神经网络优化方法 正则化方法 价格分类案例
梯度下降法
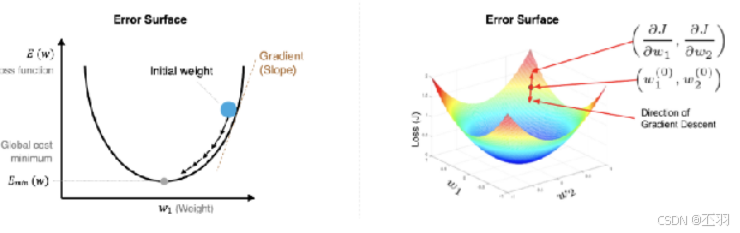
梯度下降法是一种寻找损失函数最小的方法,从数学上的角度来看,梯度的方向是函数增长速度最快的方向,那么梯度的反方向就是函数减少最快的方向,所以有:
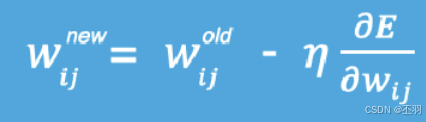
其中,η是学习率,如果学习率太小,那么每次训练之后得到的效果都太小,增大训练的时间成本。如果,学习率太大,那就有可能直接跳过最优解,进入无限的训练中。解决的方法就是,学习率也需要随着训练的进行而变化。
- 在进行模型训练时,有三个基础的概念:
- Epoch: 使用全部数据对模型进行以此完整训练,训练轮次
- Batch_size: 使用训练集中的小部分样本对模型权重进行以此反向传播的参数更新,每次训练每批次样本数量
- Iteration: 使用一个 Batch 数据对模型进行一次参数更新的过程
- 假设数据集有 50000 个训练样本,现在选择 Batch Size = 256 对模型进行训练。
- 每个 Epoch 要训练的图片数量:50000
- 训练集具有的 Batch 个数:50000/256+1=196
- 每个 Epoch 具有的 Iteration 个数:196
- 10个 Epoch 具有的 Iteration 个数:1960
在深度学习中,梯度下降的几种方式的根本区别就在于 Batch Size不同,如下表所示:
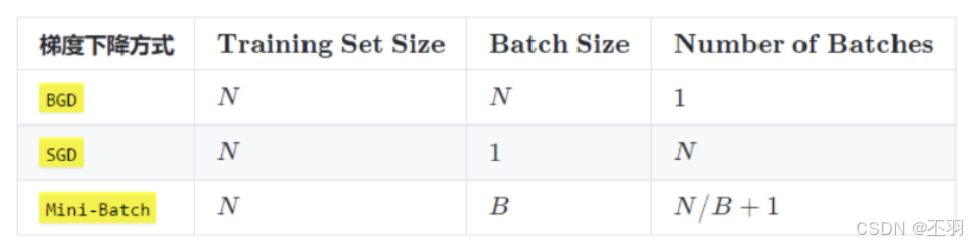
上表中 Mini-Batch 的 Batch 个数为 N / B + 1 是针对未整除的情况。整除则是 N / B。
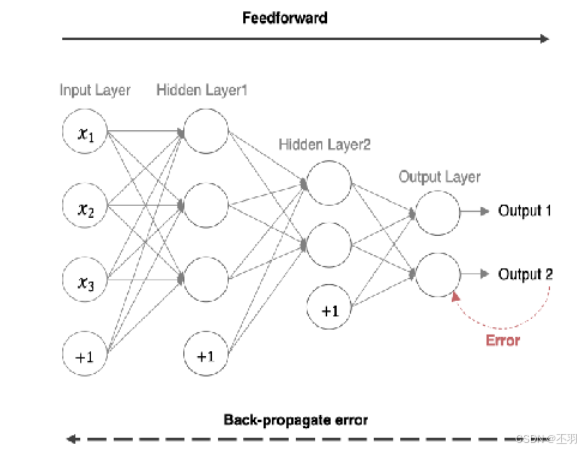
反向传播(BP算法)
- 前向传播: 指的是数据输入的神经网络中,逐层向前传输,一直运输到输出层为止
- 反向传播(back propagation): 利用损失函数ERROR 从后往前,结合梯度下降算法,依次求各个参数的偏导,并进行参数更新
import torch
from torch import nn
from torch import optim
# 创建神经网络类
class Model(nn.Module):
# 初始化参数
def __init__(self):
# 调用父类方法
super(Model, self).__init__()
# 创建网络层
self.linear1 = nn.Linear(2, 2)
self.linear2 = nn.Linear(2, 2)
# 初始化神经网络参数
self.linear1.weight.data = torch.tensor([[0.15, 0.20], [0.25, 0.30]])
self.linear2.weight.data = torch.tensor([[0.40, 0.45], [0.50, 0.55]])
self.linear1.bias.data = torch.tensor([0.35, 0.35])
self.linear2.bias.data = torch.tensor([0.60, 0.60])
# 前向传播方法
def forward(self, x):
# 数据经过第一层隐藏层
x = self.linear1(x)
# 计算第一层激活值
x = torch.sigmoid(x)
# 数据经过第二层隐藏层
x = self.linear2(x)
# 计算第二层激活值
x = torch.sigmoid(x)
return x
if __name__ == '__main__':
# 定义网络输入值和目标值
inputs = torch.tensor([[0.05, 0.10]])
target = torch.tensor([[0.01, 0.99]])
# 实例化神经网络对象
model = Model()
output = model(inputs)
print("output-->", output)
loss = torch.sum((output - target) ** 2) / 2 # 计算误差
print("loss-->", loss)
# 优化方法和反向传播算法
optimizer = optim.SGD(model.parameters(), lr=0.5)
optimizer.zero_grad()
loss.backward()
print("w1,w2,w3,w4-->", model.linear1.weight.grad.data)
print("w5,w6,w7,w8-->", model.linear2.weight.grad.data)
optimizer.step()
# 打印神经网络参数
print(model.state_dict())
梯度下降的优化方法
-
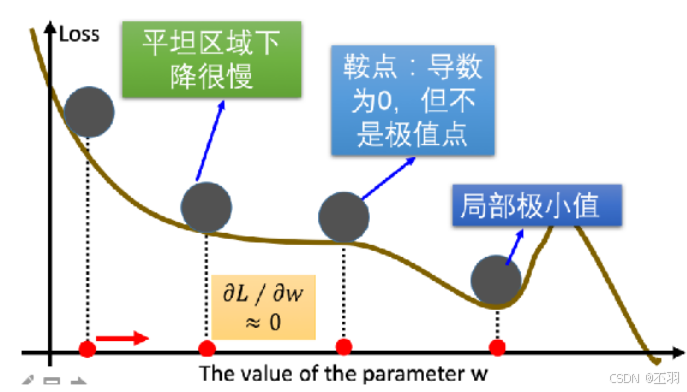
梯度下降优化算法中,可能会碰到以下情况:
- 碰到平缓区域,梯度值较小,参数优化变慢
- 碰到 “鞍点” ,梯度为 0,参数无法优化
- 碰到局部最小值,参数不是最优
对于这些问题, 出现了一些对梯度下降算法的优化方法,例如:Momentum、AdaGrad、RMSprop、Adam 等
指数加权平均
指数移动加权平均是参考个数值,并且各数值的权重都不同,距离越远的数字对平均数计算的贡献就越小(权重较小),距离越近泽对平均数的计算贡献就越大(权重越大)
比如:明天气温怎么样,和昨天气温有很大关系,而和一个月前的气温关系就小一些。
计算公式可以用下面的式子来表示:
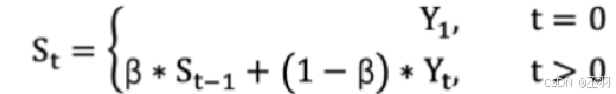
- St 表示指数加权平均值;
- Yt 表示 t 时刻的值;
- β 调节权重系数,该值越大平均数越平缓。
import torch
import matplotlib.pyplot as plt
ELEMENT_NUMBER = 30
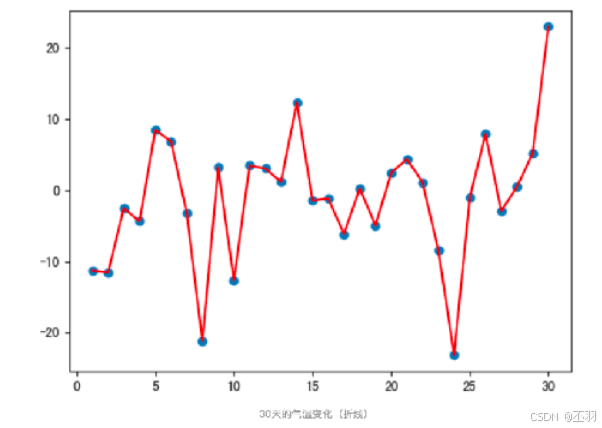
# 1. 实际平均温度
def test01():
# 固定随机数种子
torch.manual_seed(0)
# 产生30天的随机温度
temperature = torch.randn(size=[ELEMENT_NUMBER,]) * 10
print(temperature)
# 绘制平均温度
days = torch.arange(1, ELEMENT_NUMBER + 1, 1)
plt.plot(days, temperature, color='r')
plt.scatter(days, temperature)
plt.show()
# 2. 指数加权平均温度
def test02(beta=0.9):
torch.manual_seed(0) # 固定随机数种子
temperature = torch.randn(size=[ELEMENT_NUMBER,]) * 10 # 产生30天的随机温度
exp_weight_avg = []
for idx, temp in enumerate(temperature, 1): # 从下标1开始
# 第一个元素的的 EWA 值等于自身
if idx == 1:
exp_weight_avg.append(temp)
continue
# 第二个元素的 EWA 值等于上一个 EWA 乘以 β + 当前气温乘以 (1-β)
new_temp = exp_weight_avg[idx - 2] * beta + (1 - beta) * temp
exp_weight_avg.append(new_temp)
days = torch.arange(1, ELEMENT_NUMBER + 1, 1)
plt.plot(days, exp_weight_avg, color='r')
plt.scatter(days, temperature)
plt.show()
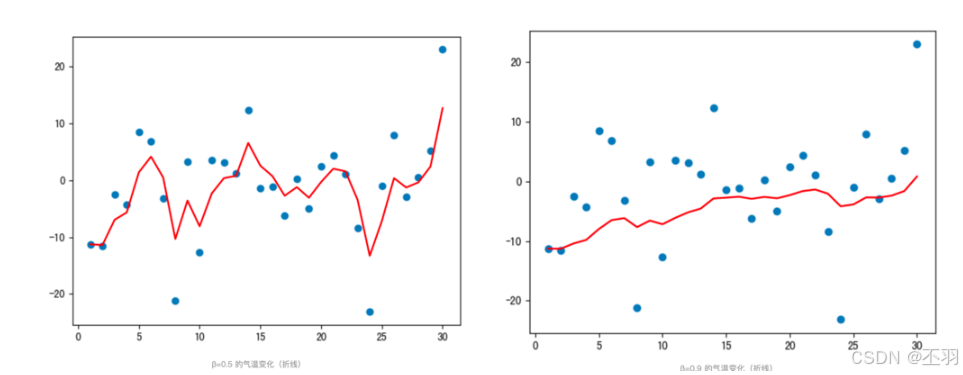
上图是β为0.5和0.9时的结果,从中可以看出:
指数加权平均绘制出的气氛变化曲线更加平缓,
β 的值越大,则绘制出的折线越加平缓,波动越小。
动量算法Momentum
梯度计算公式:Dt = β * St-1 + (1- β) * Wt
- St-1 表示历史梯度移动加权平均值
- Wt 表示当前时刻的梯度值
- Dt 为当前时刻的指数加权平均梯度值
- β 为权重系数
假设:权重 β 为 0.9,例如:
第一次梯度值:s1 = d1 = w1
第二次梯度值:d2=s2 = 0.9 * s1 + w2 * 0.1
第三次梯度值:d3=s3 = 0.9 * s2 + w3 * 0.1
第四次梯度值:d4=s4 = 0.9 * s3 + w4 * 0.1
梯度下降公式中梯度的计算,就不再是当前时刻 t 的梯度值,而是历史梯度值的指数移动加权平均值。公式修改为:
W_t+1 = W_t - a * Dt
Monmentum 优化方法是如何一定程度上克服 “平缓”、”鞍点” 的问题呢?
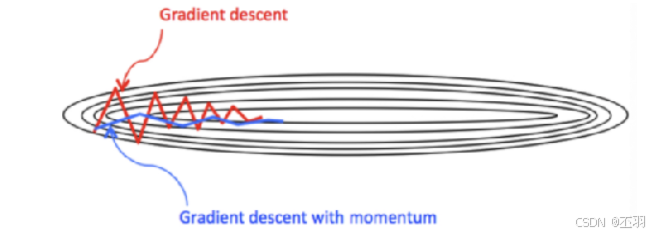
- 当处于鞍点位置时,由于当前的梯度为 0,参数无法更新。但是 Momentum 动量梯度下降算法已经在先前积累了一些梯度值,很有可能使得跨过鞍点。
- 由于 mini-batch 普通的梯度下降算法,每次选取少数的样本梯度确定前进方向,可能会出现震荡,使得训练时间变长。Momentum 使用移动加权平均,平滑了梯度的变化,使得前进方向更加平缓,有利于加快训练过程。
def test01():
# 1 初始化权重参数
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
y = ((w ** 2) / 2.0).sum()
# 2 实例化优化方法:SGD 指定参数beta=0.9
optimizer = torch.optim.SGD([w], lr=0.01, momentum=0.9)
# 3 第1次更新 计算梯度,并对参数进行更新
optimizer.zero_grad()
y.backward()
optimizer.step()
print('第1次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy()))
# 4 第2次更新 计算梯度,并对参数进行更新
# 使用更新后的参数机选输出结果
y = ((w ** 2) / 2.0).sum()
optimizer.zero_grad()
y.backward()
optimizer.step()
print('第2次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy()))
adaGrad
AdaGrad 通过对不同的参数分量使用不同的学习率,AdaGrad 的学习率总体会逐渐减小。
其计算步骤如下:
初始化学习率 α、初始化参数 θ、小常数 σ = 1e-6
初始化梯度累积变量 s = 0
从训练集中采样 m 个样本的小批量,计算梯度 g
累积平方梯度 s = s + g ⊙ g,⊙ 表示各个分量相乘
学习率 α 的计算公式如下:
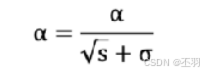
参数更新公式如下:
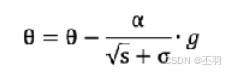
重复 2-4 步骤,即可完成网络训练。
AdaGrad 缺点是可能会使得学习率过早、过量的降低,导致模型训练后期学习率太小,较难找到最优解。
def test02():
# 1 初始化权重参数
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
y = ((w ** 2) / 2.0).sum()
# 2 实例化优化方法:adagrad优化方法
optimizer = torch.optim.Adagrad ([w], lr=0.01)
# 3 第1次更新 计算梯度,并对参数进行更新
optimizer.zero_grad()
y.backward()
optimizer.step()
print('第1次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy()))
# 4 第2次更新 计算梯度,并对参数进行更新
# 使用更新后的参数机选输出结果
y = ((w ** 2) / 2.0).sum()
optimizer.zero_grad()
y.backward()
optimizer.step()
print('第2次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy()))
RMSProp
RMSProp 优化算法是对 AdaGrad 的优化. 最主要的不同是,其使用指数移动加权平均梯度替换历史梯度的平方和。其计算过程如下:
初始化学习率 α、初始化参数 θ、小常数 σ = 1e-6
初始化参数 θ
初始化梯度累计变量 s
从训练集中采样 m 个样本的小批量,计算梯度 g
使用指数移动平均累积历史梯度,公式如下:
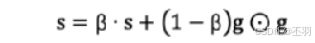
学习率 α 的计算公式如下:
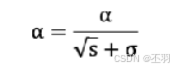
参数更新公式如下:
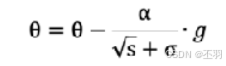
def test03():
# 1 初始化权重参数
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
y = ((w ** 2) / 2.0).sum()
# 2 实例化优化方法:RMSprop算法,其中alpha对应这beta
optimizer = torch.optim.RMSprop([w], lr=0.01,alpha=0.9)
# 3 第1次更新 计算梯度,并对参数进行更新
optimizer.zero_grad()
y.backward()
optimizer.step()
print('第1次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy()))
# 4 第2次更新 计算梯度,并对参数进行更新
# 使用更新后的参数机选输出结果
y = ((w ** 2) / 2.0).sum()
optimizer.zero_grad()
y.backward()
optimizer.step()
print('第2次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy()))
Adam
- Momentum 使用指数加权平均计算当前的梯度值
- AdaGrad、RMSProp 使用自适应的学习率
- Adam优化算法(Adaptive Moment Estimation,自适应矩估计)将 Momentum 和 RMSProp 算法结合在一起。
1.修正梯度: 使⽤梯度的指数加权平均
2.修正学习率: 使用梯度平方的指数加权平均。
def test04():
# 1 初始化权重参数
w = torch.tensor([1.0], requires_grad=True)
y = ((w ** 2) / 2.0).sum()
# 2 实例化优化方法:Adam算法,其中betas是指数加权的系数
optimizer = torch.optim.Adam([w], lr=0.01,betas=[0.9,0.99])
# 3 第1次更新 计算梯度,并对参数进行更新
optimizer.zero_grad()
y.backward()
optimizer.step()
print('第1次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy()))
# 4 第2次更新 计算梯度,并对参数进行更新
# 使用更新后的参数机选输出结果
y = ((w ** 2) / 2.0).sum()
optimizer.zero_grad()
y.backward()
optimizer.step()
print('第2次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy()))
学习率衰减方法
等间隔学习率衰减
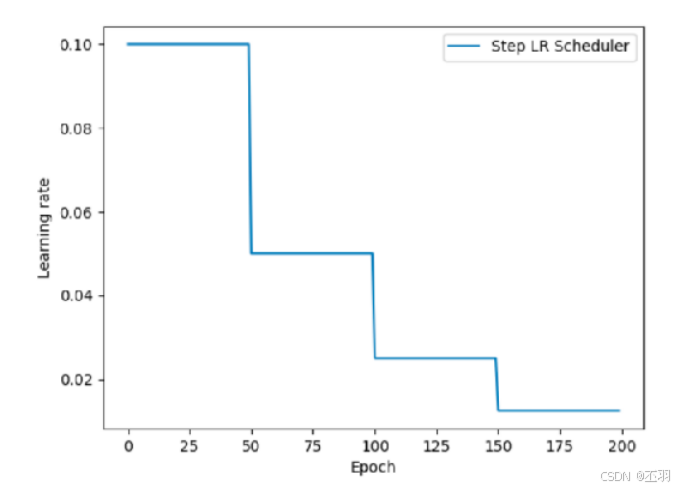
lr_scheduler.StepLR(optimizer, step_size, gamma=0.1)
# 功能:等间隔-调整学习率
# 参数:
# step_size:调整间隔数=50
# gamma:调整系数=0.5
# 调整方式:lr = lr * gamma
def test_StepLR():
# 0.参数初始化
LR = 0.1 # 设置学习率初始化值为0.1
iteration = 10
max_epoch = 200
# 1 初始化参数
y_true = torch.tensor([0])
x = torch.tensor([1.0])
w = torch.tensor([1.0], requires_grad=True)
# 2.优化器
optimizer = optim.SGD([w], lr=LR, momentum=0.9)
# 3.设置学习率下降策略
scheduler_lr = optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.5)
# 4.获取学习率的值和当前的epoch
lr_list, epoch_list = list(), list()
for epoch in range(max_epoch):
lr_list.append(scheduler_lr.get_last_lr()) # 获取当前lr
epoch_list.append(epoch) # 获取当前的epoch
for i in range(iteration): # 遍历每一个batch数据
loss = ((w*x-y_true)**2)/2.0 # 目标函数
optimizer.zero_grad()
# 反向传播
loss.backward()
optimizer.step()
# 更新下一个epoch的学习率
scheduler_lr.step()
# 5.绘制学习率变化的曲线
plt.plot(epoch_list, lr_list, label="Step LR Scheduler")
plt.xlabel("Epoch")
plt.ylabel("Learning rate")
plt.legend()
plt.show()
指定间隔学习率衰减
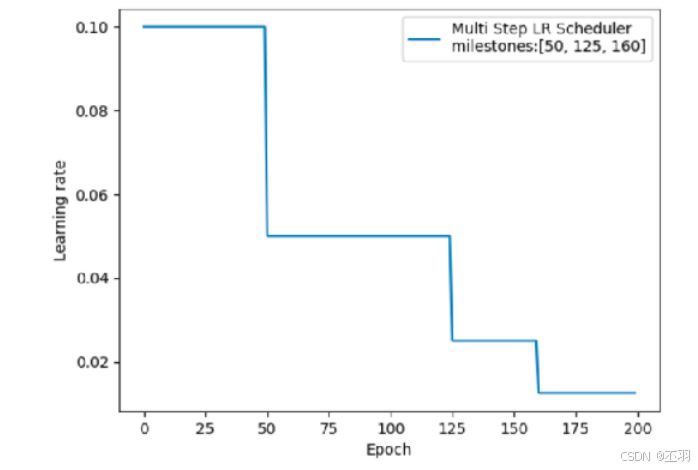
lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1)
# 功能:指定间隔-调整学习率
# 主要参数:
# milestones:设定调整轮次:[50, 125, 160]
# gamma:调整系数
# 调整方式:lr = lr * gamma
def test_MultiStepLR():
torch.manual_seed(1)
LR = 0.1
iteration = 10
max_epoch = 200
weights = torch.randn((1), requires_grad=True)
target = torch.zeros((1))
print('weights--->', weights, 'target--->', target)
optimizer = optim.SGD([weights], lr=LR, momentum=0.9)
# 设定调整时刻数
milestones = [50, 125, 160]
# 设置学习率下降策略
scheduler_lr = optim.lr_scheduler.MultiStepLR(optimizer, milestones=milestones, gamma=0.5)
lr_list, epoch_list = list(), list()
for epoch in range(max_epoch):
lr_list.append(scheduler_lr.get_last_lr())
epoch_list.append(epoch)
for i in range(iteration):
loss = torch.pow((weights - target), 2)
optimizer.zero_grad()
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
# 更新下一个epoch的学习率
scheduler_lr.step()
plt.plot(epoch_list, lr_list, label="Multi Step LR Scheduler\nmilestones:{}".format(milestones))
plt.xlabel("Epoch")
plt.ylabel("Learning rate")
plt.legend()
plt.show()
指数学习率衰减
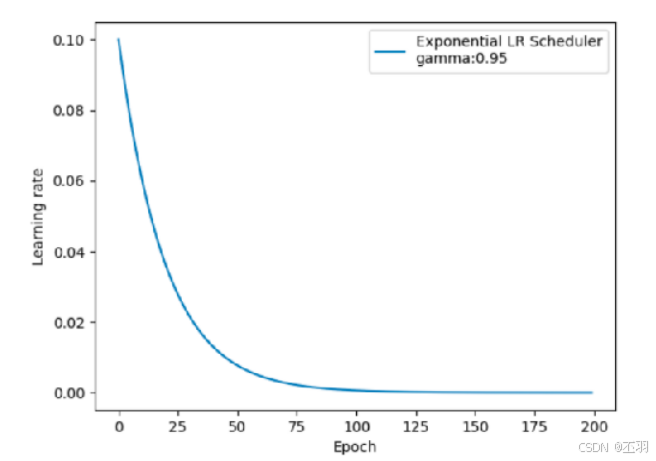
lr_scheduler.ExponentialLR(optimizer, gamma)
# 功能:按指数衰减-调整学习率
# 主要参数:
# gamma:指数的底
# 调整方式
# lr= lr∗ gamma^epoch
def test_ExponentialLR():
# 0.参数初始化
LR = 0.1 # 设置学习率初始化值为0.1
iteration = 10
max_epoch = 200
# 1 初始化参数
y_true = torch.tensor([0])
x = torch.tensor([1.0])
w = torch.tensor([1.0], requires_grad=True)
# 2.优化器
optimizer = optim.SGD([w], lr=LR, momentum=0.9)
# 3.设置学习率下降策略
gamma = 0.95
scheduler_lr = optim.lr_scheduler.ExponentialLR(optimizer, gamma=gamma)
# 4.获取学习率的值和当前的epoch
lr_list, epoch_list = list(), list()
for epoch in range(max_epoch):
lr_list.append(scheduler_lr.get_last_lr())
epoch_list.append(epoch)
for i in range(iteration): # 遍历每一个batch数据
loss = ((w*x-y_true)**2)/2.0
optimizer.zero_grad()
# 反向传播
loss.backward()
optimizer.step()
# 更新下一个epoch的学习率
scheduler_lr.step()
# 5.绘制学习率变化的曲线
plt.plot(epoch_list, lr_list, label="Multi Step LR Scheduler")
plt.xlabel("Epoch")
plt.ylabel("Learning rate")
plt.legend()
plt.show()
正则化方法
- 希望在新样本上的泛化能力强,许多机器学习算法都采用相关的策略来减小测试误差,这些策略被统称为正则化
- 神经网络的强大的表示能力经常遇到过拟合,所以需要不同形式的正则化策略
- 目前在深度学习中使用较多的策略有范数惩罚,DropOut,特殊的网络层等
Dropout 正则化
在神经网络中模型参数较多,在数据量不足的情况下,很容易过拟合,Dropout(随机失活)是一个简单有效的正则化方法
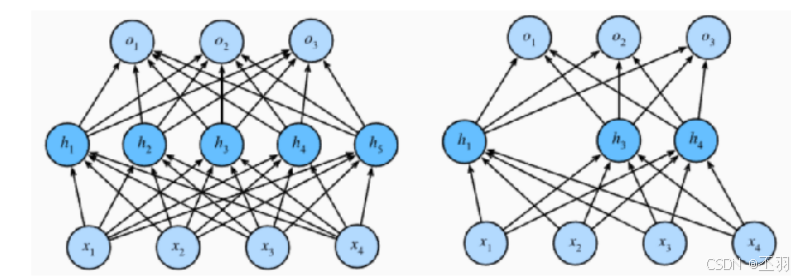
- 在训练过程中,Dropout的实现是让神经元以超参数p的概率停止工作或者激活被设置为0,未被置为0的进行缩放,缩放比例为1/(1-p).训练过程可以认为是对完整的神经网络的一些子集进行训练,每次基于输入数据只更细子网络的参数
- 在测试过程中,随机失活不起作用
import torch
import torch.nn as nn
def test():
# 初始化随机失活层
dropout = nn.Dropout(p=0.4)
# 初始化输入数据:表示某一层的weight信息
inputs = torch.randint(0, 10, size=[1, 4]).float()
layer = nn.Linear(4,5)
y = layer(inputs)
print("未失活FC层的输出结果:\n", y)
y = dropout(y)
print("失活后FC层的输出结果:\n", y)
批量归一化(BN层)
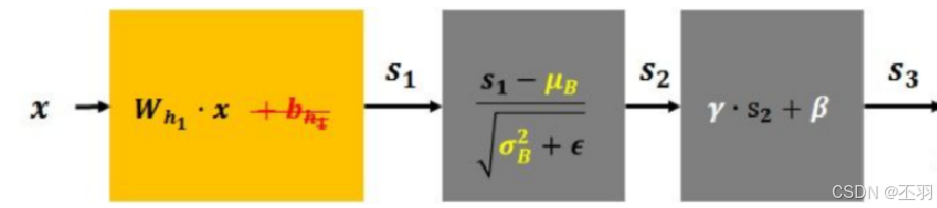
先对数据标准化,再对数据重构(缩放+平移),如下图所示:
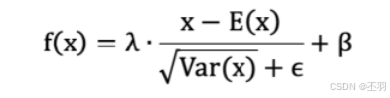
- λ 和 β 是可学习的参数,它相当于对标准化后的值做了一个线性变换,λ 为系数,β 为偏置;
- eps 通常指为 1e-5,避免分母为 0;
- E(x) 表示变量的均值;
- Var(x) 表示变量的方差;
批量归一化层在计算机视觉领域使用较多
价格分类案例
需求分析
小明创办了一家手机公司,他不知道如何估算手机产品的价格。为了解决这个问题,他收集了多家公司的手机销售数据。该数据为二手手机的各个性能的数据,最后根据这些性能得到4个价格区间,作为这些二手手机售出的价格区间。主要包括:

我们需要帮助小明找出手机的功能(例如:RAM等)与其售价之间的某种关系。我们可以使用机器学习的方法来解决这个问题,也可以构建一个全连接的网络。
需要注意的是: 在这个问题中,我们不需要预测实际价格,而是一个价格范围,它的范围使用 0、1、2、3 来表示,所以该问题也是一个分类问题。接下来我们还是按照四个步骤来完成这个任务:
- 准备训练集数据
- 构建要使用的模型
- 模型训练
- 模型预测评估
import torch
from torch.utils.data import TensorDataset
import torch.nn as nn
from torch.utils.data import DataLoader
import torch.optim as optim
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import time
from torchsummary import summary
def create_dataset():
data = pd.read_csv('../data/手机价格预测.csv')
x, y = data.iloc[:, :-1], data.iloc[:, -1]
x, y = x.astype(np.float32), y.astype(np.int64)
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.8, random_state=88)
train_dataset = TensorDataset(torch.from_numpy(x_train.values), torch.tensor(y_train.values))
test_dataset = TensorDataset(torch.from_numpy(x_test.values), torch.tensor(y_test.values))
return train_dataset, test_dataset, x_train.shape[1], len(np.unique(y))
# 构建网络模型
class PhonePriceModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(PhonePriceModel, self).__init__()
# 1. 第一层: 输入为维度为 20, 输出维度为: 128
self.linear1 = nn.Linear(input_dim, 128)
# 2. 第二层: 输入为维度为 128, 输出维度为: 256
self.linear2 = nn.Linear(128, 256)
# 3. 第三层: 输入为维度为 256, 输出维度为: 4
self.linear3 = nn.Linear(256, output_dim)
def forward(self, x):
# 前向传播过程
x = torch.relu(self.linear1(x))
x = torch.relu(self.linear2(x))
output = self.linear3(x)
# 获取数据结果
return output
def train(model, train_dataset):
# 初始化参数 损失函数 优化器
# 损失函数
loss1 = nn.CrossEntropyLoss()
# 优化方法
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
# 训练轮数
num_epochs = 100
# 2个遍历 epoch dataloader
# 遍历每个轮次的数据
for epoch in range(num_epochs):
# 训练时间
start = time.time()
# 计算损失
total_loss = 0.0
total_num = 0
# 初始化数据加载器
dataloader = DataLoader(train_dataset, batch_size=8, shuffle=True)
# 遍历每个batch数据
for x, y in dataloader:
# x, y = x.to(torch.float32), x.to(torch.float32)
x, y = x.to('cuda:0'), y.to('cuda:0')
# 前向传播 损失计算 梯度归零 反向传播 参数更新
output = model(x).to('cuda:0')
loss = loss1(output, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_num += 1
total_loss += loss.item()
# 打印损失变换结果
print('epoch: %4d loss: %.2f, time: %.2fs' % (epoch + 1, total_loss / total_num, time.time() - start))
# 模型持久化
torch.save(model.state_dict(), "../model/phone_price_model.pth")
def test(test_dataset, model):
dataloader = DataLoader(test_dataset, batch_size=8, shuffle=False)
correct = 0
for x, y in dataloader:
# 前向传播
output = model(x)
print(output)
# 获取输出结果(类别)
y_pred = torch.argmax(output, dim=1)
# 计算准确率Acc
# 获取预测正确的个数
correct += (y_pred == y).sum()
# 求预测精度
print('Acc: %.5f' % (correct.item() / len(test_dataset)))
if __name__ == '__main__':
train_dataset, test_dataset, input_dim, class_num = create_dataset()
model = PhonePriceModel(input_dim, class_num)
model.load_state_dict(torch.load("../model/phone_price_model.pth"))
model.to('cuda:0')
test(model, train_dataset)