Prompt Pre-Training with Twenty-Thousand Classes for Open-Vocabulary Visual Recognition(NeurIPS 2023)
- 提出了一种用于视觉语言模型的提示(prompt)预训练方法,称为 POMP
- POMP 在内存和计算方面都很高效,使得学习到的提示能够为超过两万类的丰富视觉概念凝聚语义信息。
- 代码:https://github.com/amazon-science/prompt-pretraining
1 Introduction
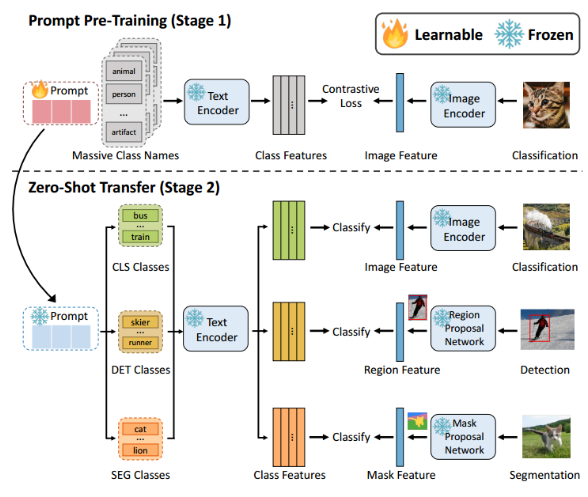
将pre-training应用于prompt-learning的一篇文章,将模型在imagenet-21k上进行预训练时,存在GPU显存资源受限的问题,作者提出了local contrast和local correction来解决显存过载的问题。
2 Motivation
-
问题
作者指出COOP等方法将soft promp tuning到task-specific datasets上,因此训练得到的prompt很难泛化到new classes。 -
解决
提出要在更大的数据集上训练,得到universal prompt(通用的提示)。
3 Method
3.2 POMP
提示调优的计算和缓存成本与类别数量N成正比,在ImageNet-21k上高达316.4GB
![![[POMPf3.png|400]]](/image/aHR0cHM6Ly9pbWctYmxvZy5jc2RuaW1nLmNuL2RpcmVjdC85OWYxMjE5NDU2ZjE0MmQ2OTIwZjY2YTRiMDlmM2YwZi5wbmcjcGljX2NlbnRlcg%3D%3D)
作者提出高效训练的POMP方法,包含以下两个部分:
- local contrast:通过负类抽样减少进行对比学习的类别数量
- local correction:通过调整负类的logits分数来减少局部对比造成的偏差。
3.2.1 Local contrast
传统的计算contrastive loss时,需要正样本与所有负样本对比,需要的资源过高,因此提出每次训练时,从21k的类别中采样k个类别,包括真类y和k-1个负类,用于与ground truth的contrastive loss的计算。采样是通过均匀分布采样。
消融:均匀分布、频率分布、相似度分布
![![[POMPt12.png]]](/image/aHR0cHM6Ly9pbWctYmxvZy5jc2RuaW1nLmNuL2RpcmVjdC9lMDNjMDQyMTNhYTc0YjE4ODcyYWJmYzE2MGIzNTI3OS5wbmcjcGljX2NlbnRlcg%3D%3D)
频率分布:
![![[POMPg8.png]]](/image/aHR0cHM6Ly9pbWctYmxvZy5jc2RuaW1nLmNuL2RpcmVjdC82OTQ1OTBhNjNjNDc0YTlmOTJkOGRjYWI2MmUwOGU3My5wbmcjcGljX2NlbnRlcg%3D%3D)
相似度分布:
对hard负类进行抽样,hard负类是指与输入图像x具有较高相似性的类别,很容易与正确类别混淆。
![![[POMPg9.png]]](/image/aHR0cHM6Ly9pbWctYmxvZy5jc2RuaW1nLmNuL2RpcmVjdC83ZWM0ZWU5NWUzNzQ0ZmQzYTNiMGFmOTZiZWQ3Y2JhNy5wbmcjcGljX2NlbnRlcg%3D%3D)
动机类似于NCE-based,抽取一个batch作为样本。
3.2.2 Local correction
由于计算contrastive loss时没有使用所有的负样本,所以会导致训练出来的prompt存在偏差,因此提出local correction来规范这个prompt。
我们在logits计算中添加了一个局部矫正项m。

4 实验
4.1 实验细节
- CLIP ViT/B-16
- 16 shots
- prompt 长度=16
- K=1000
4.2 zero-shot inference
![![[POMPt1.png|300]]](/image/aHR0cHM6Ly9pbWctYmxvZy5jc2RuaW1nLmNuL2RpcmVjdC9hZGJhNTBhNDlmZjg0ZTlmYjhmMjNmMjBjNzRiNTBlNy5wbmcjcGljX2NlbnRlcg%3D%3D)
4.5 详细理解
通常,图像特征和它的真实类别特征应该非常接近(对齐),所有类别特征应该均匀分布,保留最大信息量并使得类别更容易区分。

POMP在特征空间中的优势:
- 确保图像特征与真实类别特征的紧密对齐
- 使类别特征在特征空间中均匀分布。