目录
3, MongoDB的体系结构
一,数据库管理系统
1, 什么是数据库
数据: 描述事物的符号记录, 可以是数字、 文字、图形、图像、声音、语言等,数据有多种形式,它们都可以经过数字化后存入计算机。
数据库: 存储数据的仓库,是长期存放在计算机内、有组织、可共享的大量数据的集合。数据库中的数据按照一定数据模型组织、描述和存储,具有较小的冗余度,较高的独立性和易扩展性,并为各种用户共享。
2,什么是数据库管理系统
数据库系统成熟的标志就是数据库管理系统的出现。数据库管理系统(DataBase ManagermentSystem,简称DBMS)是管理数据库的一个软件,是对数据库的一种完整和统一的管理和控制机制。数据库管理系统不仅让我们能够实现对数据的快速检索和维护,还为数据的安全性、完整性、并发控制和数据恢复提供了保证。数据库管理系统的核心是一个用来存储大量数据的数据库。
数据库管理系统主要分为俩大类:RDBMS、NOSQL。
二, NoSQL 是什么
1,NoSQL 简介
NoSQL 是不同于传统的关系型数据库的数据库管理系统的统称。 两者存在许多显著的不同点,其中最重要的是NoSQL 不使用 SQL 作为查询语言。 其数据存储可以不需要固定的表格模式,也经常会避免使用 SQL 的 JOIN 操作,一般有水平可扩展性的特征。 NoSQL 一词最早出现于 1998 年,是 Carlo Strozzi 开发的一个轻量、开源、不提供 SQL 功能的关系数据库。 2009 年,Last.fm 的 Johan Oskarsson 发起了一次关于分布式开源数据库的讨论, 来自 Rackspace 的 Eric Evans 再次提出了 NoSQL 的概念,这时的 NoSQL 主要指非关系型、分布式、不提供 ACID 的数据库设计模式。 2009 年在亚特兰大举行的"no:sql(east)"讨论会是一个里程碑,其口号是"select fun, profit from real_world where relational=false;"。因此,对 NoSQL 最普遍的解释是“非关联型的”,强调 Key-Value Stores 和文档数据库的优点,而不是单纯的反对RDBMS。
2,NoSQL数据库
传统的关系型数据库只能存储结构化数据,对于非结构化的数据支持不够完善。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。根据不同的存储方式可以将NoSQL数据库分为以下几类:
- 键值(Key-Value)存储数据库
说明:这一类数据库主要会使用到一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据。
Key/Value模型对于IT系统来说优势在于简单、易部署。
应用:内容缓存,主要用于处理大量数据的高访问负载。
产品:Tokyo Cabinet/Tyrant、Redis、Voldemort、Berkeley DB
优势:快速查询
劣势:存储的数据缺少结构化 - 列存储数据库
说明:这部分数据库通常是用来应对分布式存储的海量数据。键仍然存在,但是它们的特点是指向了多个列,这些列是由列家族来安排的。
应用:分布式文件系统
产品:Cassandra,HBase,Riak
优势:查找速度快,可扩展性强,更容易进行分布式扩展
劣势:功能相对局限 - 文档型数据库
说明:该类型的数据模型是版本化的文档,半结构化的文档以特定的格式存储,如JSON。文档型数据库可以看作是键值数据库的升级版,允许之间嵌套键值。而且文档型数据库比键值数据库的查询效率更高。
应用:Web应用
产品:CouchDB,MongoDB
优势:数据结构要求不严格
劣势:查询性能不高,且缺乏统一的查询语法 - 图形(Graph)数据库
说明:图形结构的数据库同其他行列以及刚性结构的SQL数据库不同,它是使用灵活的图形模型,并且能够扩展到多个服务器上。NoSQL数据库没有标准的查询语言(SQL),因此进行数据库查询需要制定数据模型。许多NoSQL数据库都有REST格式的数据接口或者查询API。
应用:社交网络
产品: Neo4j,InfoGrid,Infinite Graph
优势:利用图结构相关算法
劣势:需要对整个图做计算才能得出结果,不容易做分布式的集群方案
3,NoSQL 与 RDBMS 对比
RDBMS :
- 高度组织化结构化数据
- 结构化查询语言(SQL), 数据和关系都存储在单独的表中。
- 数据操纵语言,数据定义语言严格的一致性
- 事务遵循ACID特性
NoSQL :
- 代表着不仅仅是 SQL
- 没有标准的查询语言
- 键-值对存储,列存储,文档存储,图形数据库,最终一致性,而非 ACID 属性
- 可以应对高并发读写请求,海量数据的高效率存储和访问需求,满足对数据库的高可伸缩性和高可用性的需求
三,MongoDB简介
1, MongoDB 是什么
MongoDB 是由 C++语言编写的,是一个高性能的基于分布式文件存储的开源数据库系统,是NoSQL数据库产品中的一种。MongoDB 旨在为 WEB 应用提供可扩展的高性能数据存储解决方案, 在高负载的情况下,可以添加更多的节点保证服务器性能。MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象,即一个文档认为就是一个对象,字段的数据类型是字符型,字段值除了使用基本的一些类型外,还可以包含其他文档,数组及文档数组。

2,mongodb发展史
2007 年 10 月,MongoDB 由 10gen 团队所发展。2009 年 2 月首度推出。 2012 年 05 月 23 日,MongoDB2.1 开发分支发布了! 该版本采用全新架构,包含诸多增强。 2012 年 06 月 06 日,MongoDB 2.0.6 发布,分布式文档数据库。 2013 年 04 月 23 日,MongoDB 2.4.3 发布,此版本包括了一些性能优化,功能增强以及 bug 修复。 2013 年 08 月 20 日,MongoDB 2.4.6 发布。 2013 年 11 月 01 日,MongoDB 2.4.8 发布。 2017年03月17日,MongoDB 3.0.1发布。 2018年08月06日,MongoDB 4.0.2发布,支持多文档事务。 2019年08月13日,MongoDB 4.2.0 发布 ,引入分布式事务。
3, MongoDB的体系结构
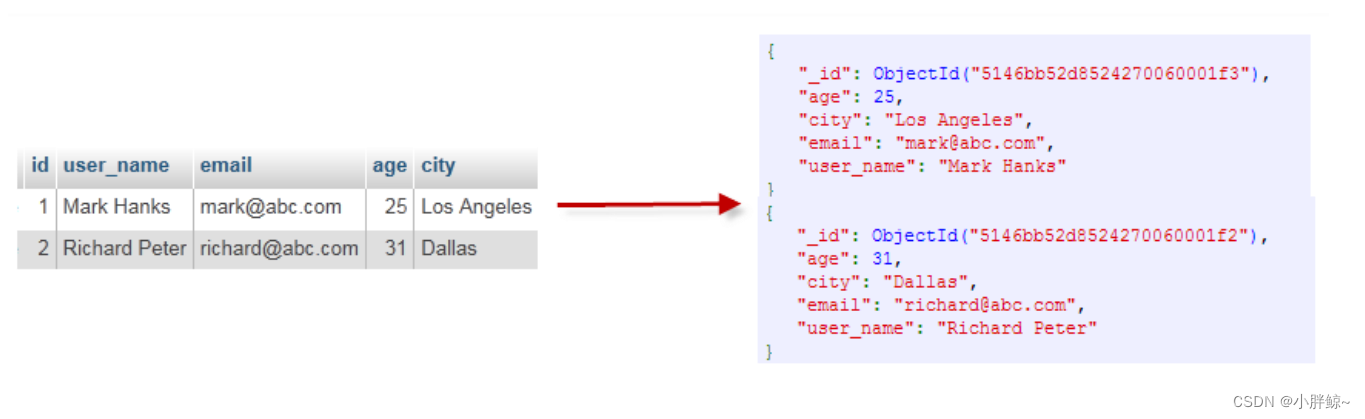
Mysql和MongoDB对比:关系型数据库中有数据库,表和行记录;对应着MongoDB中的数据库,集合,文档。

| SQL术语/概念 | MongoDB术语/概念 |
| database,数据库 | database,数据库 |
| table,表 | collection,集合 |
| row,记录行 | document,文档 |
| column,数据字段 | field,域 |
| index,索引 | index,索引 |
| primary key,主键 | primary key,MongoDB自动将_id字段设置为主键 |
通过下图示例,我们可以更直观的了解MongoDB中的一些概念:
4,MongoDB的数据模型
MongoDB的最小存储单位就是文档(document)对象。文档(document)对象对应于关系型数据库的行。数据在MongoDB中以BSON(Binary-JSON)文档的格式存储在磁盘上。 BSON(Binary Serialized Document Format)是一种类json的一种二进制形式的存储格式,简称Binary JSON。BSON和JSON一样,支持内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,如Date和BinData类型。 BSON采用了类似于 C 语言结构体的名称、对表示方法,支持内嵌的文档对象和数组对象,具有轻量性、可遍历性、高效性的三个特点,可以有效描述非结构化数据和结构化数据。这种格式的优点是灵活性高,但它的缺点是空间利用率不是很理想。 Bson中,除了基本的JSON类型:string,integer,boolean,double,null,array和object,mongo还使用了特殊的数据类型。这些类型包括date,object id,binary data,regular expression 和code。每一个驱动都以特定语言的方式实现了这些类型,查看你的驱动的文档来获取详细信息。 BSON数据类型参考列表:
| 数据类型 | 描述 | 举例 |
| 字符串 | UTF-8字符串都可表示为字符串类型的数据 | {"x" : "foobar"} |
| 对象id | 对象id是文档的12字节的唯一 ID | {"X" :ObjectId() } |
| 布尔值 | 真或者假:true或者false | {"x":true}+ |
| 数组 | 值的集合或者列表可以表示成数组 | {"x" : ["a", "b", "c"]} |
| 32位整数 | 类型不可用。JavaScript仅支持64位浮点数,所以32位整数会被 自动转换。 | shell是不支持该类型的,shell中默认会转换成64 位浮点数 |
| 64位整数 | 不支持这个类型。shell会使用一个特殊的内嵌文档来显示64位整数 | shell是不支持该类型的,shell中默认会转换成64 位浮点数 |
| 64位浮点数 | shell中的数字就是这一种类型 | {"x":3.14159,"y":3} |
| null | 表示空值或者未定义的对象 | {"x":null} |
| undefined | 文档中也可以使用未定义类型 | {"x":undefined} |
| 符号 | shell不支持,shell会将数据库中的符号类型的数据自动转换成 字符串 | |
| 正则表达式 | 文档中可以包含正则表达式,采用JavaScript的正则表达式语法 | {"x" : /foobar/i} |
| 代码 | 文档中还可以包含JavaScript代码 | {"x" : function() { /* …… */ }} |
| 二进制数据 | 二进制数据可以由任意字节的串组成,不过shell中无法使用 | |
| 最大值/最 小值 | BSON包括一个特殊类型,表示可能的最大值。shell中没有这个类型 |
5,适用场景
具体的应用场景如:
- 社交场景,使用 MongoDB 存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能。
- 游戏场景,使用 MongoDB 存储游戏用户信息,用户的装备、积分等直接以内嵌文档的形式存储,方便查询、高效率存储和访问。
- 物流场景,使用 MongoDB 存储订单信息,订单状态在运送过程中会不断更新,以 MongoDB 内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来。
- 物联网场景,使用 MongoDB 存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析。
- 视频直播,使用 MongoDB 存储用户信息、点赞互动信息等。

这些应用场景中,数据操作方面的共同特点是: (1)数据量大 (2)写入操作频繁(读写都很频繁) (3)价值较低的数据,对事务性要求不高 对于这样的数据,我们更适合使用MongoDB来实现数据的存储。
在架构选型上,除了上述的三个特点外,如果你还犹豫是否要选择它?可以考虑以下的一些问题:
- 应用不需要事务及复杂 join 支持
- 新应用,需求会变,数据模型无法确定,想快速迭代开发
- 应用需要2000-3000以上的读写QPS(更高也可以)
- 应用需要TB甚至 PB 级别数据存储
- 应用发展迅速,需要能快速水平扩展
- 应用要求存储的数据不丢失
- 应用需要99.999%高可用
- 应用需要大量的地理位置查询、文本查询
如果上述有1个符合,可以考虑 MongoDB,2个及以上的符合,选择 MongoDB 绝不会后悔。
四,MongoDB的部署与连接
1,安装
(1)配置软件仓库
[root@localhost yum.repos.d]# vim mongodb.repo
[mongodb]
name=mongo
baseurl=https://mirrors.aliyun.com/mongodb/yum/redhat/8Server/mongodb-org/4.4/x86_64/
gpgcheck=0
#gpgkey=https://www.mongodb.org/static/pgp/server-4.4.asc

(2)安装mongodb
[root@localhost yum.repos.d]# yum install mongodb-org -y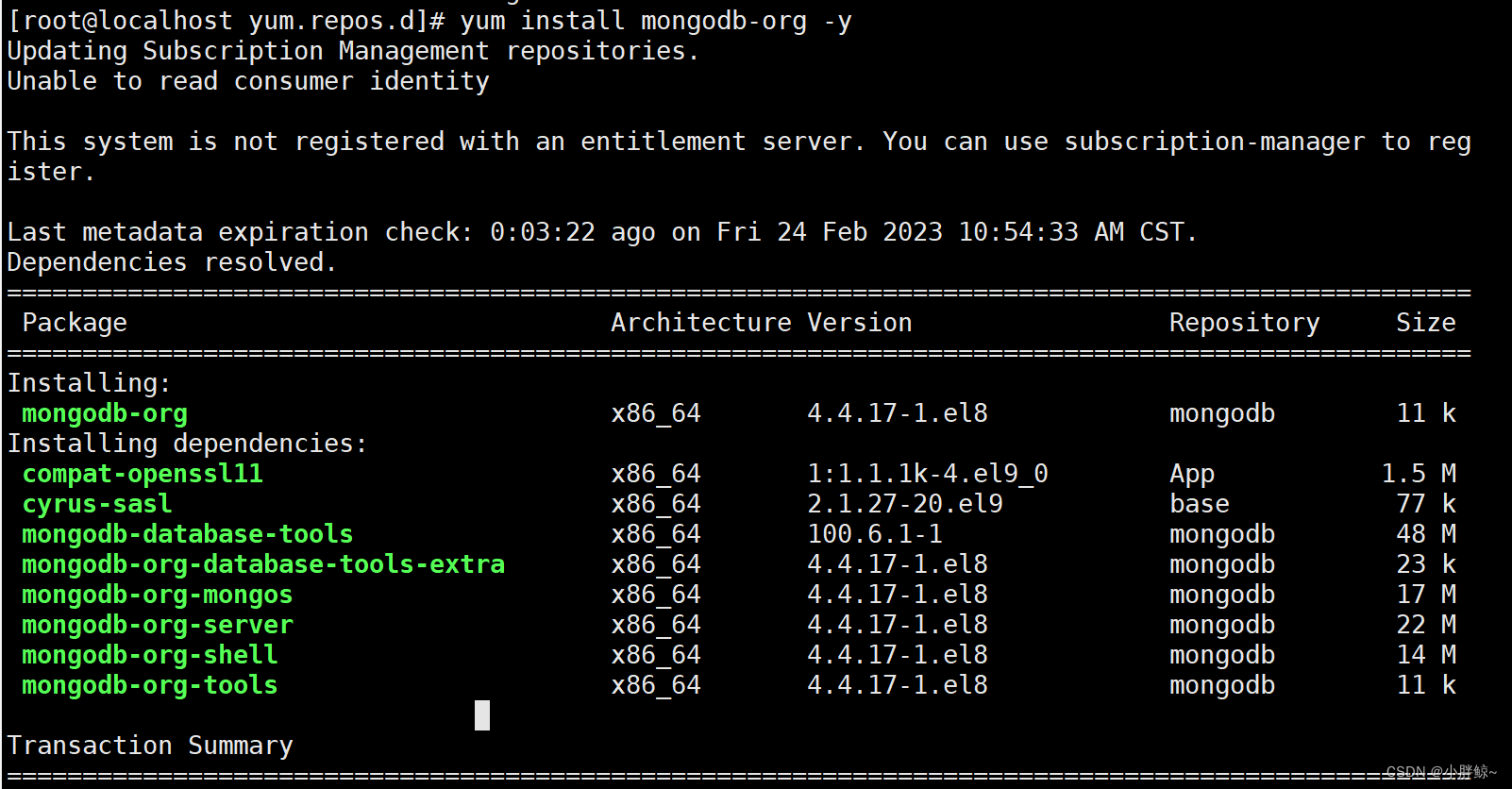
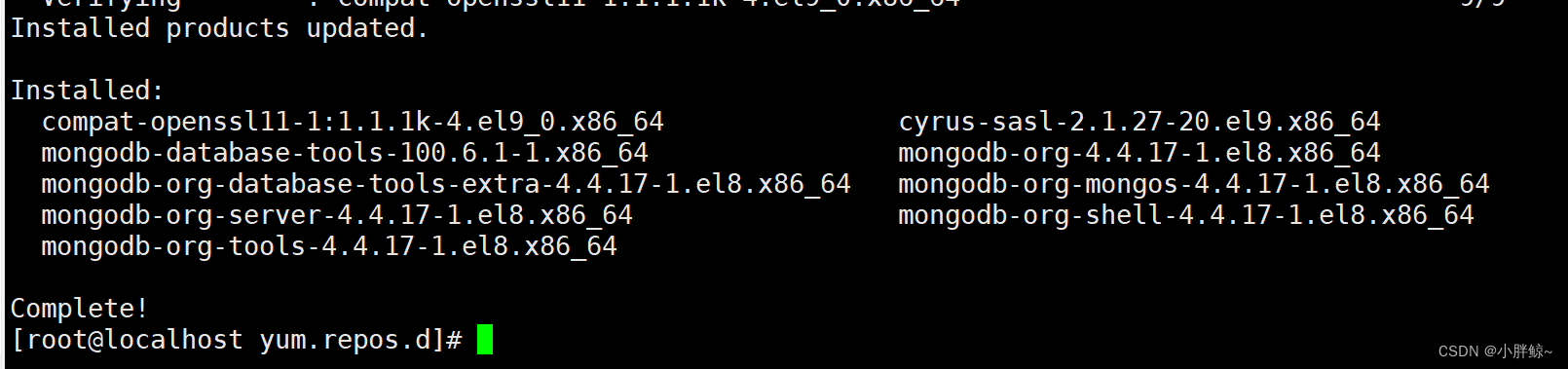
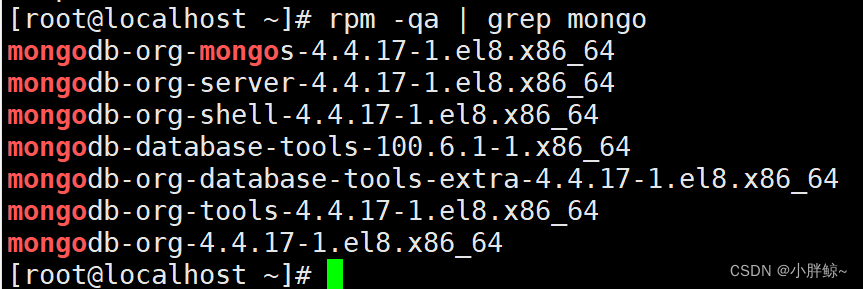
(3)查看安装的有关mongo的所有包
[root@localhost ~]# rpm -qa | grep mongomongodb-org-mongos-4.4.17-1.el8.x86_64 #mongos指令
mongodb-org-server-4.4.17-1.el8.x86_64 #包含mongod进程,相关初始化脚本和配置文件
mongodb-org-shell-4.4.17-1.el8.x86_64 #包含了mongo shell
mongodb-database-tools-100.6.1-1.x86_64 #包含MongoDB的工具: mongoimport, bsondump, mongodump, mongoexport, mongofiles, mongorestore, mongostat, mongotop。
mongodb-org-database-tools-extra-4.4.17-1.el8.x86_64 #包含install_compass脚本
mongodb-org-tools-4.4.17-1.el8.x86_64 #mongodb工具元数据包
mongodb-org-4.4.17-1.el8.x86_64 #元数据包,安装这个包会自动安装上面的包
2,启动
(1)启动mongo服务
[root@localhost yum.repos.d]# systemctl start mongod
(2)设置开机自启
[root@localhost yum.repos.d]# systemctl enable mongod
(3)查看进程
[root@localhost yum.repos.d]# ps -ef | grep mongo
(4)查看端口号
只能自己访问自己127.0.0.1
[root@localhost yum.repos.d]# ss -lntup | grep mongo
(5)关闭mongodb服务
[root@mysql8-0-30 ~]# systemctl stop mongod
(6)设置mongo shell的提示符
[root@mysql8-0-30 ~]# cat .mongorc.js
prompt = function() {
return db + ">";
}
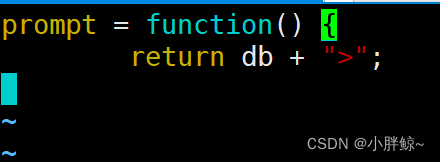
此时登录数据库,默认使用的数据库为test数据库
3, 使用mongo shell连接
语法:mongo --host 主机名 --port 端口号 [-u 用户名 -p 密码]
方法一:
[root@localhost yum.repos.d]# mongo --host 127.0.0.1 --port 27017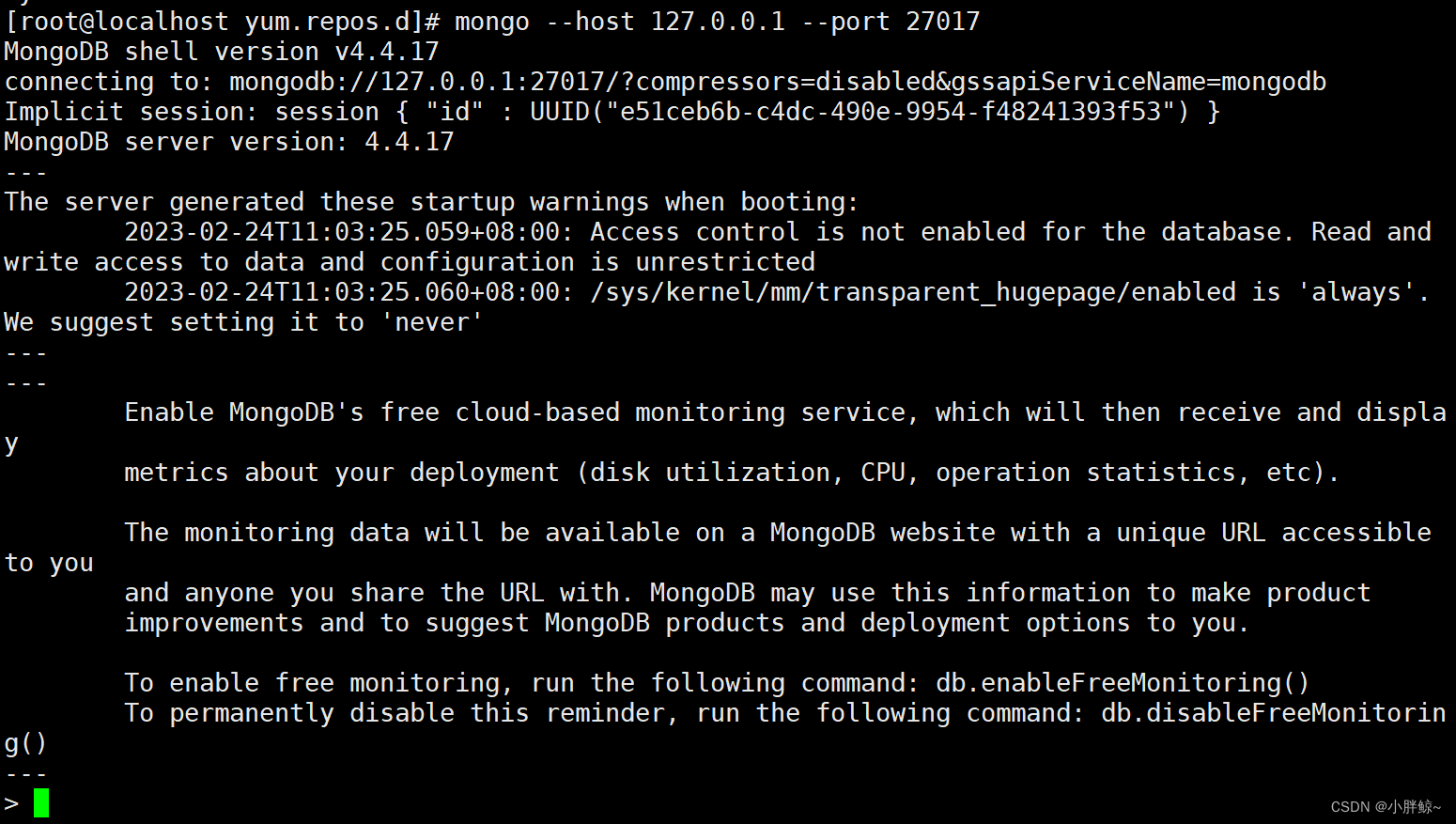
查看数据库
> show dbs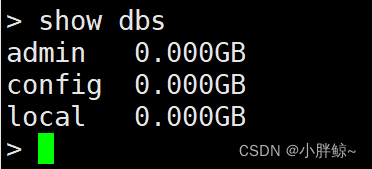
方法二:
[root@localhost yum.repos.d]# mongo
查看所有的数据库
> show databases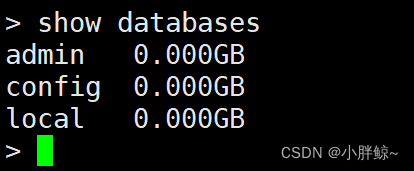
方法三:
[root@localhost ~]# mongo mongodb://127.0.0.1:27017/
查看所有的数据库
> show databases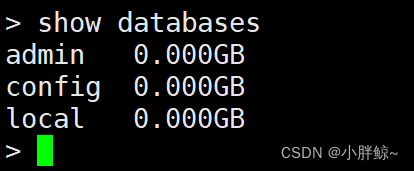
4,查看mongo的配置文件
[root@localhost ~]# vim /etc/mongod.conf
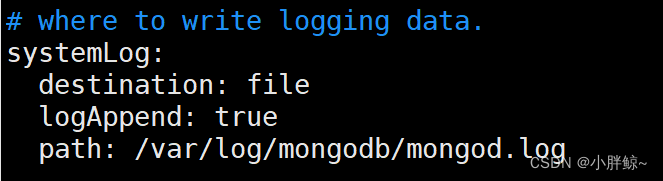
日志
# where to write logging data.
systemLog: 系统日志
destination: file #MongoDB发送所有日志输出的目标指定为文件
logAppend: true #当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加
到现有日志文件的末尾。
path: /var/log/mongodb/mongod.log #mongod或mongos所有诊断日志记录信息的日志文件路径
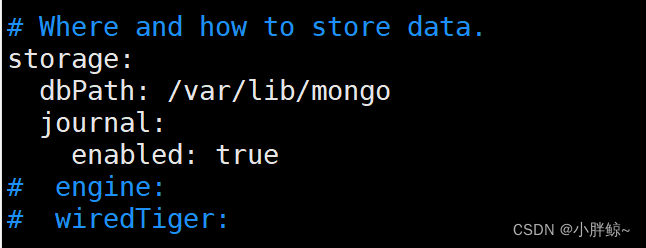
存储数据
# Where and how to store data.
storage: 存储
dbPath: /var/lib/mongo #mongod实例存储其数据的目录,storage.dbPath设置仅适用于mongod。
journal: 日志
enabled: true #启用持久性日志以确保数据文件保持有效和可恢复。
# engine:
# wiredTiger:
进程
# how the process runs
processManagement: 进程管理
fork: true #启用在后台运行mongos或mongod进程的守护进程模式。
pidFilePath: /var/run/mongodb/mongod.pid # location of pidfile pid路径
timeZoneInfo: /usr/share/zoneinfo

网络
此处把bindip改为0.0.0.0 方便后面客户端连接
# network interfaces
net:
port: 27017 #绑定的端口,默认是27017
bindIp: 0.0.0.0 # Enter 0.0.0.0,:: to bind to all IPv4 and IPv6 addresses or, alternatively, use the net.bindIpAll setting.

Mongodb的一些内建角色。
1.数据库用户角色:read、readWrite;
2.数据库管理角色:dbAdmin、dbOwner、userAdmin;
3.集群管理角色:clusterAdmin、clusterManager、clusterMonitor、hostManager;
4.备份恢复角色:backup、restore;
5.所有数据库角色:readAnyDatabase、readWriteAnyDatabase、userAdminAnyDatabase、dbAdminAnyDatabase
6.超级用户角色:root
7.系统角色:__system
5, 使用MongoDB Compass连接
可以在官网下载: https://downloads.mongodb.com/compass/mongodb-compass-1.35.0-win32-x64.exe
关闭防火墙
[root@localhost ~]# systemctl status firewalld 
直接打开下载好的exe文件连接mongodb数据库即可,连接成功后如图

五,基本操作
mongo shell里面支持使用帮助,也支持使用上下键查看命令历史
(1)查看帮助
> help1, 数据库操作
(1)查看数据库的帮助
> db.help()(2)使用数据库mytest
选择使用一个数据库,如果数据库不存在则会自动创建。
test>use mytest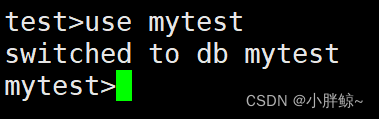
(3)查看所有的数据库,因为数据库mytest里面没有数据,所以不显示
mytest>show dbs
(4)删除数据库
先创建一个数据库mytest1
mytest>use mytest1
删除数据库mytest1
mytest1>db.dropDatabase()
(5)查看当前使用的数据库,MongoDB 中默认的数据库为 test,如果你没有选择数据库,集合将存放在 test 数据库中。
> db
test
> db.getName()
test
(6)查看当前库状态
> db.stats()数据库名可以是满足以下条件的任意UTF-8字符串。
- 不能是空字符串("")。
- 不得含有' '(空格)、.、$、/、\和\0 (空字符)。
- 应全部小写。
- 最多64字节。
有一些数据库名是保留的,可以直接访问这些有特殊作用的数据库。
- admin: 从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
- local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
- config: 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
2,集合操作
Collection,集合,类似关系型数据库中的表。可以显示的创建,也可以隐式的创建(当向一个集合中插入一个文档的时候,如果集合不存在,则会自动创建集合 )。
语法:db.createCollection(name, {capped: <Boolean>, autoIndexId: <Boolean>, size:<number>, max:<number>} )
说明:
(1)name表示要创建的集合名称,集合的命名规范:
- 集合名不能是空字符串""。
- 集合名不能含有\0字符(空字符),这个字符表示集合名的结尾。
- 集合名不能以"system."开头,这是为系统集合保留的前缀。
- 用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非你要访问这种系统创建的集合,否则千万不要在名字里出现$。
(2)capped:(可选,默认不启用)如果为true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。当该值为true时,必须指定size参数。
(3)size:(可选,默认为没有限制)限制集合使用空间的大小,即字节数,size的优先级比max要高。如果capped为true,也需要指定该字段。
(4)max:(可选,默认为没有限制)指定固定集合中包含文档的最大数量。 (5)autoIndexId:(可选,默认使用_id作为索引)是否使用_id作为索引,值为true或false。
(1)在数据库mytest下面创建一个集合books
mytest>db.createCollection("books")
(2)此时查看所有数据库,发现数据库mytest已经创建成功
mytest>show dbs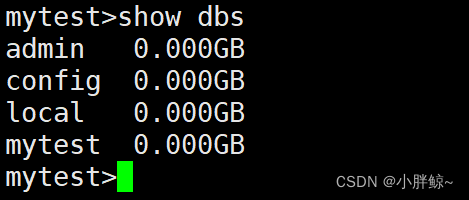
重载数据库,mytest在图形化界面也创建成功

(3)再次在数据库mytest中创建一个集合account
mytest>db.createCollection("account")
(4)创建固定集合student,整个集合空间大小 6142800 KB, 文档最大个数为10000 个
mytest>db.createCollection("student",{capped:true,autoIndexId:true,size:6142800,max:10000})
(5)查看当前库中的表
mytest> show tables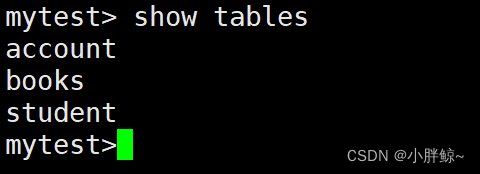
(6)查看当前数据库中的所有的集合
命令一:
mytest>show collections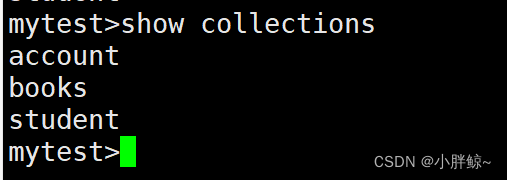
命令二:
mytest> db.getCollectionNames()
(7)查看指定的集合
mytest>db.getCollection("books")
(8)删除books集合,成功删除返回true,否则返回false
mytest>db.books.drop()
查看删除books集合后的所有集合
(9)获得当前的集合所在的DB,若没有集合,返回当前库的集合
mytest>db.books.getDB()
(10)查看当前集合的状态
> db.account.stats()(11)查询当前集合的数据条数
mytest> db.account.count()
(12)查询当前集合数据空间大小
mytest>db.account.dataSize()
(13)查询当前集合总大小
mytest>db.account.totalSize()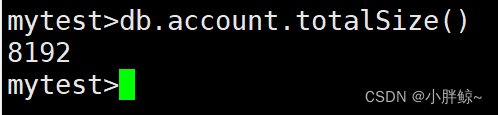
(14)集合重命名
mytest>db.account.renameCollection("ACCOUNT")
(15)查看集合的帮助
> db.account.help()
3, 文档基本CRUD
文档(document)的数据结构和 JSON 基本一样。 所有存储在集合中的数据都是 BSON 格式。
1、插入文档
test> use mytest
switched to db mytest
mytest> show collections
ACCOUNT
mytest>
插入单条文档,返回WriteResult({ "nInserted" : 1 })表示插入成功
mytest>db.ACCOUNT.insert({id:201,name:"zhangsan",gender:"M",age:18})
mytest>show tables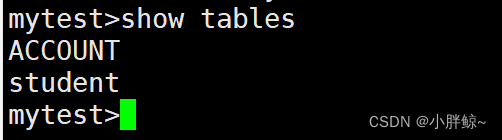
(2)隐式创建集合account,(如果集合不存在,那么在插入文档时,会自动创建集合)
mytest>db.account.insert({id:100,name:"xiaoming",gender:"M",age:18})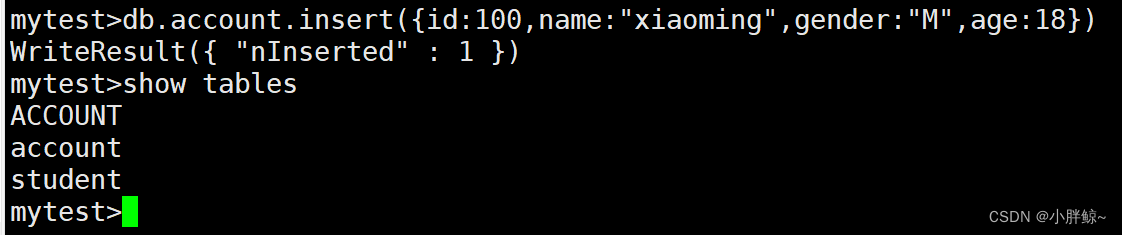
(3)继续向account集合中插入数据
mytest>db.account.insert({id:100,name:"xiaohong",gender:"F",age:18,"current date":new Date("2023-02-23")})
(4)先创建变量,再在集合中插入
创建变量document
mytest>document=({title:"mongodb",
... tags:['mongodb','database','nosql']})
把变量doucument插入到集合message中
mytest>db.message.insert(document)

注意:
(1)comment集合如果不存在,则会隐式创建。
(2)文档键命名规范:
1)键不能含有\0 (空字符)。这个字符用来表示键的结尾。
2).和$有特别的意义,只有在特定环境下才能使用。
3)以下划线"_"开头的键是保留的(不是严格要求的)。
(3)文档中的键/值对是有序的;MongoDB的文档不能有重复的键;文档的键是字符串,除了少数例外情况,键可以使用任意UTF-8字符。
(4)插入的数据没有指定 _id ,会自动生成主键值。
(5)文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。
1)mongo中的数字,默认情况下是double类型,如果要存整型,必须使用函数NumberInt(整型数字),否则取出来就有问题了。
2)插入当前日期使用 new Date()。
3)如果某字段没值,可以赋值为null,或不写该字段。
(6)MongoDB区分类型和大小写。
(5)插入多条数据
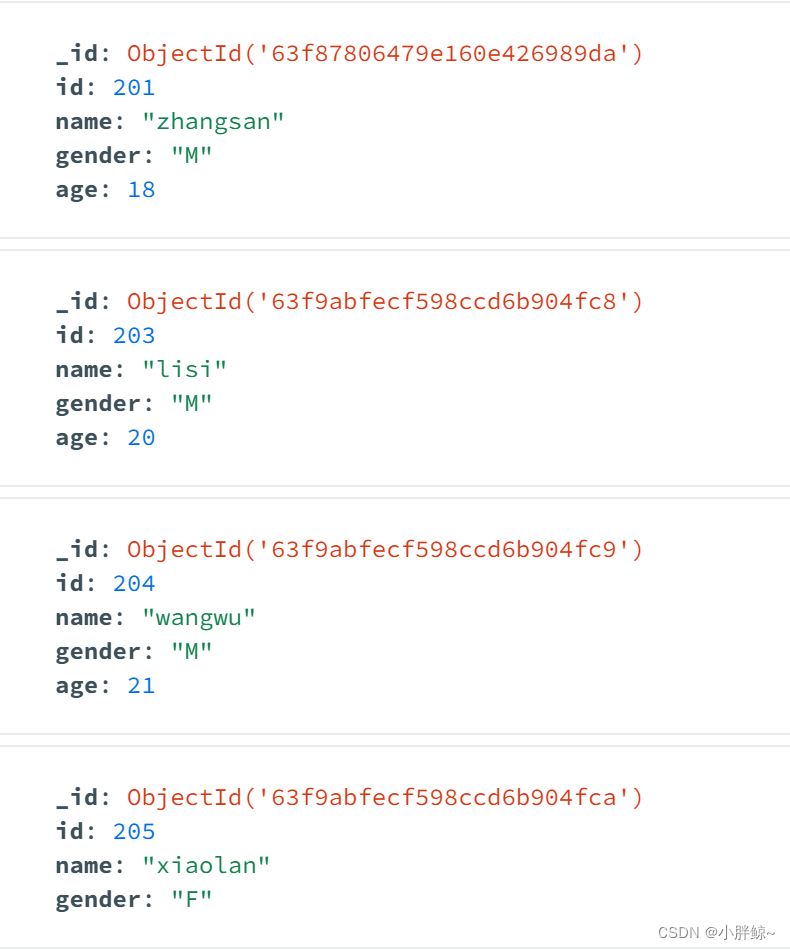
mytest>db.ACCOUNT.insertMany(
... [{id:203,name:"lisi",gender:"M",age:20},
... {id:204,name:"wangwu",gender:'M',age:21},
... {id:205,name:"xiaolan",gender:'F'}])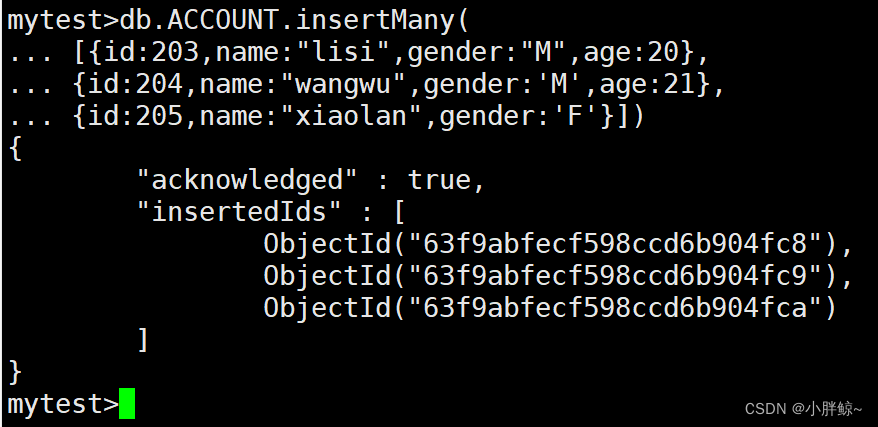
2、文档的基本查询
(1)查询集合ACCOUNT中的所有数据
方式1
mytest>db.ACCOUNT.find()
方式2
mytest>db.ACCOUNT.find({})
注:这里你会发现每条文档会有一个叫_id的字段,这个相当于我们原来关系数据库中表的主键,当你在插入文档记录时没有指定该字段,MongoDB会自动创建,其类型是ObjectID类型。
如果我们在插入文档记录时指定该字段也可以,其类型可以是ObjectID类型,也可以是MongoDB支持的任意类型。
方式3
更方便观看的展示
mytest>db.ACCOUNT.find().pretty()
mytest>db.ACCOUNT.find({}).pretty()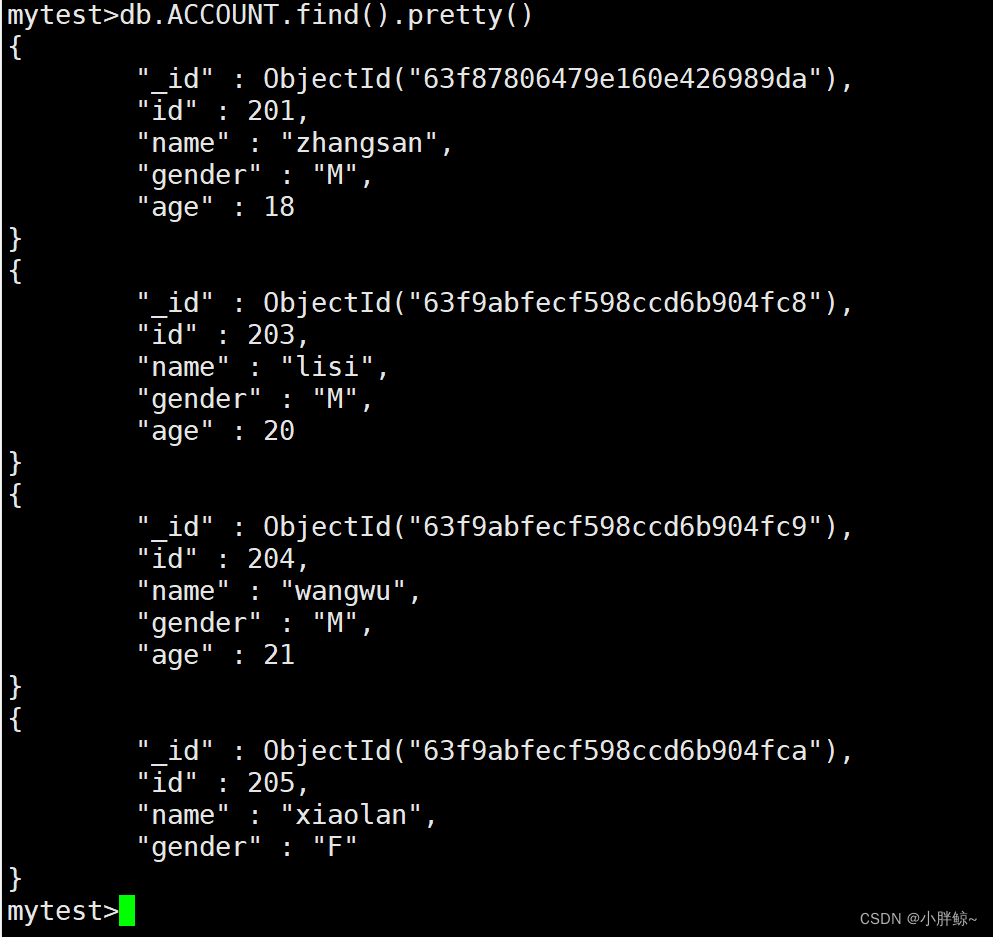
(4)以好看的方式查找名字叫zhangsan的记录
mytest>db.ACCOUNT.find({name:'zhangsan'}).pretty()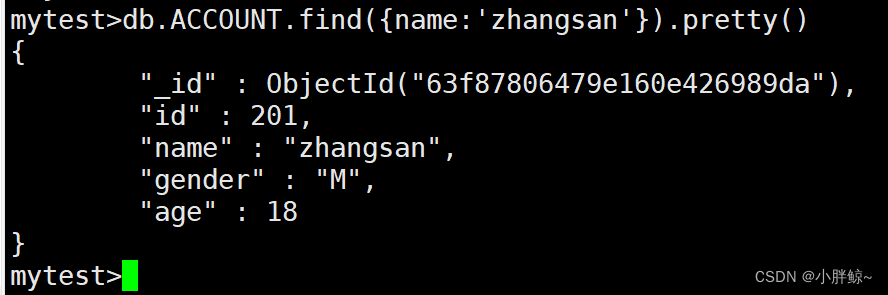
(5)只返回符合条件的第一条数据
mytest>db.ACCOUNT.findOne({gender:'M'})
(6)显示所有记录,但只显示_id、id和name,默认情况会显示_id
mytest> db.ACCOUNT.find({},{id:1,name:1})
第一个{}表示显示所有记录,第二个{}表示要查询的字段,
mytest>db.ACCOUNT.find({},{id:1,name:1})
—id等于0,表示不显示—id
mytest>db.ACCOUNT.find({},{_id:0,id:1,name:1})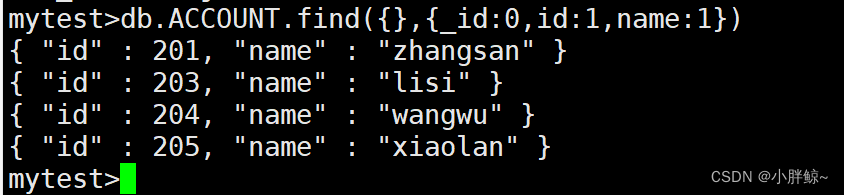
(7)显示id为201的记录的_id、id和name
第一个{}内写查询的条件,第二个{}内写查询的属性
mytest> db.ACCOUNT.find({id:201},{id:1,name:1})
(8)范围条件查询,$gt $lt $gte $lte 表示大于、小于、大于等于、小于等于,$ne不等于
查找ACCOUNT中age小于20的
mytest>db.ACCOUNT.find({age:{$lt:20}})
查找ACCOUNT中age大于等于18,小于等于21的所有信息
mytest>db.ACCOUNT.find({age:{$gte:18,$lte:21}}).pretty()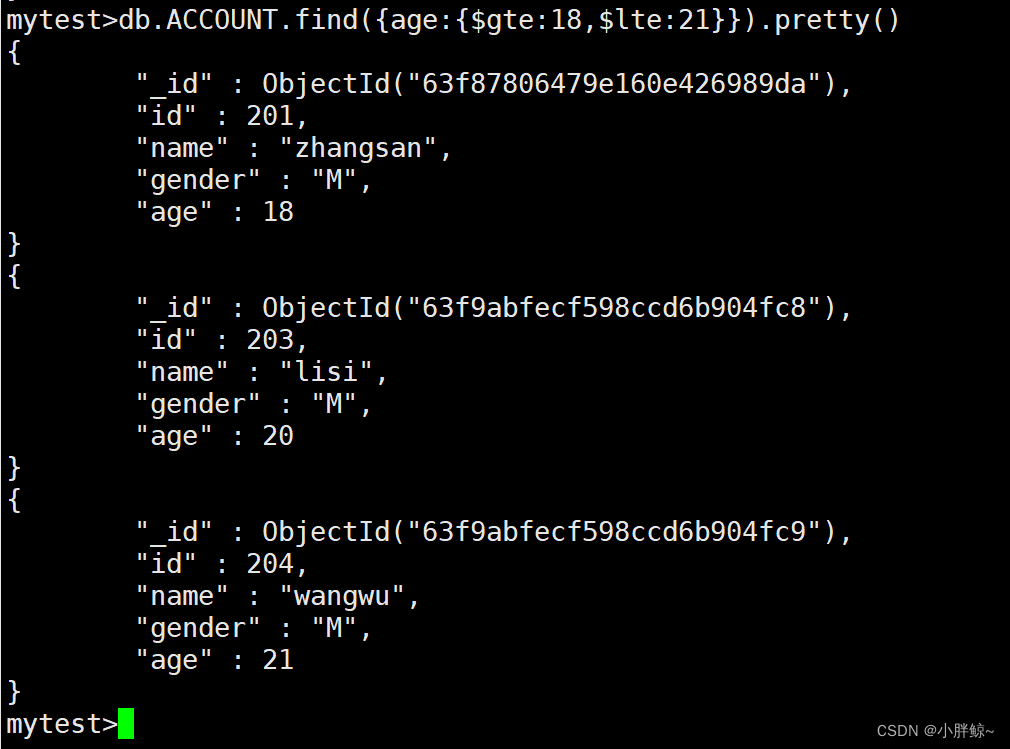
(9)查询相应字段的值是$in后面的任意值;$nin不包含操作
查找ACCOUNT中age的值是18,20,21的所有信息
mytest>db.account.find({age:{$in:[18,20,21]}}).pretty()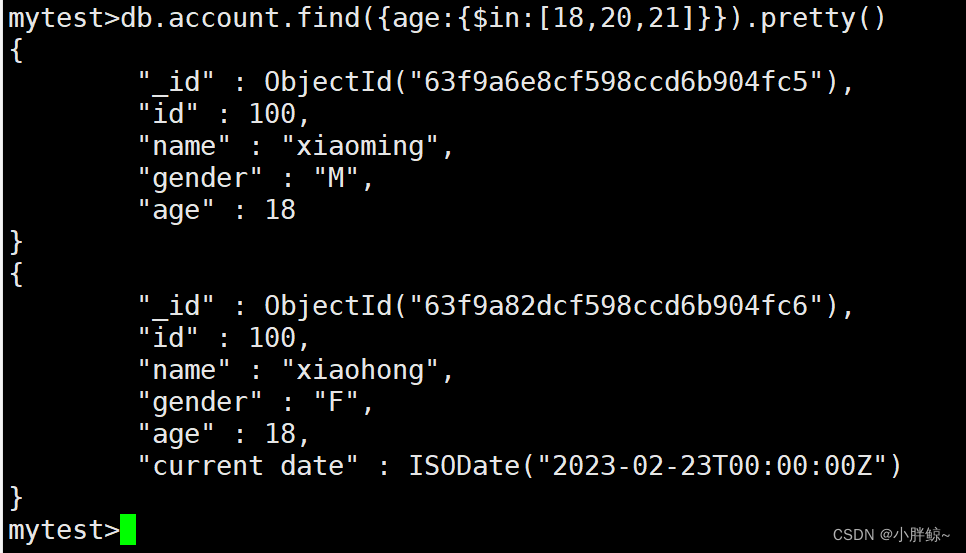
(10)使用正则表达式查询
查找ACCOUNT中姓张的
mytest> db.ACCOUNT.find({name:/^z/})
(11)排序显示,升序显示
mytest>db.ACCOUNT.find().sort({age:1}).pretty()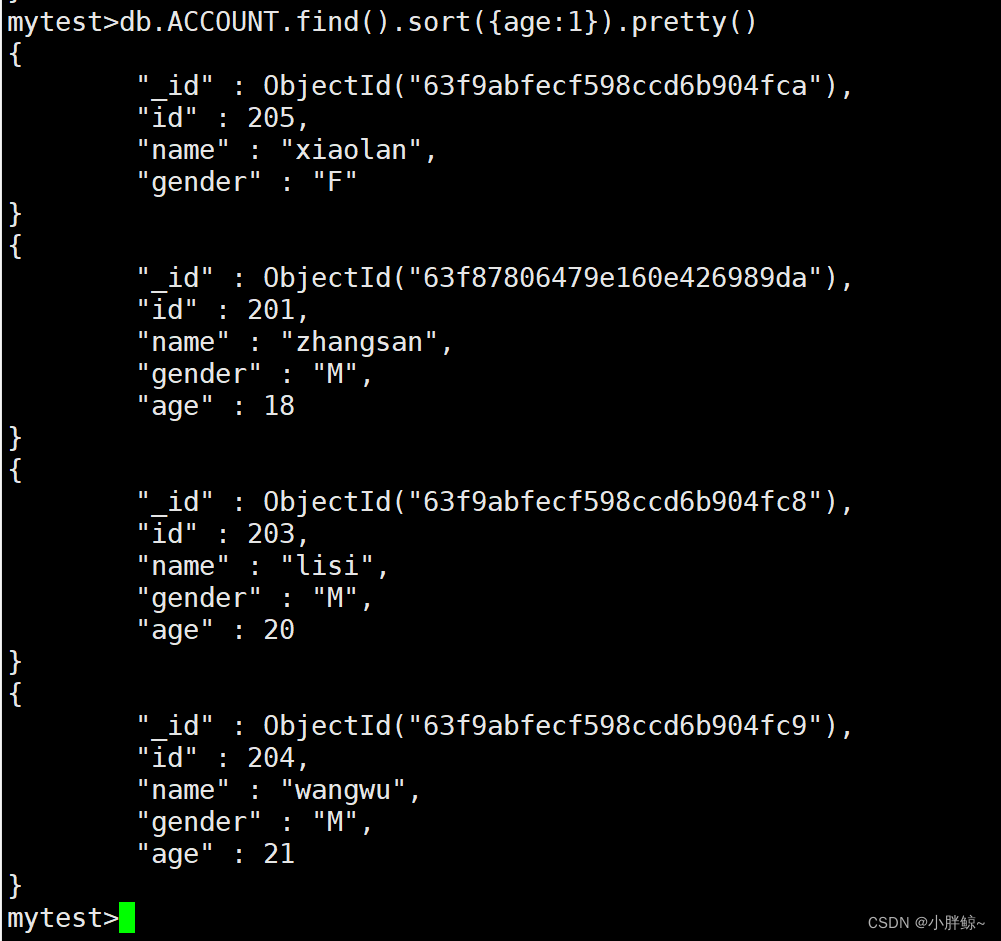
(12)排序显示,降序显示
mytest>db.ACCOUNT.find().sort({age:-1}).pretty()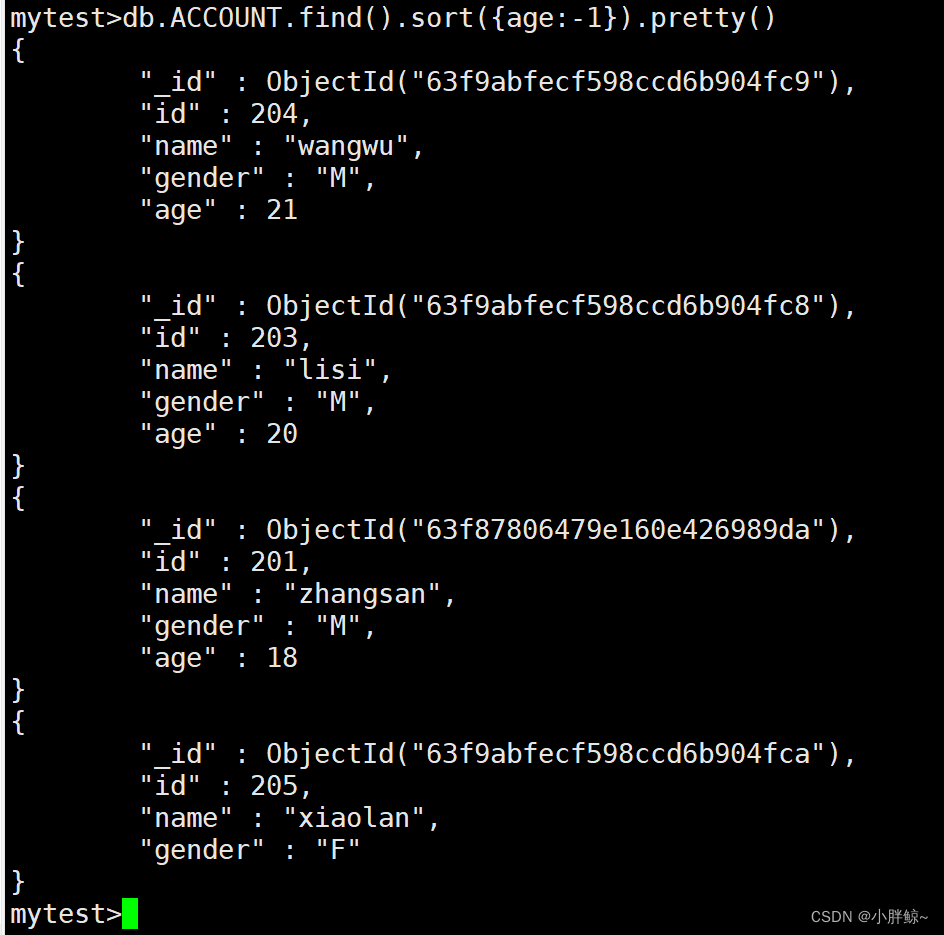
(13)查询前3条数据
mytest>db.ACCOUNT.find().limit(3).pretty()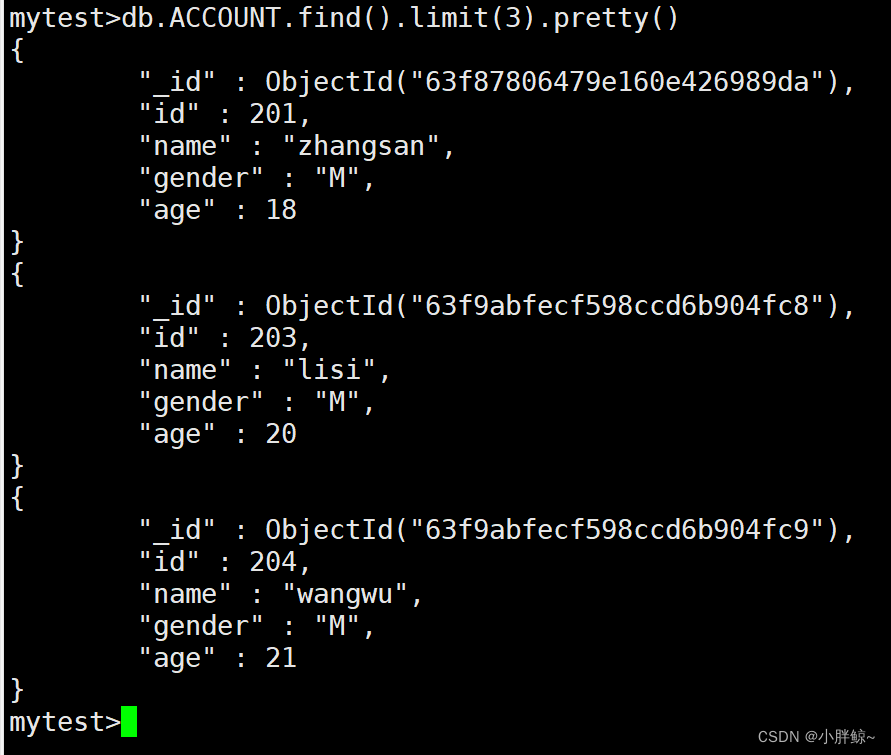
(14)查询2条以后的数据,也就是第3,4条数据
mytest>db.ACCOUNT.find().skip(2).pretty()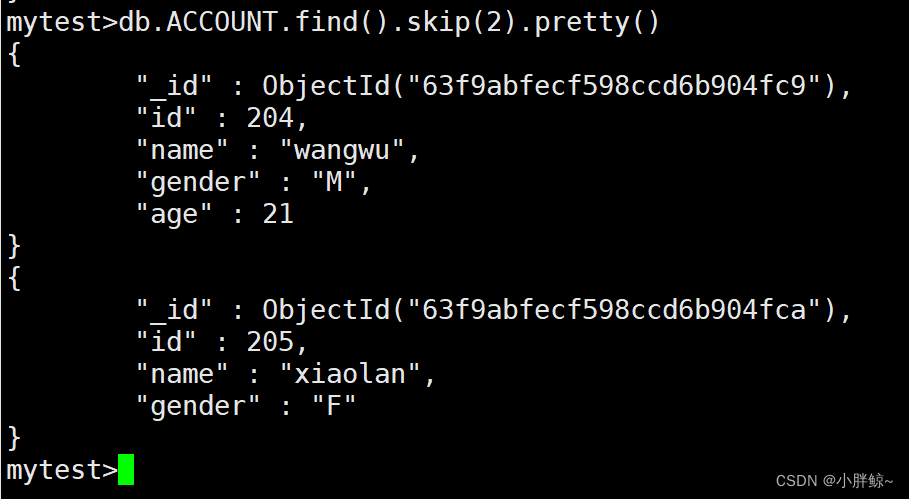
(15)查询2-3之间的数据,1之后的所有数据的前两行
mytest>db.ACCOUNT.find().skip(1).limit(2).pretty()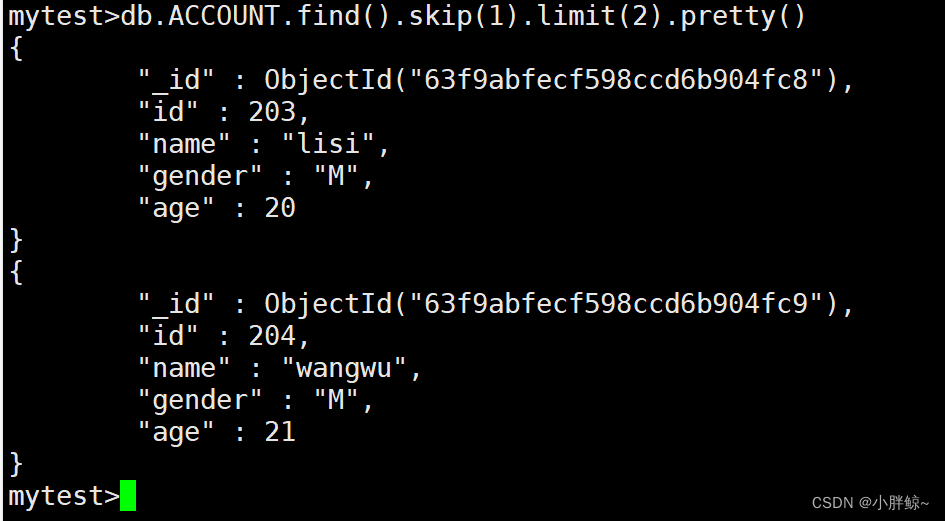
(16)$exists判断字段是否存在
查看含有age字段的所有信息
mytest>db.ACCOUNT.find({age:{$exists:true}})
(17)db.表.find({字段(数组):{ ‘$all’ :[v1,v2]}}) //数组元素值,存在v1和v2即可,顺序不做要求
> db.student.find({hobdy:{$all:['dance','sing']}})3、文档的更新
此时,ACCOUNT下的所有记录入如下显示:
mytest>db.ACCOUNT.find().pretty()
(1)把id=201的改为ID=100,修改完成后除了id字段其它字段都不见了,默认只修改第一条记录
把id=201的改为ID=100
mytest>db.ACCOUNT.update({id:201},{id:100})
(2)使用修改器$set修改,只修改想要修改的字段,其他字段不变。
把id=204改为id=402,并保证其它字段不变
mytest>db.ACCOUNT.update({id:204},{$set:{id:402}})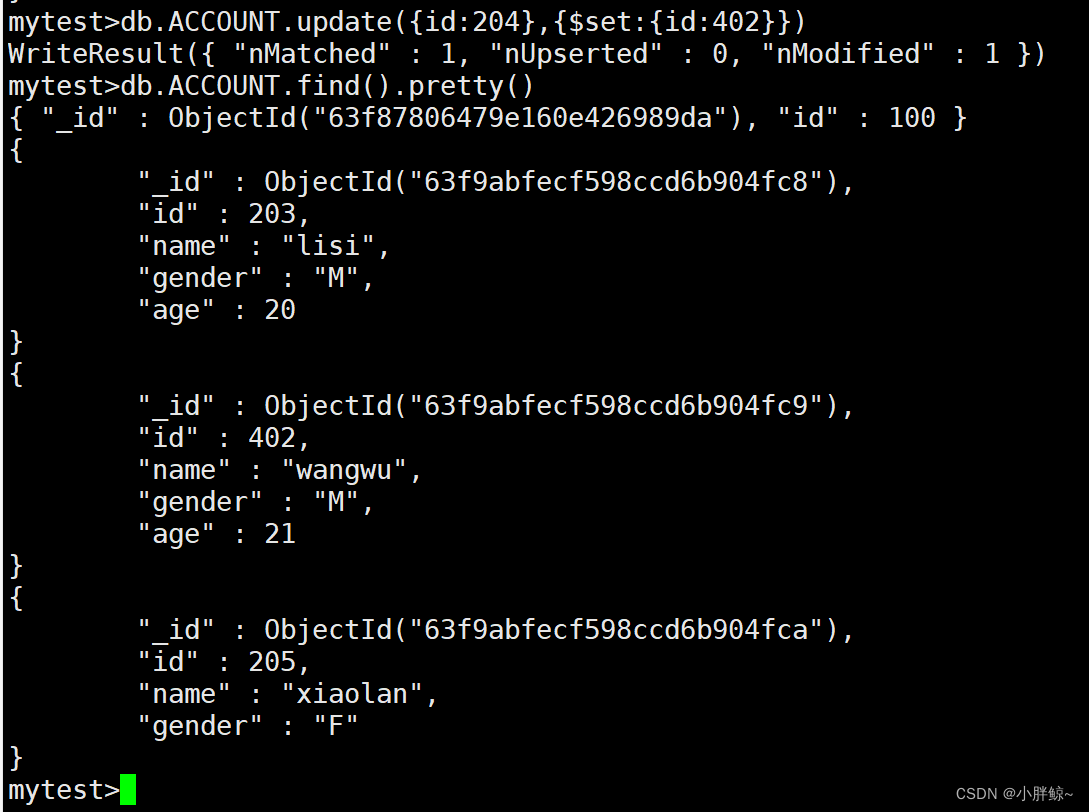
(3)使用修改器$set修改,只修改想要修改的字段,其他字段不变。如果多条记录都匹配默认只修改第一条记录
把gender='M'的id改为403,默认修改匹配到的第一条记录
mytest>db.ACCOUNT.update({gender:'M'},{$set:{id:403}})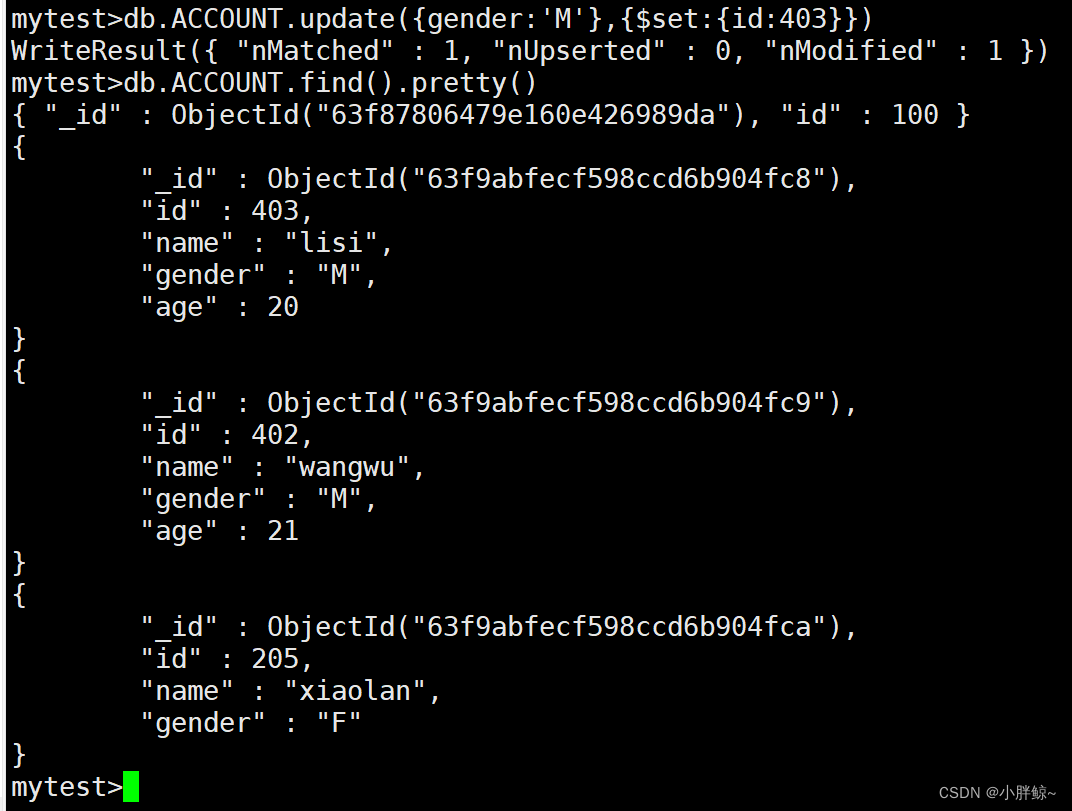
(4)修改所有的记录
把性别为M的年龄都改为23
mytest>db.ACCOUNT.update({gender:'M'},{$set:{age:23}},{multi:true})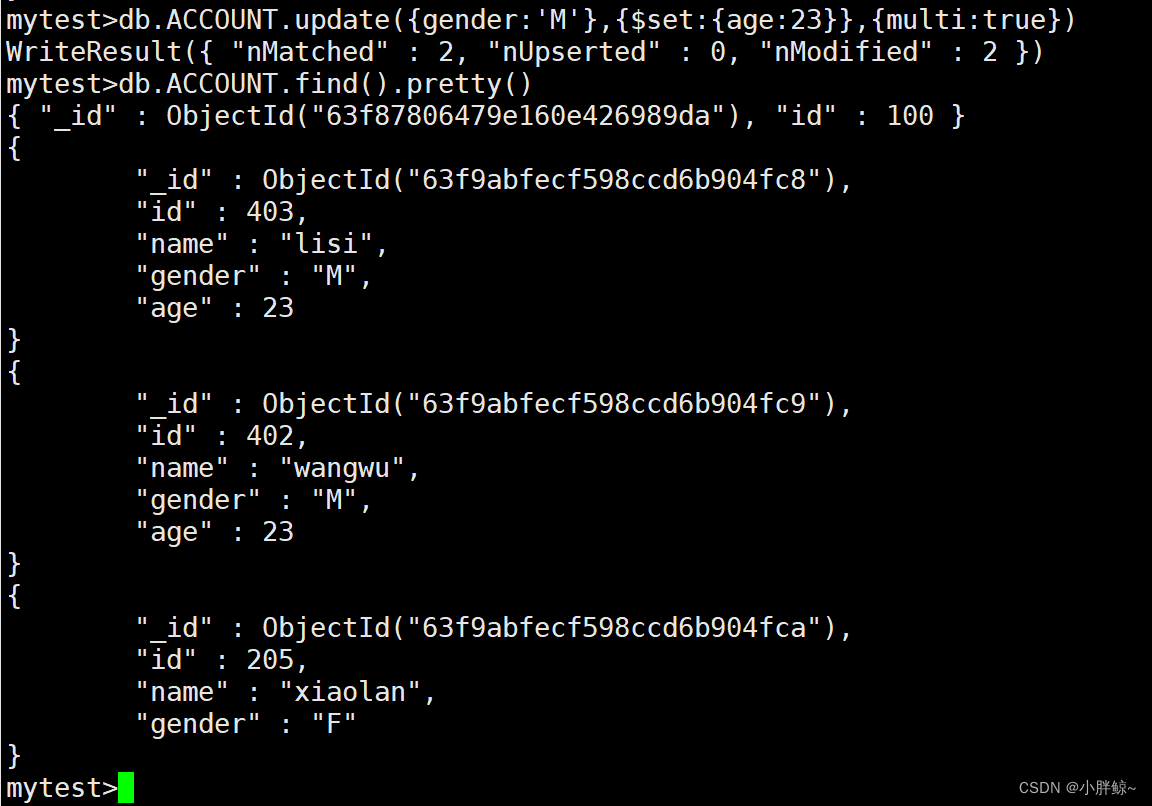
(5)列值增长的修改
#设置id为403的记录的age每次增长1,默认也只修改第一条记录,使用{multi:true}修改所有记录
mytest> db.ACCOUNT.update({id:403},{$inc:{age:1}})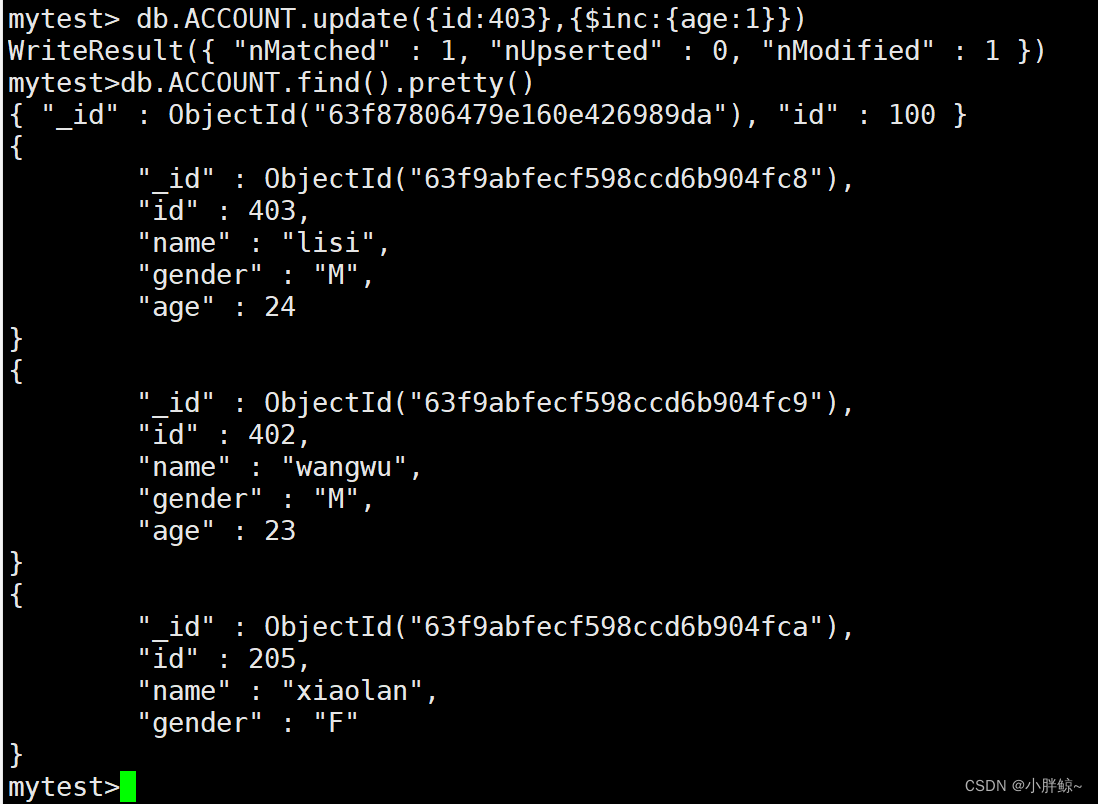
(6)update找到才会更新,找不到不管
使用save方法来替换已有的文档,有相应_id主键的记录就更新,没有就插入
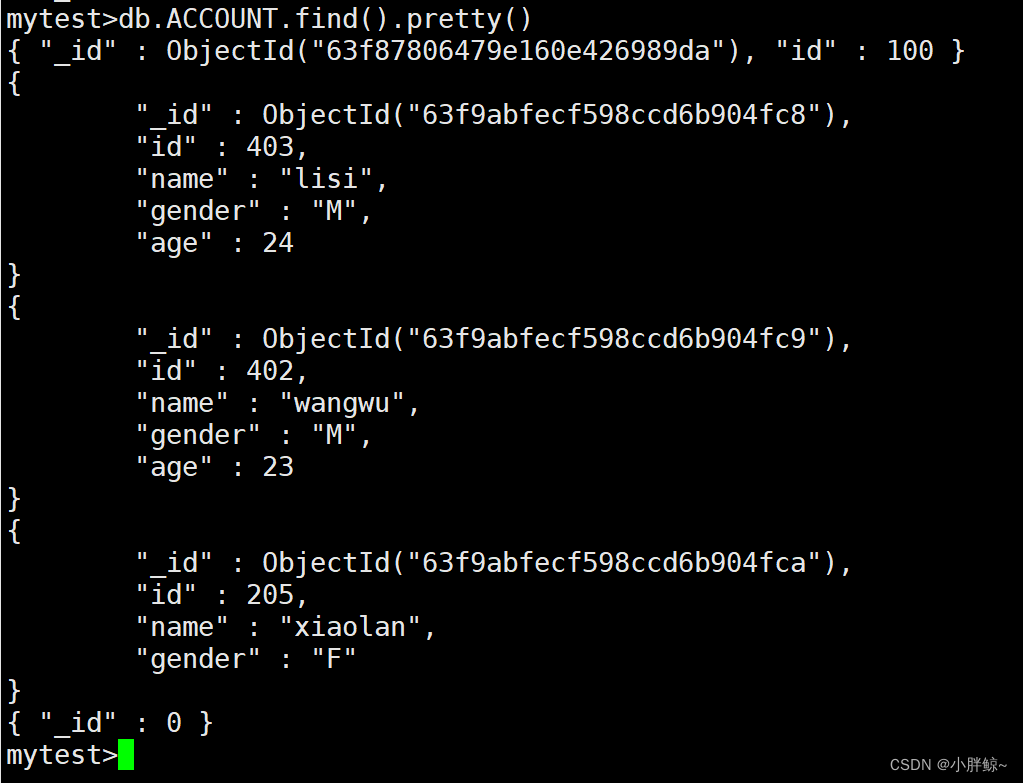
将age设为30;没指定—id,则插入一条新的记录
mytest>db.ACCOUNT.save({age:30})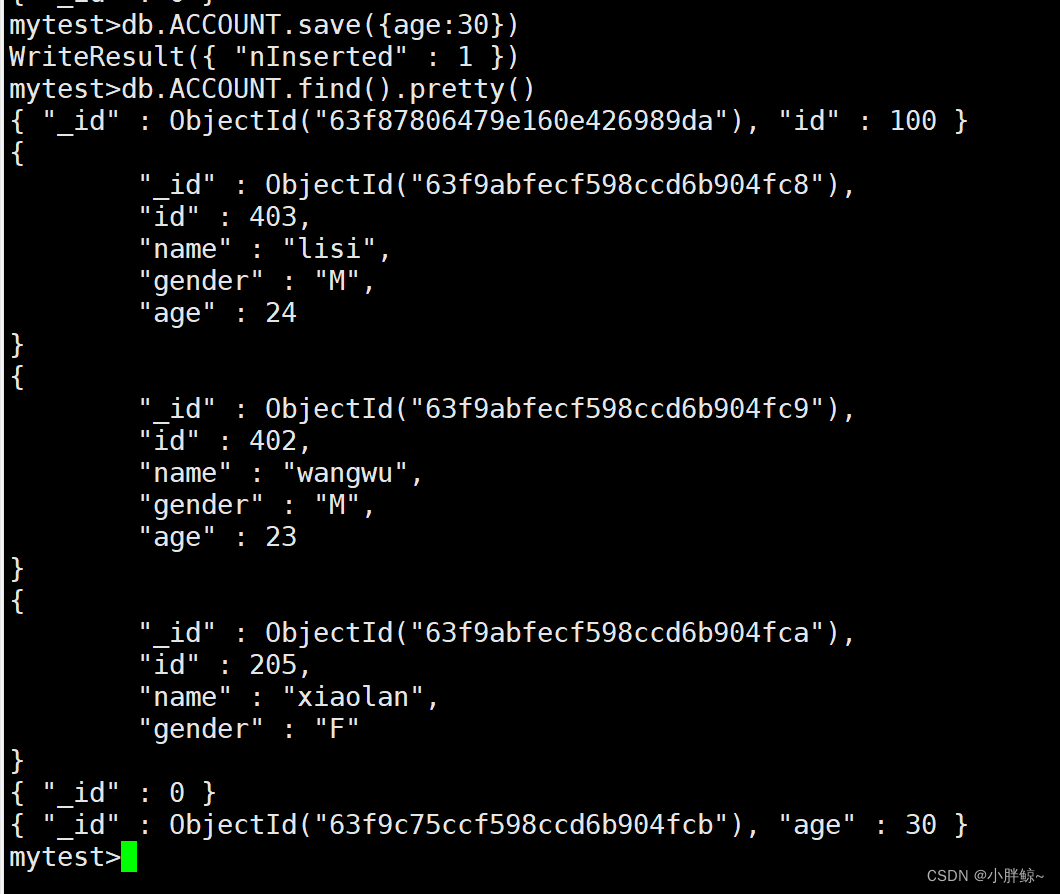
将age设为30;指定—id=0,则更新_id=0的age为30
mytest>db.ACCOUNT.save({_id:0,age:30})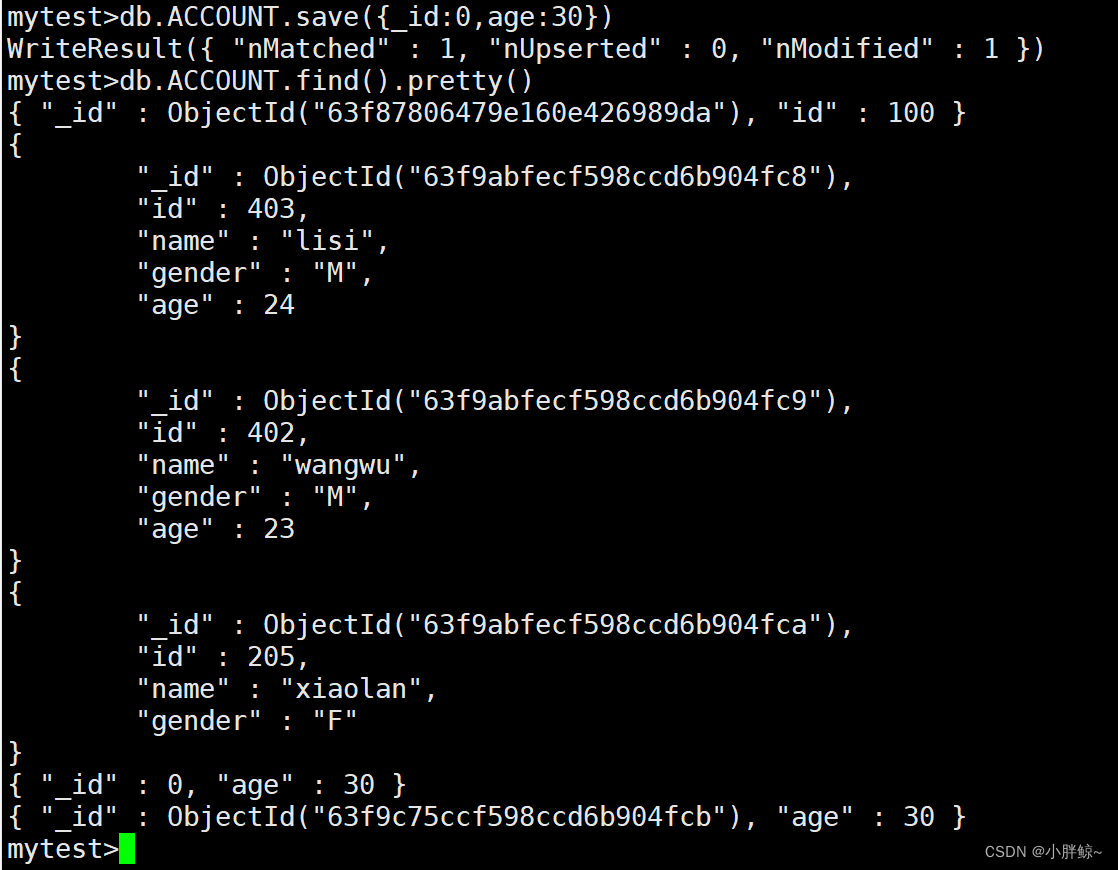
4、删除文档
删除age=30的所有记录,删除后,其它记录还在
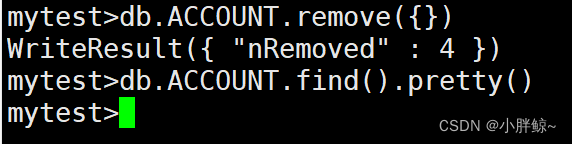
mytest>db.ACCOUNT.remove({age:30})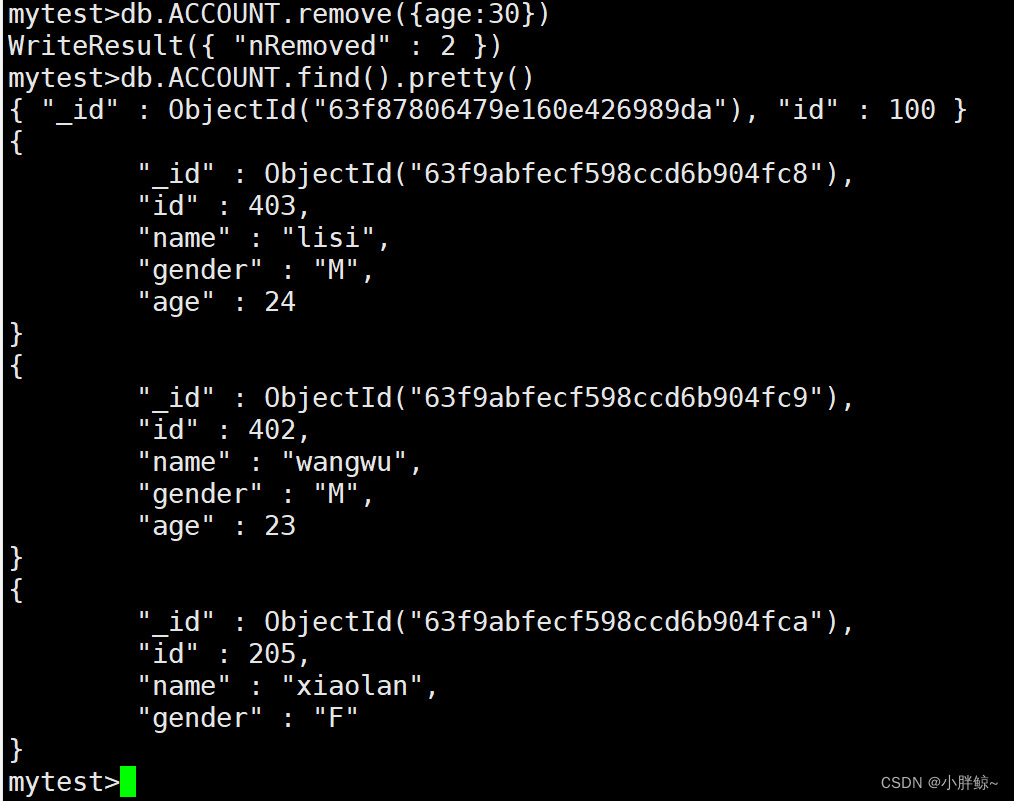
删除此集合下的所有记录,删除后,集合变为空的
mytest>db.ACCOUNT.remove({})