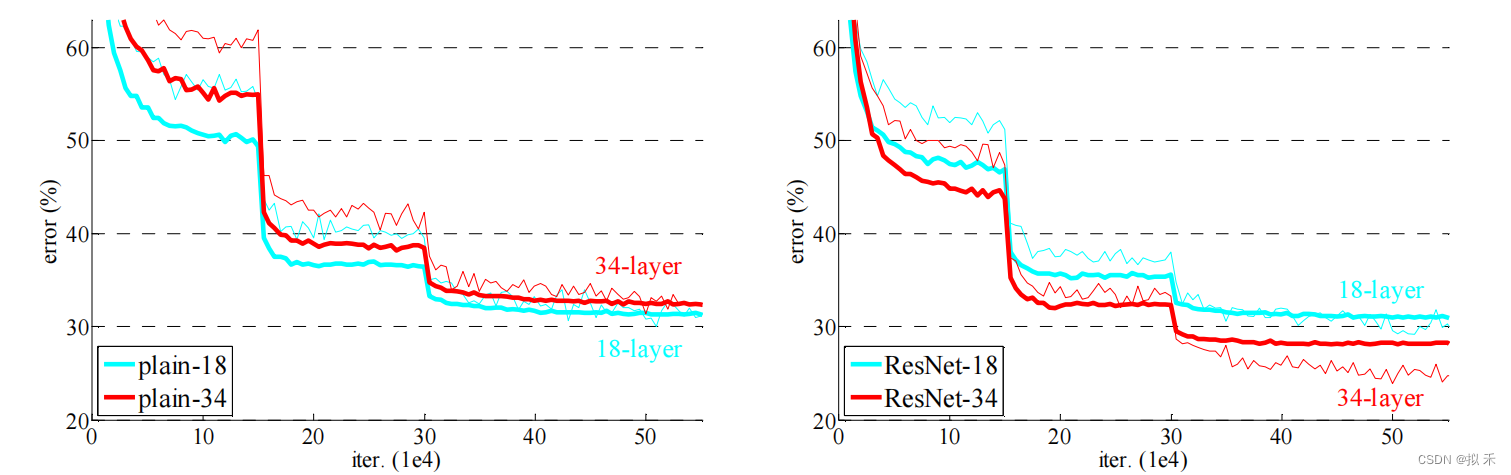
上图表明ResNet的效果要优于相同深度的plain network。
4 Supplement💋

- 这里的 f(x) 表示深层网络,g(x) 表示浅层网络。
- 对于一般的卷积神经网络,随着网络加深,梯度反向传播时由于多次乘法(如上图的Plain)变得很小,即使有Batch Normalization等手段,但是最后还是会出现梯度消失,导致模型过早的收敛,因为没有梯度,学不动了,最后的结果就会较差。
- 而对于ResNet(如上图的ResNet),即使左边的梯度值很小,但是右边的梯度值比较大,小数加大数,总的梯度还是会比较大的,模型就能训练的动,所以训练速度也较快,不管你后面的网络有多深,我的浅层网络 g(x) 的梯度总是有用的,最后的结果就会变好。残差网络起作用的主要原因就是这些残差块学习恒等函数非常容易,很多时候甚至可以提高效率,因此创建类似残差网络可以提升网络性能。
5 Conclusion☀️
- 残差结构的主要作用是传递信号,把深度学习浅层的网络信号直接传给深层的网络。深度学习中不同的层所包含的信息是不同的,一般我们认为深层的网络所包含的特征可能对最后模型的预测更有帮助,但是并不是说浅层的网络所包含的信息就没用,深层网络的特征就是从浅层网络中不断提取而得到的。现在我们给网络提供一个捷径,也就是Shortcut Connections,它可以直接将浅层信号传递给深层网络,跟深层网络的信号结合,从而帮助网络得到更好的效果。
- 从 ResNet 的设计和发展过程中我们可以知道,深度学习是一门非常注重实验的学科,我们需要有创新的好想法,同时也需要大量的实验来支撑和证明我们的想法。有些时候我们无法从理论上推断哪种模型设计或优化方法是最好的,这个时候我们可能就需要做大量的实验来不断尝试,找到最好的结果。如今 ResNet 已经得到广泛的应用和肯定,对深度学习和计算机视觉做出了卓越贡献。