1. Motivation
在线批次选择(Online batch selection)方法通过在训练期间动态选择数据批次,为静态训练数据的选择提供了一种自适应替代方案。然而,现有方法要么依赖于参考模型(reference model),要么依赖于一些可能无法捕获真实数据信息的简单启发式方法。
- 基于参考模型的批次选择方法: 依赖于额外的参考模型。一些方法的参考模型是根据大量保留数据进行训练的,这会导致相当大的计算成本,并减少可用于训练主模型的数据量。另一些方法则利用公开的大规模预训练模型作为参考模型,但是也需要进行贝叶斯处理,并在每次迭代时查询候选批次中每个样本的参考模型。这些操作的计算成本很高,使得该方法对于大规模 LLM 训练来说不切实际。
- 启发式方法:根据高损失或大梯度范数等指标对具有挑战性的样本进行优先级排序。但这些启发式方法可能无法捕获示例的真实信息或相关性。因此,这些方法在性能方面常常不足,在某些情况下甚至可能比简单的均匀选择表现不佳。
静态数据选择(static data selection):在训练过程之前仅进行一次数据训练的选择。这种方法主要是出于效率考虑,因为花在数据选择上的时间可以分摊到大量的训练步骤中。然而,这种单步选择的非自适应性质通常会导致性能不佳,因为所选数据在整个训练过程中可能不是最具信息性或相关性的。此外,这些算法通常需要大量且复杂的数据预处理步骤,一些数据选择算法甚至需要为了做数据选择还额外训练模型,这带来了额外的计算成本和实现复杂性。
基于此,作者提出了Online batch selection,这是一个更具适应性和动态性的数据选择方法。通过根据模型的进度不断更新选择标准,在线批量选择可以在训练的每个阶段识别最相关和信息最丰富的示例,从而有可能实现更快的收敛和更好的泛化性能。此外,与预先处理整个数据集的静态数据选择方法相比,在线批量选择对较小批次的数据进行操作,减少了繁琐的数据预处理的需要,并能够更有效地利用计算资源。
2.Contribution
在这项工作中,作者提出了GREedy近似泰勒选择(GREATS),它解决了现有方法的局限性,并显着提高了语言模型训练的收敛速度和泛化性能。
- 原则性公式化(
Principled Formulation for Optimal Batch Selection)提出了一种原则性的在线批量选择问题公式化,将其视为一个集合效用函数优化任务。 - 高效近似(
Efficient Approximations for Scalable Batch Selection.)使用了一种高效的近似方法,利用泰勒展开来近似数据批次质量,并通过梯度内积高效近似模型验证损失的变化。 - 在线批量选择的速度(
Online Batch Selection at the Speed of Regular Training.)提出了一种名为“ghost inner-product”的技术,无需实例化任何模型大小的向量即可高效计算成对梯度内积。 - 全面评估(
Comprehensive Evaluations.):在多种语言建模任务上进行了广泛的实验,证明了GREATS在不同模型、训练数据集和评估数据集上都能显著加快训练收敛速度并提高泛化性能。
3. Background
Set-up of online batch selection
在深度学习模型的训练过程中,通常需要最小化训练损失,这通过迭代优化方法如随机梯度下降(SGD)实现。在每次迭代中,从训练数据集Dtr中抽取一个批次S,用于更新模型参数。在online batch selection的设置中,每次迭代t时,从训练集Dtr中抽取一个大批次Bt ={z1, . . . , zB},然后在线批量选择算法的目标是从Bt中选择最有价值的子集^Bt。这个过程可以被表述为一个优化问题,目的是最大化所选^Bt对模型更新的效用。
Utility Function
效用函数U(t)在每次迭代t时,将输入的训练数据批次S映射到一个分数,表示该批次对模型更新的效用。在线批量选择的任务是找到一个子集^Bt,使得效用函数U(t)(S)最大化。然而,由于U(t)是集合函数,解决这个问题面临重大挑战,因为它可能需要对Bt的大量子集S进行效用评估。
现有的在线批量选择方法通过“评分和Top-k范式”来规避这个问题,即计算每个数据点z ∈ Bt的重要性分数φz,然后选择分数最高的数据点子集。例如,有些方法使用训练数据点上的个体损失或梯度范数作为重要性分数。这些方法本质上定义了效用函数U(t)(S)为各个数据点重要性分数的总和,并假设这些分数之和是数据集S效用的可靠指标,希望与模型在更新后的性能正相关。
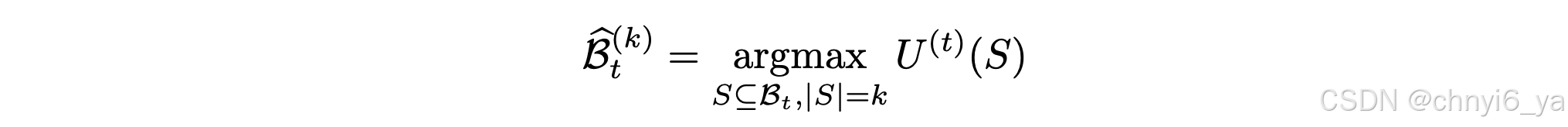
Limitations of Scoring and Top-k Paradigm
这种基于评分和Top-k的方法存在局限性,大多数评分机制会导致相似的数据点获得相似的分数,但在在线批量选择的背景下,多样性至关重要。因此,由Top-K值数据点组成的子集Bbt可能缺乏多样性。特别是,重复的点可能会获得相同的高分,并且可能被错误地认为可以双重提高模型性能,尽管情况可能并非如此。这种Top-K方法的主要问题是忽略了所选数据点之间的相互作用。当一个数据点被选中时,其余数据点的重要性分数通常会发生变化。例如,与所选数据点相似的数据点的值通常会减少,而与所选数据点差异很大的数据点的值会增加。
4.Optimizing Utility in Online Batch Selection via Greedy Algorithms
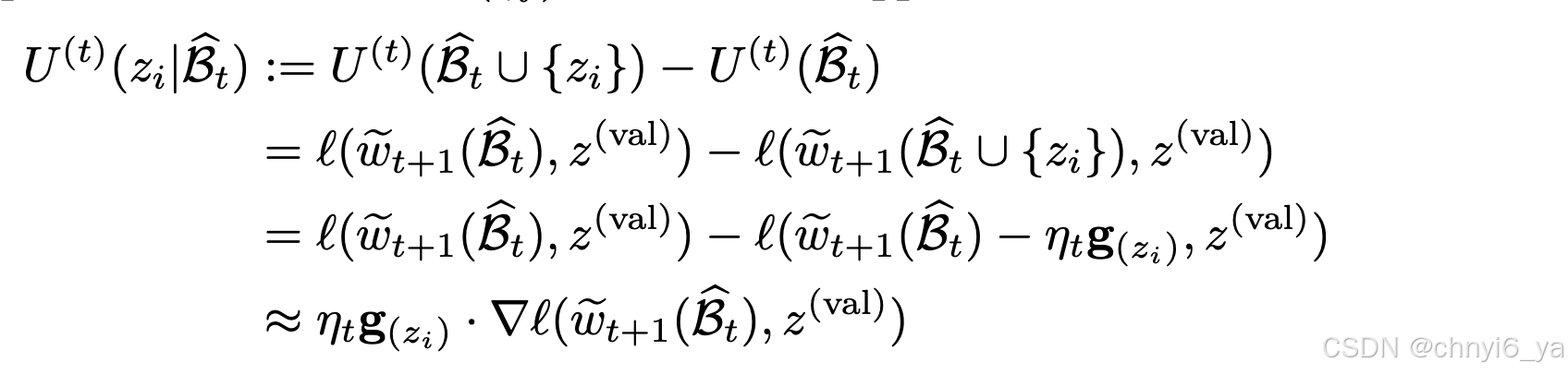

对于文章给的公式,我的推导如下(但不确定)
第一项的梯度内积衡量的是 数据点zi的重要程度,它捕获 zi 的训练损失梯度和验证损失梯度之间的对齐关系,表明基于 zi 的更新将有助于相对于原始模型 wt 减少验证损失。

第二项表示的是 选取 Bt 后 zi 原始重要性的修正项。它惩罚 zi 和 Bt 中数据点之间的相似性,通过其梯度的 Hessian 加权内积来衡量。直观上,如果 zi 的梯度与 Bt 中数据点的梯度相似,则校正项会很大,从而降低将 zi 添加到所选子集的总体边际增益。这鼓励选择不同的数据点,为模型更新提供补充信息。
算法
使用公式,作者开发了一种近似普通贪婪算法的新算法。最初,每个数据点 z ∈ Bt 被分配一个重要性得分 φz,初始化为 φz = ηtg(z) · g(z(val)),它近似于将 z 添加到空集的边际增益,即 U (t) (zi | {}) = U (t)({zi})。该算法首先选择具有最高重要性得分的数据点 z1* = argmaxz∈Bt φz。选择数据点 z* 进行模型更新后,其余数据点的重要性得分通过 −ηt2g(zi)H(z(val))g(z*) 进行调整。此调整近似将每个剩余数据点添加到包含 z* 的集合(即 U (t)(zi | {z*}))的边际增益。该算法迭代地选择具有最高调整重要性得分的数据点,并更新其余点的得分,直到选择了 k 个数据点。
