1. SimpleRNN
学习视频:https://www.youtube.com/watch?v=Cc4ENs6BHQw&t=0s
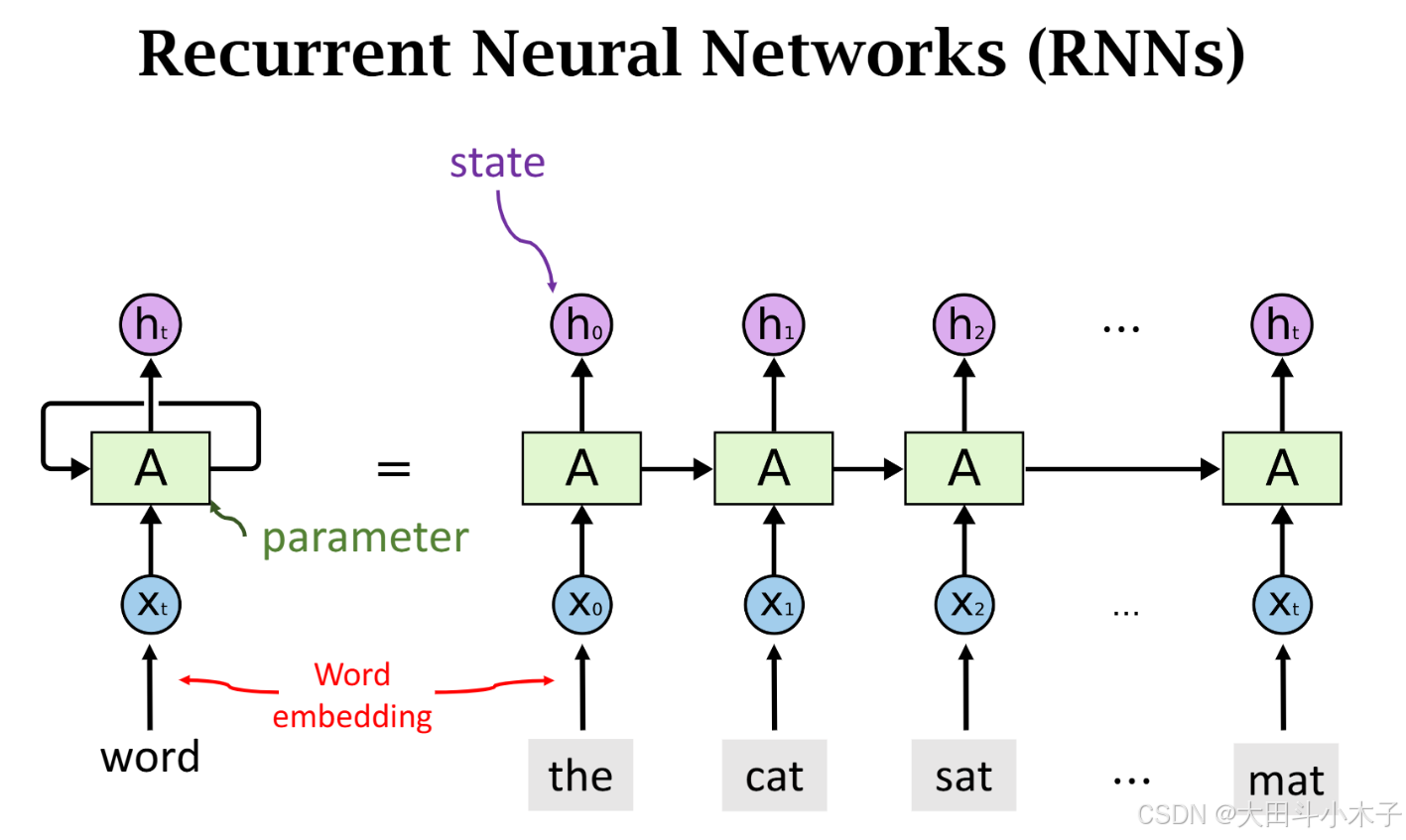
- 对于时序数据,输入输出都不固定,需要many-one、many-many模型,RNN很适合时序数据
整个RNN 只有一个参数A
1.1 h t h_t ht计算
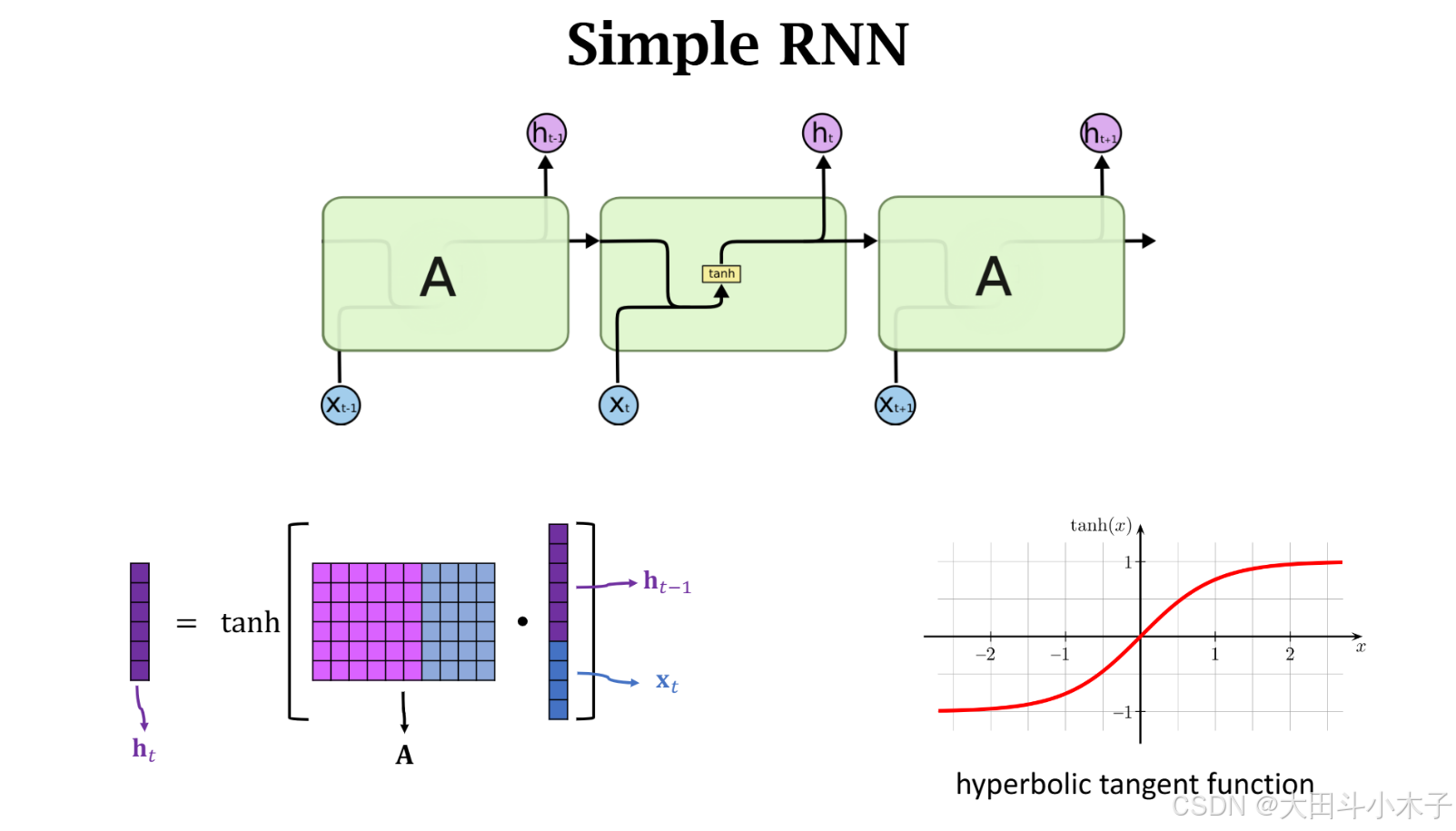
1.2 激活函数
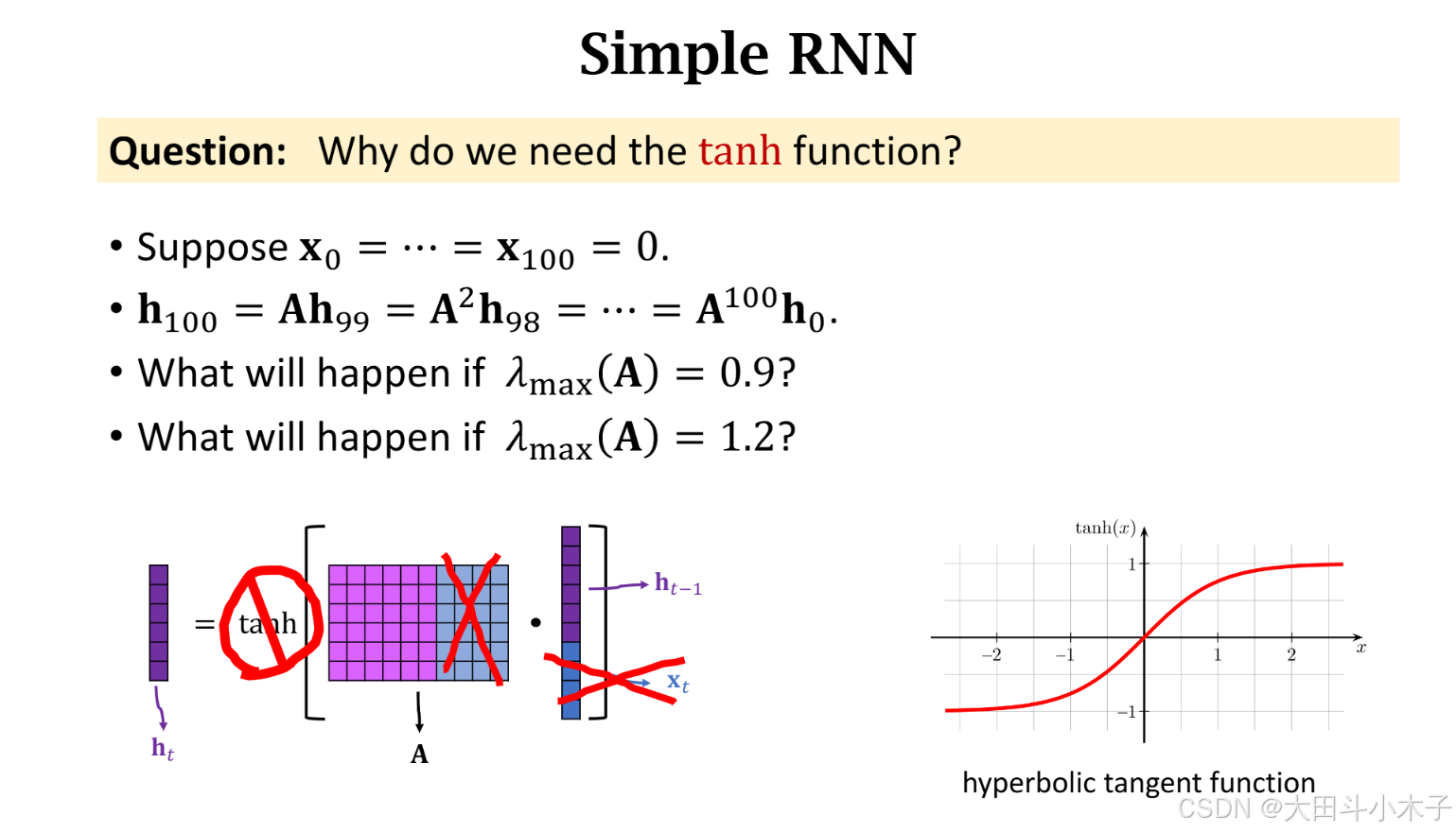
为什么需要双曲正切函数作为激活函数?
假设输入为0,当矩阵A最大特征值=0.9,则
h
100
h_{100}
h100每个元素近似为0;当矩阵A最大特征值=1.2,则
h
100
h_{100}
h100每个元素都很大,状态向量会爆炸
- 训练参数

2. SimpleRNN+Self-Attention
学习链接:https://www.youtube.com/watch?v=Vr4UNt7X6Gw&t=0s
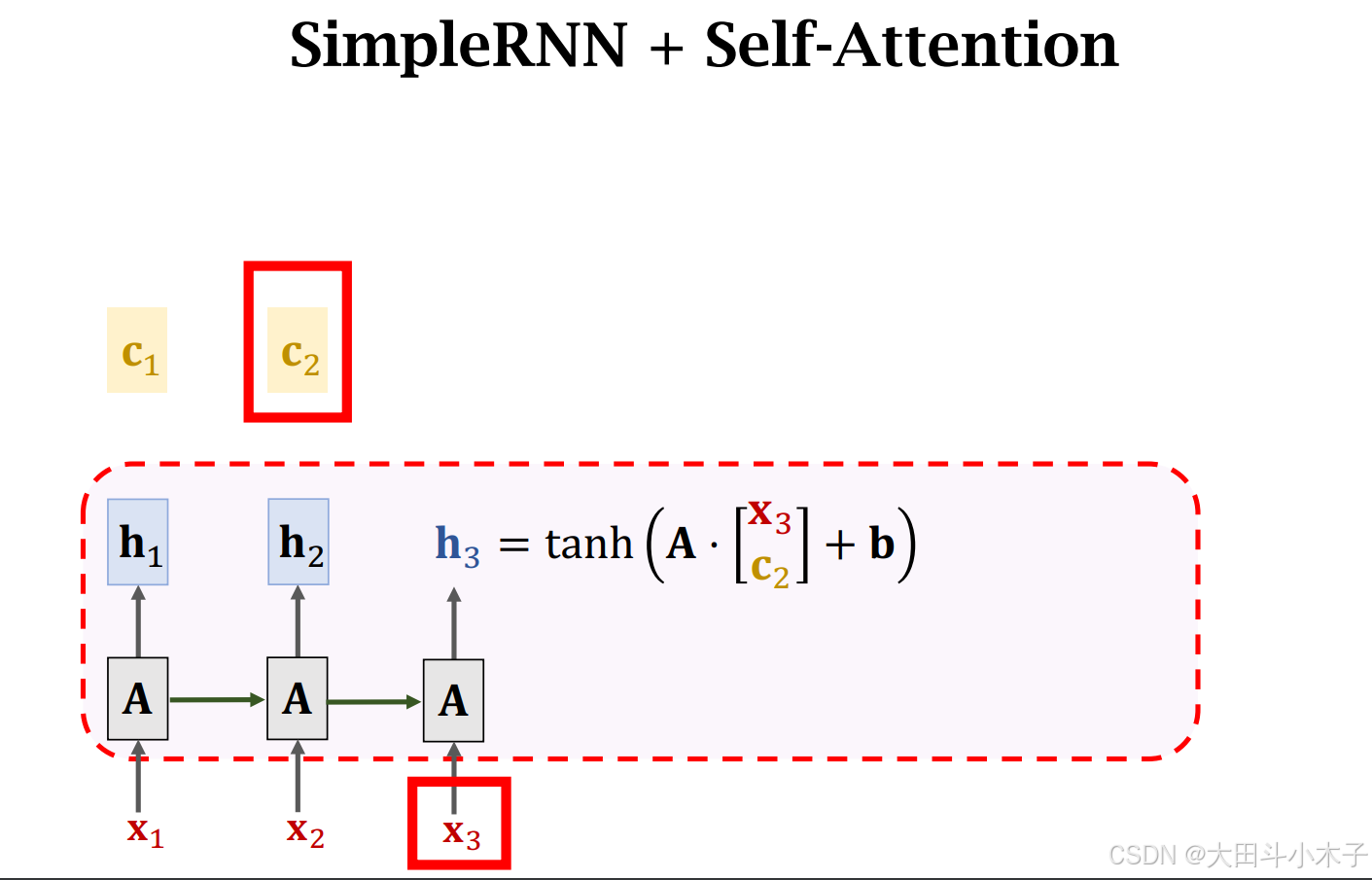
2.1 状态更新
对于SimpleRNN,新的状态
h
i
+
1
h_{i+1}
hi+1与
h
i
h_{i}
hi以及
x
i
+
1
x_{i+1}
xi+1有关
引入Self-Attention后,新的状态
h
i
+
1
h_{i+1}
hi+1与
c
i
c_{i}
ci以及
x
i
+
1
x_{i+1}
xi+1有关。
每一轮更新状态之前,都会用context vector c看一遍之前所有状态,解决遗忘问题
$c$是已有状态h的加权平均,初始$h_0$为全0向量,可以忽略

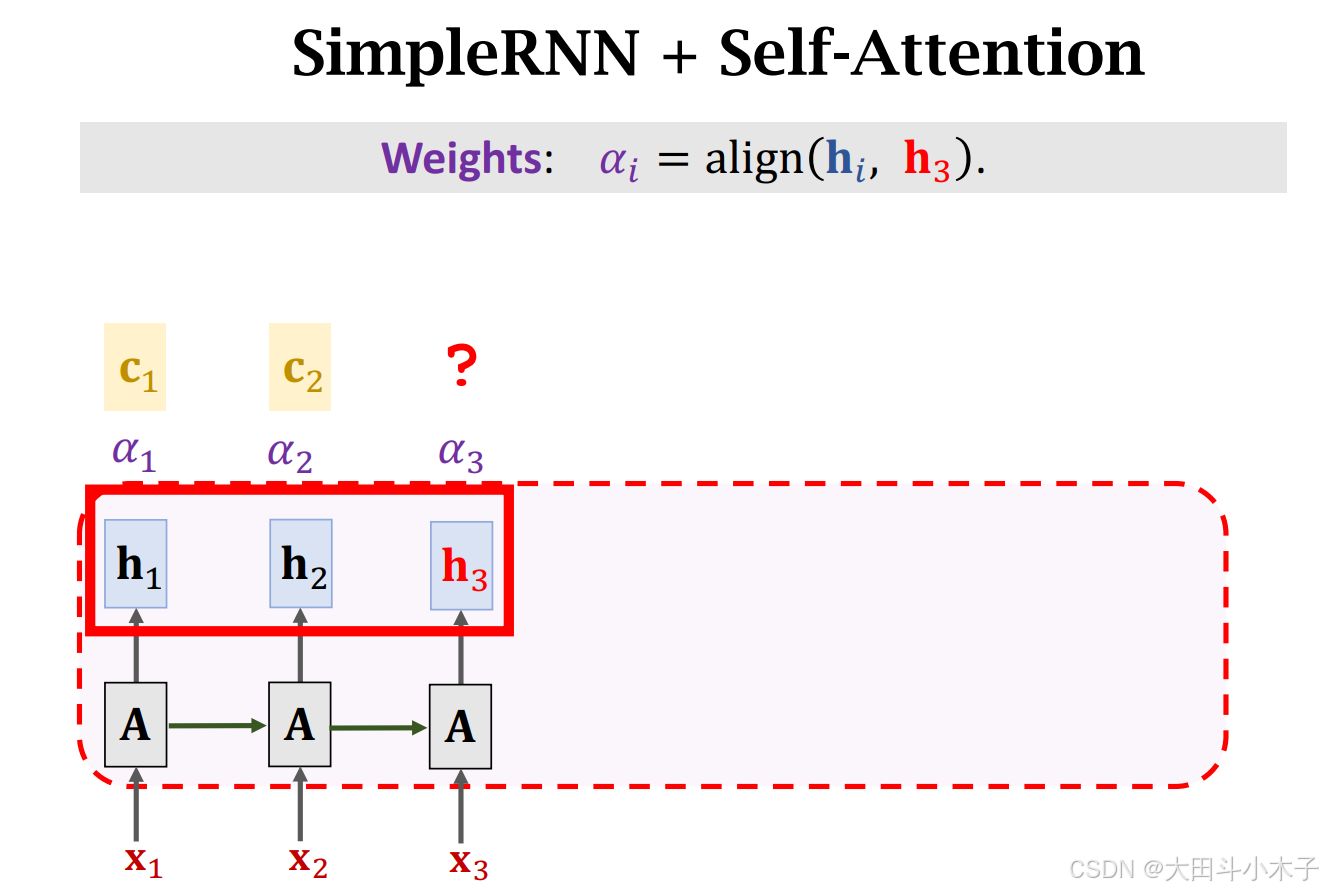
2.2 权重 α α α
用当前状态
h
i
h_i
hi与已有状态作对比,包括与
h
i
h_i
hi自己做对比,得到
i
个
α
i个α
i个α