今天在做拟合优度检验时,一直都使用手动的代码编写计算,忽然发现scipy包中已经封装好了现成的,就想记录一下新发现。并给出实例使用吧!
1、卡方统计量
在分类数据分析中,进行拟合优度检验时,一般使用卡方(Chi-squared)拟合优度统计量。这是因为拟合优度检验用于检查观察值与理论期望值之间的偏离程度,特别是在一个分类变量中的多个类别之间。
1.1、计算公式
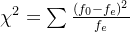
其中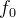
1.2、代码实现
chi2_contingency是Python中scipy.stats库中的一个函数,用于执行卡方独立性检验和卡方拟合优度检验。这个函数可以用于分析分类数据中的两个或多个分类变量之间的关系,以确定它们是否相互独立或是否符合预期的分布。
自由度 = (Row-1)(Column-1)
import pandas as pd
from scipy.stats import chi2_contingency
# 创建一个示例DataFrame
data = {
'Column1': [31,8,12,10],
'Column2': [13,16,10,5],
'Column3': [16,7,17,7]
}
index = ['row1', 'row2', 'row3','row4']
df = pd.DataFrame(data, index=index)
# 计算卡方统计量
chi2, p, dof, expected = chi2_contingency(df)
print("卡方统计量:", chi2)
print("p值:", p)
print("自由度:", dof)
print("期望频数:", expected)2、示例
以下列表格4
| 会计 | 统计 | 市场营销 | 总计 | |
| 专业一 | 31 | 13 | 16 | 60 |
| 专业二 | 8 | 16 | 7 | 31 |
| 专业三 | 12 | 10 | 17 | 39 |
| 专业四 | 10 | 5 | 7 | 22 |
| 总计 | 61 | 44 | 47 | 152 |
原假设:
备择假设:
、
、
、
不完全相同
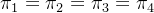
2.1、计算实现
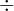
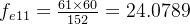
计算每一个
| 31 | 13 | 16 | 8 | 16 | 7 | 12 | 10 | 17 | 10 | 5 | 7 |
| 24 | 17 | 19 | 12 | 9 | 10 | 16 | 11 | 12 | 9 | 6 | 7 |
 | 7 | -4 | -3 | -4 | 7 | -3 | -4 | -1 | 5 | 1 | 1 | 0 |
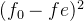 | 49 | 16 | 9 | 16 | 49 | 9 | 16 | 1 | 25 | 1 | 1 | 0 |
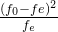 | 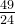 | 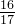 | 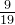 | 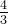 | 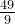 | 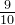 | 1 | 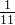 | 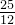 | 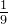 | 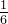 | 0 |
故:卡方统计量 = 14.58 (最后一行全加起来就是这个数值了)
注:人工计算的数据由于都是按照四舍五入,故在最后的计算结果也会存在一定的误差
2.1、代码求解
import pandas as pd
from scipy.stats import chi2_contingency
# 创建一个示例DataFrame
data = {
'会计': [31,8,12,10],
'统计': [13,16,10,5],
'市场营销': [16,7,17,7]
}
index = ['专业A', '专业B', '专业C','专业D']
df = pd.DataFrame(data, index=index)
# 计算卡方统计量
chi2, p, dof, expected = chi2_contingency(df)
print("卡方统计量:", chi2)
print("p值:", p)
print("自由度:", dof)
print("期望频数:", expected)结果输出:
| 卡方统计量 | P值 | 自由度 | 期望频数 |
| 14.701859 | 0.0227067 | 6 | [[24.07894737 17.36842105 18.55263158] [12.44078947 8.97368421 9.58552632] [15.65131579 11.28947368 12.05921053] [ 8.82894737 6.36842105 6.80263158]] |
可以看到此时的卡方统计量为14.7,与上面手动计算的会存在一些误差,但影响不大。
结论:
此时以0.05的显著性水平可以得到 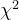
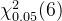
情感如泉涌,文字成舟。