文章目录
一、Redis实践
1.Redis的网页缓存
1.1创建一个springboot项目
-
创建时需要选择依赖,Lombok,Spring Web,SpringDataReactiveRedis,SpringDataJPA,MySQLDriver
-
将Editor下的FileEncoding全部设置为UTF-8。
-
配置resources下的配置文件application.properties,此时数据库用的是本机的,redis服务用的是虚拟机的。配置如下:
######################################################## ### 配置连接池数据库访问配置 ######################################################## spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.datasource.url=jdbc:mysql:///test?characterEncoding=utf-8&&useSSL=false spring.datasource.username=root spring.datasource.password=root ######################################################## ### Java Persistence Api --y ######################################################## # Specify the DBMS spring.jpa.database = MYSQL # Show or not log for each sql query spring.jpa.show-sql = true # Hibernate ddl auto (create, create-drop, update) spring.jpa.hibernate.ddl-auto = update # Naming strategy #[org.hibernate.cfg.ImprovedNamingStrategy #org.hibernate.cfg.DefaultNamingStrategy] spring.jpa.hibernate.naming-strategy = org.hibernate.cfg.ImprovedNamingStrategy # stripped before adding them to the entity manager) spring.jpa.properties.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect ######################################################## ### 配置连接池数据库访问配置 ######################################################## #Redis服务器连接地址 spring.redis.host=192.168.126.12 #Redis服务器连接端口 spring.redis.port=6379 #连接池最大连接数(使用负值表示没有限制) spring.redis.pool.max-active=8 #连接池最大阻塞等待时间(使用负值表示没有限制) spring.redis.pool.max-wait=-1 #连接池中的最大空闲连接 spring.redis.pool.max-idle=8 #连接池中的最小空闲连接 spring.redis.pool.min-idle=0 #连接超时时间(毫秒) spring.redis.timeout=30000 logging.pattern.console=%d{MM/dd HH:mm:ss.SSS} %clr(%-5level) --- [%-15thread] %cyan(%-50logger{50}):%msg%n -
创建实体类包entity,在包中创建一个类GoodsEntity。代码:
/** * 商品数据模型 */ @Data @Entity @Table(name="goods") public class GoodsEntity { //自增ID @Id @GeneratedValue(strategy= GenerationType.IDENTITY)//自增 private Long id; // 商品名字 private String goodsName; // 订单id private String orderId; // 商品数量 private Integer goodsNum; // 商品价格 private Double price; } -
创建一个service包,在包中创建GoodsService类
/** * 商品业务层 */ @Service @Repository public class GoodsService{ @Autowired private GoodsRepository goodsRepository; @Autowired private StringRedisTemplate stringRedisTemplate; /** * 根据id查询商品信息 * @param id * @return */ public GoodsEntity getById(Long id) { //查询缓存 String goodsString = stringRedisTemplate.opsForValue().get("goods:"+id); //判断有没有缓存 if(StringUtils.isEmpty(goodsString)) { //从数据库中查询商品信息 Optional<GoodsEntity> optionalGoodsEntity = goodsRepository.findById(id); if(optionalGoodsEntity.isPresent()) { GoodsEntity goodsEntity = optionalGoodsEntity.get(); //把对象转换成Json字符串 String s = JSON.toJSONString(goodsEntity); //添加缓存 stringRedisTemplate.opsForValue().set("goods:"+id,s); return goodsEntity; } }else { //字符串转对象 GoodsEntity goodsEntity = JSON.parseObject(goodsString, GoodsEntity.class); return goodsEntity; } return null; } } -
创建一个repository包,在包中创建GoodsRepository接口
/** * 商品持久层 */ public interface GoodsRepository extends JpaRepository<GoodsEntity,Long> { } -
创建一个controller包,在包中创建一个GoodsController类
@RestController @RequestMapping("/goods") public class GoodsController { //商品业务层 @Autowired private GoodsService goodsService; /** * 根据id查询商品信息 * @return */ @RequestMapping("/getById") public GoodsEntity getById(String id) { return goodsService.getById(Long.valueOf(id)); } }
1.2使用redis缓存
-
通过spring容器注入StringRedisTemplate;
-
在业务层访问数据库时,查看redis缓存,有则直接返回;没有则访问数据库,将数据缓存进redis并返回,下次可以直接从redis缓存获取。
-
需要将对象转换为json字符串缓存进redis,引入json依赖:
<dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>2.0.10</version> </dependency>
1.3压力测试
- jmeter压力测试:
参数选择:线程数1000,循环10次。
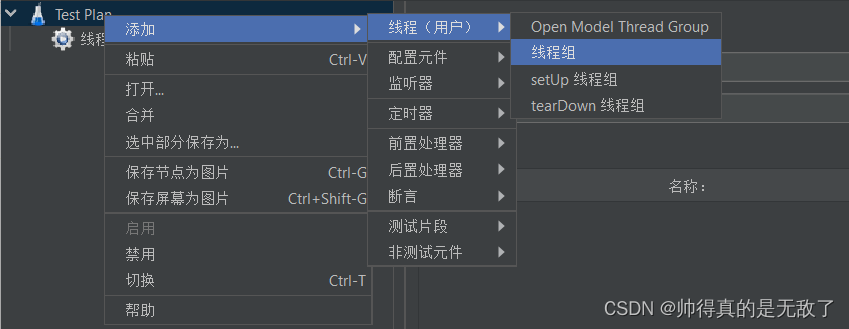
参数选择:协议HTTP,服务器ip为localhost,端口号8080,请求类型为get,路径为/goods/getById?id=1
没有加入Redis缓存时,是1400/s的吞吐量。
使用redis缓存时,是8600/s的吞吐量。
2.redis.conf配置文件
1.units单位,配置大小单位,开头定义基本度量单位,只支持bytes,大小写不敏感。
2.includes,redis只有一个配置文件,如果多人进行开发维护,那么就需要多个这样的配置文件。
3.network
- bind:绑定redis服务器网卡IP,默认为127.0.0.1,即本地回环地址。这样只有通过本机的服务端连接才能访问redis服务,而无法通过远程连接。如果bind选项为空的话,那就可以接受所有来自可用网络接口的连接。
- port:指定redis运行的端口,默认是6379。由于redis是单线程模型,因此单机开多个redis进程的时候会修改端口。
- timeout:设置客户端连接的超时时间,单位为秒。当客户端在这段时间内没有发出任何指令,那么关闭该连接。默认值为0,表示不关闭。
- tcp-keepalive:单位是秒,表示将周期性的使用SO_KEEPALIVE检测客户端是否还处在健康状态,避免服务器一直阻塞,官方建议300s,如果设置为0,则不会周期性检测。
4.general
- daemonize:设置为yes表示指定redis以守护进程的方式启动(后台启动)。默认值为no
- pidfile:配置PID文件路径,当redis作为守护进程运行时,它会把pid默认写到/var/run/redis_6379.pid文件里面
- loglevel:定义日志级别,默认值为notice,有4种取值
- debug,记录大量日志信息,适用于开发、测试阶段。
- verbose,较多日志信息
- notice,适量日志信息,适用于生产环境
- warning,仅有一部分重要、关键信息才会被记录
- logfile:配置log文件地址,默认打印在命令行终端的窗口上
- databases:设置数据库的数目。默认值是16,也就是说默认redis有16个数据库。
默认的数据库时DB 0,可以在每个连接上使用select命令选择一个不同的数据库,dbid是一个介于0到databases -1之间的数值。
5.snapshotting,这里的配置主要用来做持久化操作。
save:这里用来配置触发redis的持久化条件,也就是什么时候将内存中的数据保存到硬盘
save 900 1:表示900秒内如果至少有1个key的值发生变化,则保存
save 300 10:表示300秒内如果至少有10个key的值发生变化,则保存
save 60 10000:表示60秒内如果至少有10000个key的值发生变化,则保存
6.replication
- slave-serve-stale-data:默认值为yes。当一个slave与master失去联系,或者复制正在进行的时候,slave可能会有两种表现:
- 如果为yes,slave仍然会答应客户端请求,但返回的数据可能是过时的,或者在第一次同步时数据可能是空的
- 如果为no,在你执行了info he slaveof之外的其他命令时,slave都将返回一个"SYNC with master in progress"的错误。
- slave-read-only:配置Redis的slave实例是否接受写操作,即slave是否为只读redis,默认值为yes。
- repl-diskless-sync:主从数据复制是否使用无硬盘复制功能。默认值为no。
- repl-diskless-sync-delay:当启用无硬盘备份,服务器等待一段时间后才会通过套接字向 从站传送RDB文件,这个等待时间是可配置的。
- repl-disable-tcp-nodelay:同步之后是否禁用从站上的tcp-nodelay,如果选择yes,redis会使用较少量的TCP包和宽带向从站发送数据。
7.security
requirepass:设置redis连接密码。
8.clients
maxclients:设置客户端最大并发连接数,默认无限制,redis可以同时打开的客户端连接数为redis进程可以打开的最大文件。描述符数 -32(redis server自身会使用一些),如果设置maxclients为0,表示不作限制。当客户端连接数达到限制时,redis会关闭新的连接并向客户端返回max number of clients reached错误信息。
9.memory management
- maxmemory:设置redis的最大内存,如果设置为0,表示不作限制。通常配合maxmemory-policy一起使用。
- maxmemory-policy:当内存使用达到maxmemory设置的最大值时,redis使用内存清除策略。
- volatile-lru,利用LRU算法移除设置过过期时间的key(LRU:最近使用Least Recently Used)
- allkeys-lru,利用LRU算法移除任何key
- volatile-random,随机移除设置过过期时间的key
- allkeys-random,随机移除key
- volatile-ttl,移除即将过期的key
- noeviction,不移除任何key,只是返回一个写错误,默认选项
- maxmemory-samples:LRU和minimal TTL算法都不是精准的算法,但是相对精准的算法(为了节约内存)。可以随意选择样本大小进行检验,redis默认选择3个样本进行检测。
10.append only mode
- appendonly:默认值为no。redis默认使用的是rdb方式持久化,这种方式在许多应用中已经足够用了。但是redis如果中途宕机,会导致可能有几分钟的数据丢失,根据save策略来进行持久化,append only file是另一种持久化方式,可以提供更好的持久化特性。Redis会把每次写入的数据在接收后都写入appendonly.aof文件中,每次启动时,redis都会先把这个文件的数据读入内存里,先忽略RDB文件。
- appendfilename:aof文件名,默认是"appendonly.aof"
- appendfsync:aof持久化策略的配置;no表示不执行fsync,由操作系统保证数据同步到磁盘,速度最快;always表示每次写入都执行fsync,以保证数据同步到磁盘;everysec表示每秒执行一次fsync,可能会导致丢失这1s的数据。
11.LUA scripting
lua-time-limit:一个lua脚本执行的最大时间,单位为ms(毫秒)。默认值为5000。
12.redis cluster
cluster-enabled:集群开关,默认是不开启集群模式。
cluster-conif-file:集群配置文件的名称
cluster-node-timeout:可以设置值为15000。节点互联超时的阀值,集群节点超时毫秒数
cluster-slave-validity-factor:可以设置值为10。即从节点的有效数
3.redis其他功能
1.发布订阅
- redis发布订阅是(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
- redis发布订阅的命令行实现
- 订阅语法:
subscribe 主题名字 - 发布语法:
publish 主题名字 message
- 订阅语法:
直接双击终端链接,打开一个新的终端窗口,作为发布者即可测试。
2.慢查询
-
redis命令执行的过程:1.客户端发送命令到redis,2.redis将这些命令进行排队等待,3.执行命令,4.最后返回结果。
- 慢查询发生在第三步。
- 客户端超时不一定是慢查询,但慢查询是客户端超时的一个原因
- 慢查询日志是存放在redis内存列表中的。
-
慢查询日志是Redis服务端在执行命令前后计算每条命令的执行时长,当超过某个阈值时记录下来的日志。日志中记录了慢查询发生的时间,还有执行时长、具体什么命令等信息,它可以用来帮助开发或运维人员定位系统中存在的慢查询。
-
可以使用
slowlog get命令获取慢查询日志,在slowlog get后面还可以加上一个数字,用于指定获取慢查询日志的条数。 -
可以使用
slowlog len命令获取慢查询日志的长度。 -
需要在redis.conf中配置慢查询的参数
- 命令执行时长的指定阈值 slowlog-log-slower-than 1000
即执行命令的时长超过这个阈值就会被记录下来。(单位为微妙,此时为1ms) - 指定慢查询日志最多存储的条数 slowlog-max-len 1200
redis使用一个列表存放慢查询日志,slowlog-max-len就是这个列表的最大长度
- 命令执行时长的指定阈值 slowlog-log-slower-than 1000
-
也可以在redis客户端窗口使用
config set命令动态修改redis.conf内的参数- config set slowlog-log-slower-than 1000
- config set slowlog-max-len 1200
- config rewrite,即将config set修改的内容写入redis.conf配置中
-
slowlog-max-len配置建议
- 线上建议调大慢查询列表,记录慢查询时redis会对长命令做截断操作,并不会占用大量内存。
- 增大慢查询列表可以减缓慢查询被剔除的可能,线上可设置为1000以上
-
slowlog-log-slower-than配置建议
- 默认值超过10毫秒判定为慢查询,需要根据redis并发量调整该值。
- 由于redis采用单线程响应命令,对于高流量的场景,如果命令执行时间在1毫秒以上,那么redis最多可支撑的OPS不到1000。因此对于高OPS场景的redis建议设置为1毫秒。
3.流水线pipeline
- 经历了1次pipeline(n条命令)= 1次网络时间+n次命令时间,这大大减少了网络时间的开销,这就是流水线。
即相对于批量网络命令通信模型来说,减少了n-1次网络时间。 - 执行一条命令在redis段可能需要几百微妙,而在网络光纤中需要13毫秒。
在执行批量操作而没有使用pipeline功能,会将大量时间耗费在网络传输过程上;而使用pipeline后,只需要经过一次网络传输,然后批量在redis端进行命令操作,这会大大提高效率。
即相当于网络I/O多路复用技术。 - 实践示例:
- 引入jedis依赖包:
<dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>4.2.3</version> </dependency>- 代码如下:
Jedis jedis; @Before public void init() { //创建redis连接实例 jedis = new Jedis("192.168.126.12", 6379); } /** * 没有pipeline * 4492ms */ @Test public void noPipelineTest() { //开始时间 long startTime = System.currentTimeMillis(); //添加hash元素 for (int i = 0; i < 10000; i++) { jedis.hset("hashkey"+i,"field"+i,"value"+i); } //结束时间 long endTime = System.currentTimeMillis(); System.out.println(endTime-startTime); } /** * 使用pipeline * 102毫秒 */ @Test public void pipelineTest() { //开始时间 long startTime = System.currentTimeMillis(); //添加hash元素 // for (int i = 0; i < 100; i++) { // Pipeline pipelined = jedis.pipelined(); // for (int j = i*100; j < (i+1)*100; j++) { // pipelined.hset("hashkey"+i,"field"+j,"value"+j); // } // pipelined.syncAndReturnAll(); // } Pipeline pipelined = jedis.pipelined(); for (int i = 0; i < 10000; i++) { pipelined.hset("hashkey"+i,"field"+i,"value"+i); } //结束时间 long endTime = System.currentTimeMillis(); System.out.println(endTime-startTime); } @After public void close() { //关闭jedis连接 jedis.close(); }
二、redis数据安全
1.redis数据安全
1.持久化机制
- 由于redis的数据都存放在内存中,如果没有配置持久化,redis重启后数据就全丢失了,于是需要开启redis的持久化功能,将数据保存到磁盘上,当Redis重启后可以从磁盘中恢复数据。
- 持久化的意义在于故障恢复。
部署一个redis,可以作为cache缓存,同时也可以保存一些比较重要的数据。 - redis提供了两个不同形式的持久化方式。
- RDB(Redis Database)
- AOF(Append Only File)
2. RDB持久化机制
- RDB是在指定的时间间隔内将数据集快照写入磁盘,它恢复时是将快照文件直接读到内存
这种格式是经过压缩的二进制文件。 - RDB保存的文件,在redis.conf中的配置文件名称,默认为dump.rdb。
默认是在redis启动时命令行所在的目录下/usr/local/bin,但是我的dump.rdb默认是与redis.conf文件同一目录,也就是redis目录下/usr/local/redis。
dump.rdb的保存路径是在redis.conf中的dir那里配置的。 - RDB快照的三种触发机制
- RDB配置
即在redis.conf中以save 300 5的这种形式进行配置,就是说在300s内,至少有5个key的值变化,则保存(更新快照) - FLUSHALL命令
执行FLUSHALL命令,也会触发rdb规则。 - save与bgsave
手动触发redis进行RDB持久化的命令- save,该命令会阻塞当前redis服务器,执行save命令期间,redis不能处理其他命令,直到RDB过程完成为止,不建议使用。
- bgsave,执行该命令时,redis会在后台异步进行快照操作,快照的同时还可以响应客户端请求。
- RDB配置
- stop-writes-on-bgsave-error
默认值是yes。当redis无法写入磁盘时,直接关闭redis的写操作。 - rdbcompression
默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是,redis会采用LZF算法进行压缩。如果你不想消耗CPU来进行压缩的话,可以设置为关闭,但是存储在磁盘上的快照会比较大。 - rdbchecksum
默认值是yes。在存储快照后,还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取最大性能提升,可以选择关闭此功能。 - 恢复数据
只需要将rdb文件放在Redis的启动目录,Redis启动时会自动加载dump.rdb并恢复数据。
优势:
- 适合大规模的数据恢复
- 对数据完整性和一致性要求不高更适用
- 节省磁盘空间
- 恢复速度快
劣势:
- 备份周期在一定间隔时间做一次备份,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改。
3. AOF持久化机制
- AOF是以日志的形式来记录每个写操作,将Redis执行过的所有写指令记录下来。
AOF默认不开启,可以在redis.conf中进行配置。AOF文件的保存路径和RDB一致,如果AOF和RDB同时启动,则Redis默认读取AOF文件的数据。 - 开启AOF:
appendonly yes - AOF同步频率设置
- appendfsync always
始终同步,每次redis的写入都会立刻记入日志,性能较差,但数据完整性比较好。 - appendfsync everysec
每秒同步,每秒记入日志一次,如果宕机,本秒数据可能丢失。 - appendfsync no
redis不主动进行同步,把同步时机交给操作系统。
- appendfsync always
优势:
- 备份机制更稳健,丢失数据概率更低。
- 可读的日志文本,通过操作AOF文件,可以处理错误操作。
劣势:
- 比起RDB会占用更多的磁盘空间。
- 恢复备份速度要慢。
- 每次读写都同步的话,有一定的性能压力。
4.选用持久化方式
- RDB数据快照文件,都是每隔5分钟或者更长时间生成一次,这个时候一旦redis宕机,那么会丢失最近5分钟的数据。
- 通过AOF做冷备,没有RDB做冷备恢复速度来得更快。
- RDB每次简单粗暴生成数据快照,更加健壮,可以避免AOF这种复杂的备份和恢复机制的bug。
- 综合使用AOF和RDB两种持久化机制
用AOF来保证数据不丢失,作为恢复数据的第一选择,用RDB来做不同程度的冷备,在AOF文件都丢失或损坏不可用的时候,还可以使用RDB来进行快速的数据恢复。
2.redis事务
1.事务概念与ACID特性
- 在数据库层面,事务是指一组操作,这些操作要么全都被成功执行,要么全都不执行。
- 数据库事务的四大特性:
- A:Atomic,原子性,将所有SQL作为原子工作单位执行,要么全部执行,要么全部不执行。
- C:Consistent,一致性,事务完成后,所有数据的状态都是一致的,即A账户只要减去了100,B帐号则必定加上了100;
- I:Isolation,隔离性,如果有多个事务并发执行,每个事务做出的修改必须与其他事务隔离。
- D:Duration,持久性,即事务完成后,对数据库数据的修改被持久化存储。
- Redis事务
是一组命令的集合,一个事务中所有命令都将被序列化,按一次性、顺序性、排他性地执行一系列的命令。 - Redis事务的三大特性
- 单独的隔离操作:事务中所有命令都将被序列化、按顺序地执行。事务在执行过程中,不会被其他客户端发来的命令请求所打断。
- 没有隔离级别的概念:队列中的命令没有提交之前都不会被实际执行,因为事务提交前任何指令都不会被实际执行,也就不存在"事务内的查询看到事务内的更新,在事务外的查询不能看到"。
- 不保证原子性:redis同一个事务中如果有一条命令执行失败,其后的命令仍会被执行,没有回滚。
- Redis事务执行的三个阶段
- 以
MULTI开始一个事务 - 将多个命令入队到事务中,接到这些命令并不会立即执行,而是放到等待执行的事务队列里面
- 由
EXEC命令触发事务执行
- 以
2.事务基本操作
- 事务从输入Multi命令开始,输入的命令都会依次压入命令缓冲队列中,并不会执行,直到输入Exec后,redis会将之前的命令缓冲队列中的命令依次执行。
组队过程中,可以通过discard来放弃组队。也就是放弃命令缓冲队列的所有命令。
命令集合中有错误指令(语法错误),命令集合全部失败(不执行)。
运行时错误,即非语法错误,正确命令都会执行,错误命令返回错误。
总结:
1.使用redis网页缓存可以增加并发量,就是网页有缓存时,直接拿缓存,如果没有缓存,则去访问数据库,将数据库的数据缓存进redis,再返回,下次访问就是访问缓存。
2.慢查询用以定位系统中存在的慢操作。对于高OPS场景,慢查询阈值slowlog-log-slower-than设置为1000,也就是1毫秒。而慢查询日志最大条数slowlog-max-len设置为1000以上。当慢查询日志条数达到上限时,再去记录新的慢查询日志会把最早的慢查询日志依次剔除。
pipeline技术主要减少了网络时间的开销,,只需要一次网络时间,相当于多路复用技术。
3.redis持久化机制主要解决数据丢失的问题,开启持久化会将数据保存到磁盘。redis持久化又分为RDB和AOF,即快照和写操作日志的形式。AOF解决数据丢失相对于RDB更稳健,但是RDB恢复数据速度更快,磁盘占用更小,综合使用AOF和RDB持久化,将AOF作为主持久化,当AOF出现bug或丢失,还可以使用数据快照RDB恢复数据。
Redis事务是一组命令的集合,一个事务中所有命令都将被序列化,按一次性、顺序性、排他性地执行一系列的命令。
在数据库层面,事务是指一组操作,这些操作要么全都被成功执行,要么全都不执行。
Redis是基于队列实现事务,Redis事务有三大特性,分别是单独的隔离操作、没有隔离级别的概念、不保证原子性。数据库事务有ACID四大特性,分别是原子性、一致性、隔离性、持久性。
由Multi开启事务,Exec执行该事务的命令集或者使用Discard取消该事务的命令集。