20 理解业务和数据:我们需要做好什么计划?_哔哩哔哩_bilibili
目录
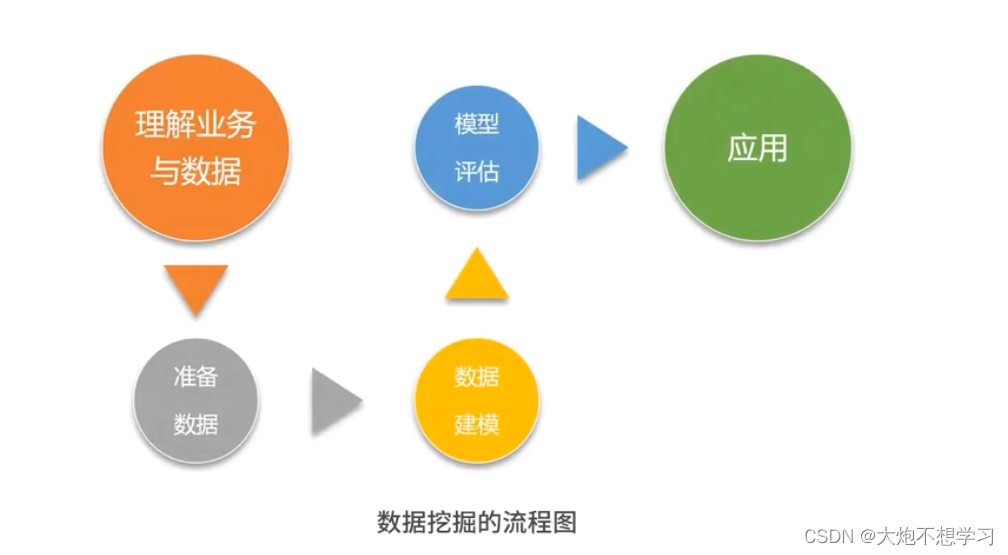
一、理解业务和数据:我们需要做好什么计划?
在开始数据挖掘的时候
要确保你对业务及其数据有充分的理解
1.1两个思想问题



1.2为什么数据挖掘不是万能的
数据挖掘只能在有限的资源与条件下去提供最大化的解决方案


1.3业务背景与目标



1.4把握数据


1.5总结

二、 准备数据:如何处理出完整、干净的数据?
做好数据的准备工作是获得一个好结果的必由之路,准备数据不是独立存在的,不是说一次性做完数据准备工作就结束了。后面的模型训练和模型评估环节数据的准备相关,当模型出现错误,结果达不到预期,往往需要重新回到数据准备环节进行处理,反复迭代几次最终才能达到期望。

2.1找到数据

2.2数据探索

2.3数据清洗

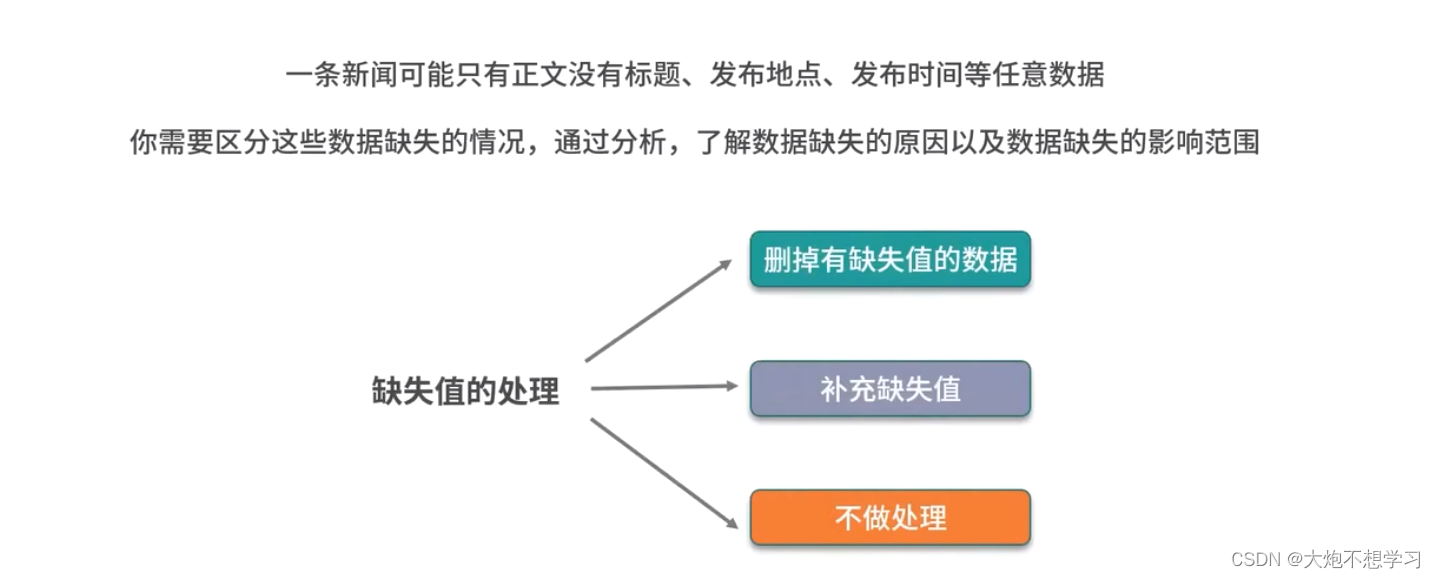
2.3.1缺失值处理
2.3.2异常值的处理

2.3.3数据偏差



2.3.4数据标准化


2.3.5特征选择


2.4构建训练集和测试集


三、 数据建模:该如何选择一个适合我需求的算法?

3.1分类问题
有监督学习:
概念:通过已有的训练样本去训练得到一个最优模型,再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现预测和分类的目的,也就具有了对未知数据进行预测和分类的能力。简单来说,就像有标准答案的练习题,然后再去考试,相比没有答案的练习题然后去考试准确率更高。监督学习中的数据中是提前做好了分类信息的, 它的训练样本中是同时包含有特征和标签信息的,因此根据这些来得到相应的输出。
有监督算法常见的有:线性回归算法、BP神经网络算法、决策树、支持向量机、KNN等。
有监督学习中,比较典型的问题可以分为:输入变量与输出变量均为连续的变量的预测问题称为回归问题(Regression),输出变量为有限个离散变量的预测问题称为分类问题(Classfication),输入变量与输出变量均为变量序列的预测问题称为标注问题。




3.2聚类问题
无监督学习:
概念:训练样本的标记信息未知, 目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础,此类学习任务中研究最多、应用最广的是"聚类" (clustering),聚类目的在于把相似的东西聚在一起,主要通过计算样本间和群体间距离得到。深度学习和PCA都属于无监督学习的范畴。
无监督算法常见的有:密度估计(densityestimation)、异常检测(anomaly detection)、层次聚类、EM算法、K-Means算法(K均值算法)、DBSCAN算法 等。


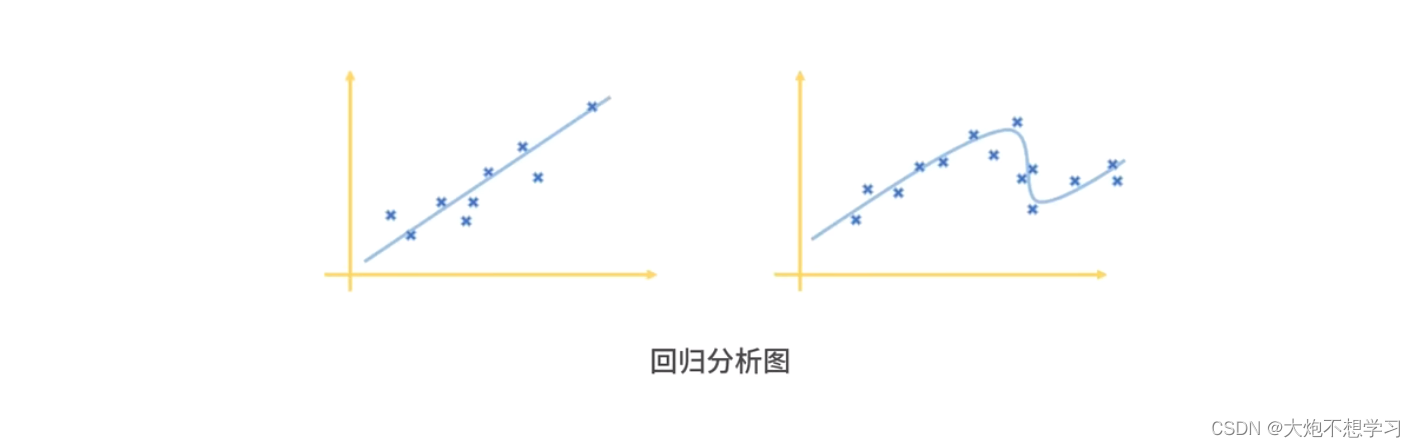
3.3回归问题


不管是线性数据还是非线性数据都可以用回归分析
通过学习可以得到一条线,较好的拟合了这些数据,可能不通过任何一个数据点,而是使得所有数据点到这条线的距离都是最短的,或者说损失是最小的。根据这条线,如果给出一个新的x,你就可以算出对应的y是多少。


3.4关联问题

3.5模型集成
模型集成也可以叫做集成学习
思路:合并多个模型来提升整体的效果
三种模型集成的方法:
3.5.1(bagging)装袋法
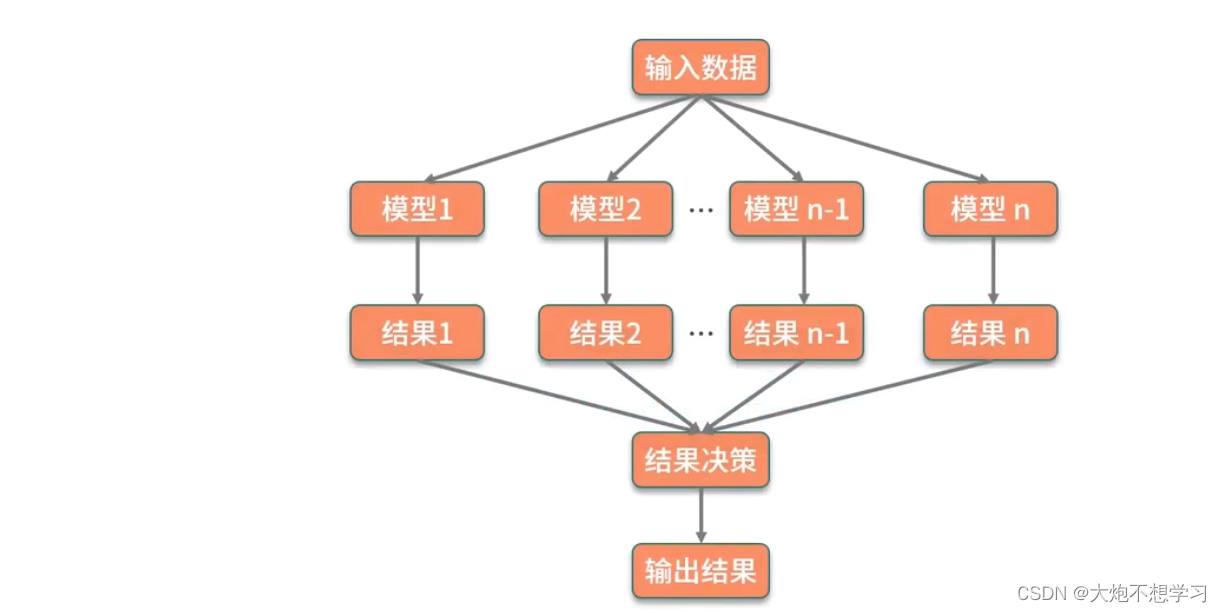
3.5.2boosting增强法
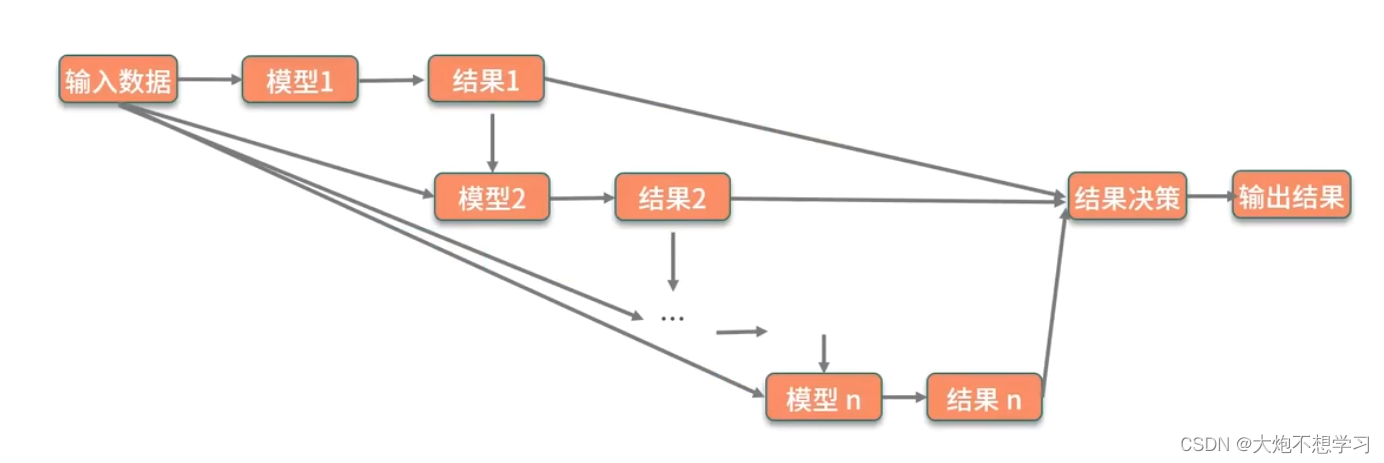
3.5.3stacking堆叠法

四、模型评估:如何确认我们的模型已经达标?
模型评估是对模型进行多种维度的评估,来确认模型是否可以放到线上去使用
4.1一个关于“训练一个小猪图片分类模型”的例子

4.1.1评估指标:混淆矩阵与准确率指标
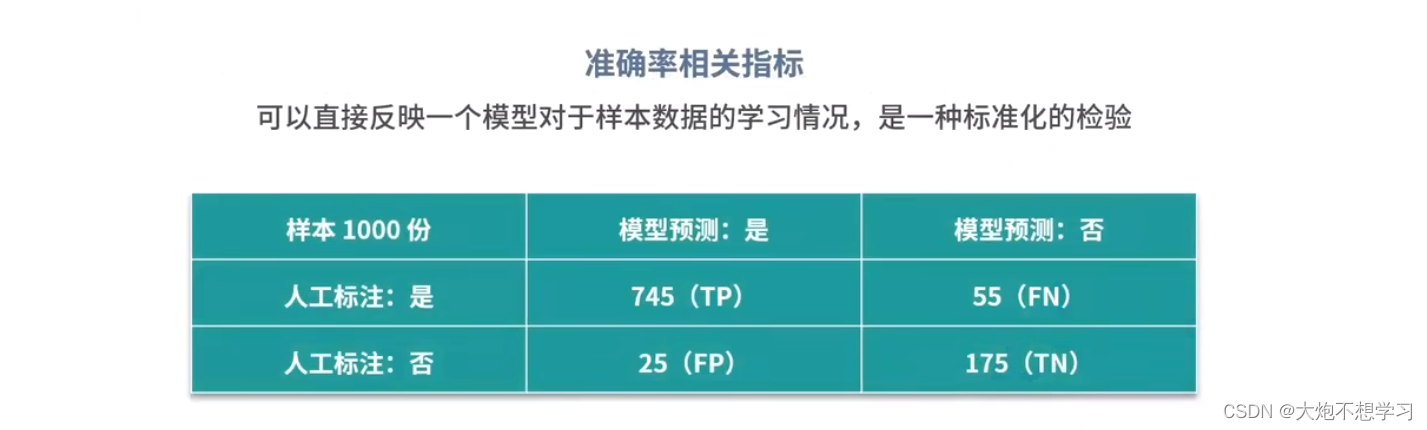


具体是如何构建的,以小猪图为例:
选定若干组判定的概率就能得到若干组混淆矩阵:
使用这些值画在坐标轴上:横坐标是假正例率,纵坐标是真正例率,这些点连起来形成的曲线我们就称为ROC曲线,ROC曲线下方的面积就是AUC值。
ROC曲线和AUC值可以反应一个模型的稳定性,当ROC曲线接近于对角线的时候说明模型的输出极不稳定,模型就更加不准确。




4.1.2评估指标:十分重要的业务抽取评估

4.1.3泛化能力评估
除了要求模型的准确外,模型的泛化能力也值得重视
通过两个指标来评估模型泛化能力是好还是好坏
以小猪为例:


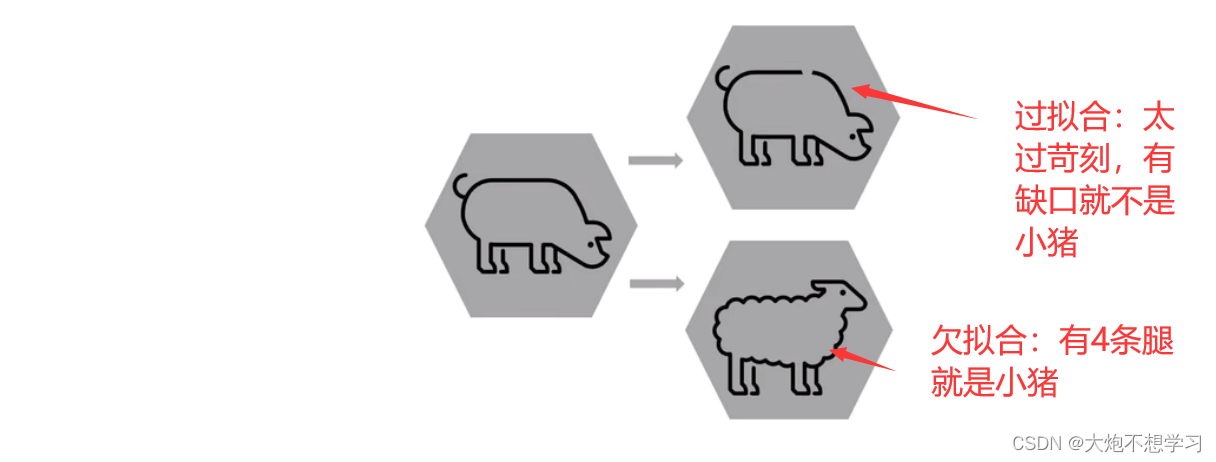

4.1.4其他评估指标

4.1.5评估数据集的处理


4.2总结


五、 模型应用:我们的模型是否可以解决业务需求?
5.1模型部署

5.2模型保存
把模型保存好以方便应用,要给模型定义好一个名字,甚至需要维护好一个详细的文档来记录模型所使用的算法,训练数据,评估结果等信息。因为在整个过程中会进行很多次训练,产生很多的模型,或者把很多的模型组合在生产中使用,同时还需要跟后面的重新训练进行效果的对比,有时候模型的训练和部署可能由不同的人来实施,如果保存时没有注意到这些问题,很可能导致出现混乱的情况,所以我们要制定好模型保存的规范,包括存放的位置,名字的定义,模型使用的算法,数据效果等内容,防止发生遗忘,丢失,误删除甚至是服务器崩坏等人为的事故造成不要损失。

5.3模型的优化

5.4离线应用还是在线应用

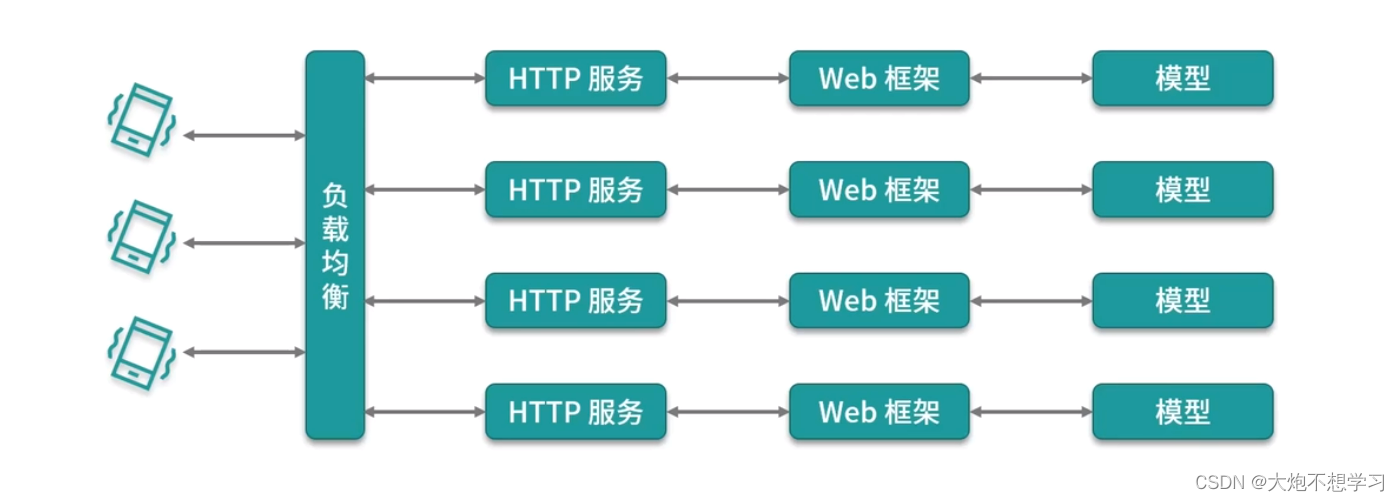
5.5一个方案
通常算法工程师或者数据挖掘工程师,都忙于解决模型问题,到了模型部署阶段就头疼不已,尤其是大规模的需要运行的线上服务可能会耗费很多时间。以下是一个简单的部署方案

5.6总结
- 记录项目 经验,学会总结反思
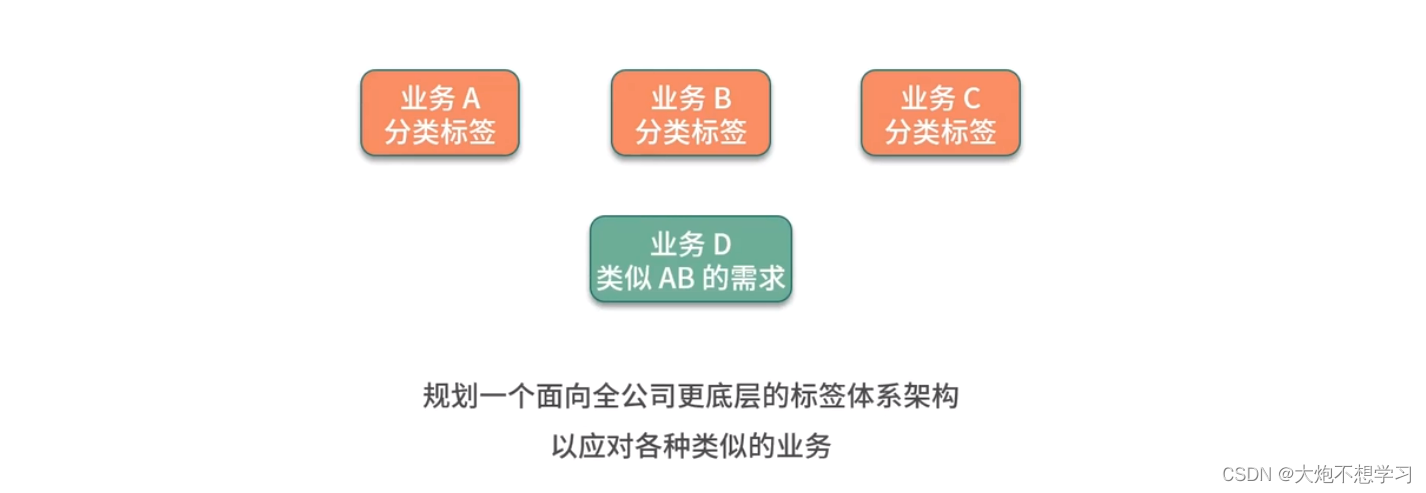
- 多考虑一点,如何适用更多的场景
比如说在做标签....避免冗余开发
- 监控与迭代
模型的监控从以下3个方面入手
1、结果监控主要是针对一些具体的指标(准确率、召回率等)进行监控,还可以根据具体产出的结果在业务中的效果进行监控
2、人工定期复审
3、Case收集与样本积累
通过具体的Case我们可以知道当前的模型存在哪些问题,有些Case可能是因为模型本身的问题造成,有些是因为业务场景的数据发生变化造成的。通过收集的Case进行分析,可以知道我们需要从哪个方向去优化模型。
所以在前期准备数据时遇到的数据准备不充分的情况,也可以在收集环节重点关注,以补全上一版训练时的一些缺失情侣,这样在下次迭代训练时能够有更好的样本集。