
引言
本期分享主题是美图SRE团队的稳定性运营实践,本期分享内容为SRE的目标&挑战、指导破局的理论框架。
一、SRE的目标&挑战
VUCA时代

SRE的目标: 寻求三个核心职责之间的平衡
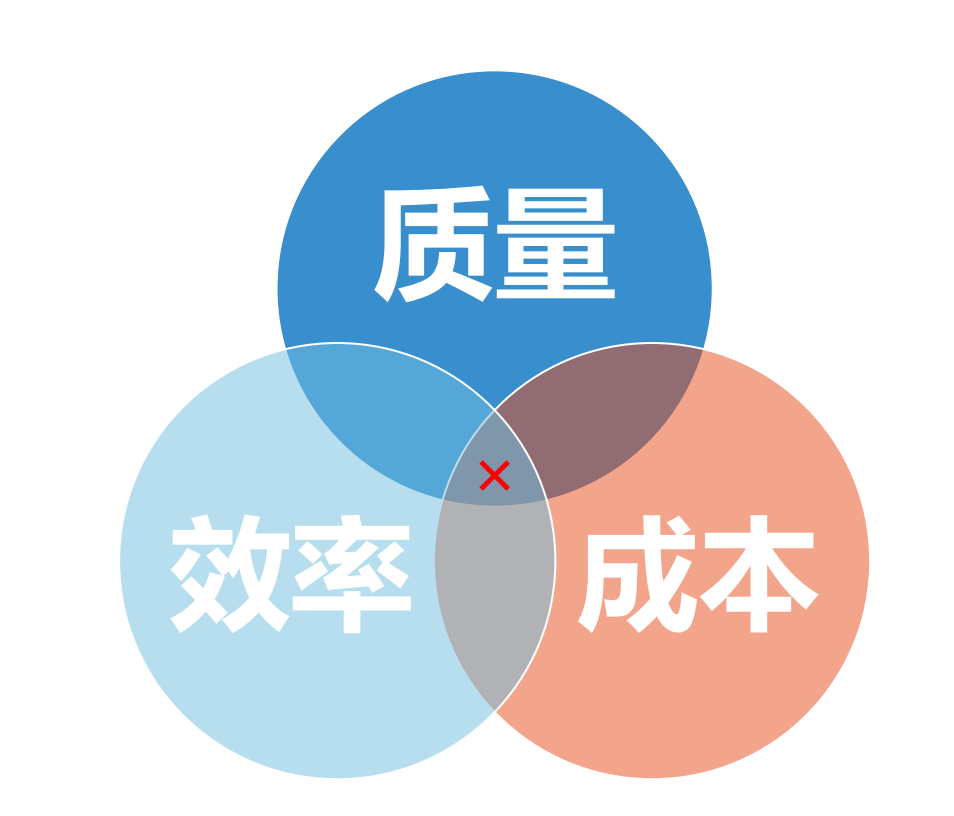
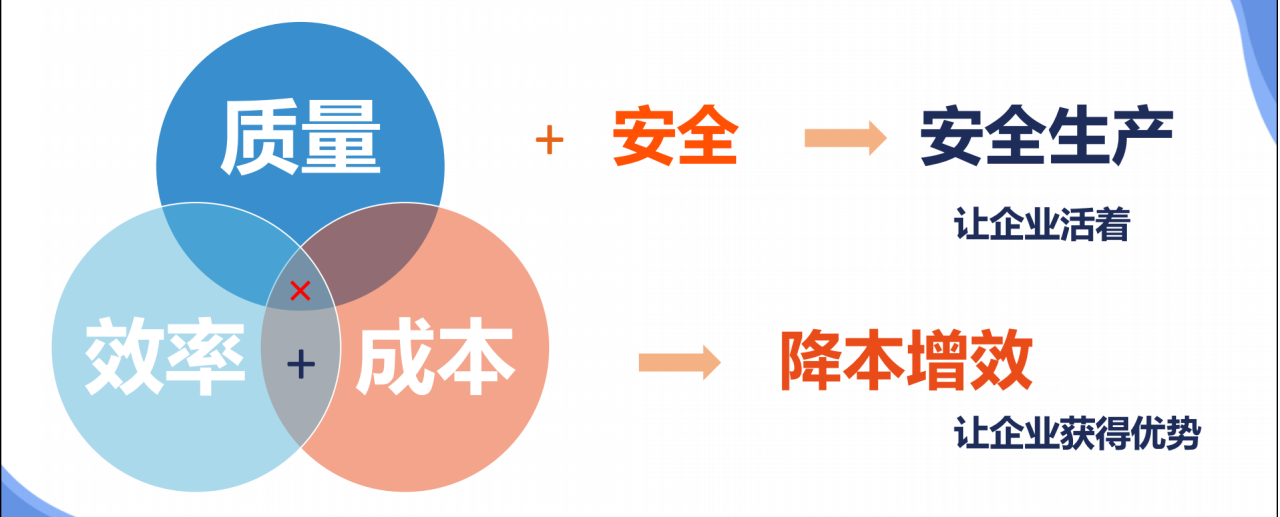
核心职责与企业发展的关系
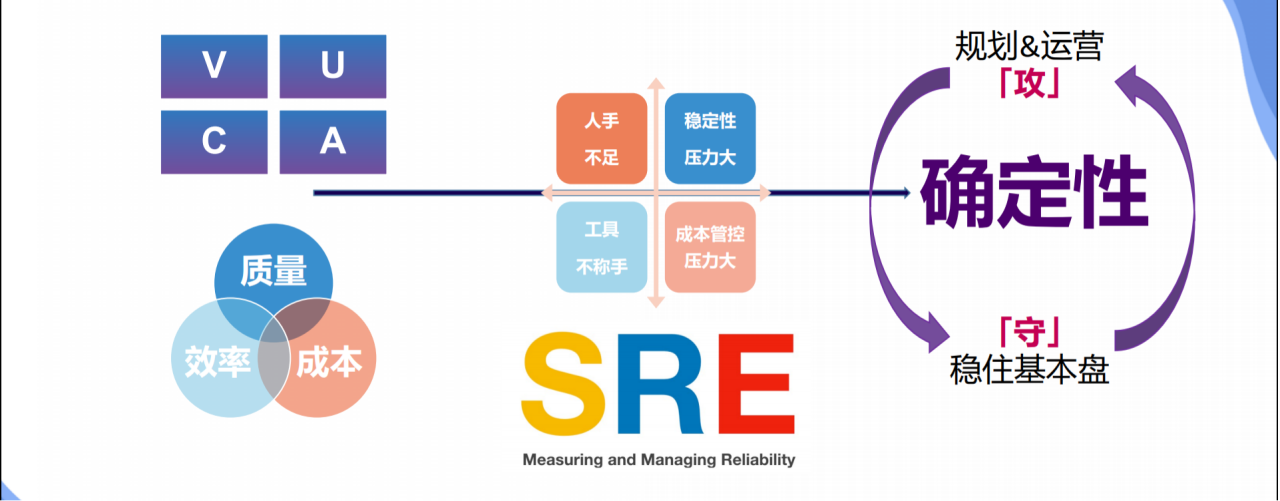
SRE的困境
人手不足
- 业务线众多且复杂
- 琐事过多
- 低效的咨询或求助
- 例行的工作事项
- 新人培养成本高
- 风吹草动 捉襟见肘
稳定性压力大
- 技术栈多样 更新快
- 服务发布频率高
- 历史技术债务
- 告警消息满天飞
- 战战兢兢 如履薄冰
- 忙于救火 疲于应付
工具不称手
- 工具缺失或落后
- 工具建设进度缓慢
- 轮子众多 不成体系
- 工具间数据割裂
- 数据/行为的不一致性
成本管控压力大
- 资源用量管控
- 资源利用率管控
- 资源容量规划和管控
- 成本归集、分析、核算
- 成本持续优化
SRE的目标和挑战
二、指导破局的 「理论框架」
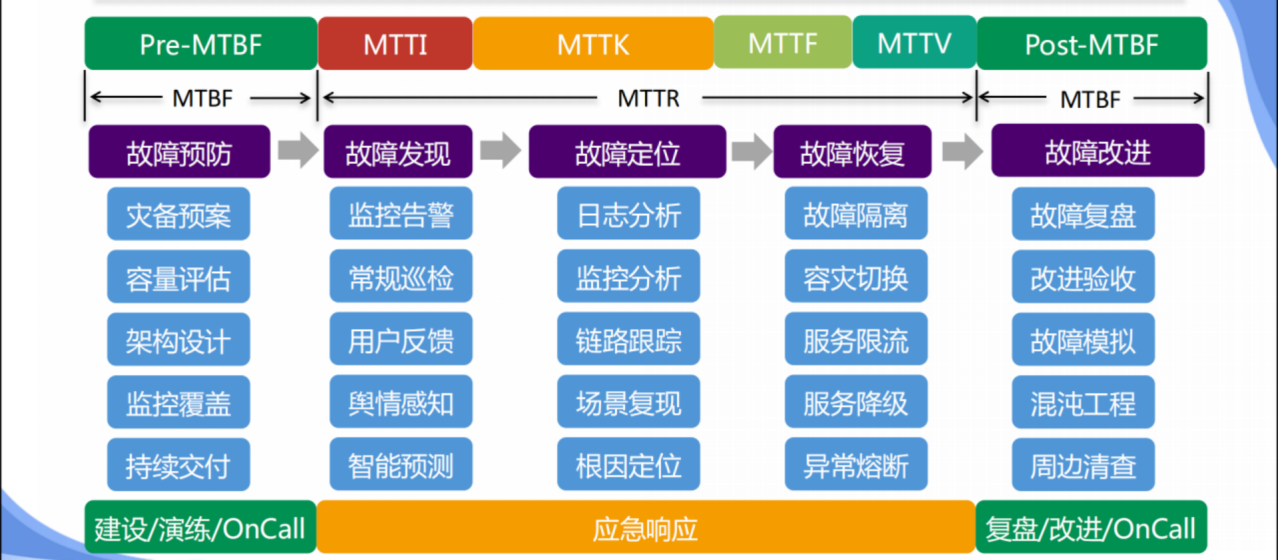
SRE稳定性建设全景图(故障生命周期视角)
框架/体系 (DevXOps vs AppLifecycle)
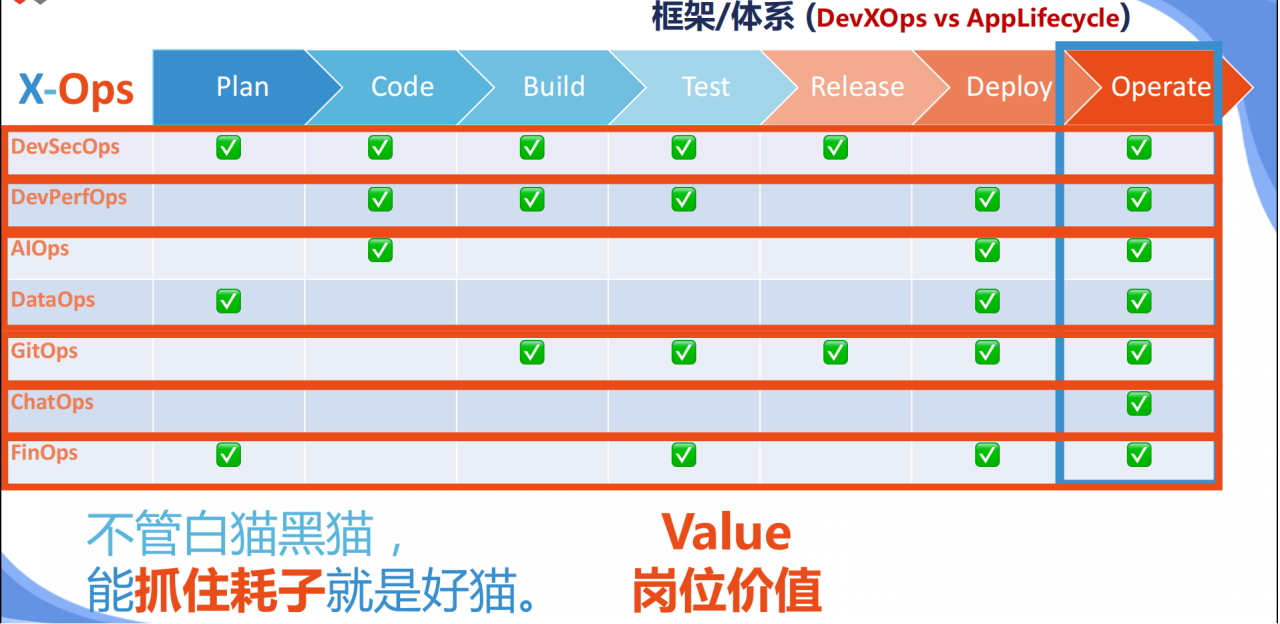
框架/体系 (CI/CD → CI/CD/CO)
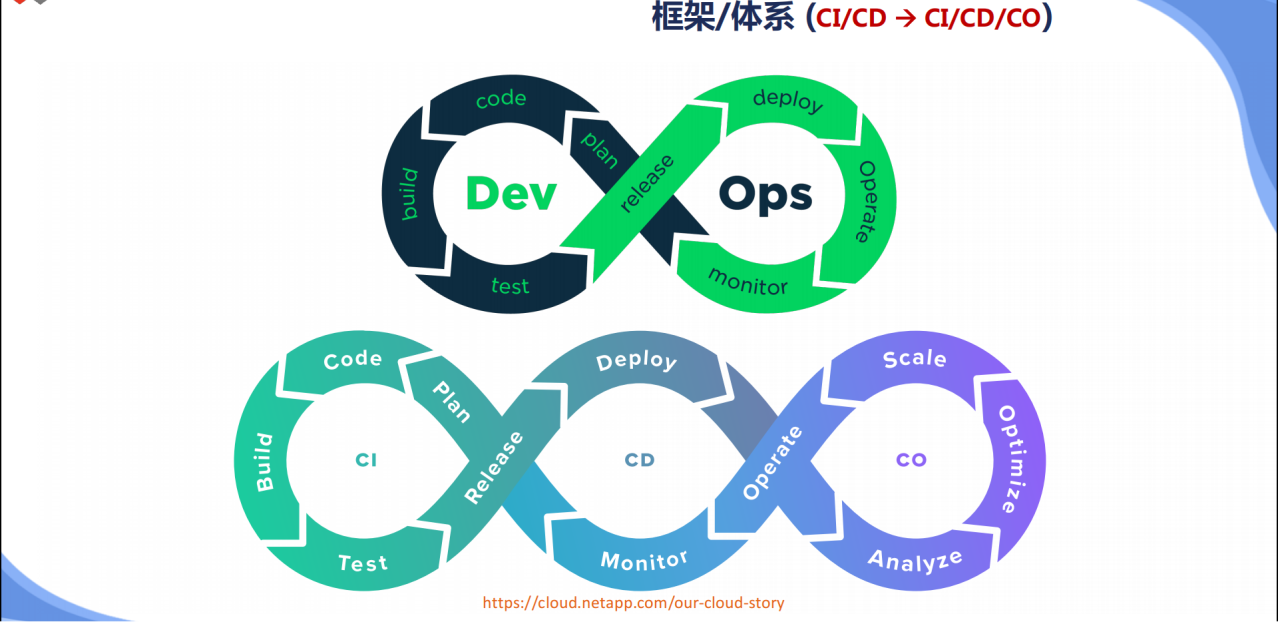
云成本管理运营平台能力评估
伴随着企业云资源投入的不断增加,企业需要从财务角度进行云服务的预算制定、成本核算、成本归集和成本优化,以实现对云服务的精细化管理、经济型使用。
云成本管理运营平台能力评估依据标准《面向云资源的财务运营能力通用成熟度模型》,面向于构建云资源财务运营能力的平台进行指导和评价,对云投入成本的合理性、实际效果进行整体、客观、清晰化的理解和评价。
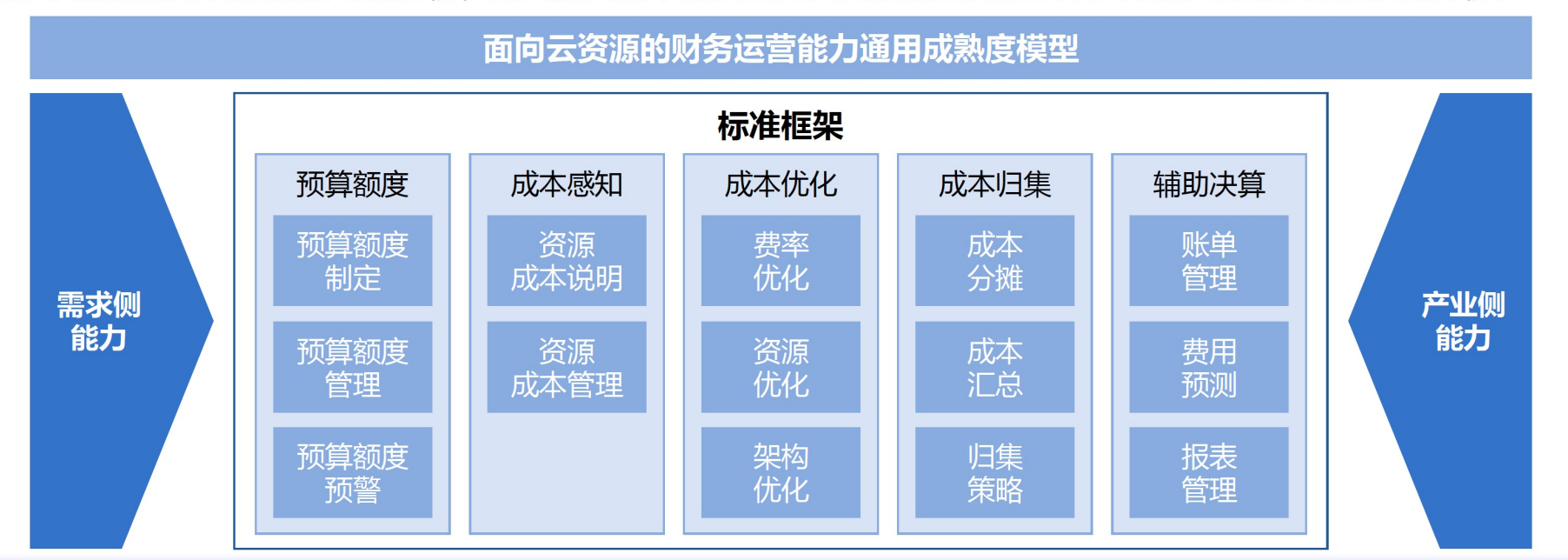
SRE稳定性运营体系(演进方向)
三、互动答疑(Q&A)

石鹏(东方德胜)
2016年加入美图,运维技术专家,美图产品SRE负责人。目前在美图负责社区、商业化、实验室、影像SaaS、创新等全线产品的运维保障工作,同时参与公司日志、监控等基础设施的建设。参与或主导过多次公司基础设施的调整、改造,在监控、灾备、故障管理、稳定性运营等方面有一定的经验和积累。业界多个技术峰会的分享嘉宾或出品人。
Q1:关于各种Ops在operate阶段中,你们的宗旨是:不管白猫黑猫,能抓住耗子就是好猫。这句话具体是什么意思?其中抓住耗子指的是什么?
A1:不管白猫黑猫,不管你叫什么OPS,只要它能够持续地帮我们去输出前面提的几个价值点,能够让我们更高效地、更高质量地去提升质量、提高效率、降低成本,那它就是一个好的OPS,就是值得我们去探索的一个OPS。这里其实隐含着一层信息,就是这个猫它所提供的价值是什么。这里讲的猫的“岗位职责”就是需要抓耗子,而不是像现在我们这个“撸猫”等行为中为人们提供了一些其他的价值。
Q2:在SRE稳定运营体系中,你们从以前的被动应对到现在主动出击,过程中是不是要做一些项目?像数据化、Automation、体系化、智能化?或者上一些平台?美图是大概做哪些事情?
A2:因为这一页ppt材料,它展示了我们整个的演进方向和思路,没有具体到我们在这个过程里边需要做什么。那说到这个的话,比如前面我们观测的部分与量化的部分,要从不同领域来看。比如商业领域,我们会去搞一些BI。然后如果说我们是单纯指稳定性保障方向的,我们会去做各种可观测性的建设,我们会去关注服务的质量是什么样子的?研发效能方向,需求迭代的效率是什么样子的?然后平台的话,当然是会需要有一些平台去承载的,不同公司可能会不一样。
本期视频回看:

官方网站:www.sretraining.cn